
Я обязан рассказать вам о фильтре Калмана, потому что он выполняет просто потрясающую задачу.
Как ни удивительно, о нём, похоже, знают немногие разработчики ПО и учёные, и это печалит меня, потому что это очень обобщённый и мощный инструмент для объединения информации в условиях присутствия неопределённости. Иногда его способность извлечения точной информации кажется почти магической, а если вы думаете, что я слишком много болтаю, то взгляните на это видео, в котором я показываю, как фильтр Калмана определяет ориентацию свободно плавающего тела, посмотрев на его вектор скорости. Потрясающе!
Что это такое?
Фильтр Калмана можно использовать любой сфере, где есть неопределённая информация о какой-то динамической системе, и вы можете сделать обоснованное предположение о том, что система будет делать дальше. Даже если в дело вмешивается хаотичная реальность и влияет на предположенное нами чёткое движение, фильтр Калмана часто достаточно неплохо справляется с предсказанием того, что на самом деле произойдёт. И он пользуется корреляциями между безумными явлениями, использовать которые вы могли даже не додуматься!
Фильтры Калмана идеальны для непрерывно меняющихся систем. Они не занимают слишком много памяти (потому что им не нужно хранить историю, кроме как предыдущего состояния) и очень быстры, благодаря чему они хорошо подходят для задач реального времени и встраиваемых систем.
В большинстве статей, которые вы найдёте в Google, математика реализации фильтра Калмана выглядит довольно пугающе. И это плохо, ведь на самом деле фильтр Калмана очень легко
и просто понять, если смотреть на него под правильным углом. Поэтому он является отличной темой для статьи, и я попытаюсь раскрыть его на примере чётких и понятных изображений и цветов. От вас не требуется многого, достаточно знать основы теории вероятности и матриц.
Я начну с расплывчатого примера, решить который можно при помощи фильтра Калмана, но если вы хотите перейти сразу к красивым картинкам и математике, то можете пропустить этот раздел.
Что можно сделать при помощи фильтра Калмана?
Давайте рассмотрим пример: вы создали маленького робота, который может блуждать по лесу; чтобы выполнять перемещение, ему точно нужно знать, где он находится.

Наш маленький робот
Допустим, наш робот имеет состояние
Обратите внимание, что состояние — это всего лишь список чисел, задающий конфигурацию нашей системы; это может быть что угодно. В нашем примере это позиция и вектор скорости, но это могут быть и данные о количестве жидкости в цистерне, температуре двигателя автомобиля, позиции пальца пользователя на тачпаде или любое количество объектов, которое вам нужно отслеживать.
Наш робот также имеет датчик GPS, обладающий точностью порядка 10 метров, и это хорошо, но ему нужно знать своё местоположение более точно в этом диаметре 10 метров. В этом лесу много оврагов и обрывов, поэтому если робот ошибётся на несколько метров, он может упасть с обрыва. Поэтому самого по себе GPS недостаточно.

О нет!
Также мы можем узнать кое-что о том, как двигается робот: он знает команды, передаваемые двигателям колёс, и знает, что если он направляется в одну сторону и ему ничего не мешает, то в следующее мгновение он с большой вероятностью продвинется в том же направлении. Но, разумеется, он не знает ничего о своём движении: его может сдуть ветром, его колёса могут немного завязнуть или скатиться по кочкам; поэтому количество оборотов колёс может и неточно отражать перемещение робота, и это предсказание будет неидеальным.
Датчик GPS сообщает нам информацию о состоянии, но только косвенно, с долей неопределённости или неточности. Наш прогноз сообщает нам нечто о том, как движется робот, но только косвенно, с долей неопределённости или неточности.
Но если воспользоваться всей доступной нам информацией, сможем ли мы получить более точный ответ, чем каждая из приблизительных оценок по отдельности? Разумеется, ответ положительный, и вот для чего нужен фильтр Калмана.
Как вашу задачу видит фильтр Калмана
Давайте взглянем на информацию, которую пытаемся интерпретировать. Мы продолжим с простым состоянием, содержащим только позицию и скорость.
Мы не знаем истинных позиции и скорости; истинными могут быть целое множество возможных комбинаций позиции и скорости, но некоторые из них вероятнее других:

Фильтр Калмана предполагает, что обе переменные (в нашем случае это позиция и скорость) случайны и имеют гауссово распределение. Каждая переменная имеет среднее значение

На этом изображении между позицией и скоростью нет корреляции, и это значит, что состояние одной переменной ничего не скажет нам о том, каким может быть состояние второй.
Показанный ниже пример демонстрирует нечто более любопытное: позиция и скорость коррелируют. Вероятность наблюдения конкретной позиции зависит от имеющейся скорости:

Такая ситуация может возникнуть, если, допустим, мы вычисляем новую позицию на основании старой. Если скорость была высокой, мы, вероятно, продвинулись дальше, поэтому позиция будет более удалённой. Если мы движемся медленно, то продвинемся не так далеко.
Подобную связь очень важно отслеживать, потому что она даёт нам больше информации: одно измерение сообщает нам нечто о том, каким может быть второе. В этом и заключается цель фильтра Калмана: мы хотим выжать как можно больше информации из неточных измерений!
Эта корреляция задаётся ковариационной матрицей. Если вкратце, то каждый элемент матрицы

Описываем задачу с помощью матриц
Мы моделируем наше знание о состоянии как гауссово распределение, поэтому нам нужно два элемента информации во время

(Разумеется, мы используем здесь только позицию и скорость. но полезно помнить, что состояние может содержать любое количество переменных и описывать всё, что хотите).
Далее нам нужен какой-то способ, позволяющий взглянуть на текущее состояние (во время k-1) и спрогнозировать новое состояние во время k. Помните, мы не знаем, какое состояние является «реальным», но нашей функции прогнозирования это неважно. Она просто прорабатывает все состояния и возвращает нам новое распределение:

Мы можем представить этот шаг прогнозирования с помощью матрицы

Она получает каждую точку в нашем исходном возможном значении и перемещает её в новое предсказанное место, то есть в то, куда система переместилась бы, если бы исходное возможное значение было истинным.
Давайте применим этот подход. Как использовать матрицу для прогнозирования позиции и скорости в следующий момент в будущем? Мы воспользуемся очень простой кинетической формулой:

Иными словами:

Теперь у нас есть матрица проецирования, дающая следующее состояние, но мы по-прежнему не знаем, как обновить ковариационную матрицу.
И здесь нам нужна другая формула. Если мы перемножим каждую точку в распределении на матрицу
Это просто. Я просто покажу вам тождественное равенство:
То есть объединив это с предыдущим, мы получим:

Внешнее воздействие
Однако мы описали не всё. Могут присутствовать изменения, не связанные с самим состоянием — на систему может влиять внешний мир.
Например, если состояние моделирует движение поезда, машинист может изменить скорость, что приведёт к ускорению поезда. Аналогично, в нашем примере с роботом, ПО навигации может отдать команду вращать или остановить колёса. Если мы знаем эту дополнительную информацию о том, что происходит в мире, можно засунуть её в вектор под названием
Допустим, мы знаем ожидаемое ускорение

В матричном виде:

Давайте добавим ещё подробностей. Что произойдёт, если наш прогноз не является на 100% точной моделью происходящего на самом деле?
Внешняя неопределённость
Всё замечательно, если состояние развивается в соответствии с собственными свойствами. Всё по-прежнему замечательно, если состояние развивается в соответствии с внешними силами, если мы знаем, каковы эти внешние силы.
Но как насчёт сил, которых мы не знаем? Если мы следим, например, за квадрокоптером, его может унести ветром. Если мы следим за колёсным роботом, то колёса могут проскальзывать или его могут замедлять кочки на земле. Мы не можем отслеживать подобные аспекты, и если что-то из этого произойдёт, наш прогноз может оказаться ошибочным, потому что мы не учитываем эти дополнительные силы.
Мы можем смоделировать вызванную «миром» неопределённость (то есть то, что мы не отслеживаем), добавляя новую неопределённость после каждого шага прогнозирования:

Каждое состояние в нашем исходном возможном значении может переместиться в диапазон состояний. Так как нам очень нравятся гауссовы распределения, мы можем сказать, что каждая точка в

Так мы создаём новое гауссово распределение с другой ковариацией (но с тем же средним значением):

Расширенную ковариацию мы получим, просто прибавив

Иными словами, новое лучшее возможное значение является прогнозом, сделанным из предыдущего лучшего возможного значения плюс поправка на известные внешние воздействия.
А новая неопределённость прогнозируется из старой неопределённости с дополнительной неопределённостью, вызванной окружением.
Отлично, всё довольно просто. У нас есть нечёткое возможное значение того, где может находиться наша система, заданное
Уточняем возможное значение на основе измерений
Допустим, у нас есть множество датчиков, дающих нам информацию о состоянии системы. Пока нам неважно, что они измеряют; допустим, один считывает позицию, а другой скорость. Каждый датчик сообщает нам нечто косвенное о состоянии, иными словами, датчики оказывают влияние на состояние и возвращают множество показаний.

Стоит заметить, что единицы измерения и масштаб показаний может отличаться от единиц измерения и масштаба состояния, которое мы отслеживаем. Возможно, вы уже догадались, к чему всё идёт: мы смоделируем датчики при помощи матрицы

Мы можем вычислить распределение показаний датчиков, которые ожидаем увидеть, привычным образом:

Фильтры Калмана отлично справляются с шумом датчиков. Иными словами, наши датчики хотя бы немного, но ненадёжны, и каждое состояние в исходном возможном значении может привести к диапазону показаний датчиков.

Из каждого наблюдаемого показания мы можем предположить, что наша система находилась в определённом состоянии. Но поскольку присутствует неопределённость, некоторые состояния с большей вероятностью, чем другие могут создавать наблюдаемое показание:

Мы обозначим ковариацию этой неопределённости (например, шум датчиков) как
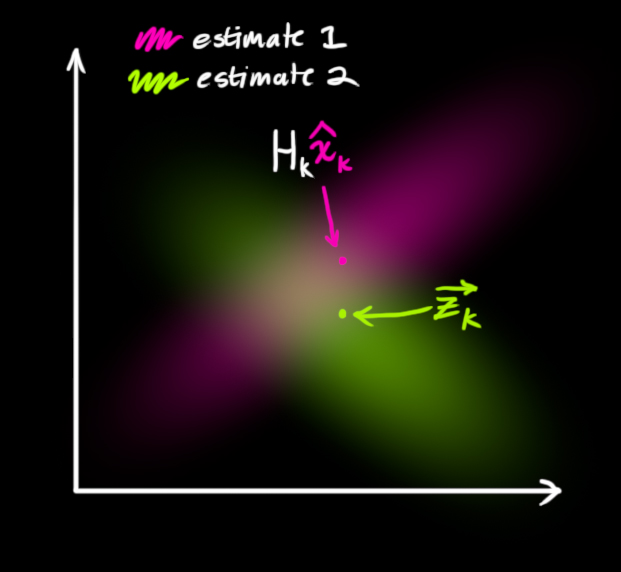
То есть теперь у нас есть два гауссовых распределения: одно окружает среднее значение преобразованного прогноза, а второе окружает действительные показания датчика.
Мы должны попытаться пересмотреть наше предположение о показателях, которые мы увидим, на основании прогнозируемого состояния (розовое) с другим предположением, основанным на показаниях датчиков (зелёным), которые мы наблюдаем.
Каким же будет наиболее вероятное новое состояние? Для каждого возможного показания
Если у нас есть две вероятности и мы хотим узнать вероятность того, что обе они истинны, нужно просто перемножить их. То есть мы берём два гауссова распределения и перемножаем их:

То, что у нас осталось — это наложение — область, где оба распределения ярки/вероятны. И это гораздо точнее, чем оба наших предыдущих возможных значения. Среднее значение распределения является конфигурацией, для которой оба возможных значения наиболее вероятны, и, следовательно, наилучшим предположением об истинной конфигурации с учётом всей имеющейся у нас информации.
Хм… Похоже на ещё одно гауссово распределение.

Оказывается, если перемножить два гауссовых распределения с собственными средними значениями и ковариационными матрицами, мы получим новое гауссово распределение с собственным средним значением и ковариационной матрицей! Возможно, вы уже видите, к чему всё идёт: должна существовать формула для получения этих новых параметров из старых!
Объединяем гауссианы
Давайте найдём эту формулу. Проще всего сначала взглянуть на это в одном измерении. Одномерная кривая Гаусса с дисперсией

Мы хотим знать, что получается при перемножении двух гауссовых кривых. Показанная ниже синяя кривая представляет собой (ненормализованное) пересечение двух гауссовых генеральных совокупностей:


Можно подставить в это уравнение предыдущее и выполнить алгебраические операции (аккуратно нормализуя, чтобы суммарная вероятность равнялась 1), чтобы получить:

Мы можем упростить уравнение, вынеся за скобки небольшую часть и обозначив её

Обратите внимание, что мы можем взять предыдущее возможное значение и прибавить нечто, чтобы создать новое возможное значение. И посмотрите, насколько проста эта формула!
Но как насчёт матричного вида? Давайте просто перепишем два предыдущих уравнения в матричном виде. Если

Всё просто! И мы уже почти закончили!
Объединяем всё вместе
У нас есть два распределения: спрогнозированное измерение с

И из этого коэффициент усиления Калмана равен:

Мы можем убрать

…и мы получаем полные уравнения для шага обновления.
Вот и всё!

Схема потоков информации фильтра Калмана
Подведём итог
Из всей представленной выше математики вам достаточно реализовать уравнения
Это позволит вам точно смоделировать любую линейную систему. Для нелинейных систем используется расширенный фильтр Калмана, который просто линеаризует прогнозы и измерения их средних значений. (Возможно, в будущем я напишу вторую статью о расширенном фильтре Калмана).
Стоит упомянуть и отдать должное этому отличному документу, в котором применяется похожее решение с использованием наложения гауссиан. Если вам любопытно, вы можете найти там более подробный вывод формул.
Комментарии (20)

mctMaks
21.12.2021 14:56такой вопрос, ведь для линейного процеса этот фильтр подходит лучше? Хочется понять, как применить фильтр, например, для синхронизации часов.
Видел в одной из реализаций PTP (Precesion Time Protocol) фильтр Калмана. На диаграмме он был показан в виде квадратика (всеми любимая абстракция черного ящика), но без объяснения как он работает в этой задаче. Время меняется линейно, ошибка при синхронизации возникает только из-за неравномерности хождения времен. Получается что уравнение одно?

тогда как для него правильно составить ковариционную матрицу?

DirectX
21.12.2021 20:29+3Кстати, очень крутой видеокурс по теме статьи: https://www.youtube.com/watch?v=CaCcOwJPytQ&list=PLX2gX-ftPVXU3oUFNATxGXY90AULiqnWT

DonStron
22.12.2021 14:27удивительное хабрасообщество... кто и за что поставил минус этому комментарию?
Таким комментариям не место на ресурсе? Это протест тому, что все лучшие курсы почему-то на английском?

esaulenka
23.12.2021 00:55-1Возможно, тот, кто просмотрел первый ролик, и за 5 минут узнал только то, что фильтр Калмана - очень крутая штука, которая по неточным измерениям может давать хороший результат. Остальное смотрите в продолжении (ещё 54 серии в сезоне "фильтр Калмана").
Но минус не мой,@DirectXто в чём виноват? Господина van Biezen, собственно, тоже обвинять как-то странно.

mayorovp
23.12.2021 16:17Минус — знак несогласия с комментарием. Возможно, кто-то не согласен с тем, что видеокурс действительно крутой. Это нормально.
DonStron
23.12.2021 18:43-1Нет, это не нормально. Потому как в комментарии со ссылкой на курс нет ничего плохого или душного! Это даже не очередной видос с однотипным введением в питон или приевшееся всем "как войти в айти".
Человек поделился ссылкой именно по теме статьи. На тот момент комментарий висел с минусом (была единственная оценка), как будто это что-то плохое! Это несправедливо.
Если какой-то гуру посчитал, что курс по ссылке недостаточно крутой, значит ему есть с чем сравнивать, значит у него есть ссылка на действительно крутой курс и это было бы полезно для сообщества, верно?
Ну так где-же тогда ссылка или какое-то объяснение почему курс недостаточно крутой? Получается этот "несогласный" сделал бяку, он поставил минус и отбивает охоту делиться чем-то полезным! При этом сам этот душитель не дал ничего взамен полезного. Фактически без аргументов просто назвал чужое мнение и полезную ссылку "говном" с высоты своего положения (ведь у него есть возможность ставить минусы). Это вы называете нормальным? Разве это принесёт пользу хоть кому-то?Комментарий заплюсовали уже после моего обращения внимания на несправедливость. Я сам на тот момент голосовать не мог, у меня не было заряда.
Минус — знак несогласия с комментарием. Возможно, кто-то не согласен с тем, что видеокурс действительно крутой. Это нормально.
Я просто оставлю тут цитаты из хабраэтикета размещенные на сайте. Они тут размещены не просто так, а чтобы те, кто имеет право минусовать - не душили хабрасообщество:
Не злоупотребляйте своей возможностью голосования. Необходимо понимать, что минус сильно отличается от плюса — минус угнетает человека, а не развивает его. Ставьте плюсы, когда вам что-то нравится, но подумайте, прежде чем ставить минус, если что-то не понравилось.
Минус — это не аргумент, и, тем более, не контраргумент.
Уважайте мнение других. Оно не обязано совпадать с вашим.
Как видите, я аргументировал своё мнение и позицию, я попытался восстановить справедливость и, похоже, привлечь внимание получилось, изначальному комментарию набросали немного плюсов.
mayorovp
24.12.2021 01:34+1Это несправедливо.
Согласие или несогласие с чужим мнением не имеет никакого отношения к справедливости. Справедливость не означает что все обязаны соглашаться с вами.
Фактически без аргументов просто назвал чужое мнение и полезную ссылку "говном"
Это всего лишь ваша интерпретация. Минус не означает "говно".
Уважайте мнение других. Оно не обязано совпадать с вашим.
Рекомендую прочитать этот пункт внимательно.
DonStron
24.12.2021 09:47-1Согласие или несогласие с чужим мнением не имеет никакого отношения к справедливости
Ставя минус - человек пытается уничтожить комментарий. Ведь много минусов обесцвечивают его, делают серым, невидимым. Так что минус - это попытка уничтожить это мнение. Ставящий минус как бы говорит, что этому комментарию не место на ресурсе.
Но конкретно тот комментарий не нёс ничего плохого! Вот почему минусование подобных комментариев - это несправедливо.Уважайте мнение других. Оно не обязано совпадать с вашим.
В том то и дело, что в случае с комментарием - есть 3 варианта: ничего не делать, поставить минус, поставить плюс.
Получается, что если мнение не совпадает, то можно пройти мимо, это как раз будет уважением к чужому мнению. Но человек не прошел мимо, он специально попытался обесценить комментарий, уничтожить, принизить.
Тут ничего уважительного. Учитывая, что минусующий не дал никаких ургументов и не предложил ничего лучше.Кто-то из добрых побуждений решил поделиться немножко знанием и дополнительной ссылкой. А кто-то решил обесценить это рвение, сделать его коммент сереньким с красной тряпкой минуса. Тем самым отбивая охоту чем-то делиться. Это токсичное душное поведение ухудшающее ресурс.
Минус — знак несогласия с комментарием
Минусы не для этого! Минусы - это если статье или комменту не место на ресурсе, например человек дичь говорит про плоскую землю. Т.е. для саморегуляции сообщества не привлекая НЛО. Тот коммент не был дичью. Выражая несогласие, аргументом было бы дать другую, более полезную ссылку. Но там не было аргумента.

Refridgerator
24.12.2021 10:46Я тоже не люблю комментарии из ссылок на видеокурсы. Если человек посмотрел такой курс, но не смог написать по теме статьи ничего вменяемого — то грош цена такому курсу. И это не считая того, что затрат времени на просмотр подобные курсы требуют в разы больше, чем прочтение комментария или даже статьи целиком. Вот вы сами посмотрели тот курс? Что в нём есть того, что нет в этой статье?

netricks
22.12.2021 11:02+1В пункте "Объединяем вместе" в первой формуле что-то не так. Кажется случился ctrl-v ctrl-v вместо простого ctrl-v.

esaulenka
23.12.2021 01:02+1Хорошая статья, спасибо. Разве что в примерах должн быть не робот, который катается по лесу, а тележка, которая ездит по одномерным рельсам.
Потому что в первом случае задача становится куда интереснее - из координат X/Y и скорости/курса с GPS и датчиков скорости с колёс (фактически, линейная скорость движения + угловая скорость поворота) надо получить координаты/скорость/курс. А оно внезапно многомерное и нелинейное. Такую задачку я решить не могу. Надо всё-таки плотно сесть, попробовать...
Refridgerator
23.12.2021 05:47+1В первом случае достаточно действительные числа заменить на комплексные. Комплексное положение будет включать в себя координаты X и Y, а комплексная скорость линейную скорость и курс.
PsyHaSTe
Помню фильтры Каллмана из универского курса. В итоге сдал его, но всегда оставалось ощущение, что оно работает на неведомой магии — ну как, КАК не зная истории можно грамотно предсказать поведение, скажем, синусоиды? Находясь в точке 0.5 мы можем пойти как вниз, так и вверх, смотря передний это фронт или задний.
Спасибо за статью, ощущение что стало понятнее как оно работает.
mayorovp
В такой постановке — никак. Но если мы работаем в фазовом пространстве, и учитываем не только значение синусоиды, но и первую производную...
PsyHaSTe
Да, теперь это стало понятнее. Стоило закочнить универ и поработать много лет заработчиком, а потом наткнуться на пару подобных статей.
Всё же при всех плюсах универа последние годы были немного поспешными — материалов давали много и очень сжато, причем практические семинары были по всяким бесполезным предметам а-ля "напишите экспертную систему на прологе". А я бы лучше вот фильтр использовал для какой-нибудь симуляции гонок по неровной дороге
lea
Синус по двум предыдущим точкам легко предсказывается.
Берем синус, два раза его дифференцируем - получаем минус синус. Ага, значит у нас есть диффур d2f(x)/dx2 = -f(x). Производную можно приблизить численно: d2f(x)/dx2 ~ (f(x + h) - 2 * f(x) + f(x - h)) / (h ^ 2), где h - некое малое число. Подставляем (f(x + h) - 2 * f(x) + f(x - h)) / (h ^ 2) = -f(x), преобразуем, получаем выражение для построения прогноза f(x + h) по точкам f(x) и f(x - h). Применяя полученное выражение несколько раз - можем прогнозировать на разный горизонт.
PsyHaSTe
По предыдущим точкам — можно. Но у нас же разговор про то что у нас нет никакой памяти
Refridgerator
В фильтре Калмана тоже есть память — это же рекурсивный фильтр, ему нужно хранить текущее состояние.