
Привет! Меня зовут Максим Гореликов, я Backend Tech Lead в M2. Несколько вещей, которые надо знать об этой статье, прежде чем углубляться в нее:
эта статья — расшифровка моего доклада на конференции Yandex Scale 2021 с некоторыми доработками;
данные собирали с разных участников переезда и набрали много интересного, но доклад был в слоте про Yandex Data Platform, поэтому оставили кейсы только на эту тему;
материал скорее обзорный, чтобы понимать, с чем можно столкнуться. Каких-то суровых технических подробностей немного, потому что в каждом переезде они будут свои.
События, описанные в статье, происходили в 2020 году, сейчас входим в топ-5 клиентов по объему потребляемых сервисов Yandex.Cloud. Когда переезжали, ещё не все процессы в Yandex.Cloud были хорошо налажены, поэтому расскажу о самых ярких воспоминаниях — проблемах, с которыми столкнулись. Хороших моментов тоже хватало, но проблемы всегда интереснее обсудить.

Почему мы решили переехать в облако
Мы достаточно молодая компания, и команда разработки у нас растет быстрее команды поддержки. Это вполне стандартный подход, потому что бизнес в первую очередь стремится вкладываться в развитие. Поэтому первая причина переезда — хотелось разгрузить нашу команду поддержки.

Вторая — возможность быстрых экспериментов с новой инфраструктурой и последующее ее масштабирование. PaaS-решения позволяют быстро развернуть хранилище или любую другую инфраструктуру и понять, подходит оно для задач компании или нет. Это важно, потому что хочется расти и при этом не страдать от ограничений. Часто они связаны с тем, что никто в компании ещё не разворачивал тот или иной компонент, который, может, нам оправданно нужен для нового проекта.
Третья причина — сертификация по персональным данным. Yandex Data Platform предоставляет готовые решения, где большинство проблем уже решены. Остается позаботиться о каких-то мелочах, а не проходить все с нуля.
Как не сломать всё и сразу
Чтобы собрать все проблемы и не получить массу недовольных пользователей на production, решили опробовать всё на dev-окружении.
Если вдуматься, разработчики — основные потребители инфраструктуры. С большой вероятностью в процессе работы они соберут все проблемы, прочувствуют на себе все баги и не будут терпеть, а расскажут о них прямо и не стесняясь в выражениях.
Кластеры для хранилищ
До этого наша система выглядела так: под каждый сервис развернута виртуальная машина и на ней же — хранилище для этого сервиса. Топорно, но просто и работает — то, что нужно на старте компании. Но на момент переезда в Yandex.Cloud и развертывания там своей dev-среды у нас уже было порядка 150 сервисов и около 5 сред, от dev до prod. Получается 750 кластеров одного хранилища — если пересчитать по ценнику на ресурсы, выходит достаточно дорого.
Поэтому мы немного оптимизировали кластеры. Для dev- и test-сред выбрали единый подход: один кластер для бэкенда, один — для фронтенда и один — для иных нужд. Для prod, stage и perf всё немного сложнее: выделили по кластеру на каждый бизнес-блок, кластер для общих сервисов и кластер для каждого критичного сервиса, чтобы на них ничего не влияло. Получили первый плюс — некий пинок, мотивирующий задуматься о ресурсах и оптимизировать их.
Воссоздали нужный набор кластеров и получили следующий набор проблем, связанный уже с работой приложений.

Несовместимость библиотек и версий
Для приложений мы используем библиотеку Mongock, которая отвечает за накатывание изменений схем данных, миграцию данных, создание индексов и т. д. После того как мы переформировали кластеры, получилось, что в один кластер входит несколько приложений и у каждого приложения своя база данных. Естественно, в этот момент права приложений мы сильно порезали оставив только readWrite на конкретную БД.
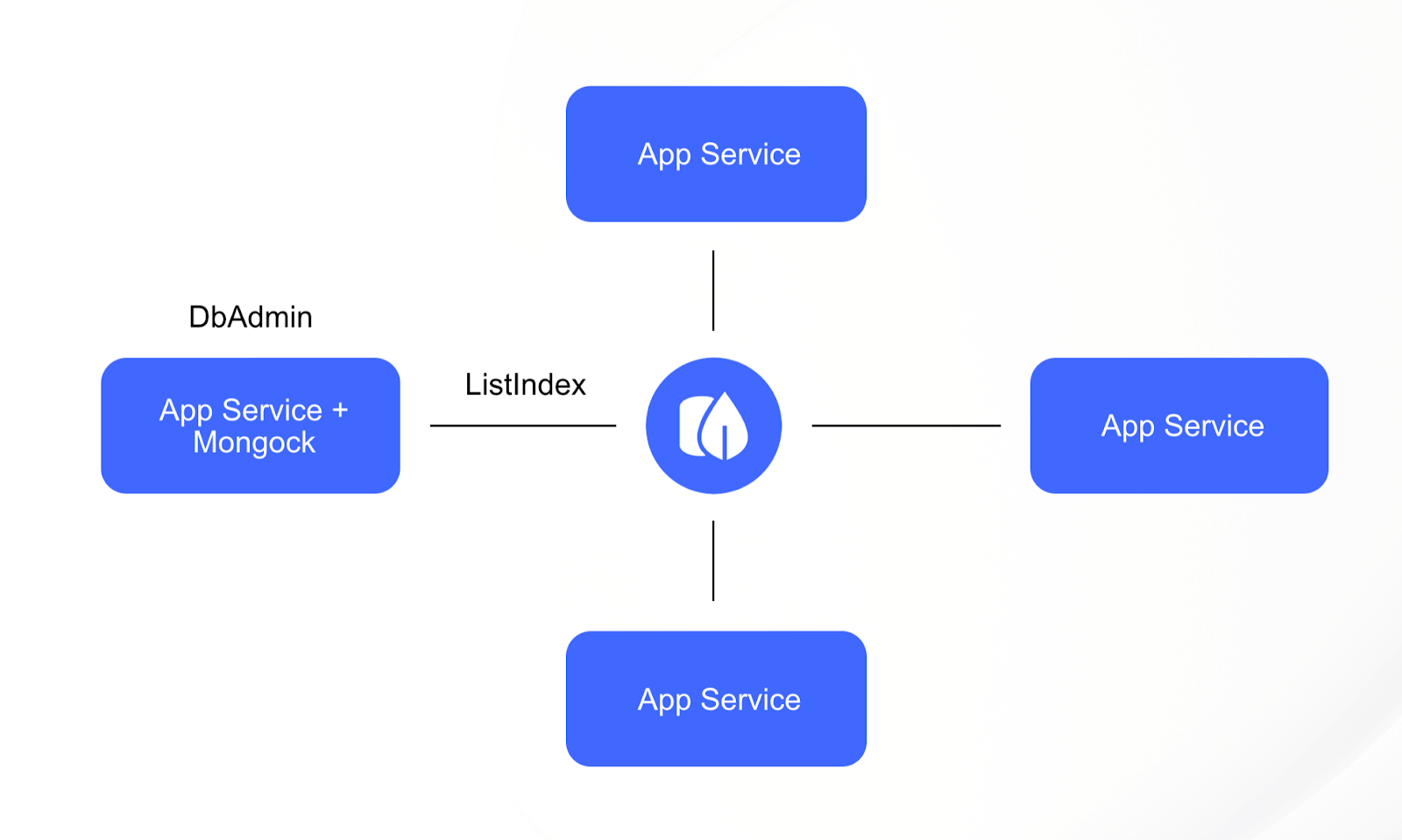
«Кажется, дело в правах», — подумали мы, когда посмотрели на новую схему и получили в логах ошибки вида not authorized to execute command. «Надо бы обновить Mongock».
«Не надо меня обновлять, не нужны мне эти права, — подумал Mongock, — лучше сходи разберись, зачем вы используете заброшенный Mongobee».
Оказалось, что пара сервисов у нас использовала Mongobee с давних времён. Ещё когда команд и сервисов было не так много и всё это вполне себе жило по принципам «работает — не трогай». При миграции в облако все сервисы естественным путем переехали на единую версию MongoDB и стрельнули конструкции, которые были отмечены как deprecated ещё в MongoDB 4.2.
Можно было обновить Mongobee, но, понятное дело, всем выгоднее переехать на общее решение в виде Mongock и не решать параллельно одинаковые проблемы с двумя разными библиотеками.
В этой ситуации только наша вина, но мораль такова: как и в обычном переезде, «по углам и темным местам» можно найти то, что в обычных ситуациях не всегда полезешь искать и исправлять. Да, пока выглядит так, что мы просто исправляли свои ошибки в процессе переезда, но это всегда полезно, и дальше будут ещё сценарии.
Слегка похожа на предыдущую, но касается сервисов на Scala и связана не с нашими рассинхронизациями или ошибками, а с особенностями облака. Для работы с Redis в этих сервисах использовался redis4cats-клиент. При поднятии приложений начали получать Segmentation fault (неприятную ошибку) и много времени в дебаге.
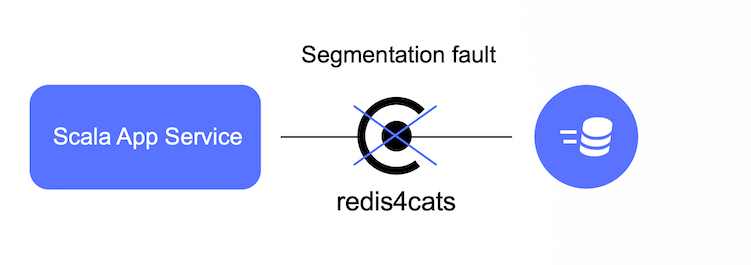
Решилась проблема просто — пошли поискать какие-то зацепки в документации Yandex.Cloud и нашли там список рекомендованных клиентов для Redis. Среди них был Jedis. Он, конечно, на Java, но это всё JVM-языки, и Jedis нам вполне подошёл.
Вывод (очевидный, когда уже найдёшь решение): на всякий случай перечитайте документацию перед переездом — можете зацепиться за что-то нужное.

После того как удалось решить проблему с совместимостью библиотек и мы наконец смогли запустить все приложения, начали отлавливать проблемы в логах.
S3 compatible storage != S3 compatible storage
Представьте S3 Compatible Storage как иерархию кластера, бакета, директории и файлов. Надеюсь, у вас получилось что-то похожее на картинку ниже. Сейчас, глядя на нее, рассмотрим проблемы, с которыми мы сталкивались.

Главная пара особенностей, которую стоит отметить, чтобы понять проблематику:
В старом провайдере в одном бакете можно было создать ограниченное количество файлов, поэтому каждый наш сервис пытался работать с несколькими бакетами. В Yandex.Cloud таких ограничений нет.
В старом провайдере у нас был доступ к нескольким кластерам S3, в Yandex.Cloud вы можете получить доступ только к одному кластеру и будете делить его с другими клиентами Yandex.Cloud.
Проблема на бэкенде
На момент нашего переезда при выдаче прав на listBuckets, приложение, которое его использует, внезапно получало весь список бакетов, доступных нашей компании. Из-за этого всплывали некоторые артефакты. Как веселый пример: файлы в бакетах начали хаотично шифроваться одним из приложений.
Логичным решением проблемы было перейти на подход bucket per service, так ограничений старого провайдера уже не было. Пришлось немного поправить код части приложений, но, с другой стороны, упростили свои процессы работы с S3.
Бэкенд пофиксили — сломался фронтенд
Наши проблемы были связаны с тем, что в Yandex.Cloud кластер Object Storage — один на всех. В рамках любого S3 Object Storage имя бакета уникально, поэтому возникают большие риски, связанные с тем, что при переезде нужное имя бакета будет уже занято кем-то другим.
Так и вышло. К моменту нашего переезда бакет с именем assets, откуда наши фронтовые приложения забирали множество ресурсов (картинки, CSS и т. д.), был уже занят. Ведь если заглянуть в network в браузере, то на большом количестве сайтов вы найдете использование assets в пути ресурсов.
Решилась проблема просто: поверх Object Storage у нас работал CDN, в рамках которого можно было настроить rewrite адресов.
Ещё один промежуточный вывод: будьте готовы к тому, что при переезде вам потребуется не только адаптироваться к изменениям самой инфраструктуры, но и поправить свои приложения, иногда обновить или заменить библиотеки. Надо просто учитывать, что какие-то трудозатраты в этом месте понадобятся.
Переезд данных
Как минимум, для переезда клиентских сервисов и данных требовалось переместить MongoDB, PostgreSQL и Apache Kafka. Во время нашего переезда уже был Yandex Data Transfer, но работал он в preview-режиме и поддерживал только миграцию PostgreSQL, чего нам было недостаточно. Поэтому мы перевозили свои данные стандартными инструментами самих БД, поверх которых написали набор скриптов.
Насколько мне известно, сейчас Yandex Data Transfer вышел из preview и у него появилась дополнительная поддержка MySQL и MongoDB. Кроме того, у него есть режим «Копировать и реплицировать», при котором сначала переливаются старые данные, а потом включается постоянная репликация. Это позволяет переключать ваши приложения со старого кластера на новый практически без даунтайма.
В случае с Apache Kafka все было сложнее, потому что Yandex Data Transfer ее не поддерживал. Сейчас в preview-режиме есть поддержка Kafka как источника при миграции, но это может помочь скорее при миграции БД, но не одного кластера Kafka в другой . Кроме того, было нам нужно было перенести не только данные в топиках, но и offset. Мы не хотели, чтобы при потере offset у нас перечитались все данные из топиков (идемпотентность — наше все, но нагрузку при перечитывании никто не отменял). Для миграции использовали Mirror Maker 2.0 — удобная штука и рекомендован официальным гайдом Yandex.Cloud. К моменту миграции в нём уже был KIP на миграцию offset и его даже уже успели вмерджить в мастер, но релиз вышел уже после нашего переезда. Поэтому то, что нам было нужно «из коробки», мы не получили.
В итоге одной из самых сложных для нас была миграция именно Kafka. Решения получились достаточно топорные, но рабочие. Мы переключили настройки consumer в наших приложениях на чтение с offset=latest в момент их инициализации на новом кластере, чтобы не было перечитывания. При этом пришлось остановить всех producer до тех пор, пока consumer не вычитали все сообщения, и только потом переключили приложения на новый кластер. Естественно, это привело к увеличенному времени недоступности в процессе переезда.
Сейчас с этим проще: mirror maker 2.0 поддерживает миграцию offset «из коробки».
Жизнь в Yandex.Cloud и использование PaaS
Переезд закончился, но работа продолжилась. В результате переезда в облако мы получили определенные преимущества.
Разработчик может быстро попробовать что-то новое
Раньше мы боялись пробовать ClickHouse, потому что он несколько сложнее в части поддержки, чем другая наша инфраструктура. Ведь мы ещё старались экономить усилия наших operations-инженеров — они делали ещё много чего необходимого. Сейчас мы просто развернули его PaaS, испытали и начали использовать. Да, усилия на поддержку есть, но сильно меньше, чем для on-premise-решений.

Похожая ситуация с PostgreSQL. Он был у нас и до этого, но после переезда мы решили развернуть связку PostgreSQL + 1С. Те, кто знаком с этой связкой, понимают, что надо вложиться в настройку параметров дисковой подсистемы, настройку оптимизаторов, установить дополнительные модули и ещё покопаться в оптимизациях. Но если вы живёте в Yandex.Cloud, то имеете доступ к подготовленным образам определенных версий.
В нашем случае даже удалось получить сборку с нужной версией и переехать на неё. Это решает большинство проблем.
Хотя всё же стоит учитывать, что стандартного пресета хватит небольшому бизнесу. Если у вас большая нагрузка на 1С, потребуется дополнительный тюнинг, потому что виртуализация всё равно накладывает ощутимый отпечаток на производительность этой связки.
Живешь по принципам Infrastructure as code? Часть кода тебе уже подготовили
У Яндекса заготовлена пачка ресурсов для terraform-провайдера. Посмотреть список можно тут. Весомый плюс в том, что не надо писать базовые шаги вроде корректного рестарта кластера (когда мастер рестартует последним, чтобы не скакать по нодам) после обновления конфигов — всё это уже реализовано, бери и делай только те вещи, которые нужны конкретно тебе.
Понятное дело, что PaaS на патч и минорные версии обновляются автоматически и какие-то вложения времени потребуются, только если нужно обновиться на мажорную версию.
Когда все хорошо, где-то обязательно скрывается компромисс
Переезжая на PaaS- и SaaS-решения, вы снимаете с себя бремя поддержки, но теряете некоторые возможности кастомизации и контроль своей инфраструктуры. Как это проявляется, рассмотрим на примере с MongoDB.
В некоторых частях нашей системы используется Mongo Change Streams. Штука достаточно удобная, когда надо и данные обновить, и гарантированно откинуть об этом ивент куда-то ещё.

Вся эта связка разворачивается достаточно просто и работает. Что надо понимать про change streams:
Mongo Change Streams основан на OpLog;
OpLog работает по принципу циклического буфера, новые ивенты пишутся поверх старых.
Как все это может работать в облаке:
Если планируется хранить небольшой объем данных в кластере MongoDB, скорее всего, выберете диск поменьше (подешевле);
размер OpLog в Yandex.Cloud определяется автоматически исходя из размеров диска, и задать его отдельно нельзя.
Если добавить к этому набору вводных ещё один фактор: данные в этом кластере будут обновляться достаточно часто, то можно поймать следующую проблему. OpLog маленький, изменений много, данные не успевают вычитываться, и вы начинаете терять часть ивентов. На это мы и нарвались, и возможности настроить этот параметр через интерфейс или ещё как всё ещё нет. Но можно попробовать написать в поддержку и попросить донастроить.
Посмотрим ещё один пример про возможности конфигурации связки ClickHouse и Kafka.

Как писал выше, использовать ClickHouse мы решились только после переезда в Yandex.Cloud. Если вы сами поднимаете ClickHouse (не как PaaS), то связка настраивается достаточно просто и поддерживает работу с Protobuf «из коробки» — достаточно подложить proto-контракт в директорию ClickHouse и сделать пару настроек.
У нас в системе достаточно широко используется gRPC с proto-контрактами, поэтому и тут нам было бы удобно передавать данные в Protobuf. Проблема состоит в том, что ни в UI, ни в API в момент поднятия нами этой связки на PaaS-решениях не было возможности передать proto-контракт. Способ «написать в поддержку» будет работать и тут, но если контракт меняется достаточно часто, то способ не слишком удобный.
Хорошая новость состоит в том, что спустя достаточно небольшое количество времени после поднятия нами этой связки в Yandex.Cloud всё-таки появилась возможность передавать proto через API.
Небольшой вывод из этого блока: усилия, сэкономленные на поддержке PaaS-решений, стоят ограничений по кастомизации, но только если они не блокируют развитие вашей системы и их можно обойти, а это надо проверять на практике
Как всё это поддерживается
Чтобы картина была полной, нельзя обойтись без завершающего штриха: усилия по поддержке PaaS минимальные, но они всё равно есть.
Бэкапы
Для PaaS-решений они есть, делаются автоматически, восстановление запускается простым нажатием кнопочки (ну или пары кнопочек) в UI.
Небольшая ложка дёгтя в том, что бэкапится целиком кластер и восстановить его можно также только целиком.
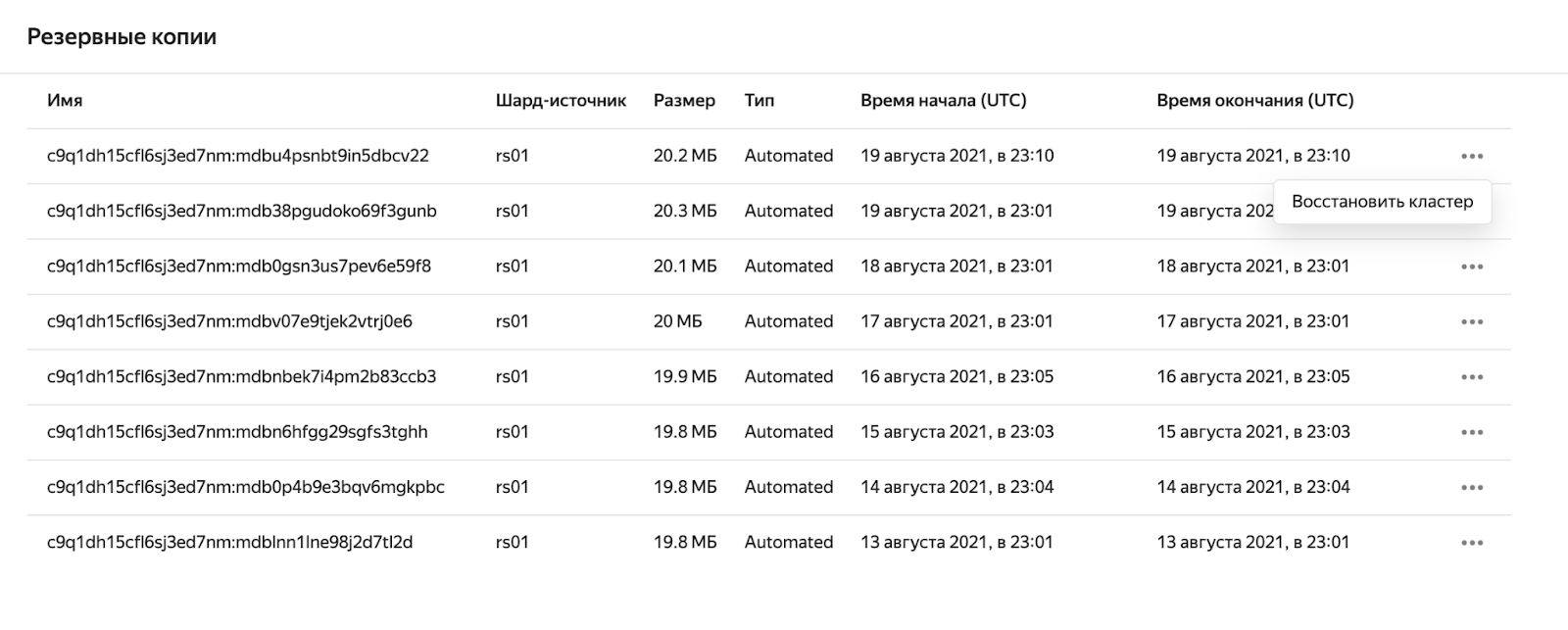
Если у вас в одном кластере несколько БД и вы не просто потеряли кластер, а, допустим, не особо удачно накатили DDL или ошибка в коде внезапно снесла часть критичных данных, то, скорее всего, вам придется поднимать ещё один кластер, восстанавливать данные на него, а потом уже переливать конкретную БД в исходный кластер — не очень удобно, но схема рабочая в случае аварий.
Если немного отойти от Yandex Data Platform и предположить, что какой-то инфраструктуры в PaaS вам не хватило и вы пошли сами разворачивать ее в Compute Cloud, то тут с бэкапами всё немного хуже.
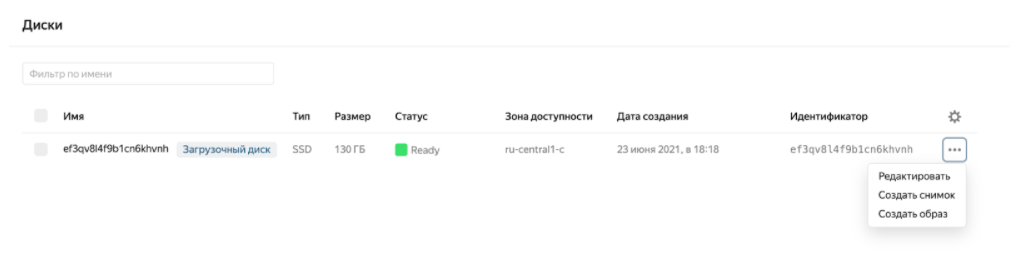
Опять же можно создавать снимки с виртуальной машины, но настроить это на периодической основе «из коробки» нельзя. Специальный человек должен периодически нажимать кнопочку — шучу. Специальный человек с прямыми руками (а у наших ребят в компании они прямые) может достаточно быстро собрать на том, что есть в облаке, систему с автоматическими бэкапами:
Message Queue и Cloud Functions вполне позволяют автоматизировать этот процесс.
Логи
В момент переезда это было неприятной проблемой: логи PaaS нельзя было посмотреть ни в UI, ни в CLI. И тут опять пригодился стандартный способ «запросить у поддержки». За прошедший год CLI был сильно доработан, и сейчас эти самые логи от того или иного PaaS можно удобно получить.
Кроме того, в preview-режиме стал доступен Yandex Cloud Logging и в перспективе можно будет попробовать переехать на него. Пока вопрос в возможности и удобстве работы с логами приложений через этот инструмент.
Мониторинг и Алерты
Для PaaS они есть.
Плюсы:
заготовленный набор дашбордов вполне себе удобный и есть возможность настройки;
есть алерты по имейлу и SMS;
метрики PaaS-решений можно выгружать по API.
Минусы:
в редких случаях экспортируемого набора метрик не хватает (добавить самим нельзя);
нет возможности отправлять алерты в мессенджеры (Telegram, Slack).
Сейчас мы выбрали гибридную схему работы: метрики инфраструктуры выгружаются по API в наш кластер Prometheus в дополнение к метрикам наших приложений, и работаем в основном с дашбордами в нашей Grafana. Алерты также настраиваются через наш alertmanager. Иногда используются дашборды в Yandex.Cloud, но в основном для общения с поддержкой и обсуждения проблем инфраструктуры. Возможно, в дальнейшем мы и перейдем на встроенный в облако мониторинг, но всё будет зависеть от того, как он будет доработан.
Вывод итоговый (возможно, очевидный, но только когда весь процесс завершен): С момента нашего переезда инструменты облака были существенно доработаны, поэтому, если вы переезжали недавно, скорее всего, не столкнулись с большинством наших проблем. Но перед переездом я всё равно рекомендую протестировать среду на своем dev-окружении, чтобы понять, какие из особенностей вы можете обойти и как.
Supervadim
Несколько я знаю, никаких папок у S3 нет. Есть только bucket и file. Имитация папок идёт с помощью имени файла
somemaxim Автор
Так и есть, там плоская структура файлов. Имитация папок только для удобства работы. На уровне базовых операций(например, "удалить") эти "папки" поддерживаются и через некоторое время в голове залипает мысль(отсюда всплыли на картинке), что они есть, так как с ними можно работать.