

Портфель решений VMWare Tanzu для работы с платформой Kubernetes упрощает задачи многооблачного развёртывания за счёт централизации управления кластерами и командами в корпоративной инфраструктуре, публичных облаках и на мобильных периферийных устройствах. Tanzu для Kubernetes — согласованный с технологиями открытого кода дистрибутив Kubernetes с последовательными принципами работы и управления для модернизации инфраструктуры и приложений.
В данной статье представлен эталонный проект развёртывания VMWare Tanzu для работы с Kubernetes при помощи компонентов Tanzu на платформе AWS.
Приведённый ниже проект основан на архитектуре и компонентах, описанных в «Обзоре эталонной архитектуры решения Tanzu».
Примечание: Эталонный проект поддерживается и проверен для заказчиков, развёртывающих Tanzu Kubernetes Grid 1.4 на платформе AWS.

Краткий обзор характеристик сети
Приведённая ниже схема даёт понимание характеристик сети, использованной для проекта. Схема предназначена для single virtual private cloud (VPC). Сеть включает в себя следующие типы подсетей:
- Одну частную подсеть для каждой зоны доступности AWS. Этим подсетям публичный IP-адрес не присваивается в автоматическом режиме. Шлюз по умолчанию — NAT.
- Одну публичную подсеть для каждой зоны доступности AWS. Этим подсетям публичный IP-адрес присваивается автоматически. Шлюз по умолчанию — интернет-шлюз, в случае если подсеть подключена к интернету. Наличие публичной подсети необязательно, если не предполагается входящий и исходящий интернет-трафик.

Рекомендации по структуре сети
В данном эталонном проекте Tanzu Kubernetes Grid используется для управления жизненным циклом нескольких кластеров рабочей нагрузки Kubernetes за счёт самозагрузки кластера управления Kubernetes с инструментом командной строки Tanzu. При настройке сети под Tanzu Kubernetes Grid следует учитывать несколько моментов:
- Используйте схему с внутренним балансировщиком нагрузки, чтобы не открывать доступ к API Kubernetes по интернету. Для использования такого балансировщика кастомизируйте шаблоны Tanzu Kubernetes Grid с помощью инструмента
kustomize. Если вы уже используете внутренний балансировщик нагрузки, запустите Tanzu Kubernetes Grid с машины, имеющей доступ к частному IP-пространству целевого VPC. К файлу, который называется~/.config/tanzu/tkg/providers/ytt/03_customizations/internal_lb.yaml, надо добавить:#@ load("@ytt:overlay", "overlay") #@ load("@ytt:data", "data") #@overlay/match by=overlay.subset({"kind":"AWSCluster"}) --- apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3 kind: AWSCluster spec: #@overlay/match missing_ok=True controlPlaneLoadBalancer: #@overlay/match missing_ok=True scheme: "internal"
Примечание: узнать больше про взаимное наложение кластеров ytt можно здесь. - Если исходящее интернет-соединение или входящее соединение с AWS вам не нужны, смело удаляйте публичную подсеть.
- Следует помнить, что 172.17.0.0/16 по умолчанию является подсетью Docker. Если вы планируете использовать её для развёртывания VPC, необходимо поменять подсеть контейнера Docker.
Хранение
Tanzu Kubernetes Grid поставляется с драйвером облачного хранения AWS, что обеспечивает хранение объёмов данных с отслеживанием состояния в кластере Tanzu Kubernetes Grid. Доступны следующие классы хранилищ:
- gp2 — SSD общего назначения (класс хранения по умолчанию)
- io1 — SSD с выделенным IOPS
- st1 — HHD с оптимизированной пропускной способностью
- sc1 — COLD HDD
Более подробно о доступных вариантах хранилищ написано здесь.
Пример класса хранилища AWS:
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp2
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
fsType: ext4
encrypted: "true"Архитектуры VPC
Производственное развёртывание Tanzu Kubernetes Grid охватывает несколько зон доступности (multi-AZ deployment).
Рекомендуется создать VPC до развёртывания Tanzu Kubernetes Grid. Кроме того, не забудьте указать публичную и частную подсеть для каждой зоны доступности, включая кластер плоскости управления, следующим ключом:
kubernetes.io/cluster/<cluster_name>. Желательно использовать такое значение публичной и частной подсетей зоны доступности, которое позволяет однозначно определить, что две подсети относятся к одной и той же зоне. Например:aws ec2 create-subnet --vpc-id $vpcId --cidr-block <ip_address> --availability-zone ${AWS_REGION}b --tag-specifications ‘ResourceType=subnet, Tags=[{Key=Name,Value=priv-b}]’ --output json > $WORKING_DIR/subnet-priv-b
aws ec2 create-subnet --vpc-id $vpcId --cidr-block <ip_address> --availability-zone ${AWS_REGION}b --tag-specifications ‘ResourceType=subnet, Tags=[{Key=Name,Value=pub-b}]’ --output json > $WORKING_DIR/subnet-pub-bИсходя из практических соображений и желаемых результатов, можете организовать свои рабочие нагрузки с использованием одной из следующих архитектур VPC.
Единый VPC с несколькими зонами доступности
В большинстве случаев достаточно одного VPC, распределённого по нескольким зонам доступности, как показано на схеме проекта. Если в рамках одного VPC нужно усилить функциональное разделение, можно использовать больше подсетей — и заодно улучшить видимость IP-адресов для корпоративных брандмауэров.

Несколько VPC с несколькими зонами доступности
Для большего функционального разделения рабочей нагрузки приложений на AWS можно развернуть кластеры Kubernetes на независимых VPC. Такое разделение предпочтительно для рабочих нагрузок, которые подчинены разным требованиям безопасности, относятся к разным бизнес-подразделениям или отличаются уровнем входящего и исходящего интернет-трафика. По умолчанию Tanzu Kubernetes Grid создаёт VPC для каждого кластера.
На схеме приводится пример архитектуры с несколькими VPC. В рассматриваемой архитектуре балансировщики нагрузки плоскости управления конфигурируются как внутренние.

Также возможен вариант, при котором используются два VPC с множественными зонами доступности: один VPC для плоскости управления, а второй — для кластеров рабочей нагрузки. Вот пример подобной архитектуры.

Доступность
Рекомендуется развёртывать кластер Tanzu Kubernetes Grid на нечётном количестве зон доступности. Это обеспечит высокую доступность компонентов, требующих консенсуса для работы при разных типах отказов.
Управляющий кластер Tanzu Kubernetes Grid выполняет проверку состояния машин на всех рабочих узлах Kubernetes. Так обеспечивается функциональность рабочей нагрузки и решаются следующие проблемы:
- Случайное удаление или повреждение рабочей ВМ
- Случайная остановка или нарушение процесса Kubelet на рабочей ВМ
Такая проверка состояния обеспечивает стабильность рабочих мощностей и возможность планирования нагрузки. Однако ВМ плоскости управления или балансировщика нагрузки не проверяются. Кроме того, по итогам проверки не воссоздаются ВМ, утраченные в результате отказа физического хоста.
Создание кластеров и управление ими
В эталонном образце Tanzu Kubernetes Grid используется для создания общедоступных кластеров Kubernetes на платформе AWS и управления ими с помощью Kubernetes Cluster API. Tanzu Kubernetes Grid оперирует через создание кластера управления, в котором размещается Cluster API. Затем Cluster API взаимодействует с поставщиком инфраструктуры для выполнения запросов кластеров рабочей нагрузки Kubernetes на протяжении их жизненного цикла.
Различные версии Tanzu включают в себя компоненты мониторинга, а также реестр контейнеров. Необходимые компоненты рекомендуется устанавливать в централизованный кластер общих устройств.
Управление жизненным циклом глобальных кластеров
Прикрепляя кластеры к инструменту Tanzu Mission Control, вы получаете возможность управления глобальным портфелем кластеров Kubernetes. Tanzu Mission Control предоставляет следующие возможности:
- Централизованное управление жизненным циклом — создание и удаление кластеров рабочей нагрузки с помощью зарегистрированного кластера управления или кластера типа Supervisor.
- Централизованное управление — доступ к перечню кластеров и данным об их состоянии и компонентах.
- Авторизация — централизованная аутентификация и авторизация с помощью федеративных учётных данных из нескольких источников (например, AD, LDAP и SAML), а также удобная в использовании система обработки политик для предоставления доступа нужным пользователям, работающим в разных командах.
- Соответствие требованиям — обеспечение применения одного и того же набора политик ко всем кластерам.
- Защита данных — управление развёртыванием, конфигурацией и графиком Velero для обеспечения резервного копирования и возможности восстановления манифестов и постоянных томов кластера.
- Инспекции — использование инструмента Sonobouy для проверки кластеров Kubernetes на соответствие требованиям функциональности.

Полный список функций Tanzu Mission Control для работы с Tanzu приведён в этой таблице.
Чтобы прикрепить кластер для управления через Tanzu Mission Control, перейдите в
Clusters > Attach Cluster на консоли Tanzu Mission Control и следуйте подсказкам.Примечание: если одному из управляемых кластеров рабочей нагрузки требуется прокси-сервер для интернет-доступа, используйте Tanzu Mission Control CLI, чтобы сгенерировать YAML для установки на нём компонентов Tanzu Mission Control.

Входящий трафик и балансировка нагрузки
Tanzu Kubernetes Grid требует балансировки нагрузки как для плоскости управления, так и для кластеров рабочей нагрузки. В обоих случаях Tanzu Kubernetes Grid для AWS использует сервис ELB (Elastic Load Balancing).
Для кластеров рабочей нагрузки в Tanzu Kubernetes Grid можно использовать пакет Ingress-контроллеров Contour, обеспечивающий маршрутизацию трафика уровня 7.
Если развёртывание включает в себя и публичные, и частные подсети, у вас по умолчанию будет балансировщик нагрузки с выходом в интернет. Если требуется частный балансировщик, можно его запросить, указав
service.beta.kubernetes.io/aws-load-balancer-internal: "true" в аннотациях сервиса. Эта настройка применяется также к входящему трафику и элементам управления Contour, независимо от того, есть ли у модуля выход в интернет.
В Tanzu Kubernetes Grid существует опция развёртывания пакета external-dns, который автоматизирует обновление записей DNS в AWS (сервис Route 53), привязанных к ресурсам управления входящим трафиком и сервисам балансировщика нагрузки. Это избавляет от кропотливого труда по управлению записями DNS для сервисов, открытых для внешнего использования.
Аутентификация с помощью Pinniped
Компоненты сервиса аутентификации и авторизации Pinniped развёртываются в кластере управления с помощью поставщика учётных данных (IDP) OIDC или LDAP, указанного в ходе развёртывания. Кластер рабочей нагрузки перенимает конфигурацию проверки подлинности пользователя от кластера управления. Когда аутентификация настроена, администратор Kubernetes может с помощью ресурсов Kubernetes RoleBinding задать управление доступом на основе ролей (RBAC). Эти ресурсы привязывают пользователя, чьи учётные данные предоставил поставщик, к назначенной роли в кластере рабочей нагрузки Kubernetes.
Pinniped состоит из нескольких компонентов:
Supervisor, Dex и Concierge.- Pinniped Supervisor — это сервер OIDC, который проверяет подлинность пользователя через внешнего поставщика учётных данных (IDP)/LDAP, а затем выдаёт собственный токен федеративной идентификации, который передается в кластеры в соответствии с данными пользователя, полученными от поставщика учётных данных.
- Pinniped Concierge — это ИПП для обмена учётными данными, который на входе получает учётные данные от какого-либо поставщика (Pinniped Supervisor, собственный IDP), проводит аутентификацию пользователя по этой единице учётных данных и возвращает другую единицу учётных данных, которую понимает кластер-хост или прокси-сервер обезличивания, действующий от лица пользователя.
- Dex в Pinniped используется как посредник для вышестоящего поставщика учётных данных LDAP. Развёртывается Dex, только если LDAP выбран как серверная часть OIDC при создании кластера управления Tanzu Kubernetes Grid.

Вот несколько примеров поставщиков учётных данных:
- Okta (OIDC) — сервис управления идентификацией корпоративного уровня, выстроенный с нуля в облаке. С помощью сервиса Okta ИТ-специалисты могут управлять доступом пользователей и устройств к любым приложениям и подключать единый вход Single Sign On (SSO), используя Okta как поставщика учётных данных.
- Active Directory — система Microsoft для управления учётными данными.
- OpenLDAP — бесплатная, основанная на открытом коде реализация протокола LDAP (Lightweight Directory Access Protocol).

Из документации Pinniped можно узнать, как интегрировать его в Tanzu Kubernetes Grid с поставщиками учётных данных OIDC и LDAP.
Мониторинг
Отслеживание метрик с помощью Tanzu Observability by Wavefront
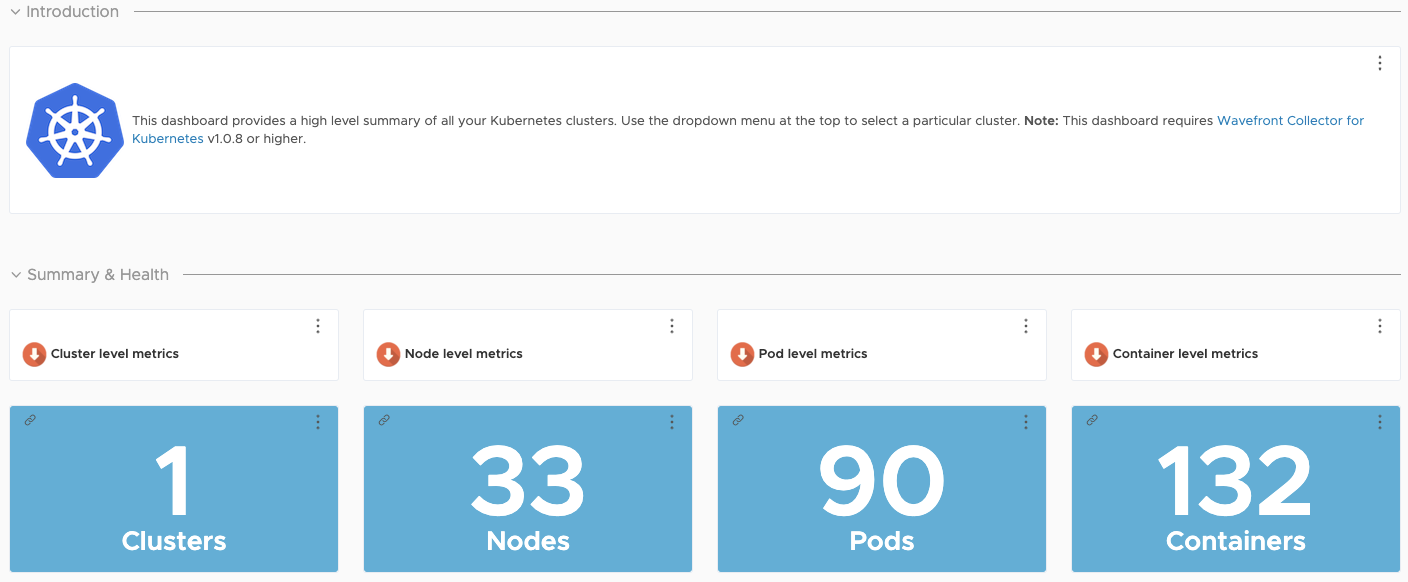
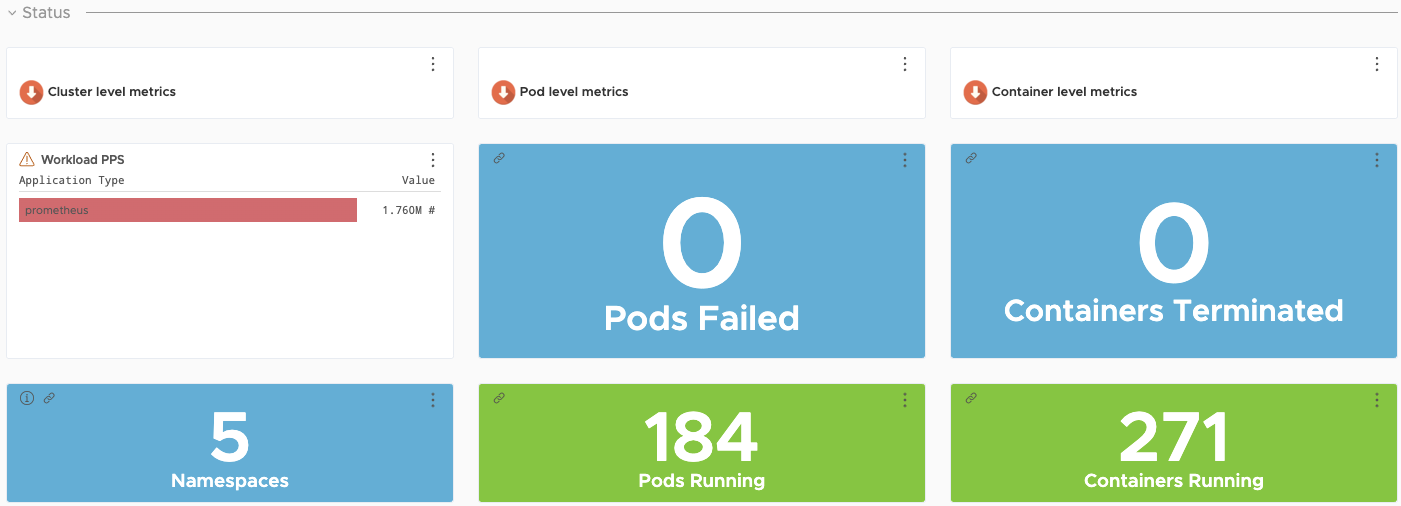
Возможности мониторинга существенно расширяются при использовании VMWare Tanzu Observability by Wavefront. Wavefront — SaaS- сервис компании VMWare, который собирает и отображает метрики и данные трассировки как от полностековой платформы, так и от приложений. Сервис предоставляет возможность создавать расширенные уведомления с продвинутой аналитикой, помогает устранять неполадки в системах и улучшает понимание результатов выполнения производственного кода.
Инструмент Wavefront используется для сбора данных с Kubernetes и приложений, запущенных на платформе.
Конфигурация Wavefront включает в себя широкий ряд возможностей. В нём доступно более 200 интеграций с готовыми к использованию панелям управления.
Для данного образца рекомендуются следующие плагины:
| Плагин | Назначение | Ключевые метрики | Примеры метрик |
|---|---|---|---|
| Интеграция Wavefront в Kubernetes | Собирайте метрики с кластеров и подов Kubernetes | Статистика контейнеров и подов Kubernetes | Загрузка центрального процессора подами |
| Wavefront by VMware для Istio | Адаптирует метрики, собранные Istio, и передает их в Wavefront | В числе метрик Istio — частота запросов, скорость трассировки, пропускная способность и т. д. | Частота запросов (кол-во транзакций в секунду) |
Отслеживание метрик с помощью инструментов Prometheus и Grafana (альтернативное решение)
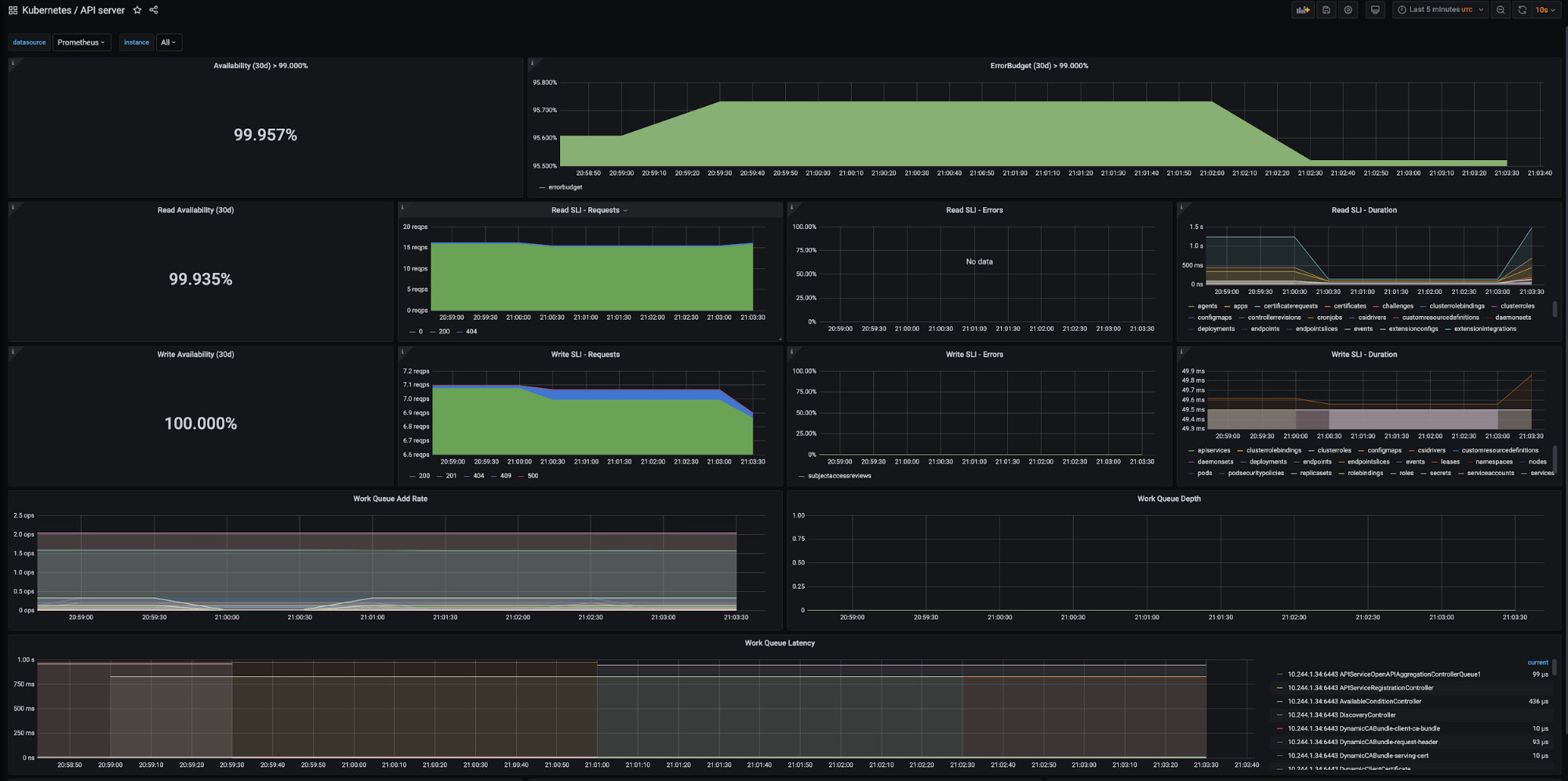
Tanzu Kubernetes Grid также поддерживает инструменты Prometheus и Grafana как альтернативные локальные решения для мониторинга кластеров Kubernetes.
Prometheus выявляет в кластере конечные устройства, с которых можно скрейпить (извлекать) метрики для различных задач мониторинга. Метрики извлекаются через HTTP-вызовы, которые Prometheus направляет конечным устройствам с заданным временным интервалом. Затем эти метрики хранятся в базе данных временных рядов. Для работы с метриками используется интерфейс языка запросов PromQL (Prometheus Query Language).
Инструмент Grafana визуализирует метрики, собранные Prometheus, и избавляет от необходимости вручную писать запросы на
PromQL. Кроме готовых к использованию шаблонов, в Grafana можно создавать кастомные диаграммы и графики.
Prometheus и Grafana представляют собой управляемые пользователем наборы инструментов, доступные к использованию с Tanzu Kubernetes Grid. Подробнее о возможностях их установки в едином блоке с Tanzu Kubernetes Grid можно узнать здесь: «Установка и конфигурация пакетов». А про управляемые пользователем пакеты — здесь: «Управляемые пользователем пакеты».
Перенаправление журналов
В состав Tanzu также входит компонент Fluent Bit, который обеспечивает интеграцию с платформами журналирования: vRealize, Log Insight Cloud, Elasticsearch и не только. Подробные сведения о конфигурации Fluent Bit для работы с вашим провайдером журналирования содержатся в документации.
Заключение
Tanzu Kubernetes Grid на AWS — это высокий потенциал производительности и удобное решение трудоёмких задач создания, тестирования и обновления облачных платформ Kubernetes в консолидированной производственной среде. Этот зарекомендовавший себя подход обеспечивает соответствие процесса установки производственным требованиям и предоставляет все необходимые сервисы приложений для объединённых и распределённых типов рабочей нагрузки в комбинированной инфраструктуре.
Предложенный вашему вниманию план удовлетворяет многие потребности, возникающие на старте проектов: быстрая адаптация возможностей продукта к полностековой инфраструктуре, включая сетевые настройки, конфигурацию брандмауэра, балансировку нагрузки, сопоставление вычислительных рабочих нагрузок и другие. И наконец, решение Wavefront обеспечивает быструю настройку системы мониторинга и удобство её использования.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
— 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC.
past
Я думал, Tanzu умеет только поверх всферы кластера крутить