
Хотел бы написать небольшой цикл статей посвященных тому, как я написал свою RTOS с какими трудностями столкнулся и зачем вообще писать свою RTOS если уже есть FreeRTOS, RTX, embOS и т.д. список достаточно большой.
Начнем с того, что по мере работы я сталкивался с тем, что часть разработчиков (и я в том числе когда-то и сам) относятся к RTOS как к некоторому черному магическому ящику, мол что-то там происходит как-то все это работает и лучше туда не лезть, а то поломается ящик и проекту «ХАНА». И все хорошо пока хорошо, но как только появляются проблемы, то начинаются бессонные ночи с отладчиком, сроки по проекту горят, а самое главное и коварное, что ошибки в RTOS отловить крайне сложно. Зачастую они имеют плавающий характер и такие эффекты как переполнение стека, инверсия приоритетов, взаимные блокировки, и все, что связанное со средствами синхронизации отладить крайне сложно.
Cо всем этим я решил разобраться в корне, и чисто в академических целях начал писать свою RTOS, чтобы так сказать прочувствовать все изнутри.
В итоге, оказалось, что написать RTOS не так уж и сложно, как кажется. И есть один существенный плюс, когда пишешь все сам и осознанно, то на поиск артефактов в виде багов уходит гораздо меньше времени (пара часов или полдня максиму). Кроме того, открываются внутренние чакры и начинаешь чувствовать, как работают другие RTOS, в чем плюсы или минусы разных RTOS, в общем, возникает чувство явного прозрения.
При написании RTOS, я осознанно отказался от поддержки проприетарных архитектур как AVR, PIC и мой выбор пал на семейство CORTEX, поскольку cortex-mX, на сегодня самая распространенная архитектура в Embedded.
И, как оказалось, cortex-mX просто создан для RTOS в нем есть все необходимое, а именно:
Два стека, один для прерываний, второй для задач
Гибкая настройка приоритетов
Программное прерывание для переключения контекста
Хорошая поддержка в GCC, кстати, писать мы будем именно на нем
Для начала хочу сказать, что это моя первая статья на хабре, я не Пушкин и даже не Лермонтов и не обладаю слоганом поэта, поэтому наверняка будут опечатки и ошибки, прошу отнестись к ним с пониманием. Любые комментарии будут приветствоваться, и я постараюсь исправить те недочеты, которые явно допущу.
Готовый код вы можете найти на github по ссылке.
Итак, поехали …
Начнем с фундаментальных определений
RTOS – операционная система реального времени, основная задача которой – предоставление интерфейсов и средств синхронизации для распараллеливания кода.
Task – задача, единица программного кода, которая позволяет писать логику в линейном (последовательном) виде. У каждой задачи есть свой стек для хранения локальных переменных. Задачи обладают приоритетом. Более приоритетная задача должна вытеснять менее приоритетную задачу (так называемая вытесняемая многозадачность).
На самом деле, на контроллере в каждый момент времени выполняется только одна задача (в нашем случае мы рассматриваем только одноядерные микроконтроллеры).
Scheduler – планировщик, программный код, который переключает задачи между собой и тем самым создает иллюзию одновременного выполнения нескольких задач.
Мьютексы, семафоры, очереди, события, критические секции – это основные объекты межпоточной синхронизации.
Задача может находиться в нескольких состояниях, представим эти состояния графом переходом:

Где:
Inited – задача создана и помещена в список созданных задач, но еще не управляется планировщиком (scheduler)
Deleting – задача закончила свою работу и нуждается в уничтожение (помещена в очередь на удаление). Задачу нельзя «убить», она должна сама завершиться
Ready – задача готова к выполнению (находится в очереди готовых) и ждет, когда ее запустит планировщик
WaitTimeout – задача заблокирована на некоторое время (помещена в очередь ожидания таймаута)
WaitObj – задача ждет объект синхронизации: событие, семафор, мьютекс, очередь (помещена в очередь объекта синхронизации)
Work – задача выполняется в текущий момент времени
Итак, проблема №1
Первая проблема, с которой я столкнулся – это как ставить задачи в очередь на ожидание чего либо?
У каждой задачи есть структура em_task_t в которой хранится все, что нужно для задачи: указатель стека, приоритет, состояние задачи и т.д. Рассмотрим пример – задачи 2 и 3 пытаются захватить мьютекс, которым владеет задача 1, в этом случае задачи 2 и 3 должны встать в очередь на ожидание мьютекса. Понятно, что в некоторую очередь должна поместиться структура em_task_t, но как?
Дело в том, что мы не можем помещать указатель на задачу в массив, поскольку мы не знаем, сколько будет создано задач (задачи могут создаваться, и удалятся в процессе работы динамически), можно конечно реализовать динамический массив и в него помещать указатель на задачу, но это не лучшее решение особенно для Embedded. К тому же задача можем покинуть очередь находясь в середине очереди, например, задача находилась в середине очереди WaitObj – ожидала событие, событие произошло – задача покинула очередь WaitObj и переместилась в очередь Ready. Кроме того, перемещение задачи из одной очереди в другую должно происходить как можно быстро (не забываем, что мы пишем RTOS и у нее должна быть низкая латентность).
Решение проблемы №1
К нам на помощь приходят двусвязные списки, именно на их основе мы и будем организовывать очередь. Давайте же вспомним что это такое. Классический двусвязный список выглядит следующим образом:
typedef struct _em_list_t
{
struct _em_list_t *next;
struct _em_list_t *prev;
} em_list_t;Данный двусвязный список позволяет добавлять и удалять элементы списка из любой позиции в списке.
Например, добавить в начало/конец списка:
//--------------------------------------------------------------
// Add to head
//--------------------------------------------------------------
void rt_em_list_add_head(em_list_t *lst, em_list_t *nlst)
{
nlst->next = lst->next;
nlst->prev = lst;
lst->next->prev = nlst;
lst->next = nlst;
}
//--------------------------------------------------------------
// Add to tail
//--------------------------------------------------------------
void rt_em_list_add_tail(em_list_t *lst, em_list_t *nlst)
{
nlst->prev = lst->prev;
nlst->next = lst;
lst->prev->next = nlst;
lst->prev = nlst;
}Удалить из текущей позиции в списке:
//--------------------------------------------------------------
// Remove entry
//--------------------------------------------------------------
void rt_em_list_remove_entry(em_list_t * lst)
{
lst->prev->next = lst->next;
lst->next->prev = lst->prev;
lst->prev = lst->next = lst;
}И т. д. не будем сейчас останавливаться на этом, скажем только, что работа со списком описана в файле em_list.c
Как же теперь связать наш список и структуру em_task_t, ведь именно ее мы и должны помещать или удалять из очереди. Для этих целей мы будем использовать способ определения адреса структуры по указателю на элемент данной структуры (прошу не пугаться, понимаю, что выглядит все как-то сложно, но на самом деле это очень распространенный метод, он используется во многих RTOS и OS в том числе и в Linux)

Объясню на примере очереди ожидающих задач task_wait_list.
Основная идея состоит в том, что сами структуры em_task_t (каждой задачи) никуда не перемещаются, но в каждой структуре em_task_t есть двусвязный список wait_list. Именно по нему задачи и встают в очередь и по нему же можно определить к какой структуре em_task_t он относится, для этого нам поможет простой универсальный макрос.
#define rt_em_get_struct_by_field(addr_field, type, field) \
((type *)((unsigned char *)(addr_field) - (unsigned char *)(&((type *)0)->field)))Теперь по указателю на wait_list можно определить указатель структуры em_task к которой он относится:
inline em_task_t* rt_em_get_task_by_wait_list(em_list_t* list)
{
return rt_em_get_struct_by_field(list, em_task_t, wait_list);
}Если работа макроса rt_em_get_struct_by_field непонятна и вызывает вопросы, рекомендую почитать про макрос container_of (он используется в Linux), если понимание всё еще не придет, напишите в комментариях и я опишу его более подробно.
В общем виде по этому принципу формируется список (очередь) ожидающих задач:
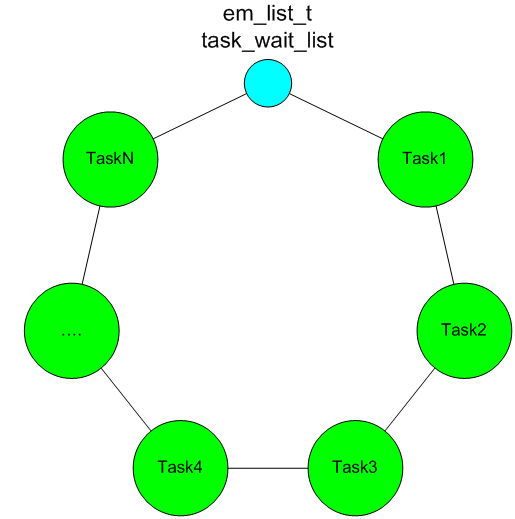
Где task_wait_list – вход в список ожидания (глобальна переменная типа em_list_t).
Понимание этого механизма крайне важно, так как в дальнейшем списки (очереди) мы будем использовать повсеместно и где только можно, задачи будут вставать в список ожидания у мьютексов, семафоров, очередей и т.д.
Еще раз сформулируем все плюсы данного подхода:
Добавление задачи в конец списка позволяет сохранять временную последовательность, поскольку задачи встают в список друг за другом
Удаление задачи из середины списка осуществляется очень быстро для этого необходимо соединить указатели next и prev соседних узлов
Сами структуры не перемещаются по памяти, но мы можем всегда по указателю на список определить адрес основной структуры (например, em_task_t) к которой он относится
Со списками вроде разобрались, но теперь еще один момент – у каждой задачи должен быть приоритет и если все готовые к выполнению задачи помещать в один глобальный список Ready, то это крайне не удобно, потому что придется каждый раз пробегаться по всему спуску Ready и искать задачу с наивысшем приоритетом, к тому же возникает вопрос как при таком подходе реализовать алгоритм Round-robin.
Round-robin – это алгоритм, по которому задачи с одинаковым приоритетом по кругу передают управление друг другу. Отсюда вытекает следующая проблема.
Проблема № 2. Как реализовать быстрый поиск наиболее приоритетной задачи из готовых к выполнению, и к тому же, чтобы между задачами равного приоритета можно было легко и быстро реализовать алгоритм Round-robin.
Решение проблемы № 2
Для решения данной проблемы необходимо иметь массив списков Ready глубина массива определяется количеством возможных приоритетов, то есть каждый элемент Ready[N] – список задач готовых к выполнению с приоритетом N, чем выше N тем приоритетнее задача (например, задача Idle имеет самый низкий приоритет 0, и находится в списке Ready[0]). Задача, когда становится готовой к выполнению, помещается в соответствие со своим приоритетом в нужных список из массива Ready, например, если задача имеет приоритет 2, то когда она готова к выполнению, то она помещается в конец списка Ready[2]. Если список Ready[N] не пуст значит выполняем задачу, которая расположена по часовой стрелки от входной метки (указатель next), если список пуст, то переходим к следующему элементу Ready[N-1] и т.д. Так реализуется алгоритм выбора наиболее приоритетной задачи из готовых к выполнению.
В этом случае алгоритм Round-robin реализуется также очень просто, достаточно на каждом временном этапе работы задач с одинаковым приоритетом перемещать входную метку по часовой стрелке (вдоль указателя next).
Для пояснения рассмотрим пример алгоритма Round-robin в картинках, допустим у нас есть список, в котором хранятся готовые к выполнению задачи с приоритетом 2. Выглядеть это будет следующим образом (желтым светом обозначена задача, которая будет выполняться):
Первый тайм-слот

Второй тайм-слот

Третий тайм-слот

И т.д. Если task_ready_list[2] пустой

Проверить список на пустоту можно очень быстро:
//--------------------------------------------------------------
// Is empty?
//--------------------------------------------------------------
int rt_em_is_list_empty(em_list_t* lst)
{
return (lst->next == lst);
}То переходим к следующему элементу task_ready_list[1] и так далее.
И вроде теперь все хорошо, но не совсем. А дело вот в чем. Допустим наша RTOS имеет 32 приоритета, самые высокоприоритетные задачи находятся в списке task_ready_list[31], а самые низко приоритетный в списке task_ready_list[0]. Так вот, чтобы найти наиболее приоритетную задачу надо пробегаться по спискам начиная с task_ready_list[31] по task_ready_list[0], в худшем случае необходимо проверить 32 списка на пустоту. Это конечно тоже решение, но не забываем, что мы боремся за низкую латентность.
Чтобы снизить время поиска используем следующий метод.
Заведем переменную:
static unsigned task_mask_pri = 0; В ней будет храниться маска приоритетов готовых к выполнению задач.
Теперь каждый раз, когда задача с приоритетов pri ,будет помещаться в список task_ready_list[pri], будем устанавливать бит в нашей маске.
task_mask_pri |= (1 << task->pri);Когда задача покидает список task_ready_list[pri] и при этом task_ready_list[pri] становится пустым – сбрасываем бит в маске.
if (rt_em_is_list_empty(&task_ready_list[task->pri]))
task_mask_pri &= ~(1 << task->pri);При таком подходе номер самого старшего бита установленного в 1 – это и есть номер самого приоритетного списка готовых к выполнению задач. Для архитектуры cortex-mX его можно определить очень и очень быстро (помните, в самом начале я говорил, что cortex-mX просто создан для RTOS).
int rt_em_find_first_bit(int value)
{
__asm volatile ( "clz %0, %0" : "=r" (value) );
return 31 - value;
}Эта функция работает следующим образом, команда clz подсчитывает количество старших 0 до первой 1 и выполняет это за 1 MIPS. Затем от 31 отнимет полученное значение, и получаем номер списка.
Чуть не забыл, в общем виде clz может вернуть значение от 0 до 32 включительно.
32 – означает, что маска равна 0. Искушенный опытом читатель, возможно, подумает, что в этом случае произойдет крах системы, посколько 31 – 32 = -1.
Однако в нашем случае этого никогда не произойдет, поскольку есть задача Idle (о ней мы поговорим в другой раз), которая ни когда не переходит в заблокированное состояние – она всегда активна, как следствие в маске всегда будет установлен младший бит.
Теперь проблема №2 решена в полном объёме.
Проблема № 3. Как правильно использовать аппаратный стек и при этом экономить на памяти
Сделаю небольшое пояснение. Архитектура cortex-mX имеет очень гибкую настройку приоритетов прерываний и допускает вложенные прерывания, при этом часть регистров общего назначения и локальные переменные вытесненного прерывания также будут сохраняться в стек.
Поясню это на упрощенном примере.
Допустим, есть 8 прерываний с разным приоритетом, и каждое прерывание потребляет 256 байт локальных переменных и к тому же у нас есть, допустим, 10 задач.
Может произойти следующее:
Прерывание 2 вытеснило прерывание 1, прерывание 3 вытеснило прерывание 2 и т.д. На картинке это будет выглядеть следующим образом:
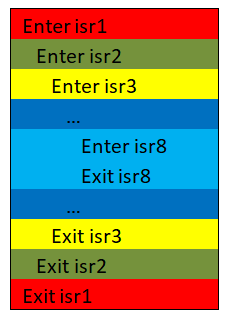
В итого получаем общую глубину стека в прерываниях 256*8 = 2 Кбайта.
Прерывания могут произойти в любой момент и если использовать в прерываниях стек текущей задачи, то необходимо этот размер учитывать в стеке каждой задачи, поскольку прерывания могут произойти при работе любой задачи. Как следствие при 10 задачах получаем 10 * 2 Кбайта = 20 Кбайт. Мягко говоря, это много и хотелось бы от этого избавиться.
Давайте же подумаем, как этого можно избежать. Первая мысль, которая наверняка Вас уже посетила – «А что если у прерываний будет свой стек?».
И действительно если у прерываний будет свой стек, а у задач свой, то для прерываний достаточно тех же 2 Кбайт вместо 20 Кбайт.
И у cortex-mX как раз есть два аппаратных стека: main и process (MSP и PSP соответственно). Но вот только дело в том, что по умолчанию при старте контроллера используется только MSP.
Так как же нам все-таки задействовать второй стек (PSP)?
Для начало хочу сказать, что всю ниже приведенную информацию вы можете найти на официальном сайте от ARM в разделе документация, там есть документация по всем ядрам от ARM https://developer.arm.com
Если найти будет сложно, то например, по ядру сortex-m3 туже самую документацию можно скачать вот по этой ссылке: https://github.com/ARM-software/CMSIS/blob/master/CMSIS/Pack/Example/Documents/dui0552a_cortex_m3_dgug.pdf
Далее на примере cortex-m3 я постараюсь кратко и понятно, насколько возможно, объяснить, как же все-таки заставить работать PSP стек в задачах, а MSP в прерываниях и как правильно инициализировать стек задач при создании, а затем их правильно переключать.
И так, в ядре есть следующие регистры:

Регистр R13 (SP) – это и есть текущий указатель стека, он может подменяться теневыми регистрами PSP и MSP.
На самом деле, когда вызывается ассемблерную инструкцию вида:
stmdb sp!, {r3, r14}То в какой именно стек (PSP или MSP) сохранятся регистры R3 и R14 определяется регистром CONTROL.
Если сказать еще проще - все команды, которые работают с регистром SP сами не знаю с каким именно регистром, отечающим за стек, (PSP или MSP) они работаю это определяет само ядро по 1-му биту в регистре CONTROL.

Как же теперь установить данный бит?
В документации сказано следующее:

Если коротко, то сказано, что для того чтобы задействовать PSP надо особым образом выйти из прерывания. В общем надо разобраться, что происходит на входе и выходе из прерываний.


Если вкратце, то говорится о следующем:
При входе в прерывание в стек SP аппаратно сохраняется часть регистров общего назначение в количестве 8 штук. Если прерывания вложенные, то аппаратное сохранение происходит 1 раз при первом прерывании. При выходе из прерываний (при условии, что это не вложенное прерывание) происходит аппаратное восстановление тех же самых регистров.
Если при выходе из прерывания в регистр LR записать 0xFFFFFFFD (вернее даже в младших 4 битах должно быть 0xD), то указатель стека SP переключится на PSP. Причем это не обходимо сделать один раз далее все будет работать автоматом.
Итак, тезисно сформулируем, что же необходимо сделать:
При создании любой задачи - подготовить стек задачи к использованию. Для этого необходимо заранее загрузить в стек задачи значение тех регистров, которые будут сохраняться и восстанавливаться аппаратно.
При самом первом запуске самой первой задачи, необходимо вызвать любое прерывание переключиться в нем на первую задачу и при выходе из прерывания обеспечить, чтобы в младших 4 битах регистра LR было записано число 0xD.
Переключение контекста также лучше делать в прерывании, поскольку аппаратное сохранение регистров будет происходить само и в нужный стек.
У cortex-mX как раз есть все необходимое, чтобы это осуществить. На самом деле пункт 2 и 3 возможно реализовать через одно прерывание, но cortex-mX настолько крут, что позволяет разделить данные процедуры на 2-а разных прерывания.
1. Инициализация стека при создании задачи
unsigned* rt_em_port_init_stack(unsigned* sp, unsigned size_sp,
void (*start_func)(void*), void* par, void (*exit_func)(void))
{
// Initialization stack
for (int i = 0; i < size_sp; i++)
*sp++ = cfgFILL_SP;
--sp;
*sp = 0x01000000; // xPSR
--sp;
*sp = (unsigned) start_func;
--sp;
*sp = (unsigned) exit_func; // LR
sp -= 5; // R12, R3, R2, R1
*sp = (unsigned) par; // R0
sp -= 8; // R11, R10, R9, R8, R7, R6, R5, R4
*sp = 0;
return sp;
}
Пояснение:
for (int i = 0; i < size_sp; i++);
*sp++ = cfgFILL_SP
Заполняем стек значением по умолчанию, далее это пригодится для диагностики глубины использования стека*sp = 0x01000000; // xPSR
Устанавливаем режим Thumb, собственно говоря cortex-mX по другому работать и не умеет*sp = (unsigned) start_func;Записываем в PC адрес входа в задачу*sp = (unsigned) exit_func; // LR
Адрес функции, которая удалит задачу при ее заверщении (при выходе из функции start_func)sp -= 5; // R12, R3, R2, R1Инициализацию регистров можно пропустить*sp = (unsigned) par; // R0Указатель, который передается в функцию start_func в виде параметраsp -= 8; // R11, R10, R9, R8, R7, R6, R5, R4Инициализацию регистров также можно пропустить*sp = 0;Метка насколько заполнен стек. Может быть любое значение не равное cfgFILL_SP. Это также нужно для диагностики заполненности стека.
2. Запуск первой задачи. Используется прерывание SVC
static void __rt_em_port_start_first_task(void)
{
__asm volatile
(
" ldr r0, =0xE000ED08 \n"
" ldr r0, [r0] \n"
" ldr r0, [r0] \n"
" msr msp, r0 \n"
" cpsie i \n"
" cpsie f \n"
" svc 0 \n"
" nop \n"
);
}Пояснение:
" ldr r0, =0xE000ED08 \n"Инициализируем стек MSP, который будет использоваться в прерываниях. Остановимся на этом подробнее. Дело в том, что когда контроллер стартует по умолчанию уже используется стек MSP, который хранится в начале таблицы прерываний. Однако пока код дойдет до этой функции стек MSP уже заполнится какими-то внутренними локальными переменными, поэтому в нем уже будет что-то лежать и это что-то нам уже больше не понадобится. В общем, мы это делаем, чтобы не терять лишнее пространство стека MSP.
" ldr r0, [r0] \n"
" ldr r0, [r0] \n"
" msr msp, r0 \n"
Более подробно делается следующее:
- берем указатель на адрес начала таблицы прерываний (0xE000ED08)
- разыменовываем его, и получаем указатель на таблицу прерываний
- в первой строчке таблицы прерываний лежит адрес начального значения MSP,
поэтому разыменовываем полученный указатель и получаем адрес начального буфера для MSP стека
- сохраняем полученный адрес буфера в MSP стек" cpsie i \n"
" cpsie f \n"
Разрешаем глобальный прерывания" svc 0 \n"Вызываем прерывание SVC
Обработчик прерывания SVC - запуск первой задачи
//--------------------------------------------------------------
// SVC ISR
//--------------------------------------------------------------
void SVC_Handler(void)
{
__asm volatile
(
" ldr r3, =ctask \n"
" ldr r1, [r3] \n"
" ldr r0, [r1] \n"
" ldmia r0!, {r4-r11} \n"
" msr psp, r0 \n"
" mov r0, #0 \n"
" msr basepri, r0 \n"
" orr r14, r14, #13 \n"
" bx r14 \n"
);
}Пояснение:
" ldr r3, =ctask \n"
" ldr r1, [r3] \n"
" ldr r0, [r1] \n"
В переменой ctask находится адрес текущей задачи (указатель на структуру em_task_t), в нашем случаем это адрес первой задачи. Первое поле в структуре em_task_t - это указатель на стек задачи. Суть этих действий такая же, как и выше: получить адрес начала буфера, который используется для стека задачи." ldmia r0!, {r4-r11} \n"Восстанавливаем регистры с r4 по r11, которые предварительно сохранили при создании задачи" mov r0, #0 \n"
" msr basepri, r0 \n"
Восстанавливаем базовый приоритет (об этом мы поговорим в следующий раз)" orr r14, r14, #13 \n"А вот здесь мы как раз добиваемся, чтобы в регистре LR(r14) младшие 4 бита были установлены в 0xD.
" bx r14 \n"
3. Переключение контекста - прерывание PendSV
//--------------------------------------------------------------
// PendSV ISR
//--------------------------------------------------------------
void PendSV_Handler(void)
{
__asm volatile
(
" mrs r0, psp \n"
" ldr r3, =ctask \n" // Get SP for current task
" ldr r2, [r3] \n" // Get stack
" stmdb r0!, {r4-r11} \n" // Save registers
" str r0, [r2] \n"
" stmdb sp!, {r3, r14} \n"
" mov r0, %0 \n" // Up base priority
" msr basepri, r0 \n"
" bl rt_em_switch_context \n" // Change task
" mov r0, #0 \n"
" msr basepri, r0 \n" // Down base priority
" ldmia sp!, {r3, r14} \n"
" ldr r1, [r3] \n" // Get SP for current task
" ldr r0, [r1] \n"
" ldmia r0!, {r4-r11} \n" // Load registers
" msr psp, r0 \n"
" bx r14 \n"
:: "i" (cfgKERNEL_MAX_PRI)
);
}Пояснение:
" mrs r0, psp \n"
Поскольку ядро уже переключилось на стек MSP, чтобы получить указатель на стек задачи (PSP) его необходимо явно загрузить в один из рабочих регистров" ldr r3, =ctask \n"Получаем адрес куда потом будем сохранять стек PSP
" ldr r2, [r3] \n"" stmdb r0!, {r4-r11} \n" // Save registersВ стек задачи сохраняем те регистры, которые не сохранены аппаратно" str r0, [r2] \n"
Сохраняем текущий указатель стека PSP в поле задачи, чтобы потом его можно восстановить при следующем запуске задачи" stmdb sp!, {r3, r14} \n"
Сохраняем скретч-регистры, потому что затем мы будем вызывать Си функцию шедулера" mov r0, %0 \n"
" msr basepri, r0 \n"
Подымаем текущей базовый приоритете до cfgKERNEL_MAX_PRI, что бы во время работы Си функции шедулера нас не могли вытеснить прерывания, которые использует функции RTOS" bl rt_em_switch_context \n"Вызываем Си функцию шедулера. Именно она найдет самую приоритетную задачу из готовых и выполнит Round-robin алгоритм для задач с одинаковым приоритетом" mov r0, #0 \n"
" msr basepri, r0 \n"
" ldmia sp!, {r3, r14} \n"
" ldr r1, [r3] \n"
" ldr r0, [r1] \n"
" ldmia r0!, {r4-r11} \n"
" msr psp, r0 \n"
" bx r14 \n"
Здесь я думаю все понятно. Восстанавливаем базовый приоритет, теперь нас могут вытеснять прерыванию, которые используют функции RTOS. Восстанавливаем регистры для новой задачи и выходим из прерывания.
Читатель, хорошо знакомый с механизмами переключения задач во FreeRTOS заметит, что это очень сильно похоже на то, как реализованно во FreeRTOS. И будет совершено прав, поскольку проанализировав несколько RTOS, мне больше всего понравилось реализация переключения контекста именно во FreeRTOS («Велосипед-то можно изобретать и свой, но что мешает позаимствовать хорошее колесо у соседа»). К тому же есть еще один плюс при добавлении нового порта, например cortex-m0 или cortex-m4f, можно всегда подсмотреть, как это сделано во FreeRTOS и при необходимости позаимствовать, естественно обдуманно и если их решение понравится.
А вот и сама функция, которая ищет и переключает задачи согласно приоритетам, а также выполняет Round-robin алгоритм, и работает она ОЧЕНЬ быстро.
//-------------------------------------------------------------
// Switch Context
//-------------------------------------------------------------
void rt_em_switch_context(void)
{
unsigned task_pri_redy;
#if cfgTEST_SP_SWITCH_TASK
extern void rt_em_port_test_sp_switch_task(void);
rt_em_port_test_sp_switch_task();
#endif /* cfgTEST_SP_SWITCH_TASK */
task_pri_redy = rt_em_find_first_bit(task_mask_pri);
ctask = rt_em_get_task_by_task_list(task_ready_list[task_pri_redy].next);
rt_em_list_jump_head(&task_ready_list[task_pri_redy]);
}Пояснение:
task_pri_redy = rt_em_find_first_bit(task_mask_pri);находим номер наиболее приоритетного списка, готовых к выполнению задачctask = rt_em_get_task_by_task_list(task_ready_list[task_pri_redy].next);Определяем задачу, которая будет выполняться по часовой стрелке от входной метки (по указателю next)rt_em_list_jump_head(&task_ready_list[task_pri_redy]);смещаем метку по часовой стрелке (по указателю next), для реализации алгоритма Round-robin.
Следующие вопросы, которые я изначально хотел обсудить:
Правильная настройка прерываний для RTOS, и работа вложенных прерываний, которые могут вытеснять любой код RTOS, включая функции планировщика
Особенности использования сопроцессора в RTOS (для архитектуры cortex-m4f). Нюансы при переключении контекста для cortex-m0 и cortex-m4f.
Использование средств межпоточной синхронизации: мьютексы, семафоры, очереди, события, критические секции
Однако в данную статья я решил это не включать (иначе статья увеличится до нереальных размеров). Если есть интерес к этим вопросам, напишите в комментариях, и я опишу их в отдельной большой статье. В связи, с чем предлагаю сменить вектор и поговорит о более общих вопросах.
Поэтому последняя проблема, которую предлагаю обсудить посвящена динамической памяти в Embedded RTOS.
Проблема №4. Как правильно использования динамической памяти в RTOS и нужна ли она?
Собственно говоря, почему я решил остановиться на heap, потому что наверняка многие из Вас слышали, что использование heap в Embedded системах не желательно и может привести к печальным последствиям. В тоже время в «больших системах» динамическая память используется везде где только можно и не вызывает ни какого негатива, вопрос почему?
И дело тут не в объеме оперативной памяти, потому что современный микроконтроллеры (например, STM32F7 или SAME51) позволяют подключить внешнюю SRAM и увеличить объем оперативной памяти до нескольких МБайт. Так же скажу, что мы не будем обсуждать утечку памяти, потому что утечка - это человеческий фактор и аппаратура в этом случае не причем.
А дело в том, что «большие системы» всегда строятся с использованием MMU (Memory Management Unit). MMU – блок управления памятью, который решает ряд важных вопросов, а именно: виртуализацию адресного пространства, устранение эффекта фрагментации памяти, защиту памяти от других процессов (задач) и т.д.
Не будем сейчас обсуждать, как именно работает MMU (у нас его все равно нет), скажем только следующее - в «больших системах» нет проблем с динамической памятью, поскольку там есть MMU, который позволяет сделать все «красиво».
В «маленьких системах» MMU нет, как следствие чтобы мы не придумали – «красиво» все равно не получится. Поэтому динамическую память необходимо использовать осознанно и понимать, как она работает.
И так, динамическую память в Embedded RTOS можно реализовать двумя способами:
На буферах фиксированного размера
На одном большом буфере, который динамически делится на нужные кусочки (блоки) по запросу RTOS
Способ организации динамической памяти на буферах фиксированного размера
Поясним на примере.
Заводим несколько массивом, допустим 3:unsigned char buf1[30][64];
unsigned char buf2[20][128];
unsigned char buf3[10][512];
Теперь если нам нужно выделить память объемом <= 64 байт, то мы резервируем под это ячейки из буфера buf1, если нужно выделить > 64 байт, но <= 128 – резервируем под это ячейки из буфера buf2 и т.д. Естественно есть некий менеджер, который учитывает свободные и занятые ячейки в каждом буфере.
При таком подходе в нашем примере мы можем выделить до 30 ячеек размером до 64 байт, 20 ячеек до 128 байт и 10 ячеек до 512 байт.
Плюсы данного способа (а он всего один, но очень важный):
память гарантированно, ни при каких условиях не фрагментируется
Минусы данного способа:
Память используется крайне не оптимально, если надо выделить 10 байт, то будет зарезервирована вся ячейка из buf1 (то есть 64 байта). Если buf1 заполнен, то будет зарезервирована ячейка из buf2 (то есть 128 байт) и т.д.
Несмотря на то, что в сумме под буфер мы выделили размер 64*30+ 128*20 + 512*10 = 9600 байт и если даже все ячейки будут свободны, нельзя выделить 1024 байта, потому что под этот размер изначально нет буферов. Можно конечно сделать алгоритм, который для этих целей резервировал бы несколько подряд идущих ячеек, но тогда теряется единственный плюс данного способа – мы не сможем гарантировать отсутствие фрагментации памяти при запросе свыше 512 байт.
Поиск свободного блока не детерминирован во времени. Как следствие один и тот же запрос памяти может выполняться разное время в зависимости от текущего состояния heap (Хотя дополнительными ухищрениями можно все-таки этот минус можно устранить)
В общем, этот способ хорошо работает тогда, когда мы знаем размеры и количество выделяемой памяти и можем предусмотреть под это буферы на этапе компиляции.
Способ организации динамической памяти на одном большом буфере, который динамически делится на нужные кусочки (блоки)
Допустим, есть некий буфер heap и на его основе мы ходим реализовать динамическое выделение памяти. Тогда буфер будет динамически делится на блоки, в каждом блоке есть:
размер блока
флаг занят блок или нет
указатель на следующий блок, если указатель = NULL, то это признак, что данный блок последний
Сами блоки вместе с выделенными данными лежит в том же буфере heap.
Изначально буфер heap. Будет выглядеть следующим образом:

По мере того как мы будем выделять/освобождать память он примет следующий вид:

Плюсы данного способа:
Память используется очень эффективно
Нет ограничений на длину запрашиваемой памяти, главное чтобы нашелся блок нужного размера
Минусы данного способа:
Память неизбежно фрагментируется. Частично проблему фрагментации можно решить путем слияния соседних свободных блоков в один блок большего размера. Однако гарантированно решить проблему фрагментации в корне, данный способ не позволяет
Поиск свободного блока не детерминирован по времени. Как следствие один и тот же запрос памяти может выполняться разное время в зависимости от текущего состояния heap.
При таком способе есть еще один нюанс – блоки, а вернее область памяти, которую они предоставляют пользователю, должна быть выровнена по 4 байт (а лучше по 8 байт для полной совместимости со всеми ядрами). Это связана с тем, что в cortex-mX часть команд требует, чтобы память, к которой они адресуются, была выровнена. Например, указатель стека всегда должен быть выровнен по слову (4 байта), а cortex-m0 вообще вызовет ошибку ядра, если разименовать не выровненный указатель типа int.
В общем подводя итоги можно сказать, что использование heap несет в себя ряд неопределенных моментов, которые имеют абсолютно плавающий эффект они могут проявиться сразу, либо через месяц после стабильной работы прибора или не проявиться вообще никогда. Все зависит от того какой вид в текущий момент принял heap.
В своей RTOS я заложил второй способ организации heap, поскольку он более эффективно использует память. Однако, чтобы не столкнутся с выше описанными эффектами я всегда рекомендую закладывать размер heap как минимум в два раза больше чем реально понадобится, а также не злоупотреблять выделением памяти маленкого размера, в этом случае высока вероятность, что проблем связанных с фрагментацией памяти никогда не возникнет.
Так же в своей RTOS я предусмотрел работу без heap – все можно сделать на статических переменных.
Так что использовать heap в Embedded или нет - это вопрос на который к сожалению нет однозначного ответа, разраотчик сам должен принять решение и помнить о последствиях.
Более детально работу heap можно посмотреть в файле em_heap.c
На этом все. Всем кто дочитал до конца - БОЛЬШОЕ СПАСИБО. Если есть интерес к данной теме - напишите об этом в коментариях и может быть появится "Часть 2", а за ней и "Часть 3" в которых можно обсудить более глубокии и интересные проблемы, а именно:
Правильная настройка прерываний для RTOS, и работа вложенных прерываний, которые могут вытеснять любой код RTOS, включая функции планировщика
Особенности использования сопроцессора в RTOS (для архитектуры cortex-m4f). Нюансы при переключении контекста для cortex-m0 и cortex-m4f.
Использование средств межпоточной синхронизации: мьютексы, семафоры, очереди, события, критические секции
В чем принципиальная разница между семафором и мьютексом
Что такое инверсия приоритетов и взаимная блокировка (как этого избежать)
Как правильно в RTOS использовать стандартную Си библиотеку из пакета GCC (в ней очень много потоко не безопасных функци, например, printf)
и т.д.
Вопросов можно обсудить очень много, что будет интересно, то и обсудим дальше.
Комментарии (72)

longtolik
30.12.2021 11:35Спасибо за Ваш труд. Интерес, конечно, есть (по крайней мере у многих).
Насчёт переключений задач: когда-то делал однозадачную ОС, можно было попробовать и многозадачность, но показалось неэффективно. Вместо этого, когда появился реальный проект, сделал задачи - каждую на своем ядре. Там надо было отслеживать датчики и выдавать воздействия в жестком реальном времени, на сохранение/извлечение контекста просто не было времени, это бы нарушило все временные характеристики. Правда, плата была RPi 3 A+ (или B+) с 4-мя ядрами Cortex-A53. Кстати, всё это работает и на Zero 2 W, которая вполне себе компактная.
Тут же встает вопрос, если ядер 8 штук (или 10), то можно ведь 10 процессов запустить без переключений задач... И RISC-V (Kendryte K210) тоже прекрасно справляется с двумя совершенно разными задачами на своих 2 ядрах (детектор объектов с камеры и распознавание голосовых команд с микрофона).

IvanShipaev Автор
30.12.2021 16:04+1Я рассматривал именно одноядерные микроконтроллеры, например как stm32F103. Если ядер больше одного, то все маленько усложняется. Я даже не встречал, чтобы использовали N ядерные системы на cortex-m3 или cortex-m4.
Cortex-A53 - это вполне мощное ядро на котором уже запускают Linux. Но Linux - это не Real Time (в отличие от QNX) на нем сложно добится даже 100 микросекундного отклика на события, нпаример, реакция на внешнее прерывание.
Если же Embdedded RTOS (на том же stm32F103) спроектирована правильно, то она обладает очень хорошей реакцией на события (в разы лучше чем Linux). При написание RTOS я делал упор именно на низкую латентность.predator86
30.12.2021 16:11+1Я даже не встречал, чтобы использовали N ядерные системы на cortex-m3 или cortex-m4.
Sony's CXD5602 microcontroller (ARM® Cortex®-M4F × 6 cores) with a clock speed of 156 MHz. Sony Spresense Main Board
longtolik
30.12.2021 17:28+1RP2040 из Rpi pico имеет два ядра ARM Cortex-M0+.
nRF5240 имеет ядро cortex-m4 для пользователей, но и вроде cortex-m0 для радиомодема.
И другие.
Cortex-A53 - я не имел ввиду Linux, а только "голое железо". И только жёсткий реал-тайм. Тот, где надо "дрыгать ногой" с частотой в (десятки) МегаГерц или следить за чей-то "ногой" с той же скоростью.
Интересно, сколько микросекунд занимает переключение задач при работе на одном ядре в cortex-m0.
Там всё просто, в программе на ассемблере разделяете ядра и направляете каждое ядро "на его путь истинный", например, на main0, main1,... или как хотите их назовите на языке C.
IvanShipaev Автор
30.12.2021 18:04Мне кажется это разные задачи. Я не работал с Rpi pico, но у меня был опыт с atsam4c и он имеет два ядра, но они не предназначены для rtos и имеют разную архитектуру. Их нужно рассматривать как два ядра в одном корпусе и они не равноправны, имеют доступ к разной периферии, одно dma может работать с одним ядром с другим нет, одно ядро имеет доступ ко всей RAM другое только к её части, одно ядро может выполнять код из flash - другое только из RAM и. д.т. Возможно существуют полноценные N ядерные микроконтроллеры, но в своей практике мне не приходилось с ними работать. Обычно если более одного ядра, то второе - это специализированное ядро для особых задач.
Для cortex-m0 время переключения можно посчитать по асемблерным командам, но я думаю даже на частоте 20-40 МГц, оно будет либо соизмеримо либо меньше 1 микро секунды.

byman
31.12.2021 13:01Правильно ли я понял, что у вас функция void PendSV_Handler(void) да еще с вызовом планировщика выполнится в худшем случае за 1 мкс?
IvanShipaev Автор
31.12.2021 14:03Смотря какая частота и надо считать по асм инструкциям. Но именно про void PendSV_Handler(void) я имел в виду. Работа планировщик тоже происходит очень быстро, когда происходит какое-нибудь событие, не важно где в прерывания или в задаче, устанавливается флаг программного прерывания. Если это прерывание, то поскольку PendSV имеет более низкий приоритет, прерывание заканчивается на PendSV (без дополнительного входа-выхода из irq, это тоже одна из фикеш cortex)
byman
31.12.2021 15:19а разве нет какого-нибудь счетчика тактов ядра? Тогда и частота не нужна.
IvanShipaev Автор
31.12.2021 15:57Есть конечно, можно и так измерить. Вот пример для stm32, но это всех ядер cortex касается https://hubstub.ru/stm32/82-vremya-vipolneniya-koda-stm32.html
byman
31.12.2021 16:11ну тогда может кто-то и измерит. У меня , к сожалению, никакого кортекса нет :)

GarryC
30.12.2021 11:54Не буду оценивать Ваши слова о том что Вы "не Пушкин и даже не Лермонтов" (то есть второй все таки пониже первого - сильное заявление, требует доказательств), но (простите великодушно) Вы и не Кнут. И если первое можно понять и простить, то невнимательность к техническим деталям на техническом ресурсе не допустима.
Итак, поехали:
0. Наличие двух стеков (все таки двух указателей стеков), изменяемых приоритетов прерываний и программного прерывания никак не является необходимым условием для написания RTOS, существуют многочисленные примеры обратного. Более того, наличие двух стеков создает определенные трудности, хотя и может быть полезным.
1. реализация двусвязного (не надо придумывать собственную терминологию) списка включает в себя данные полезной нагрузки, иначе список превращается в "вещь в себе".
2. при работе со списками задач необходима критическая секция, иначе Вам обеспечены непредсказуемые и неповторяемые баги.
3. использование абсолютно ничего не говорящего идентификатора nlst, несомненно, является фирменным стилем
4. и так далее и тому подобное.В общем, прежде чем браться за написание подобного труда, настоятельно рекомендую ознакомиться с трудами предшественников (они многочисленны, особенно на языке оригинала) и исходными кодами доступных реализаций, тогда вопросы, заданные в статье, отпадут сами собой.
IvanShipaev Автор
30.12.2021 15:41+1Честно сказать не совсем понятен коментарий.
Два стека позволяют существенно экономить на памяти. Их я использую, потому что cortex позволяет это делать. Конечно это не является обязательным условием, но если микроконтроллер это поддерживает на аппаратном уровне почему бы это не использовать.
По поводу двусвязного списка - это стандартное определение. Есть односвязный, двусвязный и XOR списки вещи вполне стандартные https://ru.wikipedia.org/wiki/Связный_список. В статье я показываю, как использовать двусвязный список и почему именно его. Это тоже вполне стандартная практика, посмотрите хотя бы ядро линукс, там он везде используется.
Критические секции по коду используются везде, где нужно, за это отвечаю функции
EM_DISABLE_TASK() и EM_ENABLE_TASK(). Почему я не описал критические именно в этой статье, потому что в ней я хотел рассказать об общих принципах. Использование критических секций планировалось описать в следующей статьеВот это если честно я вообще не понял, что не так-то?
Сложилось в печатление, что Вы даже не открывали код самой RTOS хотя ссылка на нее есть в самом начале статьи. Давайте еще раз ее продублирую https://github.com/IvanShipaev/EmTask.git

lamerok
30.12.2021 16:35Два стека позволяют существенно экономить на памяти. Их я использую, потому что cortex позволяет это делать. Конечно это не является обязательным условием, но если микроконтроллер это поддерживает на аппаратном уровне почему бы это не использовать
Наверное комментатор выше имел ввиду Task to complition операционные системы реального времени. Действительно два стека в этом случае как раз будет иметь перерасход памяти, поскольку вы под каждую задачу будете выделять стек с запасом, так как точно его вычислить практически невозможно. Когда же вы работает с одним стеком, можно границы максимально-возмодного стека определить практически точно.
В общем, все верно у вас, с комментатором выше не согласен. Можно было еще оптимизировать немного.
вместо отнимания 1
int rt_em_find_first_bit(int value) { __asm volatile ( "clz %0, %0" : "=r" (value) ); return 31 - value; }сделать так:
return __CLZ(__RBIT(taskStatus));А так, такие операционки с двумя стеками контекст переключают долго, даже у вас это будет довольно долго, несмотря на оптимальный алгоритм. В Run to comlition там буквально пару строк на ассемблере, если событие приходит из прерывания, и после прерывания надо переключиться в высокоприоритетную задачу. А если переключаться просто из низко-приоритеной в высоко-приритеной - так вообще сразу практически, как только нашел. Но это, с учетом, если я правильно понял мысль вышестоящего комментатора.
predator86
30.12.2021 16:47А так, такие операционки с двумя стеками контекст переключают долго, даже у вас это будет довольно долго, несмотря на оптимальный алгоритм.
Вы имеете в виду долгое переключение между PSP и MSP? С чем это связано?lamerok
30.12.2021 17:15Да вообще, ну смотрите, если в РанТокоплишен, переключение делается примерно вот так:
while (nextTaskId < activeTaskId) { activeTaskId = nextTaskId; CallTask(nextTaskId); // вызываем задачу и сбрасываем установленное событие nextTaskId = GetFirstActiveTaskId(); // вдруг есть еще активные задачи }Т.е. по факту, просто вызываем функцию высокопритетной задачи прямо на этом же стеке.
То в обычной, придется все делать через PendSv и иже с ним, что пойдет после прерывания таймера и вызова планировщика - ну и соотвественно вызывать планировщик с каждым тиком тоже надо, а это тоже затраты. В РанТокоплишен можно на каждую задачу навешать свой таймер и он будет вызывать её чисто в тот момент когда она должна запуститься, т.е. планировщик будет вызываться только в момент, когда реально задача или несколько задач готовы.
Я вот тут, ну совсем примитивный способ переключения описывал https://habr.com/ru/post/506414/
IvanShipaev Автор
30.12.2021 19:19Если я Вас правильно понял, то что Вы описываете - это кооперативная многозадачность. Вытесняемая многозадачность устроена по другому. Данной RTOS - вытесняемая многозадачность.
lamerok
30.12.2021 19:47Нет, это не кооперативная, это вытесняющая многозадачность. Всё тоже самое, что и у вас, только задачи это не бесконечный цикл. Но они точно также вытесняются высокоприотетными задачами. Например, рисуете вы графику, это занимает 100мс, вас точно также вытесняют высокоприотетные задачи, которые исполняются чаще, скажем раз в 1 мс. И стек один у всех задач. Если вы из низкоприритетной задачи послали евент высокоариоритеной, то она вызовется тут же на этом же стеке. Если высоприотетная задача запускается по таймеру, то она запустится точно через такой же механизм как у вас, только стеки переключать не будет.
predator86
30.12.2021 20:03Принцип работы такой же как и у стандартных прерываний? Тогда если будет несколько задач (больших и маленьких) с одинаковыми приоритетами то в этот момент многозадачность становится кооперативная для этой группы.
lamerok
30.12.2021 20:57Принцип работы такой же, как у вашей и всех остальных, типа FREE RTOS, только вместо одного таймера после прерывания которого происходит поиск задачи, и если есть готовая, идет переключение, в случае в рантокомплишен, вызов задач происходит по событию, например, от того же таймера.
Если задача должна выполнятся раз в 1 мс, то заводится таймер, который раз в 1 милисекунду посылает событие задаче. После выхода из прерывания таймера вызывается планировщик, он ищет самую высокопритеную и запускает её.
События можно посылать хоть откуда, например, из прерывания, если пришёл пакет по UART, послали событие задаче по обработке пакета. Если она самая высокоприотетная, она вытеснит текущую, запустится, выполнит обработку пакета и вернёт управление текущей.
Если задачи имеют одинаковый приоритет, то пока не выполнится одна, вторая не запустится, но тоже самое будет и у вас, пока вы не поставите, что то типа Sleep, но по сути это означает, что вы уже сделали всё что хотели и следующую порцию будете делать через некоторое время. В рантукоплишен задаче это делается так - выполнить работу, запустить таймер и выйти, таймер через заданное время снова пошлет задаче событие. Она тут же запустится.
Т. е. всё тоже самое, но быстрее и значительно компактнее по ресурсам, как по памяти ОЗУ, ПЗУ, так и энергоресурсам, потомк что, зазря таймер не долбашит и не вызывает планировщик попросту.
Планировщик вызывается только тогда, когда реально есть готовые задачи. Остальное время можно, например, спать.
Но там есть несколько других проблем, например синхронизацию между потоками типа мьютексов так просто не сделать, поэтому основные примитивы синхронизации там - это запрет планировщика или прерываний, но если упороться то можно добавить Priority Ceiling Protocol для того, чтобы позволить задачам с высоким приотетом не блокироваться вообще. Ну или Инверсию Приоритетов делать
predator86
30.12.2021 21:20Если задачи имеют одинаковый приоритет, то пока не выполнится одна, вторая не запустится, но тоже самое будет и у вас, пока вы не поставите, что то типа Sleep
Вытесняющий планировщик разделит время на все процессы с одинаковым приоритетом (условно по 10млс на задачу), даже если там будет бесконечный цикл, всё равно всем достанется. При вашем варианте будем ждать тяжёлый процесс из этой группы. Но этот метод действительно экономный и при правильном проектировании даёт значительные преимущества.Но там есть несколько других проблем, например синхронизацию между потоками типа мьютексов так просто не сделать
Если сочетать оба метода планирования, например ваш метод внутри вытесняющего планировщика в рамках одного процесса, позволит сэкономить на создании в нем потоков(нитей). И синхронизацию можно упросить, если использовать с этим методом только те функции которым она не требуется (или не создаёт проблем).lamerok
30.12.2021 21:55Вытесняющий планировщик разделит время на все процессы с одинаковым приоритетом (условно по 10млс на задачу), даже если там будет бесконечный цикл, всё равно всем достанется
Т. Е. По факту, всё задачи с равным приотетом делят своё время между собой, и просто бросают свою задачу на пол пути, планировщик вызывает другую. Ок. Но как бы это прямо реализация кооперативной многозадачности через вытеснение :)
При кооперативной многозадачности все приложения делят процессорное время, периодически передавая управление следующей задаче
Ок, я понял, что вы имели ввиду. Ну мы обычно просто задачи с равным приотетом делаем как раз, чтобы они друг друга не вытеснили и спокойно доделали своё дело. Но, Ок, теперь понял.
predator86
30.12.2021 22:04Ну мы обычно просто задачи с равным приоритетом делаем как раз, чтобы они друг друга не вытеснили и спокойно доделали своё дело.
Всё верно, подход требует правильного проектирования взаимодействия между задачами. По сути они должны всё знать друг о друге, что бы получить максимальный эффект для производительности.
IvanShipaev Автор
30.12.2021 20:36return __CLZ(__RBIT(taskStatus));
Спасибо за комментарий, но как этот код позволит определить номер установленного старшего бита? Он определяет номер установленного младшего бита, но нам не это нужно.
lamerok
30.12.2021 21:12Нам же нужен номер высыкоприоритетной задачи в массиве задач? Вот он как раз вернёт индекс задачи, дальше только вызвать её остаётся по этому индексу.
lamerok
30.12.2021 21:56Тоже самое будет, что и у вас, только меджик намбер уйдёт 31. Ну и с - проблем не будет.
IvanShipaev Автор
30.12.2021 22:02Но все-таки в чем оптимизация? И там и там 2 инструкции на ассемблере. Проблем тоже вроде нет.
byman
30.12.2021 17:15По поводу п.0 , думаю, что GarryC не понравилась Ваша стремная фраза "для RTOS в нем есть все необходимое " :) Возможно, если бы вы написали не так категорично, а,например,что-то типа "для RTOS есть интересные возможности", то ответ был бы иным ;)
По поводу 2-х указателей стека. Мне нравится такое решение. Я использовал такой же подход для FreeRTOS, портируя её на DSP 1967ВН044.
IvanShipaev Автор
30.12.2021 21:37Могу объяснить свою фразу. Дело в том, что я достаточно долго работал с AVR, stm8, pic16, mcs51 и т.д. В них также реализовывал различного рода переключатели контекстов. И как бы так сказать, там все как-то не очень удобно. И поэтому многие вещи, которые заложены в Cortex-m (также как и в либом ARM) , я думаю они закладывались специально при проектировании ядра с учётом того, чтобы для него было удобно писать rtos.
byman
31.12.2021 13:09А вот как на Ваш взгляд - RISC-V проектировался чтобы удобно было писать RTOS? Хотелось бы чтобы Вы продолжили свою тему, т.к. Вы рассмотрели пока только простые вещи, а вот интересно как раз посмотреть реализацию чего-то более сложного.
lamerok
01.01.2022 15:32Не там, не особо заморачивались, там вход и выход в trap, этакий единый обработчик прерываний занимает дофига времени. Но там фишка с переходом из машинного режима в обычный позволяет переключить контекст махом. Но это только с условием, что задачи не представляют из себя бесконечный цикл.
predator86
Интересная статья!
Расскажите как избежать.Будет ли организована защита памяти процессов с помощью MPU?
Ваша ОС будет полноценной (процессы, нити, исполняемые файлы типа «exe» и динамическая линковка типа «dll»)?
Kreastr
В РТОС обычно нет ни процессов, ни загрузки таксков, ни (особенно) динамической линковки. Потому что РТОС использую на железе, где нет аппаратного memory-management unit (не путать с memory-protection unit) и поэтому не поддерживает виртуальную память, которая для всего этого по-хорошему нужна.
"Нити", потоки в РТОС это Таски и есть.
Загружаемые таски сделать, конечно можно при помощи статически слинкованных и использующих position-independent code, но обычно для таких целей уже лучше иапользовать железо, которое тянет Embedded Linux с аппаратным или программным MMU
predator86
Так вы собираетесь его задействовать по прямому назначению?
Kreastr
Ответил ниже.
Не совсем уверен, что правильно понимаю Ваш вопрос. Но поясню в чем MMU и MPU можно перепутать, кроме очевидной ошибки в одном слове/букве и MMU и MPU выполняют функцию изоляции информации между процессами. Но при этом, MMU дополнительно предоставляет механизм вирутальной памяти. И казалось бы все просто, но вот только из некоторых MPU при желании можно сделать очень неэффективный software MMU. Для этого необходимо заблокировать процессу прямой доступ ко всем диапазонам памяти, а в обработчике прерывания ошибки доступа декодировать невыполненную инструкцию, выполнить ее "вручную" с подменой целевого адреса через софтовый же MMU/TLB и верунть исполнение программе дальше.
predator86
Kreastr
Если у Вас обычным образом настроенный MMU, то будет. Механизм простой - на железном уровне зарпашиваемый виртуальный адрес транслируется в физический. При этом запросы на чтение могут идти на одни и те же физические адреса в случае расшареных библиотек, но запись (если она вообще разрешена флагами доступа, который присвоены странице) в большинстве современных ОС вызовет механизм Copy on Write (CoW) и Ваша страница будет размножена для достижения уникальности.
Исключение из этого это виртуальная память, которую процессы специально назначают разделенной с другими процессами. В Линуксе для этого есть механизм shared memory. Про Виндоус не знаю - не приходилось такое создавать. В таких системах одна физическая страница будет доступна на запись одновременно несколькмим процессам.
predator86
Kreastr
Смотря чего Вы вообще пытаетесь добиться? Настраивать MPU при переключении задач, чтобы каждый таск в РТОС мог писать/читать только свою область памяти и вызывал ошибку при попытке влезть в чужое?
predator86
Да. Такое возможно?
Kreastr
Да, возможно. Это то, для чего MPU предназначены.
predator86
Хорошо что мы с этим разобрались. Спасибо.
byman
Я как-то сомневался, что с 8-ю регионами можно что-то напридумывать, но вот есть хороший пример https://www.freertos.org/MPU_Chapter.pdf
Dr_Zlo13
MMU мало связан с загрузкой и линковкой кода. Оно вполне осуществляется на любом контроллере который поддерживает выполнение кода из оперативной памяти.
Но да, ограничений в случае мелкого контроллера больше чем хотелось бы.
predator86
Назовите вкратце, какие ограничения (кроме фрагментации памяти) в МК мешают динамической линковке? Хочется разобраться.
Kreastr
Предположим Ваша динамически слинкованая программа ожидает, что динамически заргуженная библиотека будет находиться в блоке памяти, начиная с адреса X. Пусть для простоты этот блок включает в себя и исполняемый код и данные, которые библиотека для себя харниит в памяти. Однако на целевом процессоре у Вас эта библиотека загружена по адресу Y.
Если Вы попытаетесь загрузить ее и "слинковать" вручную, то Вам каким-то образом нужно будет перехватить все запросы к адресам в блоке Х и подменить адреса так, чтобы они ушли в блок Y с корректными смещениями. Если у Вас есть MMU, то это тривиально. Вы просто подставляете в таблице виртуальных адресов адресам для диапазона X корректные физические адреса, на которых загружена библоитека.
Однако,если у Вас MMU нет, то Вам приходится извращаться. Например, можно сделать таблицу вирутальных функций (которую Вам видимо будет предоставлять ОС), через которую Вы будете подставлять вызовы функций из библиотеки в свою программу. Но это решает только проблему с вызовом функций. Если же Вам потребуется получить прямой доступ к данным, которые хранятся в памяти этой функции, то тут уроень извращений вырастет существенно. В лучшем случае Вы, зная заранее, что у Вас такая псевдодинамическая линковка напишете функцию-обертку для доступа к этим данным вместо прямого доступа по указателям.
В общем это просто сложнее. И я не слышал, чтобы это реально кто-то применял. Тем более, что когда вы делаете встраиваемую систему куда проще просто скомпилировать свой код, заранее указав ему корректные адреса для доступа к библиотеке. То есть фактически сделав линковку статической, но позволив, например нескольким разным таскам адресовать одни и те же регионы памяти в которых будет находиться эта shared библиотека.
И это все равно будет работать только до тех пор, пока Ваша библиотека thread-safe. Если только нет, то ее разделение между тасками потребует кучу дополнительных оверхедов для менеджмента синхронизации. В случае с MMU этой проблемы нет, потому что когда нужно, страница в которую поток попытается что-то записать будет просто скопирована и станет уникальной для этого потока.
Вот здесь немного о том, как можно делать shared библиотеки без MMU http://xflat.sourceforge.net/NoMMUSharedLibs.html
predator86
А если мне не просто помигать светодиодом, но и GUI и WebCam и Webserver с Websocket и JS, C# и uPyton интерпретатор и чтобы всё одновременно и оперативы у меня 64МБ и QSPI на 1Gb, то всё, я в пролёте?
Kreastr
MMU это не устройство, которому требуется "перезагружаться" от библиотеки к библиотеки. Это не одна пара подстановок адрес-Zадрес, а целая таблица недавно запрошенных подстановок (Translation Lookaside Buffer - TLB), огромная древообразная структура в оперативной памяти, которая сохраянет все возможные значения подстановок и обычно небольшое количество указателей на эти структуры в памяти, которые определяют контекст подстановок в разных режимах работы процессора (у процесса свой указатель, у ОС свой, у гипервизора и драйверов свои).
MMU требуется только сбрасывать данные из TLB при переключении между процессами. Это одна из причин, почему в больших ОС переключение задач значительно медленнее, чем в РТОС, в которых этого механизма просто нет.
Самый главный вопрос тут: а что Вам вообще с Вашей точки зрения даст динамическая линковка, если Вам нужно чтобы "все одновременно"? Это же не какая-то магия, чтобы при динамической линковке все резко стало меньше места занимать. Статически у Вас даже больше опций будет, потому что сможете вручную свои 64 Мб расписать между программами, а выделить общие библиотеки, чтобы избежать дублирования можно и без динамической линковки. Так что либо в обоих случаях влезет, либо не влезет, какую линковку не используй.
predator86
Kreastr
Это некорректное утверждение. Загрузка двух динамических библиотек для одного процесса не будет никогда произведена на одни и те же виртуальные адреса.
Если Вы заранее знаете весь набор приложений кооторые будут одновременно запускаться и полный список общих библиотек у Вас есть, то Вы распределяете библиотеки по статичным адресам и компилируете все свои программы в режиме исполнения с относительной адресацией, но со статическими, заданными заранее адресами всех библиотек. После этого Вы сможете эти программы загружать и выгружать по желанию. Правда это в любом случае дурной подход, потому что фрагментация памяти будет.
Альтернатива только девайс с виртуальной памятью. То есть либо аппаратный, либо хотя бы софтовый MMU. Иначе никак из-за "не знать что там вообще происходит с другими процессами"
Это к разговору о динамичской линковке точно не относится. Думаю при желании можно организовать такие настройки компилятора, чтобы он использовал только общий набор команд. Ну или написать свой компиляторный фронтенд на основе общих команд. В любом случае попытки написать что-то универсально кросс-платформенное должны закончиться где-то в области портирования JVM под Ваши процессоры вместо этих извращений.
predator86
Набор всех приложений не известен.
Эти приложения могут находится в разных участках памяти и к ним нужно прилинковать ОС которая тоже может находится где угодно.
Здесь общая архитектура, а не платформа.
Kreastr
Виртулаьные адреса не совпадают у разных библиотек загружаемых в один процесс. У разных процессов на одном и том же виртуальном адресе могут не то что разные библиотеки, а вообще все что угодно. В этом и сосотоит суть концепции виртуальной памяти - с точки зрения процесса он исполняется на устройстве монопольно.
Уточню. Здесь проблема не в том, что не библиотеки не знают друг о друге в рамках одного процесса, а в том, что разные процессы, скомпилированные в расчете на виртуальную память будут каждый ожидать разное содержимое одних и тех же виртуальных адресов. Для кого-то это будет собственный код. Для кого-то данные, а какой-то процесс будет грузить туда библиотеку.
Ничего не мешает, но это уже не динамическая линковка. И Вам все-таки потребуется заранее спланировать эти самые физические адреса и для приложений и для библиотек, потому что физическое адресное пространство не резиновое.
Исключение - использование Position-Independent code, в котором все внутренние вызовы и ссылки на "глобальные переменные" привязаны к значению счетчика команд (Program Counter, PC). Такой код сам по себе можно загрузить в любое (почти) место в памяти и он будет работать. И к такому коду можно вручную "прилинковать" вызов библиотечных функций через указатели, как Вы предлагаете ниже. НО это работает с рядом оговорок, многие из которых я уже упоминал выше и поэтому я не стал бы это называть динамической линковкой, потому что это примерно как назвать велосипед автомобилем, только потому что формально и то и другое - транспортное средство.
https://en.wikipedia.org/wiki/Cross-platform_software
"Platform can refer to the type of processor (CPU) or other hardware on which an operating system (OS) or application runs, the type of OS, or a combination of the two.[4]"
Пожалуйста, обрабтите внимание на то, что я цитирую и на что отвечаю.
predator86
Так же как и процесс на МК, тоже не знает о существовании других процессов. Ведь он точно так же не имеет права исполнять, писать и читать то чего ему не выделили.
Это не так, процессы работают только с той памятью о которой им сообщат динамически, т.е. им заранее ничего не известно. Только часть заранее загруженных библиотек API у всех процессов совпадают в VM, и только по тому что процесс их линковки при запуске одинаков для всех, не более.
Динамичнее уже некуда.
1ГБ как минимум можно примапить к МК, гуляй сколько хочешь.
Можно услышать хоть одну внятную оговорочку?
Платформа очень широкое понятие, в отличие от архитектуры, и в нашем контексте не уместно.
Kreastr
Если у Вас всего один процесс, то все так. А теперь просто пресдтавьте как это все будет работать (даже безотносительно линковки и библиотек), если процессы скомипилированы с использованием одних и тех же адресов. Что тогда Ваша ОС будет делать?
Прав у него нет, конечно, а вот техническая возможность очень даже есть. А еще, рази процессы не знают (и не должны знать) о существовании друг друга на этапе компиляции, то они скорее всего будет скопилированы с использованием пересекающихся адресов.
Это Вы откуда такую информацию взяли?
Ну, если мы с Вами разные вещи называем тапками, то, кажется, продолжать обсуждение тапок довольно бесполезно.
Зачем Вам в таком случае вообще библиотеки динамически линковать? Скомпилируйте все свои таски с нужными им библиотеками статически и будет Вам простое и надежное решение.
Иcпользуемые библиотеки должны быть thread-safe.
Я не знаю, что уместно в Вашем контексте да и вообще теряюсь уже в чем он вообще состоит. Нов контексте моего комментария про использование виртуальных машин для создания кросс-платформенных (как с точки зрения архитектуры, так и с точки зрения ОС) приложений оно очень даже уместно.
predator86
Они не будут так скомпилированы если им этого не позволять.
Давно где то читал, где — уже не вспомню.
Согласен, это бессмысленно и не нужно.
Мне так кажется более удобно и экономично при переиспользовании повторяющегося кода для приложений которые компилируются независимо.
Хорошо, делаем их такими где требуется.
Хочу полноценную ОС для МК без виртуальных машин.
Kreastr
А как надо?
В таком случае советую почитать про форматы хранения файлов, например стурктуры заголовков ELF или EXE файлов. Мне кажется, Вас там ждет новая информация.
Удобно делать лишние действия? Видимо определение слова удобно у нас с Вами тоже не совпадают.
Вот так вот просто берем и делаем, да? Возможно я чего-то не знаю и где-то в документации на какой-нибудь gcc пропустил флаг --do-your-magic-and-make-it-thread-safe
Зависит от того, что Вы подразумеваете под "полноценной ОС". Но если брать максимально полноценные варианты, то:
Если у Вашего МК есть MMU -> Linux
Если у Вашего МК нет MMU -> uCLinux https://en.wikipedia.org/wiki/ΜClinux
predator86
Читаем из нашей любимой википедии:
Всё верно, как и предполагалось.
Да это удобно, разве нет?
Да, и ОС предоставит нам для этого все необходимые интерфейсы.
Как то вяло он разрабатывается. И зачем нам линукс на мк если от него там только одно название и останется.
IvanShipaev Автор
Для таких целей можно использовать виртуальную машину, например, pawn https://www.compuphase.com/pawn/pawn.htm. Однажды собранная программа будет работать везде: линукс, микроконтроллер, Windows и т. д. Она поддерживается на ARMv7. Имеет достаточно хорошую производительность, позволяет писать свои нативные функции и имеет СИ похожий синтаксис. И главное - она влазит даже в самый мелкий cortex.
Dr_Zlo13
Я реализовал динамическую загрузку кода в Flipper Zero, оно на стадии пруф оф концепт, но до доведения до юзабельного состояния правок самого механизма загрузки и линковки не требуется, вопрос в составлении ABI ядра и билд-системе.
Библиотекой в таком подходе выступает ядро, приложением - загружаемый код. Механизмы синхронизации те же самые что использует ядро (у нас ядро умеет вкомпиливать в себя приложения, поэтому оно обязано быть thread safe).
predator86
Dr_Zlo13
Нет, код компилируется в нулевой адрес, при загрузке релоцируется.
predator86
А глобальные переменные процесса как обнаруживаются?
Dr_Zlo13
А зачем это может быть нужно? В любом случае, в чем проблема?
predator86
У приложений есть глобальные переменные, и процесс должен знать где в памяти они находятся чтобы ими пользоваться. Или вы их вообще не задействуете?
Dr_Zlo13
Фрагментация памяти, ее малое кол-во, хранение списка [название функции : адрес функции] для прилинковки функций из ядра к приложению и поиск функции в этом списке на этапе загрузки (в достаточно больших ОС это вполне могут быть сотни килобайт данных).
predator86
Вполне достаточно передать адрес на таблицу относительных адресов функций. 4 байта затрат на динамическую библиотеку.
Dr_Zlo13
А библиотека-то где хранится?
predator86
Либо в ROM, либо в RAM грузим. После этого спрашиваем у неё адрес на таблицу и работаем.
Dr_Zlo13
Сотни килобайт в RAM? Даже в ROM оно не всегда помещается.
predator86
Таблица относительных адресов функций (интерфейсов динамической библиотеки) будет весить 4*N байт, где N — количество импортируемых функций. Находится она в самой библиотеке. Для вызова достаточно хранить в ОЗУ только 4 байта (на одну либу) с адресом положения этой таблицы.