
Когда чуть больше года назад я впервые услышал о слабой разметке, то поначалу отнёсся к ней скептически. Суть слабой разметки (weak labelling) заключается в том, что можно заменить аннотированные вручную данные на данные, созданные по эвристическим правилам, написанным специалистами в соответствующей области. Мне это показалось совершенно нелогичным. Если можно создать очень хорошую систему на основе правил, то почему бы просто не использовать эту систему? А если правила недостаточно хороши, то разве не будет плохой и модель, обученная на шумных данных? Это казалось мне возвратом в мир конструирования признаков, которому должно было прийти на смену глубокое обучение.
Однако за последний год моё отношение полностью переменилось. Я поработал над множеством NLP-проектов, в которых было задействовано извлечение данных, и намного сильнее углубился в изучение литературы про обучение со слабым контролем. Также я пообщался с руководителями команд ML в таких компаниях, как Apple, где услышал истории о том, как целые системы заменяли за считанные недели — благодаря сочетанию слабого контроля и машинного обучения им удавалось создать обширные наборы данных для языков, ресурсов по которым было мало и которые раньше попросту не обслуживались!
Поскольку теперь я обладаю энтузиазмом новообращённого, мне хочется рассказать о том, что такое слабый контроль, чему я научился и почему, на мой взгляд, в области аннотирования данных он дополняет такие техники, как активное обучение.
Слабый контроль — это вид программной разметки
Понятие «слабый контроль» (weak supervision) было предложено Алексом Ратнером и Крисом Ре, позже создавшими пакет Snorkel с открытым исходным кодом, а затем основавшими компанию-«единорог» Snorkel AI. Это трёхэтапный процесс, позволяющий обучать модели машинного обучения с контролем, начав с очень малого объёма аннотированных данных. Вот эти три этапа:
1. Создание ряда «функций разметки», который можно применить к набору данных
Функции разметки — это простые правила, которые могут предполагать подходящую метку для примера данных. Например, если вы пытаетесь классифицировать заголовки новостей как «кликбейт» или «настоящие новости», то можно воспользоваться следующим правилом:
«Если заголовок начинается с числа, спрогнозировать, что метка — кликбейт, а если нет, то не прогнозировать метку».
Можно представить это в виде такого кода:
def starts_with_digit(headline: Doc) -> int:
"""Labels any headlines which start with a digit."""
if headline.tokens[0].is_digit():
return 1
else:
return 0Очевидно, что это правило не будет точным на 100% и не позволит определить все кликбейтные заголовки. Но это нас устраивает. Важно то, что можно придумать несколько разных правил и добиться того, чтобы каждое правило было достаточно хорошим. Накопив коллекцию правил, мы затем можем научиться тому, когда и каким правилам доверять.
2. Применить байесовскую модель для определения метки, наиболее вероятной для каждого примера данных
Для практикующего машинное обучение хорошая новость заключается в том, что самую сложную математику берут на себя open-source-пакеты.
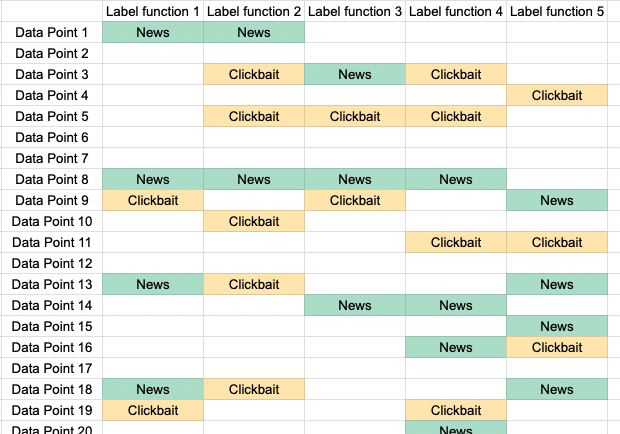
Полезно иметь наглядный пример, поэтому давайте вернёмся к нашей классификации новостных заголовков. Представим, что у нас есть 10000 заголовков и 5 функций разметки. Каждая функция разметки пытается угадать, является ли заголовок «новостным» или «кликбейтным». Чтобы визуализировать это, можно свести их в одну большую таблицу, где в строках указаны заголовки, а в столбцах — функции разметки. Мы получим таблицу с 10000 строк и 5 столбцами:
Функции разметки для распознавания кликбейта. Каждое правило может голосовать за «новость» или «кликбейт», или же воздержаться.
Теперь наша цель заключается в определении наиболее вероятной метки для каждой точки данных. Проще всего будет воспользоваться мажоритарными результатами голосования в каждой строке. Если четыре функции разметки проголосовали за «кликбейт», мы предположим, что метка — это кликбейт.
Проблема такого подхода заключается в том, что мы знаем — некоторые из правил будут плохими, а другие хорошими. Также мы знаем, что правила могут коррелировать. Обойти эту проблему можно, сначала обучив вероятностную модель, которая учится оценивать точность каждого правила. Обучив эту модель, мы сможем вычислить распределение p(y=кликбейт| функции разметки) для каждой из точек данных. Это будет более интеллектуальным взвешиванием всех 5 пяти голосов, полученных для каждого примера данных.
Модель может сказать нам, что правило точно, если оно постоянно голосует вместе с большинством. И наоборот: если правило очень хаотично и только иногда голосует с большинством, оно будет хорошим с меньшей вероятностью. Чем больше приблизительных правил у нас будет, тем лучше мы сможем их очистить.
При выборе способов очистки меток и обучения модели есть большая свобода. Большинство исследований, сделанных на ранних этапах развития обучения со слабым контролем, рассматривало вопросы совершенствования использованной модели и эффективности обучения. В первоначальной статье для изучения точности каждого правила использовались наивная модель Байеса и SGD с выборкой Гиббса. Позже были разработаны методики, позволяющие также выявлять корреляции между функциями разметки, а в недавней работе для эффективного обучения модели использовались методики восстановления матриц (matrix completion).
3. Обучить обычную модель машинного обучения на наборе данных, полученном на первом и втором этапах
Получив оценки вероятности каждой метки, можно или задать им пороговые значения, чтобы получить чёткую метку для каждого примера данных, или воспользоваться распределением вероятностей в качестве целевого показателя модели. Как бы то ни было, теперь у вас есть размеченный набор данных, который можно использовать как любой другой размеченный набор данных!
Можно пойти дальше, обучить модель и получить хорошую точность, даже если и на начало проекта у вас не было аннотированных данных!
Крупный набор данных со слабым контролем настолько же хорош, как и маленький размеченный набор данных
Одно из доказательств в исходной статье демонстрирует, что производительность слабой разметки при увеличении объёма неразмеченных данных и производительность обучения с контролем при увеличении количества размеченных данных растут с одинаковой скоростью!
Это утверждение кажется слишком сложным, и его можно не понять, но на самом деле оно очень содержательное. Когда я впервые читал о слабом контроле, я его не оценил. Именно благодаря тому, что позже оно стало мне понятным, я и стал сторонником слабой разметки.
Это означает, что после получения хорошего набора функций разметки производительность становится тем лучше, чем больше неразмеченных данных вы добавляете. Сравните это с контролируемым обучением, при котором для повышения производительности нужно добавлять размеченные данные, а их создание может потребовать работы специалистов.
Обычно при обучении модели машинного обучения, например, логистической регрессии, можно прогнозировать, что ожидаемая погрешность на тестовом наборе будет снижаться с увеличением количества размеченных данных. Но тут можно сказать и ещё кое-что. Величина погрешности на тестовом наборе уменьшается со скоростью O(1/n), где
n — это размеченные примеры данных. Поэтому если вы хотите снизить тестовую погрешность, вам придётся размечать много данных, и каждый дополнительный пример данных (выбранный случайным образом) улучшает модель всё меньше и меньше.При обучении модели машинного обучения со слабым контролем также следует ожидать, что погрешность на тестовом наборе будет убывать как O(1/n), но теперь
n — это количество неразмеченных примеров данных! И это просто чудесно, ведь достаточно небольшого объёма труда специалистов-аннотаторов, чтобы получить хорошие правила, а затем применить их к огромному набору данных.Маленький, но очень чистый набор данных эквивалентен большому, но шумному набору данных. Слабый контроль даёт вам очень большой, но слегка зашумлённый набор данных.
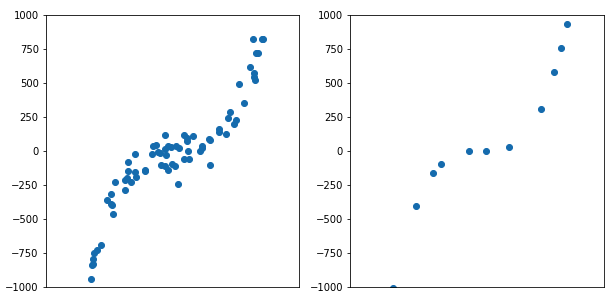
Большой шумный набор данных сравним по производительности с маленьким чистым набором данных.
Обучение модели на слабо размеченных данных даёт огромный прирост точности
Поначалу неочевидно, почему обучение модели на данных, полученных из правил, даёт повышенную точность. Разве модель не учится просто повторять правила?
Вообще-то нет, и причина этого заключается в том, что признаки, используемые дискриминантной моделью, необязательно должны совпадать с теми, которые используются как входящие данные для эвристик или правил. Это означает следующее:
1. Модель может обобщать вне пределов правил, потому что она извлекает более общие признаки.
Например, частичное правило для определения эмоционального настроя текста может использовать набор ключевых слов. Обученная на этих данных из частичного правила дискриминантная модель не видит этих ключевых слов и вместо них обучается более общему признаку о порядке слов и наличии в тексте других слов.
2. Можно использовать для правил входные данные и признаки, которые могут быть недоступными на момент прогноза.
Например, у вас есть набор медицинских снимков с сопровождающими примечаниями врача и вы хотите обучить классификатор на одних снимках. Можно написать набор правил, получающих текстовые примечания и создающих метки для снимков. Правила неприменимы для классификатора изображений, зато применимы результаты использования правил.
На практике уже существует множество конкретных примеров, доказывающих это утверждение. Например, в этой статье удалось добиться извлечения медицинских данных без размеченных данных и всё равно получить результат, менее чем на 2% отличающийся от современных моделей с полным контролем.
Обучение дискриминантной модели на очищенных от шума правил почти всегда обеспечивает очень значительный рост производительности. Часто встречается даже показатель точности в 10 единиц f1.
Помните, что после первых двух этапов у нас есть только размеченный набор данных. Дискриминантная модель может обобщать свою работу вне рамок правил точно так же, как любая модель может обобщать свою работу вне рамок вручную размеченных данных. В обоих случаях у вас имеется модель с аннотированным набором данных (имеющим шумы), и вы надеетесь, что она сможет научиться обобщать прогнозы для новых экземпляров данных.
При слабом контроле работа специалистов используется гораздо эффективнее
В NLP часто бывает, что для создания аннотаций необходима экспертиза в соответствующей области знаний, а времени специалистов в области часто бывает недостаточно.
Например, если вам необходимо извлечь информацию из юридических документов, то каким-то образом нужно убедить юристов аннотировать данные. Часто область знаний оказывается настолько специфической, что вам требуется не любой юрист, а юрист с соответствующей практикой. Убедить такого юриста выделить хотя бы несколько часов своего времени может быть чрезвычайно сложно. Если вы выполняете аннотирование вручную, то даже при использовании инструментов наподобие активного обучения вам могут понадобиться сотни меток. В таком случае вы попросту не сможете решить проблему деньгами. Вам необходимо будет получить больше меток за ограниченный объём времени специалистов. Решением становится слабый контроль. За короткий сеанс со специалистом в области можно придумать множество эвристических правил, а затем решать свою задачу благодаря доступности неразмеченных данных.
Подобные проблемы с доступностью специалистов возникают в медицине, где единственные люди, способные выполнять аннотирование, имеют постоянную работу. Если вы располагаете только несколькими часами в неделю времени специалиста, слабая разметка будет более эффективным способом использования этого времени, чем чисто ручное аннотирование. В этой статье один специалист за один день смог добиться производительности, которую команда разметчиков достигла за множество недель.
Как использовать обучение со слабым контролем сегодня?


Самый простой способ применения обучения со слабым контролем сегодня — это использование пакетов с открытым исходным кодом Snorkel или Skweak.
Snorkel изначально активно поддерживался исследователями, разработавшими эти методики. Это были полезные вспомогательные функции для создания, применения и оценки правил разметки. Также он имеет поддержку преобразования данных: например, переворота изображения или замены синонимов в тексте. Пакет поддерживает единственную модель, предполагающую, что все функции разметки не зависят друг от друга. Если вы создаёте функции разметки, имеющие корреляции, или работаете с данными последовательностей, он подойдёт не так хорошо. Похоже, библиотека развивается не очень активно, однако принимает вклад сообщества.
Skweak — это более новый научный проект, предназначенный для слабой разметки текста для NER (Named-entity recognition). Используемая им модель устраняет шумы в данных на основе скрытой модели Маркова, а также лучше справляется с обработкой корреляций между примерами данных (но опять-таки между функциями разметки). Skweak больше рассчитан на работу с текстовыми последовательностями, поэтому работает поверх объектов документов spaCy. При работе с текстом он имеет множество удобных преимуществ, потому что можно использовать части речи и другие теги, которые модели spaCy применяют к данным. Библиотека довольно нова, но её определённо стоит оценить.
Чего не хватает в современных инструментах для слабой разметки?
Современные пакеты с открытым исходным кодом делают упор на математические инструменты, необходимые для перехода от шумных функций разметки к очищенным наборам данных. Это определённо самые сложные задачи, поэтому вполне логично, что разработчики начали с них. Однако когда я впервые начал использовать слабую разметку, то осознал, что ей требуется гораздо больше.
Придумывание функций разметки — это высокоитеративный процесс, требующий обратной связи. Вы придумываете правило, проверяете, насколько оно подходит, а затем производите итерации, пока не получите качественный набор правил. Однако понять, «насколько оно подходит», достаточно сложно. Я обнаружил, что приходится писать много бойлерплейта, чтобы применить мои функции разметки, а затем писать код для отображения результатов. Цикл обратной связи/отладки очень долог, и то, что должно требовать 15 минут, растягивается на часы.
Процесс создания правил ускоряет и доступ к внешним ресурсам, например, к словарям ключевых слов или к базам знаний. Например, если вы хотите выполнить NER для нахождения упоминания лекарств в медицинских картах, то можно использовать словарь известных названий лекарств. Он не покроет все примеры, но отлично подойдёт для функции разметки. Постепенное упорядочивание таких ресурсов и внедрение их в вашу платформу слабой разметки позволяет медленно её совершенствовать.
Наличие даже небольшого объёма эталонных данных всё равно сильно помогает. Вам всё-таки нужно оценивать обученные модели, поэтому в конечном итоге понадобится аннотированный тестовый набор данных. Наличие размеченных проверочных данных ещё до создания правил тоже сильно упрощает понимание того, насколько качественны правила, и позволяет быстрее выполнять итерации.
Комментарии (2)

iRumata
13.01.2022 14:31спасибо за материал!
А можете дать ссылки на основные статьи по подходу "слабой разметки" или хотябы его описания применительно к текстам? Я в статье нашел только одну медицинскую ссылку
S_A
Другое название для синтетики и/или аугментации?