

Люди часто думают, что код на ассемблере читается не просто плохо, а очень плохо. Но я думаю, что это совершенно не так.
Я всегда считал, что читаемость кода на совести программистов и язык здесь совершенно не причём.
Так вот, когда работал над одним из своих проектов, мне понадобился алгоритм для поиска следующего или предыдущего листа дерева. Алгоритм тривиальный, но реализация получилась такой компактной и простой, что решил опубликовать её в качестве иллюстрации того, что на ассемблере можно (и нужно) писать удобочитаемый код.
Честно говоря, я сомневаюсь, что на языке высокого уровня можно написать это более компактно и понятно.
Но возможно я ошибаюсь. Увидим далее в статье.
Дерево для которого писался код, является упорядоченным, двусвязным и с произвольным количеством дочерних узлов. Каждый узел, описывается следующей структурой:
struct Node
.parent dd ? ; к родительскому узлу
.f_child dd ? ; к первому дочернему узлу
.l_child dd ? ; к последнему дочернему узлу
.next dd ? ; к следующему узлу в списке дочерних узлов
.prev dd ? ; к предыдущему узлу в списке дочерних узлов
ends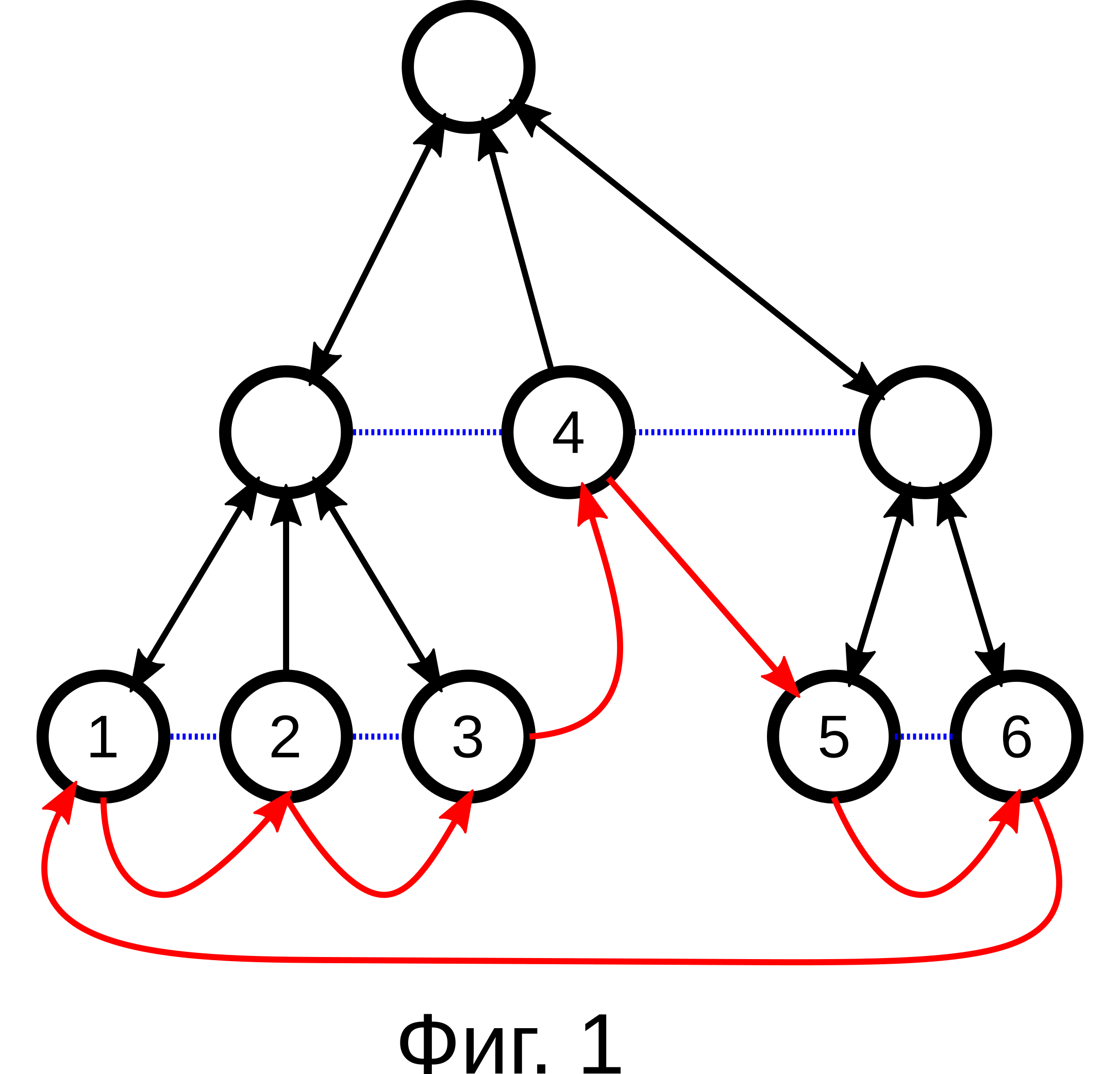 Все дочерние узлы родительского узла образуют двусвязный список (поля .next, .prev). Родительский узел указывает только на начало и конец этого списка, соответственно через указатели
Все дочерние узлы родительского узла образуют двусвязный список (поля .next, .prev). Родительский узел указывает только на начало и конец этого списка, соответственно через указатели .f_child и .l_child.
Задача: По заданному листу дерева, надо найти следующий лист. Если лист последний, найти первый лист дерева.
Это показано на Фиг.1; Синим пунктиром изображены связи через .prev и .next, черными линиями связи через .parent, .f_child и .l_child, а красными линиями, изображена последовательность переходов по алгоритму.
Я работаю над ОС-независимой GUI библиотекой на ассемблере. В этой библиотеке, каждое окно, представляет узел дерева с такой структурой.
Обсуждаемый поиск по листьям нужен, для передачи фокуса вперёд или назад при нажатии на клавиши Tab или Shift+Tab.
Конечно, в библиотеке это сложнее – нужно проверять хочет ли данное окно фокус и может ли его принять (например окно невидимое, или неактивное) в данный момент. Но это детали, которые никак не влияют на обсуждаемой теме.
В обсуждаемом коде используются только 3 инструкции:CMP– сравнивает два операнда и устанавливает флаги состояния.CMOVcc– условная пересылка данных – если условиеccвыполнено, данные пересылаются из второго операнда в первый. Если условие не выполнено, то ничего не делается. Условия могут быть разными, но здесь используется толькоNE– не равно, то есть, инструкцияCMOVNE.Jcc– условный переход. Условия те же самые как вCMOVcc. Если условие выполнено, переход делается. Если нет, исполнение продолжается вниз.
Квадратные скобки в выражениях на ассемблере означают содержание памяти на данном адресе. А значение в скобках, это адрес. То есть, примерно[eax+Node.f_child]означает, что вычисляется адрес как сумма содержания регистраeaxи константыNode.f_child(Node.f_child == 4 в этом случае), читается содержимое так полученного адреса и с ним что-то делается – пересылается куда-то (mov, cmov) или сравнивается с чем-то (cmp) и т.д.
А вот и сам код в девяти инструкциях:
; Поиск следующего листа
; EAX == указатель к исходному листу дерева.
.next:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .next
.to_leaf:
cmp [eax + Node.f_child], 0
cmovne eax, [eax + Node.f_child]
jne .to_leaf
; Здесь EAX содержит указатель к следующему листу дерева.; Поиск следующего листа
; EAX == указатель к исходному листу дерева.
.next: ; Ищем следующий узел:
cmp [eax + Node.next], 0 ; Это последний узел?
cmovne eax, [eax + Node.next] ; если нет, берём следующий...
jne .to_leaf ; ...и идём к выходу.
cmp [eax + Node.parent], 0 ; это корневой узел?
cmovne eax, [eax+Node.parent] ; если нет, берём родительский узел...
jne .next ; ...и ищем следующий узел.
.to_leaf: ; Идём вниз к листьям:
cmp [eax + Node.f_child], 0 ; это лист?
cmovne eax, [eax + Node.f_child] ; если нет, идём вниз...
jne .to_leaf ; ...и повторяем
; Здесь EAX содержит указатель к следующему листу дерева.У этого кода есть только один изъян. Если у дерева есть несколько корневых узлов, то алгоритм не будет переходить правильно от последнего к первому листу.
Конечно, это уже будет не одно дерево, а несколько несвязанных между собой деревьев (точнее связанные только через .prev и .next). Но структура позволяет такое, так что было бы хорошо, если алгоритм корректно работал с такими деревьями.
Этого можно достичь, добавив еще три инструкции. А точнее, те же три инструкции еще раз:
.next:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .next
.to_first: ; Вот здесь.
cmp [eax + Node.prev], 0
cmovne eax, [eax + Node.prev]
jne .to_first
.to_leaf:
cmp [eax+Node.f_child], 0
cmovne eax, [eax+Node.f_child]
jne .to_leafТот же самый код можно использовать и для поиска предыдущего листа, поменяв prev на next и f_child на l_child:
.prev:
cmp [eax + Node.prev], 0
cmovne eax, [eax + Node.prev]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .prev
.to_last:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_last
.to_leaf:
cmp [eax + Node.l_child], 0
cmovne eax, [eax + Node.l_child]
jne .to_leafВы наверное заметили, что весь код состоит из одинаковых триплетов:
cmp [variable], 0
cmovne REG, [variable]
jne somewhereЭто дополнительно увеличивает удобочитаемость кода. Достаточно однажды понять, как эти три инструкции работают в связке, чтобы понять весь код.
А теперь давайте сравним этот код с эквивалентным кодом на C++.
У меня, с трудом (я не силён в C++), но получилось как-то так:
Структура:
struct Node {
Node *parent;
Node *f_child;
Node *l_child;
Node *prev;
Node *next;
};И сам код:
// Поиск следующего листа
// leaf == указатель к исходному листу дерева.
while (1) {
if (leaf->next) {
leaf = leaf->next;
break;
};
if (leaf->parent)
leaf = leaf->parent;
else {
while (leaf->prev) leaf = leaf->prev;
break;
};
};
while (leaf->f_child) leaf = leaf->f_child;
// Здесь, leaf указывает на следующий лист.Я оставил только код, который непосредственно делает работу. Постарался оформить его, так, чтобы был более читабельным. Но все равно, ассемблерный код читается легче.
В коде на C++ нет никакого общего шаблона. Чтобы понять, как он работает, надо рассматривать каждую линию в отдельности и в связке с остальными.
А может это мне только кажется и зависит от знания языка? Или этот код можно написать лучше?
Компилировал так:
g++ -m32 -Os ./test.cpp -o ./testРезультатом компиляции стал следующий код (я намерено использовал те же самые метки как в ассемблерном коде, чтобы легче было сравнивать):
.next:
mov edx, [eax + Node.next]
test edx, edx
jnz .to_leaf
mov edx, [eax + Node.parent]
test edx, edx
jz .to_first
mov eax, edx
jmp .next
.to_first:
mov edx, eax
mov eax, [eax + Node.prev]
test eax, eax
jnz .to_first
.to_leaf:
mov eax, edx
mov edx, [edx + Node.f_child]
test edx, edx
jnz .to_leafНадо сказать, что код получился достойным. Не идеальным для чтения, но этого от компилятора и не требуется.
Но даже этот неидеальный код, мне кажется, читается лучше, чем оригинальный код на C++.
Напишите в комментариях, считаете ли вы ассемблерный код сложным для чтения? А что вам мешает – незнание языка, программисты, которые пишут плохо читаемый код, или вы думаете, что это свойство ассемблера и ничего нельзя сделать в принципе?
Комментарии (45)

forthuser
14.01.2022 15:23В представленном варианте, код ассемблерной программы это последовательность действий команд процессора даже без обрамления возможным синтаксисом команд структурного программирования, что, кстати, не так сложно в использовании и макрорасширений ассемблера, если изначально такие возможности не встроили в ассемблер.
Си же код записи алгоритма более подходит для «обобщённого» понимания записи алгоритма вне прямого акцентирования на потоке команд управления данными.
Как то так. ????

lorc
14.01.2022 15:40+2Честно говоря, я сомневаюсь, что на языке высокого уровня можно написать это более компактно и понятно.
Компактно - запросто. С "понятно" все сложнее, потому что это чисто субъективное понятие, которое полностью зависит от бэкграунда читающего. Например я чаще имею дело с армовским ассемблером и меня вымораживают названия регистров в x86.
picul
14.01.2022 16:02+6Автор написал код на ассемблере, транслировал его в плюсы и получил нечитабельное нечто - вот так новость, видимо ассемблер самый понятный в мире язык. Вот, ловите нормальный код:
while ( !p->next && p->parent ) p = p->parent; p = p->next ? p->next : p; while ( p->f_child ) p = p->f_child;
johnfound Автор
14.01.2022 16:47+1Ваш код не работает корректно если коренных узлов больше одного. То есть не эквивалентен C++ коду в статье.
picul
14.01.2022 22:00+4Даже если не вариант сделать список корней кольцевым, то можно так:
while ( !p->next && p->parent ) p = p->parent; if ( p->next ) p = p->next; else { while ( p->prev ) p = p->prev; } while ( p->f_child ) p = p->f_child;johnfound Автор
14.01.2022 23:29Да, теперь все в порядке.
Но самое интересное, что теперь ваш код компилируется до абсолютно тех же самых инструкции как и мой C++ код.
Теперь надо только разобраться кто из них более удобочитаемый. :)
picul
15.01.2022 01:13+1Этого не может быть. Нормальный компилятор как минимум заиспользует инструкцию test вместо cmp.
Удобочитаемый - тот, где путь выполнения выражен простыми для понимания конструкциями вроде цикла while. А не jmp и иди разбирайся куда оно там прыгает.
johnfound Автор
15.01.2022 01:27+1Нет, вы не поняли. Я имел ввиду что ваш C++ код и мой C++ код, компилируются одинаково. Хотя и отличаются в исходниках. И они компилируются до варианта в статье – с test и использованием второго регистра (код спрятан в спойлере «Конечно, я скомпилировал этот C++ код».

lgorSL
14.01.2022 21:20+1Я попробовал написать аналогичный код на kotlin (работоспособность не проверял, он больше для иллюстрации). Благодаря elvis оператору, nullable типам и хвостовой рекурсии выглядит сильно иначе. На мой взгляд, в таком декларативном стиле получается понятнее.
tailrec fun lastFChild(n: Node): Node =
n.fChild?.let{ lastFChild(it) } ?: nfun Node.first(): Node =
prev?.first() ?: thisfun cycle(n: Node): Node =
n.next ?: n.parent?.let{ cycle(it) } ?: n.first()fun Node.findNext(): Node =
lastFChild(cycle())

auddu_k
14.01.2022 22:59Кажется, если написать на С с использованием goto получится тоже самое, что на Асм?
Не понял посыла статьи: короткие алгоритмы можно писать без ограничений структурного программирования? Ну да, можно, пока их можно одним глазом видеть. Проблемы будут на алгоритмах больших.
В общем любопытно, лайкнул бы, да
грехикарма не позволяет )johnfound Автор
14.01.2022 23:06На ассемблер можно и нужно писать сообразно идеи структурного программирования. Структурное программирование далеко не заключается в неиспользованием goto/jmp.
forthuser
15.01.2022 01:54Да, но при этом использование команды перехода не помогает эту структуру легко выявлять. И даже c использованием каких то отступов.
Для примера в Форт при близкой семантике представления кода в сравнении с ассемблером всё же есть:
и IF… ELSE… THEN
и BEGIN… WHILE… REPEAT
и BEGIN… UNTIL
и DO… LOOP
и CASE… OF… ENDOF… ENDCASE
…
и возможность к произвольному созданию любых «экзотических» конструкций управления средствами самого языка и в управлении данными с возможностью и изменения синтаксиса под требуемую семантику штатно средствами языка не пересобирая ядро системы.
FOR… NEXT SWITCH BREAK CONTINUE…
P.S. Даже на стандартном ассемблере для AVR примерно такое тоже возможно Конструкции структурного программирования для AT90s8515johnfound Автор
15.01.2022 03:23Вы просто путаете форму с содержанием. Все эти if-else-while, суть высокоуровневые конструкции, которым не место в ассемблере.
Но суть структурного программирования совсем в другом. Можно программировать структурно и на ассемблере. А можно писать неструктурированный код и на C++.
forthuser
15.01.2022 04:59А, такой вариант облегчающий ассемблерное программирование? Дополнительные команды ассемблера2
Из этого проекта для AVR
И статья Машина времени для крошек.
P.S. В любом случае при использовании в большой программе ассемблера программист старается формализовать в какой то степени и возможности по его эффективному использованию с точки зрения своих трудозатрат на написание кода на нём и дальнейшего его понимания.
У меня достаточно личного опыта использования ассемблера в программировании на них, чтобы сформировался определённый взгляд на его счёт. ????
Даже когда делал эмулятор PDP-11 процессора на x86 ассемблере и то от связки его с Форт не отказался.
forthuser
15.01.2022 05:45Вы просто путаете форму с содержанием.
Мне понятна фраза о чём в ней говорится, но особо «тонких» и эффективных способов использования команд доступных в том или ином процессоре может и не потребоваться, хотя для себя нашёл «пару» моментов построения нетривиального ассемблерного кода при этом.
forthuser
15.01.2022 13:30Можно программировать структурно и на ассемблере.
Сложно, не используя комманды структурного перехода, а GOTO остаться в рамках «ограничений» структурного программирования.
В этом аспекте рассмотрения можно сказать, что и Дракон язык схем сделан «структурным» при ограничениях его применения.
P.S. Кстати, по возможностям изменения эргономики мнемоник ассемблерных команд показателен случай из программы AB (Algorithm Builder 5.44) для AVR Описание ассемблер мнемомик AB программы
Учебник по работе с АВ
Топик на форуме vrtp.ru пользователей данной программы:
Algorithm Builder for AVR, Начинаем
Сам автор программы, не найдя ей коммерческое развитие сделал её бесплатной и не стал продолжать развитие идеи в рамках ARM архитектуры.

qw1
15.01.2022 14:15Но суть структурного программирования совсем в другом. Можно программировать структурно и на ассемблере
Из текста программы будет сложно извлечь структуру. Ведь структурное программирование — это использование вложенных друг в друга блоков типа «последовательность», «ветвление», «итерация». Языки высокого уровня эти блоки естественно отображают отступами, а на ассемблере границы и вложенность блоков никак нельзя понять, не читая весь код от начала до конца.johnfound Автор
15.01.2022 16:23Ассемблер читается очень и очень не так как ЯВУ. Отступы конечно можно использовать, некоторые так и делают. Но лучше всё-таки читать по ассемблерному – по вертикали и аккордами, а не отдельными инструкциями. Тогда и вложенность отличается прекрасно.
qw1
15.01.2022 18:19Например, по условному переходу не видно даже, вверх он идёт или вниз.
А если вниз, что это за структура — ветвление (переход на else) или итерация (переход на конец цикла как часть условия while).johnfound Автор
15.01.2022 18:32-1Очень даже хорошо видно, если ограничить переходы в пределах страницы текста. А это кстати одна из хороших практик в ассемблере. Если надо прыгать дальше, значит нужно написать по другому.
Правильные имена меток тоже помогают лучше проследить структуру.
auddu_k
15.01.2022 10:35Тогда предложенный код можно на С написать так же как на АСМ и не факт, что будет менее понятно.
Короче для меня пока тезис не доказан :-)

Sayonji
15.01.2022 04:58+2А вы про язык или про один пример? А то давайте сразу к быстрой сортировке перейдём. Представляю если б мне пришлось это без комментариев читать, или ещё хуже - баг там искать.
Тот факт, что у вас названия переменных фиксированы (эах, оух, ...) уже делает любую нетривиальную программу нечитаемой (по сравнению с языком более высокого уровня).

Refridgerator
15.01.2022 10:35названия переменных фиксированы (эах, оух, ...)
Это скорее издержки IDE, которые для ассемблера от примитивного текстового редактора ничем не отличаются. В Visual Studio для MASM даже подсветки синтаксиса нет! Не говоря уже о сворачивании частей кода (аналог #region в шарпе). Я писал для этого расширение, которое в том числе позволяло привязывать к регистрам вменяемые имена (в виде всплывающих подсказок), и в идеале их вполне возможно отображать непосредственно в листинге.
johnfound Автор
15.01.2022 11:50+6Тот факт, что у вас названия переменных фиксированы
Не надо рассуждать о регистрах как о переменных. Они такими не являются. Переменные в ассемблере, находятся в памятью и имеют нормальные имена. А регистры, это регистры – ресурс которого просто нет в высокоуровневых языков.
forthuser
15.01.2022 13:43+1А регистры, это регистры – ресурс которого просто нет в высокоуровневых языков.
Изначально предполагалось, что в Си будет к ним определённый доступ по ключевому слову их расположения register, но это так и осталось только задекларированной, но не поддержанной возможностью в Си компиляторах, а также могли бы быть добавлены команды непосредственно присутствующие в процессоре, как теже сдвиги по непосредственной работе с ними.
И язык Си по части своих возможостей стал бы похожим на существующий и сейчас проект С-- языка. ????
P.S. И непосредственного доступа к стеку процессора нет в высокоуровневом языке, если не ввести, как в Форт, непосредственно доступ к управлению им и дополнительного стека оперирования данными вместо необходимости использования непосредственных регистров процессора в явной форме.
Kotofay
16.01.2022 18:52В Turbo C register вполне размещал переменную в регистр.
Но если переменная использовалась не как регистровая, например брался её адрес, то она размещалась в памяти.

qw1
17.01.2022 14:11Тут речь о том, что ключевое слово
registerигнорируется компиляторами. Вы не проверяли, какой код сгенерирует Turbo C без словаregister? Все обычные компиляторы так же по возможности поместят переменную в регистр. То есть, что есть это слово, что нет его, на кодогенерацию никак не влияет.
qw1
15.01.2022 14:07То есть, для повышения читаемости вы предлагаете писать код в стиле gcc -O0, если надо изменить переменную, надо её прочитать из памяти (используя символьную метку, чтобы видеть название переменной), модифицировать, записать в память. А больше чем на 1 операцию держать в регистрах не рекомендуется, чтобы человек, читающий код, не напрягал себя запоминанием соответствий регистров и переменных.
johnfound Автор
15.01.2022 16:16Конечно нет. Я такое не писал. Опять повторяю, регистры (да и стек тоже) это ресурс, которого нет в языках высокого уровня. И поэтому нельзя рассматривать их с высокоуровневой точки зрения. Ничего не получится.
Вообще, тема о удобочитаемости ассемблерного кода и вообще структурного программирования на ассемблере очень длинная и непростая. В этой статье я рассматриваю микроскопическую долю этой темы. Может быть напишу отдельную статью, где рассмотрю все это более обобщенно.
qw1
15.01.2022 18:22Тогда вернёмся на сообщение выше. В computer science, в алгоритмах, есть такая абстракция, как переменная. Она соответствует регистру, или нет? Если да, как узнать, какому регистру соответствует какая переменная в некотором участке кода?
johnfound Автор
15.01.2022 18:33Она соответствует регистру, или нет?
Нет.
qw1
15.01.2022 19:27Вы же писали
Переменные в ассемблере, находятся в памятью и имеют нормальные имена
Как в соответствии с этим реализовать, например, алгоритм Евклида с переменными a и b
Чему в ассемблере соответствует переменная a? Регистру, адресу в памяти?while (a != b) { if (a > b) a = a - b else b = b - a; }johnfound Автор
16.01.2022 13:41Как в соответствии с этим реализовать, например, алгоритм Евклида с переменными a и b
А зачем нужно это ограничение «с переменными a и b»? Правильный вопрос будет «Как реализовать алгоритм Евклида?»
qw1
17.01.2022 14:15Когда вы будете обдумывать реализацию алгоритма, или объяснять его кому-то, вы как будете называть объекты «a» и «b»?
go-prolog
16.01.2022 17:46+1Любопытно, а как Эвклид представлял переменные и поток команд в своем алгоритме.
Может не переменные, а парметры/неизвестные:
gcd(A,A)->A;
gcd(A,B)when A>B ->gcd(A-B,B);
gcd(A,B)->gcd(B,A).


vasyakolobok77
15.01.2022 15:33Не холивара ради, но вот такой вопрос: а для arm-процессоров будете повторно такой код писать? Поскольку набор команд и подходы написания кода для arm совсем другие. Или же ОС-независимый GUI не включает ОС под arm?
К чему это я – если вам нравится хардкор и оттачивание до мелочей, не эффективней ли писать на C (т.е. даже не плюсах)?
0x4eadac43
16.01.2022 19:03Можно и на плюсах написать такой же рекурсивный читабельный алгоритм, повторяющий указанный в статье один к одному: https://godbolt.org/z/nEcWE73Eo. (Рассматривается лишь случай с одним корнем. Функция find_leaf была заинлайнена.) Естественно, компилятор не заставишь использовать единственный регистр (но зачем?).
Node * find_next(Node * node) { assert(node); if (node->next) return find_leaf(node->next); if (node->parent) return find_next(node->parent); return find_leaf(node); } Node * find_leaf(Node * node) { if (node->first) return find_leaf(node->first); return node; }johnfound Автор
16.01.2022 19:12Ну-у-у, а зачем вообще рекурсивно??? Нерекурсивный алгоритм в случае намного и читабельнее и компактнее.
0x4eadac43
17.01.2022 00:33Читабельность - субъективная штука. Мне вот проще рекурсивный вариант воспринимать.
Реализовал для интереса компактный вариант с циклом: https://godbolt.org/z/4fPhnThMG. С точки зрения компилятора не изменилось ничего (тот же самый скомпилированный код). Забавно
qw1
17.01.2022 14:19Это удивительно. Две рекурсивные функции компилятор сложил в одну большую нерекурсивную.
Kotofay
Компилятор делает более оптимально, минимизируя циклы обращения к RAM.
johnfound Автор
Статья о удобочитаемости, а не о эффективности кода.
Хотя, все эти данные находятся в кеше, так что какой из вариантов будет быстрее, это далеко не простой вопрос. Здесь могут вмешаться и механизмы предсказания переходов.
Но опять – статья о читаемости и понятности, а не о производительности.
Kotofay
Кэш не регистр, быстрее быть не может априори.
А мне всегда казалось, что чистый ассемблер это не про удобочитаемость.
Тут, думаю, будут удобнее макрокоманды ассемблерные а не чистый код.