
В статье рассмотрим полезный инструмент облегчающий сбор данных с сетевых устройств. Для работы скриптов с командной строкой по SSH на языке Python нужно использовать множество сторонних модулей, а вернее множество зависимостей одного модуля (привет paramiko), а если на машине где будет работать скрипт нет интернета или нет возможности установить Python последних версий, то задача запуска скрипта становится практически невозможной. Для решения подобной проблемы был разработан SSH Picker с возможностью подключения дополнительных модулей через AMQP протокол.

Есть различные способы взаимодействия с сетевыми узлами, самый востребованный из которых это command-line interface (CLI) посредствам протокола SSH. В сетях операторского класса с огромным количество устройств на сети часто возникает необходимость собрать различные выводы команд с сетевых устройств, обработать и представить в определенном виде. Несмотря на наличие различных OSS которые должны позволять выполнять подобные задачи очень быстро, обычному сетевому инженеру будет намного проще выполнить сбор данных самостоятельно к примеру запустив скрипт в SecureCRT или какой-либо заранее подготовленный скрипт на Python/TCL.
Для запуска подобного скрипта, должна быть основа в виде кода для подключения к узлу, отправки команды на узел и получения результата выполнения команды с узла, затем данные нужно куда-то сложить или сразу обработать. Так же бывают ситуации когда данные нужно собирать на протяжении некоторого промежутка времени или на постоянной основе. Множество OSS систем реализовывают данные методы сбора через периодическое подключение и отключения к узлу, что сильно засоряет логи оборудования т.к. в них отображается каждый вход\выход пользователя.
SSH Picker модульный сборщик данных с сетевых узлов, позволяющий работать в разных режимах и подключать внешние парсеры для последующей обработки данных.
Описание сборщика
SSH Picker состоит из двух обязательных частей. Конфигурационный файл в формате toml и списка команд в обычном текстовом виде. Стоит сразу отметить, что использовать протокол telnet коллектор не умеет, поскольку данный функционал изначально не закладывался в него. Аутентификация по SSH выполняется через связку логин/пароль либо с использованием публичного ключа.
Коллектор может работать в следующих режимах:
Единоразовое выполнение команд на узле.
В этом режиме сборщик подключится к узлу, выполнит команду, получит результат и отправит его в указанное место, отключится от узла закрыв при этом SSH сессию. Это удобно в случае использования коллектора совместно с кроном.
Постоянное подключение
Постоянно находится на узле и периодически выполняет заданные команды. В данном режиме коллектор работает как автономный сервис. Он единожды подключается к узлу и держит SSH сессию постоянно открытой. В случае разрыва соединения, подключение перезапускается самостоятельно с увеличением интервала переподключения в случае неуспешности. Отвечает за этот режим параметр конфигурации:
[common]
# If true, then script will not connect and disconnect every 5-10 minutes.
# It will stay constantly on the nodes.
stay_on_node = true
На анимации представлено как работает режим постоянного подключения
Специальный поток Session Controller (SC) мониторит статусы каждого SSH подключения и в случае возникновения проблем с любым из них SC перезапускает его.
Скачивание файла с узла с помощь SCP
Полезно при необходимости выгрузить одинаковые файлы с множества устройств.
Отправлять полученные результаты по HTTP, SFTP, TCP/UDP socket, AMQP брокеру и складывать файлы локально. Все выходные данные представлены в формате json.
Коллектор имеет возможность указать профиль оборудования, указав для него свой default command line иначе как prompt. Всем знакомые user и privilege mode в Cisco и shell mode в Juniper. Изначально было 4 профиля, но так исторически сложилось, что одного профиля оказалось достаточно, остался универсальный профиль Router.
Хотелось бы обратить внимание на процес получения данных от узла. Коллектор должен понять, что команда выполнилась и сохранить полученные данные для дальнейшей обработки. Как коллектор понимает, что команда выполнилась? Думаю многие сталкивались с ситуацией когда после ввода команды, узел подвисает собирая данные, а затем выводит информацию на экран, так вот коллектор ждет вывода команды не закрывая сокет до тех пор пока не получит весь вывод. Но как коллектор поймет, что это весь вывод? Весь вывод или не весь он понимает на основе состояния command line.
Пример конфигурации коллектора:
[Profiles]
[Profiles."Router"]
name = "Router"
unenable_prompt = ">"
enable_prompt = "#"
[devices]
[devices."10.222.0.1"]
Hostname = "labRouter1"
Ip = "10.222.0.1"
User = "admin"
Port = 22
Password = "adminpass"
Profile = "Router"Пример enable promptа самого узла
labRouter1#
Происходит склеивание параметров Hostname + enable_prompt получаем device_prompt. Полученный результат отдается в regexp ^device_prompt $ и каждая получаемая строка сравнивается с этим регулярным выражением. Как только есть сопадение, то команда закончила выполняться и можно отправлять следующую.
Возможность работы сборщика с внешними парсерами
Пожалуй это самый полезный функционал.
Вам необходимо собрать данные с узла, но через SNMP или Netconf их получить нет возможности, получить их можно только если выполнить серию команд на узле, при этом каждая последующая команда зависит от данных из предыдущей команды и т.д. К примеру нужно получить данные по дропам на фабрике с определнных линейных карт и эти данные нельзя получить иначе кроме как через CLI.
Алгоритм действий будет такой:
Получаем список линейных карт с узла (
show chassisилиshow hardware)Выбираем из них только те слоты где стоит нужная нам линейная карта, запоминаем слоты (к примеру слоты 1,4,6,10)
Для каждого слота выполняем команды для отображения счетчков по фабрик-дропам.
Пример команд:
show card 1 fabric-drops
show card 4 fabric-drops
show card 6 fabric-drops
show card 10 fabric-dropsт.е. в этом случае нам нужно не просто выполнить одну команду на узле и получить ее вывод, но еще и распарсить полученный вывод и на его основе составить новую команду, а затем отправить ее заново коллектору и получить уже новый данные по отправленным командам.
Для реализации подобного сценария работы сильно помогает AMQP брокер в моем случае это RabbitMQ. На серверах не всегда можно установить RabbitMQ, но его можно использовать в контейнере или вообще на другой машине.
В конфигурации коллектора включаем функционал обеспечивающий обработку входящих команд и указываем его параметры.
[inbound_commands]
enable = true
socket = "amqp://guest:guest@localhost:5672/"
exchange_name = "inbound"
routing_key = "commands"
timer = 10000далее убеждаемся, что включена отправка выводов команд в RabbitMQ
[parser."global"]
enable = true
amqp_exchange_name = "printouts"
[parser."chassis"]
enable = true
key = "show\\schassis"
uniq = "show_chassis"
socket = "amqp://guest:guest@localhost:5672/"Ниже показана схема работы коллектора когда включена возможность обработки входящих команд.
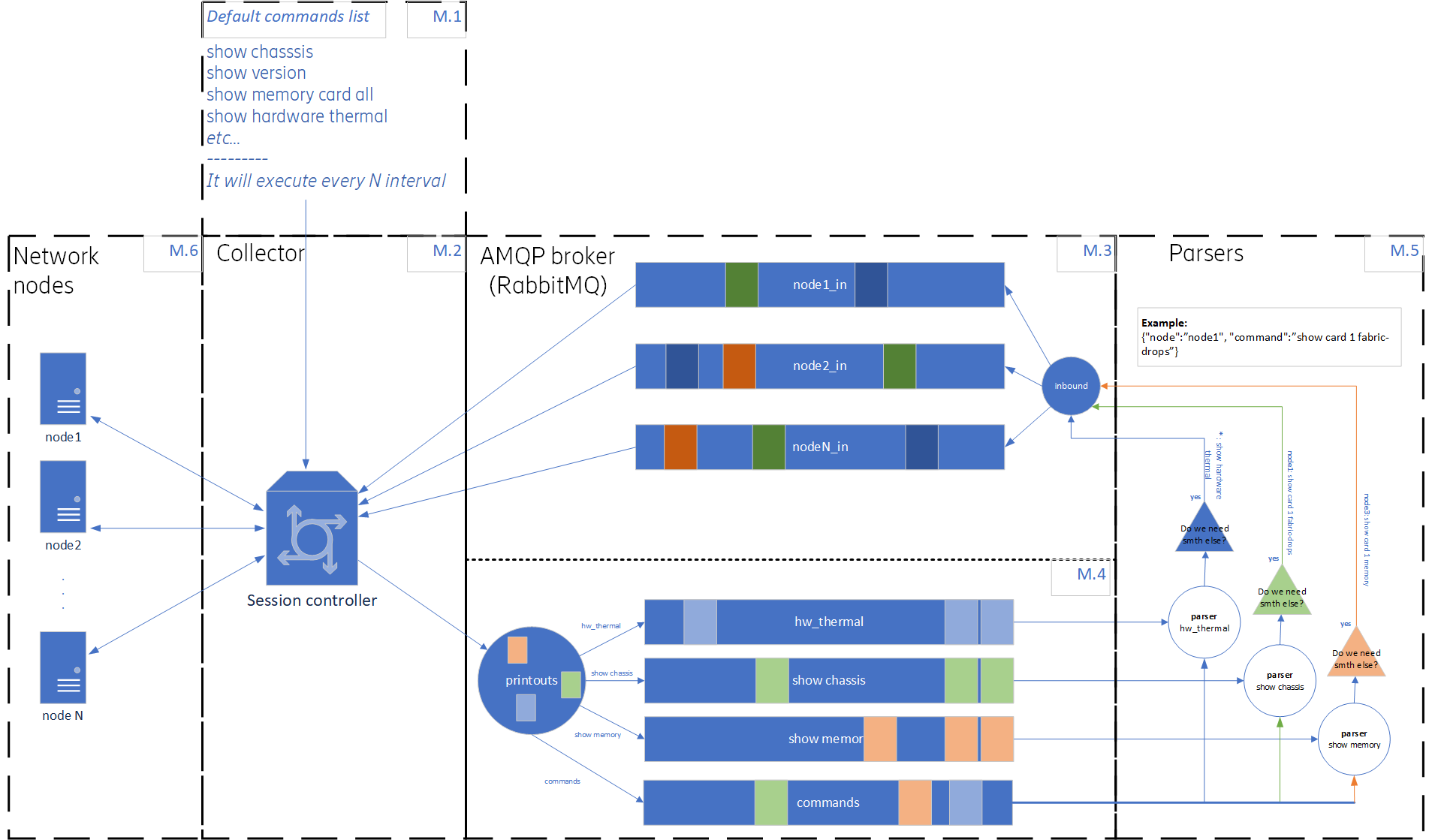
Каждый блок имеет свой номер М.1, М.2. и т.д. Опишу подробнее каждый из них.
М.1 – это обязательный список команд который прописывается в файле и передается коллектору при его запуске.
М.2 – это сам коллектор, в случае обработки входящих команд он должен работать только в режиме постоянно открытой SSH сессии. Коллектор принимает список команд из М.1 и выполняет их на узле с заданной периодичностью. Так же коллектор подключается к AMQP брокеру и создает очереди и точки обмена указанные в М.3 и М.4. Они нужны для отправки и получения данных с узлов.
М.3 – это входящие очереди и точка обмена созданные коллектором в RabbitMQ для каждого узла отдельная очередь.
М.4 – это исходящие очереди и точка обмена созданные коллектором в RabbitMQ для каждой команды отдельная очередь.
М.5 – это внешние парсеры, те самые скрипты которые будут принимать выводы команд от М.4 парсить их и создавать новую команду, которую нужно дополнительно выполнить на узле. Парсеры отправляют команды в очереди в М.3. Парсеры могут быть написаны на любимом вами языке с поддержкой AMQP протокола. В репозитории есть папка example где можно найти пример парсера на Python.
М.6 – это сетевые узлы с которыми работает коллектор.
Подробнее опишу, как будет происходить работа коллектора в случае если нужно обрабатывать серии команд.
У нас есть М.1 со списком изначальных команд который выполняется на узле с указанным интервалом. Интервал указывается в конфигуарации в параметре interval. Keepalive это интервал через который нужно отправить пустую команду для того, чтобы сессия “жила” вечно.
# Send dumb_command every keepalive
# Seconds
interval = 300
keepalive = 100
dumb_command = "!dump command"Далее, коллектор подключается к AMQP брокеру и создает exchange point и очереди, связывает их по указанным в конфигурации ключам это блоки М.3 и М.4. Затем коллектор выполняет команды на узлах, получает вывод команд и в формате json отправляет их в AMQP. Формат выходного сообщения следующий:
{
"command": "выполненная команда",
"ip": "IP адрес узла",
"nodename": "Hostname узла",
"output":"Результат выполнения команды",
"timestamp":"unixtimestamp"
}В блоке М.5 парсеры получают каждый свой вывод команды, парсит его и если нужно собрать дополнительный вывод, то формирует команду и отправляет его в AMQP обратно через очереди в M.3. Формат сообщения:
{
"node": "node1",
"command": "show card 1 fabric-drops"
}Коллектор получает данные с очередей из блока М.3, выполняет команды на узле и результат выполнения отправляет в AMQP через routing key “commands” (указывается в конфигурации) и соответсвующую ей очередь. Парсеры получают данные из очереди “commands” и если команда относится к парсеру который отправил эту команду, он подтверждает ее удаление из очереди. На этом цикл может повторится при необходимости.
Используя этот механизм можно создавать сценарии для траблшутинга или автоматической проверки каких-либо значений на узлах.
Компиляция и запуск сборщика
Коллектор написан на Go и это позволяет создать один исполняемый файл который будет содержать в себе все необходимые модули, таким образом скомпилированный файл можно использовать на системах где нет возможности устанавливать дополнительные модули вместе с их зависимостями. Более того коллектор можно запустить на Windows машине, но надо понимать, что возможны проблемы с TCP/UDP сокетами т.к. их работа в Windows и Linux системах различная. В случае использования AMQP проблем не наблюдалось.
Установка ENV переменных при компиляции для Linux будучи не на Linux, а к примеру в Windows
set GOOS=linux
set GOARCH=amd64Установка ENV переменных при компиляции для Windows будучи не на Windows, а к примеру в Linux
export GOOS=windows
export GOARCH=amd64 Клонируем репозиторий к себе на компьютер, затем нужно дать права на выполнение скрипту build.sh и запустить его , он все соберет в единый бинарный файлик. Внести необходимые изменения в config.tml и запустить сборщик.
chmod +x build.sh
./build.sh
./collector_2.3 ./config.tmlПослесловие
Я не профессиональный программист. Проект начинал создавать когда в Go не разбирался и создавал его для ухода от скриптов на Python. После этого уже прошло 4 года в течении которых были пройдены курсы программирования, прочитаны умные книжки по архитектуре проектов и написан не один проект на Go. Все на личном энтузиазме для автоматизации рутинных задач. Я понимаю, что код ужасный, но если проект кому-либо будет интересен, то я с радостью сделаю его рефакторинг во благо общества.
Всем спасибо за уделенное время!
Полезные ссылки
Комментарии (5)

SkyRE
24.01.2022 13:18RANCID не?
alexvangog Автор
25.01.2022 12:36RANCID хороший инструмент, но он все-таки предназначен для сравнения конфигов (и все что с этим связано), а не для обработки серии команд.
tdemin
Это все точно нельзя было сделать посредством сборки фактов (модуль setup) в Ansible?
skymal4ik
Такая же мысль была в голове. Причём можно использовать raw модуль для каких-то особенных кейсов и не переизобретать велосипед.
RoutePrint
Ну так Ansuble, точно так же как и доп. модули для Python, устанавливать нужно. Автор же предлагает использовать исполняемый файл для управляющего хоста без инета