
Базы нешуточные: две базы, в каждой по 180ТБ. В них сливаются данные из многих других, непостгресовых баз. А этими, огромными напрямую пользуются аналитики компании, и эта деятельность критически важная. ZFS сжала эти базы в два раза — теперь каждая занимает на диске по 90 ТБ, железу бы вздохнуть с облегчением. А стало только хуже. Пригласили наших сотрудников из поддержи, они провели аудит. Случай нам показался интересным, и мы решили о нём рассказать. Заодно напомнив о средствах диагностики.
Набор инструментов
Для этого у нас используют обычно набор опенсорсных и своих утилит. Свой скрипт
pg_diagdump.sh (по просьбе клиента его можно загрузить), выполняющий подкоманды perf для формирования файлов с данными семплирования. А на основе полученной информации мы формируем уже наглядную картинку в FlameGraph.Скрипт умеет получать:
- статистику производительности процессов СУБД PostgreSQL с помощью perf
- stacktrace процессов СУБД PostgreSQL и взятые ими блокировки
- core dump процессов СУБД PostgreSQL с помощью gcore
- информацию из pg_stat_statements, pg_stat_activity, pg_stat_all_tables
Кроме того в базу устанавливается либо опенсорсная утилита pg_profile, либо её разновидность с расширенной функциональностью PWR (pgpro_pwr), когда это вписывается в политику клиента (Андрей Зубков — автор обеих версий). Она заглядывает в системные представления — pg_stat_statesments и во многие другие, умеет работать с pg_stat_kcache. Она делает снимки текущей статистики через настраиваемые промежутки времени (допустим, полчаса), агрегирует данные, которые выводятся в отчёты. В них много разделов.
Масштабы бедствия
Самые жуткие цифры были в разделе Vacuum-related statistics:
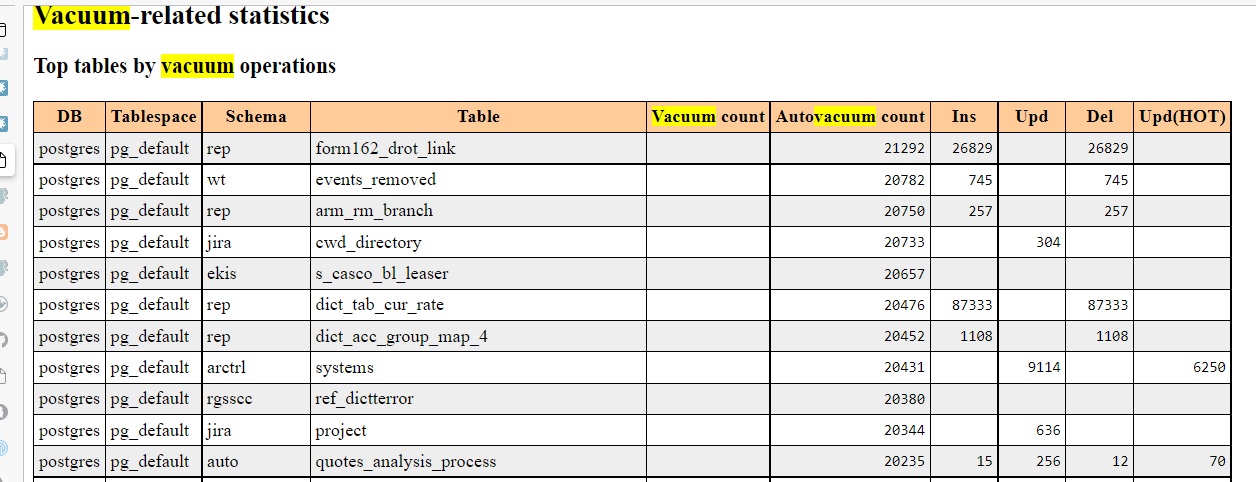
Ежедневно процесс autovacuum обрабатывает некоторые таблицы более 20 тысяч раз за сутки! (интервалы сбора данных задаются, в данном случае агрегировались данные за полдня). При этом наблюдается достижение пикового значения количества процессов автоматической очистки. Среди процессов автовакуума можно было увидеть немало процессов, помеченных
to prevent wraparound. Что за метка и с чем её едят — тут советуем начать с основательной статьи Егора Рогова Автоочистка (она же autovacuum); можно ещё почитать, скажем, здесь — где эта метка как раз упоминается. А в документации об этом тут.Настройки автовакуума были довольно необычны: параметр
autovacuum_max_workers, который ограничивает параллельную работу процессов автовакуума, выставлен в 50. По умолчанию он равен 3. Его иногда докручивают до, скажем, 10, но 50 — такого моим коллегам встречать не приходилось. Но и эти 50 были израсходованы: в представлении pg_stat_progress_vacuum максимальное кол-во строк было 50. Кстати, в отчётах pg_profile есть раздел Cluster settings during the report interval, который показывает и значение параметра autovacuum_max_workers.Это очевидная патология. Но ужасы автовакуума не причина, а симптом. Надо было искать долгоиграющие транзакции, понять из-за чего они стали долгоиграющими — а там видно будет. Долгоиграющие незавершённые транзакции не дают автовакууму вычистить «старые» данные, поэтому ему приходится предпринимать попытки вновь и вновь, так как максимальное количество «мусора» для таблицы по-прежнему выше допустимого порога, который определяется несколькими параметрами, это подробно расписано в документации.
В поисках долгоиграющих транзакций
pg_profile даёт возможность увидеть среднее время выполнения запроса из секции Top SQL by execution time.

Кликнув ссылку в отчёте, можно увидеть полный текст запроса. Параметры, правда, мы не увидим. Например, WHERE x=1 и WHERE x=2 будут представлены как WHERE х=$1 — в таком виде они доступны в представлении
pg_stat_statements. И это к лучшему, иначе была бы каша из запросов.А вот как ищутся долгоиграющие транзакции не в среднем, а в конкретный момент:
SELECT *
FROM pg_stat_activity
WHERE state = 'active'
ORDER BY now() – xact_start DESC NULLS LAST;Информация о них содержится в строках представления pg_stat_activity. В данном случае искали активные транзакции, то есть те, в которых запрос ещё обрабатывается. Иногда не спеша: оказалось, что некоторым, рекордным транзакциям исполнилось уже 3 дня.
По отчёту можно обнаружить и сессии с состоянием
idle in transaction, когда транзакция не завершилась и не откатила свои изменения, что не даёт автовакууму вычистить устаревшие строки в таблице и в соответствующем индексе.Найти их можно аналогичным запросом:
SELECT *
FROM pg_stat_activity
WHERE state LIKE '%idle%'
ORDER BY now() – xact_start DESC NULLS LAST;Среди этих транзакций тоже нашилсь висевшие часами. Теперь можно, например, проанализировать текст запроса, посмотреть какое приложение его инициировало, что-то подкорректировать, если ситуация позволяет.
Но и этим не ограничиваются возможности диагностики. Полезно понять, «где», на каком этапе, в какой функции, запрос проводит время.
Анализ с помощью
perf top и perf с визуализаций в flamegrahp навёл на функцию ядра Linux osq_lock(), которая сжирала почти 38% CPU — одна из основных причин большого потребления CPU System Time. Вот эта красивая картинка:
Функция
osq_lock фиолетового цвета. Как можно догадаться, эта функция связана с блокировками. osq это optimistic spin queue — в ядре Linux. Виновники и жертвы
Тут началось, может, самое интересное. Выходило, что PostgreSQL не виновник, а жертва. Безобразно ведёт себя функция лежащего ниже слоя — ОС.
Запуск
perf script (top, script и многие другие — подкоманды perf) показал, что взятие блокировки osq_lock происходило во время выполнения функции aggsum_add() модуля ZFS. Семейство функций aggsum_* увеличивают счётчики, когда происходит чтение или запись.Напомним, базы с 180ТБ (или 90ТБ на диске после сжатия) обслуживаются серверами архитектуры NUMA с 8 сокетами (процессорами) с суммарным числом ядер 8 x 24 = 192. Известно, что NUMA не всегда искренне дружит (или хотя бы масштабируется) с Postgres. О том, как подружить Postgres с NUMA была, например, статья Параллелизм в PostgreSQL: не сферический, не конь, не в вакууме. На этой машине все 8 процессоров на одной материнской плате, но доступ к чужой памяти всё равно на порядок медленней, чем к своей.
Чтобы понять, что происходит, наши коллеги изучили код этих функций. Вообще-то ZFS оптимизировали под NUMA-машины и придумали, грубо говоря, вот что: в помощь глобальному счётчику операций записи-чтения добавили на каждый процессор этакий вспомогательный счётчик-ведёрко (bucket), накапливающий локальные значения, а потом сливающий их глобальному начальнику. Идея, вроде бы, хорошая, но работала не слишком проворно. В результате требуются блокировки и на каждое ведёрко на местном CPU, и на глобальный счётчик. За глобальный счётчик сражаются процессы на разных CPU, и чем их больше, чем медленней каналы межпроцессорных коммуникаций, тем неторопливей и сами коммуникации, тем дольше стоять в очередях. Для любителей заглянуть в первоисточники: подробней это описано в комментариях к файлу aggsum.c. Процессоры работают вовсю, но вхолостую, а с точки зрения Postgres транзакции проводят время в праздности (
idle), и автовакуумы штурмуют таблицы и индексы раз за разом.Но хорошо, когда за кто виноват следует что делать. Самый простой способ: взять и отказаться от ZFS вообще, раз он доставляет такие хлопоты, а сжимать как-то по-другому. В Postgres Pro Enterprise, например, есть собственное сжатие — на уровне базы данных. Но такие радикальные перемены не планировались. Айтишники заказчика не были готовы отказаться от преимуществ ZFS.
ZFS это больше, чем файловая система со сжатием. Она работает по принципу COW (Copy On Write): при чтении области данных используется общая копия, в случае изменения данных создается новая копия. Её можно откатывать к предыдущим состояниям, так что можно даже обходиться без бэкапов. А масса возможностей настройки и управления. Вот статья ZFS: архитектура, особенности и отличия от других файловых систем Георгия Меликова из Mail.ru Cloud Solutions — он контрибьютор и коммитер OpenZFS и ZFS на Linux. Остаётся разбираться с комбинацией ZFS-NUMA.
Не желающие рассасываться очереди объясняли и неадекватно-активную работу автовакуума: из-за больших очередей на получение ZFS-счётчиков время выполнения запросов было гораздо больше ожидаемого, таблицы и индексы разрастались. У индексов нет карты видимости, поэтому автовакууму приходится проходить каждый блок каждого индекса. Так можно чистить сутками.
Happy End
В результате поисков по форумам и другим ресурсам удалось найти информацию: Александр Мотин из компании iXsystems (США) наблюдал такое поведение на 40-ядерной машине под FreeBSD и сделал патч, который убирает лишние операции со счётчиками. Этот коммит попал в основную ветку ZFS 2.0+.
У клиента же была версия 0.8. Это не значит, что она такая старая: когда приводили к единому виду нумерацию версий ZFS и OpenZFS, пропустили единичку, а рестартовали сразу с 2.0.
Итого: клиенту посоветовали перейти на свежие версии ZFS (2.1+). Клиент последовал совету — обновил и Linux, и ZFS. Сейчас всё работает нормально, жалоб нет. Хотя, конечно, оптимизировать и настраивать непростую систему из ОС+ZFS и Postgres, можно бесконечно. Так как нюансы неисчерпаемы.
Технические подробности этой статьи помогли изложить сотрудники Postgres Professional Михаил Жилин и Пётр Петров.
Комментарии (56)

emerald_isle
24.01.2022 20:41А почему был сделан выбор в пользу ZFS, а не BTRFS, который тоже вроде как умеет в копирование при записи? Интересно, там может быть такая же проблема с NUMA? Или куча других неожиданных нюансов?

blind_oracle
25.01.2022 09:35+1Потому что БТР по сути заброшен. Красная шапка от него отказалась насколько помню. Реализации RAID5/6 там если и завезли то недавно. Ну и были кейсы с потерей данных.
Тот же ZFS в линуксе юзаю ещё со времён FUSE моделей лет 10 назад и потерь данных ни разу не было.

SabMakc
25.01.2022 10:49RedHat одновременно и от ZFS отказались )
Как понимаю, продвигают альтернативу - некий Stratis...
blind_oracle
25.01.2022 11:49За ZFS они никогда и не топили, особенно учитывая что лицензия CDDL не даёт его в ядро включить уже много лет. И не факт что эта проблема решится...
А Stratis это не файловая система, а попытка реализовать часть фич ZFS используя текущие подсистемы ядра и не только (XFS/LVM/DM/LUKS/...) и обернуть это всё удобным CLI/API

Gutt
25.01.2022 14:08+3А почему был сделан выбор в пользу ZFS, а не BTRFS
Так BTRFS вышла в production-ready дай боже года три назад, а OpenZFS (ранее -- ZFS on Linux и собственная адаптация на FreeBSD) стабильна уже больше десяти лет. И ZFS намного фичастее. Опять же, я пока не видел примеров больших (сотни и тысячи TB) разделов с BTRFS. Как она себя вести будет, чёрт её знает.

poige
25.01.2022 16:25Тот, кто знает, как жрёт RAM'у ZFS (by design, кстати говоря, не говоря уж про какой-нить dedup, упаси вас сила интернета включать его!), на сотнях и тысячах терабайт её запускать не будет. А тот, кто запустит, узнает. )
Как ни странно, факт останется фактом — нормальной CoW до сих пор нет. И по факту, да, гонять базу на них, это про удобство, но не про оптимальность, потому что дублирование логики просто чудовищное получается — версионность, например, будет и у базы, и у файловой системы. Понятно, что это гибко и удобно. Но если вам нужно выжать максимум из железки, вы этим заниматься не должны по определению.
Gutt
25.01.2022 18:17О, ну ZFS -- это вообще не про производительность. Во всяком случае на куче мелких файлов. Я в 2013, выбирая ФС под хранилище Zoneminder (он тогда видео хранил в виде отдельного JPEG'а на каждый кадр), погонял разные варианты и ужаснулся тому, насколько же ZFS on Linux тормозной на этом сценарии. Выиграл ReiserFS (правда, через пару лет пришлось сменить на EXT4 с отключённым журналом, потому что ReiserFS стала нестабильной на Ubuntu).
poige
26.01.2022 07:02+2Не всё так однозначно. Просто CoW имеют свою специфику, её нужно понимать, и знать, где они хороши, а где — так себе. В частности, они уменьшают seek'и при записи, что для HDD просто прекрасно. Но это не решает проблему seek'ов при чтении, конечно же, а фрагментация растёт быстро, и неумолимо. И это не единственная проблема, конечно.

pansa
25.01.2022 18:17+2$ zpool list NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT storage 300T 286T 13.7T - - 56% 95% 1.00x ONLINE -И таких хостов много. И, поверьте, легко потянет и петабайт. Головой просто надо пользоваться - и будет ок.
А (бесплатных) альтернатив у ZFS просто нет. Какой бы она ни была. Ну вот такова реальность.
poige
25.01.2022 19:43-1бгг. Мне тут особенно колонка FRAG нравится. А пул-то, ведь, не такой уж и старый, да? А дефрага нет, и не будет. Ну и забивка 95 % слабо стыкуется с лозунгом дружбы с головой. В большинстве случаев те, кто дружат с головой, ставят на такие (и бОльшие) объёмы CEPH. Прочие же только думают, что дружат. )
pansa
25.01.2022 21:52+2Мне тут особенно колонка FRAG нравится. А пул-то, ведь, не такой уж и старый, да? А дефрага нет, и не будет.
Здорово, что вам нравится FRAG ! Я думаю, это отличный повод почитать, что же она таки означает ;-)
А байки-бабайки про фрагментацию оставьте детей пугать. Ах, да, там же дальше еще байка-бабайка про 95% заполненного пула... Ну давайте.
Ну и забивка 95 % слабо стыкуется с лозунгом дружбы с головой.
Слабо стыкуется только воинствующее незнание и работа сложных систем. А еще вера в байки, астрологию, арбидол и тп =)
ставят на такие (и бОльшие) объёмы CEPH.
Сравнивать тёплое и мягкое - очень весело и забавно, но, если не возражаете, мы с вами на этом завершим.
poige
25.01.2022 20:02И, поверьте, легко потянет и петабайт.
Дался вам этот петабайт — вот система (у того же Мотина, кстати), где таких петабайтов 20, и 1248 дисков в одном пуле: "… This particular system is about capacity -- ~20PiB raw on 1248 disks in one ZFS pool. …".
Посчитаем, сколько должно быть RAM для обслуживания такого пула, если исходить из правила «1 TB дискача — 1 GB рамы» — ?
Посчитаем! Для массива с 1 PiB (сырых) — 1 TiB RAM'ы. А там, напоминаю, 20 их.

gmelikov
25.01.2022 21:25+2Нет никаких требований "Х ОЗУ на ТБ", это тот же кеш, как и в любой другой ФС. Хотите держать больше кеша - увеличиваете его. В памяти нужна только мета - отдайте ей гигабайт 10 хоть на 10 петабайт и всё.
Хотите экономить и страдать на любой ФС - задушите её по памяти, в ZFS никто вам этого не мешает сделать.
poige
26.01.2022 05:06-1Во, да, узнаю фанатов — «задушить можно, лол, любую файловую систему». Весь прикол в том, что ZFS вы задушите там, где XFS будет дышать полной грудью. )
И если кэшем файловых данных зачастую можно пренебречь, то внутренние структуры самой файловой системы, так просто из песни не выкинешь.
gmelikov
26.01.2022 09:45+1Xfs на петабайты чудесным образом работает без кеша метаданных? И её мета из lru кеша не вымывается тем же чудом?
Расскажите, пожалуйста, как без озу держать петабайты и дышать полной грудью на какой-то ФС.


rPman
24.01.2022 21:25+3как CoW файловые системы помогут с бакапами если основной ее потребитель — база данных, которую неправильно копировать на живую средствами файловой системы?
что происходит если берется снапшот CoW для файлов базы данных, postgres как то гарантирует что данные не будут потеряны?poige
24.01.2022 21:47+3у баз обычно журналы есть. Поэтому по-факту будет откат до последней консистентной «версии», с который можно дальше догонять мастер, при желании.

middle
25.01.2022 08:06Копирование на живую - это не атомарная операция, в отличии от взятия снэпшота и отката.
rPman
25.01.2022 08:24само собой, на живую вообще не рекомендуется копировать что-либо, куда идет запись, так как в результате в копии будет каша из старых и новых данных.
я говорю про то что для восстановленной из копии базы данных, если копирование было на уровне файлов — равнозначно запуску после аппаратной перезагрузки по reset, у CoW систем есть конечно бонус, защищающий данные от сбоев, но речь о вероятностях а не о гарантиях
Нормально — резервную копию базы данных делать средствами самой БД, настроив master-slave репликацию, в этом случае резервная копия будет не просто копией но и готовой к эксплуатации базой данных, и если позволяет железо, ее можно просто использовать как рабочую, пока идет восстановление основной машины.
mizhka
25.01.2022 10:23+4ZFS CoW снепшот атомарен, моментален, не вызывает деградации производительности и не требует больших расходов. Гарантии есть.
В чём плюс такой схемы с ZFS снепшотам, что можно восстановиться на любой момент времени. Выбирается точка во времени, откатывается на снепшот перед точкой, а потом добираются WAL-ы которые лежат в следующем снепшоте. И делается recovery.
А и про бекапы - снепшоты инкрементально отправляются в СРК или на реплику ZFS-а через zfs send/receive. То есть можно держать 100500 снепшотов в СРК, а на мастере хранить за последние сутки.
А вот реплика - это не совсем безкап ибо она не позволяет восстановиться на точку в прошлом. Если кто-то дропнул таблицу или зашифровал ключевые блоки, то реплика окажется также поломанной.

khajiit
25.01.2022 14:33wal_archive/wal_recieve + PITR позволяют перематывать состояние реплики, разве нет?
poige
25.01.2022 20:41Про деградацию производительности — она там изначально, by design. Просто выглядит это обычно как небольшой налог, по сравнению с non-CoW, поэтому он до поры-до времени фанатами^W энтузиастами не замечается, а потом, бац — и приходит понимание, что за всё нужно платить. )
И я понимю, почему у зэтки так много фанатов среди пользователей BSD — просто у них файловой системы нормальной никогда не было. ) UFS традиционно тормоз, вторая версия, конечно, получше, но всё же даже не EXT4, и не XFS. Хаммерфс, Дилоном запиленный, вообще мало кто помнит (а он есть). Так что не, ZFS, конечно, ничё так, местами, но высоконагруженные базы данных это не её конёк.
khajiit
26.01.2022 10:04"Места" сильно устарели, а местами просто никогда не были правдой.
poige
26.01.2022 10:42<бгг>В вашем ответе, что характерно, конкретики не просто не хватает, её там просто нет вообще. В отличие от текста по ссылке.</бгг>
khajiit
26.01.2022 10:53Ну так профактчекайте, вместо selection bias, статью.
Но это ж лень, это ж думать надо матчасть изучать. Сотни <бгг></бгг> не будут написаны! ;)
blind_oracle
25.01.2022 11:52+2Нормально — резервную копию базы данных делать средствами самой БД, настроив master-slave репликацию, в этом случае резервная копия будет не просто копией но и готовой к эксплуатации базой данных, и если позволяет железо, ее можно просто использовать как рабочую, пока идет восстановление основной машины.
Реплика это не бэкап. Если кто-то сделает `DELETE FROM table` то реплика радостно это исполнит и данных не будет нигде.
rPman
25.01.2022 13:26+2отвечу вам обоим
я отлично понимаю что такое снапшоты, юзаю их давно с btrfs, и прекрасно знаю чем чреват master-slave репликация
просто я пользуюсь ими обоими, останавливаешь slave базу, делаешь снапшот файловой файловой системы где она лежит, запускаешь базу — репликация подтягивает накопивушюся разницу (в основном время тут — остановка базы чтобы завершить транзакции), в результате у тебя бонусы инкрементальных снапшотов (а btrfs их позволяет складывать в файл и использовать потом — дико удобно) и гарантия консистенции базы для ее восстановленияpoige
25.01.2022 20:13Вы про какую базу сейчас вещаете? В случае той же InnoDB, достаточно взять Percona XtraBackup (или её MariaDB'шное подобие) и безо всяких дисковых snapshot'ов получить и консистентый полный снимок базы, и инкрементальные понаделать.
Что не означает, что нельзя на Btrfs держать. Можно. Просто это значит, что этот setup больше про удобство, чем про быстродействие базы.

andreyverbin
25.01.2022 01:36+2Не надо OLTP решение использовать для аналитики. 180Тб уже стоит запихать в приспособленное для этого решение, коих масса.

panchmp
25.01.2022 06:40+2ребята продают поддержку Postgres
странно от них ожидать рекомендацию использовать Clickhouse, Vertica, etcblind_oracle
25.01.2022 11:53Ну, тут не о них речь, а о некоем клиенте который такую схему придумал. Хотя может это они ему посоветовали, конечно...

Antohin
25.01.2022 14:04+2В первую очередь не надо БД (не так важно какую) ставить на ФС с COW. Сама БД обеспечивает консистентность путем избыточной записи на диск. Добавляем сюда файловую систему на своем уровне обеспечивающую консистентность путем добавочной нагрузки на диски. А дополнительная нагрузка должна получаться нехилая - БД постоянно меняет одни и те же блоки, ФС старательно сохраняет все их версии. Postgres дополнительно еще сверху проходится autovacuum'ом еще раз меняя блоки и заставляя ФС писать их новый версии. Стоит ли такой оверхэд удобной возможности откатиться на некий снэпшот в прошлом?
Antohin
25.01.2022 14:11Oracle не зря в свое время выпускала версию вообще без ФС - с прямым управлением дисками. БД в любом случае лучше знает что как и когда писать на диск, чем сторонний софт общего назначения.

wigneddoom
25.01.2022 16:32+1Oracle не зря и выпускают подобные документы: https://www.oracle.com/technetwork/server-storage/solaris10/config-solaris-zfs-wp-167894.pdf
Antohin
25.01.2022 17:32+1Спасибо, интересный документ, полистал с удовольствием.
Возможность сделать тестовый снэпшот рабочей базы минимальными затратами ресурсов очень привлекательна

LynXzp
25.01.2022 16:42Samsung делает свой key-value ssd c фронтом RocksDB
Antohin
25.01.2022 17:26Мой камент относился к временам древних HDD, где критично для производительности было управлять какие куда в какой последовательности блоки записать.
Контроллер SSD это еще один слой абстракции, влияющий на общую производительность, такая себе ФС на железе. В целом время записи на SSD сильно меньше чем на HDD, но у SSD временами случаются существенные просадки скорости записи (перераспределение данных в сценарии когда мы циклически пишем/стираем данные) На этот случай оракл в экзадата придумали достаточно оригинальное решение - данные параллельно пишутся на HDD и SSD, транзакция считается завершенной по факту успешной записи на тот или иной диск, какой быстрее успеет записать.
rPman
25.01.2022 19:08кстати такое поведение можно настроить на блочном устройстве linux bcache (writeback mode), очень удобно

jvmdude
25.01.2022 04:24+4>Её можно откатывать к предыдущим состояниям, так что можно даже обходиться без бэкапов
Феерично. На полуэкспериментальной FS без бэкапов. Данные должна жать и бэкапить СУБД.
На самом деле никогда не поверю, что нужно реально строить отчёты по 180ТБ. Вот прямо сразу по всем 180ТБ... Насколько знаю наша ERP (системообразующего предприятия) в несколько раз меньше занимает.

DaneSoul
25.01.2022 11:24Феерично. На полуэкспериментальной FS без бэкапов. Данные должна жать и бэкапить СУБД.
Если это база для анализа объединенной аналитики, то все данные получаются дублированы в отдельных базах и потеря этой аналитической базы может быть легко восстановлена из них. То есть исходные базы откуда сливают фактически и являются бэкапом интегрированной.Базы нешуточные: две базы, в каждой по 180ТБ. В них сливаются данные из многих других, непостгресовых баз. А этими, огромными напрямую пользуются аналитики компании, и эта деятельность критически важная.
blind_oracle
25.01.2022 11:55+3Ну, справедливости ради ZFS крайне стабилен и проблем с ним очень мало если использовать с умом. Использую его 10+ лет уже.
А аналитика по OLTP базе такого объема... да, идея сильно так себе. Кликхаус или Вертика решает с таком случае.
rPman
25.01.2022 07:23+1ZFS сжала эти базы в два раза — теперь каждая занимает на диске по 90 ТБ, железу бы вздохнуть с облегчением
А с чего бы должно стать легче?
количество независимых устройств стало меньше а нагрузка прежняя, значит средняя нагрузка на устройство — вырастает, это очень хорошо заметно на hdd дисках и когда нагрузка на базы — большая, затрагивающая сразу весь массив. С ssd так же но нагрузка, способная упереться в возможности ssd — сильная редкость.blind_oracle
25.01.2022 11:57+1Устройств там вполне могло остаться столько же, а за счёт сжатия мы уменьшаем количество IO (но это зависит от паттерна нагрузки) при этом увеличивая расходы на CPU (хоть и незначительно - LZ4 легко выдаёт гигабайты в секунду при распаковке).


mzinal
25.01.2022 12:45Долгоиграющие незавершённые транзакции не дают автовакууму вычистить «старые» данные
оказалось, что некоторым, рекордным транзакциям исполнилось уже 3 дня
сессии с состоянием idle in transaction ... Среди этих транзакций тоже нашилсь висевшие часами.Тема долгоиграющих транзакций не раскрыта.
Очевидно, это вопросы к приложениям, а не к БД.Процессоры работают вовсю, но вхолостую, а с точки зрения Postgres
транзакции проводят время в праздности (idle), и автовакуумы штурмуют
таблицы и индексы раз за разом.Ну какой же тут idle?
Это либо ожидание чтения блоков, либо ожидание свободных блоков буферного
пула, либо ожидание сброса буфера лога.И да, 180 Тбайт на PostgreSQL с аналитическими запросами... ну такое, на любителя.

Harliff
25.01.2022 12:45+1>Итого: клиенту посоветовали перейти на свежие версии ZFS (2.1+)
Заодно можно и на zstd_compress перейти.
wigneddoom
25.01.2022 15:05>Александр Мотин из компании iXsystems (США) наблюдал такое поведение на 40-ядерной машине под FreeBSD и сделал патч, который убирает лишние операции со счётчиками.
Статью только до aggsum дочитал и сразу вспомнил этот патч. Иногда полезно смотреть коммиты, issues и PR.
ya_penek
25.01.2022 18:29У меня был печальный опыт с ZFS + постгрес, база данных на 3 Тб. Вроде бы оно работает, но если запустить тяжелый запрос на несколько часов, система стабильно виснет намертво. После перезагрузки ZFS говорит, что все ОК и нормально монтируется, но база данных в хлам, постгрес вообще не запускается. Только бекапы спасали.
Глубоко копать не стали, перешли на UFS и все стало хорошо, даже по свободной памяти выиграли. Снапшотами не пользовались из-за ограничений по объему диска. Но они и не спасли бы, все равно часть транзакций потерялась бы.
Было это в 2017 году, возможно сейчас уже все починили, но пробовать еще раз смысла нет, работает - не трогай.

click0
26.01.2022 00:03К подобным статьям нужно приводить настройки тюнинга ZFS в системе и PostreSQL (для ZFS).
RealSup
Правильно понял суть, что пришлось залезть в душу сервера и всё перелопатить, а в итоге самым правильным и простым решением оказалось накатить актуальные обновления?
zloddey
Тут всё же важно сфокусироваться на правильной последовательности действий:
Залезли в душу сервера - нашли источник проблемы.
Проверили трекер ФС - нашли исправление.
Накатили исправление - получили профит.
Гораздо прискорбнее видеть, как люди в попытке исправить проблемы пытаются "сэкономить время" на шаге 1. Обновим подсистему Х! Помогло? Ой, не помогло. Обновим подсистему Y! Помогло? Ой, не помогло. И так повторять до бесконечности. Либо картинно развести руками: ох, какая сложная проблема, совсем ничего не помогает!
mizhka
Симптомы бывают одни, а реально болит в совсем другом месте. И да, много проблем решается обновлением того или иного. Но чтобы найти что обновлять (а вариантов тут может быть слишком много включая железо), придётся разобраться в деталях происходящего. На первый взгляд описание тикета ZFS не имеет ничего общего с симптомами в PostgreSQL, а вот как оно вышло.