

Всем привет! На связи Артемий, со-автор и преподаватель курсов Data Engineer, DWH Analyst.
Последние месяцы я много занимаюсь рефакторингом кодовой базы, оптимизацией процессов и расчетов в сфере Анализа Данных.
Появилось желание в формате “вредных советов” обратить внимание на набор практик и подходов, которые могут обернуться весьма неприятными последствиями, а порой и вовсе дорого обойтись Вашей компании.
В публикации Вас ожидает:
Использование
select *– всё и сразуУпотребление чрезмерного количество CTEs (common table expressions)
NOT DRY (Don’t repeat yourself) – повторение и калейдоскопический характер расчетов
Использование select * – всё и сразу
Начнем с банального – селект звёздочка. Комадна, с которой многие аналитики начинают свой путь в SQL. Спору нет – это прекрасный способ, чтобы начать исследовать таблицы, которые Вы можете видеть впервые, однако также это потенциально очень опасная практика в поставке PRODUCTION-кода.
Почему это важно?
1. С использованием сокращения select * вы теряете конкретику и прозрачность
А значит, для ответа на вопрос, используется ли здесь какой-то конкретный атрибут, придется, как минимум копнуть глубже и сделать 2-3-4 шага назад.
2. Хрупкость выстраиваемой архитектуры
Если нижележащие зависимости исходят из предположения наличия заданного набора атрибутов, то вся схема будет работать ровно до того момента, когда кто-либо как-либо не изменит этот набор. И, скорее всего, при этом он даже не будет хотеть что-то сломать.
3. Не стоит тянуть все имеющиеся колонки
Тем самым вы нивелируете преимущества Анлитических СУБД, которые хранят данные в виде колонок, не строк! Да, мы сейчас про Clickhouse, Snowflake, Redshift, BigQuery, Databricks, Greenplum и многие другие.
Просто посмотрите анимацию из документации Clickhouse:
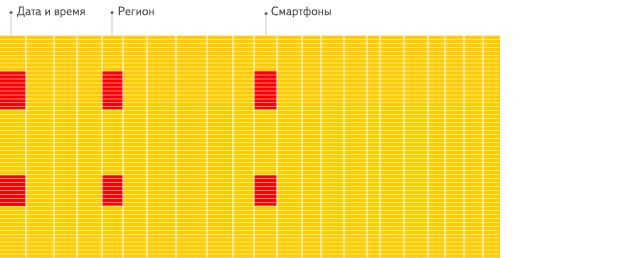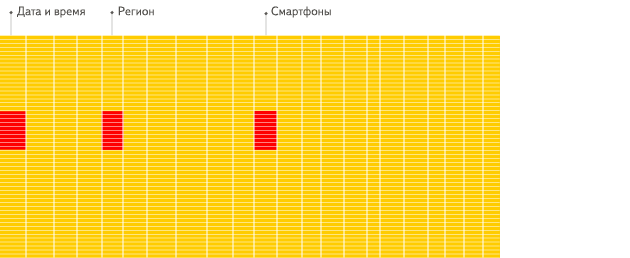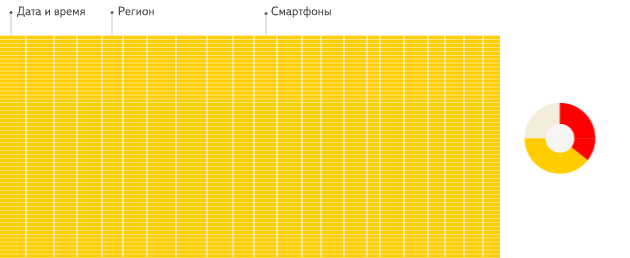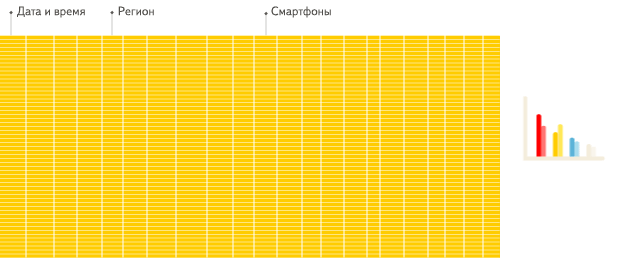
Что может пойти не так?
1. Зависимости, интеграции, BI, просто Python-скрипты могут падать с ошибкой
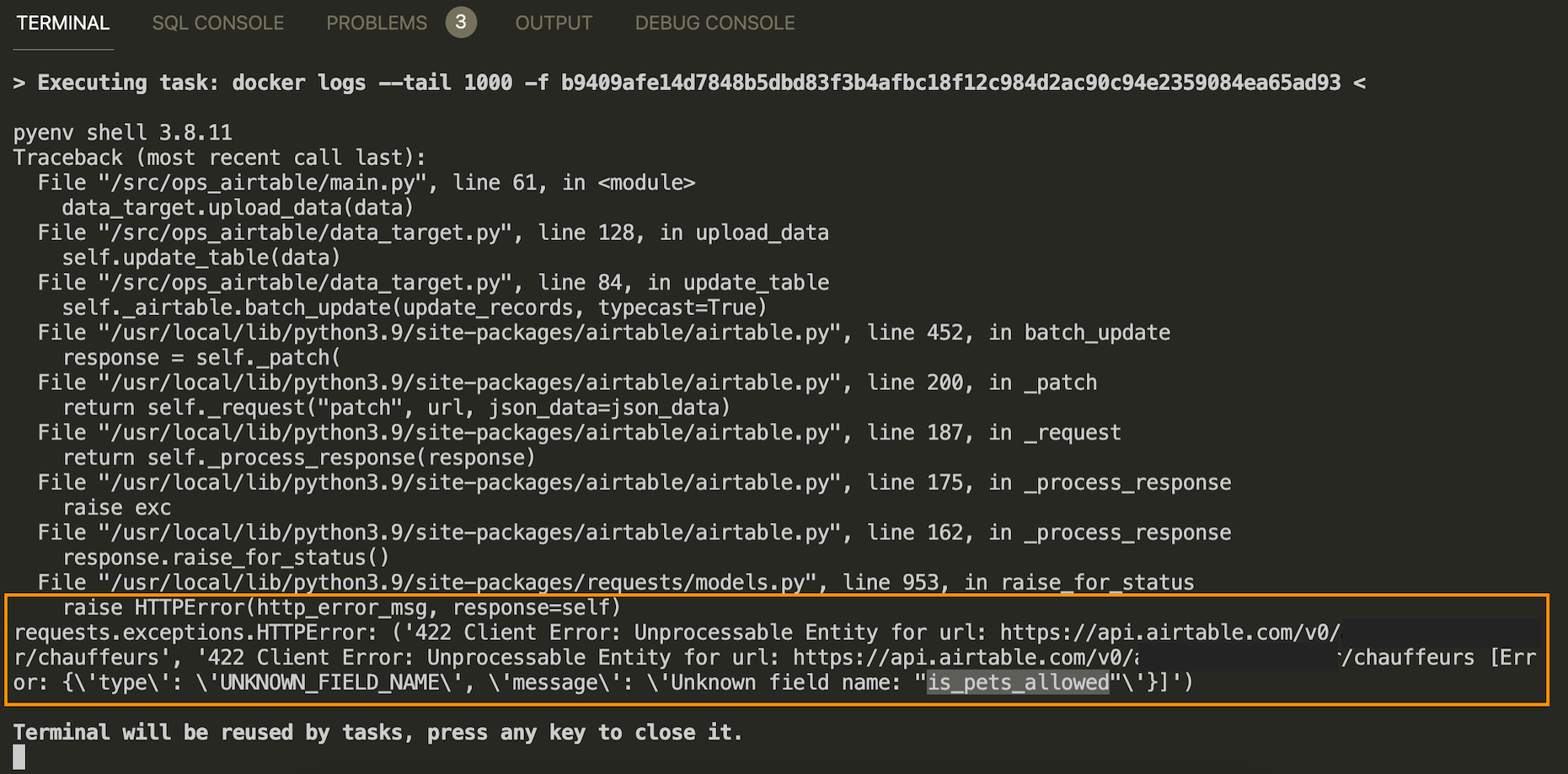
Посмотрите на интеграцию Хранилища с Airtable. Структура таблицы-приемника была однозначно зафиксирована в момент первой вставки (INSERT) и последующие записи (UPDATE + INSERT) с ранее неизвестными атрибутами возвращают ошибки.
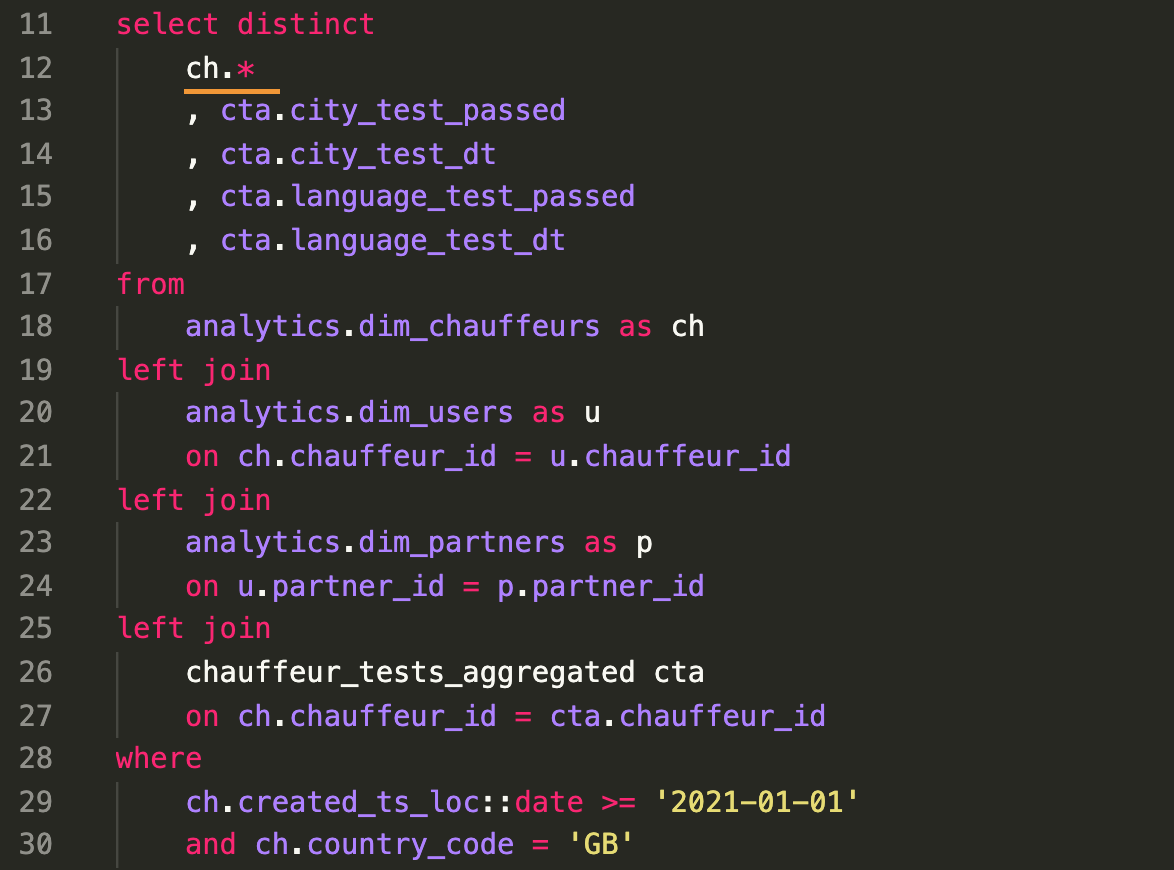
2. Появление лишней, ненужной, запретной информации там где её быть не должно
Для узкоспецилизированной задачи нет смысла выгружать полный набор атрибутов широкой таблицы-справочника. В данном случае это Chauffeur Onboarding в Airtable и большое количество колонок таблицы скорее мешает восприятию и обработке информации.
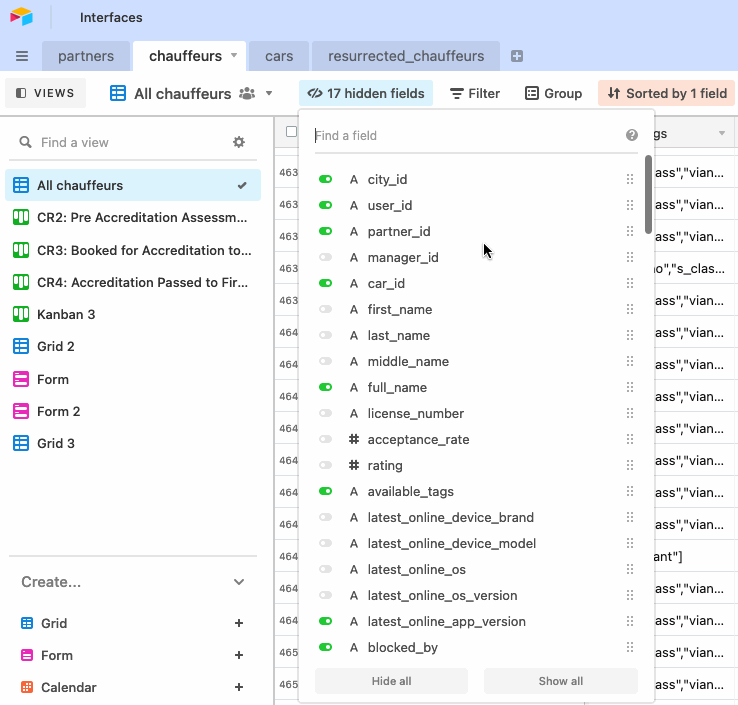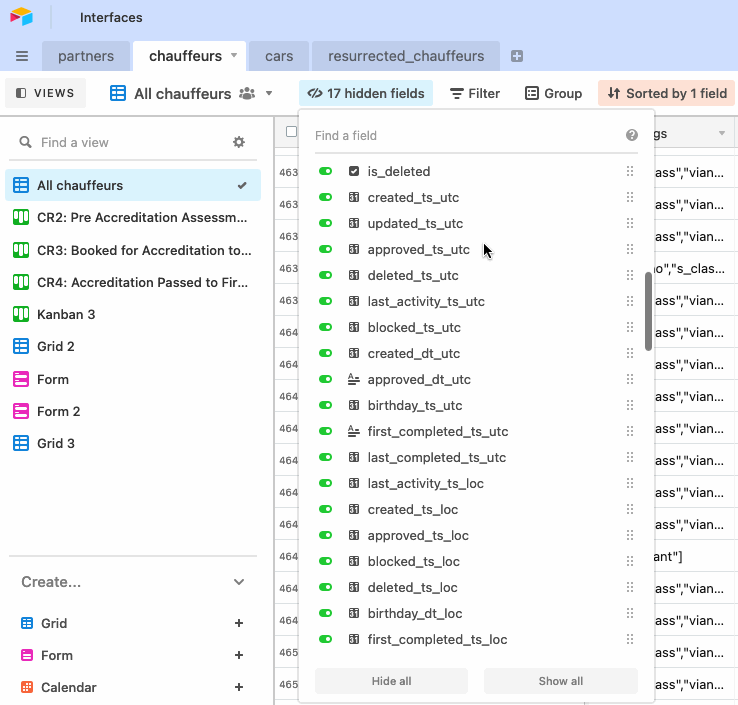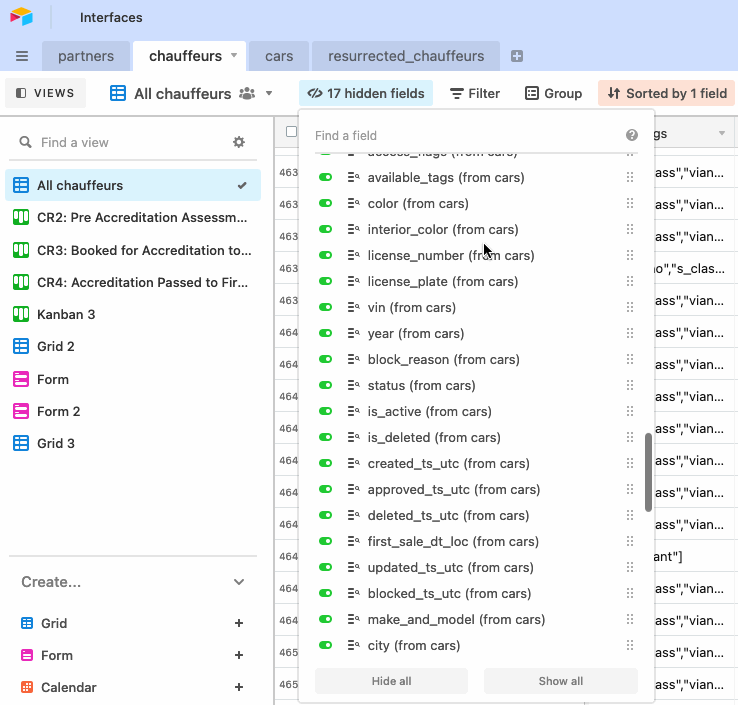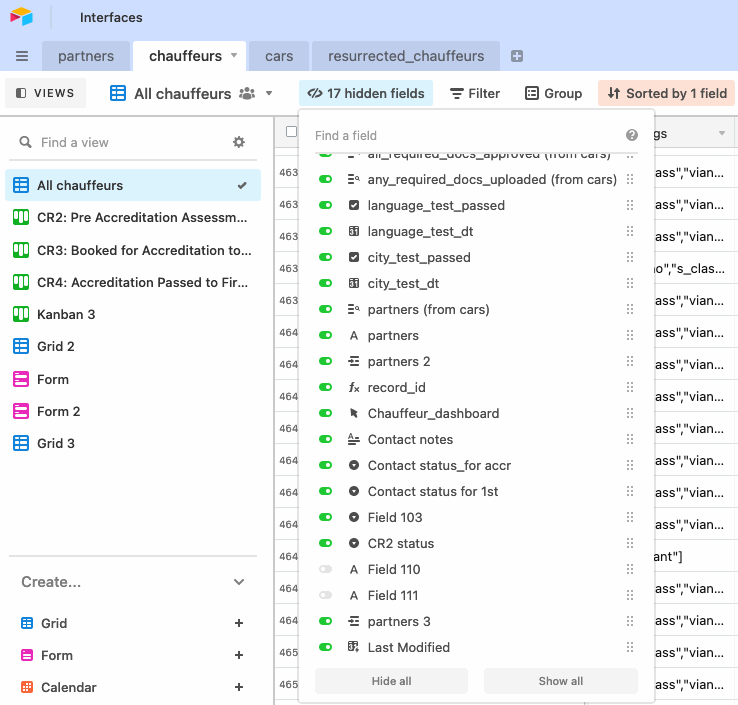
В иных случаях в обзор могут случайно попасть данные, содержащие тайну или персональные данные. Как сказал один мой коллега в Wheely:
Here in IT we love Least Privilege Principle
Что делать?
Явно указывайте минимально необходимый набор атрибутов. Строк кода будет немного больше, но выше станет и надежность этого кода.
Однако, как и всё остальное, однозначно отнести эту практику к негативным нельзя. Возможно, в Вашем случае вероятность FAIL’ов и влияние на downstream-зависимости будет минимальным, и такой подход сможет заметно ускорить и улучшить процесс разработки и поставки аналитических сервисов. Моя задача – предупредить и обратить внимание.
Чрезмерное количество CTEs (common table expressions) в логике трансформаций
CTE – это практика написания транформаций, когда вместо того чтобы городить несколько уровней подзапросов, достаточно определить их в отдельные табличные выражения и в этом же самом запросе ссылаться на них. Что-то типа alias, но для наборов строк.
Посмотрите пример красивого использования CTE в модели dbt: https://gist.github.com/kzzzr/5cccc74f6d9eeb189ae6fdba1b2ec14a
Да, это удобно. Да, это способствует структурированному решению задачи и пошаговой реализации логики. Но это не повод злоупотреблять доступной возможностью.
Почему это важно?
1. Растущая сложность
Лучше упрощать, чем усложнять. Избавляться от лишних и ненужных частей, чем хранить их и пытаться вписывать новые требования в старые рамки.
2. Неэффективное исполнение запросов с огромным количеством CTE
Как правило, запрос исполняется следующим образом:
Последовательно собираются все CTE (возможно, записываются на диск)
Выполняется финальный запрос (который, возможно, объединяет все CTE)
А это значит, что сначала будут собраны все CTE, и только потом мы начнем их фильтровать и отбрасывать ненужные колонки. Даже если у вас нет ограничений по CPU, запрос может исполнятся долго (и дорого!) из-за большого объема сканируемых данных (I/O). Есть умные движки и парсеры запросов, которые переписывают код и максимально фильтруют данные, но рассчитывать на них не следует.
Что может пойти не так?
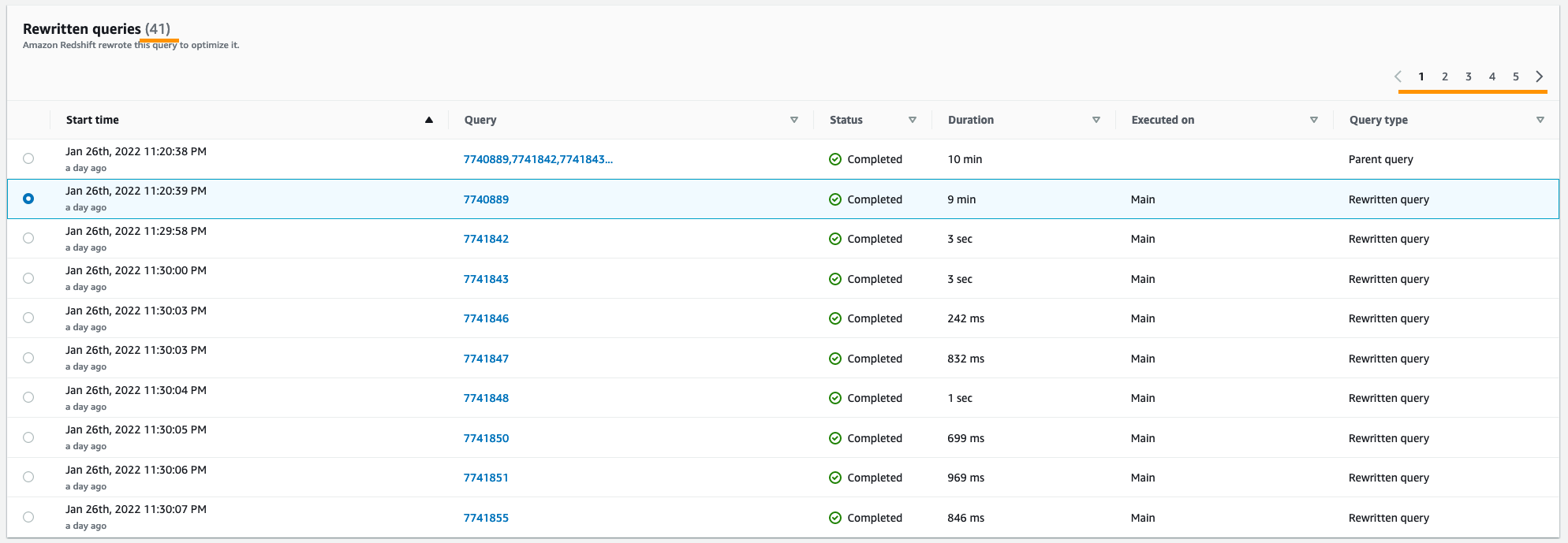
1. Появление участков-бутылочных горлышек (bottlenecks)
41 подзапрос? Запросто!
2. Изменения в таких участках кода происходят путем добавления новых CTE
Как правило, аналитики стоят перед выбором: с одной стороны – разобраться во всей цепочке CTE-выражений и внести изменения там, где правильно, с другой стороны - просто добавить свой код поверх.
В условиях множества задач и желания получить быстрый результат ответ очевиден – просто добавляем еще несколько CTE (ведь хуже уже не будет?).
3. Это трудно рефакторить
Кодовая база становится похожей на спагетти-код. Становится сложно понять, что из чего следует, и зачем здесь эти участки кода.
Реальный пример плана запроса (может быть больно для Вашего мозга!): https://gist.github.com/kzzzr/6499510ac7fa0004fd32ed30e1df4541
Спрячу его под спойлер

Пожалею Вас и не буду показывать сам запрос.
Что делать?
Решать задачу за минимум операций и шагов (keep it simple).
Не тянуть лишние строки и колонки (filter early)
Не повторять одни и те же операции (см. след пункт!)
Поймите, CTE - не пацанея. Это просто способ красиво оформить код сложного набора преобразований. Добавление новых и новых CTE будет только усугублять ситуацию.
NOT DRY (Don’t repeat yourself) – повторение и калейдоскопический характер расчетов
В условиях распределенной команды, разделения на зоны ответственности, бизнес-вертикали, так или иначе возникает ситуация, когда аналитики будут делать одни и те же вещи. И каждый своим способом.
Почему это важно?
1. Одна версия правды
Это важно для бизнес-метрик. Разные подходы, формулы, реализации расчета одного и того же показателя приводят бизнес-пользователей в ступор.
2. Одна точка для изменений и эволюции кода
Если Вам понадобилось поменять формулу расчета (добавить слагаемое, изменить налоговых коэффициент, учесть новую группу пользователей, …) – это нужно будет сделать только в одном месте, а не в нескольких.
3. Оптимальный код
Если Вы часто обращаетесь к одному и тому же набору данных – есть смысл материализовать его в виде промежуточного набора данных (таблицы).
Проведите аналогию с вызовом функции или метода в языке программирования, только здесь – набор данных.
Что может пойти не так?
1. Дублирование одной и той же бизнес-логики в разных местах
Изменили в одном месте, но забыли в другом – получите баг.
2. Излишняя нагрузка на СУБД
А равно и трата вычислительных ресурсов, за которые Вы платите.
3. Рост объема устаревшего и ненужного кода
20-30% – в среднем такова моя оценка доли legacy в проекте, которая, увы, уже вряд ли когда-то будет востребована.
Есть процессы разработки и поставки новых витрин, но пока нет процессов Garbage Collection - удаления мусора и высвобождения ресурсов.
Что делать?
Визуализируйте граф зависимостей (DAG) для поиска болевых мест
Коллеги из dbtLabs называют это Spider ????

Следуйте принципам секционирования Хранилища Данных
Модели каждого слоя обращаются только к моделям этого или предыдущего слоев.

Как всему этому можно научиться?
Наступать на грабли полезно, но всё-таки приятнее учиться на чужих ошибках.
На live-сессиях я и мои коллеги делимся выстраданным опытом и практиками. Реальные специалисты отрасли, практические знания, проекты в Яндекс.Облаке. Если Вам стало интересно, изучите программы и приходите на вебинары:
Также своими наблюдениями, опытом и практиками я делюсь в ТГ-канале Technology Enthusiast.
Если Вам понравился материал, голосуйте За, и я продолжу второй частью:
Документация с кодом; пояснения и комментарии к расчетам и атрибутам
Умение задавать вопросы заказчику и понимать истинные потребности
Проверки ожидаемых характеристик данных (Data expectation testing)
Оценка альтернатив и оптимальный выбор решений / инструментов / алгоритмов
Спасибо!
Комментарии (2)

kzzzr Автор
30.01.2022 10:30Интересный комментарий из ТГ:
От Select * есть технологический антидот - SQLFluff, rule_L044
Про CTE хотелось бы узнать, какие парсеры-компиляторы умные, какие нет; и почему нельзя рассчитывать на умные.
Привет, спасибо.
Да, SQLFluff отдельная история.
В особенности с dbt (шаблонизированным кодом). Ее можно встраивать как проверку на этапе DEV – тогда каждый разработчик/аналитик сам отвечает.
Либо на этапе TEST/CI – как проверка кода, тогда в этом контуре нужно будет скомпилировать код и проверить.По поводу парсеров – я имел в виду сами аналитические движки. Часть из них может составить полный план запроса и оптимизировать (переписать).
Например, 3 CTE читающие разные таблицы select *, финальный запрос с применением фильтра WHERE на даты + категории.
Часть движков сможет эти фильтры переместить сразу в изначальные CTE, чтобы не читать все строки. Другие движки будут полностью собирать 3 CTE-таблицы в промежуточную область, и только потом фильтровать, что будет значительно дольше.
sshikov
Вот этот вот (вполне осмысленный) совет про * — ему по-моему лет 20, если не все 30 :)
Впрочем, более новых сущностей типа колоночного формата паркет это все равно касается по полной программе — если вытащить из паркета только одну нужную колонку, можно сэкономить 99% ресурсов.