

Привет! Меня зовут Артемий Козырь, и я Analytics Engineer в Wheely.
Мы могли бы долго и нудно обсуждать, кто такой Analytics (Data / Backend) Engineer, какими инструментами он должен владеть, какие buzzwords в тренде и ценятся в CV, однако, на мой взгляд, гораздо интереснее рассмотреть процесс и результаты его деятельности в рамках конкретной прикладной задачи.
В этой публикации:
Что значит решение End-to-End и в чем его ценность?
Организация Extract & Load данных из асинхронного API MaestroQA
Моделирование витрин данных с помощью dbt
Поставка ценности для пользователей с помощью Looker
Решение End-to-End - от идеи до создания ценности
В двух словах, End-to-End – это поставка полноценного функционального решения, включающая все детали пазла.
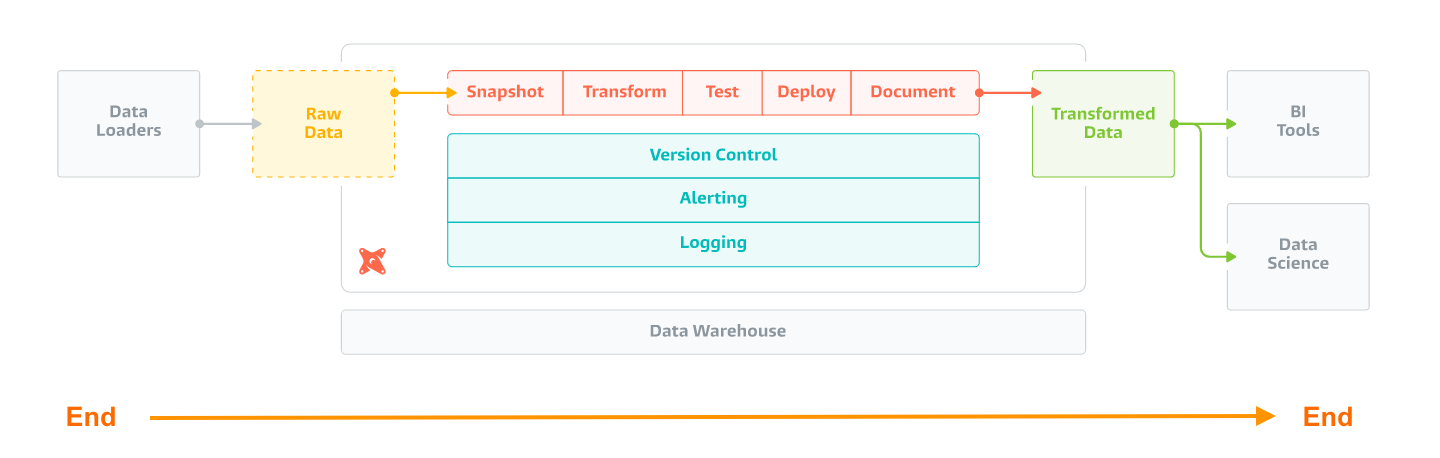
Предлагаю переходить к реальному сценарию - это работа с приложением MaestroQA, автоматизирующим мониторинг и оценку клиентского сервиса (Customer Support).
Одна из самых важных идей заключается в том, что заказчик, кем бы он ни был (Manager, Product Owner, CEO), почти никогда не ставит задачу в инженерных терминах:
Налить 100500 гигабайт в Хранилище
Добавить multithreading в код
Написать супероптимальный запрос
Создать 15 dbt-моделей
За любой инженерной задачей стоит решение конкретных бизнес-проблем. Для нас это:
Прозрачность Customer Support (фиксируем все оценки, инциденты)
Результативность на ладони (отслеживаем динамику показателей во времени)
Отчитываемся о KPI команд поддержки (агрегирующие показатели по командам, городам, странам и т.д.)
Получаем обратную связь и исправляем ошибки (идентификация слабых/проблемных мест и быстрый feedback)
Постоянно учимся и разбираем кейсы (категоризация тем, организация тренингов и разборов)
И это ключевой фокус, который отличает Analytics Engineer от, например, классических Data Engineer, Backend Engineer. Обладая всем спектром инженерных навыков и практик, Analytics Engineer создает ценность для бизнеса и решает прикладные задачи. Говорит на одном языке с заказчиком решений и мыслит в терминах бизнес-показателей.
Получим исходные данные – Extract & Load Data
Окей, теперь ближе к делу. Я выбрал MaestroQA намеренно - это источник, для которого нет готовых коннекторов в SaaS-решениях.
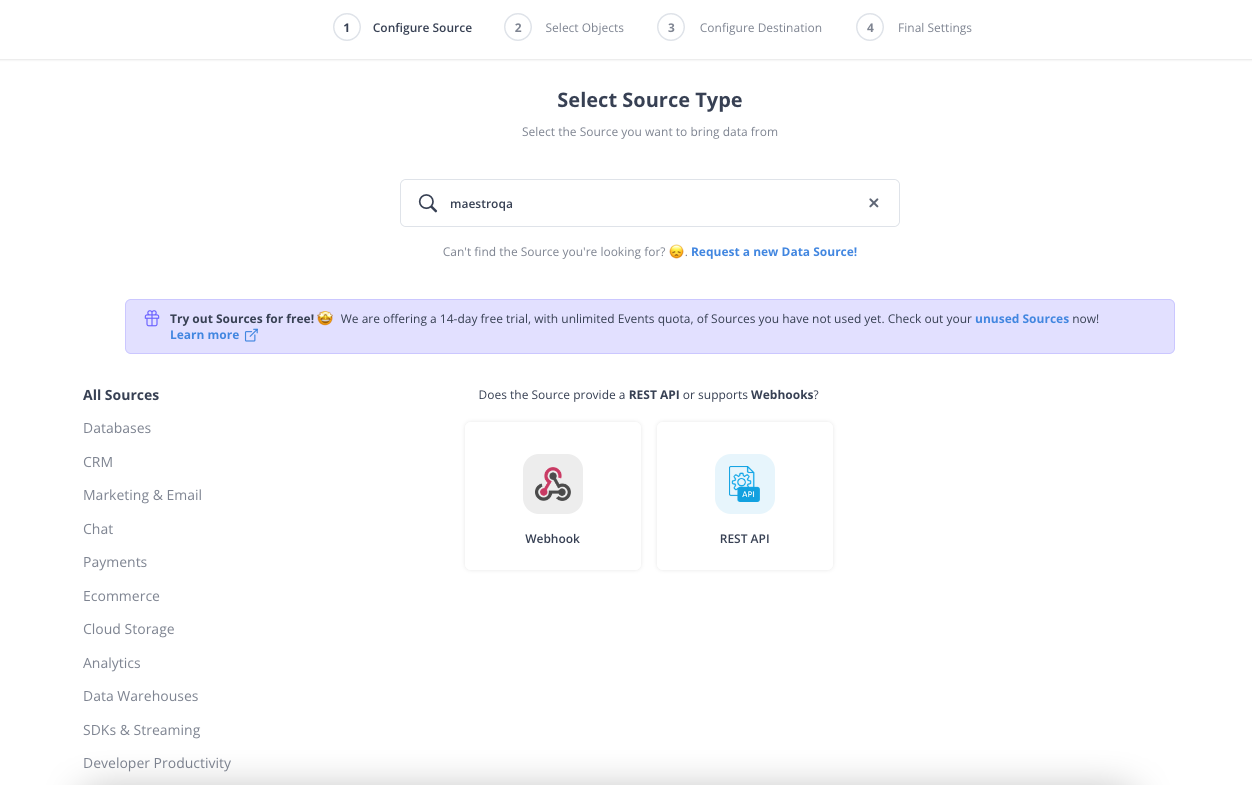
Поэтому нам придется реализовать эту интеграцию и установить ее на расписание самостоятельно.
Выбор инструментов для интеграции данных - во многом вопрос вкуса, но я предпочитаю использовать простые shell-скрипты и оркестрировать их с помощью Airflow.
1. Начнем с изучения документации к API сервиса:
Нам доступен ряд методов:
request-raw-export,request-groups-export,request-audit-log-export,get-export-dataМетоды принимают набор параметров:
apiToken,startDate,endDate,exportIdРезультирующие отчеты формируются асинхронно
Асинхронный API означает то, что в ответ на запрос той или иной выгрузки вы получите не саму выгрузку а номер в очереди. Предъявив этот номер в другое окно (метод get-export-data), вы получите выгрузку, как только она будет готова.
Использование Async API несколько усложняет задачу, а именно использованием нескольких методов и сохранением exportId, но так задача становится даже интереснее.
2. Получим API Token.
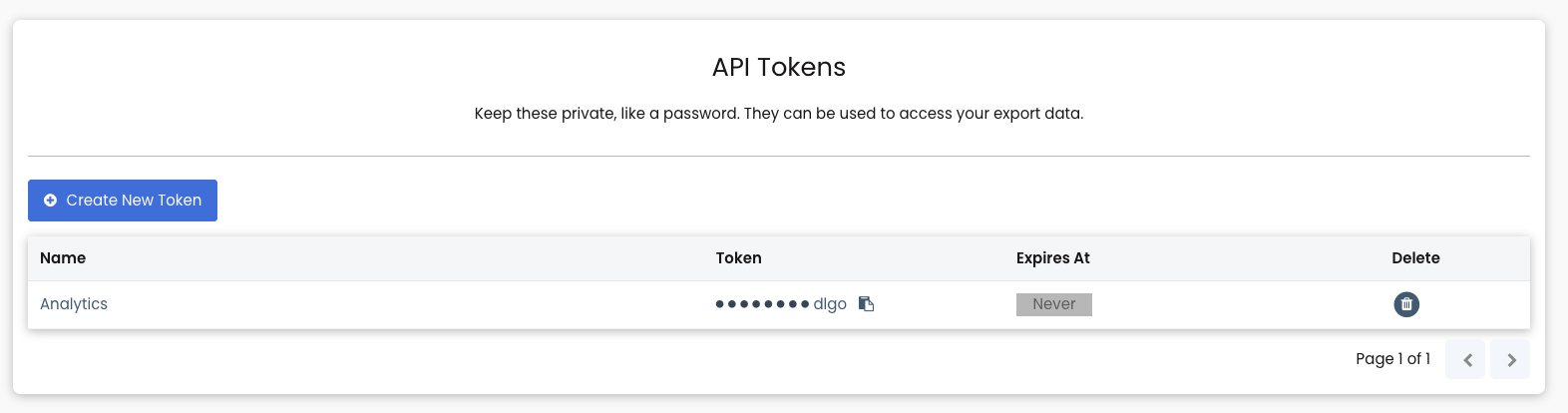
Это секретный ключ, который позволит выгружать данные, связанные с вашим аккаунтом.
3. Готовим скрипты для выгрузки.
Шаг 1. Запросить выгрузку сырых данных (total_scores.sh):
Сформировать запрос к API (
JSON_DATA)Получить
exportId(талон в очереди)Проверить значение
exportIdи если ОК, то перейти к выгрузке результата (retrieve.sh)
# 1. Prepare request
JSON_DATA=$(jq -n \
--arg maestroqa_token "$MAESTROQA_TOKEN" \
--arg start_date "$START_DATE" \
--arg end_date "$END_DATE" \
--arg single_file_export "$SINGLE_FILE_EXPORT" \
--arg name "$FILE_NAME" \
'{apiToken: $maestroqa_token, startDate: $start_date, endDate: $end_date, singleFileExport: $single_file_export, name: $name }' )
# 2. Get exportId
EXPORT_ID=$(curl -s -X POST $ENDPOINT \
-H 'Content-Type: application/json' \
-d "${JSON_DATA}" \
| jq -r '.exportId')
# 3. Retrieve data by exportId
if [ -z "$EXPORT_ID" ]
then
echo "EXPORT_ID is empty"
exit 1
else
echo "EXPORT_ID=$EXPORT_ID"
EXPORT_ID=$EXPORT_ID bash retrieve.sh
fiШаг 2. Получить готовую выгрузку (retrieve.sh):
Определить функцию для запроса статуса готовности выгрузки (
get_status())Сформировать запрос к API (
JSON_DATA)Опрашивать API о статусе готовности каждые 10 секунд
По готовности (
complete) получить файл с результатами и сохранить в S3
# 1. function used to poll to get current status
get_status() {
curl -s -X GET $RETRIEVE_ENDPOINT \
-H 'Content-Type: application/json' \
-d "${JSON_DATA}" \
| jq -r '.status' \
| cat
}
# 2. prepare request
JSON_DATA=$(jq -n \
--arg maestroqa_token "$MAESTROQA_TOKEN" \
--arg export_id "$EXPORT_ID" \
'{apiToken: $maestroqa_token, exportId: $export_id }' )
# 3. get current status ("in progress" / "complete")
STATUS="$(get_status)"
printf "STATUS=$STATUS\n"
# 4. poll every 10 seconds
while [ "$STATUS" != "complete" ]; do
printf "STATUS=$STATUS\n"
sleep 10
STATUS="$(get_status)"
done
# 5. Store resulting file to S3
curl -s -X GET $RETRIEVE_ENDPOINT \
-H 'Content-Type: application/json' \
-d "${JSON_DATA}" \
| jq -r '.dataUrl' \
| xargs curl -s \
| aws s3 cp - s3://$BUCKET/$BUCKET_PATH/$FILE_NAME/$FILE_NAME-$START_DATE-to-$END_DATE.csv
echo "UPLOADED TO s3://$BUCKET/$BUCKET_PATH/$FILE_NAME/$FILE_NAME-$START_DATE-to-$END_DATE.csv"Автоматизация на Airflow.
Отлично! После успешного формирования выгрузки в ручном режиме возникает необходимость задать расписание выполнения. Удобнее всего это сделать через Airflow, с возможностью осуществлять повторные попытки, мониторинг, получения уведомлений.
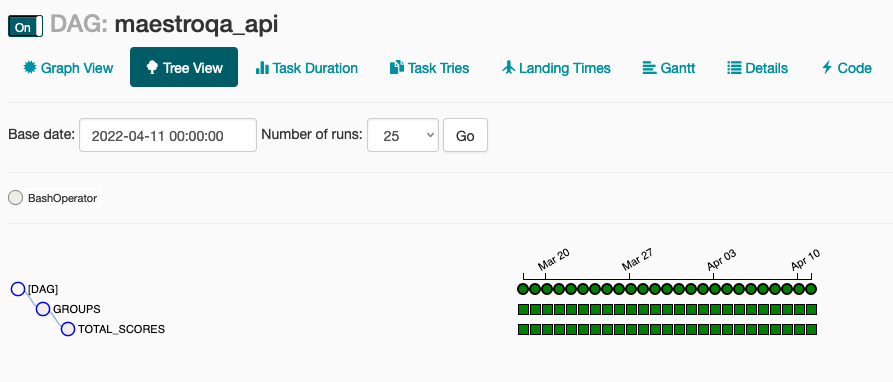
Пример DAG:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
import os
import yaml
from datetime import datetime, timedelta
from slack.notifications import failed_task_slack_notification
### INIT DAG
DAG_NAME = "maestroqa_api"
SCHEDULE_INTERVAL = '0 0 * * *'
DAG_PATH = os.path.dirname(__file__)
CONFIG_FILE_NAME = "config.yml"
CONFIG_PATH = os.path.join(DAG_PATH, CONFIG_FILE_NAME)
CONFIG = yaml.safe_load(open(CONFIG_PATH))["endpoints"]
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime(2022, 2, 1),
"retries": 1,
"retry_delay": timedelta(minutes=3),
"catchup": False,
"dagrun_timeout": timedelta(minutes=5),
'on_failure_callback': failed_task_slack_notification
}
dag = DAG(
DAG_NAME,
default_args=default_args,
schedule_interval=SCHEDULE_INTERVAL
)
os.environ["START_DATE"] = "{{ execution_date.isoformat() }}"
os.environ["END_DATE"] = "{{ next_execution_date.isoformat() }}"
groups = BashOperator(
task_id=CONFIG['groups']['FILE_NAME'],
bash_command=f"cd {DAG_PATH}/ && bash {CONFIG['groups']['FILE_NAME']}.sh ",
env={ **os.environ.copy(), **CONFIG['groups'] },
trigger_rule="all_done",
dag=dag
)
total_scores = BashOperator(
task_id=CONFIG['total_scores']['FILE_NAME'],
bash_command=f"cd {DAG_PATH}/ && bash {CONFIG['total_scores']['FILE_NAME']}.sh ",
env={ **os.environ.copy(), **CONFIG['total_scores'] },
trigger_rule="all_done",
dag=dag
)
groups >> total_scoresСмоделируем витрины данных – Transform Data
К данному этапу у нас ежедневно работает выгрузка новых данных и файлы накапливаются в S3.
Зарегистрируем файлы в S3 в качестве EXTERNAL TABLE
Чтобы иметь возможность обращаться к данным с помощью SELECT-запросов. В этом нам поможет package dbt-labs/dbt_external_tables:
version: 2
sources:
- name: maestroqa
database: wheely
schema: spectrum
tags: ["sources", "maestroqa"]
loader: Airflow (S3 via External Tables)
description: "MaestroQA – customer service quality assurance software"
tables:
- name: groups
identifier: maestroqa_groups
description: "Agent Groups"
external:
location: "s3://{{ var('s3_bucket_name') }}/maestroqa/GROUPS/"
row_format: serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
table_properties: "('skip.header.line.count'='1')"
columns:
- name: group_name
data_type: varchar
description: "Group / Team name: All Agents, UK Team, Ru Team, FR Team, UK Team"
- name: group_id
data_type: varchar
- name: agent_name
data_type: varchar
- name: agent_email
data_type: varchar
- name: agent_ids
data_type: varchar
description: "List of semicolon separated Agent IDs. Used to link with MaestroQA Total Scores table"
- name: available
data_type: bool
description: "Flag indicating if agent is available at the moment"Результирующие EXTERNAL TABLES будут использоваться в dbt в качестве sources (источников данных)
Моделирование витрины данных
Предлагаю взглянуть на то, как выглядят исходные данные, полученные из ответов API. Выгружаются 2 типа файлов:
Groups - справочник агентов, команд
Scores - факты оценок и скорингов коммуникаций
Особое внимание обратим на колонку agent_ids, представляющиую собой массив идентификаторов. С этим атрибутом придется повозиться - необходимо разбить массив на элементы и придать таблице плоский вид, добавив суррогатные ключи.
Наша задача - собрать широкую витрину, на основе которой впоследствии можно находить ответы на любые вопрос. Для этого объединим таблицы:
{{
config (
materialized='table',
dist='auto',
sort=['graded_dt', 'country'],
tags=['maestroqa']
)
}}
SELECT
-- IDs
scores.gradable_id
, scores.agent_id
-- dimensions
, scores.grader
, scores.agent_name
, scores.agent_email
, groups.group_name
, CASE groups.group_name
WHEN 'Ru Team' THEN 'RU'
WHEN 'FR Team' THEN 'FR'
WHEN 'UK Team' THEN 'GB'
WHEN 'All Agents' THEN 'All'
END AS country
-- dates
, scores.date_graded::DATE AS graded_dt
-- measures
, scores.rubric_score
, scores.max_rubric_score
FROM {{ ref('stg_maestroqa_total_scores') }} AS scores
LEFT JOIN {{ ref('flt_maestroqa_groups') }} AS groups ON groups.agent_id = scores.agent_id
AND groups.group_name IN ('All Agents', 'Ru Team', 'FR Team', 'UK Team')Итоговый граф зависимостей моделей dbt (DAG) выглядит следующим образом:

Обеспечим доступ к данным через BI – Deliver value
Отлично, к этому этапу помимо набора файлов в S3 у нас есть постоянно обновляющаяся широкая таблица в СУБД (витрина), обращаясь к которой мы можем получить ответы на любые вопросы.
Однако не все пользователи одинаково способны формулировать свои вопросы на чистом SQL. Этот барьер призваны устранить BI-инструменты, основные задачи которых сводятся к:
Предоставлению визуального конструктора запросов к данным
Формированию набора измерений, метрик и фильтров для последующего использования бизнес-пользователями
Группировке ряда визуализаций и ответов в пользовательские дашборды
Настройке рассылок данных и уведомлений по определенным правилам
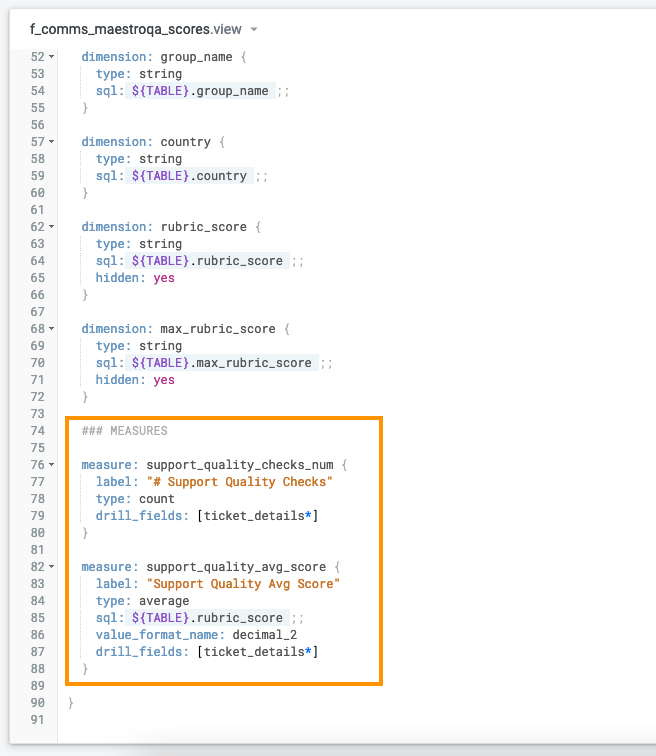
В Looker каждой колонке исходной таблицы можно присвоить статус измерения или метрики, задать правила агрегации, добавить комментарий. Это делается на языке LookML, напоминающем Javascript:
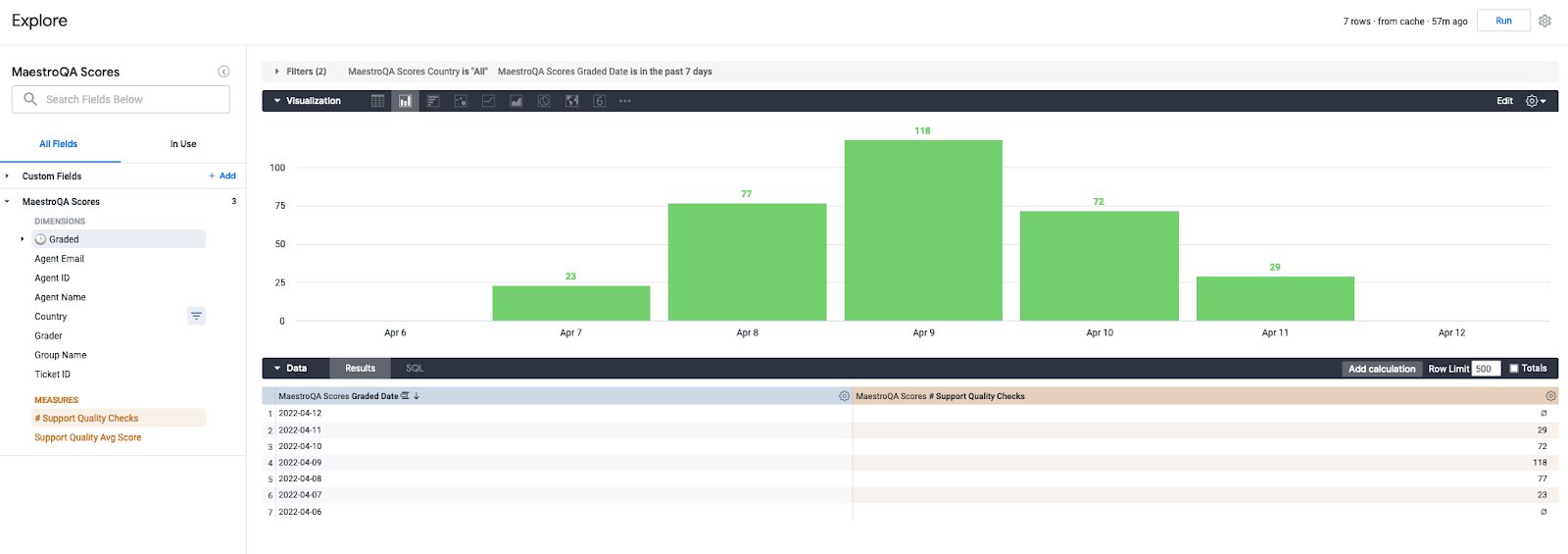
Далее любой пользователь может воспользоваться конструктором для визуального формирования ответов на свои вопросы – в Looker это называется Explore:
Готовые плиточки (tiles) можно группировать в дашборды, рассылать всем заинтересованным пользователям, устанавливать уведомления при достижении пороговых значений метрик:
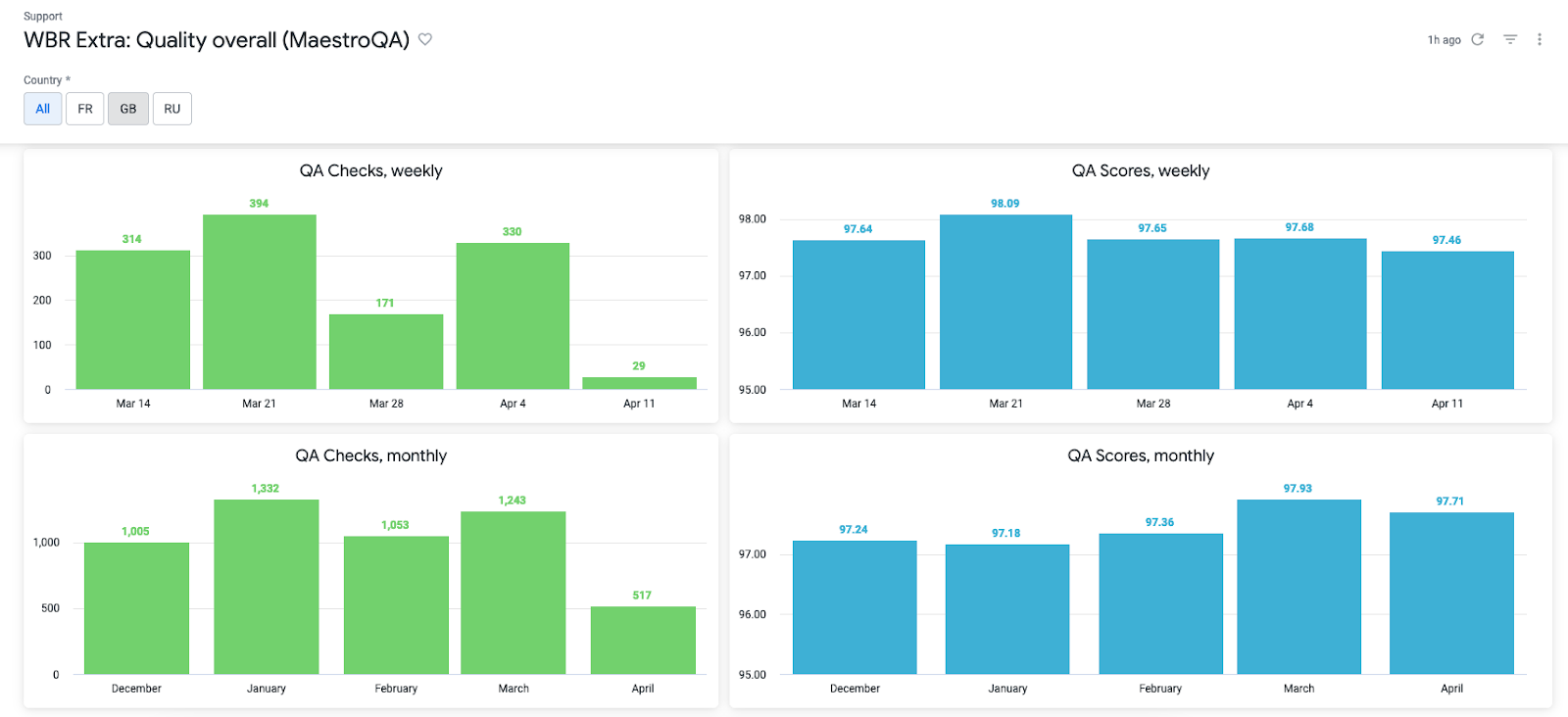
В целом - это вершина айсберга, относительно проделанной работы, но именно на этом этапе создается основная ценность и польза для компании.
Умение строить комплексные решения, отвечающие на запросы бизнеса
Это то, что хотят видеть нанимающие менеджеры. Специалисты широкого профиля, мультиинструменталисты, обладающие автономностью и способные самостоятельно решать задачи и создавать ценность для бизнеса нужны на рынке как никогда.
Именно эти аспекты я держал в уме, когда работал над программами курсов Analytics Engineer и Data Engineer в OTUS.
Это не просто набор занятий по темам, а единая, связная история, в которой акцент делается на понимание потребностей заказчиков. На live-сессиях я и мои коллеги делимся своим опытом и реальными кейсами:
Продвинутое моделирование в dbt
Развертывание и особенности работы c BI-инструментами
Аналитические паттерны и SQL
Кейсы: Сквозная аналитика, Company’s KPI, Timeseries analysis
Также своими наблюдениями, опытом и практиками я делюсь в ТГ-канале Technology Enthusiast.
Напишите комментарий, если сталкивались с потребностью строить подобные решения, и какой подход применяли?
Спасибо!
dyadyaSerezha
Для преподавателя непростительно выражаться так неграмотно. Данные выгружаются не из API, а из MaestroQA с помощью его API.
Далее, не очень понятно, зачем тут bash на нижнем уровне, если его вызывает скрипт на Python. Тот же самый нижний уровень прекрасно реализуется на Python и все получается гораздо проще и логичнее.