

Зачем нужна инкрементальная стратегия?
Итак, Вы работаете с Большими Данными:
Обработка этих данных требует значительного времени (и затрат ????)
Исторические данные не меняются (или не должны меняться) - как правило, это свершившиеся факты
Если Вам удается не делать повторную обработку исторических данных - Вы экономите время и затраты

В самом деле, давайте просто хранить одну большую таблицу, в которую будем добавлять новые данные по мере необходимости. Остается только разобраться:
Что значит новые данные и как их выделить?
Что значит добавлять?
Как не потерять строки и не остаться с копиями строк?
Если нам удастся найти ответы на эти вопросы - мы сумеем строить Хранилище более оптимальным способом!

Необходимость инкрементального расчета на реальном примере
Предлагаю попробовать найти решение на примере, приближенном к реальности. Рассмотрим сферу транспорта и передвижения по городу:
Имеем координаты начала и окончания маршрута (широта / долгота - lat / lon)
Справочник ГЕО-зон, включающий улицы, районы города, вокзалы, аэропорты, Points of interest (музеи, торговые центры и т.д.)
Возможность выполнить Spatial Join в СУБД, то есть найти привязку точки на карте конкретной ГЕО-зоне (или нескольким)

Учитывая тот факт, что Spatial Join является довольно затратной (CPU-intensive) операцией, а также то, что маршрут поездки, как правило, не может меняться после её окончания, мне представляется очень удобным накапливать эти данные инкрементальным образом. Исходный запрос выглядит следующим образом:
select
-- IDs
orders.request_id
, orders.city_id
-- PICKUP
, pickup.kind as pickup_kind
, pickup.zone_name as pickup_zone
, coalesce(pickup.is_airport, false) as pickup_is_airport
-- DROPOFF
, dropoff.kind as dropoff_kind
, dropoff.zone_name as dropoff_zone
, coalesce(dropoff.is_airport, false) as dropoff_is_airport
-- METADATA
, orders.__metadata_timestamp
from {{ ref('stg_orders') }} as orders
left join {{ ref('stg_zones') }} as pickup
on ST_Intersects(
ST_Point(orders.pickup_position_lon, orders.pickup_position_lat), pickup.geometry)
left join {{ ref('stg_zones') }} as dropoff
on ST_Intersects(
ST_Point(orders.dropoff_position_lon, orders.dropoff_position_lat), dropoff.geometry)Эволюционно, этот запрос мог проделать следующий путь:
Создадим VIEW для получения всех результатов на момент запроса
Как только запросы станут слишком долгими, материализуем результаты в виде TABLE
Когда расчет таблицы станет слишком долгим и дорогостоящим - рассмотрим применение стратегию INCREMENTAL
Как реализовать инкрементальную стратегию наполнения на уровне DDL/DML команд?
Первый запуск – полный пересчет из исходных данных
Здесь всё понятно. Пока у нас не сформирована витрина ни в каком виде, придется переварить весь набор данных из исходных таблиц.
Для любого последующего запуска – идентифицировать новые записи (дельта / delta)
В этом может помочь либо монотонно возрастащий ключ (sequence), либо временная метка (timestamp) создания или обновления записи.
Наша задача - взять те записи, которые уже есть в таблице-источнике, но которых еще нет в уже существующей версии витрины.
create temp table int_requests_zones_tmp as (
select
-- IDs
orders.request_id
, orders.city_id
-- PICKUP
, pickup.kind as pickup_kind
, pickup.zone_name as pickup_zone
, coalesce(pickup.is_airport, false) as pickup_is_airport
-- DROPOFF
, dropoff.kind as dropoff_kind
, dropoff.zone_name as dropoff_zone
, coalesce(dropoff.is_airport, false) as dropoff_is_airport
-- METADATA
, orders.__metadata_timestamp
from {{ ref('stg_orders') }} as orders
left join {{ ref('stg_zones') }} as pickup
on ST_Intersects(
ST_Point(orders.pickup_position_lon, orders.pickup_position_lat), pickup.geometry)
left join {{ ref('stg_zones') }} as dropoff
on ST_Intersects(
ST_Point(orders.dropoff_position_lon, orders.dropoff_position_lat), dropoff.geometry)
-- GET DELTA ROWS ONLY
where orders.__metadata_timestamp >=
(select max(__metadata_timestamp) as high_watermark from "intermediate"."int_requests_zones_tmp")
)Записать дельту в основную таблицу
После создания таблицы с дельта-строками, нам потребуется записать их в существующую витрину.
Сделать это можно несколькими способами, в зависимости от того, что поддерживает используемая Вами СУБД:
DELETE + INSERT (удалить старые версии строк и вставить новые целиком)
Операция MERGE (UPSERT) - оптимизированная версия UPDATE + INSERT
INSERT OVERWRITE (замена целых партиций)
delete from "intermediate"."int_requests_zones_tmp"
where request_id in (select request_id from int_requests_zones_tmp)
;
insert into "intermediate"."int_requests_zones_tmp"
select * from int_requests_zones_tmp
;
Схематично инкрементальную стратегию можно изобразить следующим образом:

dbt упрощает использование материализации incremental
dbt умеет строить инкрементальные модели из коробки. Компилируемый код уже адаптирован под возможности конкретной СУБД, будь то Redshift, Snowflake, BigQuery или даже Clickhouse! Делается это при помощи ряда конфигураций и Jinja-шаблонов:
Выбор типа материализации
incremental:
{{
config(
materialized='incremental'
)
}}Формулируем правило нахождения дельты
Ранее мы использовали конструкцию:
-- GET DELTA ROWS ONLY
where orders.__metadata_timestamp >=
(select max(__metadata_timestamp) as high_watermark from {{ ref('int_requests_zones_tmp') }})
Однако это должен быть фильтр, который применяется только для инкрементального запуска и игнорируется для полного пересчета:
where true
{% if is_incremental() %}
and orders.__metadata_timestamp >=
(select max(__metadata_timestamp) as high_watermark from {{ this }})
{% endif %}Обратите внимание на специальные переменные Jinja:
{{ this }} обозначает существующий объект в СУБД, который однозначно соответствует данной модели dbt (в которой эта консутркция используется).
is_incremental() принимает значение True при соблюдении следующих условий:
В СУБД уже существует таблица, соответствующая модели dbt
Модель сконфигурирована на материализацию
incremental(см. пункт 1)Запуск осуществляется без флага
--full-refresh(в противном случае будет полный пересчет витрины)
Обратная сторона и ограничения инкрементальных моделей
Однако как и почти везде, у инкрементального подхода тоже есть ряд ограничений, недостатков и сложностей. В основном, они связаны со спецификой использования и характером поступления исходных данных:
Late arriving data - данные, которые приходят не в порядке возникновения событий
Сложности с расчетом оконных функций (window functions), требующих наличия всей выборки строк для корректных расчетов
В случае данных, которые приходят в DWH позже есть опасность просто потерять записи. Отловить такие кейсы могут помочь тесты данных:

Каким образом можно попробовать решить эту проблему? Увеличить интервал фильтр на look-back period! Например, на 3 часа назад:
where true
{% if is_incremental() %}
and orders.__metadata_timestamp >=
(select max(__metadata_timestamp) as high_watermark from {{ this }}) - interval '3 hours'
{% endif %} Этот вариант уже означает, что я с меньшей вероятностью пропущу какие-либо строки, однако я 100% буду обрабатывать некоторый объем записей повторно, а значит мне придется выполнить ряд операций DELETE / INSERT / MERGE, чтобы избежать формирования дублирующих записей, что, конечно, в свою очередь скажется на производительности.
Чувствуете trade-off? Что-то приобретаем, что-то платим.
В свою очередь и look-back period не гарантирует 100% соответствия. Я сталкивался с ситуациями ошибок, пауз, отключений в пайплайнах Extract & Load, что look-back period в 3 часа было уже недостаточно. Можно, конечно, увеличивать интервал до 12, 24 или даже 48 часов, однако можно подумать и над альтернативным подходом.
Что если мы попробуем выполнить так называемый Anti-join?
{% if is_incremental() %}
left join {{ this }}
on orders.request_id = {{ this }}.request_id
and orders.__metadata_timestamp = {{ this }}.__metadata_timestamp
where {{ this }}.request_id is null
{% endif %} По сути это означает:
взять либо совершенно новые записи (
request_idотсутствует в{{ this }})либо взять те
request_idкоторые уже есть в{{ this }}но имеют более свежий__metadata_timestamp(запись была модифицирована с полсднего расчета)
Здесь стоит обратить внимание на план запроса, ведь наша основная задача – выполнять расчеты только с дельтой. Если этот фильтр будет применен после обработки всего массива строк - всяческий смысл в инкрементальном подходе пропадает.
Посмотрите на пример неудовлетворительного плана запроса – фильтрация происходит после выполнения 2-х GEO-spatial joins:
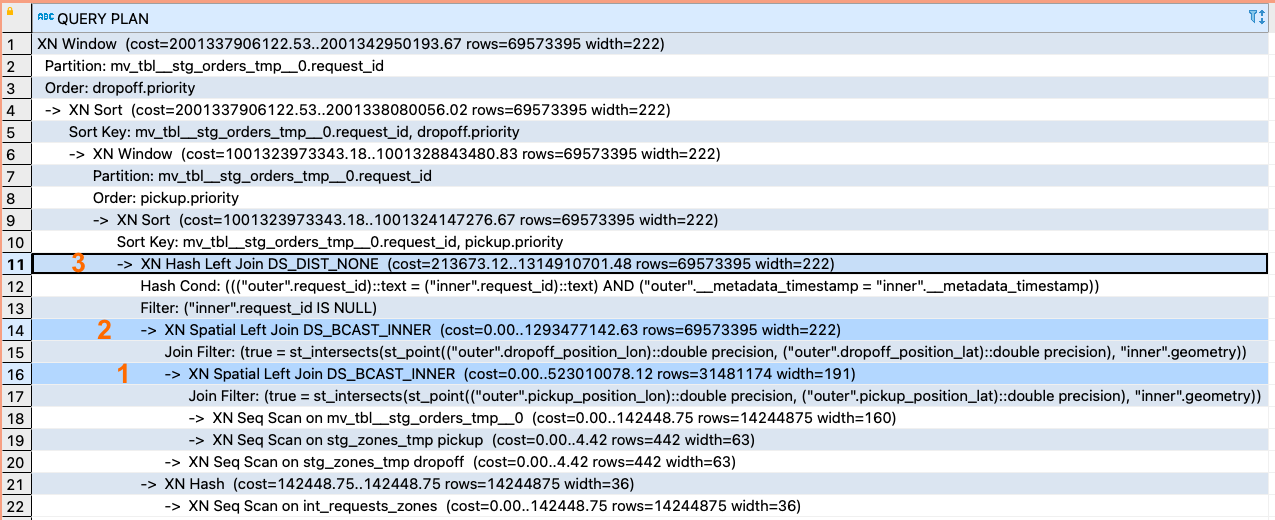
И теперь пример желаемого плана запроса – сначала фильтруем строки, потом обрабатываем:

Инкрементальная стратегия - отличный паттерн, но не панацея
Инкрементальные модели предполагают некий tradeoff:
Большинство таких моделей не гарантируют 100% точность
Подразумевается дополнительная сложность в виде кода по обработке дельта-строк
В погоне за точностью результатов можно потерять всяческие преимущества инкрементальности
Для применения этого паттерна однозначно есть хорошие кандидаты:
Immutable event streams – append-only поток событий, которые не меняются
Наличие в таблице надежной временной метки изменения записи
updated_at
В свою очередь, не очень хорошие кандидаты на применение паттерна:
Относительно небольшие таблицы
Частые изменения в данных: новые колонки, названия атрибутов и т.д.
Строки могут быть модифицированы в непредсказуемом порядке
Логика расчета требует наличия всего массива строк (оконные функции)
Умение упрощать и оптимизировать хотят видеть нанимающие менеджеры
Инженеры, обладающие широким набором паттернов, практик, подходов, а главное, умением применять их к решению конкретных задач, ценятся необычайно высоко.
На live-сессиях я и мои коллеги делимся своим опытом и реальными кейсами:
Продвинутое моделирование и Data Vault
dbt + подготовка собственных модулей к нему
Data Testing + Slim Continous Integration
Materialized Views
И многое другое
Реальные специалисты отрасли, практические знания, проекты с использованием ресурсов Яндекс.Облака. Если Вам стало интересно, изучите программы и приходите на вебинары DWH Analyst.
Также своими наблюдениями, опытом и практиками я делюсь в ТГ-канале Technology Enthusiast.
Напишите в комментарий, если сталкивались с необходимостью строить инкрементальные модели, и каким образом решали эту задачу?
Спасибо!
Geckelberryfinn
Это цветочки, если нужно просто изменившиеся данные находить и обрабатывать. Более сложный кейс - это когда связные сущности приходят независимо друг от друга и для обновления хранилища приходится по дельте одной сущности искать в истории все данные связной сущности. В таком случае сложность организации инкрементальной загрузки растёт с количеством взаимосвязанных объектов.
Пример: freights и surcharges при перевозке грузов. Зачастую эти данные приходят независимо и имеют период действия довольно широкий и совершенно разный. Например, стоимость входа в порт (surcharge) может быть валидна год. А может прийти изменение этой стоимости и тогда по этому surcharge нужно найти все freights, которые попадали в период его действия и перерасчитать полную стоимость перевозки. Таким образом дельта, состоящая из одной строки спровоцирует скан таблицы freights за год в худшем случае. А могут одновременно изменяться и freights (соответственно нужно искать связанные surcharges) и surcharges (нужно искать связанные freights).