

Привет! На связи Артемий – Analytics Engineer @ Wheely.
В последние годы явным стал тренд на анализ слабоструктурированных данных – всевозможных событий, логов, API-выгрузок, реплик schemaless баз данных. Но для привычной реляционной модели это требует адаптации ряда новых подходов к работе с данными, о которых я и попробую рассказать сегодня.
В публикации:
Преимущества гибкой схемы и semi-structured data
Источники таких данных: Events, Logs, API
Подходы к обработке: Special Data Types, Functions, Data Lakehouse
Принципы оптимизации производительности
Преимущества гибкой схемы и semi-structured data
Прежде чем мы перейдем к обработке данных, предлагаю разобраться с тем, какие данные могут называться слабоструктурированными. И пойдем мы от реляционных баз данных, при работе с которыми необходимо явным образом указывать схему данных.
Например, прежде чем записать данные в БД (в таблицу), мы сначала должны создать эту таблицу, и именно её definition (Data Definition Language – DDL), состоящий из наименований (таблицы и атрибуты), схемы (атрибуты и их типы), ограничений (PK, FK, constraints) и конфигураций хранения.

И уже после создания, на этапе вставки данных, механизм СУБД проследит, что то, что вы пытаетесь записать в таблицу соответствует её схеме. Этот подход можно также назвать schema-on-write.
Полуструктурированные данные же, в свою очередь, обладают свойством гибкости – для них нет четкой и заранее заданной схемы. Документы (записи) могут менять свою структуру, наименования атрибутов, типы без каких-либо ограничений.
Когда это полезно?
Динамический набор атрибутов: простое добавление и удаление
Скорость изменений, развития, Time to Market (T2M)
Мыслим в терминах документов и суб-документов (иерархий)

Например, с самого основания компании в Wheely используется популярная документ-ориентированная БД MongoDB:
С точки зрения бизнеса важнейшим преимуществом является тот факт, что MongoDB позволяет хранить данные в виде полуструктурированных документов. Если внезапно меняются требования, возникают новые идеи, например, мы вдруг захотим сохранять версию ОС и приложения клиента, причины отмены бронирования, время водителей на линии для последующей аналитики, — эти данные можно добавить буквально в считанные секунды, и нам не придется ничего менять. Время от идеи до внедрения (Time to Market, T2M) - одна из наиболее важных метрик. А требования бизнеса, как вы знаете, обычно очень динамичны и могут меняться буквально на ходу. Так что скорость и гибкость это не столько плюшка, сколько насущная необходимость в нормальной работе.
Источники полуструктурированных данных
Важно понимать, что слабоструктурированные данные – не редкость, значительная доля источников для современной аналитики предпочитает json-like формат выгрузок. Гибкость и простота нравится всем.
Откуда могут поступать такие данные?
Трекеры событий (event trackers): Yandex.Metrika, GAnalytics, Segment, Snowplow
Без гибкости не обойтись – события разные, контекст разный, специфика компаний и приложений тоже разная.

API Endpoints: Интеграции с различными источниками данных и приложениями.
Самые простые и распространенные примеры:
Currency Exchange – Курсы валют
Рекламные кабинеты: Яндекс.Директ, Facebook, Google Ads, VK
CRM & Customer engagement: AMO CRM, Bitrix24, Braze, MailChimp

Webhooks: дословно веб-крюк – адрес, на который приходят те или иные уведомления
Один из самых известных источников – Github Webhooks. Далее будет пример обработки данных из Github.
Webhooks allow you to build or set up integrations, such as GitHub Apps or OAuth Apps, which subscribe to certain events on GitHub.com. When one of those events is triggered, we'll send a HTTP POST payload to the webhook's configured URL.

Application Logs: логи приложений, веб-серверов, и даже системные логи
Логи, логи, логи. Все пишут логи, но не все умеют извлекать полезные выводы и знания из огромных объемов информации. Упомянем здесь знаменитый стек ELK – ElasticSearch, Logstash, Kibana, который отлично справляется с аналитикой и поиском по (полу/не)структурированным данным.

А также, конечно, ранее упомянутые Schemaless баз данных: MongoDB, CouchDB, CosmosDB, DynamoDB.
Как работать с полуструктурированными данными?
Аналитические движки, которые используются для построения Хранилищ Данных, в подавляющем большинстве являют собой реляционные СУБД с некоторыми отличительными чертами:
Параллельная обработка на кластере – MPP архитектура
Колоночное хранение и компрессия данных
Слабая поддержка (либо отсутствие) транзакций
И, конечно, отвечая на запрос рынка, каждый вендор стремится добавить в свой продукт функциональность для обработки полуструктурированных данных. Существует несколько подходов, о которых речь пойдет далее.
Использование специализированных функций
Например, набор JSON functions для Amazon Redshift:
IS_VALID_JSON
IS_VALID_JSON_ARRAY
JSON_ARRAY_LENGTH
JSON_EXTRACT_ARRAY_ELEMENT_TEXT
JSON_EXTRACT_PATH_TEXT
JSON_PARSE
JSON_SERIALIZE
Намного более разнобразны Functions for Working with JSON в Clickhouse.
Доступный набор методов и реализация функции разнятся для каждой СУБД, поэтому стоит быть внимательным и обращать внимание на руководство и документацию:
Часто функции не имеют оптимизации и предназначены для небольших объемов данных (справочники)
Вендор может предложить более оптимальные способы работы с данными (ниже)
Пример работы с JSON functions на Amazon Redshift:
Разбить массив на отдельные строки для каждого элемента
JSON_EXTRACT_ARRAY_ELEMENT_TEXT+JSON_ARRAY_LENGTHОбработать вложенные структуры с помощью функции
JSON_EXTRACT_PATH_TEXT
-- 1. split arrays to individual rows for each element
with splitted as (
select
_id
, seq.generated_number as element_number -- price_details_number
, JSON_EXTRACT_ARRAY_ELEMENT_TEXT("price_details", seq.generated_number::INT - 1, TRUE) AS price_details
from source
inner join seq on seq.generated_number <= JSON_ARRAY_LENGTH(price_details, TRUE)
),
-- 2. parse nested data
select
_id
, element_number
, JSON_EXTRACT_PATH_TEXT("price_details", 'service', TRUE) AS price_details_service
, JSON_EXTRACT_PATH_TEXT("price_details", 'price', TRUE) AS price_details_price
, JSON_EXTRACT_PATH_TEXT("price_details", 'unit_price', TRUE) AS price_details_unit_price
, JSON_EXTRACT_PATH_TEXT("price_details", 'value', TRUE) AS price_details_value
, JSON_EXTRACT_PATH_TEXT("price_details", 'type', TRUE) AS price_details_type
, JSON_EXTRACT_PATH_TEXT("price_details", 'unit', TRUE) AS price_details_unit
from splittedИспользование специальных типов данных
В дополнение к простым (primitive) типам данных, многие вендоры вводят дополнительные типы данных, предназначенные в том числе и для работы со слабоструктурированными данными:
Здесь я предлагаю рассмотреть пример SUPER data type в Amazon Redshift & Github Webhook.
Исходные данные, которые мы получаем от Github имеют иерархическую структуру.

Первый шаг – сериализовать текстовые строки в специальный тип SUPER
select
"__hevo_id" as id
, "action"
, "number"
, "before"
, "after"
, json_parse(pull_request) as pull_request
, json_parse(repository) as repository
, json_parse(assignee) as assignee
, json_parse(requested_team) as requested_team
, json_parse(requested_reviewer) as requested_reviewer
, json_parse(sender) as sender
, __metadata_timestamp
from "src"."github_pull_request"
Второй шаг – обратиться к вложенным структурам данных
И сделаем мы это очень просто и красиво – через dot-нотацию, т.е. обращение ко вложенным структурам через точку!
select
id
, "action"
, "number"
, "before"
, "after"
, pull_request.id::int as pull_request_id
, pull_request.html_url::text as pull_request_html_url
, pull_request.state::text as pull_request_state
, pull_request.title::text as pull_request_title
, pull_request.body::text as pull_request_body
, pull_request.created_at::timestamp as pull_request_created_at
, pull_request.updated_at::timestamp as pull_request_updated_at
, pull_request.closed_at::timestamp as pull_request_closed_at
, pull_request.assignee::text as pull_request_assignee
, pull_request.author_association::text as pull_request_author_association
, pull_request.auto_merge::text as pull_request_auto_merge
, pull_request.active_lock_reason::text as pull_request_active_lock_reason
, pull_request.merged::bool as pull_request_merged
, pull_request.mergeable::text as pull_request_mergeable
, pull_request.rebaseable::text as pull_request_rebaseable
, pull_request.comments::int as pull_request_comments
, pull_request.review_comments::int as pull_request_review_comments
, pull_request.maintainer_can_modify::bool as pull_request_maintainer_can_modify
, pull_request.commits::int as pull_request_commits
, pull_request.additions::int as pull_request_additions
, pull_request.deletions::int as pull_request_deletions
, pull_request.changed_files::int as pull_request_changed_files
, pull_request.user.login::text as pull_request_user_login
, pull_request.user.html_url::text as pull_request_user_html_url
, pull_request.user.type::text as pull_request_user_type
, pull_request.user.site_admin::bool as pull_request_user_site_admin
, pull_request.merged_by.login::text as pull_request_merged_by_login
, pull_request.merged_by.html_url::text as pull_request_merged_by_html_url
, pull_request.merged_by.type::text as pull_request_merged_by_type
, pull_request.merged_by.site_admin::bool as pull_request_merged_by_site_admin
, repository.name::text as repository_name
, repository.full_name::text as repository_full_name
, repository.private::bool as repository_private
, repository.html_url::text as repository_html_url
, repository.description::text as repository_description
, repository.created_at::timestamp as repository_created_at
, repository.updated_at::timestamp as repository_updated_at
, repository.pushed_at::timestamp as repository_pushed_at
, assignee.login::text as assignee_login
, assignee.html_url::text as assignee_html_url
, assignee.type::text as assignee_type
, assignee.site_admin::bool as assignee_site_admin
, requested_team.name::text as requested_team_name
, requested_team.slug::text as requested_team_slug
, requested_team.description::text as requested_team_description
, requested_team.html_url::text as requested_team_html_url
, requested_reviewer.login::text as requested_reviewer_login
, requested_reviewer.html_url::text as requested_reviewer_html_url
, requested_reviewer.type::text as requested_reviewer_type
, requested_reviewer.site_admin::bool as requested_reviewer_site_admin
, sender.login::text as sender_login
, sender.html_url::text as sender_html_url
, sender.type::text as sender_type
, sender.site_admin::bool as sender_site_admin
, __metadata_timestamp
from "dbt_test"."flt_github_pull_request"
Вуаля – все необходимые для аналитики измерения и метрики доступны в отдельных колонках с целевыми типами.
Как правило, работа с такими типами оптимизирована на низком уровне и показывает отличные результаты на больших объемах данных. На мой взгляд, это самый приоритетный способ.
Использование интеграции с Озером Данным (Lakehouse)
Архитектура с использованием Озера Данных (Data Lake) и Хранилища Данных (Data Warehouse) одновременно имеет массу преимуществ и неоднократно рассматривалась и обсуждалась. Однако интеграция этих двух архитектурных паттернов не всегда была бесшовной и простой. Cегодня каждая из компонент делает шаги навстречу друг другу, превращаясь в продукты типа Data Lakehouse, AWS Spectrum.
Возможность обращаться в одном SQL-скрипте к файлам в Data Lake и витринам в DWH всегда была желанна среди инженеров и аналитиков. С использованием External Tables это стало обыденной реальностью.
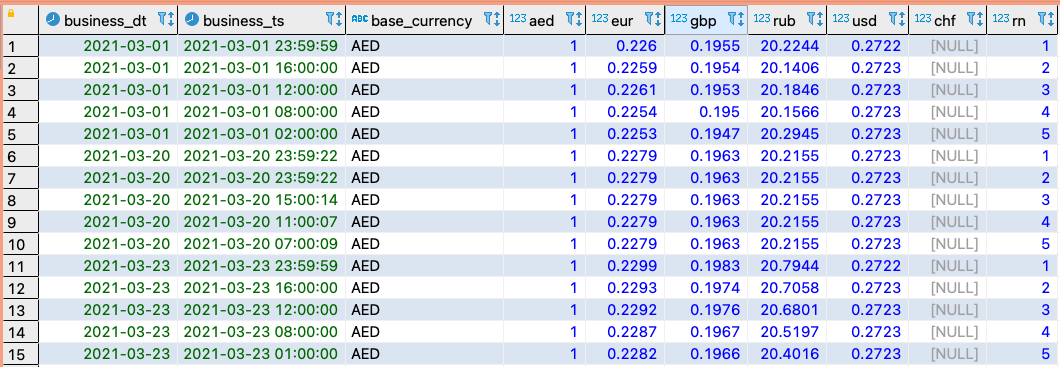
Давайте вернемся к примеру с курсами валют. Предположим, что каждый час или каждые сутки вы выгружаете актуальные курсы и записываете их в файловое хранилище S3 (Object Storage).

Тогда с помощью простого DDL-скрипта можно создать таблицу-ссылку на эти файлы:
create external table "currencies_oxr" (
"timestamp" bigint,
"base" varchar(3),
"rates" struct<aed:float8, eur:float8, gbp:float8, rub:float8, usd:float8>
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
location 's3://my.data.lake/dwh/currencies/'В Clickhouse, например, такую фунцию исполняет S3 Table Engine.
При этом попытка добавить в DDL-схему атрибут, который в файле отсутствует, например, валюту CHF, выдаст NULL, а не ошибку. Это является свидетельством работы принципа Data Lake schema-on-read – применение схемы к файлам в момент чтения, но не записи, в противовес упомянутому ранее принципу schema-on-write.
Принципы оптимизации производительности
Часто при работе с большими наборами данных, а тем более полуструктурированного характера, можно столкнуться с проблемами производительности. Попросту говоря – мы будем долго ждать, использовать много дискового пространства и ресурсов CPU там, где этого потенциально можно избежать.
Есть ряд проверенных опытом практик и рекомендаций, которые я постараюсь резюмировать.
Одна колонка – один атрибут
Для использования ключевых преимущества Колоночных СУБД. Запрашивайте только необходимые для ответа колонки, минимизируйте операции с диском. К тому же колонки простых типов с отдельными атрибутами содержат однородные данные, лучше сжимаются.
Материализация в отдельные атрибуты (колонки) как можно раньше (в графе преобразований)
Если граф преобразований сложный, многоуровневый, то имеет смысл материализовать (в отдельные колонки) необходимые атрибуты (из массива полуструктурированных данных) как можно раньше и отбросить всё ненужное.
Использование специальных типов данных
Там, где они доступны. Как правило они оптимизированы разработчиками СУБД на низком уровне.
Материализация в фоне
При поступлении новых порций данных. То есть обработка небольших порций данных средствами самой СУБД. С этой задачей отлично справляется Materialized Views. MV доступны и используются во многих СУБД, например, Redshift и Clickhouse.
Дальнейшие шаги
1. Изучите возможности своей СУБД
Какие подходы и инструменты для работы с semi-structured data доступны в используемой Вами СУБД.
2. Пробуйте найти источники полуструктурированных данных в своем проекте
И посмотреть, насколько оптимально они используются.
3. Приходите на live сессии и вебинары
Я и мои коллеги стремимся делиться своим лучшим опытом и знаниями в рамках занятий на курсе Analytics Engineer:
Практики от лидеров отрасли в рамках живого общения
Ваучер Яндекс.Облака на все эксперименты и задания
Множество продвинутых тем по моделированию DWH в программе
Движуха в Slack и сообщество
Спасибо за внимание!