

Статья будет полезна начинающему разработчику или тому, кто хочет расширить свой кругозор практическим знакомством с графовыми базами данных. Часто в аналогичных статьях не хватает либо пошаговой инструкции по установке, либо более детального разъяснения – как общаться с данными в базе.
Информации по теории графов достаточно много, поэтому в материале будут сугубо прикладные знания, которые существенно облегчат закрепление материала практикой. В данном примере рассматривается работа с локальным экземпляром БД Neo4j. СУБД именно этого вендора позволяет осваивать тему графовых баз данных с достаточно низким порогом входа – нам понадобится только понимание SQL. Иными словами, статья представляет собой краткую сводку/инструкцию о том, какие шаги нужно пройти и что освоить, чтобы начать "играться" с Neo4j на вашем личном ПК или сервере в инфраструктуре вашей компании. Поскольку в этот тип БД заходят специалисты, ранее работавшие с реляционными БД, для облегчения понимания принципов в статье сделан упор на сопоставление языка общения с графовыми базами данных и классическим SQL. Чтобы сделать пример прикладным, в материале приводится решение типовой бизнес-задачи для графовых БД на простом примере из финансовой предметной области.
Установка
Для установки сначала скачиваем дистрибутив на официальном сайте https://neo4j.com/. Там большая кнопка «Get Started». Нас интересует версия Neo4j Desktop.
По традиции сталкиваемся с тем, что бесплатный сыр бывает только в обмен на ваши персональные данные:

К счастью, удалось ввести произвольные – никаких подтверждающих кодов не потребовалось:

Если даже это делать лень, есть прямая ссылка для того, чтобы скачать дистрибутив Neo4j Desktop.
Установка производится по принципу next-next-next-finish и по завершению можно сразу запустить:

Далее предлагается ознакомиться с текстом лицензионного соглашения и принять условия, если всё устраивает.
Выбираем на свое усмотрение каталог для хранения данных приложения. Позже при желании его можно изменить.

Если процедура регистрации приносит дискомфорт, можно от нее отказаться с помощью кнопки "Register later":
При запуске приложения Neo4j предложит обновить некоторые модули, если обнаружит, что используется не последняя версия. Лучше обновить, но можно и потом.

Интерфейс
Установка позади. Перед нами уже запущенный экземпляр БД Movie DBMS. Здесь же из описания можно узнать о том, что из себя представляет эта база (about-movies.neo4j-browser-guide), а также подсмотреть – каким скриптом её создавали (load-movies.cypher):
Все интуитивно понятно. В будущем планирую на примерах показать работу различных приложений и плагинов Neo4j. В данной статье ограничусь их перечислением с кратким описанием:
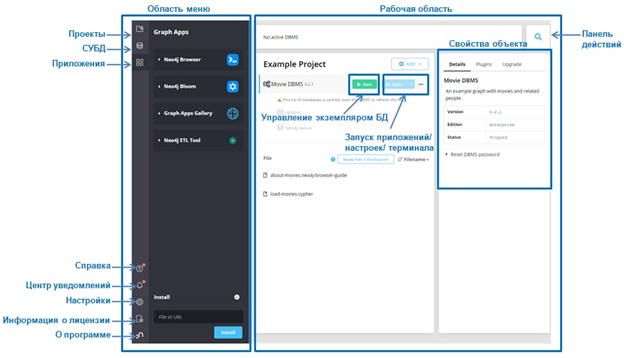
Приложение, в котором предстоит работать – Neo4j Browser. С остальным можно разобраться по ходу практики. Поэтому после того, как сориентировались, можно приступать к работе.
Создание и наполнение БД
В качестве примера предлагаю поработать с банковским сектором и вечной системой любого уважающего себя банка – anti-fraud («борьба с мошенничеством»). В качестве данных возьму предлагаемый пример от Kenny Bastani (Twitter – @kennybastani). Исходники брал из репозитория https://github.com/neo4j-contrib/gists/blob/master/other/BankFraudDetection.adoc. Поскольку все действия носят ознакомительный характер, упражняться можно в рамках одного проекта – Example Project. Создаем БД: для начала жмем Add->Local DBMS

Вписываем наименование БД по своему усмотрению, пароль для доступа и создаем БД.В моем случае рассматриваем пример на версии 4.3.1

Запускаем созданную БД, открываем Neo4j Browser с помощью кнопки Open. Далее я её заполнил данными из примера на GitHub:
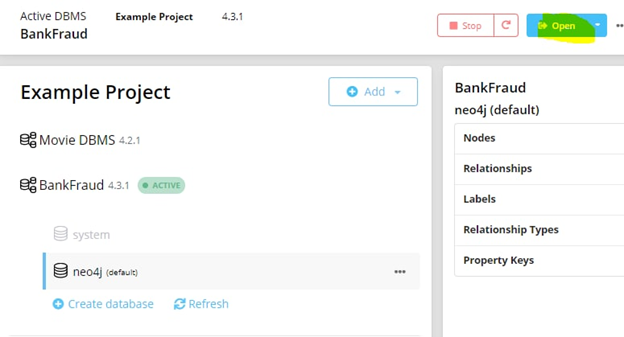
Слева можно выбрать инстанс, увидеть, что БД пуста и в ней нет никаких связей, узлов, меток и т.д.

После наполнения БД объектами статус изменился: появились некоторые сведения о сущностях и отношениях между ними.
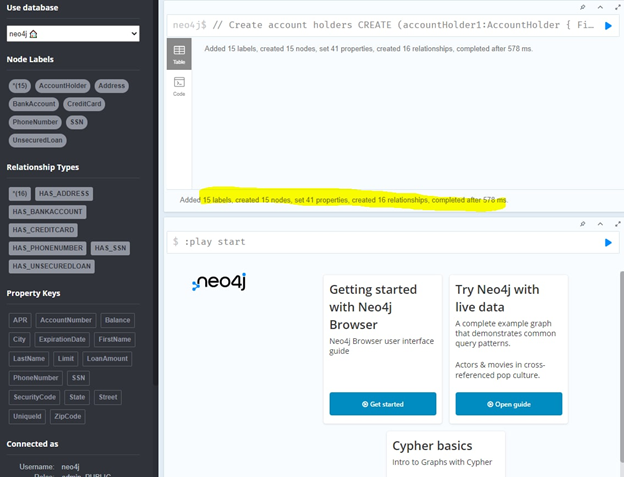
Модель предельно проста и состоит из типичных для банка сущностей: номера счета и сведений о владельце (адрес, телефон, номер социальной страховки), а также сведений о его отношениях с банком (есть ли у него кредитная карта или необеспеченный кредит).
MATCH, RETURN
Обращение к данным Neo4j происходит с помощью языка Cypher. Хотя его и позиционируют как SQL-подобный язык, но есть некоторые нюансы, и без краткого экскурса совокупность двоеточий, скобок и стрелок создают ощущение беспорядка в синтаксисе. Попробуем разобраться в нем пошагово, усложняя простейший запрос.
Например, чтобы выбрать все данные, можно использовать только два ключевых слова – MATCH и RETURN.
MATCH – своего рода аналог SELECT для графовых БД. Это ключевое слово позволяет задать критерии для поиска нужного элемента (например, вершина графа, ребро, свойство, метка и т.д.)
RETURN – ключевое слово, характеризующее возвращаемые данные из набора в MATCH.
Если нам нужно выбрать все вершины с их связями, можем написать запрос таким образом:
MATCH (n) RETURN nРезультат в виде графа:

Слева есть переключатель, позволяющий рассмотреть эти данные в другом виде: например, как таблицу или текст в формате json.
Для получения количества узлов необходимо изменить выражение в блоке RETURN:
MATCH (n) RETURN count(n)По аналогии с отдельной таблицей в реляционных БД у каждой вершины есть свой тип согласно модели данных. Если требуется выбрать конкретные вершины, например, перечень владельцев счета, название типа вершины добавляется через двоеточие:
MATCH (n:AccountHolder) RETURN n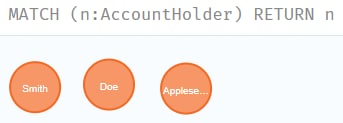
Запрос вернул именно вершины, уже без их связей, т.к. владельцы не связаны напрямую между собой. Попробуем добавить в запрос ещё и адреса:
MATCH (n:AccountHolder), (m:Address) RETURN n, m
Видно, что такой синтаксис Neo4j подсвечивает предупреждением о декартовом произведении. В реляционных БД аналогом этому служит cross join или выбор из нескольких таблиц без указания условий соединения. Но есть нюанс. Попробуем выбрать несколько не связанных напрямую между собой объектов:
MATCH (n:SSN), (m:Address), (k:CreditCard), (l:BankAccount) RETURN n,m,k,lВнешне все выглядит так, будто никакого декартова произведения нет:

Но при переключении на табличный вид обнаружим, что «под капотом» у нас 3*2*2*1 = 12 записей:

Добавление связующего элемента ситуацию не улучшает – записей теперь 36:

Хотя граф кажется не таким громоздким:

Это поведение наглядно демонстрирует концептуальные отличия между БД в виде графов и БД в виде таблиц. Здесь ключевую роль играют не сущности и их отношения, а вершины графа и его дуги.
Следовательно, для выбора некоторого перечня нужна другая форма запроса MATCH. Согласно синтаксису Cypher вершины графа объявляются круглыми скобками, дуги – квадратными, т.е. логическая модель запроса будет выглядеть как (вершина)-[связь]-(вершина). Также можно обратить внимание, что дуга имеет направление, и это тоже может быть отражено в тексте запроса, используя <- или ->. Схематично это может выглядеть следующим образом: (вершина)-[связь]->(вершина) или (вершина)<-[связь]-(вершина). Причем направление «<» или «>» должны примыкать к вершине, т.е. запись в виде (вершина)->[связь]-(вершина) некорректна и выдаст ошибку. Это может быть полезно, когда интересует только одно направление дуги – исходящее или входящее. В данной статье важность направления связи не рассматривается, но в будущих материалах по neo4j или Cypher добавлю наглядные примеры.
Перепишем запрос выше так, чтобы нам возвращался граф, содержащий связи от владельца счета к его определенным атрибутам: адресу, номеру социального страхования, кредитной карте и банковскому счету. Для начала выберем все связи и их вершины m, которыми обладает владелец счета n:
MATCH (n:AccountHolder)-[]-(m) RETURN n,m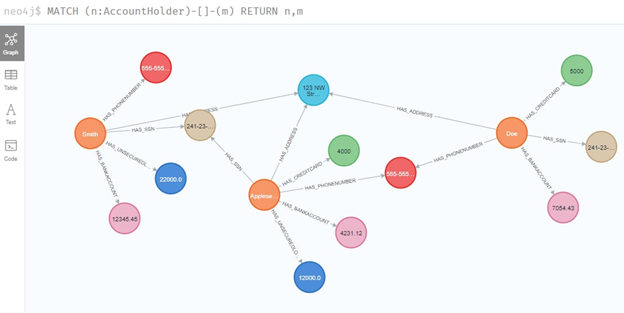
В запросе нет ни направленности, ни какой-либо фильтрации по атрибутам, а возвращает он 16 строк, что соответствует числу всех связей от владельца счета.
WHERE
Вариант решения «в лоб» знакомит нас с оператором WHERE. Принцип действия аналогичен SQL.
Картинка идентична варианту с декартовым произведением, а вот записей теперь 11, что соответствует числу связей:

Для более изящного варианта запроса следует обратить внимание на наличие типа у каждой связи. И по паттернам разработки моделей данных один тип связи должен соответствовать дуге между двумя вершинами определенных типов. Если вернуться к формулировке задачи, граф, содержащий связи от владельца счета к его определенным атрибутам – адресу, номеру социального страхования, кредитной карте и банковскому счету –, то следует искать связи определенного типа от владельца счета:
MATCH (n:AccountHolder)-[r:HAS_BANKACCOUNT|HAS_CREDITCARD|HAS_SSN|HAS_ADDRESS]-(m)
RETURN n,r,m
WITH
Следующее выражение, с которым стоит познакомиться по-новому и которое используется в примере – WITH. Как и ранее, принцип очень схож с SQL, но есть свои нюансы. Например, для выбора переменных из нескольких подзапросов, нужно написать столько пар MATCH-WITH, сколько это необходимо для получения данных. Также для получения результатов, аналогичных HAVING, с помощью WITH можно зафиксировать агрегированные данные, а затем добавлять в фильтры. Например, чтобы узнать, с какими элементами есть связь более чем у одного владельца счета, можно воспользоваться следующим запросом:
MATCH (a:AccountHolder)-[]->(c)
WITH c, count(a) AS cnt_a
WHERE cnt_a > 1
RETURN c, cnt_aПеречень функций для агрегации весьма стандартный: кроме приведенного выше count есть также avg, max, min, percentileCont, percentileDisc, stDev, stDevP и collect. Последняя нам понадобится в приводимом примере, поэтому стоит её рассмотреть подробнее. В Oracle, например, похожая роль у функции LISTAGG. То есть это функция, с помощью которой можно собрать в массив значения некоторых атрибутов. Кстати, как указано выше, каждая связь характеризует взаимоотношения двух вершин, но и у каждой вершины может быть набор атрибутов, который будет характеризовать объект независимо от остальных элементов графа. Для просмотра атрибутов можно открыть представление в виде таблицы или же панель свойств, кликнув на элемент в визуальном представлении графа:

Как видно, кроме назначенного автоматически ID у владельцев счета есть еще некоторый перечень атрибутов в виде FirstName, LastName, UniqueId. Эти атрибуты ранее назначались в скрипте создания:
CREATE (accountHolder1:AccountHolder {
FirstName: "John",
LastName: "Doe",
UniqueId: "JohnDoe" })COLLECT
Таким образом, усложняя предыдущий пример, можем получить не только контактные данные, указанные несколькими владельцами счета, но и UniqueId этих владельцев:
MATCH (a:AccountHolder)-[]->(c)
WITH c, count(a) AS cnt_a, collect(a.UniqueId) AS UniqueIds
WHERE cnt_a > 1
RETURN c, cnt_a, UniqueIdsПо понятным причинам в визуальном отображении графа эти данные не отобразятся, а вот в табличном их можно будет увидеть:

labels
Итак, у нас в распоряжении некоторые атрибуты владельцев, указавших одни и те же контактные данные. Чтобы в текущих реалиях понять, о каких контактных данных речь, необходимо взглянуть на свойство связанной вершины и на его раздел Labels, то есть метки. Этот атрибут примечателен тем, что служит для некоторой группировки вершин по типу данных между собой. При добавлении вершины в БД ей автоматически присваивается одноименная с типом объекта метка. Эти метки можно добавлять и удалять, но для примера важно показать то, как их можно использовать. Вместо вершин-контактов, количества связей и владельцев счета можно вывести только нужную информацию – владельцев счета и тип контактной информации, которая у них совпадает, разместив в порядке уменьшения количества таких пользователей. Заодно добавим более удобоваримые псевдонимы для вершин, связей и докажем, что ORDER BY тот же, что в SQL и на этот раз без нюансов:
MATCH (a:AccountHolder)-[]->(ContactInformation)
WITH ContactInformation,
count(a) AS AccountHoldersQty,
collect(a.UniqueId) AS UniqueIds,
labels(ContactInformation) as ContactType
WHERE AccountHoldersQty > 1
RETURN UniqueIds, ContactType
ORDER BY AccountHoldersQty desc
Финальный запрос
В нашем примере ситуация, при которой несколько владельцев счета указывают одну и ту же контактную информацию, потенциально служит средой для проведения мошеннических операций. Как и во многих других случаях для принятия дальнейших решений необходимо оценить риск. Нужно добавить вычисление риска в запрос, а заодно объединить в одном запросе информацию о Cypher, рассмотренную ранее:
MATCH (AccountHolder:AccountHolder)-[]->(ContactInformation)
WITH ContactInformation,
collect(DISTINCT AccountHolder.UniqueId) AS UniqueIds,
COUNT(AccountHolder) AS AccountHoldersQty
MATCH (AccountHolder)-[]->(ContactInformation),
(AccountHolder)-[r:HAS_CREDITCARD|HAS_UNSECUREDLOAN]->(UnsecuredAccount)
WITH labels(ContactInformation) as ContactType,
UniqueIds,
AccountHoldersQty,
SUM(
CASE type(r)
WHEN 'HAS_CREDITCARD' THEN UnsecuredAccount.Limit
WHEN 'HAS_UNSECUREDLOAN' THEN UnsecuredAccount.Balance
ELSE 0
END) as FinancialRisk
WHERE AccountHoldersQty > 1
RETURN UniqueIds, ROUND(FinancialRisk,2) as FinancialRisk
ORDER BY FinancialRisk DESC
Резюме
Как мы видим, знание SQL все еще является немаловажным требованием при знакомстве с новыми базами, однако сам способ мышления при обращении к данным должен измениться, поскольку они представлены не в табличном виде. В статье использована структура данных, в которой нет нескольких типов связей между двумя вершинами, а также сложной сети графов с циклами и большой иерархией. Без разбора базовых упражнений такой материал будет очень сложно освоить. В статье детально описаны все шаги по знакомству с азами Cypher и Neo4j: от установки ПО до последовательного усложнения запроса, демонстрируя каждый пункт отдельно. Теперь, когда есть базовое понимание по работе с графовыми БД, усложнение структуры и запросов будет уже более логичным. В будущем планируем привести некоторые способы генерации данных и их преобразования из плоской структуры в графовую, а заодно продемонстрировать работу плагинов, которые поставляются с дистрибутивом этой СУБД.
laatoo
Вы табличные данные нарисовали на диаграмме с кружочками и стрелочками, они от этого не стали графом.
По-моему, это забивание гвоздей микроскопом, поэтому простых запросов не получилось, а не потому что способ мышления при обращении к данным должен измениться
Найти дубликаты, по ходу дела посчитать чего-нибудь - это не про графы от слова совсем.
Неудачный пример
neoflex Автор
Благодарим за мнение. Не будем забывать, что любой граф можно попробовать разложить в табличный вид с помощью матрицы N*N, где N - количество вершин, а связи указаны на пересечении строк и столбцов. Указанный пример не случайно легко представляется в табличном формате - большинство разработчиков баз данных сейчас работают в основном с SQL и таблицами. В статье как раз красной нитью прошита аналогия именно с табличным представлением, и очень хорошо, что вы её заметили. По мнению автора, для разработчиков SQL на прикладном примере из привычного мира реляционных СУБД подобные аналогии упрощают понимание графовых баз данных. Сложные примеры, направленные именно на демонстрацию графового представления планируется раскрыть в последующих статьях, но без раскрытия основ это будет тяжело разъяснить тем, кто привык общаться с базой с помощью SQL. Хотелось бы быть последовательными в публикациях.
barloc
А можно уточнить про случай с нахождением дубликатов и почему это не про графовые базы?
Только давайте накинем сразу, что нам надо выдавать дубликаты онлайн (ну скажем 200мс для 99 перцентиля), и поток атрибутов идет онлайн.