
Первая и вторая части описывают действия, которые привели к разработке текущей модели.
Основные принципы построения процесса загрузки:
Поток NIFI максимально универсален для источников
Метаданные потоков загрузки расположены вне NIFI
С добавлением нового потока загрузки должен справится аналитик/разработчик БД
В общем виде взаимодействие сиситем можно представить в следующем виде.
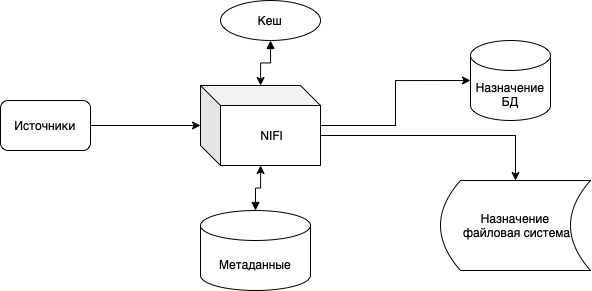
На рисунке:
Источники - все, что поставляет данные. В моей текущей реализации это только базы данных.
Кеш - либо внутренний кэш NIFI, либо Redis.
БД метаданых - хранилище инормации о потоках.
Назначение - приемники данных. У меня сейчас реализованы две БД, и одно файловое хранилище.
Метаданные
Прежде, чем показать поток обработки на NIFI, необходимо уделить внимание метаданным. Метаданные можно хранить любым удобным для вас способом. Например, в виде XML файла в GIT репозитории. В текущей реализации я использую плоскую таблицу в БД.
Структура таблицы (основные элементы потока):
Параметр |
Описание |
Пример |
id |
Идентификатор потока. |
|
active |
Флаг активности потока |
|
last_start |
Последний старт потока |
Служебные поля, применяется для контроля запуска и завершения потоков |
last_complete |
Последнее завершение потока |
|
src_erp |
Имя источника |
Текст, по которому Nifi может определить источник данных. Одним из основных источников в моем случае является Oracle и БД "Галактика" - поэтому значение параметра равно "galaxy" |
src_schema |
Схема в БД |
|
src_table |
Имя таблицы или представления |
|
src_incrementkey |
Имя поля, по которому проводится инкрементальная загрузка |
О принципе инкрементальной загрузки я говорил в предыдущей части. |
src_incrementvalue |
Значение инкрементального поля |
После каждой загрузки значение вычисляется. Также его можно устанавливать внешним воздейтсвием. |
src_additionalwhere |
Дополнительное условие отбора |
Все, что будет в этом поле добавится в условие WHERE. И можно использовать выражения EL. Например: VALUE > ${now():toNumber()} |
tgt_erp |
Имя целевой системы |
|
tgt_schema |
Схема в целевой БД |
В случае, если требуется сохранить файл, тут указываю подкаталог |
tgt_table |
Тия целевой таблицы |
Для файловой системы указываю целевое имя файла |
column_list |
Список полей |
Если задано это поле, то в процессе генерации запроса к источнику подставляется данный список. Т.о. можно вставить SQL-синтаксис. |
tgt_truncate |
Очищать целевую таблицу при старте потока |
|
avro_schema |
Авро-схема |
Если требуется задать схему, то в этом поле можно ее указать. В будущем я планирую перейти на Schema Registry, и тут будет ссылка |
adddefstgfields |
Добавлять поля Stage слоя |
В данной реализации это основная трансформация, в ходе которой рассчитывается HASH записи. |
customselect |
Запрос к источнику |
Если задан этот параметр, то генерировать запрос не надо, надо использоть текущий. |
priority |
Приоритет потока |
Применяется для приоритета даных в очередях. Например, чтобы большая по объему историческая загрузка не мешала текущим задачам, можно поставить ей низкий приоритет (в Nifi чем больше знаечние, тем ниже приоритет) |
execprocedure_end |
Запрос на целевой БД, который выполнится после завершения загрузки |
Например, можно задать такой запрос: UPDATE ${paramtable} Т.о. после запуска, поток уберет в БД влаг активности, и не будет в следующий раз участвовать в загрузке. |
schedule |
Расписание через точку с запятой |
10:00;21:00;manual |
sche_to_exec |
При каком расписании запускать запрос из поля execprocedure_end |
21:00;special |
Поток зарузки
Итак, поток NIFI состоит из следующих процесных групп:

Генерация (Shedulers)
В блоке собраны все возможные генераторы, триггеры.

Для удобства я разделил генераторы на группы. Общий смысл данной процесной группы - полуить файл с заполненым атрибутом ${schedule}, по которому будут выбраны потоки из БД. В интервальной группе находятся триггеры, котрые срабатывают по интервалу, например, триггер раз в пять минут генерирует файл с расписанием 5min.
В группе TimeOfDay я генерирую файл раз в минуту, и выставляю ${schedule} = ${now():format("HH:mm")}.
Таким образом, можно поместить проццессор GenerateFlowFile с нужным интервалом или crone выражением, и поток будет загружен только при срабатывании нужного зрачения.
Инициализация (Init)
В данной группе выполняется инициализация потока. Ядром и основным элементом является получение метаданых потока:

В этом блоке я запрашиваю в БД все активные потоки с соответсвующим расписанием, выполняю проверку на результат и извлекаю знаечния в атрибуты.
Запрос простой:
SELECT * from ${paramtable}
WHERE
active = 1 AND
'${schedule}' in (
SELECT value
FROM string_split(schedule, ';')
)
ORDER BY priorityДалее в этой же группе реализованы проверки на наличие таблицы источника, таблицы назначения, определяется формат инкремента.

Также при наличии флага tgt_truncate выполняется удаление целевой таблицы. В атрибут ${database.name} помещается значение из ${src.erp}, это позволит использовать один сервис для проксирования подключенных источников.
Извлекаем данные (Extract)
В этой группе происходит гегерация запросов и выполнение их к источникам. Здесь применяется замечательный компонент DBCPConnectionPoolLookup, позволяющий перечислить все доступные системы, и выполнять доступ к ним по атрибуту ${database.name}.

В общем случае я использую компонент GererateTableFetch, предварительно выбрав, к какой системе надо генерировать запрос.

Однако данный процессор работает медленно, по раней мере к нагруженным БД гереация запросы выполнялась за несклько секунд. При повышении требований по скорости обработки решено было сделать свой генератор для основных систем - MSSql и Oracle. Использовал следующее выражение:
SELECT ${column.list:isEmpty():ifElse('*', ${column.list})}
FROM ${src.schema}.${src.table}
${src.additionalwhere:isEmpty():ifElse(${src.additionalwhere},
${src.additionalwhere:prepend('WHERE ')})}Иногда может возникнуть ситуация, когда источник долго отдате данные, либо сеть подвисла, а запросы валятся с болшой частотой. Чтобы исключить одинаковые запросы к источнику сделал простую вещь - на значимых полях и тексте запроса ситаю хеш и проверяю его на дубликат. Для этого используется либо встроенный DistributedMapCacheServer или Redis.

Если дубликатов нет, то переходим к запросам к источнику. Если задана схема, то запрос идет через ExecuteSQLRecord, в котором Writer сконфигурирован на схему в атрибуте.

Параметры ExecuteSql:

В параметрах я указываю:
Max Rows Per Flow File - eсли надо сохранять файл для Clickhouse (так грузим словари), то выгрузку не разбивать, в противном случае задаю значение из глобальной переменной.
Output Batch Size - если задан запрос, который надо выполнить в конце загрузки, то выполнять батчевую загрузку, иначе отправлять на выход по пять файлов. Батчевая загрузка позволит отследить количество фрагментов в процессе запроса.
Fetch Size - некоторые драйверы умеют принимать этот параметр: количество записей, передаваемых в пакете.
На следующем этапе я вношу в случае батчевой загрузки все фрагменты в служебную таблицу. Необходимость этого шага я поясню позже, в разделе Постзагрузки.

Трансформация (Trasnform)
В данный момент у нас применяется одна трансформация - это формирование полей Starge слоя. Эти поля и уже описывал в первой и второй части, покажу лишь небольшую автоматизацию.

Сначала извлекается авто-схема в атрибут ${avro.schema}, для этого есть процессор ExtractAvroMetadata. Далее формируется правило конкатенации полей:
${avro.schema:jsonPath("$.fields..name"):replace('[',''):
replace(']',''):replace('"',''):replace(',',',/'):replace('\r',''):
replace('\n',''):replace(' ',''):prepend('/')}И с помощью процессора UpdateRecord вычисляется хеш записи, предварительно схема модифицируется:

Загрузка (Load)
Для загрузки применяется процессор PutDataвaseRecord, предварительно в атрибут ${database.name} помещается значение из ${tgt.erp}. Изначально применялся один процессор, но в последствии в целях оптимизации производительности и разделения реалтаймовских потоков от интервальных, предварительно определяется система назначения.

Также есть группа, где потоки сохраняются в виде файлов. В ней обновляются атрибуты ${filename}, конвертируется формат в Parquet и выполняется сохранение в смонтированную NFS директорию. Далее на сервере Clickhouse эти файлы подтягиваются как словари.
Постзагрузка (Postload)
На текущем этапе выполняются два основных элемента. Это вычисление максимального значения инкрементального ключа, и выполнение запроса по окончанию загрузки.

Сначала производится вычисление максимума. Для этого применяется процессор QueryRecord, запрос имеет вид:
SELECT MAX(${src.incrementkey}) as MaxValue
FROM FLOWFILEДалее значение извлекается в атрибут и вносится в БД. Так как обработка данных является многопоточной, не факт, что фрагмент с максимальным значением придет последним. Поэтому внесение в БД реализовано скриптом - проверка на текущее значение в БД, сравнение с поступившим, и, при необходимости, обновление.
И вторая важная вещь - выполнение запроса к целевой системе после завершения загрузки в случае батча. Сначала происходит обновление информации, что текущий фрагмент загружен. Обновляется та же служебная таблица, которая заполняется на этапе выгрузки. Далее производится проверка - все ли фрагменты батча занеслись в целевую систему, и в случае успеха очищается служебная таблица.

После этого можно выполнять запрос к целевой системе, так как получена гарантия того, что батч полностью загружен.
Дальнейшие шаги являются служебными - формирования лога, выполнение уведомлений в канал Slack и так далее.
Заключение
Я постарался описать сам подход к построению параметризованного универсального потока загрузки. Конечно, у такого подхода есть и плюсы и минусы, и не всегда его можно применить. Но если у вас единый стандарт заполнения DWH, то большинство операций можно свести к одному потоку с небольшим набором ветвлений.
Преимущества
Все потоки описаны единым образом, для добавления нового потока нет необходимости привлекать разработчика Nifi, весь процесс заключается в добавлении или редактировании записи в таблице.
Любые преобразования в потоке находятся в одном месте, и количество ошибок при разработке сводится к минимуму.
Поток загрузки может быть запущен с различным расписанием, а не только по интервалу или крону. Также, добавив обработку HTTP запросов и принимая на входе JSON с параметрами, можно гибко формировать условия отбора. Мы таким образом формируем запросы к целевой системе в зависимости от преобразований в Clickhouse, формирование запроса выполняется в Airflow.
Деплой выполняется обновлением одной верхней процессором группы.
Недостатки
В данный момент есть одна плоская таблица для хранения метаданных. Ведутся разработки над более гибкой структурой - иерархическим JSON, который позволит подключать настраиваемые трансформации и выходы.
Требуется тщательно планировать большие исторические загрузки, и не отдавать этот момент аналитикам и разработчикам БД. Однако, если с ресурсами нет проблем, то этот пункт исключается.
Выполнение потока зависит от доступности внешних систем - кеша, БД метаданных и так далее.
Для управления метаданными желательно разработать интерфейс. Первые 200 потоков можно редактировать в БД, но потом таблица разрастается, возрастает вероятность ошибки.
Спасибо за то, что прочитали этот текст. Жду ваших комментариев. На вопросы могу ответить в группе телеграмм. Если есть опечатки/ошибки в тексте - сообщайте, устраню.