
Структурирование информации — очень полезный навык. И дабы привнести некоторый порядок в этап подготовки к интервью на должность Golang разработчика (и немножко техлида) решил записывать в этой заметке в формате FAQ те вопросы, которые я задавал, задавали мне или просто были мной найдены на просторах сети вместе с ответами на них. Стоит относиться к ним как к шпаргалке (если затупишь на реальном интервью — будет где подсмотреть) и просто набору тем, которым тебе стоит уделить внимание.
Я постарался копнуть в каждый вопрос чуть глубже чем, возможно, надо бы — что бы у читателя был не только короткий ответ на вопрос, но и некоторое понимание "а почему именно так устроена та или иная штука". Более того, крайне рекомендую ознакомиться и с ссылками на источники, что будут под овтетами — там вы найдете более развернутые ответы.
Да, это очень объемный пост, и врятли его можно вдумчиво осилить за один подход, но поместив его в закладки он, возможно, когда-то сослужит вам добрую службу (читать его можно по частям, находясь в метро или между вечными совещаниями; да и Ctrl + F никто не отменял). Ещё ему очень не хватает оглавления для удобной навигации между вопросами, но у хабраредактора нет возможности генерировать TOC (если будут запросы об этом в комментариях — сделаю его руками). Об очепятках, пожалуйста, пишите в личку.
Расскажи о себе?
Чаще всего этот вопрос идёт первым и даёт возможность интервьюверу задать вопросы связанные с твоим резюме, познакомиться с тобой, попытаться понять твой характер для построения последующих вопросов. Следует иметь в виду, что интервьюверу не всегда удается подготовиться к интервью, или он банально не имеет перед глазами твоего резюме. Тут есть смысл ещё раз представиться (часто в мессенджерах используются никнеймы, а твоё реальное имя он мог забыть), назвать свой возраст, образование, рассказать о предыдущих местах работы и должностях, сколько лет в индустрии, какие ЯП и технологии использовал — только "по верхам", для того чтоб твой собеседник просто понял с кем он "имеет дело".
Расскажи о своем самом интересном проекте?
К этому вопросу есть смысл подготовиться заранее и не спустя рукава. Дело в том, что это тот момент, когда тебе надо подобно павлину распустить хвост и создать правильное первое впечатление о себе, так как этот вопрос тоже очень часто идёт впереди всех остальных. Возьми и выпиши для себя где-нибудь на листочке основные тезисы о том, что это был за проект/сервис/задача, уделяя основное внимание тому какой профит это принесло для компании/команды в целом. Например:
- Я со своей командой гоферов из N человек в течении трех месяцев создали аналог сервиса у которого компания покупала данные за $4000 в месяц, а после перехода на наш сервис — расходы сократились до $1500 в месяц и значительно повысилось их качество и uptime;
- Внедренные мной практики в CI/CD пайплайны позволили сократить время на ревью изменений в проектах на 25..40%, а зная сколько стоит время работы разработчиков — вы сами всё понимаете;
- Разработанный мной сервис состоял из такого-то набора микросервисов, такие-то службы и протоколы использовал, были такие-то ключевые проблемы которые мы так-то зарешали; основной ценностью было то-то.
Кем был создан язык, какие его особенности?
Go (часто также golang) — компилируемый многопоточный язык программирования, разработанный внутри компании Google. Разработка началась в 2007 году, его непосредственным проектированием занимались Роберт Гризмер, Роб Пайк и Кен Томпсон. Официально язык был представлен в ноябре 2009 года.
В качестве ключевых особенностей можно выделить:
- Простая грамматика (минимум ключевых слов — язык создавался по принципу "что ещё можно выкинуть" вместо "что бы ещё в него добавить")
- Строгая типизация и отказ от иерархии типов (но с сохранением объектно-ориентированных возможностей)
- Сборка мусора (GC)
- Простые и эффективные средства для распараллеливания вычислений
- Чёткое разделение интерфейса и реализации
- Наличие системы пакетов и возможность импортирования внешних зависимостей (пакетов)
- Богатый тулинг "из корочки" (бенчмарки, тесты, генерация кода и документации), быстрая компиляция
Для того, чтоб вспомнить историю создания Go и о его особенностях можно посмотреть:
Go — императивный или декларативный? А в чем разница?
Go является императивным языком.
Императивное программирование — это описание того, как ты делаешь что-то (т.е. конкретно описываем необходимые действия для достижения определенного результата), а декларативное — того, что ты делаешь (например, декларативным ЯП является SQL — мы описываем что мы хотим получить от СУБД, но не описываем как именно она должна это сделать).
Что такое ООП? Как это сделано в Golang?
ООП это методология (подход) программирования, основанная на том, что программа представляет собой некоторую совокупность объектов-классов, которые образуют иерархию наследования. Ключевые фишки — минимализация повторяемости кода (принцип DRY) и удобство понимания/управления. Фундаментом ООП можно считать идею описания объектов в программировании подобно объектам из реального мира — у них есть свойства, поведение, они могут взаимодействовать. Мы (люди) так понимаем мир, и нам (людям) так проще описывать всякие штуки в коде. Основные принципы в ООП:
-
Абстракция вообще присуща для любого программирования, а не только для ООП. По большому счету (топорный, но понятный пример) это про выделение общего и объединение этого в какие-то сущности но без реализации, про контракты. Например — экземпляры абстрактных классов не могут быть созданы (
new AbstractClass), но могут содержать абстрактные методы, чтоб разработчик решив наследоваться от этого абстрактного класса их реализовал так, как ему нужно для своих целей (например — ходить в SQL СУБД или файл). Другой пример — это интерфейсы, они же контракты чистой воды — содержат только сигнатуры методов и ни капельки реализации. Но абстракция не ограничивается ими и должна быть умеренной, так как усложняет архитектуру приложения в общем и целом. Опираться следует на интуицию и опыт. Слишком много слоев абстракции (ещё раз — тут дело не ограничивается интерфейсами и абстрактными классами) приводит к переусложнению и головной боли последующего сопровождения продукта. Недостаточная — к сложности внесения изменений и расширению функционала - Инкапсуляция про контроль доступа к свойствам объекта и их динамическая валидация/преобразования. Если метод/свойство должно быть доступно "извне" объекта — объявляем публичным, иначе — приватным. Если есть необходимость переопределять его из потомков класса — то защищенным (protected). Python, например, реализуют инкапсуляцию, но не предусматривает возможности сокрытия в принципе; в то время как С++ и Java она просто всюду
- Наследование это возможность (барабанная дробь!) наследоваться одним объектам от других, "перенимая" все методы родительских объектов. Своеобразный вариант Матрешки. Т.е. выделяя в родительских объектах "всё общее" мы можем не повторяться в реализации частных, а просто "наследоваться"
-
Полиморфизм — "поли" — много, "морф" — вид. Везде, где есть интерфейсы — подразумевается полиморфизм. Суть — это контракты (интерфейсы), мы можем объявить "что-то умеет закрывать себя методом
Close()", и нам не важно что именно это будет. Реализаций может быть много, и если это что-то умеет делать то, что нам надо — нам удобнее с этим работать
Тут же можно упомянуть про знание SOLID, а именно:
- S (single responsibility principle, принцип единственной ответственности) — определенный класс/модуль должен решать только определенную задачу, максимально узко но максимально хорошо (своеобразные UNIX-way). Если для выполнения своей задачи ему требуются какие-то другие ресурсы — они в него должны быть инкапсулированы (это отсылка к принципу инверсии зависимостей)
- O (open-closed principle, принцип открытости/закрытости) — классы/модули должны быть открыты для расширения, но закрыты для модификации. Должна быть возможность расширить поведение, наделить новым функционалом, но при этом исходный код/логика модуля должна быть неизменной
- L (Liskov substitution principle, принцип подстановки Лисков) — поведение наследующих классов не должно противоречить поведению, заданному базовым классом, то есть поведение наследующих классов должно быть ожидаемым для кода
- I (interface segregation principle, принцип разделения интерфейса) — много тонких интерфейсов лучше, чем один толстый
- D (dependency inversion principle, принцип инверсии зависимостей) — "завязываться" на абстракциях (интерфейсах), а не конкретных реализациях. Так же (это уже про IoC, но всё же) можно рассказать что если какому-то классу для своей работы требуется функциональность другого — то есть смысл "запрашивать" её в конструкторе нашего класса используя интерфейс, под который подходит наша зависимость. Таким образом целевая реализация опирается только на интерфейсы (не зависит от реализаций) и соответствует принципу под буквой S
А теперь о том, как это реализовано в Go (наконец-то!).
В Go нет классов, объектов, исключений и шаблонов. Нет иерархии типов, но есть сами типы (т.е. возможность описывать свои типы/структуры). Структурные типы (с методами) служат тем же целям, что и классы в других языках. Так же следует упомянуть что структура определяет состояние.
В Go нет наследования. Совсем. Но есть встраивание (называемое "анонимным", так как Foo в Bar встраивается не под каким-то именем, а без него) при этом встраиваются и свойства, и функции:
import "fmt"
type Foo struct {
name string
Surname string
}
func (f Foo) SayName() string { return f.name }
type Bar struct {
Foo
}
func main() {
bar := Bar{Foo{name: "one", Surname: "baz"}}
fmt.Println(bar.SayName()) // one
fmt.Println(bar.Surname) // baz
bar.name = "two"
fmt.Println(bar.SayName()) // two
}Есть интерфейсы (это типы, которые объявляют наборы методов). Подобно интерфейсам в других языках, они не имеют реализации. Объекты, которые реализуют все методы интерфейса, автоматически реализуют интерфейс (так называемый Duck-typing). Не существует наследования или подклассов или ключевого слова Implements:
import "fmt"
type Speaker interface {
Speak() string
}
type Foo struct{}
func (Foo) Speak() string { return "foo" }
type Bar struct{}
func (Bar) Speak() string { return "bar" }
func main() {
var foo, bar Speaker = new(Foo), &Bar{}
fmt.Println(foo.Speak()) // foo
fmt.Println(bar.Speak()) // bar
}В примере выше мы объявили переменные foo и bar с явным указанием интерфейсного типа, а так интерфейс это "ссылочный" тип (на самом деле в Go нет ссылок, но есть указатели) — то и структуры мы инициализировали указателями на них с использованием new() (что аллоцирует структуру и возвращает указатель на неё) и (или) &.
Инкапсуляция реализована на уровне пакетов. Имена, начинающиеся со строчной буквы, видны только внутри этого пакета (не являются экспортируемыми). И наоборот — всё, что начинается с заглавной буквы — доступно извне пакета. Дешево и сердито.
Полиморфизм — это основа объектно-ориентированного программирования: способность обрабатывать объекты разных типов одинаково, если они придерживаются одного и того же интерфейса. Интерфейсы Go предоставляют эту возможность очень прямым и интуитивно понятным способом. Пример использования интерфайса был описан выше.
Что можно почитать: ООП в картинках, Golang и ООП
Как устроено инвертирование зависимостей?
Инвертирование зависимостей позволяет в нашем коде не "завязываться" на конкретную реализацию (используя, например, интерфейсы), тем самым понижая связанность кода и повышая его тестируемость. Так же сужается зона ответственности конечной структуры/пакета, что повышает его переиспользуемость.
Принцип инверсии зависимостей (dependency inversion principle) в Go который можно реализовывать следующим образом:
import (
"errors"
"fmt"
)
type speaker interface {
Speak() string
}
type Foo struct {
s speaker // s *Foo - было бы плохо
}
func NewFoo(s speaker) (*Foo, error) {
if s == nil {
return nil, errors.New("speaker is nil")
}
return &Foo{s: s}, nil
}
func (f Foo) SaySomething() string { return f.s.Speak() }
func main() {
var foo, err = NewFoo(someSpeaker)
if err != nil {
panic(err)
}
fmt.Println(foo.SaySomething()) // depends on the speaker implementation
}Мы объявляем интерфейс speaker не экспортируемым на нашей, принимающей стороне, и используя псевдо-конструктор NewFoo гарантируем что свойство s будет проинициализировано верным типом (дополнительно проверяя его на nil).
Как сделать свои методы для стороннего пакета?
Например, если мы используем логгер Zap в нашем проекте, и хотим к этому Zap-у прикрутить наши методы — то для этого нам нужно будет создать свою структуру, внутри в неё встраивать логгер Zap-а, и к этой структуре уже прикручивать требуемые методы. Просто "навесить сверху" функции на сторонний пакет мы не можем.
Типы данных и синтаксис
К фундаментальным типам данных можно отнести:
- Целочисленные —
int{8,16,32,64},int,uint{8,16,32,64},uint,byteкак синонимuint8иruneкак синонимint32. Типыintиuintимеют наиболее эффективный размер для определенной платформы (32 или 64 бита), причем различные компиляторы могут предоставлять различный размер для этих типов даже для одной и той же платформы - Числа с плавающей запятой —
float32(занимает 4 байта/32 бита) иfloat64(занимает 8 байт/64 бита) - Комплексные числа —
complex64(вещественная и мнимая части представляют числаfloat32) иcomplex128(вещественная и мнимая части представляют числаfloat64) - Логические aka
bool - Строки
string
Как устроены строки в Go?
В Go строка в действительности является слайсом (срезом) байт, доступным только для чтения. Строка содержит произвольные байты, и у неё нет ёмкости (cap). При преобразовании слайса байт в строку (str := string(slice)) или обратно (slice := []byte(str)) — происходит копирование массива (со всеми следствиями).
Создание подстрок работает очень эффективно. Поскольку строка предназначена только для чтения, исходная строка и строка, полученная в результате операции среза, могут безопасно совместно использовать один и тот же массив:
var (
str = "hello world"
sub = str[0:5]
usr = "/usr/kot"[5:]
)
print(sub, " ", usr) // hello kotGo использует тип rune (алиас int32) для представления Unicode. Конструкция for ... range итерирует строку посимвольно (а не побайтово, как можно было бы предположить):
var str = "привет"
println(str, len(str)) // привет 12
for i, c := range str {
println(i, c, string(c))
}
// 0 1087 п
// 2 1088 р
// 4 1080 и
// 6 1074 в
// 8 1077 е
// 10 1090 тИ мы видим, что для кодирования каждого символа кириллицы используются по 2 байта.
Эффективным способом работы со строками (когда есть необходимость часто выполнять конкатенацию, например) является использование слайса байт или strings.Builder:
import "strings"
func main() { // происходит только 1 аллокация при вызове `Grow()`
var str strings.Builder
str.Grow(12) // сразу выделяем память
str.WriteString("hello")
str.WriteRune(' ')
str.WriteString("мир")
println(str.String()) // hello мир
}И ещё одну важную особенность стоит иметь в виду — это подсчет длины строки (например — для какой-нибудь валидации). Если считать по количеству байт, и строка содержит не только ASCII символы — то количество байт и фактическое количество символов будут расходиться:
const str = "hello мир!"
println(len(str), utf8.RuneCountInString(str)) // 13 10Тут дело в том, что для кодирования символов м, и и р используются 2 байта вместо одного. Поэтому len == 13, а фактически в строке лишь 10 символов (пакет utf8, к примеру, нам в помощь).
Что можно почитать: Строка, байт, руна, символ в Golang
В чём ключевое отличие слайса (среза) от массива?
- Срез — всегда указатель на массив, массив — значение
- Срез может менять свой размер и динамически аллоцировать память
В Go не бывает ссылок — но есть указатели. Где говорится про "по ссылке" имеется в виду "по указателю"
Слайсы и массивы в Go это упорядоченные структуры данных последовательностей элементов. Ёмкость массива объявляется в момент его создания, и после изменить её уже нельзя (его длина это часть его типа). Память, необходимая для хранения элементов массива выделяется соответственно сразу при его объявлении, и по умолчанию инициализируется в соответствии с нулевыми значением для типа (fasle для bool, 0 для int, nil для интерфейсов и т.д.). На стеке можно разместить массив объемом 10 MB. В качестве размера можно использовать константы (компилятор должен знать это значение на этапе компиляции, т.е. что-то вида var a [getSize()]int или i := 3; var a [i]int недопустимо):
const mySize uint8 = 8
type myArray [mySize]byte
var constSized = [...]int{1, 2, 3} // размер сам посчитается исходя из кол-ва эл-овКстати, массивы с элементами одного типа но с разными размерами являются разными типами. Массивы не нужно инициализировать явно; нулевой массив — это готовый к использованию массив, элементы которого являются нулями:
var a [4]int // [0 0 0 0]
a[0] = 1 // [1 0 0 0]
i := a[0] // i == 1Представление [4]int в памяти — это просто четыре целых значения, расположенных последовательно. Так же следует помнить что в Go массивы передаются по значению, т.е. передавая массив в какую-либо функцию она получает копию массива (для передачи его указателя нужно явно это указывать, т.е. foo(&a)).
А слайс же это своего рода версия массива но с вариативным размером (структура данных, которая строится поверх массива и предоставляет доступ к элементами базового массива). Слайсы до 64 KB могут быть размещены на стеке. Если посмотреть исходники Go (src/runtime/slice.go), то увидим:
type slice struct {
array unsafe.Pointer // указатель на массив
len int // длина (length)
cap int // вместимость (capacity)
}Для аллокации слайса можно воспользоваться одной из команд ниже:
var (
a = []int{} // [] len=0 cap=0
b = []int{1, 2} // [1 2] len=2 cap=2
c = []int{5: 123} // [0 0 0 0 0 123] len=6 cap=6
d = make([]int, 5, 10) // [0 0 0 0 0] len=5 cap=10
)В последнем случае рантайм Go создаст массив из 10 элементов (выделит память и заполнит их нулями) но доступны прямо сейчас нам будут только 5, и установит значения len в 5, а cap в 10. Cap означает ёмкость и помогает зарезервировать место в памяти на будущее, чтобы избежать лишних операций выделения памяти при росте слайса (это ключевой параметр для аллокации памяти, влияет на производительность вставки в срез). При добавлении новых элементов в слайс новый массив для него не будет создаваться до тех пор, пока cap меньше len.
Слайсы передаются "по ссылке" (фактически будет передана копия структуры slice со своими len и cap, но указатель на массив array будет тот-же самый). Для защиты слайса от изменений следует передавать его копию:
var (
a = []int{1, 2, 0, 0, 1}
b = make([]int, len(a))
)
copy(b, a)
fmt.Println(a, b) // [1 2 0 0 1] [1 2 0 0 1]Важной особенностью является то, так как "под капотом" у слайса лежит указатель на массив — при изменении значений слайса они будут изменяться везде, где слайс используется (будь то присвоение в переменную, передача в функцию и т.д.) до момента, пока размер слайса не будет переполнен и не будет выделен новый массив для его значений (т.е. в момент изменения cap слайса всегда происходит копирование данных массива):
var (
one = []int{1, 2} // [1 2]
two = one // [1 2]
)
two[0] = 123
fmt.Println(one, two) // [123 2] [123 2]
one = append(one, 666)
fmt.Println(one, two) // [123 2 666] [123 2]Что можно почитать: Как не наступать на грабли в Go, Слайсы в Go: использование и особенности, Принцип работы типа slice в GO
Как вы отсортируете массив структур по алфавиту по полю Name?
Например, преобразую массив в слайс и воспользуюсь функцией sort.SliceStable:
package main
import (
"fmt"
"sort"
)
func main() {
var arr = [...]struct{ Name string }{{Name: "b"}, {Name: "c"}, {Name: "a"}}
// ^^^^^^^^^^^^^^^^^^^^^ анонимная структура с нужным нам полем
fmt.Println(arr) // [{b} {c} {a}]
sort.SliceStable(arr[:], func(i, j int) bool { return arr[i].Name < arr[j].Name })
// ^^^ вот тут вся "магия" - из массива сделали слайс
fmt.Println(arr) // [{a} {b} {c}]
}Вся магия в том, что при создании слайса из массива "под капотом" у слайса начинает лежать исходный массив, и функции из пакета sort нам становятся доступны над ними. Т.е. изменяя порядок элементов в слайсе функцией sort.SliceStable мы будем менять их в нашем исходном массиве.
Как работает append в слайсе?
append() делает простую операцию — добавляет элементы в слайс и возвращает новый. Но под капотом там делаются довольно сложные манипуляции, чтобы выделять память только при необходимости и делать это эффективно.
Сперва append сравнивает значения len и cap у слайса. Если len меньше чем cap, то значение len увеличивается, а само добавляемое значение помещается в конец слайса. В противном случае происходит выделение памяти под новый массив для элементов слайса, в него копируются значения из старого, и значение помещается уже в новый массив.
Увеличении размера слайса (метод growslice) происходит по следующему алгоритму — если его размер менее 1024 элементов, то его размер будет увеличиваться вдвое; иначе же слайс увеличивается на ~12.5% от своего текущего размера.
Что важно помнить — если на основании слайса one выделить подслайс two, а затем увеличим слайс one (и его вместимость будет превышена) — то one и two будут уже ссылаться на разные участки памяти!
var (
one = make([]int, 4) // [0 0 0 0]
two = one[1:3] // [0 0]
)
one[2] = 11
fmt.Println(one, two) // [0 0 11 0] [0 11]
fmt.Printf("%p %p\n", one, two) // 0xc0000161c0 0xc0000161c8
one = append(one, 1)
fmt.Printf("%p %p\n", one, two) // 0xc00001c1c0 0xc0000161c8
one[2] = 22
fmt.Println(one, two) // [0 0 22 0 1] [0 11]
fmt.Printf("%p %p\n", one, two) // 0xc00001c1c0 0xc0000161c8Есть еще много примеров добавления, копирования и других способов использования слайсов тут — Slice Tricks.
Что можно почитать: Как не наступать на грабли в Go
Задача про слайсы #1
Вопрос: У нас есть 2 функции — одна делает append() чего-то в слайс, а другая просто сортирует слайс, используя пакет sort. Модифицируют ли слайс первая и (или) вторая функции?
Ответ: append() не модифицирует а возвращает новый слайс, а sort модифицирует порядок элементов, если он изначально был не отсортирован.
Задача про слайсы #2
Вопрос: Что выведет следующая программа?
package main
import "fmt"
func main() {
a := [5]int{1, 2, 3, 4, 5}
t := a[3:4:4]
fmt.Println(t[0])
}Выведет 4
Объяснение: Такой синтаксис позволяет задать capacity (вместимость) для полученного под-слайса, который будет равен "последний элемент минус первый элемент из выражения в квадратных скобках", т.е. из примера выше он будет равен 1 (т.к. от четырёх, т.е. третьего сегмента вычитаем первый, т.е. тройку). Если бы выражение имело вид a[3:4:5], то cap была бы равна 2 (5 — 3 = 2). Но при этом на сами данные он не влияет.
Появилась эта штука в Go 1.2.
Что можно почитать: Slicing a slice with slice [a : b : c], Full slice expressions
Какое у слайса zero value? Какие операции над ним возможны?
Zero value у слайса всегда nil, а len и cap равны нулю, так как "под ним" нет инициализированного массива:
var a []int
println(a == nil, len(a), cap(a)) // true 0 0
a = append(a, 1)
println(a == nil, len(a), cap(a)) // false 1 1Как видно из примера выше — несмотря на то, что a == nil (слайс "не инициализирован"), с этим слайсом возможна операция append — в этом случае Go самостоятельно создаёт нижележащий массив и всё работает так, как и ожидается. Более того — для полной очистки слайса рекомендуется его присваивать к nil.
Так же важно помнить, что не делая make для слайса — не получится сделать пре-аллокацию, что часто очень болезненно для производительности.
Что можешь рассказать про map?
Карта (map или hashmap) — это неупорядоченная коллекция пар вида ключ-значение. Пример:
type myMap map[string]intПодобно массивам и слайсам, к элементам мапы можно обратиться с помощью скобок:
var m = make(map[string]int) // инициализация
m["one"] = 1 // запись в мапу
fmt.Println(m["one"], m["two"]) // 1 0Лучше выделить память заранее (передавая вторым аргументом функции make), если известно количество элементов — избежим эвакуаций
В случае с m["two"] вернулся 0 так как это является нулевым значением для типа int. Для проверки существования ключа используем конструкцию вида (доступ к элементу карты может вернуть два значения вместо одного) называемую "multiple assignment":
var m = map[string]int{"one": 1}
v1, ok1 := m["one"] // чтение
v2, ok2 := m["two"]
fmt.Println(v1, ok1) // 1 true
fmt.Println(v2, ok2) // 0 false
for k, v := range m { // итерация всех эл-ов мапы
fmt.Println(k, v)
}
delete(m, "one") // удаление
v1, ok1 = m["one"]
fmt.Println(v1, ok1) // 0 falseМапы всегда передаются по ссылке (вообще-то Go не бывает ссылок, невозможно создать 2 переменные с 1 адресом, как в С++ например; но зато можно создать 2 переменные, указывающие на один адрес — но это уже указатели). Если же быть точнее, то мапа в Go — это просто указатель на структуру hmap:
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}Так же структура hmap содержит в себе следующее:
- Количество элементов
- Количество "ведер" (представлено в виде логарифма для ускорения вычислений)
- Seed для рандомизации хэшей (чтобы было сложнее заddosить — попытаться подобрать ключи так, что будут сплошные коллизии)
- Всякие служебные поля и главное указатель на buckets, где хранятся значения
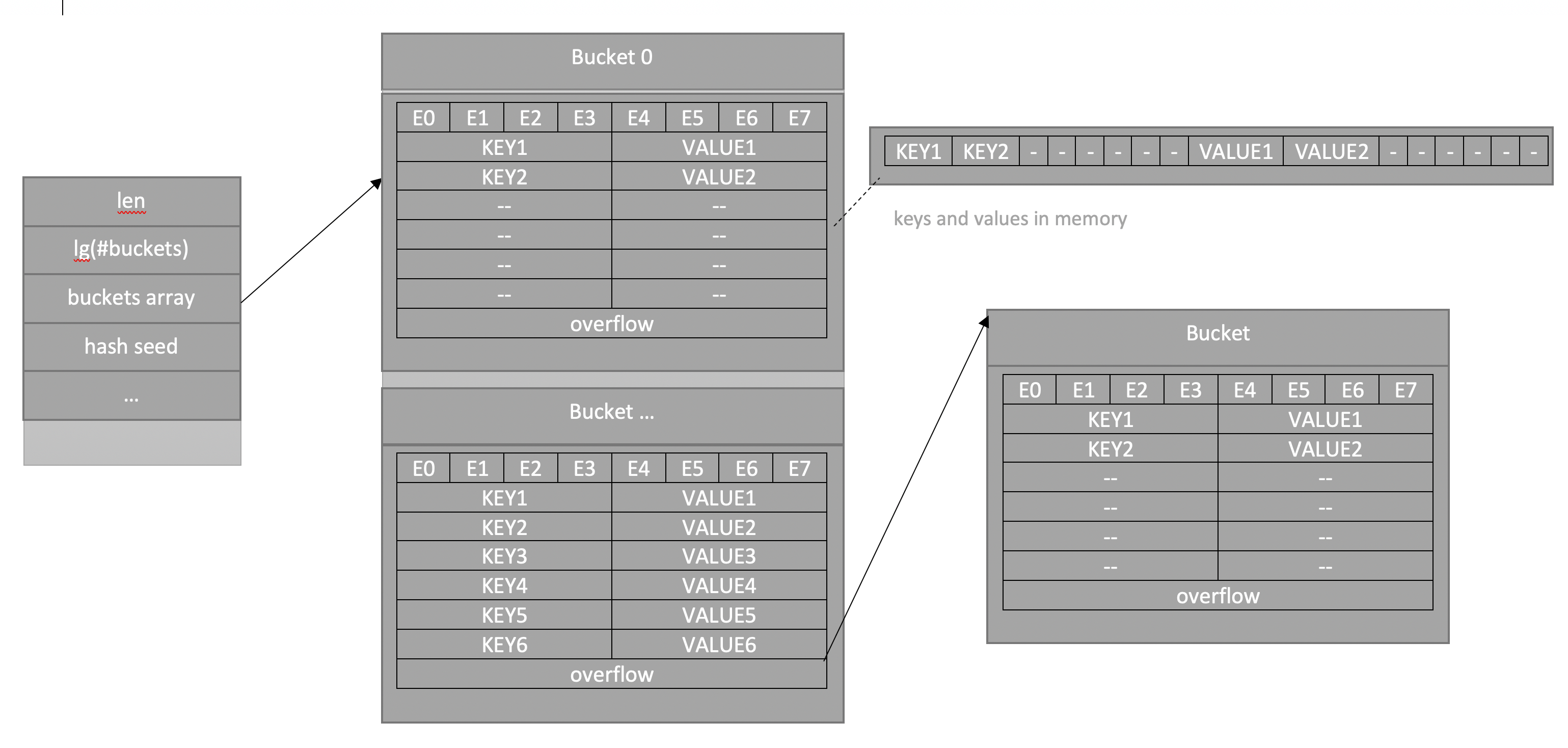
На картинке схематичное изображение структуры в памяти — есть хэдер hmap, указатель на который и есть map в Go (именно он создается при объявлении с помощью var, но не инициализируется, из-за чего падает программа при попытке вставки). Поле buckets — хранилище пар ключ-значение, таких "ведер" несколько, в каждом лежит 8 пар. Сначала в "ведре" лежат слоты для дополнительных битов хэшей (e0..e7 названо e — потому что extra hash bits). Далее лежат ключи и значения как сначала список всех ключей, потом список всех значений.
По хэш функции определяется в какое "ведро" мы кладем значение, внутри каждого "ведра" может лежать до 8 коллизий, в конце каждого "ведра" есть указатель на дополнительное, если вдруг предыдущее переполнилось.
Как растет map?
В исходном коде можно найти строчку Maximum average load of a bucket that triggers growth is 6.5. То есть, если в каждом "ведре" в среднем более 6,5 элементов, происходит увеличение массива buckets. При этом выделяется массив в 2 раза больше, а старые данные копируются в него маленькими порциями каждые вставку или удаление, чтобы не создавать очень крупные задержки. Поэтому все операции будут чуть медленнее в процессе эвакуации данных (при поиске тоже, нам же приходится искать в двух местах). После успешной эвакуации начинают использоваться новые данные.
Из-за эвакуации данных нельзя и взять адрес мапы — представьте, что мы взяли адрес значения, а потом мапа выросла, выделилась новая память, данные эвакуировались, старые удалились, указатель стал неправильным, поэтому такие операции запрещены.
Что там про поиск?
Поиск, если разобраться, устроен не так уж и сложно: проходимся по цепочкам "ведер", переходя в следующее, если в этом не нашли. Поиск в "ведре" начинается с быстрого сравнения дополнительного хэша, для которого используется всего 8 бит (вот для чего эти e0...e7 в начале каждого — это "мини" хэш пары для быстрого сравнения). Если не совпало, идем дальше, если совпало, то проверяем тщательнее — определяем где лежит в памяти ключ, подозреваемый как искомый, сравниваем равен ли он тому, что запросили. Если равен, определяем положение значения в памяти и возвращаем.
К сожалению, мир не совершенен. Когда имя хешируется, то некоторые данные теряются, так как хеш, как правило, короче исходной строки. Таким образом, в любой реализации хеш таблицы неизбежны коллизии когда по двум ключам получаются одинаковые хеши. Как следствие, поиск может быть дороже чем O(1) (возможно это связано с кешем процессора и коллизиями коротких хэшей), так что иногда выгоднее использовать бинарный поиск по слайсу данных нежели чем поиск в мапе (пишите бенчмарки).
Что можно почитать: Хэш таблицы в Go. Детали реализации, Кажется, поиск в map дороже чем O(1)
Есть ли у map такие же методы как у слайса: len, cap?
У мапы есть len но нет cap. У нас есть только overflow который указывает "куда-то" когда мапа переполняется, и поэтому у нас не может быть capacity.
Какие типы ключей разрешены для ключа в map?
Любым сравнимым (comparable) типом, т.е. булевы, числовые, строковые, указатели, канальные и интерфейсные типы, а также структуры или массивы, содержащие только эти типы. Слайсы, мапы и функции использовать нельзя, так как эти типы не сравнить с помощью оператора == или !=.
Может ли ключом быть структура? Если может, то всегда ли?
Как было сказано выше — структура может быть ключом до тех пор, пока мы в поля структуры не поместим какой-либо слайс, мапу или любой другой non-comparable тип данных (например — функцию).
Что будет в map, если не делать make или short assign?
Будет паника (например — при попытке что-нибудь в неё поместить), так как любые "структурные" типы (а мапа как мы знаем таковой является) должны быть инициализированы для работы с ними.
Race condition. Потокобезопасна ли мапа?
Нет, потокобезопасной является sync.Map. Для обеспечения безопасности вокруг мапы обычно строится структура вида:
type ProtectedIntMap struct {
mx sync.RWMutex
m map[string]int
}
func (m *ProtectedIntMap) Load(key string) (val int, ok bool) {
m.mx.RLock()
val, ok = m.m[key]
m.mx.RUnlock()
return
}
func (m *ProtectedIntMap) Store(key string, value int) {
m.mx.Lock()
m.m[key] = value
m.mx.Unlock()
}Что такое интерфейс?
Интерфейсы — это инструменты для определения наборов действий и поведения. Интерфейсы — это в первую очередь контракты. Они позволяют объектам опираться на абстракции, а не фактические реализации других объектов. При этом для компоновки различных поведений можно группировать несколько интерфейсов. В общем смысле — это набор методов, представляющих стандартное поведение для различных типов данных.
Как устроен Duck-typing в Go?
Если это выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, утка и есть.
Если структура содержит в себе все методы, что объявлены в интерфейсе, и их сигнатуры совпадают — она автоматически удовлетворяет интерфейс.
Такой подход позволяет полиморфно (полиморфизм — способность функции обрабатывать данные разных типов) работать с объектами, которые не связаны в иерархии наследования. Достаточно, чтобы все эти объекты поддерживали необходимый набор методов.
Интерфейсный тип
В Go интерфейсный тип выглядит вот так:
type iface struct {
tab *itab
data unsafe.Pointer
}Где tab — это указатель на Interface Table или itable — структуру, которая хранит некоторые метаданные о типе и список методов, используемых для удовлетворения интерфейса, а data указывает на реальную область памяти, в которой лежат данные изначального объекта (статическим типом).
Компилятор генерирует метаданные для каждого статического типа, в которых, помимо прочего, хранится список методов, реализованных для данного типа. Аналогично генерируются метаданные со списком методов для каждого интерфейса. Теперь, во время исполнения программы, runtime Go может вычислить itable на лету (late binding) для каждой конкретной пары. Этот itable кешируется, поэтому просчёт происходит только один раз.
Зная это, становится очевидно, почему Go ловит несоответствия типов на этапе компиляции, но кастинг к интерфейсу — во время исполнения.
Что важно помнить — переменная интерфейсного типа может принимать nil. Но так как объект интерфейса в Go содержит два поля: tab и data — по правилам Go, интерфейс может быть равен nil только если оба этих поля не определены (faq):
var (
builder *strings.Builder
stringer fmt.Stringer
)
fmt.Println(builder, stringer) // nil nil
fmt.Println(stringer == nil) // true
fmt.Println(builder == nil) // true
stringer = builder
fmt.Println(builder, stringer) // nil nil
fmt.Println(stringer == nil) // false (!!!)
fmt.Println(builder == nil) // trueПустой interface{}
Ему удовлетворяет вообще любой тип. Пустой интерфейс ничего не означает, никакой абстракции. Поэтому использовать пустые интерфейсы нужно в самых крайних случаях.
Что можно почитать: Краш-курс по интерфейсам в Go, Реализация интерфейсов в Golang, Интерфейсы в Go — как красиво выстрелить себе в ногу
На какой стороне описывать интерфейс — на передающей или принимающей?
Многое зависит от конкретного случая, но по умолчанию описывать интерфейсы следует на принимающей стороне — таким образом, ваш код будет меньше зависеть от какого-то другого кода/пакета/реализации.
Другими словами, если нам в каком-то месте требуется "что-то что умеет себя закрывать", или — умеет метод Close() error, или (другими словами) удовлетворят интерфейсу:
type something interface {
Close() error
}То он (интерфейс) должен быть описан на принимающей стороне. Так принимающая сторона не будет ничего знать о том, что именно в неё может "прилететь", но точно знает поведение этого "чего-то". Таким образом реализуется инверсия зависимости, и код становится проще переиспользовать/тестировать.
Что такое замыкание?
Замыкания — это такие функции, которые вы можете создавать в рантайме и им будет доступно текущее окружение, в рамках которого они были созданы.
Функции, у которых есть имя — это именованные функции. Функции, которые могут быть созданы без указания имени — это анонимные функции.
func main() {
var text = "some string"
var ourFunc = func() { // именованное замыкание
println(text)
}
ourFunc() // some string
getFunc()() // another string
}
func getFunc() func() {
return func() { // анонимное
println("another string")
}
}Замыкания сохраняют состояние. Это означает, что состояние переменных содержится в замыкании в момент декларации. Одна из самых очевидных ловушек — это создание замыканий в цикле:
var funcs = make([]func(), 0, 5)
for i := 0; i < 5; i++ {
funcs = append(funcs, func() { println("counter =", i) })
// исправляется так:
//var value = i
//funcs = append(funcs, func() { println("counter =", value) })
}
for _, f := range funcs {
f()
}
// counter = 5 (так все 5 раз)Что можно почитать: Замыкания
Что такое сериализация? Зачем она нужна?
Сериализация — это процесс преобразования объекта в поток байтов для сохранения или передачи. Обратной операцией является десериализация (т.е. восстановление объекта/структуры из последовательности байтов). Синонимом можно считать термин "маршалинг" (от англ. marshal — упорядочивать).
Из минусов сериализации можно выделить нарушение инкапсуляции, т.е. после сериализации "приватные" свойства структур могут быть доступны для изменения.
Типичными примерами сериализации в Go являются преобразование структур в json-объекты. Кроме json существуют различные кодеки типа MessagePack, CBOR и т.д.
Что такое type switch?
Проверка типа переменной, а не её значения. Может быть в виде одного switch и множеством case:
package main
func checkType(i interface{}) {
switch i.(type) {
case int:
println("is integer")
case string:
println("is string")
default:
println("has unknown type")
}
}А может в виде if-конструкции:
package main
func main() {
var any interface{}
any = "foobar"
if s, ok := any.(string); ok {
println("this is a string:", s)
}
// а так можно проверить наличие функций у структуры
if closable, ok := any.(interface{ Close() }); ok {
closable.Close()
}
}Какие битовые операции знаешь?
Побитовые операторы проводят операции непосредственно на битах числа.
// Побитовое И/AND (разряд результата равен 1 только тогда, когда оба соответствующих бита операндов равны 1)
println(0b111_000 /* 56 */ & 0b011_110 /* 30 */ == 0b011_000 /* 24 */)
// Побитовое ИЛИ/OR (разряд результата равен 0 только тогда, когда оба соответствующих бита в равны 0)
println(0b111_000 /* 56 */ | 0b011_110 /* 30 */ == 0b111_110 /* 62 */)
// Исключающее ИЛИ/XOR (разряд результата равен 1 только тогда, когда только один бит равен 1)
println(0b111_000 /* 56 */ ^ 0b011_110 /* 30 */ == 0b100_110 /* 38 */)
// Сброс бита AND NOT
println(0b111_001 /* 57 */ &^ 0b011_110 /* 30 */ == 0b100_001 /* 33 */)
// Сдвиг бита влево
println(0b000_001 /* 1 */ << 3 == 0b001_000 /* 8 */)
// Сдвиг бита вправо
println(0b000_111 /* 7 */ >> 1 == 0b000_011 /* 3 */)Пример использования простой битовой маски:
type Bits uint8
const (
F0 Bits = 1 << iota // 0b00_000_001 == 1
F1 // 0b00_000_010 == 2
F2 // 0b00_000_100 == 4
)
func Set(b, flag Bits) Bits { return b | flag }
func Clear(b, flag Bits) Bits { return b &^ flag }
func Toggle(b, flag Bits) Bits { return b ^ flag }
func Has(b, flag Bits) bool { return b&flag != 0 }
func main() {
var b Bits
b = Set(b, F0)
b = Toggle(b, F2)
for i, flag := range [...]Bits{F0, F1, F2} {
println(i, Has(b, flag))
}
// 0 true
// 1 false
// 2 true
}Что можно почитать: О битовых операциях, Поразрядные операции
Дополнительный блок фигурных скобок в функции
Его можно использовать, и он означает отдельный скоуп для всех переменных, объявленных в нём (возможен и "захват переменных" объявленных вне скоупа ранее, естественно). Иногда используется для декомпозиции какого-то отдельного куска функции, к примеру.
var i, s1 = 1, "foo"
{
var j, s2 = 2, "bar"
println(i, s1) // 1 foo
println(j, s2) // 2 bar
s1 = "baz"
}
println(i, s1) // 1 baz
//println(j, s2) // ERROR: undefined: j and s2Так же это может быть связано с AST (Abstract Syntax Tree) — когда оно строится и происходят SSA (Static Single Assignment) оптимизации, к сожалению SSA не работает на всю длину дерева. Как следствие, если у нас слишком длинная функция (примерно дохулион строк) и мы по каким-то причинам не можем её декомпозировать, но можем изолировать какие-то скоупы то, таким образом, мы помогаем SSA произвести оптимизации (если они возможно).
Что такое захват переменной?
Во вложенном скоупе есть возможность обращаться к переменным, объявленных в скоупе выше (но не наоборот). Обращение к переменным из вышестоящего скоупа и есть их захват. Типичной ошибкой является использование значение итератора в цикле:
var out []*int
for i := 0; i < 3; i++ {
out = append(out, &i)
}
println(*out[0], *out[1], *out[2]) // 3 3 3Испраляется путём создания локальной (для скоупа цикла) переменной с копией знаяения итератора:
var out []*int
for i := 0; i < 3; i++ {
i := i // Copy i into a new variable.
out = append(out, &i)
}
println(*out[0], *out[1], *out[2]) // 0 1 2Что можно почитать: Using reference to loop iterator variable
Как работает defer?
Defer является функцией отложенного вызова. Выполняется всегда (даже в случае паники внутри функции вызываемой) после того, как функция завершила своё выполнение но до того, как управление вернётся вызывающей стороне (более того — внутри defer возможен захват переменных, и даже возвращаемого результата). Часто используется для освобождения ресурсов/снятия блокировок. Пример использования:
func main() {
println("result =", f())
// f started
// defer
// defer in defer
// result = 25
}
func f() (i int) {
println("f started")
defer func() {
recover()
defer func() { println("defer in defer"); i += 5 }()
println("defer")
i = i * 2
}()
i = 10
panic("panic is here")
}Когда выполняется ключевое слово defer, оно помещает следующий за ним оператор в список, который будет вызван до возврата функции.
Как работает init?
В Go есть предопределенная функция init(). Она выделяет фрагмент кода, который должен выполняться перед всеми другими частями пакета. Этот код будет выполняться сразу после импорта пакета.
Также функция init() используется для автоматической регистрации одного пакета в другом (например, так работает подавляющее большинство "драйверов" для различных СУБД, например — go-sql-driver/mysql/driver.go).
Функцию init() можно использовать неоднократно в рамках даже одного файла, выполняться они будут в этом случае в порядке, как их встречает компилятор.
Хотя использование init() и является довольно полезным, но часто оно затрудняет чтение/понимание кода, и (почти) всегда можно обойтись без неё, поэтому необходимость её использования — всегда очень большой вопрос.
Прерывание for/switch или for/select
Что произойдёт в следующем примере, если f() вернёт true?
for {
switch f() {
case true:
break
case false:
// Do something
}
}Очевидно, будет вызван break. Вот только прерван будет switch, а не цикл for. Простое решение проблемы – использовать именованный (labeled) цикл и вызывать break c этой меткой, как в примере ниже:
loop:
for {
switch f() {
case true:
break loop
case false:
// Do something
}
}Сколько можно возвращать значений из функции?
Теоретически, неограниченное количество значений. Так же хочется отметить, что есть правила "де-факто", которых следует придерживаться:
- Последним значением возвращать ошибку, если её возврат подразумевается
- Первым значением возвращать контекст, если он подразумевается
- Хорошим тоном является не возвращать более четырёх значений
- Если функция что-то проверяет и возвращает значение + булевый результат проверки — то результат проверки возвращать последним (пример —
os.LookupEnv(key string) (string, bool)) - Если возвращается ошибка, то остальные значения возвращать нулевыми или
nil
Дженерики — это про что?
Дженерики, или обобщения — это средства языка, позволяющего работать с различными типами данных без изменения их описания.
В версии 1.18 появились дженерики (вообще-то они были и ранее, но мы не могли их использовать в своём коде — вспомни функцию make(T type)), и они позволяют объявлять (описывать) универсальные методы, т.е. в качестве параметров и возвращаемых значений указывать не один тип, а их наборы.
Появились новые ключевые слова:
-
any— аналогinterface{}, можно использовать в любом месте (func do(v any) any,var v any,type foo interface { Do() any }) -
comparable— интерфейс, который определяет типы, которые могут быть сравнены с помощью==и!=(переменные такого типа создать нельзя —var j comparableбудет вызывать ошибку)
И появилась возможность определять интерфейсы, которые можно будет использовать в параметризованных функциях и типах (переменные такого типа создать нельзя — var j Int будет вызывать ошибку):
type Int interface {
int | int32 | int64
}Если добавить знак ~ перед типами то интерфейсу будут соответствовать и производные типы, например myInt из примера ниже:
type Int interface {
~int | ~int32 | ~int64
}
type myInt intРазработчики golang создали для нас уже готовый набор интерфейсов (пакет constraints), который очень удобно использовать.
Параметризованные функции
Рассмотрим пример функции, что возвращает максимум из двух переданных значений, причём тип может быть любым:
import "constraints"
func Max[T constraints.Ordered](a T, b T) T {
if a > b {
return a
}
return b
}Ограничения на используемые типы описываются в квадратных скобочках. В качестве ограничения для типов можно использовать любой интерфейс и особые интерфейсы описанные выше.
Для слайсов и мап был создан набор готовых полезных функций.
Параметризованные типы
import "reflect"
type myMap[K comparable, V any] map[K]V
func main() {
m := myMap[int, string]{5: "foo"}
println(m[5]) // foo
println(reflect.TypeOf(m)) // main.myMap[int,string]
}Что можно почитать: Зачем нужны дженерики в Go?, Golang пощупаем дженерики
Память и управление ей
Что такое heap и stack?
Стек (stack) — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Стек быстрый, так как часто привязан к кэшу процессора. Размер стека ограничен, и задаётся при создании потока.
Куча (heap) — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. То что попадает в кучу, живёт там пока не придёт GC.
Но почему стек так быстр? Основных причин две:
- Стеку не нужно иметь сборщик мусора (garbage collector). Как мы уже упоминали, переменные просто создаются и затем вытесняются, когда функция завершается. Не нужно запускать сложный процесс освобождения памяти от неиспользуемых переменных и т.п.
- Стек принадлежит одной горутине, переменные не нужно синхронизировать в сравнении с теми, что находятся в куче. Что также повышает производительность
Где выделяется память под переменную? Можно ли этим управлять?
Прямых инструментов для управления местом, где будет выделена память у нас, к сожалению — нет. Но есть некоторые практики, которые позволяют это понять и использовать эффективно.
Память под переменную может быть выделена в куче (heap) или стеке (stack). Очень приблизительно:
- Стек содержит последовательность переменных для заданной горутины (как только функция завершила работу, переменные вытесняются из стека)
- Куча содержит общие (shared) переменные (глобальные и т.п.)
Давайте рассмотрим простой пример, в котором вы возвращаем значение:
func getFooValue() foo {
var result foo
// Do something
return result
}Здесь переменная result создаётся в текущей горутине. И эта переменная помещается в стек. Как только функция завершает работу, клиент получает копию этой переменной. Исходная переменная вытесняется из стека. Эта переменная всё ещё существует в памяти, до тех пор, пока не будет затёрта другой переменной, но к этой переменной уже нельзя получить доступ.
Теперь тот же пример, но с указателем:
func getFooPointer() *foo {
var result foo
// Do something
return &result
}Переменная result также создаётся текущей горутиной, но клиент получает указатель (копию адреса переменной). Если result вытеснена из стека, клиент функции не сможет получить доступ к переменной.
В подобном сценарии компилятор Go вынужден переместить переменную result туда, где она может быть доступна (shared) – в кучу (heap).
Хотя есть и исключение. Для примера:
func main() {
p := &foo{}
f(p)
}Поскольку мы вызываем функцию f() в той же горутине, что и функцию main(), переменную p не нужно перемещать. Она просто находится в стеке и вложенная функция f() будет иметь к ней доступ.
В качестве заключения, когда мы создаём функцию — поведением по умолчанию должно быть использование передачи по значению, а не по указателю. Указатель должен быть использован только когда мы действительно хотим переиспользовать данные.
Как работает Garbage Collection (GC) в Go?
Garbage Collection — это процесс освобождения места в памяти, которая больше не используется. Стек освобождается быстро и просто (условно-самостоятельно), а вот с кучей имеются некоторые сложности.
В основе работы GC в Go лежит:
- "Трехцветный алгоритм пометки и очистки" (выполняется параллельно с основной программой) — все данные в куче представляются в виде связанного графа, каждая вершина которого (каждый объект, данные) может быть помечена как "белая", "серая", или "чёрная"; данный граф обходится в несколько проходов, все вершины размечаются своими цветами, и "белые" (мусорные) объекты могут быть удалены ("чёрные" — точно нельзя удалять; "серые" — под вопросом, пока не трогать)
- Write Barrier, следящий за тем, чтоб черные объекты не указывали на белые; и "останавливать мир" (Stop The World, STW) для включения или отключения Write Barrier
GC можно вызвать ручками — runtime.GC(), но пользоваться этим нужно с осторожностью (есть риск блокировки вызывающей стороны или всего приложения целиком).
По умолчанию, GC запускается самостоятельно когда размер кучи становится в 2 раза больше (за это отвечает Pacer; данный коэффициент можно регулировать при сборке с помощью env GOGC).
Полный цикл работы GC:
-
Sweep termination — фаза завершения очистки:
- Stop the World
- Ожидаем пока все горутины достигнут safe-point
- Завершаем очистку ресурсов
-
Mark phase — фаза разметки (выполняется конкурентно с основной программой, выделяется на неё ~25% CPU):
- Включаем Write Barrier
- Start the World
- Запускаем сканирование глобальных переменных и стеков
- При сканировании работа горутины приостанавливается (но не происходит полная остановка всей программы)
- Выполняем 3-х цветный алгоритм поиска мусора
-
Mark termination — фаза завершения разметки
- Stop the World (не является обязательной, но с ней проце было реализовать)
- Дожидаемся завершения обработки последних задач из очереди
- Очистка кэшей
- Завершаем разметку
-
Sweep phase — фаза очистки
- Отключаем Write Barrier
- Start The World
- Очистка ресурсов происходит в фоне
???? Недостатки:
- Не реализован алгоритм поколений (GC Generations)
- Не реализовано уплотнение
- Stop the World (STW), вызываемый аж дважды
- Нет возможности тонкой настройки
Для оптимизации можно:
- Уменьшить частоту вызова GC с помощью
GOGC - Использовать балласт (выделять большое количество памяти при запуске приложения
make([]byte, 10 << 30) // 10 GiB), который увеличивает базовый размер кучи, не будет выделен как мусор, помечается заO(1), и выделяется в виртуальном пространстве не используя физическую память - Использовать
sync.Pool(он хорошо дружит с GC)
Какое поведение по умолчанию используется в Go при передаче в функцию?
По умолчанию всегда используется копирование, т.е. передача по значению. Для передачи по указателю необходимо это явно указывать:
func main() {
var i = 5
byValue(i) // 5
byPointer(&i) // 5
}
func byValue(i int) { println(i) } // передача по значению (копии переменной)
func byPointer(i *int) { println(*i) } // передача по указателюЧто можешь рассказать про escape analysis?
Escape analysis — это процесс, который компилятор использует для определения размещения значений, созданных вашей программой.
В частности, компилятор выполняет статический анализ кода, чтобы определить, может ли значение быть помещено в стековый фрейм для функции, которая его строит, или значение должно "сбежать" в кучу. Используется разработчиками для оптимизации кода и аналитики причин возможного замедления.
Команда для запуска escape-анализа: go build -gcflags="-m" (так же можно использовать флаги -N для отключени оптимизаций, -l для отключения "инлайнинга").
Что можно почитать: Языковая механика escape analysis, Escape Analysis in Golang
Сoncurrency (конкурентность)
В данном разделе будут вопросы, относящиеся к параллелизму и конкурентной работе.
Как устроен мьютекс?
Mutex означает MUTual EXclusion (взаимное исключение), и обеспечивает безопасный доступ к общим ресурсам.
Под капотом мьютекса используются функции из пакета atomic (atomic.CompareAndSwapInt32 и atomic.AddInt32), так что можно считать мьютекс надстройкой над atomic. Мьютекс медленнее чем atomic, потому что он блокирует другие горутины на всё время действия блокировки. А в свою очередь atomic быстрее потому как использует атомарные инструкции процессора.
В момент, когда нужно обеспечить защиту доступа — вызываем метод Lock(), а по завершению операции изменения/чтения данных — метод Unlock().
В чем отличие sync.Mutex от sync.RWMutex?
Помимо Lock() и Unlock() (у sync.Mutex), у sync.RWMutex есть отдельные аналогичные методы только для чтения — RLock() и RUnlock(). Если участок в памяти нуждается только в чтении — он использует RLock(), который не заблокирует другие операции чтения, но заблокирует операцию записи и наоборот.
По большому счёту, RWMutex это комбинация из двух мьютексов.
Что такое synс.Map?
Коротко — предоставляет атомарный доступ к элементам map.
Go, как известно, является языком созданным для написания concurrent программ — программ, который эффективно работают на мультипроцессорных системах. Но тип map не безопасен для параллельного доступа. То есть для чтения, конечно, безопасен — 1000 горутин могут читать из map без опасений, но вот параллельно в неё ещё и писать — уже нет.
Для обеспечения потоко-безопасного доступа к map можно использовать sync.RWMutex, но он имеет проблему производительности при работе на большом количестве ядер процессора (в RWMutex при блокировке на чтение каждая горутина должна обновить поле readerCount — простой счётчик, с помощью atomic.AddInt32(), что проиводит к сбросу кэша для этого адреса памяти для всех ядер, и каждое ядро становится в очередь и ждёт этот сброс и вычитывание из кэша — эта проблема называется cache contention).
sync.Map решает совершенно конкретную проблему cache contention в стандартной библиотеке для таких случаев, когда ключи в map стабильны (не обновляются часто) и происходит намного больше чтений, чем записей.
Пример работы с sync.Map:
var m sync.Map
m.Store("one", 1) // запись
one, ok := m.Load("one") // чтение
fmt.Println(one, ok) // 1 true
m.Range(func(k, v interface{}) bool { // итерация эл-ов мапы
fmt.Println(k, v) // one 1
return true
})
m.Delete("one") // удалениеЧто можно почитать: Разбираемся с новым sync.Map в Go 1.9
Какие ещё примитивы синхронизации знаешь?
Как было сказано выше — для синхронизации можно использовать мьютексы. Кроме того из стандартной библиотеки нам доступны:
sync.WaitGroup
Используется для координации в случае, когда программе приходится ждать окончания работы нескольких горутин (эта конструкция похожа на CountDownLatch в Java). Отличный способ дождаться завершения набора одновременных операций. Принцип работы следующий:
var wg sync.WaitGroup
wg.Add(1) // увеличиваем счётчик на 1
go func() {
fmt.Println("task 1")
<-time.After(time.Second)
fmt.Println("task 1 done")
wg.Done() // уменьшаем счётчик на 1
}()
wg.Add(1) // увеличиваем счётчик на 1
go func() {
fmt.Println("task 2")
<-time.After(time.Second)
fmt.Println("task 2 done")
wg.Done() // уменьшаем счётчик на 1
}()
wg.Wait() // блокируемся, пока счётчик не будет == 0
// task 2
// task 1
// task 2 done
// task 1 done
// Total time: 1.00ssync.Cond
Условная переменная (CONDition variable) полезна, например, если мы хотим разблокировать сразу несколько горутин (Broadcast), что не получится сделать с помощью канала. Метод Signal отправляет сообщение самой долго-ожидающей горутине. Пример использования:
var (
c = sync.NewCond(&sync.Mutex{})
wg sync.WaitGroup // нужна только для примера
free = true
)
wg.Add(1)
go func() {
defer wg.Done()
c.L.Lock()
for !free { // проверяем, что ресурс свободен
c.Wait()
}
fmt.Println("work")
c.L.Unlock()
}()
free = false // забрали ресурс, чтобы выполнить с ним работу
<-time.After(1 * time.Second) // эмуляция работы
free = true // освободили ресурс
c.Signal() // оповестили горутину
wg.Wait()sync.Once
Позволяет определить задачу для однократного выполнения за всё время работы программы. Содержит одну-единственную функцию Do, позволяющую передавать другую функцию для однократного применения.
var once sync.Once
for i := 0; i < 10; i++ {
once.Do(func() {
fmt.Println("Hell yeah!")
})
}
// Hell yeah! (выводится 1 раз вместо 10)sync.Pool
Используется для уменьшения давления на GC путём повторного использования выделенной памяти (потоко-безопасно). Пул необязательно освободит данные при первом пробуждении GC, но он может освободить их в любой момент. У пула нет возможности определить и установить размер и нет необходимости заботиться о его переполнении.
Что можно почитать: Go sync.Pool
Какие типы каналов существуют?
Если которотко, то синхронные (небуферизированным) и асинхронные (буферизированные), оба работают по принципу FIFO (first in, first out) очереди.
Канал — это объект связи, с помощью которого (чаще всего) горутины обмениваются данными. Потокобезопасен, передаётся "по указателю". Технически это можно представить как конвейер (или трубу), откуда можно считывать и помещать данные. Для создания канала предоставляет ключевое слово chan — создание не буферизированного канала c := make(chan int), для чтения из канала — data := <-c, для записи — c <- 123, и закрытие close(c).
Запись данных в закрытый канал вызовет панику.
Чтение или запись данных в небуферизированный канал блокирует горутину и контроль передается свободной горутине. Через закрытый канал невозможно будет передать или принять данные (проверить открытость канала можно используя val, isOpened := <- channel, где isOpened == true в том случае, если канал открыт; в противном случае вернётся false и нулевое значение val исходя из типа данных для канала; isOpened == false если канал закрыт и отсутствуют данные для чтения из него).
Буферизированный канал создается указанием второго аргумента для make — c := make(chan int, 5), в этом случае горутина не блокируется до тех пор, пока буфер не будет заполнен. Подобно слайсам, буферизированный канал имеет длину (len, количество сообщений в очереди, не считанных) и емкость (cap, размер самого буфера канала):
c := make(chan string, 5)
c <- "foo"
c <- "bar"
close(c)
println(len(c), cap(c)) // 2 5
for {
val, ok := <-c // обрати внимание - читаем из уже закрытого канала
if !ok {
break
}
println(val)
}
// "foo"
// "bar"Используя буферизованный канал и цикл for val := range c { ... } мы можем читать с закрытых каналов (поскольку у закрытых каналов данные все еще живут в буфере).
Кроме того, сужествует синтаксический сахар однонаправленных каналов (улучшает безопасность типов в программe, что, как следствие, порождает меньше ошибок):
-
c := make(<-chan int)— только для чтения -
c := make(chan<- int)— только для записи
Так же можно в сигнатуре принимаемой функции указать однонаправленность канала (func write(c chan<- string) { ... }) — в этом случае функция не сможет из него читать, а сможет только писать или закрыть его.
Читать "одновременно" из нескольких каналов возможно с помощью select (оператор select является блокируемым, за исключением использования default):
c1, c2 := make(chan string), make(chan string)
defer func() { close(c1); close(c2) }() // не забываем прибраться
go func(c chan<- string) { <-time.After(time.Second); c <- "foo" }(c1)
go func(c chan<- string) { <-time.After(time.Second); c <- "bar" }(c2)
for i := 1; ; i++ {
select { // блокируемся, пока в один из каналов не попадёт сообщение
case val := <-c1:
println("channel 1", val)
case val := <-c2:
println("channel 2", val)
}
if i >= 2 { // через 2 итерации выходим (иначе будет deadlock)
break
}
}
// channel 1 foo
// channel 2 bar
// Total execution time: 1.00sВ случае, если в оба канала одновременно придут сообщения (или они уже там были), то case будет выбран случайно (а не по порядку их объявления, как могло бы показаться).
Если ни один из каналов недоступен для взаимодействия, и секция default отсутствует, то текущая горутина переходит в состояние waiting до тех пор, пока какой-то из каналов не станет доступен.
Если в select указан default, то он будет выбран в том случае, если все каналы не имеют сообщений (таким образом select становится не блокируемым).
Под капотом (src/runtime/chan.go) канал представлен структурой:
type hchan struct {
qcount uint // количество элементов в буфере
dataqsiz uint // размерность буфера
buf unsafe.Pointer // указатель на буфер для элементов канала
elemsize uint16 // размер одного элемента в канале
closed uint32 // флаг, указывающий, закрыт канал или нет
elemtype *_type // содержит указатель на тип данных в канале
sendx uint // индекс (смещение) в буфере по которому должна производиться запись
recvx uint // индекс (смещение) в буфере по которому должно производиться чтение
recvq waitq // указатель на связанный список горутин, ожидающих чтения из канала
sendq waitq // указатель на связанный список горутин, ожидающих запись в канал
lock mutex // мьютекс для безопасного доступа к каналу
}В общем случае, горутина захватывает мьютекс, когда совершает какое-либо действие с каналом, кроме случаев lock-free проверок при неблокирующих вызовах.
Go не выделяет буфер для синхронных (небуферизированных) каналов, поэтому указатель на буфер равен nil и dataqsiz равен нулю. При чтении из канала горутина произведёт некоторые проверки, такие как: закрыт ли канал, буферизирован он или нет, содержит ли гоуртины в send-очереди. Если ожидающих отправки горутин нет — горутина добавит сама себя в recvq и заблокируется. При записи другой горутиной все проверки повторяются снова, и когда она проверяет recvq очередь, она находит ожидающую чтение горутину, удаляет её из очереди, записывает данные в её стек и снимает блокировку. Это единственное место во всём рантайме Go, когда одна горутина пишет напрямую в стек другой горутины.
При создании асинхронного (буферизированного) канала make(chan bool, 1) Go выделяет буфер и устанавливает значение dataqsiz в единицу. Чтобы горутине отправить отправить значение в канал, сперва производятся несколько проверок: пуста ли очередь recvq, пуст ли буфер, достаточно ли места в буфере. Если всё ок, то она просто записывает элемент в буфер, увеличивает значение qcount и продолжает исполнение далее. Когда буфер полон, буферизированный канал будет вести себя точно так же, как синхронный (небуферизированный), тоесть горутина добавит себя в очередь ожидания и заблокируется.
Проверки буфера и очереди реализованы как атомарные операции, и не требуют блокировки мьютекса.
При закрытии канала Go проходит по всем ожидающим на чтение или запись горутинам и разблокирует их. Все получатели получают дефолтные значение переменных того типа данных канала, а все отправители паникуют.
Что можно почитать: Анатомия каналов в Go, Как устроены каналы в Go, Под капотом Golang — как работают каналы. Часть 1, Строение каналов в Golang. Часть 2
Что можно делать с закрытым каналом?
Из закрытого канала можно читать с помощью for val := range c { ... } — вычитает все сообщения что в нём есть, или с помощью:
for {
if val, ok := <-c; ok {
println(val)
} else {
break
}
}Расскажи про планировщик (горутин)
Goroutine scheduler является перехватывающим задачи (work-stealing) планировщиком, который был введен еще в Go 1.1 Дмитрием Вьюковым вместе с командой Go. Основная его суть заключается в том, что он управляет:
-
G(горутинами) — просто горутины Go -
M(машинами aka потоками или тредами) — потоки ОС, которые могут выполнять что-либо или же бездействовать -
P(процессорами) — можно рассматривать как ЦП (физическое ядро); представляет ресурсы, необходимые для выполнения нашего Go кода, такие как планировщик или состояние распределителя памяти
Основная задача планировщика состоит в том, чтобы сопоставить каждую G (код, который мы хотим выполнить) с M (где его выполнять) и P (права и ресурсы для выполнения).
Когда M (поток ОС) прекращает выполнение нашего кода, он возвращает свой P (ЦП) в пул свободных P. Чтобы возобновить выполнение Go кода, он должен повторно заполучить его. Точно так же, когда горутина завершается, объект G (горутина) возвращается в пул свободных G и позже может быть повторно использован для какой-либо другой горутины.
Go запускает столько тредов, сколько доступно процессорных ядер (если вы специально это не перенастраиваете) и распределяет на эти треды сколько угодно горутин которые уже запускает программист. В один момент на одном ядре ЦП может находиться в исполнении только одна грутина, а в очереди исполнения их может быть неограниченное количество.
Треды M во время выполнения могут переходить от одного процессора P к другому. Например, когда тред делает системный вызов, в ответ на который ОС блокирует этот тред (например — чтение какого-то большого файла с диска) — мало того что заблокируется сама горутина, что спровоцировала этот вызов, но и все остальные, что стоят в очереди для этого процессора P. Чтоб этого не происходило — Go отвязывает горутины стоящие в очереди от этого процессора P и переназначает на другие.
Основные типы многозадачности что используются в большинстве ОС это "вытесняющая" (все ресурсы делятся между всеми программами одинаково, всем выделяется одинаковое время выполнения) и "кооперативная" (программы выполняются столько, сколько им нужно, и сами уступают друг-другу место). В Go используется неявная кооперативность:
- Горутина уступает место другис при обращении к вводу-выводу, каналам, вызовам ОС и т.д.
- Может уступить место при вызове любой функции (с некоторой вероятностью произойдет переключение между горутинами)
- Есть явный способ переключить планировщик на другую горутину — вызвать функцию
runtime.Gosched()(почти никогда не нужна, но она есть)
Основные принципы планировщика:
- Очередь FIFO (first in — first out) — порядок запуска горутин обуславливается порядом их вызова
- Необходимый минимум тредов — создается не больше тредов чем доступных ядер ЦП
- Захват чужой работы — когда тред простаивает, то он не удаляется рантаймом Go, а будет по возможности "нагружен" работой, взятой из очередей горутин на исполнение с других тредов
- "Неинвазивность" — работа горутин насильно не прерывается
Ограничения:
- Очередь FIFO (нет приоритезации и изменения порядка исполнения)
- Отсутствие гарантий времени выполнения (времени запуска горутин)
- Горутины могут перемещаться между тредами, что снижает эффективность кэшей
Что можно почитать: Горутины: всё, что вы хотели знать, но боялись спросить, Что такое горутины и каков их размер?
Что такое горутина?
Горутина (goroutine) — это функция, выполняющаяся конкурентно с другими горутинами в том же адресном пространстве.
Для её запуска достаточно использовать ключевое слово go перед именем вызываемой (или анонимной) функции.
Горутины очень легковесны (~2,6Kb на горутину). Практически все расходы — это создание стека, который очень невелик, хотя при необходимости может расти. Область их применения чаще всего следующая:
- Когда нужна асинхронность (например когда мы работаем с сетью, диском, базой данных, защищенным мьютексом ресурсом и т.п.)
- Когда время выполнения функции достаточно велико и можно получить выигрыш, нагрузив другие ядра
Сама структура горутины занимает порядка 600 байт, но для неё ещё выделяется и её собственный стек, минимальный размер котого составляет 2Kb, который увеличивается и уменьшается по мере необходимости (максимум зависит от архитектуры и составляет 1 ГБ для 64-разрядных систем и 250 МБ для 32-разрядных систем).
Переключение между двумя Горутинами — супер дешевое, O(1), то есть, не зависит от количества созданных горутин в системе. Всё, что нужно сделать для переключения, это поменять 3 регистра — Program counter, Stack Pointer и DX.
В чем отличия горутин от потов ОС?
- Каждый поток операционной системы имеет блок памяти фиксированного размера (зачастую до 2 Мбайт) для стека — рабочей области, в которой он хранит локальные переменные вызовов функций, находящиеся в работе или приостановленные на время вызова другой функции. В противоположность этому go-подпрограмма начинает работу с небольшим стеком, обычно около 2 Кбайт. Стек горутины, подобно стеку потока операционной системы, хранит локальные переменные активных и приостановленных функций, но, в отличие от потоков операционной системы, не является фиксированным; при необходимости он может расти и уменьшаться
- Потоки операционной системы планируются в ее ядре, а у go есть собственный планировщик (m:n) мультиплексирующий (раскидывающий) горутинки (m) по потокам (n). Основной плюс — отсутствие оверхеда на переключение контекста
- Планировщик Go использует параметр с именем
GOMAXPROCSдля определения, сколько потоков операционной системы могут одновременно активно выполнять код Go. Его значение по умолчанию равно количеству процессоров (ядер) компьютера, так что на машине с 8 процессорами (ядрами) планировщик будет планировать код Go для выполнения на 8 потоках одновременно. Спящие или заблокированные в процессе коммуникации go-подпрограммы потоков для себя не требуют. Go-подпрограммы, заблокированные в операции ввода-вывода или в других системных вызовах, или при вызове функций, не являющихся функциями Go, нуждаются в потоке операционной системы, но GOMAXPROCS их не учитывает - В большинстве операционных систем и языков программирования, поддерживающих многопоточность, текущий поток имеет идентификацию, которая может быть легко получена как обычное значение (обычно — целое число или указатель). У горутин нет идентификации, доступной программисту. Так решено во время проектирования языка, поскольку локальной памятью потока программисты злоупотребляют
Где аллоцируется память для горутин?
Так как горутины являются stackful — то и память для них (их состояние) хранится на стеке. Поэтому, теоритически, если очень постараться и сделать милилард вложенных вызовов, то можно сделать себе переполнение стека.
Для самих же переменных, что используются внутри горутин память берётся с хипа (ограничены только размером "физического" хипа, т.е. объемом памяти сколько есть на машине).
Что можно почитать: Достучаться до небес — Корутины, Горутины и прочие Рутины, Go: как изменяется размер стека горутины?
Как завершить много горутин?
Один из вариантов — это пристрелить main (шутка). Работу одной гороутины в принципе нельзя принудительно остановить из другой. Механизмы их завершения необходимо реализовывать отдельно (учить сами горутины завершаться).
Наиболее часто используются 2 подхода — это использование контекста context.Context:
import (
"context"
"time"
)
func f(ctx context.Context) {
loop:
for {
select {
case <-ctx.Done():
println("break f")
break loop
default:
println("do some work")
<-time.After(time.Millisecond * 100)
}
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
for i := 0; i < 3; i++ {
go f(ctx) // запускаем 3 горутины
}
<-time.After(time.Millisecond * 50)
cancel() // отменяем контекст, на что горутины должны среагировать выходом
<-time.After(time.Millisecond * 60)
// do some work
// do some work
// do some work
// break f
// break f
// break f
}И отдельного канала для уведомлений о необходимости завершения (часто для уведомлений используется пустая структура struct{}, которая ничего не весит):
import (
"time"
)
func f(c <-chan struct{}) {
loop:
for {
select {
case <-c:
println("break f")
break loop
default:
println("do some work")
<-time.After(time.Millisecond * 100)
}
}
}
func main() {
const workersCount = 3
var c = make(chan struct{}, workersCount)
for i := 0; i < workersCount; i++ {
go f(c) // запускаем 3 горутины
}
<-time.After(time.Millisecond * 50)
for i := 0; i < workersCount; i++ {
c <- struct{}{} // отправляем 3 сообщения в канал (по одному для каждой горутины) о выходе
}
// ВООБЩЕ - цикл с отправкой сообщений НЕ является обязательным, и можно просто закрыть канал
close(c)
<-time.After(time.Millisecond * 60)
// do some work
// do some work
// do some work
// break f
// break f
// break f
}Кейсы использования контекста
Пакет context в Go особенно полезен при взаимодействиях с API и медленными процессами, особенно в production-grade системах. С его помощью можно уведомить горутины о необходимости завершить свою работу, "пошарить" какие-то данные (например, в middleware), или легко организовать работу с таймаутом.
context.WithCancel()
Эта функция создает новый контекст из переданного ей родительского, возвращая первым аргуметом функцию "отмены контекста" (при её вызове родительский контект "отменен" не будет), а вторым — новый контекст. Важно — вызывать функцию отмены контекста должна только та функция, которая его создает. При вызове функции отмены сам контекст и все котнекты, созданные на основе него получат в ctx.Done() пустую структуру и в ctx.Err() ошибку context.Canceled.
ctx, cancel := context.WithCancel(context.Background())
fmt.Println(ctx.Err()) // nil
cancel()
fmt.Println(<-ctx.Done()) // {}
fmt.Println(ctx.Err().Error()) // context canceledcontext.WithDeadline()
Так же создает контекст от родительского, который отменится самостоятельно при наступлении переданного ему временной отметке, или при вызове функции отмены. Отмена/таймаут затрагивает только сам контекст и его "наследников". ctx.Err() возвращает ошибку context.DeadlineExceeded. Полезно для реализации таймаутов:
ctx, cancel := context.WithDeadline(
context.Background(),
time.Now().Add(time.Millisecond*100),
)
defer cancel()
fmt.Println(ctx.Err()) // nil
<-time.After(time.Microsecond * 110)
fmt.Println(<-ctx.Done()) // {}
fmt.Println(ctx.Err().Error()) // context deadline exceededcontext.WithTimeout()
Работает аналогично context.WithDeadline() за исключением того, что принимает в качестве значения таймаута длительность (например — time.Second):
ctx, cancel := context.WithTimeout(context.Background(), time.Second*2)context.WithValue()
Позволяет "пошарить" данные через всё контекстное деверо "ниже". Часто используют чтоб передать таким образом, например, логгер или HTTP запрос в цепочке middleware (но в 9 из 10 случаев так делать не надо, это можно считать антипаттерном). Лучше всего использовать функции для помещения/извлечения данных из контекста (так как "в нём" они храняться как interface{}):
import (
"context"
"log"
"os"
)
const loggerCtxKey = "logger" // should be unique
func PutLogger(ctx context.Context, logger *log.Logger) context.Context {
return context.WithValue(ctx, loggerCtxKey, logger)
}
func GetLogger(ctx context.Context) *log.Logger {
return ctx.Value(loggerCtxKey).(*log.Logger)
}
func f(ctx context.Context) {
logger := GetLogger(ctx)
logger.Print("inside f")
println(logger)
}
func main() {
var (
logger = log.New(os.Stdout, "", 0)
ctxWithLogger = PutLogger(context.Background(), logger)
)
logger.Printf("main")
println(logger)
f(ctxWithLogger)
// main
// 0xc0000101e0
// inside f
// 0xc0000101e0
}Что можно почитать: Разбираемся с пакетом Context в Golang
При этом ok == true до того момента, пока в канале есть сообщения (вне зависимости от того, открыт он или закрыт), в противном случае ok == false а val будет нулевым значением в зависимости от типа данных канала. При попытке записи в закрытый канал будет паника (авторы языка так сделали "ибо нефиг — канал закрыт значит закрыт").
Как задетектить гонку?
Пишем тесты, и запускаем их с флагом -race (в этом случае рантайм будет в случайном порядке переключаться между горутинами (если не ошибаюсь), и компилятор генерирует дополнительный код, который "журналирует" обращения к памяти). Этот флаг можно использовать как для go test, так и для go run или go build.
Детектор гонки основан на библиотеке времени выполнения (runtime library) C/C++ ThreadSanitizer.
Так же предпочитаю писать тесты, провоцирующие гонку. Код в этом случае будет работать значительно медленнее, но для этапа тестирования это и не так важно. А именно для тестируемоой структуры запускаю (например) 100 горутин которые читают и пишут что-то в случайном порядке.
Важно и ещё одно высказывание — "Если race detector обнаруживает состояние гонки, то оно у вас наверняка есть; если же не обнаруживает — то это не означает что его нет".
Тестирование
Для unit-тестирования (aka модульного) используется команда вида go test, которая запускает все функции, что начинаются с префикса Test в файлах, что имеют в своем имени постфикс _test.go — всё довольно просто.
Важно писать сам код так, чтоб его можно было протестировать (например — не забывать про инвертирование зависимостей и использовать интерфейсы там, где они уместны).
TDT, Table-driven tests (табличное тестирование)
Являются более предпочтительным вариантом для тестирования множества однотипных кейсов перед описанием "один кейс — один тест", так как позволяют отделить часть входных данных и ожидаемых данных от всех этапов инициализации и tear-down (не знаю как это будет по-русски). Например, тестируемая функция и её тест могут выглядеть так:
package main
func Sum(a, b int) int { return a + b }package main
import "testing"
func TestSum(t *testing.T) {
for name, tt := range map[string]struct { // ключ мапы - имя теста
giveOne, giveSecond int
wantResult int
}{
"1 + 1 = 2": {
giveOne: 1, giveSecond: 1, wantResult: 2,
},
"140 + 6 = 146": {
giveOne: 140, giveSecond: 6, wantResult: 146,
},
} {
t.Run(name, func(t *testing.T) {
// setup here
if res := Sum(tt.giveOne, tt.giveSecond); res != tt.wantResult {
t.Errorf("Unexpected result. Want %d, got %d", tt.wantResult, res)
}
// teardown here
})
}
}Имя пакета с тестами
Если имя пакета в файле с тестами (foo_test.go) указывать с постфиксом _test (например — имя пакета, для которого пишутся тесты foo, а имя пакета указанное в самом файле с тестами для него — foo_test), то в тестах не будет доступа в не-экспортируемым свойствам, структурам и функциям, таким образом тестирование пакета будет происходить "как извне", и не будет соблазна пытаться использовать что-то приватное, что в пакете содержится. По идее, в одной директории не может находиться 2 и более файлов, имена пакетов в которых отличаются, но *_test является исключением из этого правила.
Более того, этот подход стимулирует тестировать API, а не внутренние механизмы, т.е. относиться к функциональности как к "черному ящику", что очень правильно.
Статические анализаторы (линтеры)
Уже давно на все случаи жизни существует golangci-lint, который является универсальным решением, объединяющим множество линтеров в "одном флаконе". Удобен как для запуска локально, так и на CI.
Ошибка в бенчмарке
Про бенчмарки — иногда встречается кейс с написанием бенчмарка который внутри своего цикла выполняет тестируемую функцию, а результат этого действия никуда не присваивается и не передаётся:
func BenchmarkWrong(b *testing.B) {
for i := 0; i < b.N; i++ {
ourFunc()
}
}Компилятор может принять это во внимание, и будет выполнять её содержимое как inline-последовательность инструкций. После чего, компилятор определит, что вызовы тестируемой функции не имеет никаких побочных эффектов (side-effects), т.е. никак не влияет на среду исполнения. После чего вызов тестируемой функции будет просто удалён. Один из вариантов избежать сценария выше – присваивать результат выполнения функции переменной уровня пакета. Примерно так:
var result uint64
func BenchmarkCorrect(b *testing.B) {
var r uint64
for i := 0; i < b.N; i++ {
r = ourFunc()
}
result = r
}Теперь компилятор не будет знать, есть ли у функции side-effect и бенчмарк будет точен.
Что про функциональное тестирование?
Тут всё зависит от того, что мы собираемся тестировать, и тянет на отдельную тему для разговора. Для HTTP посоветовать можно postman и его CLI-версию newman. Ещё как вариант "быстро и просто" — это hurl.
Для за-mock-ивания стороннего HTTP API — jmartin82/mmock или lamoda/gonkey.
Профилирование (pprof)
Для профилирования "родными" средствами в поставке с Go имеется пакет pprof и одноименная консольная утилита go tool pprof. Причинами необходимости в профилировании могут стать:
- Длительная работа различных частей программы
- Высокое потребление памяти
- Высокое потребление ресурсов процессора
Профилировщик является семплирующим — с какой-то периодичностью мы прерываем работу программы, берем стек-трейс, записываем его куда-то, а в конце, на основе того, как часто в стек-трейсах встречаются разные функции, мы понимаем, какие из них использовали больше ресурсов процессора, а какие меньше. Работа с ним состоит из двух этапов — сбор статистики по работе сервиса, и её визуализация + анализ. Собирать статистику можно добавив вызовы пакета pprof, либо запустив HTTP сервер.
Пример использования pprof
Рассмотрим простой случай, когда у нас есть функция, которая выполняется по какой-то причине очень долго. Обрамим вызовы потенциально-тяжелого кода в startPprof и stopPprof:
package main
import (
"os"
"runtime/pprof"
"time"
)
func startPprof() *os.File { // вспомогательная функция начала профилирования
f, err := os.Create("profile.pprof")
if err != nil {
panic(err)
}
if err = pprof.StartCPUProfile(f); err != nil {
panic(err)
}
return f
}
func stopPprof(f *os.File) { // вспомогательная функция завершения профилирования
pprof.StopCPUProfile()
if err := f.Close(); err != nil {
panic(err)
}
}
func main() { // наша основания функция
var (
slice = make([]int, 0)
m = make(map[int]int)
)
pprofFile := startPprof() // начинаем профилирование
// тут начинается какая-то "тяжелая" работа
for i := 0; i < 10_000_000; i++ {
slice = append(slice, i*i)
}
for i := 0; i < 10_000_000; i++ {
m[i] = i * i
}
<-time.After(time.Second)
// а тут она завершается
stopPprof(pprofFile) // завершаем профилирование
}После компиляции и запуска приложения (go build -o ./main . && ./main) в текущей директории появится файл с именем profile.pprof, содержащий профиль работы. "Конвертируем" его в читаемое представление в виде svg изображения с помощью go tool pprof -svg ./profile.pprof (на Linux для этого понадобится установленный пакет graphviz) и открываем его (имя файла будет в виде profile001.svg):

Посмотрим на получившийся граф вызовов. Изучая такой граф, в первую очередь нужно обращать внимание на толщину ребер (стрелочек) и на размер узлов графа (квадратиков). На ребрах подписано время — сколько времени данный узел или любой из ниже лежащих узлов находился в стек-трейсе во время профилирования.
В нашем профиле можем заметить, что runtime evacuate_fast64 занимает очень много времени. Связано это с тем, что из мапы данным приходиться эвакуироваться, так как размер мапы очень сильно растёт. Исправляем это (а заодно и слайс) всего в двух строчках:
var (
slice = make([]int, 0, 10_000_000) // заставляем аллоцировать память в слайсе
m = make(map[int]int, 10_000_000) // и в мапе заранее
)Повторяем все сделанные ранее операции снова, и видим уже совсем другую картину:

Теперь картина значительно лучше, и следующее место оптимизации (потенциально) это пересмотреть работу с данными, а именно — нужна ли нам работа с мапой в принципе (может заменить её каким-то слайсом), и если нет — то как можно улучшить (оптимизировать) запись в неё.
Так как же профилировщик работает в принципе?
Go runtime просит ОС посылать сигнал (man setitimer) с определенной периодичностью и назначает на этот сигнал обработчик. Обработчик берет стек-трейс всех горутин, какую-то дополнительную информацию, записывает ее в буфер и выходит.
Каковы же недостатки данного подхода?
- Каждый сигнал — это изменение контекста, вещь довольно затратная в наше время. В Go сейчас получается получить порядка 100 в секунду. Иногда этого мало
- Для нестандартных сборок, например, с использованием
-buildmode=c-archiveили-buildmode=c-shared, профайлер работать по умолчанию не будет. Это связано с тем, что сигналSIGPROF(который посылает ОС) придет в основной поток программы, который не контролируется Go - Процесс
user space, которым является программа на Go, не может получить ядерный стек-трейс. Неоптимальности и проблемы иногда кроются и в ядре
Основное преимущество, конечно, в том, что Go runtime обладает полной информацией о своем внутреннем устройстве. Внешние средства, например, по умолчанию ничего не знают о горутинах. Для них существуют только процессы и треды.
Что можно почитать: Профилирование и оптимизация программ на Go
Компилятор
Компиляция — это процесс преобразования вашего (говно)кода в кашу из машинного кода. Первое понятно тебе, второе — машине.
Из каких этапов состоит компиляция?
cmd/compile содержит основные пакеты Go компилятора. Процесс компиляции может быть логически разделен на четыре фазы:
-
Parsing (
cmd/compile/internal/syntax) — сорец парсится, разбивается на токены, создается синтаксическое дерево -
Type-checking and AST (Abstract Syntax Tree) transformations (
cmd/compile/internal/gc) — дерево переводится в AST, тут же происходит магия по авто-типизации, проверок интерфейсов этапа компиляции, определяется мертвый код и происходит escape-анализ -
Generic SSA (Static Single Assignment) (
cmd/compile/internal/gc,cmd/compile/internal/ssa) — AST переводится в SSA (промежуточное представление более низкого уровня), что упрощает реализацию оптимизаций; так же применяются множественные оптимизации этого уровня (тут, например, циклыrangeпереписываются в обычныеfor; аcopyзаменяется перемещением памяти), удаляются ненужные проверки наnilи т.д. -
Generating machine code (
cmd/compile/internal/ssa,cmd/internal/obj) — универсальные штуки перезаписываются на машинно-зависимые (в зависимости от архитектуры и ОС), после чего над SSA снова выполняются оптимизации, удаляется мертвый код, распределяются регистры, размечается стековый фрейм; после — ассемблер превращает всё это добро в машинный код и записывает объектный файл
Что можно почитать: Введение в компилятор Go
Статическая компиляция/линковка — что это, и в чем особенности?
Линковка (ну или компоновка) последний этап сборки. Статически слинкованный исполняемый файл не зависит от наличия других библиотек в системе во время своей работы.
Для включения статической компиляции/линковки (при этом все внешние библиотеки, от которых зависит исполнение кода будут встроены в итоговый бинарный файл) необходимо использовать переменную окружения при сборке CGO_ENABLED=0 (т.е. CGO_ENABLED=0 go build ...). Полученный бинарный файл можно безбоязненно использовать, например, в docker-образе, основанном на scratch (т.е. не содержащем абсолютно никаких файлов, кристально чистая файловая система).
Однако, это накладывает некоторые ограничения и привносит особенности, которые необходимо помнить:
-
C-код будет недоступен, совсем (часть модулей из stdlib Go от него зависят, к слову, но не критичных) - Не будет использоваться системный DNS-резольвер
- Не будет работать проверка
x.509сертификатов, которая должна работать на MacOS X
И ещё, если итоговый бинарный файл планируется использовать в docker scratch, то так же следует иметь в виду:
- Для осуществления HTTP запросов по протоколу HTTPS вашим приложением, в образ нужно будет поместить корневые SSL/TLS сертификаты
/etc/ssl/certs - Файл временной зоны (
/etc/timezone) тоже будет необходим, чтоб корректно работать с датой/временем
Что можно почитать: Docker scratch & CGO_ENABLED=0, Кросс-компиляция в Go, Go dns
Какие директивы компилятора знаешь?
Компилятор Go понимает некоторые директивы (пишутся они в виде комментариев, как правило //go:directive), которые влияют на процесс компиляции (оптимизации, проверок, и т.д.) но не являются частью языка. Вот некоторые из них:
//go:linkname
Указывает компилятору реальное местонахождение функции или переменной. Можно использовать для вызова приватных функций из других пакетов. Требует импортирования пакета unsafe (import _ "unsafe"). Формат следующий:
//go:linkname localname [importpath.name]Пример использования:
import (
_ "strings" // for explodeString
_ "unsafe" // for go:linkname
)
//go:linkname foo main.bar
func foo() string
func bar() string { return "bar" }
//go:linkname explodeString strings.explode
func explodeString(s string, n int) []string
func main() {
println(foo()) // bar
println(explodeString("foo", -1)) // [3/3]0xc0000a00f0
}//go:nosplit
Указывается при объявлении функции, и указывает на то, что вызов функции должен пропускать все обычные проверки на переполнение стека.
//go:norace
Так же указывается при объявлении функции и "выключает" детектор гонки (race detector) для неё.
//go:noinline
Отключает оптимизацию "инлайнига" для функции. Обычно используется отладки компилятора, escape-аналитики или бенчаркинга.
//go:noescape
Тоже "функциональная" директива, смысл которой сводится к тому, что "я доверяю этой функции, и ни один указатель, переданных в качестве аргументов (или возвращенных) этой функции не должен быть помещен в кучу (heap)".
//go:build
Эта директива обеспечивает условную сборку. То есть мы можем "размечать" тегами файлы, и таким образом компилировать только определенные их "наборы" (тегов может быть несколько, а так же можно использовать ! для указания "не"). Часто используется для кодогенерации, указывая какой-то специфичный тег (например ignore — //go:build ignore) чтоб файл никогда не учавствовал с борке итогового приложения.
В качестве примера создадим 2 файла в одной директории:
// file: main.go
//go:build one
package main
func main() { println("one!") }// file: main2.go
//go:build two
package main
func main() { println("two!") }И соберем с разными значениями -tags для go build или go run (обрати внимение — какой именно файл собирать не указывается, только тег):
$ go run -tags one .
one!
$ go run -tags two .
two!//go:generate
Позволяет указать какие внешние команды должны вызваться при запуске go generate. Таким образом, мы можем использовать кодогенерацию, к примеру, или выполнять какие-то операции что дожны предшевствовать сборке (например — //go:generate go run gen.go где gen.go это файл, что содержит //go:build ignore т.е. исключён из компиляции, но при этом генерирует для нас какие-то полезные данные и/или целые .go файлы):
package main
//go:generate echo "my build process"
func main() {
println("hello world")
}$ go generate
my build process//go:embed
Позволяет "встраивать" внешние файлы в Go приложение. Требует импортирования пакета embed (import _ "embed"). Поддерживает типы string, []byte и embed.FS. Пример использования:
package main
import _ "embed"
//go:embed test.txt
var hello string
func main() {
println(hello)
}$ echo "hello world" > test.txt
$ go run .
hello worldЧто можно почитать: pkg.go.dev/cmd/compile, Go Compiler Directives, Генерация кода в Go, pkg.go.dev/embed
Комментарии (9)


WASD1
02.04.2022 14:08+3Важной особенностью является то, так как "под капотом" у слайса лежит указатель на массив — при изменении значений слайса они будут изменяться везде, где слайс используется (будь то присвоение в переменную, передача в функцию и т.д.) до момента, пока размер слайса не будет переполнен и не будет выделен новый массив для его значений (т.е. в момент изменения
capслайса всегда происходит копирование данных массива):Я прям не сразу понял как такого добиться, а потом каааак понял.
Вот это грабли.
Мне кажется архитекторы языка переупоролись в "простоту" и "интуитивную понятность", в итоге такое поведение является интуитивно понятным лишь в каких-то совсем простых кейсах, а шаг влево-шаг вправо и всё надо понимать как сделано под капотом.

vn_sten
02.04.2022 17:28+1Увеличении размера слайса (метод growslice) использует другую стратегию начиная с 1.18

QtRoS
02.04.2022 22:27Переключение между двумя Горутинами — супер дешевое,
O(1), то есть, не зависит от количества созданных горутин в системе. Всё, что нужно сделать для переключения, это поменять 3 регистра —Program counter,Stack PointerиDX.Напомните плз, что с остальными регистрами происходит?
Могу предположить такую реализацию: код языка компилируется так, что в моменты возможного переключения на другую горутину все значения из регистров уже находятся в стеке горутины. То есть в специальных точках программы гарантируется независимость от значений регистров общего назначения. В таком случае ими и правда можно пожертвовать.Но ИМХО не совсем честно называть это O(1).

NeoCode
03.04.2022 00:15+1Хорошая статья, спасибо. Узнал для себя много нового, хотя язык вроде как "простой" и казалось что ничего сильно нового быть там не должно.
Слайс, насколько я понимаю, это аналог std::vector из С++. Непонятно почему его назвали "срезом", мне интуитивно казалось что "срез" больше подходит к какому-то range или view - невладеющей структуре, ссылающейся на часть массива или строки.
"Захват переменной цикла" меня конечно сильно удивил. Но проверил - да, действительно, переменная именно захватывается, хотя казалось бы - это всего лишь передача адреса. После С/С++ это может быть источником граблей.
var out []*int for i := 0; i < 3; i++ { out = append(out, &i) } println(*out[0], *out[1], *out[2]) // 3 3 3
powerman
03.04.2022 00:50-1Так срез - это именно невладеющая структура, ссылающаяся на часть массива. В простых случаях при создании среза создаётся и массив, который никем кроме этого среза не используется, что создаёт между ними связь 1-к-1 и иллюзию того, что массив является частью среза, плюс срез начинается в начале массива. Но это - просто частный случай. Никто не мешает иметь несколько срезов, которые указывают на разные части одного массива, в т.ч. пересекающиеся между собой.
powerman
Статья громадная, но и ошибок с неточностями в ней тоже хватает. Вот первая порция.
SRP вообще не про это. Читайте первоисточник (дядю Боба), хватит уже повторять эту чушь. Цитата из его книжки "Чистая архитектура": "Модуль должен отвечать за одного и только за одного актора.", где актор определён как "группа, состоящая из одного или нескольких лиц, желающих данного изменения". Иными словами, SRP - про то, что требования к каждому "модулю" (цитата: "связному набору функций и структур данных") должны поступать от одного актора. И пример нарушения SRP в книжке рассматривает ситуацию, когда требования к одному куску кода поступают одновременно и от отдела бухгалтерии и от отдела работы с персоналом - и, разумеется, требования одних не учитывают (а то и конфликтуют с) требования других.
Никакой связи между D и S нет.
Методы можно объявить на любом типе данных, хоть на
bool- обычно для этого действительно используются структуры, как наиболее гибкий вариант, но неправильно говорить, что это обязательно должны быть структуры.На самом деле Foo встраивается в Bar не без имени, а под именем совпадающим с названием типа, т.е. Foo. Анонимность заключается не в отсутствии имени поля, а в том, что имя поля можно не указывать при обращении к полям/методам встроенного типа.
Это полностью некорректно.
Во-первых, в Go ссылки есть - через пакет unsafe.
Во-вторых, интерфейс не является ссылочным типом (хоть технически и состоит из пары указателей) и не работает как ссылочные типы (мы не можем внутри функции изменив свой аргумент интерфейсного типа изменить переданное в функцию значение).
В-третьих, в значение интерфейсного типа можно положить не указатель.
Несмотря на то, что в Go нет специальной сущности "конструктор" и создавать объекты можно несколькими способами, на мой взгляд функцию, чьё основное назначение это создание объекта определённого типа, вполне корректно называть конструктором, без "псевдо".
Это хоть и корректная, но неполная информация - есть возможность сделать строку из среза байт без копирования, вот пример из стандартной библиотеки: (*strings.Builder).String() (но изменение исходного среза байт изменит и строку).
Откуда такая информация? (Я уже молчу о том, что любой срез это ровно 24 байта.)
Это описывает эффект, но не суть происходящего, и только запутывает. В Go всё передаётся "по значению". Вопрос только в том, что это за значение: в случае массива это весь массив, в случае среза это два числа и ссылка на массив, в случае мапы это одна ссылка, в случае указателя на что угодно это одна ссылка… Поэтому не стоит говорить, что "слайсы передаются по ссылке" - слайс состоит из трёх значений и только одно из них является ссылкой, поэтому "по ссылке" передаётся только "часть" слайса. А чтобы действительно передать слайс "по ссылке" нужно явно передать указатель на слайс.
Далеко не всегда - при уменьшении cap никакого копирования не происходит. https://go.dev/play/p/rDLV1t5-dWr
paramtamtam Автор
Спасибо за ваш комментарий! Не со всем согласен, кое-что перепроверю, но за зашу обратную связь и развернутую мысль - огромное спасибо!
Nikolino
Спасибо за столь развернутый комментарий. Хотелось бы почитать вторую и другие порции исправленных неточностей (на ваш взгляд), указанных в статье.