
Правильное использование структур данных поможет оптимизировать скорость/память кода. В больших продуктах каждая оптимизация умножается на миллионы/миллиарды сессий пользователей. Так я сэкономил Uber $22 000 в год используя базовые знания структуры данных Set.
Проблема
Часто используемый скрин приложения отправлял impression аналитику при прокрутке экрана с дублированием. Например если вы видели на экране “XYZ” 10 раз прокрутив контент вверх вниз несколько раз, то аналитика отправлялась 10 раз.
Я поговорил с нашими аналитиками и они сказали что им достаточно 1 раза отправки данного события. Они добавили что делают дедупликацию этих событий на своей стороне.
Решение
Я добавил дедупликацию аналитики перед отправкой. Ниже упрощенный псевдо код:
// Было
logAnalytics(for: uuid)
// Стало
let uuids = Set<String>()
...
if uuids.insert(uuid).inserted {
logAnalytics(for: uuid)
}Результат
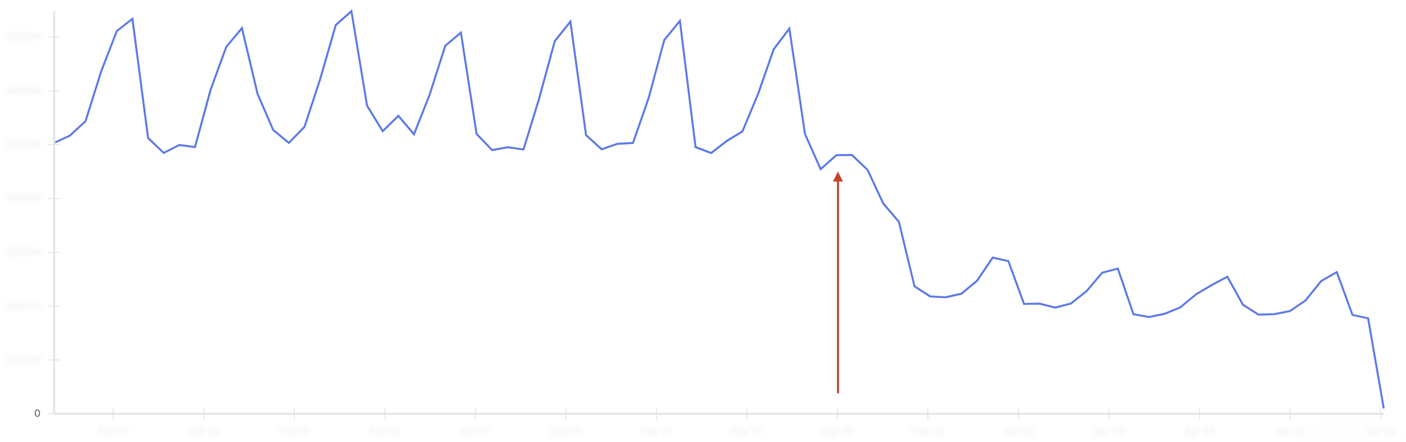
На графике ниже показан объём аналитики для конкретного события. С момента выпуска оптимизированного кода (красная стрелка) видно падение в количестве событий. Новый код сократил расходы на аналитику этого события на $22 000 в год.
Падение в конце графика это не очередная оптимизация. Сервер тоже не падал. Данные аналитики поступают с задержкой. Поэтому новые события еще не поступили.
Вывод
Знание структур данных поможет оптимизировать код. Чем больше продукт, тем больше эффект оптимизации.
Спасибо за прочтение чернового варианта статьи Азизбеку Матчанову, Айгуль Джуманазаровой, Муслимбеку Абдуганиеву.
Обо мне
Меня зовут Дархонбек. Автор ИТ блога 10x Engineer. Я работаю iOS разработчиком в Сан Франциско в компании Uber.
Связаться со мной можно по почте: darkhonbek.interview@gmail.com
Комментарии (58)

agent10
03.05.2022 07:26+23А причём тут структуры данных? Если бы я использовал List, то что-то изменилось бы в логике?

randomsimplenumber
03.05.2022 08:50+24Вот видите, знать 2 структуры данных ещё лучше ;)
ЗЫ: автор конечно же молодец. Почти как дорожник, наконец заасфаальтировавший дырку в асфальте, и сэкономивший сотне автомобилистов ресурс ходовой.

bugy
03.05.2022 09:29+11Справедливости ради, проверка contains в List'e может занимать изрядное время. Насколько это критично зависит от количества и качества данных
ПС видимо автор Set таки и не знает, иначе бы не добавлял эту проверку

askharitonov
03.05.2022 10:07+1ПС видимо автор Set таки и не знает, иначе бы не добавлял эту проверку
А почему? Он ведь проверяет наличие uuid в uuids для того, чтобы определить, отправлять ли информацию, или она уже была ранее отправлена, а не для того, чтобы избежать повторного добавления данных в Set.

Gordon01
03.05.2022 10:32+3.contains() для
List: O(min(i, n-i))
Set: O(1)~
askharitonov
03.05.2022 10:39Если я правильно понял, комментарий в постскриптуме не относился к List, а был просто про Set.

reatfly
03.05.2022 11:41+1Вы еще забыли константу перед сложностью, и для небольших размеров в десятки записей линейный поиск по вектору (я про С++, где вектор - это непрерываня область памяти; не знаю, как лист а iOS устроен) быстрее и выгоднее, чем любые сеты/мапы.
bugy
03.05.2022 10:44Теоретически да, но мне кажется там просто неправильный код. Вряд ли они отправляют все uuid каждый раз при добавлении одного элемента.

mayorovp
03.05.2022 12:48+4Потому что во многих языках у множеств операция add возвращает boolean, и скорее всего можно было написать вот так:
if uuids.add(uuid) { logAnalytics(for: uuid) }Ещё бы понять что это вообще за язык, в хабах только Swift указан, но там у множества метода add нету.

GerrAlt
03.05.2022 23:48А если бы просто сложил все в сет без проверки на наличие, и потом уже отправил весь полученный сет возможно сэкономил бы еще больше (особенно если там пакетная обработка возможна)

sshikov
03.05.2022 09:30> Если бы я использовал List, то что-то изменилось бы в логике?
Внутри Set как правило хеш таблица.randomsimplenumber
03.05.2022 09:46-2А внутри list что?
sshikov
03.05.2022 09:51+12Что-то другое (массив или связанный список). Хеш таблиц внутри list точно нет.

AnthonyMikh
03.05.2022 21:54-1Если только речь не идёт о PHP
sshikov
03.05.2022 22:30-1Ну… это скорее исключение, подтверждающее правило. Там же поди строковые ключи, а не целочисленные индексы?
mayorovp
04.05.2022 10:24В PHP и структуры данных-то такой нет

eandr_67
04.05.2022 15:50Списки в PHP есть: www.php.net/manual/ru/class.spldoublylinkedlist.php, а множества элементарно реализуются через массивы.
Но речь выше была о том, что массив в PHP — достаточно необычный тип данных, одновременно совмещающий в себе и линейный, и ассоциативный массивы.mayorovp
04.05.2022 15:59Тот список, ссылку на который вы дали, реализуется не через массив и точно не через хеш-таблицу.

lamerok
03.05.2022 09:36+1Ну наверное поиск по списку был бы дольше. О(n) , против O(1) в среднем.
agent10
03.05.2022 09:40+2И? Логика то бы не изменилась. Как будет отправляться аналитика один раз так и будет. Цимес в том, что автору помогли не знания структур данных(отличие Set от List), а понимание предметной области и процессов внутри проекта.

vladimirelizarov89
03.05.2022 10:26Да.
Видимо приходит много одинаковых событий, и они запихиваются в set, он по определению не хранит в себе одинаковых объектов, таким образом происходит дедупликация.
Если бы был list, то одинаковые события так бы и сыпались и сохранялись как и раньше, тк list позваляет хранить внутри себя одинаковые элементы.
agent10
03.05.2022 10:32-2Это смотря в каком языке. В Java, скажем, метод contains использует для сравнения метод объектов - equals. А значит для одинаковых строк(как в примере), List будет работать также как и Set. Просто дольше.

CoolCmd
03.05.2022 08:15+15я не согласен с автором, потому чт

justmara
03.05.2022 12:35+12наша группа копирайтеров всё ещё вычитывает черновой вариант комментария
CoolCmd
03.05.2022 16:03+2говорите тише — Азизбек, Айгуль и Муслимбек еще спят (про часовые пояса не забываем)

Muslimbek_Abduganiev
04.05.2022 17:53+1Лол. Мы просто пытаемся минимазировать недочёты в постах у друг друга.
P.S.
Спасибо Дархонбеку Маматалиеву и Азизбеку Матчанлву за ревью чернового варианта данного коментария.

saipr
03.05.2022 08:27+8Знание структур данных поможет оптимизировать код.
Для начала позволит создать работающий код.
P.S.В больших продуктах каждая оптимизация умножается на миллионы/миллиарды пользователей.
И сколько же у нас МИЛЛИАРДОВ пользователей?

masv
03.05.2022 08:47+6Не только пользователи страдают от вездесущей, всеятормозящей, трафикожрущей телеметрии.





ssurrokk
03.05.2022 10:05почему именно 22 000 $ , как считали?

ialexander
03.05.2022 10:43+4Этот момент как раз не вызывает вопросов, если вкратце $22000 - виртуальные попугаи.
Компании с достаточно обширной инфраструктурой ведут мониторинг используемых ресурсов, как минимум сколько каждое приложение в данный момент потребляет CPU и сколько памяти, делается это как минимум для того, чтобы «сошедшее с ума» приложение которое внезапно начинает потреблять много ресурсов можно было прибить, чтобы оно не аффектило другие приложения.
Следующий шаг очень простой можно посчитать сколько то или иное приложение потребляет CPU/RAM в течении дня/месяца/года и раздать бюджеты командам разработчикам, чтобы они были заинтересованы в создании более эффективных приложений - сэкономить памяти в одном месте, чтобы потратить ее в другом.
Следующий шаг это введение единой метрики, когда минута процессорного времени получает какое-то значение в попугаях, так и мегабайт памяти ещё какое-то значение. Попугаи можно обозвать долларами, так выглядит более наглядно.
К CPU/RAM можно добавить и другие компоненты - жесткий диск, сеть. Тут уж что важно для компании и что можно посчитать.
Ну и походя к сути вопроса, после внедрения той фичи метрика показала падение использования ресурсов эквивалентного 22000 попугаев в год.

aPiks
03.05.2022 11:53Если использовать для сбора аналитики какой-нибудь segment, то количество запросов будет равно количеству уплаченных денег.
soundengineer
03.05.2022 10:26+3Только ногами не пинайте, я не настоящий сварщик, но нельзя ли как-то последовательно пронумеровать элементы на экране числами от 0 и выше? Тогда для хранения информации о том, что аналитика по элементу отправлена, хватило бы битового вектора, где id элемента - это позиция бита в векторе. Думаю, что одного единственно int на экран хватило бы за глаза. Ну и пара битовых операций к нему. Быстрее просто некуда.
ialexander
03.05.2022 10:49+2У разных пользователей могут показываться разные элементы на экране, поэтому нужны глобальные идентификаторы. Какие-нибудь A/B тесты проводят.

merinoff
03.05.2022 11:15+1Так вроде это и сделано, у объектов вычисляются хэши. А что в функции logAnalytics мы не знаем, может там по уиду находится объект и отсылается все состояние.


Wyrd
03.05.2022 11:07+11Например если вы видели на экране “XYZ” 10 раз прокрутив контент вверх вниз несколько раз, то аналитика отправлялась 10 раз. Хоть 1 раза было достаточно.
Ну то есть раньше в аналитике были видны множественные прокрутки до конкретного контента, а теперь нет. Надеюсь, аналитики были в курсе изменений.
Kotsusamu
03.05.2022 11:15+5Вот вот, обычно аналитикам крайне важно, сколько раз и как было показано ключевое слово/фраза/картинка.
Чета тут не то...
ialexander
03.05.2022 11:59+1Их больше метрики типа кликов на показы интересуют. Притом показ пользователю должен считаться один раз за сессию, скроллинг не должен генерировать новые показы. Похоже автор топика ещё и баг исправил. У них теперь CTR должны немного подрасти.

kubk
03.05.2022 11:54+4Очень верное замечание. Такими темпами можно вообще аналитику удалить и сэкономить ещё больше непонятно как посчитанных денег.


astralNord
03.05.2022 12:59+2-Босс, я придумал как фирме экономить 2 тысячи баксов в месяц!
-Решил уволится?Не, фикс, наверно полезный для Uber, но памятуя какие у них зарплаты вспоминается этот анекдот.

yukon39
03.05.2022 13:26+4Дедупликация UUID-ов? Они же «по определению» уникальные. Сдается мне, что настоящая ошибка находится несколько выше по стеку, а это всего лишь попытка исправить следствие неверной архитектуры решения.
До кучи, писать в такой «лог» чревато потерей информации — представленный фрагмент кода просто отбрасывает ЛЮБЫЕ новые сообщения с тем же идентификатором.makar_crypt
03.05.2022 15:20+2Сто процентов , только хотел написать. Проблема явно в архитетуре , а это попытка замазать проблему. Ну а по поводу статьи , больше самопиар

nochkin
03.05.2022 18:47-1Справедливости ради, там написано "дедупликация аналитики", а не "дедупликация UUID". Это не одно и тоже.
Да и по логике видно, что идёт проверка на наличие UUID, а не проверка на его уникальность.
hellamps
03.05.2022 15:20+6Я правильно понял, что в конце графика бэкенд упал с ООМ?
Этот сет по-хорошему должен быть ограниченным по количеству LRU list

yegreS
03.05.2022 21:43+1Проблема
Часто используемый скрин приложения отправлял impression аналитику при прокрутке экрана с дублированием. Например если вы видели на экране “XYZ” 10 раз прокрутив контент вверх вниз несколько раз, то аналитика отправлялась 10 раз. Хоть 1 раза было достаточно.
А с каких пор для аналитики это стала проблема? мне кажется это автор своим решением сделал проблему для аналитиков

Zuy
У этих 3х абзацев ещё и черновой вариант был?! Чуствую все таки дождусь когда статьи на хобре в виде твитов появятся.
SDKiller
У этих 3х абзацев еще и tldr есть в телеграм-канале автора
goldrobot
Как бы вам помягче рассказать...