
В 2022 году «бигдатой» никого не удивишь. Эта область компьютерных наук из инновационной и хайповой стала необходимой и привычной. Однако внутри она по-прежнему бурно развивается. Один из восходящих трендов — синергия данных. Объединяя и совместно анализируя данные из разных отраслей, можно сделать много интересного.
Этому подходу, а также более общим вопросам Big Data и Machine Learning была посвящена конференция Data Fusion, прошедшая 14–15 апреля в онлайн-формате. На ней был затронут широкий спектр тем, от маркетинга до свободы воли. Пересказывать конференцию целиком — труд огромный и напрасный. Поэтому поговорим об отдельных интересных докладах, а с остальной программой вы можете ознакомиться самостоятельно.
Доверие и этика в ИИ
Если в мире и наступает киберпанк с его безжалостными и беспринципными мегакорпорациями, то делает он это очень постепенно. Современный капитализм старается иметь человеческое лицо. Иногда благодаря государственному регулированию, порой из репутационных соображений, но так или иначе вопросы этики и доверия не чужды продвинутому инфобизнесмену, а уж тем более — дата-сайентисту.
Ответственность ИИ — очевидная вещь, когда речь идёт об автопилоте Tesla. Однако и в более безобидных случаях действия ИИ могут влиять на человеческие судьбы. Например, в случае рекомендательной системы. Представим систему, которая советует книги, похожие на уже прочитанные. Что, если вслед за книжками для детсада такая система посоветует де Сада? Или человеку, который ищет способы борьбы с депрессией, — «Страдания юного Вертера»?

Ладно, это тоже слишком драматичные примеры. А если, наоборот, ИИ по каким-то причинам отказывается рекомендовать одну конкретную книгу, которая действительно похожа на прочитанную? Психика читателей не пострадает, а вот автор будет голодать.
Конечно, полностью исключить возможность ошибок нельзя. Но можно уменьшить их вероятность. Обучающие данные должны быть максимально репрезентативными — не содержать ни личных предпочтений разработчиков, ни «накруток» пользователей. Также важна работа над ошибками. Удобная форма репорта и оперативное реагирование позволят свести ущерб к минимуму.
Технологии машинного обучения меняют мир. А когда меняешь мир, важно понимать, в какую сторону. Разработчик ИИ должен думать не только о том, насколько корректно его детище будет исполнять свою функцию, но и о том, как оно повлияет на общество в целом. В качестве примера можно вспомнить аналитические системы на вооружении американской полиции. Они предсказывали большую вероятность преступления для чернокожих граждан. Статистически это совершенно корректное предсказание, однако если его принять как руководство к действию, оно становится самоисполняющимся пророчеством: тот, к кому заранее относятся как к преступнику, с большей вероятностью им станет.
И, наконец, самое главное: ответственности ИИ не существует. Возможно, в мире победившего киберпанка искусственный интеллект и приобретёт субъектность, но в наше прекрасное время ответственным может быть только человек. Действительно важные решения всегда должны контролироваться человеком. ИИ может давать рекомендации, но он не должен самостоятельно, допустим, увольнять сотрудника, негативно оценив его эффективность. Или отправлять пациента на удаление опухоли. Увольнением должен заниматься HR, лечением рака — онколог. ИИ — лишь инструмент в их руках.
Робастность глубоких нейросетей
Не все знают слово «робастность», но все должны помнить хотя бы одну из длинной серии новостей про «обманывание» классифицирующих нейросетей. Наложив на изображение едва заметный шум, можно превратить панду в гиббона, а с помощью почти неразличимого макияжа удаётся обмануть систему распознавания лиц. Такие трюки получили общее название Adversarial Attack.
Принцип атаки прост. Во-первых, нужен классификатор, похожий на атакуемый. Например, сам атакуемый классификатор, если к нему есть доступ. Либо его «копия» — собственная модель, обученная на схожей выборке схожим образом.
Во-вторых, нужна генеративная модель с хитрой целевой функцией. Она будет стремиться генерировать объекты, которые по какой-то метрике (скажем, по среднеквадратичному отклонению) максимально похожи на искажаемый объект, но максимально далеки от него с точки зрения классификатора из предыдущего пункта.
Объекты, с которыми работают нейросети, обычно существуют в очень многомерных пространствах. Скажем, изображение объёмом 32 килобайта — это двоичный вектор в 262144-мерном пространстве. В многомерных пространствах у каждого объекта очень много соседей, отличающихся от него лишь несколькими координатами. А значит, высока вероятность, что один из соседей будет ошибочно классифицирован.

В прозвучавшем докладе предлагается метод борьбы с такими подделками, основанный на специальных математических объектах — многообразиях. Докладчик предлагает особую меру схожести, которая основана на топологических свойствах пространства распознаваемых объектов. Используя эту меру схожести вместо стандартной, можно затруднить проведение Adversarial Attack.
Конфиденциальные вычисления
В современном мире обработка данных всё чаще совершается с помощью внешних сервисов. Но что, если это конфиденциальные данные? Можно найти обработчика, достойного доверия, скажете вы. А если вы параноик? Тогда можно не отдавать данные никому, обсчитывать их самостоятельно. А если вы не умеете? Казалось бы, ситуация из серии «и рыбку съесть, и в кресло сесть». Однако выход существует: маленькое алгоритмическое чудо, имя которому — конфиденциальные вычисления.
Есть несколько общих принципов, на которых основываются конфиденциальные вычисления. Один из них — разделение секрета. Допустим, у вас есть данные о множестве транзакций, вы хотите посчитать итоговый баланс, однако величины транзакций — страшная коммерческая тайна. Не беда. Разделите каждую транзакцию на две случайных части, все «левые» части отправьте одному обработчику, все «правые» части — другому. Получатся две суммы, останется только сложить их между собой. Разумеется, это до предела упрощённый пример, но принцип рабочий. Разделяя секретные данные на части, можно сохранить их в секрете.
Другой принцип — гомоморфное шифрование. Это ещё интереснее: производящий вычисления вообще понятия не имеет, с какими данными работает. Очень грубый пример: допустим, у нас есть те же самые данные о транзакциях. Умножим все числа на одно и то же случайно выбранное число (например, 293). Вычислитель просуммирует эти домноженные данные, затем мы разделим итоговый результат на 293. Поскольку множитель не был известен тому, кто вычислял, он не сможет восстановить истинные величины транзакций.
Конечно, такое шифрование сработает только с очень недогадливым вычислителем, который не заметит, что все числа делятся на 293, или не сумеет воспользоваться пропорцией (узнав величину одной транзакции из какого-то третьего источника). Тем не менее в реальности существуют такие способы гомоморфного шифрования, которые дают криптографические гарантии конфиденциальности.
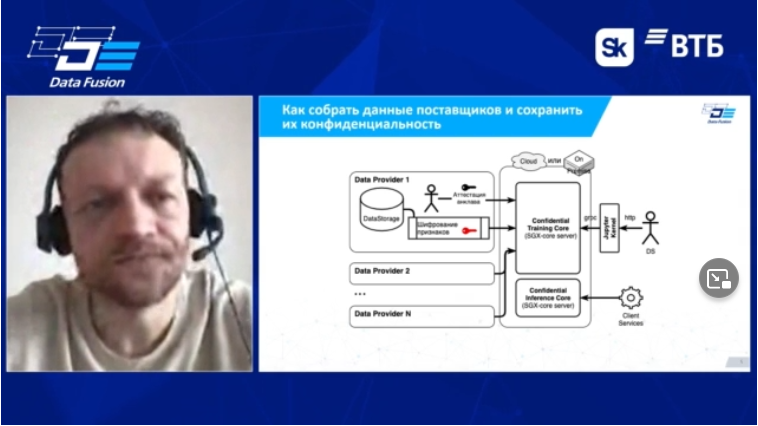
Более того, существуют даже способы скрыть сам факт запроса. Однако о них лучше узнать непосредственно от докладчика.
Нейроданные
Многие считают, что нейросеть — это такая универсальная машина, в которую надо просто насы́пать побольше данных, а она уже сделает все необходимые выводы, понятия не имея, с чем вообще работает. Особенность этого заблуждения в том, что это, в общем-то, не заблуждение, а правда. Но есть нюансы.
Если взять очень большую нейросеть, дать ей очень много данных и очень много времени — скорее всего, она действительно во всём разберётся, самостоятельно выявит все существенные признаки и так далее. Но на практике мы хотим подешевле, побыстрее, понадёжнее. А для этого может быть полезно «информировать» нейросеть о природе обрабатываемых данных. Этого можно добиться при выборе архитектуры, или модифицируя целевую функцию, или, по крайней мере, валидируя результаты.
Первое правило работы с нейроданными (то есть данными о работе нервной системы): нужно убедиться, что действительно имеешь дело с нейроданными. Снимать активность нейронов нелегко, на детекторы могут влиять разнообразные помехи или феномены, с нервной системой напрямую не связанные. Как отделить мух от котлет? В нейроданных есть закономерности, на которые можно ориентироваться. Например, большие популяции нейронов активны на низких частотах, а маленькие — на высоких. Если в данных, снимаемых, скажем, с коры головного мозга, присутствует высокочастотная активность на большом количестве соседних электродов — значит, данные врут и показывают не активность нейронов, а что-то другое. Заранее встроив фильтрацию таких вещей в архитектуру нейросети, можно избавить себя от множества проблем.

Второе правило работы с нейроданными: одни и те же данные можно интерпретировать по-разному. Выбор верного представления данных опять же может облегчить работу нейросети. Например, данные МРТ можно интерпретировать как набор срезов, можно как единый 3D-массив. А можно воспользоваться знанием предметной области. Мозг — структура непрерывная, в том смысле, что данные очень близких точек, скорее всего, будут также очень близкими. Вместо того чтобы брать данные по всему мозгу, можно выбрать разрежённое облако точек в нём — эти данные будут менее скоррелированными между собой и потому будут содержать больше полезной (для нейросети) информации на бит. Более того, зная устройство мозга, мы понимаем, какие его части нам более интересны в рамках конкретной задачи (скажем, поиска опухоли). И можем сделать наше облако точек более плотным в этих местах.
Третье правило работы с нейроданными: процессы, происходящие в нервной системе, — это… процессы. В прошлом пункте мы говорили о непрерывности в пространстве, но существует также непрерывность во времени. Предыдущее, текущее и последующее значения измерений связаны между собой, и эту связь, как и любую другую, нейросеть может ухватить. Благодаря этому можно, например, с помощью генеративных моделей предсказывать рост опухолей.
Заключение
Конференция Data Fusion сама по себе иллюстрирует принцип синергии данных. Из докладов множества узких специалистов складывается целостная картина и понимание, где сегодня пролегает фронтир Data Science. А каждый, кто читал в детстве Фенимора Купера, помнит: фронтир — это интересно и романтично.