
Меня зовут Мешкова Анна. Я руковожу стримом «Озеро данных» на Фабрике данных ВТБ. И этот текст о том, как мы в банке смогли выстроить унифицированный процесс загрузки данных, какие задачи себе ставили и что из этого получилось.
Наша команда входит в Фабрику данных банка ВТБ и отвечает за загрузку всех внешних и внутренних систем-источников в Datalake на базе Hadoop.

Объёмы создаваемых банком данных неуклонно растут: уже сейчас в озере несколько петабайт данных, объём загрузки за последний год вырос в пять раз. За последний год было загружено более 50 новых источников. И каждый день процесс доступа к данным становится на пути решения бизнес-задач. Приоритеты бизнеса сдвигаются в сторону скорости доставки данных и удобства доступа к ним.
Уже недостаточно иметь гарантированную доставку данных. Сейчас надо обеспечивать доставку real time, сохраняя при этом структурированность, надежность и консистентность данных.
Кто из вас не сталкивался с ситуацией, когда текущая архитектура выстроена, исходя из разной логики обработки данных на системе-источнике, и как результат одновременно существуют несколько движков загрузки и несколько команд для их развития и сопровождения? И с каждым днем с ростом объемов функционала непропорционально растут затраты на последующие доработки и поддержку.
Также, я думаю, вы не раз сталкивались с задачей, как аргументировать заказчику трудоемкость перевода той или иной загрузки на другой режим, а уж тем более, если требуется объединить несколько типов репликации в один для бесшовного использования самих данных.
В этих условиях процессы развития, сопровождения и установки релизов становились всё более ресурсоемкими. Требовалось больше ресурсов для поддержания темпов развития и качества загрузки. Тогда мы решили сделать реинжиниринг процессов и привести все к единому знаменателю — перейти на унифицированный движок.
Какую цель мы себе поставили?
Создать единый централизованный механизм загрузки из реляционных источников данных (Oracle DB, MSSQL, PostgreSQL, Vertica, Teradata, HDFS, Arenadata DB) и из нереляционных (S3, Kafka, NFS);
Новый механизм загрузки должен быть создан на импортозамещенных и opensource решениях;
Уменьшить количество используемых и поддерживаемых алгоритмов загрузки;
Упростить процесс разработки (привести к режиму конфигурации);
Упростить процесс локализации ошибок;
Перейти к централизованной установке версий.
Для создания движка мы выделили отдельную команду разработки из наиболее мотивированных и квалифицированных сотрудников. Их задача – развивать движок загрузки, соблюдая разумный баланс между поддерживаемой функциональностью и сложностью конфигурации.
После детального анализа было решено сделать реализацию в виде Spark-приложения на Scala: этот язык — «родной» для Spark, а сам Spark — один из одновременно зрелых и активно развивающихся проектов Hadoop. Оркестрация и конфигурация потоков была делегирована Apache Airflow, это стандарт нашей фабрики. Для хранения credentials выбрали Hashicorp Vault, что позволило избежать уязвимостей Airflow с точки зрения безопасности.
Метаинформацию решили класть в отдельную БД на Pоstgres, чтобы не заставлять себя и hdfs страдать от мелких, часто обновляемых файлов. Результатом такого верхнеуровневого проектирования стал следующий архитектурный дизайн:
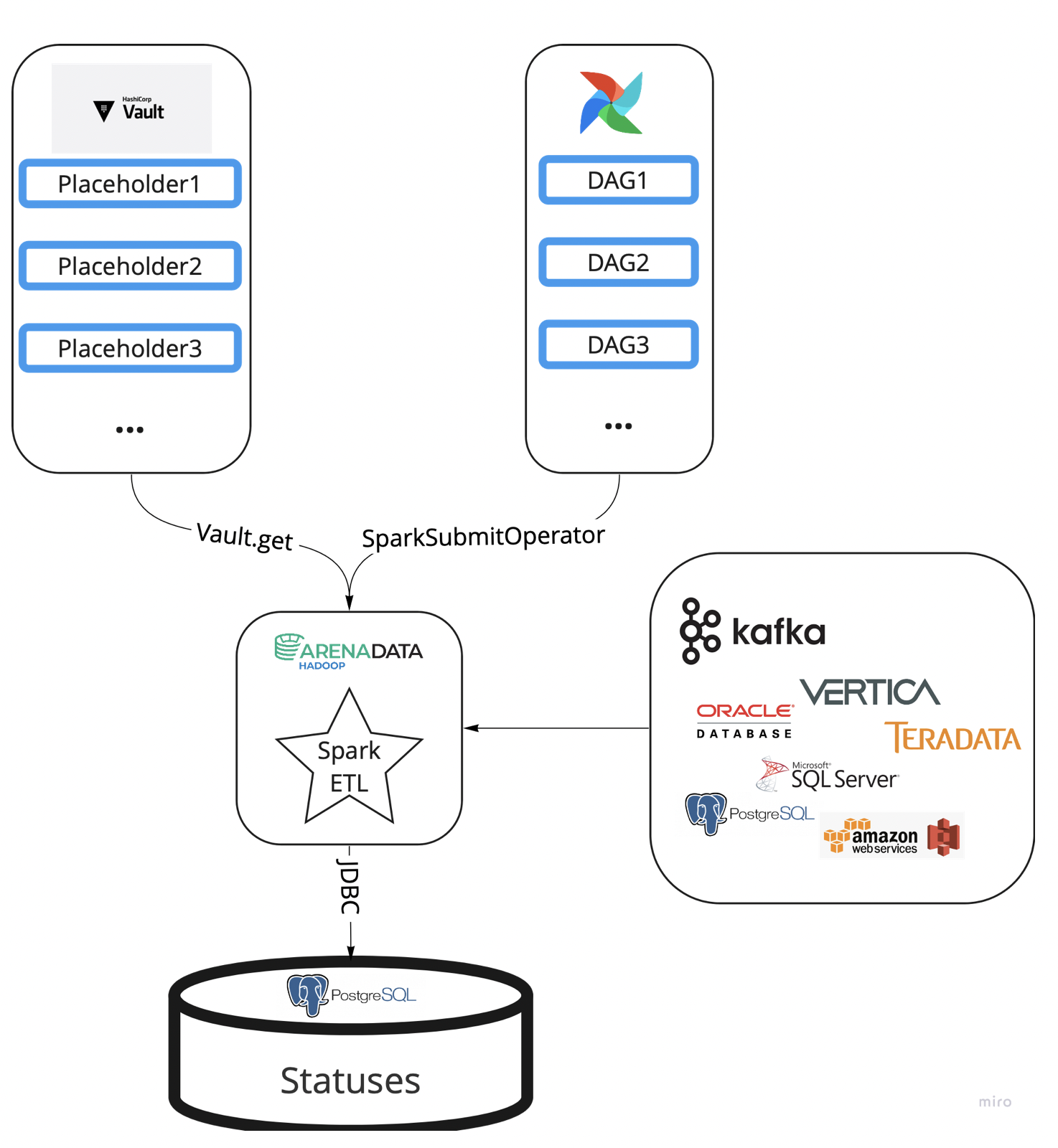
Что было дальше
Договорившись о том, как продукт должен выглядеть в результате и что должен делать, команда приступила к реализации.
Agile-подход помог максимально быстро выйти на MVP и раз в спринт выпускать новую версию, реализующую очередную часть заявленной функциональности. Как и все новые проекты в банке, мы используем стандартный набор инструментов для реализации CI/CD. Регулярная обратная связь от коллег, пользующихся фреймворком, позволила сохранить баланс между покрытием legacy-алгоритмов и возрастающей сложностью настройки. В ходе разработки пришлось решать ряд инженерных вопросов, например, compaction-файлов в hdfs и запрет параллельной записи в одну таблицу.
В процессе проектирования мы также решили оптимизировать процесс хранения мелких файлов. Для оптимального хранения, как известно, желательно в hdfs-директории складывать файлы размером около hdfs block size каждый. Для этого перед записью файлов нужно знать размер датафрейма, пришедшего на шаге Extract. Здесь мы решили поэкспериментировать и взяли из текущего кластера информацию по каждой таблице об объеме памяти, которую она занимает в hdfs, о количестве строк и о типах всех атрибутов в данной таблице, чтобы вычислить зависимость между количеством строк, столбцов, типов данных и целевой переменной — размером датасета.

Интерес представляет случай, когда статус объекта — RUNNING. Тут, несмотря на статус, возможны два случая:
1) Объект действительно сейчас грузится.
2) Кластер упал во время работы приложения, и терминальный статус по объекту уже некому было проставить.
Для определения второго случая мы из приложения идем в логи yarn и по applicationId определяем статус последнего приложения. Оно либо RUNNING, либо KILLED. И мы предпринимаем skip\sleep, либо disaster recovery plan соответственно.
Спустя три спринта разработки команда сформировала продукт с широким охватом функциональности и достаточной стабильностью. На этом прочном фундаменте стало возможно с минимальными трудозатратами проводить тестирования новых lakehouse-фреймворков работы с объектами на уровне hdfs.
Как известно, к Hdfs и Hive применим принцип write once read many. Что на уровне разработки вызывает неудобства и различные самописные реализации обновления данных в таблицах. Эту задачу решили в четырех разных фреймворках: Delta Lake, Hudi, Iceberg, Carbondata. В рамках пилотирования мы сделали четыре ветки для работы с каждым из фреймворков, что позволило провести сравнение производительности, оптимальности и зрелости фреймворков. Выбранный на основе критериальной таблицы лидер был влит в мастер-ветку проекта в виде отдельного алгоритма загрузки.
Помимо функциональности, несущей полезность для нас как для команды, загружающего данные в Data Lake, метаинформация о ETL-потоках позволяет потребителям наших данных оптимизировать свои процессы. Самый очевидный кейс такого использования — проверка готовности таблиц перед построением витрин над ними. Также business critical процессы, пользующиеся нашими данными, на основе метаинформации способны нивелировать временной промежуток в цепочке процессов с помощью событийных механизмов.
Чего мы добились?
Результатом работы стал общий движок загрузки в data lake c обвязкой отдельных полезных сервисов (рис. 3);
За квартал тиражные команды смогли настроить загрузку более 2000 объектов. Ежедневный поток обрабатываемых данных — 2.2 Тб;
Снизился порог вхождения. Для настройки потока не требуется знаний языков программирования;
Создали общую базу кода на промышленном контуре;
Упростили процесс миграции с Cloudera Hadoop на Arenadata Hadoop;
Сократили время загрузки initial load с помощью автоматического режима многопоточности.
Но все это лишь первая версия продукта, наша ближайшая цель — его декомпозиция в полноценный фреймворк.

Комментарии (3)

beTrue
27.10.2022 21:22Анна, вы вообще не алло. Репликацию данных не пишут на спарке, вы кластером идете читать с дисков БД, это не правильно, если инкремент будет аховый вы будете не ночью, а уже днём нагибаться диски БД АСок - это первое, тут даже не про спарк, а вообще о подходе. Второе - спарк не для репликации , тем более тех БД которые вы перечислили , м б Кассандра , и то такое себе. Третье - у вас был BDA там экстернал тэйблы, зачем вообще реплика вам из оракла, там хдфс и оракла БД как один инстанс. Вы смигрировали в арену, или ещё в BDA? И последнее и самое важное, вам нужно писать свой аналог golden gate, с чтением налёту из лога БД, а не с дисков. Вот напишите, тогда крутые, а так велосипед немасштабируевым и идиоматически кривой, озеро никуда само за данными не ходит. Пишите в ЛС, проконсультирую

BogdanPetrov
27.10.2022 21:25Кажется, что кусок статьи пропал (после проблемы мелких файлов какой-то резкий переход к проблеме одновременной записи (?))
Конфигурация пишется вручную полностью с нуля или есть какой-то wizard, с помощью которого можно получить конфиг, который потом при необходимости отредактировать вручную? Есть ли Web UI? Конфиг хранится с Git-е или тоже в PostgreSQL?
Bigata
Ну да, ну да, шашечки вы отлично наловчились рисовать, а вот в интерфейсе интернет банка не допросишься платежного поручения, нужно за бумажкой ехать в банк.
И ещё для некоторых карт почему нет вообще истории операций, это как?