
Много лет я пользовался языком программирования Julia для преобразования, очистки, анализа и визуализации данных, расчёта статистики и выполнения симуляций.
Я опубликовал несколько опенсорсных пакетов для работы с такими вещами, как поля расстояний со знаком, поиск ближайших соседей и паттерны Тьюринга (а также с другими), создавал визуальные объяснения таких концепций Julia, как broadcasting и массивы, а ещё применял Julia при создании генеративной графики для моих визиток.
Какое-то время назад я перестал пользоваться Julia, но иногда мне задают о нём вопросы. Когда люди спрашивают меня, я отвечаю, что больше не рекомендую его. Мне подумалось, что стоит написать, почему.
После многолетнего использования Julia я пришёл к выводу, что в его экосистеме слишком много багов корректности и сочетаемости, и это не позволяет использовать этот язык в контекстах, где важна корректность.
По моему опыту, Julia и его пакеты имеют наибольшую частоту серьёзных багов корректности из всех использованных мной программных систем, а ведь я начинал программировать с Visual Basic 6 в середине 2000-х.
Наверно, будет полезно привести конкретные примеры.
Вот проблемы корректности, о которых я составил отчёты:
- Сэмплирование плотности вероятности даёт некорректный результат
- Сэмплирование массива может давать результаты со смещением
- Функция произведения может давать некорректные результаты для 8-битных, 16-битных и 32-битных integer
- Подгонка гистограммы под массив Float64 может давать некорректные результаты
Базовые функции sum!,prod!,any!иall!могут возвращать некорректные результаты без сообщения об ошибке
Вот похожие проблемы, о которых сообщали другие люди:
- Summarystats возвращает квантили NaN для массивов со средним значением 0
- OrderedDict может повреждать ключи
- Ошибка смещения на единицу в dayofquarter() в високосные годы
- Некорректные результаты симуляции при использовании типа number с величиной ошибки
- Pipeline со stdout=IOStream выполняет запись не по порядку
Неверные результаты, поскольку некоторые методы copyto!не выполняют проверку на наложение- Неверный поток управления if-else
Я сталкивался с багами подобного уровня серьёзности достаточно часто, поэтому это заставило меня подвергнуть сомнению корректность любых вычислений умеренной сложности на Julia.
Особенно справедливо это было при использовании нового сочетания пакетов или функций — комбинирование функциональности из нескольких источников было существенным источником багов.
Иногда проблемы возникают из-за несочетаемых друг с другом пакетов, в других случаях к неожиданному сбою приводит неожиданное сочетание возможностей Julia внутри одного пакета.
Например, я выяснил, что евклидово расстояние из пакета Distances не работает с векторами Unitful. Другие люди обнаружили, что функция Julia для запуска внешних команд не работает с подстроками. Кто-то выяснил, что поддержка отсутствующих значений Julia в некоторых случаях ломает матричное умножение. И что макрос стандартной библиотеки
@distributed не работал с OffsetArray.OffsetArray вообще оказался серьёзным источником багов корректности. Пакет предоставляет тип массива, использующий гибкую функцию настраиваемых индексов Julia, позволяющую создавать массивы, индексы которых не обязаны начинаться с нуля или единицы.
Их использование часто приводит к доступу к памяти out-of-bounds, с которым вы могли встречаться в C или C++. Если повезёт, это приведёт к segfault, а если нет, то результаты будут неверными без сообщений об ошибках. Однажды я нашёл баг в ядре Julia, который может привести к доступу к памяти out-of-bounds, даже если и пользователь, и создатели библиотеки написали корректный код.
Я отправил множество отчётов о проблемах индексации в организацию JuliaStats, занимающуюся обслуживанием статистических пакетов наподобие Distributions, от которого зависят 945 пакетов, и StatsBase, от которого зависят 1660 пакетов. Вот некоторые из них:
- Большинство методов сэмплирования небезопасно и некорректно в случае наличия смещённых осей
- Выравнивание распределения DiscreteUniform может вернуть некорректный ответ без сообщения об ошибке
- counteq, countne, sqL2dist, L2dist, L1dist, L1infdist, gkldiv, meanad, maxad, msd, rmsd и psnr со смещёнными индексами могут возвращать некорректные результаты
- Некорректное использование @inbounds может вызывать неверный расчёт статистики
- Colwise и pairwise могут возвращать некорректные расстояния
- Отображение вектора Weights, оборачивающего массив со смещением, выполняет доступ к памяти out-of-bounds
Первопричиной этих проблем является не сама индексация, а её совместное использование с другой фичей Julia под названием
@inbounds, позволяющей Julia удалять проверки границ при доступе к массивам.Пример:
function sum(A::AbstractArray)
r = zero(eltype(A))
for i in 1:length(A)
@inbounds r += A[i] # ← ????
end
return r
endПоказанный выше код выполняет итерации
i от 1 до длины массива. Если передать массив с необычным диапазоном индексов, код выполнит доступ к памяти out-of-bounds: операции доступа к массив аннотированы @inbounds, что убирает проверку границ.Этот код показывает, как неправильно использовать
@inbounds. Однако многие годы это был официальный пример по правильному использованию @inbounds. Этот пример был расположен прямо над предупреждением о том, почему он неправилен: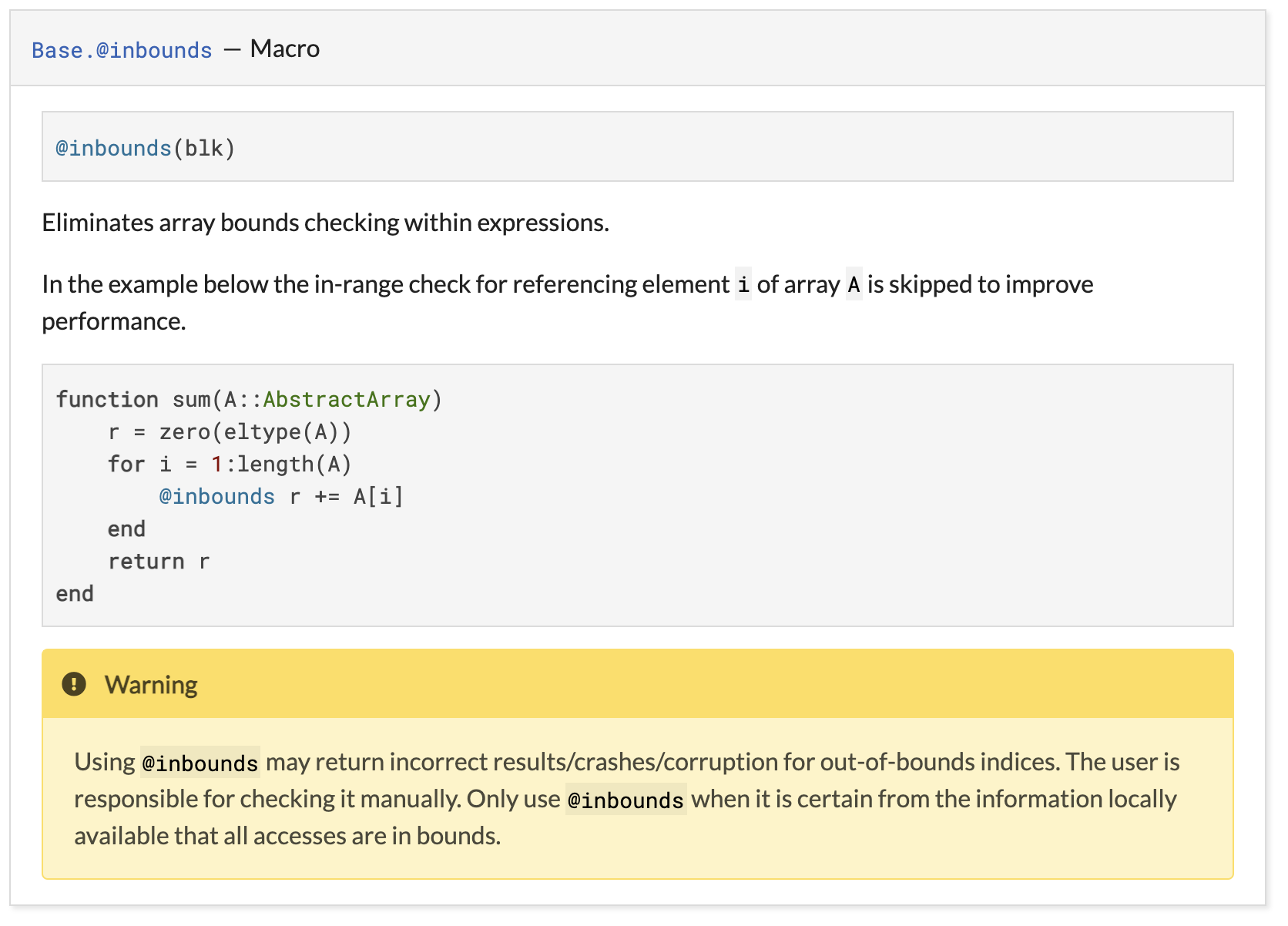
Эту проблему уже устранили, однако вызывает беспокойство то, что
@inbounds можно так легко использовать неверно, что приводит к незаметному повреждению данных и некорректным математическим результатам.По моему опыту, подобные ошибки касаются не только математической части экосистемы Julia.
Я сталкивался с багами библиотек в процессе выполнения повседневных задач, например, при кодировании JSON, отправке HTTP-запросов, использовании файлов Arrow совместно с DataFrames и редактировании кода Julia в реактивной среде ноутбуков Pluto.
Когда мне стало интересно, репрезентативен ли мой опыт, множество пользователей Julia поделилось со мной похожими историями. Недавно стали появляться и публичные отчёты о подобном опыте.
Например, в этом посте Патрик Киджер описывает свои попытки использовать Julia для исследований машинного обучения:
На Julia Discourse довольно часто встречаются посты «Библиотека XYZ не работает», на которые следуют ответы одного из мейнтейнеров библиотеки: «Это апстрим-баг в новой версии a.b.c библиотеки ABC, от которой зависит XYZ. Мы запушим исправление ASAP».
Вот каким был опыт Патрика по выявлению бага корректности (выделено мной):
Чётко помню момент, когда одна из моих моделей Julia отказывалась обучаться. Я много месяцев пыталась заставить её работать, пробуя все трюки, которые мог придумать.
В конце концов, я нашёл ошибку: Julia/Flux/Zygote возвращал некорректные градиенты. После того, как я потратил так много энергии на указанные выше пункты 1 и 2, на этом пункте я просто сдался. Спустя ещё два часа разработки я успешно обучил модель… в PyTorch.
В обсуждении этого поста другие пользователи писали, что у них тоже был похожий опыт.
@Samuel_Ainsworth:
Как и @patrick-kidger, я пострадал от багов с некорректными градиентами в Zygote/ReverseDiff.jl. Это стоило мне недель жизни и заставило меня серьёзно пересмотреть уровень своего опыта во всей системе Julia AD. За все годы работы PyTorch/TF/JAX я ни разу не столкнулся с багом некорректных градиентов.
@JordiBolibar:
С момента, когда я начал работать с Julia, у меня возникло два бага с Zygote, замедливших мою работу на много месяцев. С другой стороны, это заставило меня погрузиться в код и многое узнать о библиотеках, которые я использую. Но я оказался в ситуации, когда нагрузка стала слишком большой и я тратил много времени на отладку кода вместо того, чтобы проводить климатические исследования.
Учитывая чрезвычайную обобщённость Julia, не очевидно, можно ли решить проблемы корректности. В Julia нет формального понятия интерфейсов, в generic-функциях часто в пограничных случаях семантика не указывается, а природа самых общих косвенных интерфейсов не сделана чёткой (например, в сообществе Julia нет согласия по поводу того, что является числом).
В сообществе Julia множество способных и талантливых людей, щедро делящихся своим временем, трудом и опытом. Однако подобные систематические проблемы редко удаётся исправить снизу вверх, и мне кажется, что руководство проекта не согласно, что существует серьёзная проблема корректности. Оно соглашается с существованием отдельных несвязанных друг с другом проблем, но не с паттерном, который подразумевают эти проблемы.
Например, в то время, когда экосистема машинного обучения Julia была ещё более незрелой, один из создателей языка с энтузиазмом рассказывал об использовании Julia в продакшене для беспилотных автомобилей:
И хотя с тех пор, как я перестал быть активным участником, отношение к этому могло измениться, следующая цитата ещё одного создателя языка, произнесённая примерно в то же время, стала хорошей иллюстрацией разницы восприятий (выделено мной):
Думаю, самый важный вывод здесь заключается не в том, что Julia — отличный язык (хотя это и так) и что его нужно использовать для всего (хотя это и не самая плохая идея), а в том что его архитектура сделала важный шаг к возможности повторного использования кода. На самом деле в Julia вы можете взять обобщённые алгоритмы, написанные одним человеком, и собственные типы, написанные другими людьми, и просто использовать и эффективным образом. Это серьёзно повышает ставки уровня повторного использования кода в языках программирования. Проектировщикам языков не нужно копировать все возможности Julia, но им, по крайней мере, стоит понимать, почему он так хорошо работает, и стремиться к тому же уровню повторного использования кода в архитектурах будущего.
Каждый раз, когда появляется пост с критикой Julia, люди из сообщества обычно быстро пишут в ответ, что раньше были проблемы, но сейчас всё существенно улучшилось и большинство проблем уже устранено.
Примеры:
- В 2016 году: «Проблемы, перечисленные в этом посте, устранены».
- В 2018 году: «Когда начинал знакомство с языком, я тоже жаловался на „ковбойскую“ культуру, которую наблюдал в среде Julia-разработчиков, но те времена уже прошли».
- В 2020 году: «В 2016 году да. Но теперь проблемы уже решены».
- В 2021 году: «В Julia нет технического принуждения к согласованности, однако семантическое значение generic-функций соблюдается большинством и обобщённый код работает».
- В 2022 году: «Разумеется, баги есть, но ни один из них не является серьёзным».
Эти ответы в своём узком контексте часто кажутся разумными, но в целом из-за них настоящие ситуации кажутся приуменьшенными, а глубокие проблемы остаются непризнанными и нерешёнными.
Мой опыт взаимодействия с языком и сообществом за прошедший десяток лет намекает, что, по крайней мере, с точки зрения базовой корректности язык Julia сейчас ненадёжен и не находится на пути к становлению надёжным. В большинстве случаев использования, на которые нацелена команда разработчиков Julia, риски попросту не стоят выгод.
Десять лет назад создатели языка Julia рассказали миру о вдохновляющих и амбициозных целях. Я по-прежнему верю, что однажды их можно будет достичь, но без пересмотра паттернов, приведших проект в текущее состояние, это невозможно.
Комментарии (29)

nin-jin
18.05.2022 16:22+3Есть же нормальные языки типа D, которые и удобные как Python, и быстрые как C, и с мощным тайпчеком как Rust. Зачем люди бросаются в эти крайности, переписывая код с одного на другой, потом вообще вляпываясь в Julia без гарантий корректности?

ZaDOOMchiviy
18.05.2022 19:10+2От части согласен, но дело наверное в том что Julia это что-то вроде попытки совместить язык программирования общего назначения и математический пакет наподобие Matlab. Потому возможно люди занимающиеся научными вычислениями его и полюбили.

borovichok13
18.05.2022 22:18+4Я пишу небольшие программы программы раз 3-5 лет. Каков порог вхождения в D ? Как и в Си? Тогда - мимо кассы. Julia, как и Бейсик (классический) имеет низкий порог вхождения. В первый же день можешь начать писать программу. В этом их плюс. А в Си мне не удалось. За три года почти все забудешь и заново по примерам будешь восстанавливать. Наука, однако. Писал в машинных кодах, Бейсике, Обероне, а теперь вот на Julia. Просто удобно в в ней писать программы. Для таких как, я, важна не красота кода и скорость исполнения программы, а результат.

Druj
19.05.2022 11:31Зависит от сложности программ которые вы собираетесь писать и варьируется от уровня JS до уровня раста.
nin-jin
19.05.2022 11:33+1Можете сами попробовать: https://tour.dlang.org/tour/ru/welcome/welcome-to-d
Ну и D - не единственная альтернатива. Nim, например, ещё есть: https://nim-lang.org/borovichok13
19.05.2022 13:14+1Спасибо. D - не понравился, а вот Nim вполне приятен моему глазу. Когда буду писать новую программу, то его попробую.

Siemargl
19.05.2022 09:27+1Потому что на вычислительных задачах D проигрывает Julia в удобсте и лаконичности. Все же специализация.
Я переводил. Код можно посмотреть и сравнить, на D он там ужасен.
nin-jin
19.05.2022 11:46Не нашёл там ужасного кода, куда смотреть?
Siemargl
19.05.2022 11:49+1https://github.com/dataPulverizer/KernelMatrixBenchmark
135 LOC для Julia и куча невнятного изобретения велосипедов на D
nin-jin
19.05.2022 22:59https://github.com/dataPulverizer/KernelMatrixBenchmark/blob/master/julia/KernelMatrix.jl 3.22 KB
https://github.com/dataPulverizer/KernelMatrixBenchmark/blob/master/d/kernel.d 3.94 KB
Где там "куча невнятных велосипедов"?
Siemargl
20.05.2022 10:31arrays.d +426 LOC
итого на D 229+426 LOC vs 135 Джулии
nin-jin
20.05.2022 11:29https://github.com/JuliaLang/julia/blob/master/stdlib/LinearAlgebra/src/symmetric.jl + 30 KB
https://github.com/JuliaLang/julia/blob/master/stdlib/LinearAlgebra/src/symmetriceigen.jl + 10 KB
Вы сравниваете тёплое с мягким.
Siemargl
20.05.2022 19:46ну да, в специализированном языке все необходимое есть в стандартной библиотеке.
а в универсальном - пишется каждый раз свой велосипед.
я знаю, что есть D libmir, но почему его не использовали - хз
nin-jin
20.05.2022 20:09Да какая разница стандартная или нестандартная библиотека? Они только неймспейсом отличаются. Ну и предустановленностью с компилятором с соответствующими проблемами с обновлениями.

DirectoriX
20.05.2022 13:05+1arrays.d +426 LOC
Это же с учётом кучи скобочек на отдельных строках. Если убрать строки, в которых только пробелы и открывающая скобка — останется 357 строк.
Я это к чему: даже если у вас будет 2 абсолютно одинаковых по структуре куска кода (например набор базовых арифметических операций типаfn sum(a, b) return a+b, то D проиграет по LOC из-за одного форматирования.
Поэтому LOC нет смысла сравнивать на голом месте, особенно для настолько разных языков (отступы vs скобочки), ну или хотя бы надо учитывать вот такие нечестные различия.
P.S. минифицированные JS-файлы имеют 1 LOC.Siemargl
20.05.2022 19:43вообще неверно. это языки одной группы Алгола, и там и там используются операторные скобки.
ну да, в Джулии только end, но это большой разницы не объясняет.
сравниваются читаемые программы от одного автора

AnthonyMikh
20.05.2022 01:37+1Есть же нормальные языки типа D, которые <...> и с мощным тайпчеком как Rust.
Извините, но сравнивать Rust с тайпчеком до мономорфизации и D с тайпчеком после инстанцирования шаблонов просто смешно. Rust уже за счёт этого на голову выше.

0xd34df00d
18.05.2022 18:43+3@inbounds
В Julia нет формального понятия интерфейсов, в generic-функциях часто в пограничных случаях семантика не указывается, а природа самых общих косвенных интерфейсов не сделана чёткой (например, в сообществе Julia нет согласия по поводу того, что является числом).Тяжко без завтипов. Зачем проектировать новые языки без них?

insecto
18.05.2022 22:37+2Потому что отрасль ещё не научилась в завтипы. Посмотреть сколько времени программисты учились в простые замыкания и first-class функции, до промышленных завтипов нам как до луны.
0xd34df00d
18.05.2022 23:51+2У меня есть чувство, что программисты, с трудом осилившие замыкания и вот это всё, не считают потом градиенты и не пишут хардкорный вычислительный код.
borovichok13
19.05.2022 16:31Даже без хардкорного кода бывают ещё те задачки. Например, поиск минимума в четырёхмерном овраге в резкими стенками и почти плоским дном. Для усложнения задачи: конец 80х и ДВК. Пока нашёл работающий поиск минимума, причём каждый надо было написать самому (алгоритмы были приведены в книге). Для науки, часто важен результат расчёта, а не скорость его получения. И чтобы совсем стало тоскливо - с использованием комплексных чисел. Это сейчас просто.

flx0
21.05.2022 08:49Вот кстати с завтипами в Julia все лучше чем в большинстве языков. Умножение в кольце вычетов, к примеру, выглядит так:
struct Quot{T, n} v::T end function (*)(a::Quot{T,n}, b::Quot{T,n}) where {T,n} Quot{T,n}(mod(a.v * b.v, n)) endТайпчекер сам проверит что вы ему скормили вычеты одного и того же типа по одному и тому же модулю, либо выкинет понятное исключение. Увы, в рантайме, это же скриптовый язык, зато никаких ручных проверок!
Но вот отсутствие интерфейсов - действительно беда. В коде выше прямо так и напрашивается указать трейты для T, а нельзя.
nin-jin
21.05.2022 10:48Где вы тут завтипы-то увидели? Это обычная типизация. На том же D этот код выглядит так:
struct Quot( alias Val, Val mod ) { Val val; alias Self = Quot!(Val,mod); auto opBinary( string op )( Self other ) { return Self( mixin( q{this.val} ~ op ~ q{other.val} ) % mod ); } } void main() { import std.stdio: writeln; auto left = 3.Quot!(uint,10); auto right = 5.Quot!(uint,10); writeln( left + right*left ); }И типы чекаются компилятором.
flx0
21.05.2022 12:31О, интересно. А если я вместо uint воткну какой-нибудь многочлен, или bigint, оно это прожует? На Расте так нельзя. Пойти что-ли попробовать этот ваш D.
Где вы тут завтипы-то увидели?
Ну как же, это П-тип, оно становится обычным типом только после подставления переменной n. Разве нет?
Tiendil
Julia - очень экспериментальный язык с интересной концепцией. Описанные проблемы выглядят как раз как детские проблемы любой технологии, просто их больше из-за нового подхода к семантике кода.
Пробовал экспериментировать с этим языком и меня смутили более фундаментальные штуки. Например, логика работы с памятью (где выделять память: на стеке или куче) зависит от описания типов. Из-за этого изменения в структуре данных влияют на выделение памяти для всех структур, которые прямо или косвенно её используют. Как следствие, сложно предсказать (по крайней мере новичку) как изменение повлияет на производительность.
А так, Dynamic typing + Multiple dispatch + JIT рулит. Если забыть о семантике памяти, то писать код приятнее, чем на других ЯП.
Если интересно, у меня в блоге подробный рассказ о пробном заходе на Julia: https://tiendil.org/julia-experience/
darksnake
Нет, это к сожалению не "детские" проблемы, а как раз проблемы, которые возникают при масштабировании. Это не отменяет того, что джулия весьма хороша в области прототипирования и изолированых научных задач. Но для больших многоцелевых фреймворков она вряд ли будет пригодна.
yokotoka
"Детские проблемы" в беспилотных автомобилях на дорогах общего пользования? Не, спасибо, а можно ТАМ что-то без детских проблем?
Tiendil
Так никто не заставляет использовать язык для беспилотных автомобилей.