

Привет, Хабр! Я работаю инженером компьютерного зрения в направлении искусственного интеллекта компании Норникель. Мы разрабатываем и внедряем модели с применением машинного обучения на наши производственные площадки.
В скоуп наших проектов попадают как системы, управляющие (или частично управляющие) технологическим процессом (например, флотация или плавка), так и системы промышленного машинного зрения, которые по сути представляют из себя одну из разновидностей датчиков.
В этой статье я расскажу про основные архитектуры генеративных сетей для задачи перевода изображения из одного домена в другой (image-to-image translation). В конце расскажу, для чего именно мы применяем синтетические данные и приведу примеры изображений, которых нам удалось достичь. Но перед погружением в данную тему рекомендую ознакомиться с тем, что такое свёрточная сеть, U-Net и генеративная сеть. Если же Вы готовы, поехали.
Каждое производство в той или иной степени индивидуально. Картинки на разных площадках могут сильно отличаться. Поэтому хочется сократить время, которое уходит на разметку данных. Например, при помощи генерации изображений по бинарной маске.

Существующие архитектуры можно разделить на 2 типа: supervised и unsupervised. Для supervised подхода входная маска и целевое изображение должны соответствовать друг другу, как на картинке выше. Для unsupervised такого условия не требуется. В обоих случаях мы хотим сгенерировать изображение таким образом, чтобы сохранилось содержимое маски (расположение объектов), при этом стиль сгенерированного изображения совпадал с целевым.
Supervised image-to-image translation
pix2pix
[Статья, реализация]

Про архитектуру
Генератор представляет собой U-Net подобную архитектуру, на вход которой подаётся бинарная маска. Дискриминатор - это классификатор типа PatchGAN, на вход которому подаются бинарная маска и целевое изображение.
Как и в задаче сегментации, в архитектуре генератора нужны skip connections из энкодер блоков в декодер блоки. Но есть и некоторые отличия от архитектур сегментации.
Например, при обучении ГАНов для уменьшения размерности рекомендуется заменить операции max pooling на свёртки со страйдом. А в качестве финальной активации используется гиперболический тангенс, т.к. сгенерированные изображение мы затем подаём на вход дискриминатору, т.е. мат. ожидание выходного изображения должно быть нулевым, а дисперсия единичной.
PatchGAN - это свёрточный классификатор, который классифицирует каждый патч (реальный или фейковый). Реализовано это следующим образом.
NLayerDiscriminator
import functools
import torch.nn as nn
class NLayerDiscriminator(nn.Module):
"""Defines a PatchGAN discriminator"""
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
"""Construct a PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the last conv layer
n_layers (int) -- the number of conv layers in the discriminator
norm_layer -- normalization layer
"""
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4
padw = 1
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
self.model = nn.Sequential(*sequence)
def forward(self, input):
"""Standard forward."""
return self.model(input)
В дискриминаторе ReLU активации заменены на LeakyRELU, удалены все fully connected слои, а на выходе нет никакой активации, т.е. выходные значения ничем не ограничены. Теоретически это может привести к gradient explosion, однако в данной конфигурации это работает стабильно.
Про обучение и борьбу с затуханием градиентов
Модели обучаются в генеративно-состязательном режиме. Т.е. цель дискриминатора - научиться отличать оригинальные изображения от сгенерированных, цель генератора - научиться генерировать такие изображения, что дискриминатор не сможет их отличить от реальных.
Такой способ обучения называется minimax game. В этой игре дискриминатор минимизирует кросс-энтропию между целевым классом и предсказанным распределением а генератор наоборот максимизирует кросс-энтропию. Это приводит к тому, что, когда дискриминатор слишком уверенно отклоняет сгенерированные изображения, градиенты генератора затухают.
Один из способов для борьбы с затуханием градиентов генератора - non-saturating game, который был найден эвристическим путём:
Вместо минимизации
для генератора максимизируем
Авторы pix2pix и используют non-saturating game.
Также они добавляют к лосс-функции (L2 loss даёт более размытые результаты):
И L1 и L2 loss между реальным и сгенерированным изображения хорошо улавливают низкочастотные детали, но не высокочастотные детали.

Для увеличения фокуса на высокочастотных деталях, картинку делят на патчи, как это и сделано в PatchGAN.
Архитектура pix2pix является базовой для supervised image-to-image translation. Pix2pixHD и SPADE, которые мы рассмотрим дальше, улучшают её идеи.
pix2pixHD
[Статья, реализация]
Данная архитектура, как следует из названия, предназначена для генерации изображений более высокого разрешения, чем её предшественница.
Про архитектуру
Можно выделить следующие модификации:
Multi-scale discriminators
Исходная картинка уменьшается в 2 и 4 раза - получаем 3 изображения разного масштаба. На каждый масштаб создаётся свой дискриминатор PatchGAN, которые имеют одинаковую структуру. Реализация.
MultiscaleDiscriminator
class MultiscaleDiscriminator(nn.Module):
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d,
use_sigmoid=False, num_D=3, getIntermFeat=False):
super(MultiscaleDiscriminator, self).__init__()
self.num_D = num_D
self.n_layers = n_layers
self.getIntermFeat = getIntermFeat
for i in range(num_D):
netD = NLayerDiscriminator(input_nc, ndf, n_layers, norm_layer, use_sigmoid, getIntermFeat)
if getIntermFeat:
for j in range(n_layers+2):
setattr(self, 'scale'+str(i)+'_layer'+str(j), getattr(netD, 'model'+str(j)))
else:
setattr(self, 'layer'+str(i), netD.model)
self.downsample = nn.AvgPool2d(3, stride=2, padding=[1, 1], count_include_pad=False)
def singleD_forward(self, model, input):
if self.getIntermFeat:
result = [input]
for i in range(len(model)):
result.append(model[i](result[-1]))
return result[1:]
else:
return [model(input)]
def forward(self, input):
num_D = self.num_D
result = []
input_downsampled = input
for i in range(num_D):
if self.getIntermFeat:
model = [getattr(self, 'scale'+str(num_D-1-i)+'_layer'+str(j)) for j in range(self.n_layers+2)]
else:
model = getattr(self, 'layer'+str(num_D-1-i))
result.append(self.singleD_forward(model, input_downsampled))
if i != (num_D-1):
input_downsampled = self.downsample(input_downsampled)
return resultProgressive generator

Сперва сеть G1 обучается на низком разрешении, потом добавляются слои G2 и модель дообучается на высоком разрешении.
Про обучение
Feature matching + perceptual loss
Во время обучения из дискриминатора извлекаются промежуточные признаки с разных слоёв и считается L1 loss между признаками реального изображения и сгенерированного. Реализация.
Perceptual loss похож на Feature matching, но вместо дискриминатора используется предобученная на Imagenet модель, например, VGG16 (во время обучения GANов она не обучается). Реализация.
Обе лосс-функции стабилизируют обучение, т.к. генератор должен производить правдоподобные статистики на разных масштабах изображения.
Lsgan
Вместо cross-entropy в minimax game считаем L2 loss [lsgan].
Про instance-wise генерацию. Boundary map
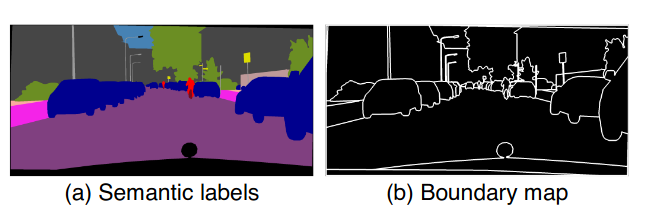
 внизу) сгенерированного изображения по семантической маске и пример (рис. (b) внизу) сгенерированного изображения по семантической маске и boundary map")
Ко входной семантической маски добавляется boundary map, которая содержит instance-wise информацию. Это делается для того, чтобы разные объекты одного класса не сливались в один объект, как на рисунке выше.
Про instance-wise генерацию. Feature encoder network

Feature Encoder Network представляет собой encoder-decoder архитектуру (без skip-connections), выход которой подаётся на слой instance-wise average pooling. Новый слой усредняет признаки для каждого инстанса по boundary map, полученная маска добавляется к семантической маске.
Таким образом, во время инференса для одной и той же семантической маски мы можем сгенерировать разные изображения, подавая на вход сети E, случайные изображения из нашего набора (instance-wise average pooling усредняет признаки, в соответствии с семантической маской).
Энкодер E обучается совместно с генератором и дискриминатором.
SPADE
[Статья, реализация]
Про архитектуру
Multi-sclae discriminators
Как и в pix2pixHD используются Multi-scale discriminators.
Feature matching + perceptual loss
Также как и в pix2pixHD.
SPADE generator
Генератор сильно отличается от двух предыдущих архитектур. На вход генератору подаётся либо случайный вектор (если используем конфигурацию с VAE) либо маска уменьшенной размерности.
В конфигурации с автоэнкодером вводится дополнительная сеть - вариационный энкодер, на выходе которого и получаем случайный вектор (входной вектор для генератора). Энкодер и генератор, таким образом, формируют VAE.

Архитектура состоит из несколько SPADE Res блоков, внутри которых применяется новый слой нормализации - SPADE.
")
Как видно на рисунке маска прогоняется через свёртки для получения параметров гамма и бетта (В BatchNorm2d либо InstanceNorm2d параметр affine=False) [реализация].
Когда мы применяем InstanceNorm2d на однотонную маску, практически вся информация теряется (см. рисунок ниже). Блок SPADE это исключает.

Spectral Norm
Авторы также добавляют спектральную нормализацию во все архитектуры - генератор, дискриминатор и энкодер. Например, для свёрток в SPADEResnetBlock и слоёв нормализации Batch/InstanceNorm.
Спектральная норма (сигма) по сути измеряет, как сильно матрица W может растянуть любой ненулевой вектор h, и равна максимальному сингулярному значению матрицы W [proof].
Спектральная нормализация стабилизирует процесс обучения ГАНов за счёт того, что делает константу Липшица L = 1 для всех слоев.
Про обучение
Обучается SPADE таким же образом, как и pix2pixHD, только вместо LSGAN используется Hinge loss.
Unsupervised image-to-image translation
Cycle-GAN
[Cтатья, реализация]
 Перевод изображения из домена X в Y и наоборот, (b) cycle-consistency loss для домена X, (c) cycle-consistency loss для домена Y")
Про архитектуру
Архитектуры генератора и дискриминатора в Cycle-GAN такие же, как и в pix2pix. Меняется только постановка задачи и процедура обучения.
Про обучение
Мы хотим перевести изображения из домена X в домен Y, сохранив при этом содержимое изображения. И наоборот, из домена Y в X. Т.е. решаем задачу style transfer.
Создаём два генератора G : X -> Y, F: Y -> X и два дискриминатора Dx, Dy. Каждую пару генератора и дискриминатора обучаем, например, через minimax game. И добавляем ещё две лосс-функции cycle consistency losses, необходимые для сохранения содержимого изображения.

UGATIT
[Статья, реализация]

Про архитектуру
UGATIT архитектура похожа на Cycle GAN. Она состоит из двух генераторов (по одному на каждый домен) и 4 дискриминаторов (по 2 на каждый домен).
Дискриминаторы одного домена - это два PatchGAN разной глубины (таким образом, реализуется multi-scale дискриминатор).
Генератор представляет собой Resnet-based архитектуру (без skip connections).
Внутри Resnet блоки с AdaLIN (adaptive layer instance normalization)
где μI , μL and σI , σL - это channel-wise и layer-wise мат. ожидание и стандартное отклонений активаций соответственно, γ и β - параметры, генерируемые fully connected слоем, τ - это learning rate и ∆ρ - градиент, определённый оптимайзером. Значения ρ ограничены отрезком [0, 1].
Про обучение
Внутри дискриминатора есть дополнительная классификационная голова. Ей на вход подаются 2D карты признаков, по ним с помощью avg_pooling и fully connected слоёв считаются веса и умножаются на соответствующие карты признаков.
Во время инференса по этим картам строятся class activation map (CAM; attention feature map; heatmap)
Полученный 2d тензор и есть выход дополнительной классификационной головы. Получаем + 4 дополнительных лосса для обучения генератора:
G_ad_cam_loss_GA = self.MSE_loss(fake_GA_cam_logit, torch.ones_like(fake_GA_cam_logit).to(self.device))
G_ad_cam_loss_LA = self.MSE_loss(fake_LA_cam_logit, torch.ones_like(fake_LA_cam_logit).to(self.device))
G_ad_cam_loss_GB = self.MSE_loss(fake_GB_cam_logit, torch.ones_like(fake_GB_cam_logit).to(self.device))
G_ad_cam_loss_LB = self.MSE_loss(fake_LB_cam_logit, torch.ones_like(fake_LB_cam_logit).to(self.device))D_ad_cam_loss_GA = self.MSE_loss(real_GA_cam_logit, torch.ones_like(real_GA_cam_logit).to(self.device)) + self.MSE_loss(fake_GA_cam_logit, torch.zeros_like(fake_GA_cam_logit).to(self.device))
D_ad_cam_loss_LA = self.MSE_loss(real_LA_cam_logit, torch.ones_like(real_LA_cam_logit).to(self.device)) + self.MSE_loss(fake_LA_cam_logit, torch.zeros_like(fake_LA_cam_logit).to(self.device))
D_ad_cam_loss_GB = self.MSE_loss(real_GB_cam_logit, torch.ones_like(real_GB_cam_logit).to(self.device)) + self.MSE_loss(fake_GB_cam_logit, torch.zeros_like(fake_GB_cam_logit).to(self.device))
D_ad_cam_loss_LB = self.MSE_loss(real_LB_cam_logit, torch.ones_like(real_LB_cam_logit).to(self.device)) + self.MSE_loss(fake_LB_cam_logit, torch.zeros_like(fake_LB_cam_logit).to(self.device))Основные лоссы (minimax game):
G_ad_loss_GA = self.MSE_loss(fake_GA_logit, torch.ones_like(fake_GA_logit).to(self.device))
G_ad_loss_LA = self.MSE_loss(fake_LA_logit, torch.ones_like(fake_LA_logit).to(self.device))
G_ad_loss_GB = self.MSE_loss(fake_GB_logit, torch.ones_like(fake_GB_logit).to(self.device))
G_ad_loss_LB = self.MSE_loss(fake_LB_logit, torch.ones_like(fake_LB_logit).to(self.device))
D_ad_loss_GA = self.MSE_loss(real_GA_logit, torch.ones_like(real_GA_logit).to(self.device)) + self.MSE_loss(fake_GA_logit, torch.zeros_like(fake_GA_logit).to(self.device))
D_ad_loss_LA = self.MSE_loss(real_LA_logit, torch.ones_like(real_LA_logit).to(self.device)) + self.MSE_loss(fake_LA_logit, torch.zeros_like(fake_LA_logit).to(self.device))
D_ad_loss_GB = self.MSE_loss(real_GB_logit, torch.ones_like(real_GB_logit).to(self.device)) + self.MSE_loss(fake_GB_logit, torch.zeros_like(fake_GB_logit).to(self.device))
D_ad_loss_LB = self.MSE_loss(real_LB_logit, torch.ones_like(real_LB_logit).to(self.device)) + self.MSE_loss(fake_LB_logit, torch.zeros_like(fake_LB_logit).to(self.device))Также как и в cycle gan добавляются cycle consistency losses
И identity loss (для сохранения содержимого):
fake_A2A, fake_A2A_cam_logit, _ = self.genB2A(real_A)
fake_B2B, fake_B2B_cam_logit, _ = self.genA2B(real_B)
G_identity_loss_A = self.L1_loss(fake_A2A, real_A)
G_identity_loss_B = self.L1_loss(fake_B2B, real_B)В генераторы, как и в дискриминаторы, добавляются дополнительные классификационные головы, которая предсказывают принадлежит ли изображение домену А или домену B, в зависимости от генератора.
G_cam_loss_A = self.BCE_loss(fake_B2A_cam_logit, torch.ones_like(fake_B2A_cam_logit).to(self.device)) + self.BCE_loss(fake_A2A_cam_logit, torch.zeros_like(fake_A2A_cam_logit).to(self.device))
G_cam_loss_B = self.BCE_loss(fake_A2B_cam_logit, torch.ones_like(fake_A2B_cam_logit).to(self.device)) + self.BCE_loss(fake_B2B_cam_logit, torch.zeros_like(fake_B2B_cam_logit).to(self.device)) - исходное изображение; (b) - CAM генератора (c-d) - CAM локального и глобального дискриминатора (e) - сгенерированное изображение с CAM головой; (f) - сгенерированное изображение без CAM головы")
Финальный лосс:
MUNIT
[Статья, реализация]

Про архитектуру
Данная архитектура значительно отличается от двух предыдущих. В отличие от них, MUNIT кодирует исходное изображение на содержимое и стиль при помощи Content and Style Encoder.
Style Encoder состоит из strided свёрток, global average pooling и fully connected слоя. Instance Normalization в Style Encoder не используется, т.к. он удаляет оригинальное мат. ожидание и дисперсию признаков, которые содержат информацию о стиле.
Content encoder состоит из тех же свёрток и residual blocks.
Декодер по содержимому и стилю восстанавливает исходное изображение. Он состоит из свёрток и интерполяции (nearest-neighbor interpolation) для повышения размерности. Внутри residual blocks используется Adaptive Instance Normalization.
где z - это активация предыдущего свёрточного слоя, μ и σ - это channel-wise мат. ожидание и стандартное отклонение активаций, γ и β - это параметры, генерируемые fully connected слоем.
Дискриминатор - multi-scale дискриминатор с LSGAN лоссом (в minimax game)
Про обучение
Также как и в pix2pixHD используется perceptual loss. Перед вычислением дистанции к эмбэддингам применяется Instance Normalization, чтобы удалить информацию о стиле.
")
MUNIT обучается одновременно и как автоэнкодер и как GAN. Для преобразования изображения из домена А в B и наоборот они пропускаются через style и content энкодер. У каждого домена свои энкодеры. Затем, чтобы получить изображение из домена B(с2 - содержимое; s2 - стиль), но с содержимым изображения из домена А (с1 - содержимое; s1 - стиль), мы заменяем s1 на s2 и пару (с1, s2) пропускаем через декодер для домена B. Аналогично для преобразования из B в А.
Для обучения как обычно используется adversarial loss (minimax game), reconstruction loss (cycle consistency losses) для изображений, как и в двух предыдущих моделях, и reconstruction loss для содержимого и стиля.
Что получилось у нас
И так мы разобрали основные, на мой взгляд, архитектуры в image-to-image translation, а теперь мне бы хотелось рассказать, зачем мы это применяли у себя и как это нам помогло.
Для чего применяем
Нередко у нас появляется задача - обучить Unet/LinkNet модель, чтобы точно находить объекты и определять их размеры. Разметка таких объектов крайне кропотливое занятие, а новые домены могут сильно отличаться от тех, с которыми мы уже умеем работать.


Как вариант, можно применять Domain Adaptation методы (DA), но иногда домены отличаются довольно сильно, например, руда и пузыри. В таком случае DA не поможет. Поэтому мы захотели научиться генерировать синтетические изображения по бинарной маске, имея всего лишь небольшое количество размеченных изображений (~ 100).
Генерация масок
До сих пор мы ничего не говорили про генерацию самих масок, хотя это тоже довольно важный этап для получения разнообразных и качественных изображений.
Мы попробовали обучить ProgressiveGAN, но получилось плохо. В масках было мало разнообразия.

Наилучшие результаты получились с масками, которые генерировали сегментационные модели, и с рандомно расставленными по пустому изображению масками объектов (из небольшого набора).
Генерация изображений по маскам
Мы попробовали все приведённые в статье архитектуры и наилучшие результаты показали SPADE (среди supervised архитектур) и UGATIT (среди unsupervised).

")



Таким образом, мы сгенерировали набор синтетических данных (порядка 10 000 изображений), преодобучили UNet модель на них, а затем дообучили на реальных данных. Это дало ~1-2% прироста в точности по метрикам precision, recall (для объектов, не для пикселей) по сравнению с моделью, обученной только на реальных данных.
Заключение
Генеративные сети можно применять для предобучения моделей либо в качестве аугментации. Сгенерированные, таким образом, пары - маска и картинка - лучше соответствуют друг другу, чем пара - реальное изображения и маска, сгенерированная сегментационной моделью. Но совсем без разметки не обойтись.
Качество unsupervised методов сильно ниже supervised. Последние же хоть и генерируют реалистичные изображения, но недостаточно разнообразные.
Также стоит отметить, что и у supervised и у unsupervised архитектур появляются артефакты на разряжённых масках.
To be discussed
А используете ли Вы генеративные сети у себя на работе? И если да, то какие архитектуры?
Azraeldk
Зачем так сложно, если есть спектроскопия, ультразвуковое сканирование, OpenCV для анализа геометрических аномалий и т.д.
mana_aka_forcesh Автор
Под сложностью вы имеете ввиду нейронные сети? Классическим компьютерным зрением можно было бы сегментировать объекты, но точность будет гораздо ниже. + На конвейере, например, высокая скорость, поэтому нужен высокий fps