
Недавно мы проводили вебинар «Обзор паттернов интеграции микросервисов». На нём энтерпрайз архитектор Пётр Щербаков рассказал, зачем IT-специалистам нужны шаблоны интеграции, и разобрал, для каких задач они подходят, а для каких нет. Для тех, кто пропустил или предпочитает читать, а не смотреть подготовили текстовый обзор интеграционных паттернов: Circuit Breaker, Sidecar, Ambassador, Anti-Corruption Layer и Async Request-Reply.

Пару слов про анализ паттернов
Мы выделили три пункта, по которым анализировали каждый паттерн. Это SOLID, DbC и LC/HC.
SOLID
SOLID — пять основных принципов объектно-ориентированного программирования, которые помогают разобраться в шаблонах проектирования и архитектуре ПО в целом.
S — Single Responsibility — принцип единой ответственности.
O — Open-Closed — принцип открытости/закрытости.
L — Liskov Substitution — принцип подстановки Барбары Лисков.
I — Interface Segregation — принцип разделения интерфейса.
D — Dependency Inversion — принцип инверсии зависимостей.
При анализе интеграционных паттернов нас интересовали три принципа:
Single Responsibility говорит о том, что каждый микросервис должен нести единую ответственность с точки зрения функции, контекста и работы. Это значит, что не нужно намешивать много всего, иначе получится антипаттерн.
Open-Closed можно наблюдать, когда у нас есть версии контракта. Скажем, в первой и второй версии контракта метод одинаковый, но данные по нему приходят разные.
Interface Segregation — в системах можно делать разные интерфейс-взаимодействия: одни методы для одной системы и другие методы для второй.
DbC
Design by contract — контрактное программирование. Прежде чем пилить сервис или какую-то функцию, мы понимаем, какие входные/выходные данные у нас будут и какие условия возникновения исключений.
Предусловия — то, что должно выполниться «до», чтобы выполнилась функция.
Инварианты — то, что функция должна обеспечивать: её основной посыл.
Постусловия — то, что придёт, и как это затем можно обработать или запросить что-то ещё дополнительно.
Гарантии — время, объём данных, ответ. Например, мы гарантируем, что объём данных будет не больше 10 МБ, время не больше 500 миллисекунд, а ответ придёт в конкретном формате.
LC/HC
LC/HC — паттерны GRASP.
Low coupling — система не должна зависеть от большого количества сервисов. Если ваш код или функция зависят от 10 и более систем, это не очень хорошая история, так как модернизация каждого влечет за собой изменение последующих.
High cohesion — ясна фокусировка системы, функции определены, управляемы и понятны.
В рамках этих терминов и в этом контексте мы разбирали интеграционные паттерны: Circuit Breaker, Sidecar, Ambassador, Anti-Corruption Layer и Async Request-Reply. Перейдем непосредственно к обзору.
Circuit Breaker
Circuit Breaker — паттерн интеграции между сервисами с гарантией ответа на запрос. Предназначен для интеграции с внешними системами, ответ от которых может завершиться ошибкой и не является критичным для приложения.
Основные характеристики:
конечный автомат;
имеет три состояния;
работает в режиме прокси;
гарантирует ответ на запрос;
для каждого состояния своя метрика перехода в другое состояние;
может кэшировать запросы.

Как работает: между Application и удаленным сервисом мы ставим Circuit Breaker. У Circuit Breaker есть три состояния: открытое, закрытое и полуоткрытое. Он всегда инициализируется в закрытом состоянии — первый запуск закрытый. Мы делаем вызов через Circuit Breaker. Circuit Breaker отправляет запрос в удаленный сервис, но перед этим сбрасывает счетчик — значок «умножить на ноль». Мы делаем вызов удаленного сервиса, получаем от него ответ и передаём ответ Application. При необходимости в промежутке кэшируем.
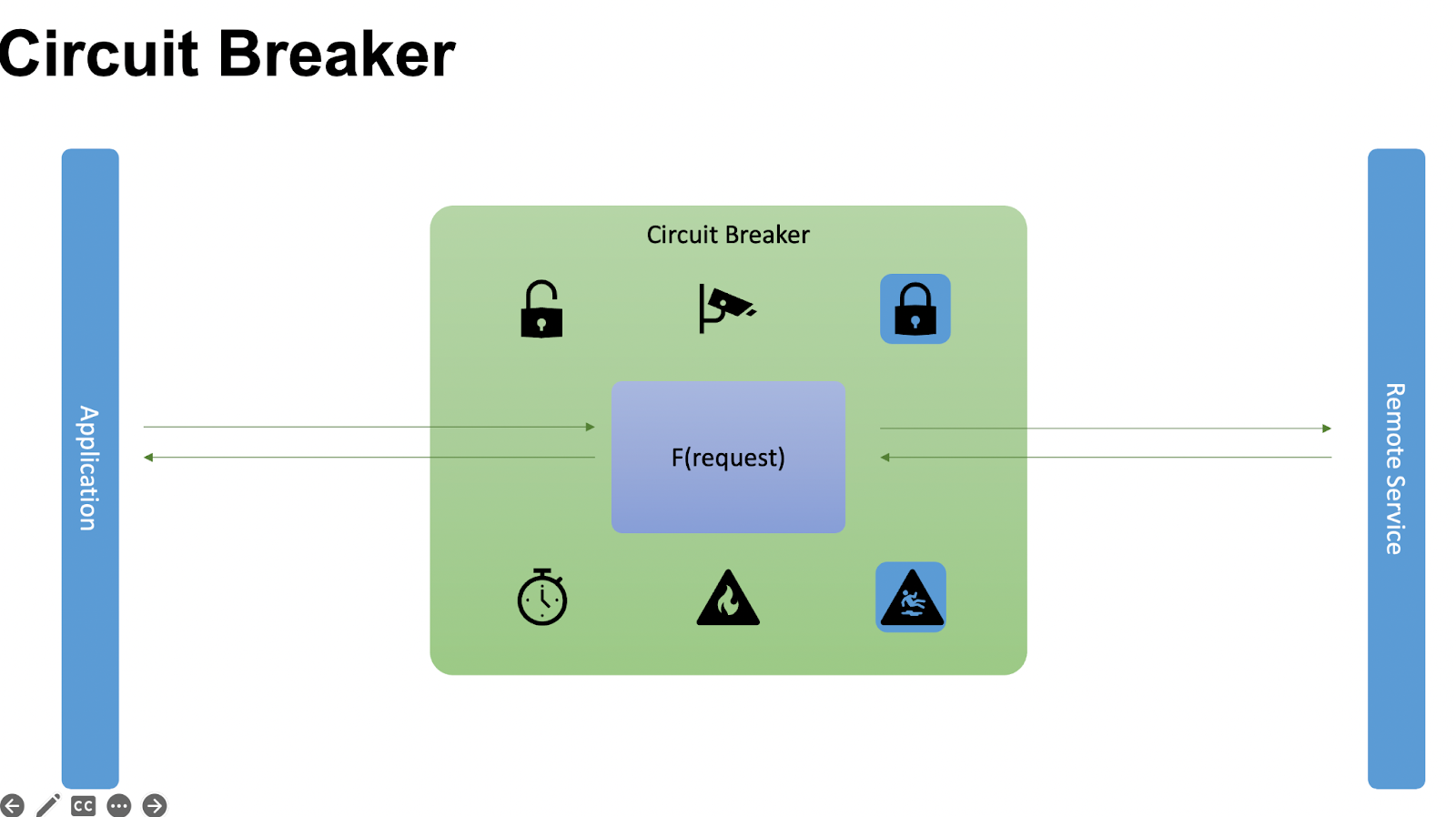
Это сценарий, когда всё успешно, и Circuit Breaker долго находится в закрытом состоянии. Но что делать, когда происходят падения? Мы идём к нашему приложению и говорим: «Всё упало, делаем счетчик падений «+1». Повторяем итерацию «+1», пока всё продолжает падать, и в какой-то момент достигаем MAX_ERR_COUNT.
Превышаем MAX_ERR_COUNT — максимально доступное количество ответов, которое задали. Далее предполагаем, что сервер уже не в рабочем состоянии. После этого переходим в открытое состояние.
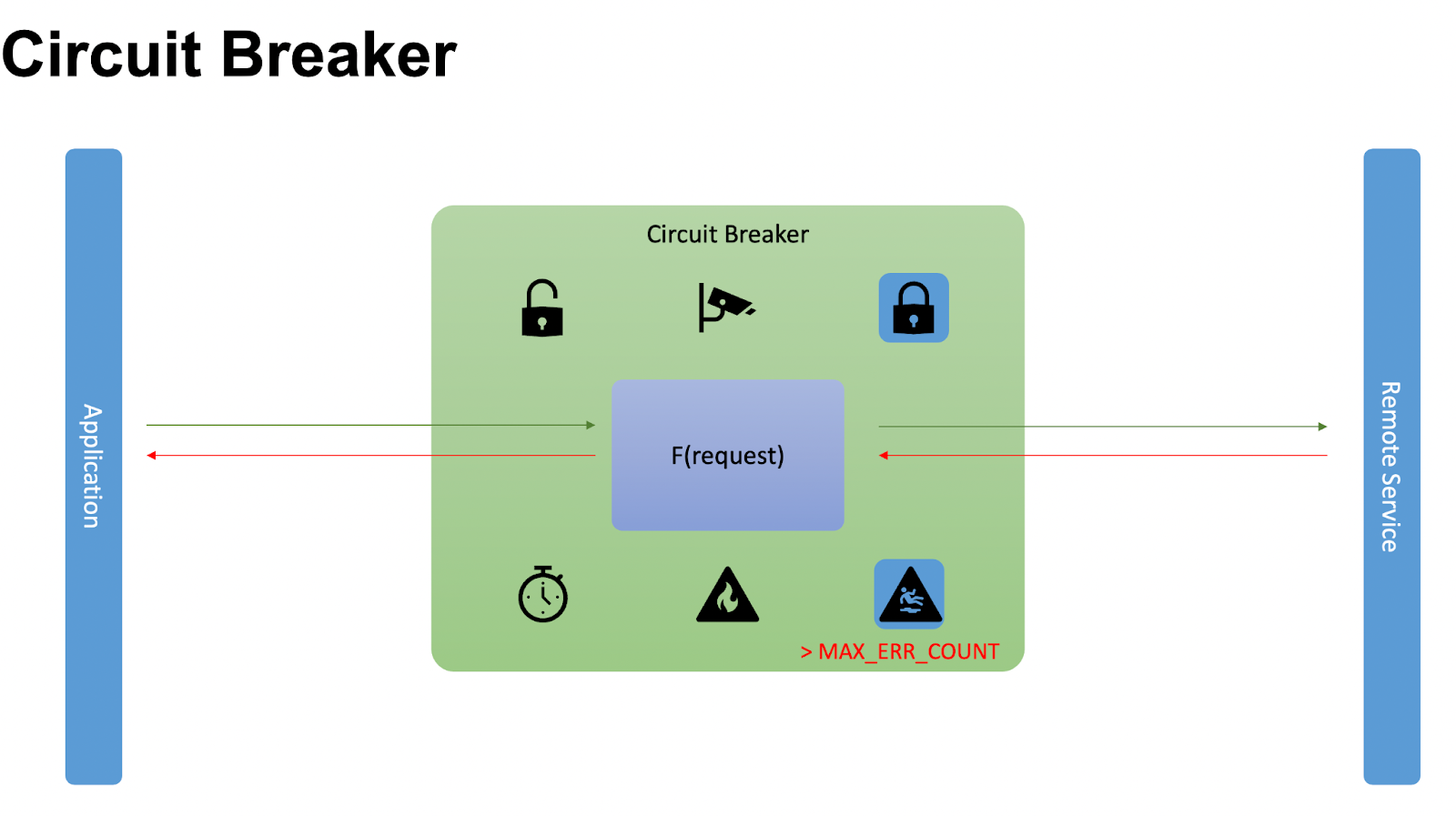
В открытом состоянии мы инициализируем таймер. Пока он работает, все принимаемые запросы отправляем с ошибкой или из кэша.
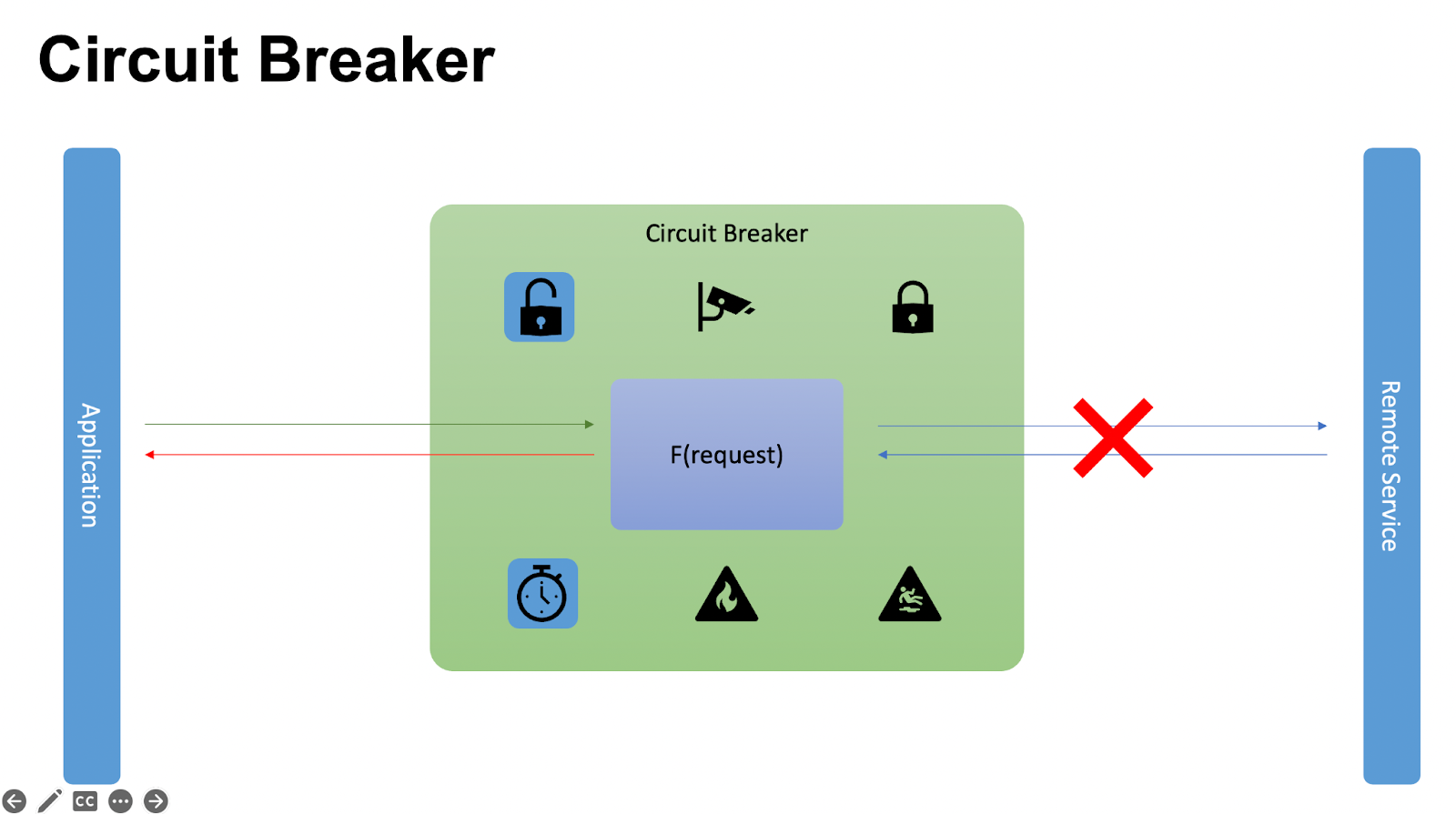
Когда таймер останавливается, переходим в полуоткрытое состояние и считаем только количество успешных запросов. С Application приходит запрос в Circuit Breaker. Мы сбрасываем счетчик успешных запросов, если он не обнулен, делаем запрос к удаленному сервису, получаем успешный ответ и успешно отвечаем.
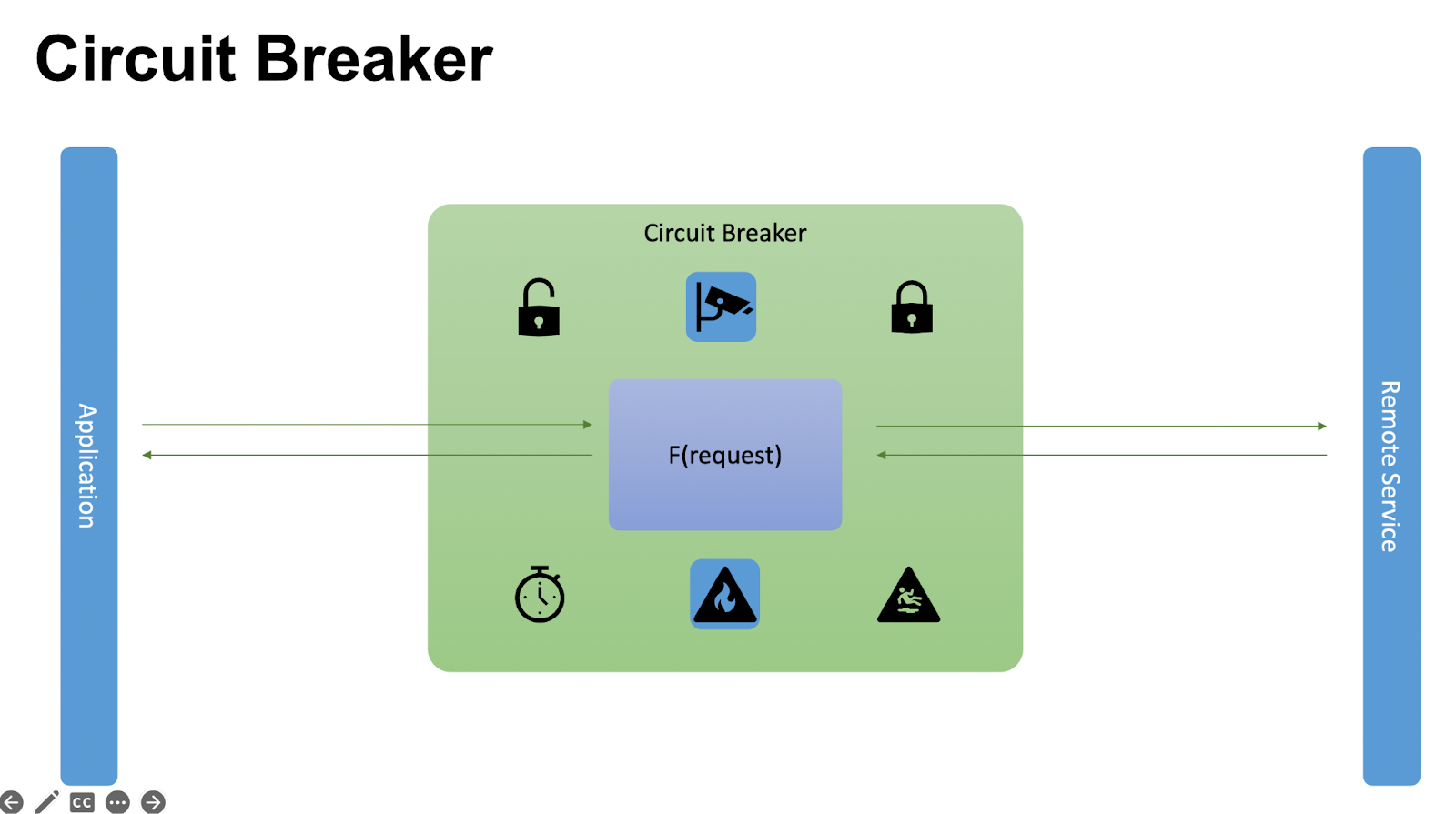
Каждый следующий запрос мы накидываем к счётчику «+1» до тех пор, пока не достигнем MAX_SUCCESS_COUNT. По достижению MAX_SUCCESS_COUNT мы переходим в закрытое состояние и начинаем считать количество падений.
Если в полуоткрытом состоянии падает запрос, то обнаруживается ошибка, и мы перетекаем в открытое состояние.

Sidecar
Sidecar — паттерн интеграции между приложением и сервисом, развернутый на стороне приложения. Отвечает за развертывание компонентов приложения в отдельном процессе или контейнере для обеспечения изоляции и инкапсуляции, а также:
позволяет приложениям состоять из разнородных компонентов и технологий;
берёт на себя сервисные функции интеграции (SRP);
может размещаться на сервере приложения;
может отличаться по технологии разработки;
обеспечивает независимость при обновлении приложения.
Как выглядит Sidecar:
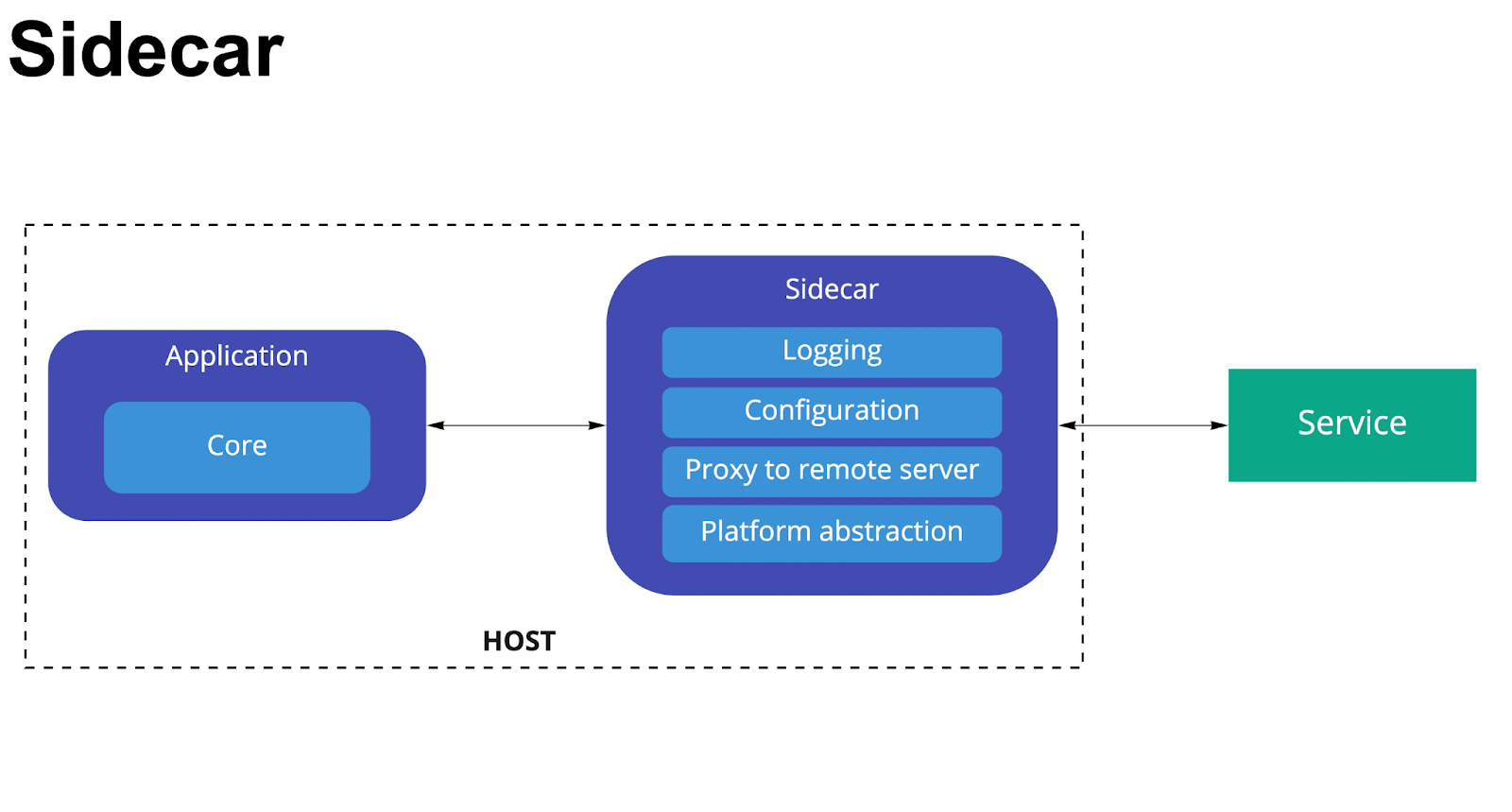
Плюсы: возможность переиспользования и технологическая агностичность.
Минусы: дополнительная точка возможного отказа и повышение нагрузки на сервер приложения.
Варианты использования:
сборщик логов (краулеры, скрапперы, коллекторы);
добавление SSL для легаси приложения;
удаленное управление конфигурацией.
Рассмотрим простейший пример с приложением и Sidecar на Java: мы посылаем запрос на локальный хост, конфигурируем его и настраиваем для подключения к внешнему сервису. При необходимости трансформируем. Далее вызываем внешний сервис, который работает под HTTPS. Происходит обработка ответа, получение ответа, логирование запроса и возврат результата — цикл завершается.

Ambassador
Ambassador — паттерн интеграции между приложением и сервисом, развернутый на стороне приложения. Частный случай Sidecar. Предназначен для работы с внешними сервисами, доступность которых не является стабильной. Позволяет решать задачи подключения к удаленному сервису: мониторинга, маршрутизации, логирования и безопасности. С помощью Ambassador вы можете запустить обработку политик безопасности, добавить сертификат либо проверить токены.
Плюсы:
возможность переиспользования;
возможность внедрять функции безопасности и авторизации без аффекта основной функциональности;
детальная настройка функций подключения;
независимая модернизация;
позволяет создать общий набор функций подключения клиентов для нескольких языков или фреймворков.
На последнем пункте остановимся более подробно. Допустим, вы не хотите писать SDK. У вас есть API для Ambassador. Вы предоставляете его Ambassador, а он уже подключается к облачному сервису.
Минусы:
увеличивает время выполнения запроса;
повышает риск потери фокуса посредника.
Работает Ambassador по принципу Sidecar:

Anti-Corruption Layer
Anti-Corruption Layer — реализует фасад или адаптер между двумя подсистемами. Предполагает устранение зависимости дизайна приложения от внешних подсистем. Первое описание появилось в DDD Эванса. Решает проблемы переписывания системы на новый стек или взаимодействия с внешними легаси системами.
Как работает: есть три микросервиса со своими базами и большая база в системе B, где лежат все данные. Система B — наш монолит, который мы хотим распилить. У нас есть часть интеграции, которая доступна в системе B по каким-то протоколам. В Anti-Corruption Layer мы начинаем прописывать функции работы с базой, подключаться к ней, брать оттуда данные и записывать данные, если это требуется. На внешнем слое Anti-Corruption Layer мы реализуем контракты и протоколы, необходимые микросервису. Фактически антикоррупционный слой трансформирует данные из модели системы A в модель системы B, и берет всю логику преобразования и маршрутизации на себя.
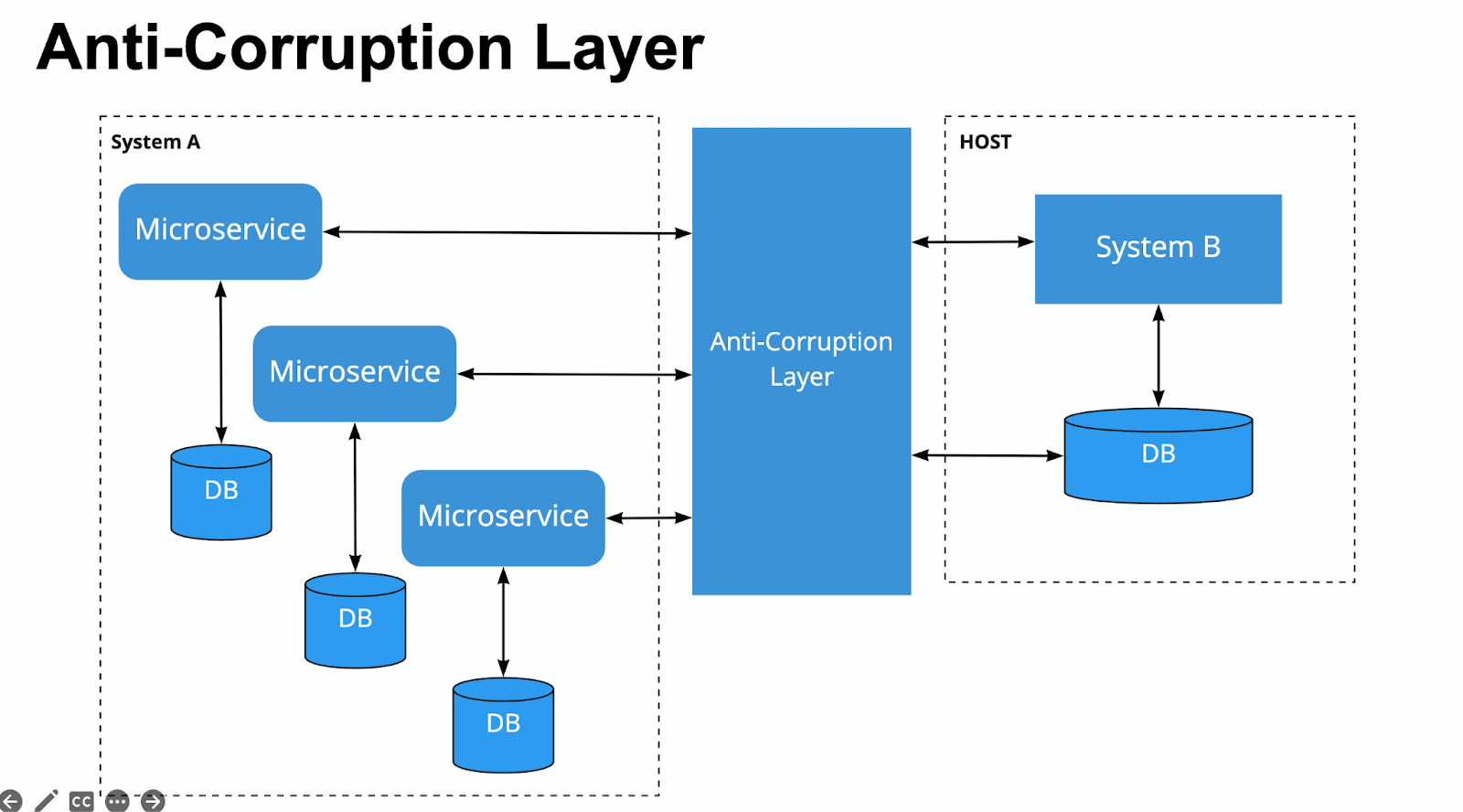
Плюсы:
устойчивость к разделению (можно разбить функции на несколько слоев или для разных языков);
можно реализовать внутри кода основного приложения;
можно удалить после окончания миграции.
Минусы:
повышает время выполнения запроса;
добавляет дополнительную службу, которую нужно поддерживать;
необходима поддержка консистентности данных.
Async Request-Reply
Async Request-Reply — паттерн интеграции для длительной обработки данных и больших объёмов ответа. Отделяет backend от клиента, при условии, что обработка асинхронна, но клиенту нужен чёткий ответ. Чаще всего используется в операциях, возвращающих большой объём информации.

Плюсы:
отложенное получение данных по готовности;
простота реализации;
высвобождение ресурсов для выполнения других операций;
замена долгого соединения и ожидания.
Минусы:
требует периодического опроса ресурса;
не отдаёт данные в реальном времени;
бесполезно реализовывать, если есть возможность использовать WebSocket или Webhook.
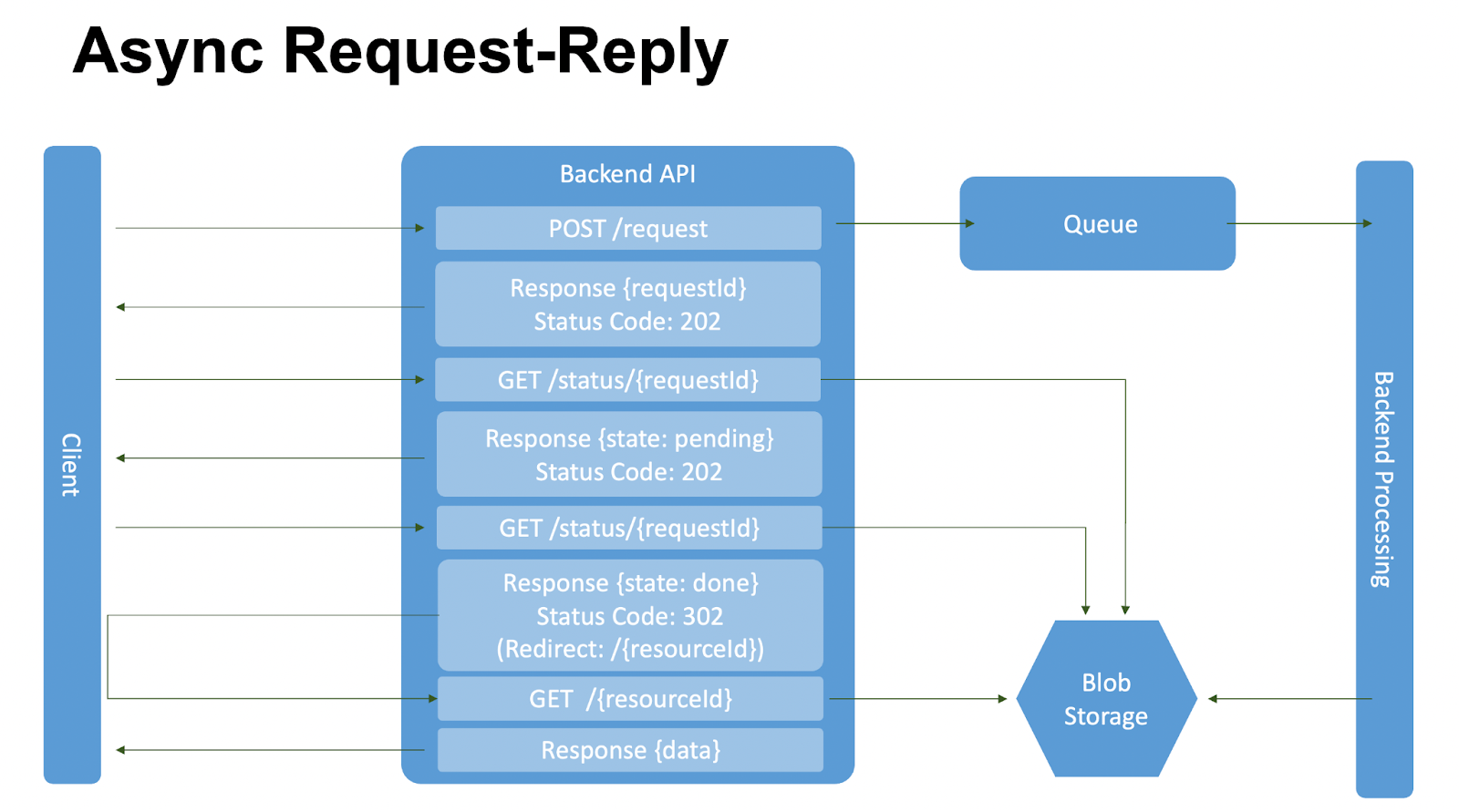
Как работает: Client делает запрос — POST/request. Мы кладём его в очередь, а Backend Processing забирает его из очереди, когда сможет обработать новое сообщение, и начинает его обрабатывать. Мы отвечаем, что запрос принят на обработку, но не выполнен.
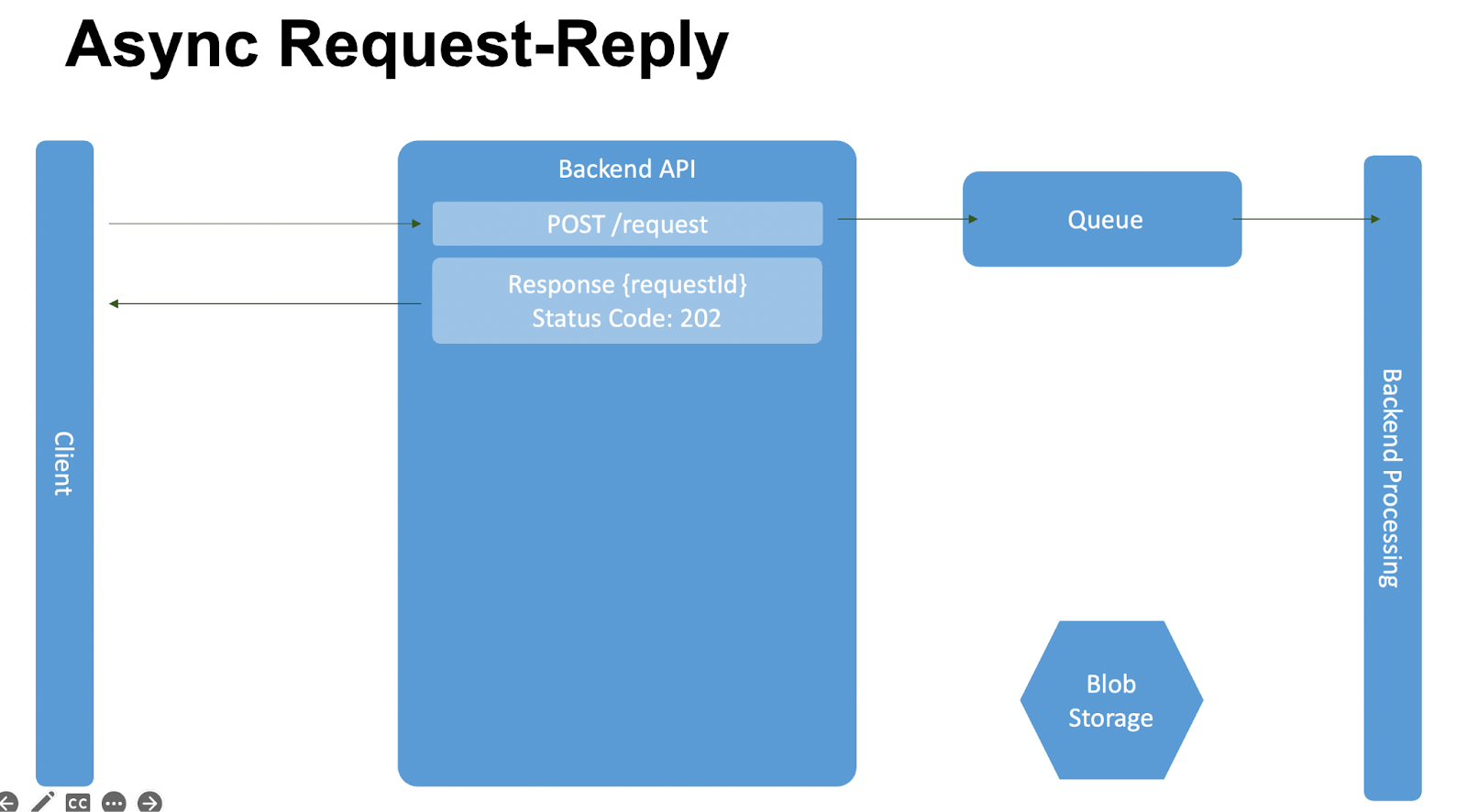
Client понимает, что запрос не обработан и запрашивает по requestId статус по методу GET/status.
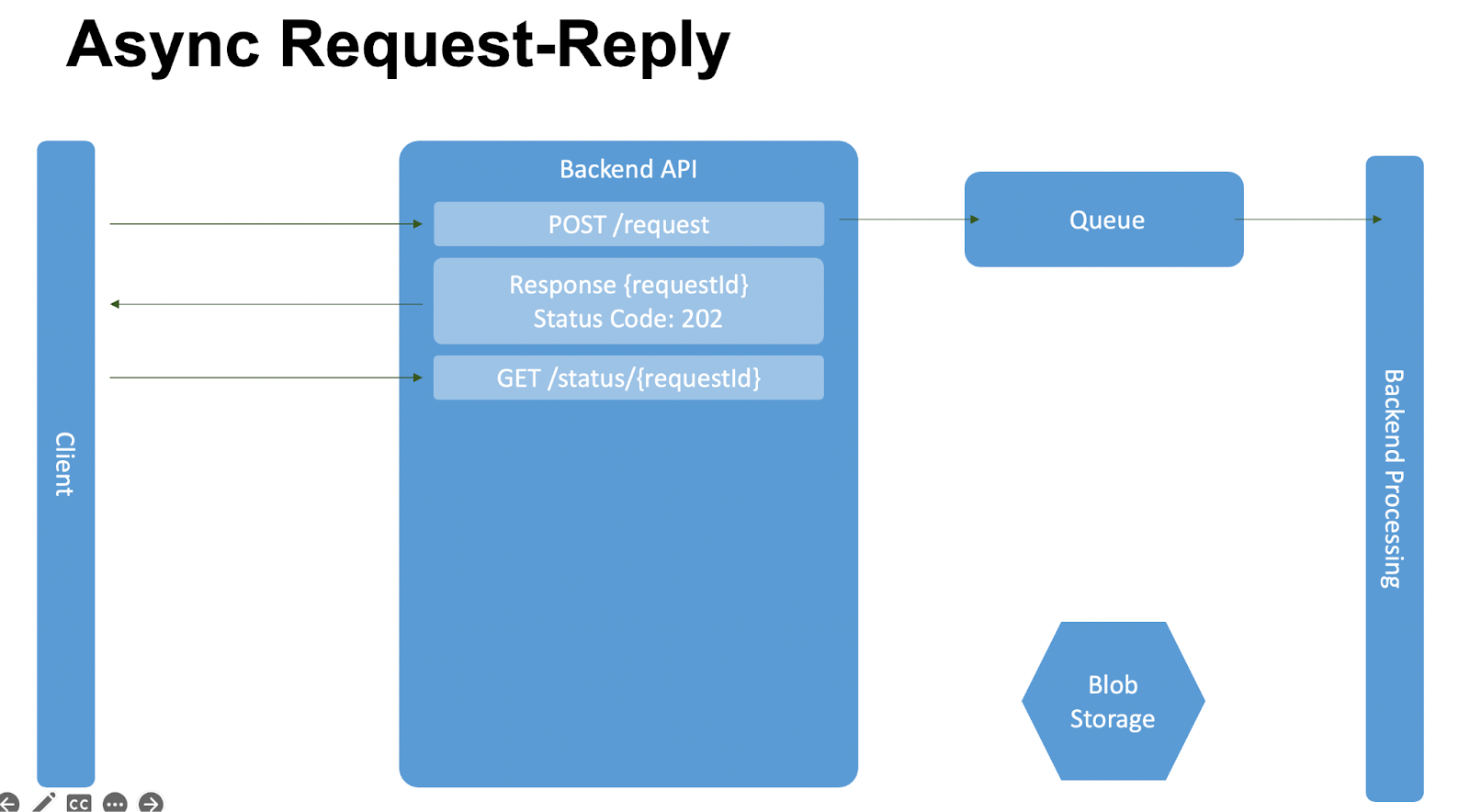
Мы делаем запрос Blob Storage, ничего не находим и отдаем Client state: pending.

Этот запрос requestId мы отправляем до тех пор, пока Backend Processing не запишет данные. Как только Backend Processing запишет данные, следующий запрос статуса вернёт ссылку на получение данных. Получаем, что ответ «готово» и отвечаем с 302-ым кодом с ссылкой на получение результирующих данных.
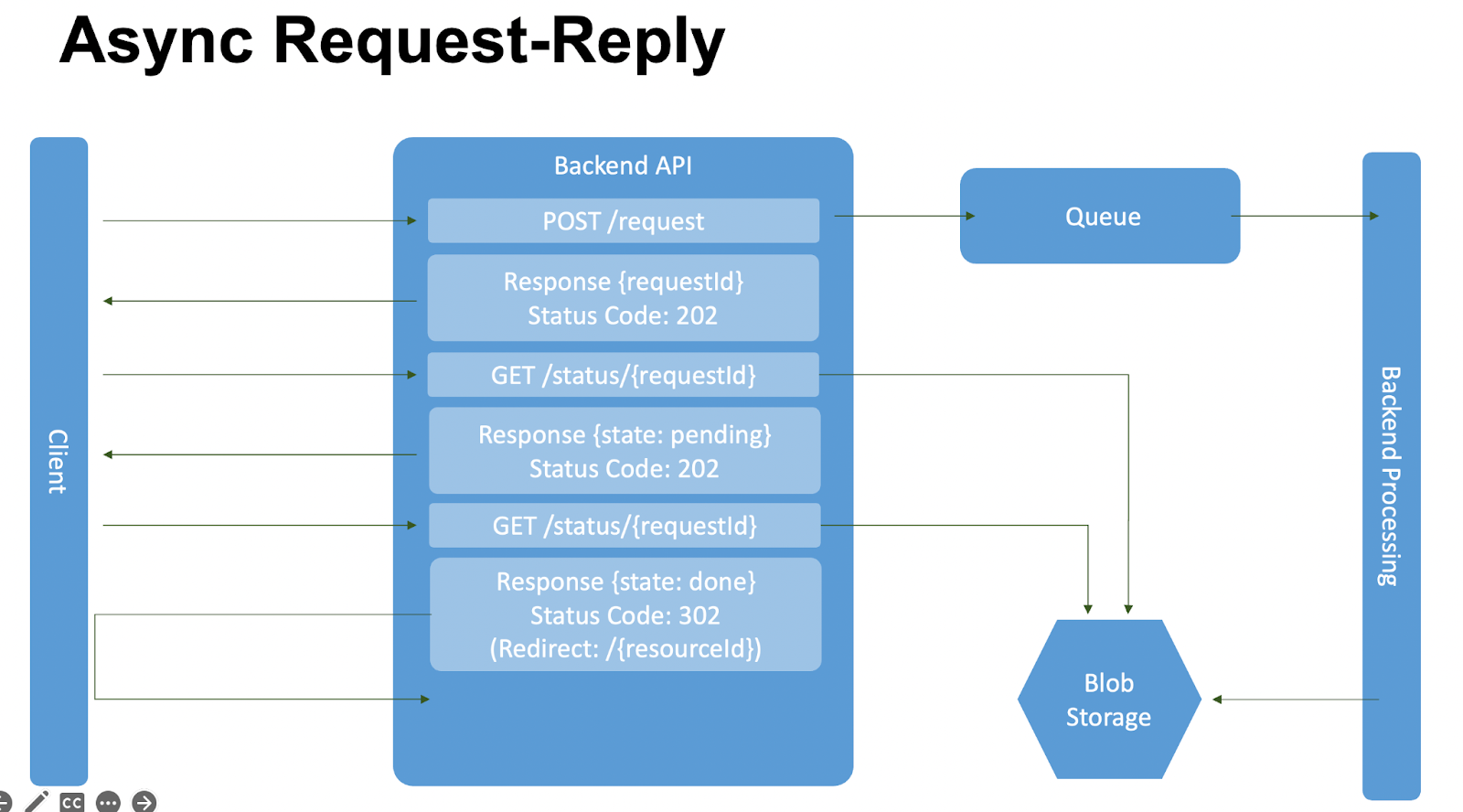
При получении ответа мы автоматически редиректимся на URL, указанный в Redirect, и перейдём на него автоматически для получения результата запроса.
Вместо заключения: что дальше
Вебинар получился объёмным, поэтому рассмотреть все интеграционные паттерны в рамках одной статьи не получилось. Сейчас мы ставим паузу, но уже через неделю вернемся с новой статьёй, в которой проанализируем оставшиеся шаблоны и то, как их правильно использовать. Большинство из паттернов пригодятся, когда вы будете распиливать монолит.
Для тех, кто хочет разобраться в теме разделения монолита
29 сентября у нас стартует курс «Разделение монолита на микросервисы», который будет полезен для middle и senior-разработчикам, системным аналитикам, архитекторам и тимлидам.
Вы узнаете:
какие бывают потребности в разделении и как к нему приступить;
какую стратегию выбрать;
как избежать подводных камней;
как поддерживать получившуюся архитектуру.
Автор курса — Петр Щербаков, Enterprise Architect.
Подробнее ознакомиться с программой: https://slurm.club/3BqoCex