
Всем привет! Меня зовут Елена Боброва, и мы в команде CloudReports работаем над проектом, с помощью которого пользователи облачных систем могут начать легко и просто работать со своими данными.
В последнее время всё большее число компаний внедряют в свою работу различные облачные сервисы, такие как CRM системы, системы управления складом, автоматизация записи клиентов и др. Рано или поздно любой бизнес сталкивается с необходимостью анализировать данные. Облачные системы в большинстве случаев имеют ряд готовых отчетов. Но если требуется более детальный анализ, то данные, как правило, можно забрать с помощью API и поместить во внешнюю базу (хранилище данных), с которым уже удобно работать аналитикам.

Но при получении данных может возникнуть ряд проблем. Вот несколько:
Если данные изменились, например, добавилось какое-то новое поле в API, необходимо перестраивать структуру таблицы в хранилище.
Загруженные ранее данные могут меняться, и их нужно как-то обновлять, это может быть достаточно проблематично.
Большинство существующих коннекторов к облачным системам работают по устоявшейся парадигме ETL (Extract, Transform, Load) - забрать, преобразовать, загрузить. Т.е. подключились к API, получили данные, сформировали таблицы и в этом виде загрузили в место назначения.
Но не так давно эта парадигма начала меняться. Ей на смену приходит другой подход EL(T). Идея в том, чтобы забрать данные, загрузить и при необходимости преобразовать уже в конечном месте. При таком подходе есть четкое разделение между перемещением и обработкой данных.

Почему подход поменялся? Потому что появились такие облачные хранилища, как BigQuery, ClickHouse, и данные стало хранить очень дешево. BigQuery - это облачная БД от компании Google с неограниченным хранилищем и высокой скоростью обработки больших массивов данных. А ClickHouse - это такое же онлайн-хранилище данных от компании Яндекс, можно сказать, что это в какой-то мере российский аналог BigQuery. Основная задача таких сервисов - выполнять аналитические запросы в режиме реального времени на больших данных.
Мы в CloudReports регулярно решаем задачи по загрузке данных из различных облачных систем. Для удобства часть процессов, относящихся непосредственно к загрузке данных в хранилища, мы перенесли в отдельную библиотеку Python и решили открыть к ней публичный доступ.
Библиотека помогает загружать данные из API облачных систем в BigQuery или ClickHouse, используя именно этот новый современный подход - EL(T). Мы сначала загружаем в BigQuery или ClickHouse данные в том виде, в котором их отдает API - JSON, и потом уже работаем с данными, преобразуем и анализируем. В нашем решении мы также решили проблемы, описанные выше. Наш алгоритм забирает json-словари с данными и формирует структуру представлений по сущностям. При этом, если потом появляется новое поле, таблицы перестраиваются автоматически.
Покажу на примере, как можно использовать нашу библиотеку.
Установка:
pip install cloudreportsПодключаем библиотеки.
from cloudreports import database, client
import requests
import json
import datetimeБудем загружать данные в датасет BigQuery.
Что такое BigQuery, можно подробно прочитать в статье.
Заполняем названия проекта и датасета и указываем путь к ключу сервисного аккаунта Google. Где взять ключ.
Инициализируем объекты классов.
project = 'project'
dataset = 'sandbox_ivan'
key_path = 'project.json'
db = database.BigQuery(project, dataset, credentials_file_path=key_path)
client = client.Client(db)Для примера загрузим в BiqQuery данные о космических объектах из API NASA - https://api.nasa.gov/. Будем использовать функцию client.load_json_data. Она принимает json словарь и отправляет данные в хранилище. Мы загружаем два разных типа сущностей: NeoWs и DONKI. Информацию по каждому из них мы в итоге получим в виде таблицы.
# Загрузка данных из https://api.nasa.gov
# NeoWs
r = requests.get('https://api.nasa.gov/neo/rest/v1/feed?start_date=2015-09-08&end_date=2015-09-09&api_key=DEMO_KEY')
r = r.json()
for key, value in r['near_earth_objects'].items():
date = datetime.datetime.strptime(key, '%Y-%m-%d')
for row in value:
# Отправляем данные в BigQuery
# load_json_data method arguments:
# entity_id - уникальный идентификатор сущности
# entity_type - тип сущности
# entity_data - данные из API в формате json
# event_moment - дата когда сущность была создана или изменена
# используется для определения последней версии сущности)
client.load_json_data(entity_id=row['id'], entity_type='NeoWs',
entity_data=row, event_moment=date)
# DONKI
r = requests.get('https://api.nasa.gov/DONKI/CME?startDate=2017-01-01&endDate=2017-01-31&api_key=DEMO_KEY')
r = r.json()
for row in r:
date = datetime.datetime.strptime(row['startTime'], '%Y-%m-%dT%H:%MZ')
# send data to BigQuery
client.load_json_data(row['activityID'], 'DONKI', row, date)
# вызываем метод для завершения загрузки
client.finish_load_json_data()На этом этапе в нашем датасете были созданы таблицы, куда загружаются все данные в исходном виде и на основе которых дальше будут собираться представления по сущностям.


Далее вызываем функцию db.update_tables, чтобы сформировать представления в датасете для новых сущностей.
# добавляем SQL представления для новых типов сущностей
db.update_tables()В датасете BigQuery появилось 2 новых представления, по одному для каждой сущности.

Но в каждом представлении свои поля, в зависимости от того, что было в словаре json.


Точно так же данные можно загрузить в ClickHouse. Для этого нужно поменять этап инициализации объектов классов - вместо класса BigQuery инициализируем класс ClickHouse в модуле database.
host = 'habr.mdb.yandexcloud.net'
db_name = 'db1'
user = 'user1'
password = '**********'
key_path = '.clickhouse-client/usr/local/share/ca-certificates/Yandex/YandexInternalRootCA.crt'
db = database.ClickHouse(host, db_name, user, password, key_path)В остальном коде ничего не меняем, запускаем и смотрим результат в нашей базе данных в ClickHouse.
Как и в прошлом примере, появились 2 таблицы и 2 представления.

И загрузились такие же данные, например, вот представление brv_NeoWs:

Далее можно соединять таблицы, строить отчеты и аналитику, используя SQL, Python и BI Инструменты (Google DataStudio, PowerBI, Tableau, DataLens).
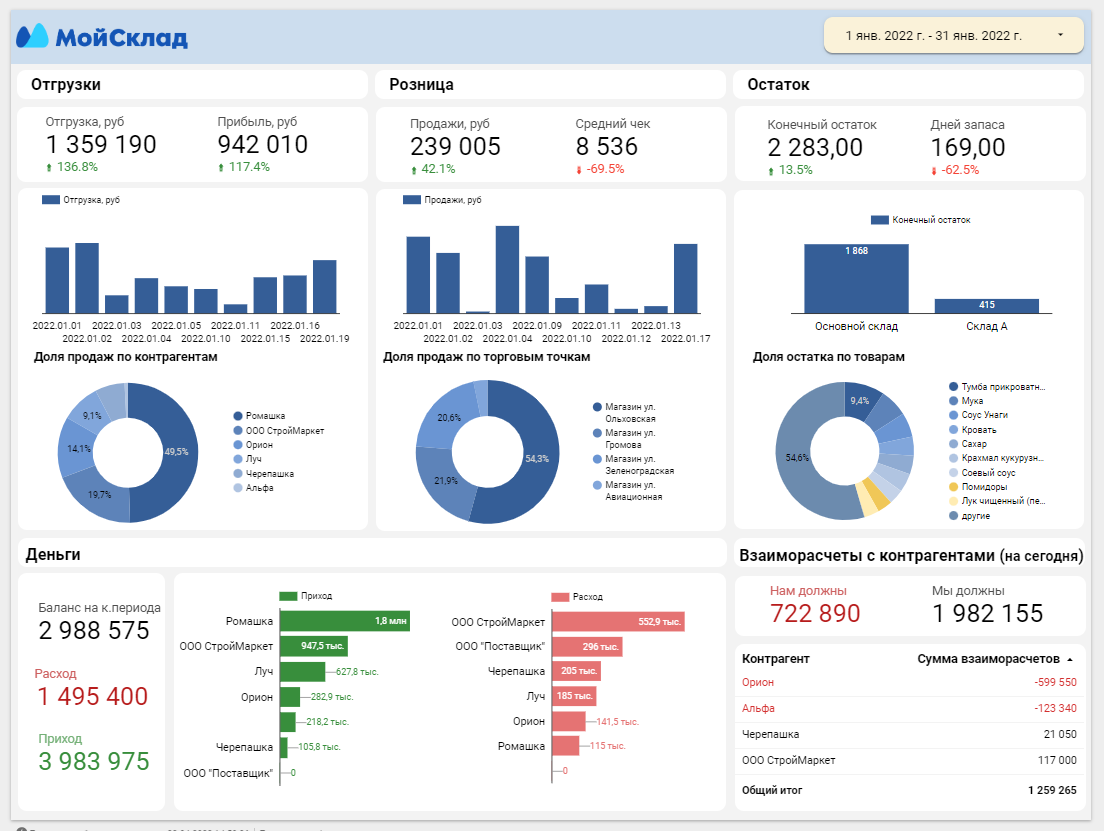
Загрузка данных из облачных систем для бизнеса позволяет нам быстро и просто строить вот такие дашборды:

Попробуйте нашу библиотеку на своих данных и пишите комментарии. Будем рады обратной связи.
mongohtotech
Отличный материал о том как BigQuery и ClickHouse помогают решать задачи анализа данных в бизнесе. Написано просто и понятно.