

Загвоздка с Kubernetes в том, что это не единая система, как, например, Redis RabbitMQ или PostgreSQL, а комбинация нескольких компонентов Control Plane: etcd, API-сервера и других. С помощью виртуальных машин или серверов они помогают контролировать пользовательские нагрузки, и от всех поступают огромные потоки метрик, в которых очень легко запутаться.
Команда VK Cloud перевела статью о том, на какие именно метрики стоит обращать внимание в первую очередь, чтобы грамотно мониторить рабочие нагрузки и поддерживать кластеры в исправном состоянии.
Что понадобится для мониторинга
Чтобы работать с метриками, нужно установить kube-state-metrics и Prometheus — так вы соберете выдаваемые метрики и сможете хранить их для выполнения запросов в дальнейшем.
Мы не будем останавливаться на процессе установки, но порекомендуем ознакомиться с Prometheus Helm Chart. С его помощью можно установить оба инструмента с настройками по умолчанию.
1. CPU / Memory Requests vs Actual Usage
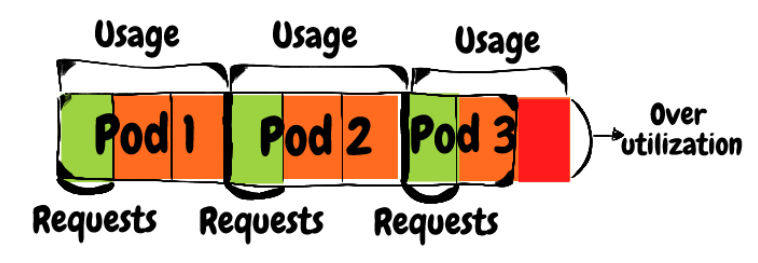
Что отслеживаем. Для каждого контейнера можно (и нужно!) задавать запросы CPU и памяти. Планировщик Kubernetes опирается на эти запросы, чтобы правильно выбрать узел, на котором можно разместить под. Для этого он рассчитывает объем неиспользуемых ресурсов на ноде, вычитая из общего объема текущие запросы запланированных подов. Поясним это на примере. Скажем, у вас есть узел с 8 ядрами процессора, на котором работает три пода. У каждого пода есть один контейнер, которому нужны ресурсы одного ядра. У ноды осталось пять незарезервированных ядер, которые планировщик может распределять между новыми подами.

Когда мы говорим «доступно», то имеем в виду не фактическое использование. Это еще не зарезервированные ядра процессора, на которые не поступили запросы от подов, запланированных в ноде. Если какому-то поду нужно шесть ядер, его выполнение не будет запланировано на этой ноде: его негде будет разместить.
Метрика «фактическое использование» отслеживает, сколько ресурсов использует под во время работы, при этом считается комбинация ресурсов: деплойментов, Statefulset и других. Поэтому здесь мы, скорее, говорим о процентиле, а не об использовании ресурсов отдельным подом. 90-й процентиль — хорошая отправная точка.
Например, деплоймент, которому требуется одно ядро процессора на под, может использовать 0,7 ядра в 90-м процентиле для всех реплик.
Почему метрика важна. Если запросы превышают фактическое использование, это приводит к неэффективному использованию ресурсов — недозагруженности. Представьте, что будет, если под, запрашивающий четыре ядра, в 90-м процентиле использует только одно.
Если Kubernetes запланирует выполнение этого пода в ноде с четырьмя ядрами, другие поды не смогут использовать три зарезервированных и неиспользуемых. На схеме ниже видно, что каждый под зарезервировал четыре ядра, но на самом деле использует только одно. То есть мы «впустую тратим» шесть ядер в ноде.

С памятью дела обстоят точно так же. Если запрос больше, чем фактическое использование, мы просто не будем задействовать всю имеющуюся память.
Другой вариант несогласованности — когда запросы пода меньше фактического использования, то есть перегруженность. В таком случае CPU приложения работают медленнее из-за нехватки ресурсов в ноде.
Представим себе три пода. Каждый из них запрашивает по одному ядру, но фактически использует три. Допустим, эти три пода запланированы на одну машину с 8 ядрами (1 запрос × 3 = 3 < 8). Но во время работы они конкурируют за ресурсы процессора, поскольку фактически используют 9 ядер, а это больше, чем есть в ноде.
При такой нехватке ресурсов процессора приложения работают медленнее
Другие проблемы возникают, когда запросы памяти меньше, чем это необходимо. Допустим, у нас три пода и каждый из них запрашивает 1 Гб памяти, а на самом деле использует 3 Гб. В итоге может оказаться, что планировщик направит все три пода на узел с 8 Гб памяти. Во время работы, когда процесс пытается получить больше памяти, чем есть у ноды, возникает состояние OOMKilled (Out Of Memory Killed), и процесс в Kubernetes перезапускается.
Когда процесс уходит в состояние OOMKilled, он теряет входящие или обрабатываемые запросы и остается недоступным до повторного запуска. В этот момент возникает недоиспользование ресурсов. А после перезапуска процесс сталкивается с холодным стартом из-за холодного кэша или пустых пулов соединений с зависимыми компонентами: базой данных, другими службами и т. п.
Как мониторить метрику. Давайте определим запросы пода как 100%. Адекватный диапазон фактического использования ресурсов (неважно, CPU или памяти) — 60–80% в 90-м процентиле.
Если у вас есть под, который запрашивает 10 Гб памяти, его 90-й процентиль фактического использования равен 6–8 Гб. Если значение ниже 6 Гб, вы недостаточно эффективно используете ресурсы памяти и теряете деньги. А если выше 8 Гб, вы приближаетесь к риску OOMKilled из-за нехватки памяти. Такое же правило действует и для запросов CPU.
2. CPU / Memory Limit vs Actual Usage
Что отслеживаем. Запросы ресурсов используются планировщиком для планирования рабочих нагрузок на нодах, а лимиты ресурсов позволяют устанавливать границы их использования во время выполнения рабочих нагрузок.
Почему метрика важна. Чтобы понять, какие последствия наступают при превышении лимитов CPU и памяти, важно разобраться, каким образом применяются эти лимиты.
Когда контейнер достигает лимита CPU, его производительность для контейнера принудительно снижается. Это значит, что он получает меньше CPU-циклов от ОС, чем мог бы, что в конечном счете приводит к увеличению времени выполнения. Не имеет значения, есть ли у ноды, на которой размещен под, свободные циклы, которые она могла бы этому поду выделить. Среда выполнения Docker в любом случае снижает производительность процессора для контейнера.
Не знать о возникшем тротлинге очень опасно. В системе подскакивают задержки произвольных потоков, и бывает очень трудно отследить исходную причину проблемы. Особенно если один из компонентов начал тротлить запросы, а вы заранее не наладили необходимые инструменты наблюдаемости. Эта ситуация может привести к частичным перебоям в работе службы или ее полной недоступности, если она участвует в основных процессах вашей системы.
Принудительное применение лимитов памяти отличается от применения лимитов CPU: когда контейнер достигает лимита памяти, возникает состояние OOMKilled. Последствия в этом случае такие же, как в результате OOMKIlled из-за нехватки памяти в ноде: процесс сбрасывает запросы, сервис не использует достаточно ресурсов, пока контейнер не перезапустится, после чего следует холодный старт.
Если процесс аккумулирует ресурсы памяти достаточно быстро, у него может возникнуть состояние Crash Loop. Оно сигнализирует, что процесс снова и снова сбоит либо при загрузке, либо вскоре после запуска. Из-за подов в состоянии Crash Loop служба часто становится недоступной.
Как мониторить метрику. Мониторинг лимита ресурсов напоминает мониторинг запросов CPU / память. Нужно стремиться к 80% фактического использования лимита в 90-м процентиле. Например, если у нас есть под с лимитом CPU два ядра и лимитом памяти в 2 Гб, оповещение нужно устанавливать на 1,6 ядра CPU и 1,6 Гб памяти.
Любое превышение этих значений приводит к риску тротлинга рабочей нагрузки или ее перезапуска из-за превышения пороговых значений.
3. Percentage of Unavailable Pods Out of Desired Replicas
Что отслеживаем. При развертывании приложения задается число желаемых реплик (подов), которое оно должно запустить. Иногда поды становятся недоступными по ряду причин, например:
- Некоторые поды не могут выполняться на работающих нодах в кластере из-за запросов ресурсов. Эти поды переходят в состояние Pending до тех пор, пока у ноды не высвободятся ресурсы для их размещения либо пока к кластеру не присоединится узел, соответствующий требованиям.
- Некоторые поды не проходят Liveness- или Readiness-пробы. Это значит, что они либо перезапускаются (Liveness), либо выводятся из конечных точек службы (Readiness).
- Некоторые поды достигают лимита ресурсов, как мы описывали выше, и входят в состояние Crash Loop.
- Некоторые поды размещаются на неисправной ноде и из-за этого не работают нормально.
Почему метрика важна. Наличие недоступных подов — это ненормальное состояние системы. Оно может проявиться в любой момент — от небольшого сбоя до полной недоступности службы. Результат зависит от доли недоступных подов из количества желаемых реплик и важности недостающих подов в основных потоках системы.
Как мониторить метрику. Здесь мы имеем дело с мониторингом доли недоступных подов из количества желаемых реплик. Точные процентные показатели, к которым следует стремиться в ваших KPI, зависят от важности службы и каждого ее пода в системе.
Для некоторых рабочих нагрузок можно смириться и с 5 % недоступных подов на какой-то период времени. Это при условии, что система сама восстанавливает работоспособность и это не сказывается на удобстве заказчиков. А для других рабочих нагрузок даже один недоступный под может стать проблемой. Хороший пример — Statefulsets, когда у каждого пода есть уникальная идентичность, так что ни один под не может быть недоступным.
4. Desired Replicas Out of HPA Maximum Replicas
Что отслеживаем. Горизонтальное автомасштабирование подов (HPA) — это ресурс Kubernetes, который позволяет корректировать количество реплик, выполняемых рабочей нагрузкой в соответствии с определенной вами целевой функцией. Распространенный сценарий использования — автомасштабирование среднего использования ресурсов CPU подами в деплойменте по сравнению с запросами CPU.
Почему метрика важна. Когда количество реплик в деплойменте достигает максимума, определенного в HPA, может возникнуть сложная ситуация. Вам понадобится больше подов, но HPA не может масштабировать. Последствия бывают разные в зависимости от настроенной функции Scale Up. Вот два примера, которые могут пролить свет на ситуацию:
- Если функция Scale Up использует ресурсы CPU, то их потребление существующими подами увеличивается до достижения лимита и возникновения тротлинга. В результате снижается пропускная способность системы.
- Если в функции Scale Up используются пользовательские метрики, например количество ожидающих в очереди сообщений, очередь может начать наполняться такими сообщениями. В итоге возникнет задержка в обработке пользовательских запросов.
Как мониторить метрику. Нужно установить пороговое значение X% для деления актуального количества реплик на максимальное количество реплик HPA. Адекватное значение X составляет 85% — так вы сможете вносить необходимые изменения до достижения предела.
Помните, что увеличение числа реплик может повлиять на другие части системы, так что в конечном счете для работы операции Scale Up придется менять гораздо больше, чем настройки HPA.
Классический пример — база данных, достигшая максимального лимита подключений, когда вы увеличиваете количество реплик и к ней пытается подключиться больше подов. Так что в этом случае очень разумно предусмотреть достаточно большой буфер в виде времени подготовки.
5. Nodes Failing Status Checks
Что отслеживаем. kubelet — это агент Kubernetes, который выполняется на каждой ноде кластера. Одна из обязанностей kubelet — публиковать несколько метрик, так называемых Node Conditions, отражающих состояние ноды, на которой он выполняется:
- Ready — True, если узел в порядке и готов принимать поды.
- DiskPressure — True, если на диске ноды не хватает места.
- MemoryPressure — True, если на узле мало памяти.
- PIDPressure — True, если на ноде запущено слишком много процессов.
- NetworkUnavailable — True, если неправильно настроена сеть ноды.
Исправный узел выдает True для состояния Ready и False для всех других четырех состояний.
Почему метрика важна. Если состояние Ready становится False или значение любого другого состояния становится True, скорее всего, некоторые или все рабочие нагрузки на этой ноде выполняются некорректно. И об этом надо знать.
Для DiskPressure, MemoryPressure и PIDPressure основную причину установить нетрудно: процесс пишет на диск, распределяет память или генерирует процессы со слишком большой для ноды скоростью.
С состояниями Ready и NetworkUnavailable не все лежит на поверхности: чтобы разобраться, в чем проблема, может потребоваться тщательное расследование.
Как мониторить метрику. Я бы для начала указал в настройках «0 неисправных нод», чтобы каждый неисправный узел присылал оповещение.
6. Persistent Volume Utilization
Что отслеживаем. Persistent Volume (PV) — это ресурс Kubernetes, блок хранилища, который можно прикреплять к подам в системе и откреплять от них. Реализация PV зависит от платформы.
Например, если вы используете деплоймент Kubernetes на основе AWS, PV будет представлять собой том EBS. Как и у каждого блочного хранилища, у него есть емкость, и со временем он может заполниться.
Почему метрика важна. Когда процесс использует диск, на котором нет свободного места, черти вырываются из ада: у одного и того же сбоя может быть миллион симптомов. И проявления, которые мы видим в стеке, не всегда выводят нас к исходной причине. Эта метрика может не только предотвратить сбои в будущем, но и помогает планировать рабочие нагрузки, которые записывают и постепенно добавляют данные.
Prometheus — отличный пример такой рабочей нагрузки: он записывает точки данных в базу временных рядов, отслеживая уменьшение свободного места на диске. Поскольку Prometheus записывает данные в постоянном темпе, метрику использования PV удобно применять для расчета, который понадобится, чтобы удалить старые данные или докупить больше емкости для диска.
Как мониторить метрику. kubelet выявляет и использование, и емкость PV. Так что простое разделение между ними — это фокус, который поможет отслеживать эффективность использования PV. Здесь довольно трудно предположить адекватный порог оповещения, поскольку все и правда зависит от траектории графика использования. Но опыт показывает, что, прежде чем хранилище PV заполнится, пройдет, возможно, две или три недели.
Попробуйте Kubernetes as a Service на платформе VK Cloud. Мы даем новым пользователям 3000 бонусных рублей на тестирование кластера или любых других сервисов.