
Представьте, что бизнес-метрика неожиданно резко вырастает или проседает. Как понять, реальное это изменение или проблема с качеством данных? Команда VK Cloud перевела статью о том, как в компании Intuit решают этот вопрос с помощью предохранителей для пайплайнов данных.
В чем суть предохранителя
Если возникают проблемы с данными, предохранитель разрывает «цепь» и не пускает некачественные данные в следующие процессы обработки. В результате данные, которые приходятся на периоды низкого качества, не входят в отчеты. А значит, можно быть уверенным в их корректности.
Такой проактивный подход сокращает Time-to-Reliable-Insights до минут. А автоматизация обеспечивает прямую зависимость данных от их качества. Это позволяет избежать разрушительных авралов, которые возникают всякий раз, когда нужно проверить и поправить метрики или отчеты. Далее мы в подробностях рассмотрим, как внедрять такие предохранители.
Реалии наших пайплайнов данных
Пайплайн — это логическая абстракция, последовательность трансформаций, необходимых для преобразования необработанных данных в аналитические выкладки. На нашей платформе обработки данных каждый день работают тысячи пайплайнов. Каждый из них принимает данные из разных источников и с помощью последовательности ETL- и аналитических запросов формирует аналитические данные в форме отчетов, дашбордов, ML-моделей и таблиц с результатами. Эти выкладки используются как для коммерческой деятельности, так и для повышения качества обслуживания клиентов.
Пайплайн принимает четыре типа данных, поступающих более чем из 100 реляционных БД и хранилищ NoSQL (ключ-значение, документ):
-
Данные, вводимые пользователями (UED) в процессе использования продукта.
-
Данные поведенческого анализа: история посещения веб-страниц, отражающая использование продукта.
-
Данные предприятия: системы back office для технической поддержки и обслуживания клиентов, выставления счетов и прочее.
-
Сторонние данные: ленты новостей в соцсетях, файлы кредиторов, банковские данные и прочее.
Из источников данные поступают в озеро (HDFS/S3) с помощью фреймворков приема пакетных данных. Для этой цели подойдут Kafka, Sqoop, Oracle GoldenGate и с десяток доморощенных инструментов. Потом в озере данные анализируют с помощью разных модулей обработки запросов (Hive, Spark) и перемещаются в MPP-хранилища, такие как Vertica. Эти результаты доступны через обслуживающие базы данных, например, Cassandra или Druid. Насколько сложны реальные пайплайны данных, видно из логического представления, сгенерированного в QuickData SuperGlue:

В пайплайне проблемы с качеством данных возникают на разных этапах. Мы разбиваем эти проблемы на три категории:
- проблемы из-за источника;
- при приеме данных;
- ссылочной целостности.
Причины, по которым с каждым бакетом чаще всего происходят проблемы, кроются в сочетании рабочих ошибок, ошибок в логике, недостаточном управлении изменениями, противоречиях в модели данных.
|
Проблемы из-за источника данных |
Проблемы при приеме данных |
Проблемы целостности |
|
|
|
Механика предохранителей для пайплайнов
Предохранители изобрели как средство против всплесков напряжения в электросети, из-за которых может случиться пожар. У нас на какое-то время пропадает электричество, зато дом не сгорит. В микросервисной архитектуре механика предохранителей тоже пользуется популярностью: мы не заставляем API ждать медленный или перегруженный микросервис, — вместо этого предохранитель просто не вызывает сервис. В конечном счете мы получаем прогнозируемое время отклика API, хотя приходится жертвовать доступностью некоторых сервисов. После устранения проблем с микросервисом «цепь» процессов снова замыкается, и сервис становится доступным.
Работа предохранителей для пайплайнов данных строится по аналогичному принципу. Выполняется проактивный анализ качества данных. И если оно оказывается ниже порогового значения, срабатывает предохранитель: пакет данных низкого качества не попадает в операции обработки.
Без предохранителя задания пайплайна продолжались бы, а качественные и некачественные данные перемешивались друг с другом. Здесь же мы исходим из гарантии, что доступные аналитические данные всегда достоверны, — ведь некачественные данные просто не берутся в обработку. Это простая договоренность, понятная всем дата-инженерам, аналитикам, дата-сайентистам и другим потребителям аналитических выкладок. Благодаря ей отпадает необходимость каждый раз вручную проверять полученные результаты.
Данные, поступающие в озеро, сохраняются в области промежуточного хранения и образуют пакеты данных за час или за день. Для каждого пакета анализируется качество данных — в случае проблемы предохранитель срабатывает, не пуская этот пакет дальше. Если предохранитель сработал и «цепь разомкнулась», команды получают предупреждение с требованием диагностировать проблему. Если ее можно решить, данные направляются в пакет, который становится доступным для дальнейшей обработки.
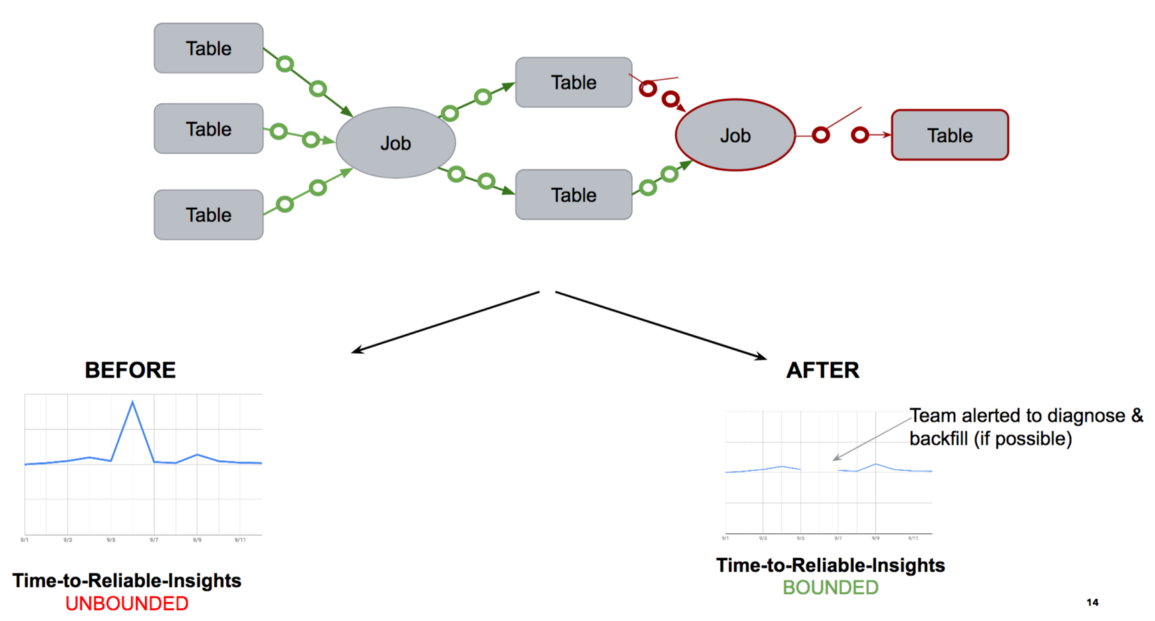
В системе предохранителей для пайплайна данных есть два состояния:
- «Цепь замкнута»: данные движутся по пайплайну.
- «Цепь разомкнута»: данные не движутся, обнаружена проблема и данные недоступны для дальнейших операций.
В обоих состояниях постоянно проверяется качество разделов данных за час или за день. Если качество пакета соответствует пороговому значению, цепь переходит из разомкнутого состояния в замкнутое. И наоборот, если качество оказывается низким, цепь размыкается.
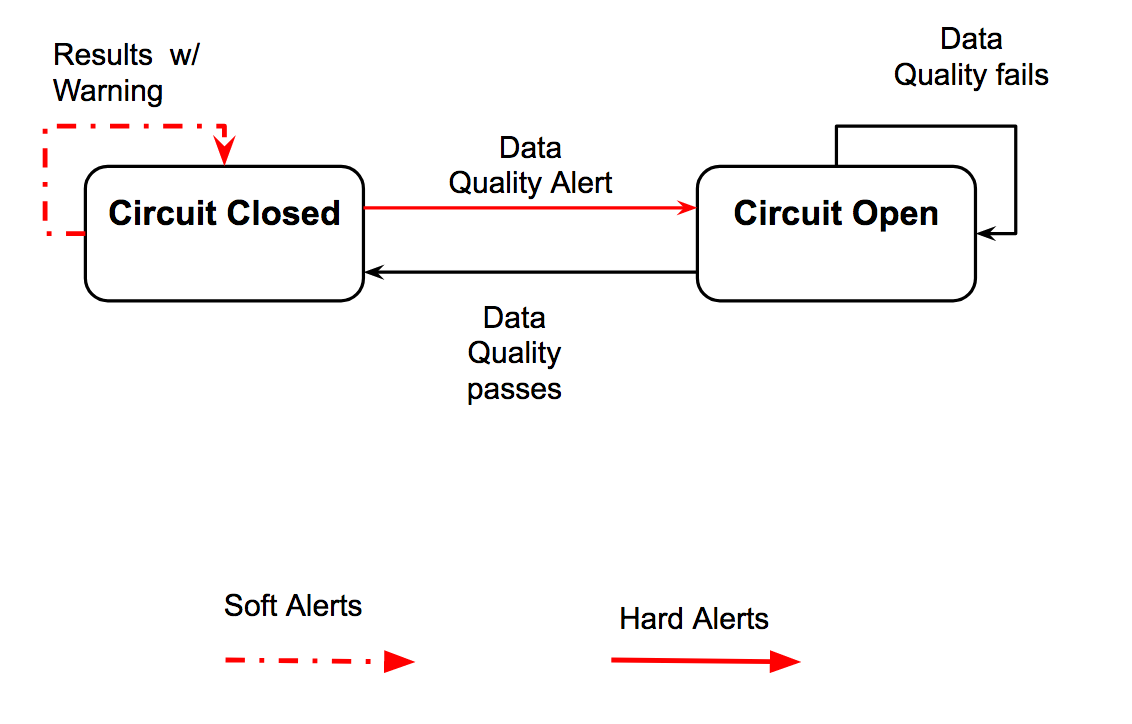
Предупреждения о проблемах качества бывают двух типов: жесткие и мягкие. Мягкие предупреждения не влияют на состояние «цепи», а просто выводят оповещение вместе с полученными аналитическими выкладками.
Реализация предохранителя на платформе обработки данных
Механика таких предохранителей строится на трех основных функциях:
-
Отслеживание Data lineage: находит все таблицы и задания, задействованные в трансформации, от таблицы-источника до таблиц, отчетов и ML-моделей на выходе.
-
Создание профиля пайплайна данных: отслеживает события, статистику и аномалии, связанные с пайплайном данных. Позже мы покажем, что создание профиля выполняется на операционном уровне и на уровне данных.
-
Контроль за предохранителем: следит за срабатыванием предохранителя в зависимости от проблем, обнаруженных при создании профиля.
Отслеживание Data lineage происходит путем анализа запросов, связанных с заданиями для пайплайна. Пайплайн состоит из заданий → каждое задание состоит из одного или нескольких скриптов → каждый скрипт состоит из одной или нескольких инструкций SQL. В запросе SQL анализируются таблицы на входе и выходе. Lineage пайплайна определяется как массив трех видов данных: <Job Name, Input Tables, Output Tables>.
Такая работа выполняется не один раз, это постоянно эволюционирующий процесс. Каждый скрипт состоит из одного или нескольких запросов на разных языках: SQL и отчасти Pig. Они склеиваются друг с другом, и результат выполнения одного скрипта используется как исходные данные для следующего задания.

Создание профиля делится на два бакета:
-
На операционном уровне. Здесь акцент делается на состоянии задания и матрицы данных. Состояние задания подразумевает отслеживание статистики выполнения, например, времени выполнения, запуска и т. п. Состояние матрицы данных подразумевает отслеживание событий и статистики по компонентам системы: исходным базам данных, инструментам приема, фреймворкам расписания, механизмам анализа, обслуживающим базам данных, фреймворкам для публикации и визуализации (например, Tableau, QlikView, SageMaker и т. п.).
-
На уровне данных. В этом бакете акцент сделан на анализе схем обработки данных. Это довольно широкая тема, в которой можно выделить три бакета.
|
Один столбец |
Несколько столбцов |
Зависимости между БД |
|
|
|
Функционирование предохранителей зависит от того, какие проблемы были обнаружены при создании профиля. Для выявления проблем можно опираться либо на абсолютные пороговые значения или правила, либо на относительные, основанные на обнаружении аномалий в ML-моделях.

Как обсуждалось ранее, при обнаружении проблемы формируется предупреждение одного из двух типов: мягкое или жесткое. При жестком предупреждении предохранитель срабатывает и цепь размыкается, а при мягком — просто выводится оповещение. Ниже мы приводим несколько примеров предупреждений обоих типов для проблем на операционном уровне и на уровне данных:
| Мягкие предупреждения (низкая вероятность) |
Жесткие предупреждения (высокая вероятность) |
|
| Создание профиля на операционном уровне |
|
|
| Создание профиля на уровне данных |
|
|
Сегодня нет четко определенных подходов к устранению проблем с качеством, выявляемых в пайплайне. Предохранители для пайплайнов — это метод, обеспечивающий доступность данных в зависимости от их качества. С помощью предупреждений разных видов мы можем контролировать работу пайплайна, меняя степень доступности критически важных таблиц, данные из которых поступают в сотни следующих за ними таблиц.

Команда VK Cloud развивает собственные Big Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3 000 бонусных рублей.
Читать по теме:
Комментарии (3)

CrocodileRed
09.09.2022 23:31Мнение не по теме, но тем не менее: неужели у команды VK Cloud нет собственного опыта, которым можно поделиться и приходится переводить всякое?))
Ivan22
И как например в случае потери одной транзакции? Отменяеете расчет выполнения всего плана продажи за год? Или нет?
economist75
Предохранитель, если сделает backfill (заливку аномального пика или "пустоты" первым текущим валидным значением) - вряд ли что-то испортит. Он не не завысит сумму налога и вряд ли приведет к судебному иску. Не остановит дымосос и не устроит аварию.
А вот без него - "кривой" дэшборд из-за ручной правки базы после выпадения данных какого-нибудь сенсора - запросто может породить офисный кризис с разборками, увольнением и сокращением целых отделов. Самодуров и лихих на расправу руководителей - хватает везде. Плюс это функция времени пребывания на посту, возраста и влияния "банно-саунного" менеджмента. Поэтому каждый такой предохранитель - спасенные судьбы линейных руководителей. Статья полезная, вот прям слышу как наши побежали что-то подобное делать.