

Команда VK Cloud перевела статью об основных принципах работы сети в Kubernetes: как кластер принимает и отправляет пакеты начиная с исходного веб-запроса и до размещения приложения в контейнере.
Требования к сети в Kubernetes
Сначала давайте проясним требования к сети Kubernetes:
- Под в кластере должен свободно взаимодействовать с любым другим подом без использования Network Address Translation (NAT).
- Любая программа, работающая на узле кластера, должна взаимодействовать с любым подом на том же узле без использования NAT.
- У каждого пода есть собственный IP-адрес (IP-per-Pod), и любой другой под может обратиться к нему по этому адресу.
Эти требования и ограничения описывают свойства сети кластера в целом и вынуждают отвечать на следующие вопросы:
- Как убедиться, что контейнеры в одном и том же поде ведут себя как на одном хосте?
- Может ли под обращаться к другим подам в кластере?
- Может ли под обращаться к службам? Обрабатывают ли службы запросы о балансировке нагрузки?
- Может ли под получать трафик извне кластера?
В этой статье мы рассмотрим первые три пункта, начиная со взаимодействия на уровне подов и контейнеров.
Как в поде работают сетевые пространства имен Linux
Допустим, основной контейнер размещает приложение, а еще один работает одновременно с основным. В этом примере у нас есть поды с контейнерами Nginx и busybox:
apiVersion: v1
kind: Pod
metadata:
name: multi-container-pod
spec:
containers:
- name: container-1
image: busybox
command: ['/bin/sh', '-c', 'sleep 1d']
- name: container-2
image: nginxПосле деплоймента:
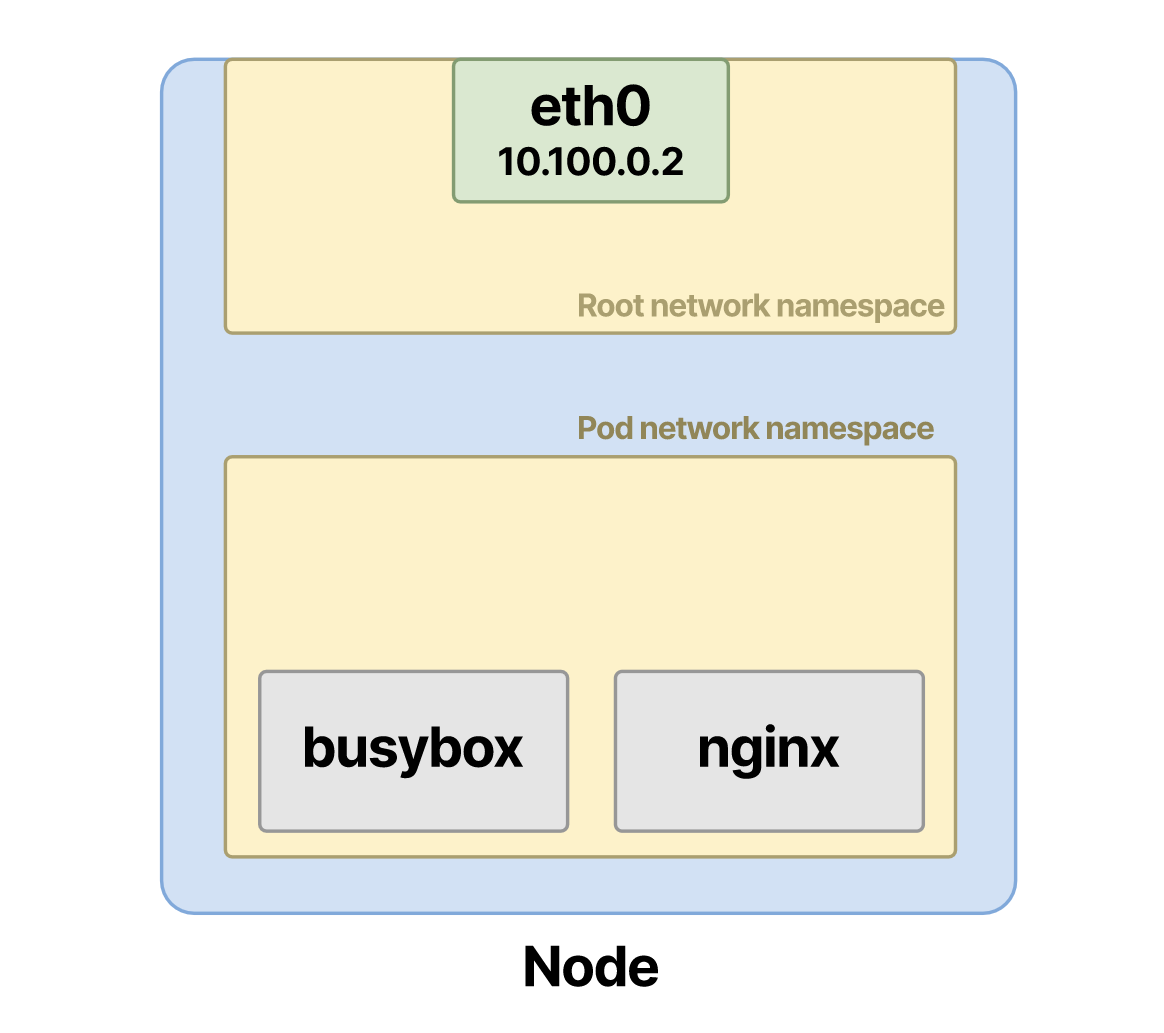
- У пода появляется собственное сетевое пространство имен на узле.
- Поду назначается IP-адрес, и два контейнера совместно используют порты.
-
Оба контейнера имеют общее сетевое пространство имен и могут видеть друг друга на localhost.
Конфигурация сети молниеносно выполняется в фоновом режиме.
Но давайте сделаем шаг назад и разберемся, почему все вышеописанное необходимо для работы контейнеров. В Linux сетевые пространства имен — это отдельные, изолированные, логические пространства.
Представьте, что мы взяли интерфейс физической сети и разрезали его на небольшие отдельные кусочки. Так мы получаем сетевые пространства имен. Каждый кусочек можно настроить отдельно, задав для него собственные сетевые правила и ресурсы. Это могут быть и правила брандмауэра, и интерфейсы (виртуальные или физические), и маршруты и вообще все, что связано с работой сети.
Физический сетевой интерфейс содержит корневое сетевое пространство имен:

Можно использовать пространства имен Linux для создания изолированных сетей. Каждая сеть является независимой и не взаимодействует с другими, если не задать для этого соответствующие настройки:

В конечном счете физический интерфейс должен обрабатывать реальные пакеты, так что на его основе создают все виртуальные интерфейсы.
Для управления сетевыми пространствами имен можно использовать утилиту управления ip-netns. Чтобы перечислять пространства имен на хосте, есть команда
ip netns list. Обратите внимание, что когда создается пространство имен, эта утилита находится в разделе /var/run/netns, но Docker не всегда это учитывает.Например, вот пространства имен из узла Kubernetes:

Обратите внимание на префикс cni-; это значит, что пространство имен создано CNI.
Когда вы создаете под и его назначают узлу, CNI:
- Назначает IP-адрес.
- Назначает сети контейнер(ы).
Если под содержит несколько контейнеров, как выше, то оба контейнера размещаются в одном и том же пространстве имен.
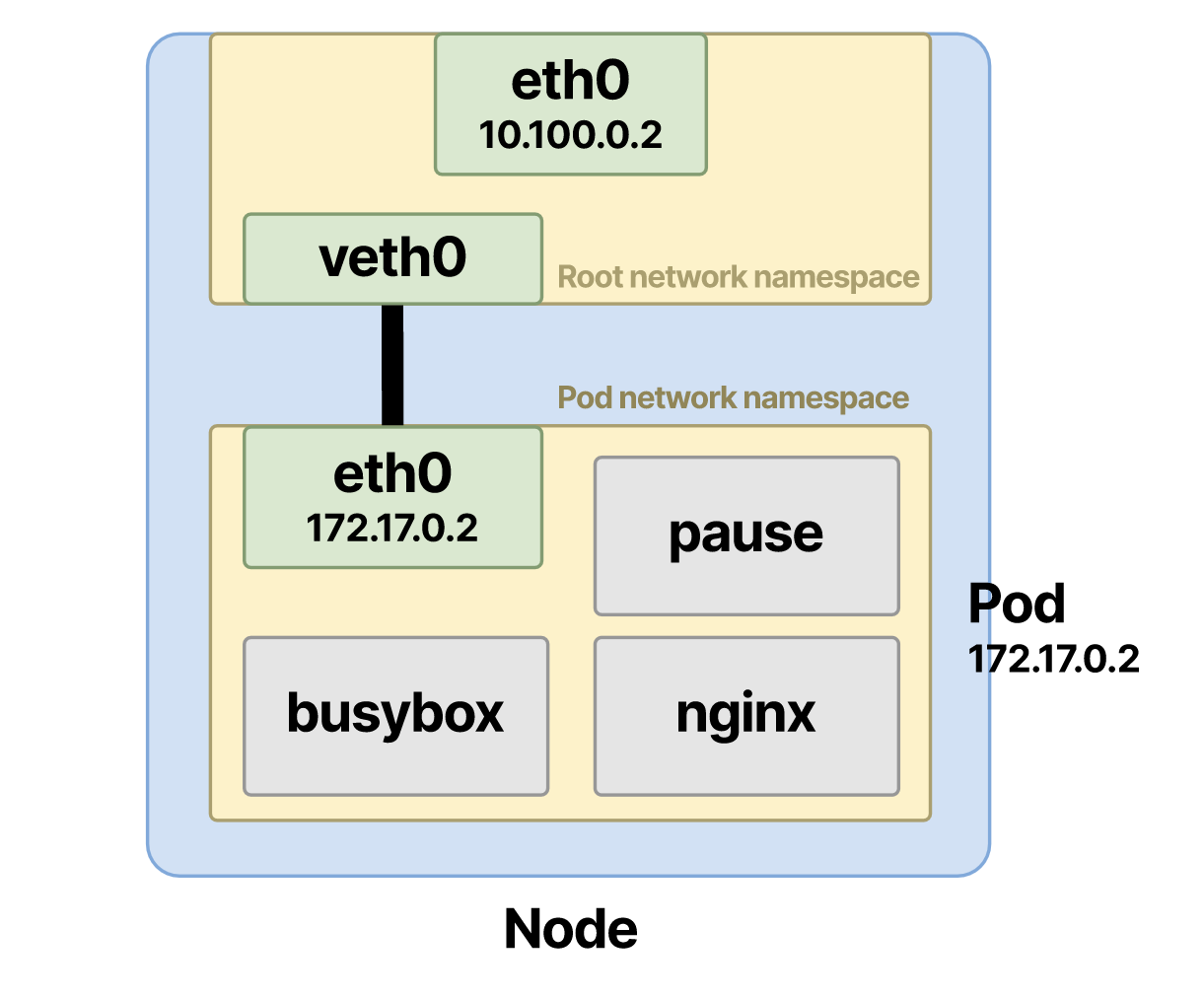
При создании пода среда выполнения контейнера сначала создает сетевое пространство имен для контейнеров:
Затем CNI приступает к работе и назначает ему IP-адрес:

Наконец, CNI прикрепляет контейнеры к остальной сети.
А что происходит, когда вы перечисляете контейнеры на узле? Можно с помощью SSH заглянуть в узел Kubernetes и посмотреть пространства имен:
lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 171 1 root unassigned /run/docker/netns/default /sbin/init noembed norestore
4026532286 net 2 4808 65535 0 /run/docker/netns/56c020051c3b /pause
4026532414 net 5 5489 65535 1 /run/docker/netns/7db647b9b187 /pause
lsns – команда для перечисления всех доступных пространств имен на хосте.
В Linux есть пространства имен разных типов. Но где контейнер Nginx? И что такое pause-контейнеры?
Pause-контейнер создает сетевое пространство имен в поде
Давайте перечислим все процессы на узле и проверим, удастся ли нам найти контейнер Nginx:
lsns
NS TYPE NPROCS PID USER COMMAND
# truncated output
4026532414 net 5 5489 65535 /pause
4026532513 mnt 1 5599 root sleep 1d
4026532514 uts 1 5599 root sleep 1d
4026532515 pid 1 5599 root sleep 1d
4026532516 mnt 3 5777 root nginx: master process nginx -g daemon off;
4026532517 uts 3 5777 root nginx: master process nginx -g daemon off;
4026532518 pid 3 5777 root nginx: master process nginx -g daemon off;
Контейнер указан в пространстве имен mount (mnt), Unix time-sharing (uts) и PID (pid), но не в сетевом пространстве имен (net). К сожалению, lsns показывает для каждого процесса только PID нижнего уровня, но можно настроить фильтр по ID процесса.
Извлечем все пространства имен для контейнера Nginx:
sudo lsns -p 5777
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 178 1 root /sbin/init noembed norestore
4026531837 user 178 1 root /sbin/init noembed norestore
4026532411 ipc 5 5489 65535 /pause
4026532414 net 5 5489 65535 /pause
4026532516 mnt 3 5777 root nginx: master process nginx -g daemon off;
4026532517 uts 3 5777 root nginx: master process nginx -g daemon off;
4026532518 pid 3 5777 root nginx: master process nginx -g daemon off;
И снова процесс
pause, только в этот раз он держит сетевое пространство имен в заложниках.У каждого пода в кластере есть дополнительный скрытый контейнер, работающий в фоновом режиме и называемый pause-контейнером. Если перечислить контейнеры, работающие на узле, и выбрать pause-контейнеры, вы увидите, что они автоматически создаются в пару каждому поду, назначенному на узле:
docker ps | grep pause
fa9666c1d9c6 k8s.gcr.io/pause:3.4.1 "/pause" k8s_POD_kube-dns-599484b884-sv2js…
44218e010aeb k8s.gcr.io/pause:3.4.1 "/pause" k8s_POD_blackbox-exporter-55c457d…
5fb4b5942c66 k8s.gcr.io/pause:3.4.1 "/pause" k8s_POD_kube-dns-599484b884-cq99x…
8007db79dcf2 k8s.gcr.io/pause:3.4.1 "/pause" k8s_POD_konnectivity-agent-84f87c…
Можно сказать, что именно этот pause-контейнер отвечает за создание и хранение сетевого пространства имен. Оно создается соответствующей средой выполнения контейнера. Обычно это containerd или CRI-O. Сразу же перед деплойментом пода и созданием контейнера среда исполнения должна, в числе прочего, создать сетевое пространство имен. Она избавляет нас от запуска ip netns и создания пространства имен вручную, делая это автоматически.
Вернемся к pause-контейнеру. Он содержит очень мало кода и «засыпает» сразу же после деплоймента. Однако контейнер играет важную роль в работе экосистемы Kubernetes.
При создании пода среда выполнения контейнера с помощью контейнера sleep создает сетевое пространство имен:

Каждый новый контейнер в поде присоединяется к существующему сетевому пространству имен, созданному этим контейнером:
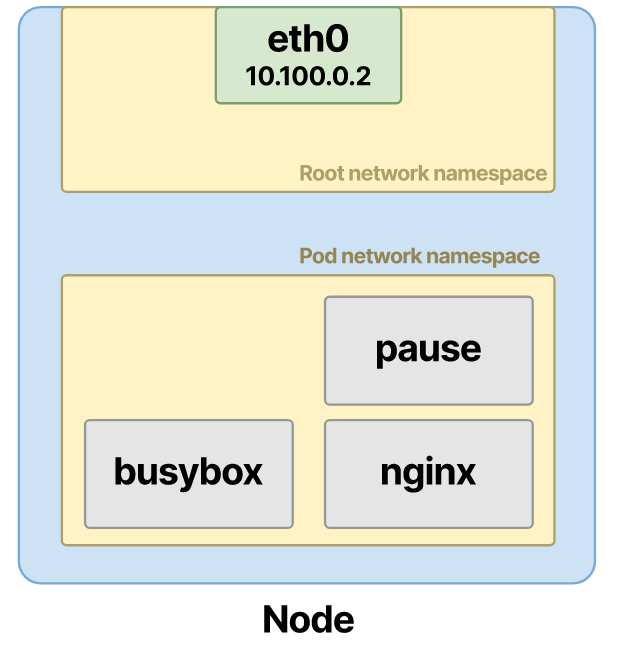
Далее CNI назначает IP-адрес и прикрепляет контейнеры к сети.

Чем может быть полезен уснувший контейнер? Чтобы разобраться в утилите CNI, давайте представим, что у нас под с двумя контейнерами, но без pause-контейнера.
Как только запускается контейнер, CNI:
- Заставляет контейнер busybox присоединиться к предыдущему пространству имен.
- Назначает IP-адрес.
- Назначает контейнерам сеть.
Что происходит в случае сбоя Nginx? CNI придется снова выполнить все эти действия, и работа сети будет прервана для обоих контейнеров.
Поскольку сбой контейнера sleep маловероятен, использовать его для создания сетевого пространства имен, как правило, безопаснее и надежнее. Если один из контейнеров в поде выходит из строя, остальные все равно могут отвечать на сетевые запросы.
Поду назначается один IP-адрес
Я упоминал, что поду и обоим контейнерам назначается один и тот же IP-адрес. Как его настроить?
В поде внутри сетевого пространства имен создается интерфейс и назначается IP-адрес. Давайте это проверим.
Во-первых, выясним IP-адрес пода:
kubectl get pod multi-container-pod -o jsonpath={.status.podIP}
10.244.4.40
Далее найдем соответствующее сетевое пространство имен. Поскольку сетевые пространства имен создаются на основе физического интерфейса, нам придется получить доступ к узлу кластера.
Если вы используете minikube, можно получить доступ к узлу через minikube ssh. Если пользуетесь услугами облачного провайдера, доступ к узлу можно получить через SSH.
Теперь давайте выясним, какое именованное сетевое пространство имен было создано последним:
ls -lt /var/run/netns
total 0
-r--r--r-- 1 root root 0 Sep 25 13:34 cni-0f226515-e28b-df13-9f16-dd79456825ac
-r--r--r-- 1 root root 0 Sep 24 09:39 cni-4e4dfaac-89a6-2034-6098-dd8b2ee51dcd
-r--r--r-- 1 root root 0 Sep 24 09:39 cni-7e94f0cc-9ee8-6a46-178a-55c73ce58f2e
-r--r--r-- 1 root root 0 Sep 24 09:39 cni-7619c818-5b66-5d45-91c1-1c516f559291
-r--r--r-- 1 root root 0 Sep 24 09:39 cni-3004ec2c-9ac2-2928-b556-82c7fb37a4d8
В нашем случае это cni-0f226515-e28b-df13-9f16-dd79456825ac.
Теперь можно выполнить команду exec внутри этого пространства имен:
ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip a
# output truncated
3: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 16:a4:f8:4f:56:77 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.4.40/32 brd 10.244.4.40 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::14a4:f8ff:fe4f:5677/64 scope link
valid_lft forever preferred_lft forever
Это и есть IP-адрес пода.
Давайте посмотрим на этот интерфейс с другой стороны — для этого выполним команду
grep для 12-й части @if12.ip link | grep -A1 ^12
12: vethweplb3f36a0@if16: mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default
link/ether 72:1c:73:d9:d9:f6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
Также можно убедиться, что контейнер Nginx слушает HTTP-трафик из этого пространства имен:
ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac netstat -lnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 692698/nginx: master
tcp6 0 0 :::80 :::* LISTEN 692698/nginx: master
Если вы не можете получить доступ к рабочим узлам в кластере с помощью команды SSH, можно использовать
kubectl exec, чтобы получить shell к контейнеру busybox и использовать IP и команду netstat непосредственно внутри него.Теперь, когда мы рассмотрели взаимодействие между контейнерами, перейдем к взаимодействию на уровне подов.
Инспекция трафика между подами в кластере
Во взаимодействии на уровне подов есть два возможных сценария: трафик пода предназначен для пода либо на том же узле, либо на другом.
Чтобы все это работало, нужны пары виртуальных интерфейсов, о которых мы уже говорили, и Ethernet-мосты. Прежде чем двигаться дальше, давайте рассмотрим их функции и выясним, для чего они нужны.
Для взаимодействия пода с другими подами ему сначала нужен доступ к корневому пространству имен узла. Для этого пара виртуальных интерфейсов с Ethernet-мостом соединяет два пространства имен: корневое и пода.
Эти устройства виртуальных интерфейсов (отсюда буква v в veth) соединяются и действуют как туннель между двумя пространствами имен.
С помощью устройства veth один конец «прикрепляется» к пространству имен пода, а другой — к корневому пространству имен.

CNI делает это за вас, но это можно сделать и вручную:
ip link add veth1 netns pod-namespace type veth peer veth2 netns root
Теперь у пространства имен пода есть «туннель» доступа к корневому пространству имен. У каждого пода, только что созданного на узле, имеется такая пара veth.
Но создание пар интерфейсов — это одна часть дела. Вторая — назначить Ethernet-устройствам адрес и создать маршруты по умолчанию. Давайте посмотрим, как настроить интерфейс
veth1 в пространстве имен пода:ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip addr add 10.244.4.40/24 dev veth1
ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip link set veth1 up
ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip route add default via 10.244.4.40
Со стороны узла создадим другую пару
veth2:ip addr add 169.254.132.141/16 dev veth2
ip link set veth2 up
Можно проверить имеющиеся пары veth, как мы это делали раньше. В пространстве имен пода извлеките суффикс интерфейса
eth0.ip netns exec cni-0f226515-e28b-df13-9f16-dd79456825ac ip link show type veth
3: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 16:a4:f8:4f:56:77 brd ff:ff:ff:ff:ff:ff link-netnsid 0
В этом случае можно выполнить команду
grep -A1 ^12 (или просто прокрутить до полученного результата):ip link show type veth
# output truncated
12: cali97e50e215bd@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-0f226515-e28b-df13-9f16-dd79456825ac
Можно также использовать
ip -n cni-0f226515-e28b-df13-9f16-dd79456825ac link show type veth.Обратите внимание на нотацию в обоих интерфейсах
3: eth0@if12и
12: cali97e50e215bd@if3.Из пространства имен пода интерфейс
eth0 соединяется с интерфейсом номер 12 в корневом пространстве имен. Отсюда и @if12.С другой стороны пары
veth корневое пространство имен соединяется с интерфейсом номер 3 в пространстве имен пода. Далее идет мост, который соединяет каждый конец пары veth.Сетевое пространство имен пода соединяется с Ethernet-мостом
Мост «связывает» вместе каждый конец виртуальных интерфейсов, расположенных в корневом пространстве имен. Он обеспечивает трафик и между виртуальными парами и через общее корневое пространство имен.
Ethernet-мост расположен на уровне 2 сетевой модели OSI. Его можно представить в виде виртуального тумблера, который принимает соединения от разных пространств имен и интерфейсов.
Мост соединяет разные сети, доступных на одном и том же узле. Таким образом с помощью моста можно соединять два интерфейса —
veth из пространства имен пода и veth другого пода в узле.
Давайте посмотрим на Ethernet-мост и пары veth в действии.
Отслеживание трафика между подами в одном узле
Допустим, у нас два пода на одном узле, и под A хочет отправить сообщение поду B.
Поскольку точка назначения находится за пределами контейнеров в пространстве имен, под A отправляет пакет своему интерфейсу — по умолчанию eth0. Этот интерфейс привязан к одному концу пары veth и работает в качестве туннеля. Таким образом, пакеты направляются в корневое пространство имен на узле.

Ethernet-мост, выступающий виртуальным коммутатором, должен тем или иным образом сопоставить IP-адрес пода точки назначения (пода B) с его MAC-адресом.

На помощь приходит протокол ARP. Когда фрейм достигает моста, всем подключенным устройствам направляется трансляция ARP. Мост спрашивает: у кого есть IP-адрес пода B?

Ответ содержит MAC-адрес интерфейса, который соединяет под B; потом эта информация хранится в кеше ARP моста (таблице поиска).

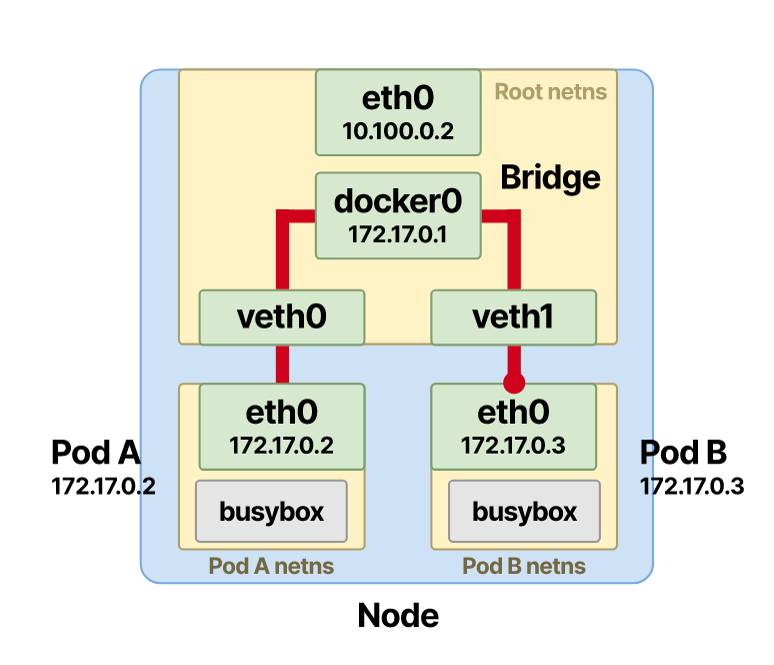
После того как сопоставленные IP- и MAC-адрес были сохранены, мост ищет по таблице и направляет пакет на правильный endpoint. Пакет приходит в veth пода B в корневом пространстве имен и оттуда быстро попадает в интерфейс eth0 внутри пространства имен пода B.

Итак, взаимодействие между подом A и подом B прошло успешно.
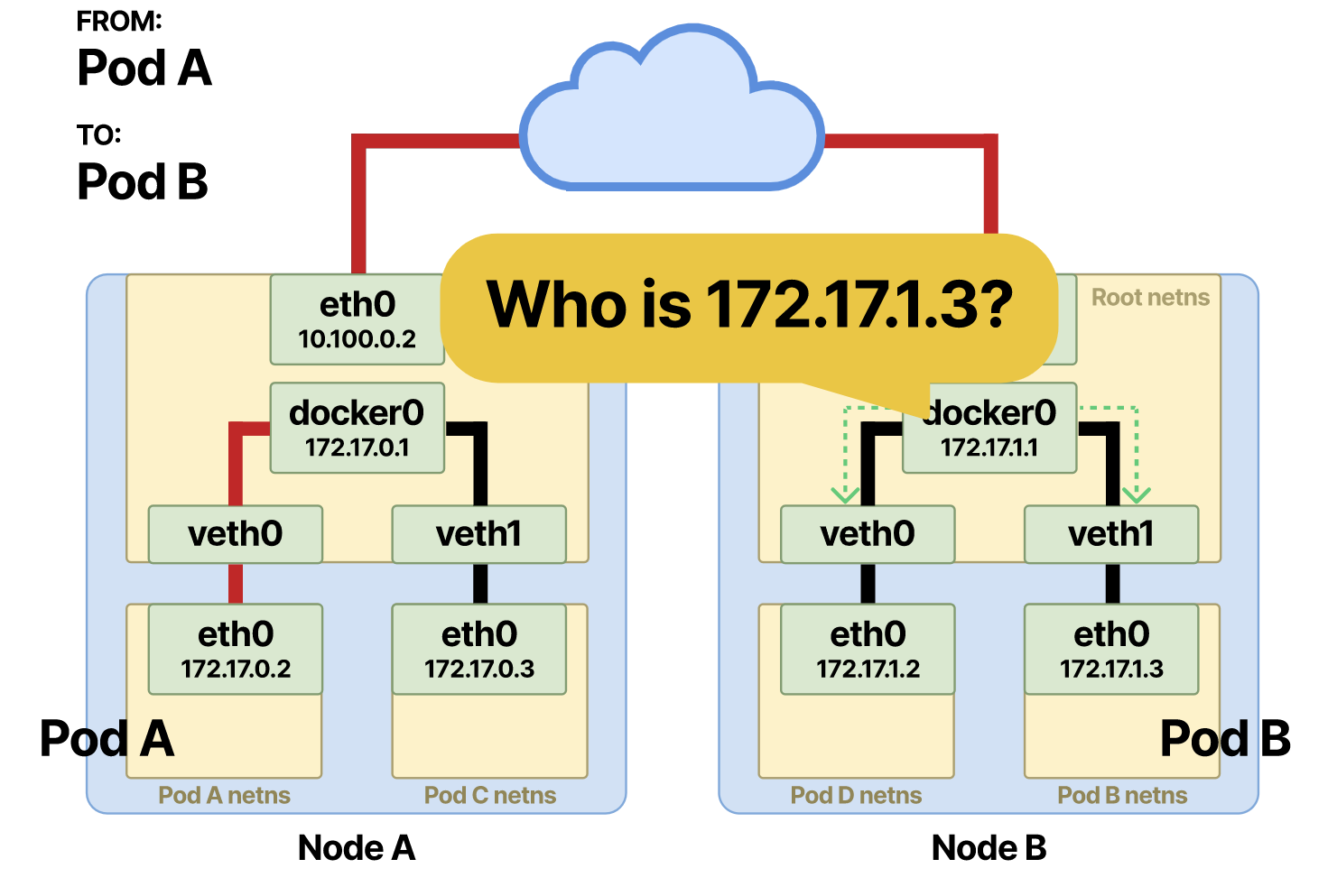
Отслеживание взаимодействия между подами на разных узлах
Если поду нужно связаться с подом на другом узле, для этого взаимодействия требуется дополнительный шаг. Первые два шага остаются такими же до момента, когда пакет поступает в корневое пространство имен, откуда его надо переслать поду B:

Если IP-адрес точки назначения находится не в локальной сети, пакет направляется в шлюз этого узла по умолчанию. Выход или шлюз по умолчанию на узле обычно находится в интерфейсе eth0 — физическом интерфейсе, который соединяет узел с сетью.

На этот раз ARP-сопоставление не происходит, потому что IP-адреса источника и точки назначения расположены в разных сетях. Для проверки используется битовая операция. Если IP-адрес точки назначения находится не в этой сети, пакет перенаправляется в шлюз узла по умолчанию.
Как работает битовая операция
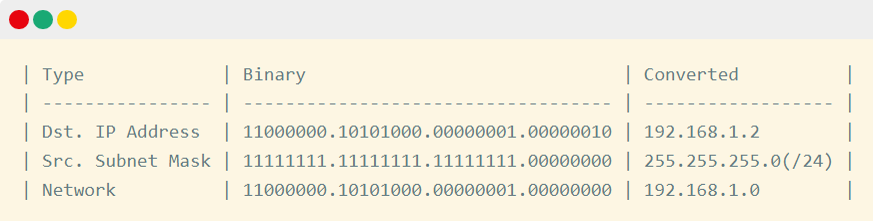
Определяя, куда отправить пакет, узел источника должен выполнить битовую операцию. Онатакже известна как ANDing. Вот что выводит битовая операция AND в качестве обновителя:

Любой результат, кроме 1 и 1, считается false. Если у исходного узла IP-адрес 192.168.1.1 с маской подсети /24, а у точки назначения IP-адрес 172.16.1.1/16, битовая операция AND подтвердит, что они действительно расположены в разных сетях. То есть IP-адрес точки назначения расположен не в той же сети, что источник пакета, поэтому пакет нужно отправить через шлюз по умолчанию.
Чтобы выполнить операцию AND, нужно начать с 32-битных адресов в binary. Сначала давайте выясним сети IP-адресов источника и точки назначения.

Для битовой операции нужно сравнить IP-адрес точки назначения с подсетью источника на узле, с которого поступил пакет.

Как видно, сеть ANDed показывает 172.16.1.0, и это значение отличается от 192.168.1.0 — сети из узла источника. Таким образом мы подтверждаем, что IP-адреса источника и точки назначения находятся не в одной и той же сети.
Например, если IP-адрес точки назначения — 192.168.1.2, то есть относится к той же подсети, что и IP-адрес отправителя, операция AND выводит в результатах локальную сеть узла.
После сравнения, выполненного битовой операцией, ARP ищет в своей таблице поиска MAC-адрес шлюза по умолчанию. Если он находит нужную запись, то сразу же отправляет пакет. В противном случае он сначала выполняет трансляцию, чтобы определить MAC-адрес шлюза.
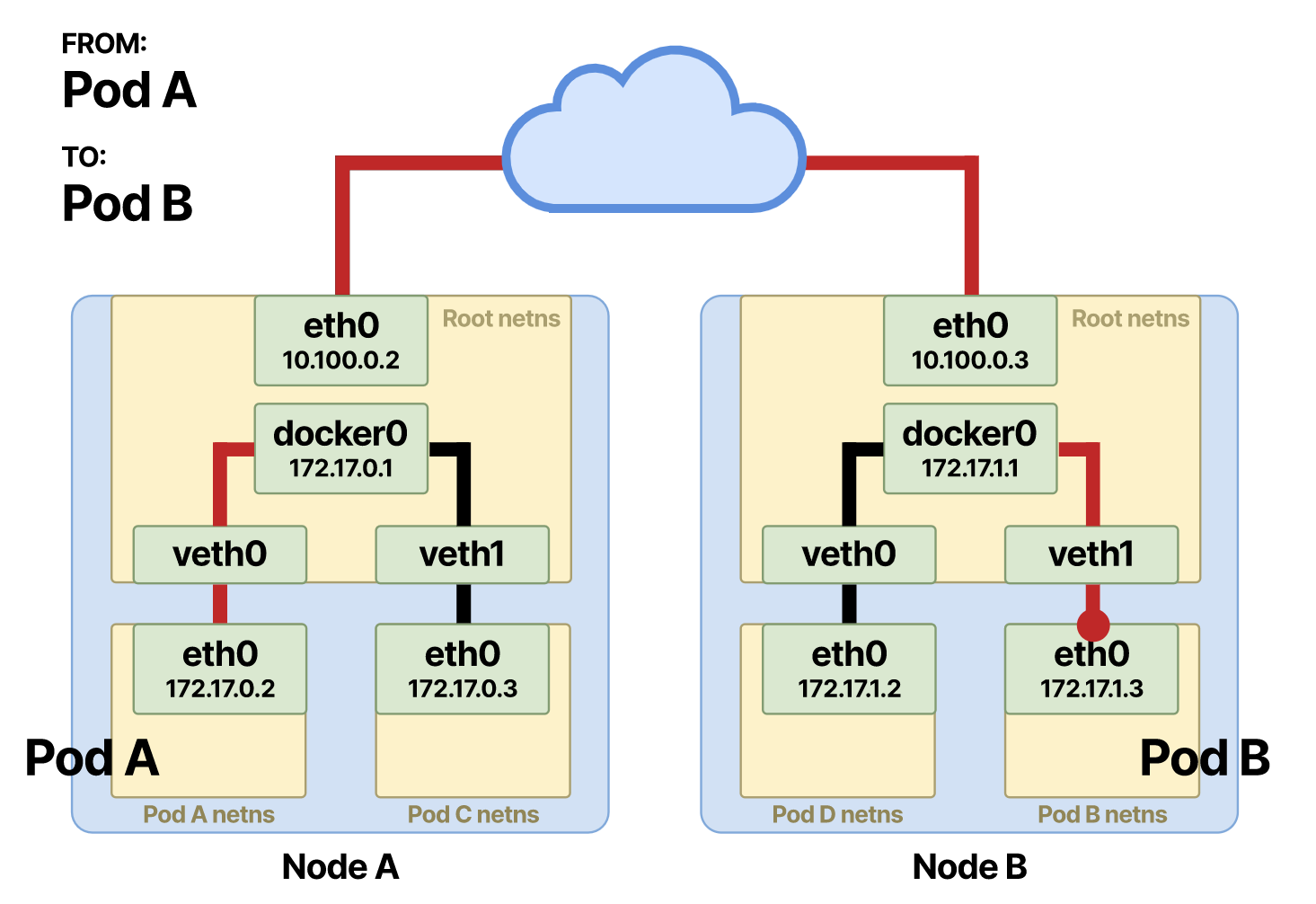
Теперь пакет отправляется интерфейсу другого узла по умолчанию. Назовем его узел B:

В обратном порядке: теперь пакет находится в корневом пространстве имен узла B и направляется на мост, где снова будет выполнено ARP-сопоставление.
Ответ получает MAC-адрес интерфейса, который соединяет под B.

На этот раз мост направляет фрейм через устройство veth пода B, и тот поступает в под B в его собственном пространстве имен.
Вы уже знаете, как трафик проходит между подами. Теперь давайте выясним, как эту же задачу решает CNI.
Container Network Interface — CNI
Container Network Interface (CNI) отвечает за сети в текущем узле.

CNI можно воспринимать как набор правил, которым должен следовать сетевой плагин, чтобы удовлетворять некоторым требованиям к сети в Kubernetes. Однако CNI не связан только с Kubernetes или с конкретным сетевым плагином, можно использовать любой интерфейс:
Все они реализуют один и тот же стандарт CNI, без которого приходится вручную:
- создать интерфейсы;
- создать пары veth;
- настроить сеть пространства имен;
- настроить статические маршруты;
- настроить Ethernet-мост;
- назначить IP-адреса;
- создать правила NAT;
И еще много моментов, для которых придется поднапрячься, не говоря уже об удалении или корректировке всего вышеописанного, если под нужно удалить или перезапустить.
CNI должен поддерживать четыре разные операции:
-
ADD — добавляет контейнер к сети;
-
DEL — удаляет контейнер из сети;
-
CHECK — выводит ошибку, если возникает проблема с сетью контейнера;
- VERSION — отображает версию плагина.
Давайте посмотрим, как это работает на практике. Когда под назначают конкретному узлу, сам kubelet не инициализирует сетевое соединение, а передает эту задачу CNI.
Можно перейти в /etc/cni/net.d на узле и проверить актуальный файл конфигурации CNI:
cat 10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"datastore_type": "kubernetes",
"mtu": 0,
"nodename_file_optional": false,
"log_level": "Info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": { "type": "calico-ipam", "assign_ipv4" : "true", "assign_ipv6" : "false"},
"container_settings": {
"allow_ip_forwarding": false
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"k8s_api_root":"https://10.96.0.1:443",
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
},
{"type": "portmap", "snat": true, "capabilities": {"portMappings": true}}
]
}
Для настройки сети каждый плагин CNI использует конфигурацию разных типов. Например, для соединения между подами Calico использует сеть третьего уровня в паре с протоколом маршрутизации BGP.
Cilium настраивает оверлейную сеть с eBPF на уровнях 3 — 7. Наряду с Calico Cilium поддерживает настройку сетевых политик для ограничения трафика.
Так что же использовать? Зависит от обстоятельств. В основном есть две группы CNI. К первой относятся интерфейсы, использующие базовую настройку сети (которую еще называют однородной сетью) и назначающие IP-адреса подам из пула IP-адресов кластера. Такой подход может оказаться проблемным — ведь можно быстро израсходовать все доступные IP-адреса.
Другой подход — использовать оверлейные сети. В самом общем виде оверлейная сеть — это дополнительная сеть поверх основной (несущей) сети. Она инкапсулирует любой пакет, поступающий из несущей сети и предназначенный для пода на другом узле. Популярная технология оверлейных сетей — VXLAN, с помощью которой можно туннелировать домены L2 по сети L3.
Так что же лучше? Нет правильного ответа на все случаи жизни, — решение обычно зависит от ваших требований.
Вы создаете большой кластер с десятками тысяч узлов? В этом случае, возможно, лучше создать оверлейную сеть.
Предпочитаете простоту настройки и не хотите затеряться во вложенных сетях при инспектировании сетевого трафика? Вам больше подойдет однородная сеть.
CNI мы уже изучили. Теперь давайте посмотрим, как происходит взаимодействие между подом и службой.
Инспектирование трафика между подом и службой
В силу динамической природы подов в среде Kubernetes им не присваиваются статические IP-адреса. Они эфемерны. Каждый раз после создания или удаления пода IP-адрес меняется.
Эта проблема решается с помощью службы, которая обеспечивает стабильный механизм соединения с набором подов.

По умолчанию при создании службы в Kubernetes ей назначается зарезервированный виртуальный IP-адрес. Таким образом с помощью селекторов можно связать службу с целевыми подами. Что происходит, если удалить один под и добавить новый? Виртуальный IP-адрес службы остается статичным и не меняется. Однако трафик поступает на недавно созданные поды — без необходимости в каком-либо вмешательстве. Иными словами, службы в Kubernetes похожи на балансировщики нагрузок.
Но как они работают?
Перехват и переписывание трафика с помощью Netfilter и iptables
Служба в Kubernetes строится на двух компонентах ядра Linux:
Netfilter — это фреймворк, позволяющий настраивать фильтрацию пакетов, создавать правила преобразования NAT или портов и управлять потоком трафика в сети.
Кроме того, он не допускает нежелательные соединения со службами. Iptables, с другой стороны, — это утилита пользовательского пространства, с помощью которой можно настроить правила фильтрации IP-пакетов в брандмауэре ядра Linux.
iptables реализуются как разные модули Netfilter. С помощью CLI iptables можно на лету менять правила фильтрации и вставлять их в точки перехвата netfilters. Фильтры организуются в разных таблицах, которые содержат цепочки обработки пакетов сетевого трафика. Для каждого протокола используются разные модули ядра и программы.
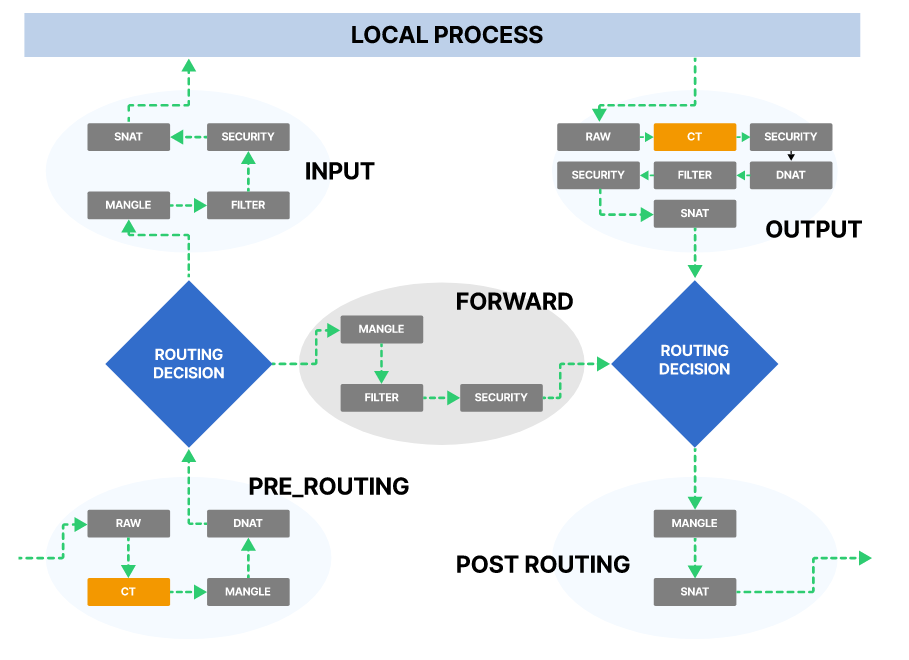
Когда мы говорим об iptables, обычно подразумевается, что он используется для IPv4. CLI для правил IPv6 называется ip6tables. У iptables есть пять типов цепочек, каждая из них имеет прямое соответствие с перехватом Netfilter. В терминах iptables это:
- PRE_ROUTING
- INPUT
- FORWARD
- OUTPUT
- POST_ROUTING
и они соответствуют следующим перехватам в Netfilter:
- NF_IP_PRE_ROUTING
- NF_IP_LOCAL_IN
- NF_IP_FORWARD
- NF_IP_LOCAL_OUT
- NF_IP_POST_ROUTING
Когда приходит пакет (и с учетом того, на каком он этапе), в Netfilter запускается перехват, который применяет тот или иной фильтр iptables.
Все это очень сложно, но поэтому мы и используем Kubernetes: все вышеперечисленное абстрагируется через использование служб, и простым определением YAML эти правила задаются автоматически. Если вам интересно взглянуть на правила iptables, можно подключиться к узлу и выполнить команду:
iptables-save
А еще можно использовать этот инструмент для визуализации цепочек iptables на узле. Пример схемы с визуализированными цепочками iptables, взятый с узла GKE:

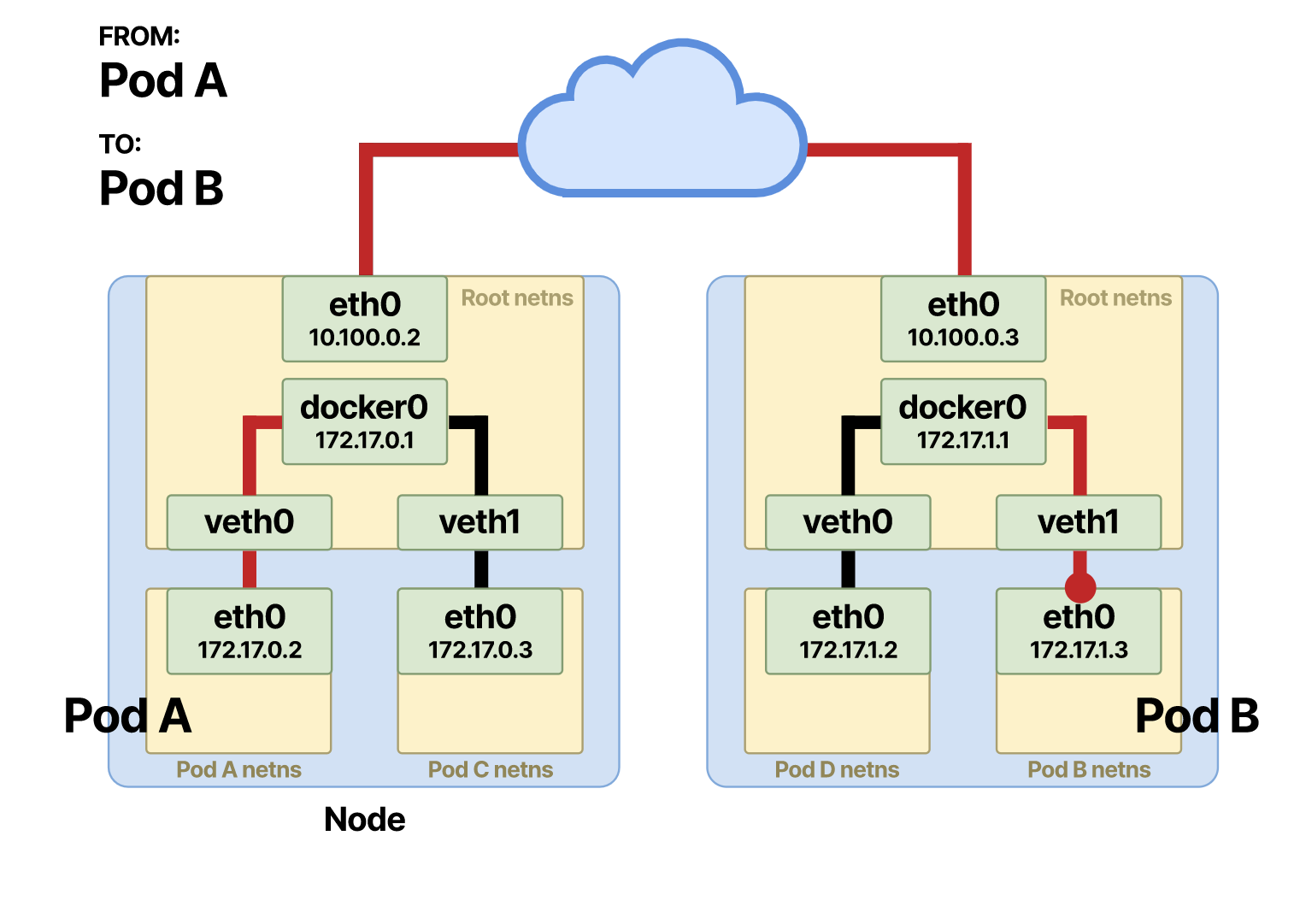
Помните, что настроенные правила могут исчисляться сотнями. Только представьте, каково создавать их вручную! Я объяснил, как взаимодействуют поды, если они находятся на одном и том же или на разных узлах. При взаимодействии пода со службой первая половина действий ничем не отличается от взаимодействия на уровне подов.

Когда под A направляет запрос и хочет обратиться к поду B, который в данном случае «прячется» за службой, то на полпути происходят дополнительные изменения. Исходный запрос выходит через интерфейс
eth0 в пространстве имен пода A. Отсюда он проходит пару veth и попадает на Ethernet-мост корневого пространства имен. С моста пакет сразу же перенаправляется через шлюз по умолчанию.Как и в случае взаимодействия между подами, хост сравнивает с помощью битовой операции, и, поскольку vIP службы не является частью CIDR-узла, пакет сразу же направляется через шлюз по умолчанию. Тот же ARP-запрос выполняется для поиска MAC-адреса шлюза по умолчанию, если он не включен в таблицу поиска.
И тут происходит чудо. Перед тем как пакет проходит процесс маршрутизации узла, запускается перехват Netfilter NF_IP_PRE_ROUTING и применяется правило iptables. Правило изменяет DNAT и переписывает IP-адрес точки назначения пакета пода A.
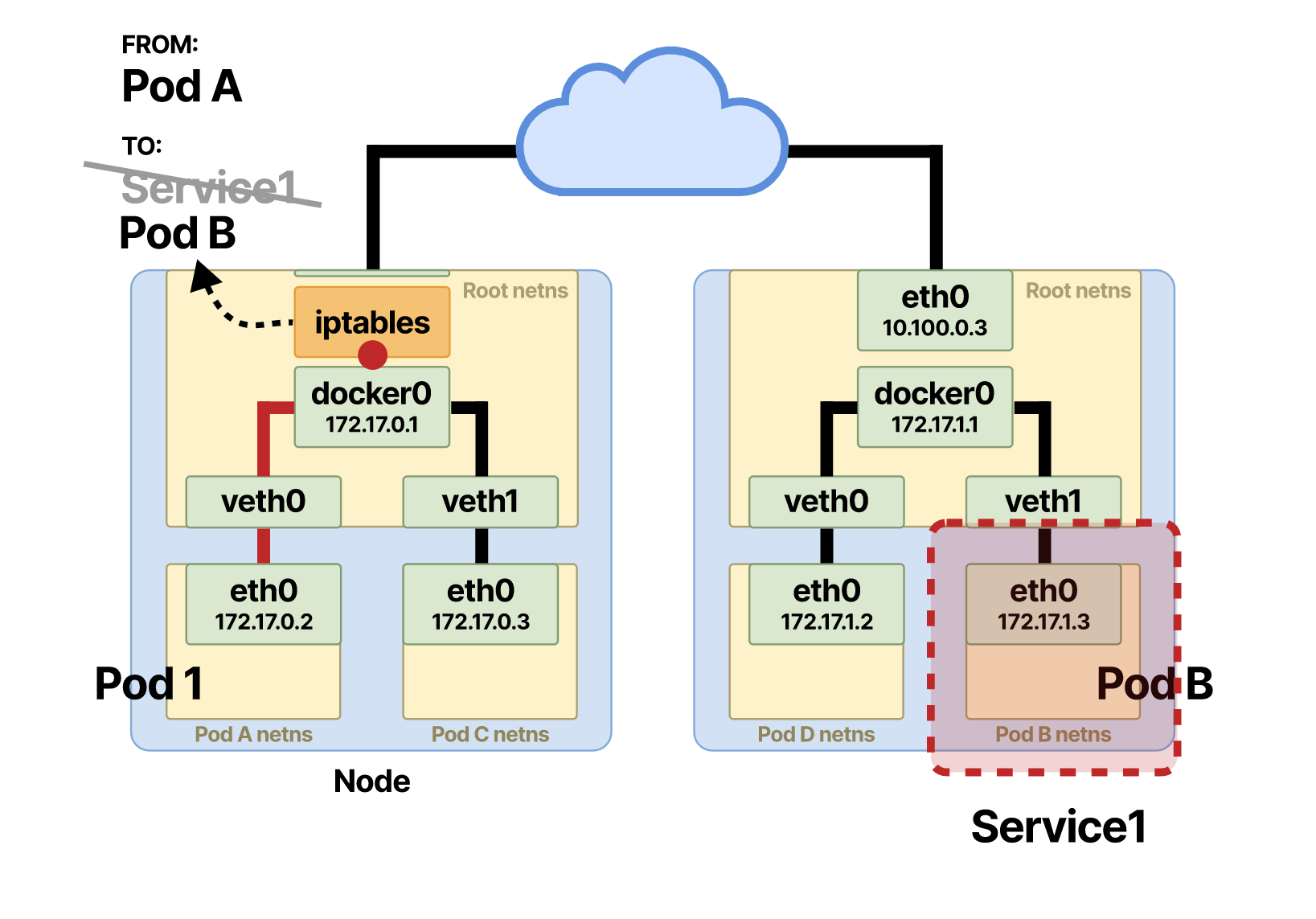
vIP-адрес точки назначения предыдущей службы переписывается на IP-адрес пода B. После этого маршрутизация ничем не отличается от непосредственного взаимодействия на уровне подов.
Но в ходе этого взаимодействия используется еще одна функция для отслеживание соединений— ее называют conntrack. Conntrack ассоциирует пакет с соединением и отслеживает его происхождение, когда под B отправляет ответ.
NAT активно использует conntrack в работе. Без отслеживания соединений было бы непонятно, куда отправлять пакеты с ответом. При использовании conntrack, обратный путь пакетов легко настроить с помощью того же изменения NAT источника или точки назначения. Вторая половина действий теперь происходит в обратном порядке. Под B получил и обработал запрос и теперь отправляет данные обратно поду A.
А что происходит теперь?
Инспектирование ответов от служб
Теперь под B отправляет ответ, указывая свой IP-адрес как источник, а IP-адрес пода A — как точку назначения. Когда пакет достигает интерфейса на узле, на котором расположен под A, происходит другая NAT:

На этот раз с помощью conntrack меняется IP-адрес источника, правило iptables выполняет SNAT и IP-адрес источника в поде B меняется на vIP исходной службы.

Для пода A дела обстоят так, будто бы входящий ответ поступил ему от службы, а не от пода B.

Других отличий нет. После SNAT пакет достигает Ethernet-моста в корневом пространстве имен и направляется на под A через пару
veth.Kubernetes aaS от VK Cloud можно попробовать бесплатно. Мы начисляем пользователям при регистрации 3 000 бонусных рублей и будем рады, если вы попробуете сервис и дадите обратную связь.