
Привет! Меня зовут Анвар, я аналитик данных RnD-лаборатории. Перед нашей исследовательской группой стоял вопрос проработки внедрения ИИ в сервис фильтрации веб-контента SWG-решения Solar webProxy. В этом посте я расскажу, зачем вообще нужен анализ веб-контента, почему из многообразия NLP-моделей для автоматизации решения этой задачи мы выбрали модель-трансформер. Кратко объясню, как с помощью математики взвесить смысловые отношения между словами. И конечно, опишу, как мы приземлили веб-фильтрацию в продукт.
Введение в веб-безопасность. Зачем анализировать содержание сайтов?
Посещая различные сайты, можно с легкостью угодить в сети запрещенного контента, попасться на уловку мошенников или поймать опасный вирус. В некоторых случаях фильтровать контент просто необходимо, например, когда мы говорим о защите детей в интернете.
Как понять, что сайт является фишинговым или мошенническим, как оградить студентов, школьников, сотрудников компании от посещения запрещенных сайтов или сайтов с нецензурным содержанием?

Безусловно, работу по анализу содержимого сайтов можно проделать вручную. И это может быть оправдано, когда речь о малом стеке задач такого типа. Не составит большого труда проверить, к примеру, 1000 сайтов. Но что делать, если перед нами стоит задача ежедневной проверки нескольких тысяч или десятков тысяч сайтов? А именно такая задача стоит перед продуктом Solar webProxy.
Очевидно, что о ручной проверке не может идти речи — нужен способ автоматизированного выполнения этой задачи.
Итак, можно разработать компьютерную программу с некоторым алгоритмом, и она будет самостоятельно анализировать текстовое содержание сайтов. На основании триггера на определенные ключевые слова она сможет определять, к примеру, признаки обмана, мошенничества. Так, в тексте могут содержаться слова «ставки», «большие выигрыши», «испытай удачу», «стань богатым» и т.п. На основании этих слов или по общему числу их вхождений в текст можно сделать вывод, что такой сайт с высокой степенью вероятности является мошенническим либо по крайней мере вредоносным, поскольку может нанести материальный ущерб. То есть, сформировав некоторый корпус слов-триггеров, вполне возможно классифицировать сайты по их текстовому содержанию.
На первый взгляд, выглядит неплохо, но уже здесь мы сталкиваемся с проблемой. Сайт может содержать определенное количество слов-триггеров, но совсем не обязательно, что он будет относиться к той категории, которая определена на их основании. Например, по контенту о вреде алкоголя и курения на основании ключевых слов «алкоголь» и «курение» программа наверняка определит сайт, как с неразрешенным контентом. Хотя из контекста мы понимаем, что содержание этой страницы веб-сайта, напротив, посвящено здоровому образу жизни.
Примерно в этот момент в игру вступает понятие контекста. С его помощью мы можем понять содержимое сайта и правильно определить его категорию. Для понимания контекста содержимого сайтов успешно применяются некоторые модели искусственных нейронных сетей, об одной из которых далее пойдет речь.
Коротко об NLP и алгоритмах обработки естественного языка
Итак, перед нами стоит задача автоматизировать процесс определения категории сайта по его текстовому содержанию. То есть, исходя из смысла отображенного на странице сайта и некоторого объема текста, понять главный его смысл, о чем этот текст.
Задача распознавания текста относится к сфере обработки естественного языка или NLP (natural language processing). NLP — направление искусственного интеллекта, нацеленное на обработку и анализ данных на естественном языке и обучение машин взаимодействию с людьми [1]. Цель NLP – научить компьютер понимать нашу разговорную и письменную речь [2].

Компьютеры понимают только числовые данные, поэтому текст должен быть определенным образом приведен в этот формат. В теории можно закодировать слова на основании частоты их вхождения в текст либо просто сформировать некоторый словарь, в котором сопоставить слова или буквы с числовыми значениями.
Но как компьютер сможет понять смысл текста, если слова и смысловое наполнение имеют неоднозначную и нелинейную взаимосвязь? Подобная информация очень плохо поддается представлению в цифровом виде. Кроме этого, каждый язык имеет свою собственную грамматику, синтаксис и словарный запас [2].
Но если слова в предложениях трансформировать в числовой вектор и за меру взять расстояние между векторами, то будет проще обобщить влияние одного слова на другое. Такой подход называется методом вложения слов (word embedding).

Суть подхода в том, что слова со схожим значением близки в векторном пространстве, поэтому можно определять значение слова по его «соседям». Над этими векторами можно производить арифметические действия и определять семантическое подобие слов, предложений и даже целых документов, а затем использовать эту информацию, чтобы выяснить, например, какой теме посвящен текст [1].
Используя данные, состоящие из таких векторов, мы можем применять различные методы Machine Learning. И поскольку искусственные нейронные сети лучшим образом справляются с векторно-матричными вычислениями, то выбор в их пользу становиться очевидным. Вцелом, нейронки более эффективны в задачах обработки естественного языка, по сравнению с иными методами машинного обучения [3].
Об NLP-нейронках
Искусственная нейронная сеть — это математическая модель, а также ее программное или аппаратное воплощение, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Искусственная нейросеть состоит из обрабатывающих элементов, подобных нейронам в мозге человека, которые взаимодействуют между собой путем отправки сигналов в соседние узлы и получения встречных сигналов [2].
Существует очень большое многообразие моделей искусственных нейронных сетей. Современные модели представляют собой так называемые глубокие модели. Они отличаются между собой количеством внутренних слоев и способом работы с данными, если говорить в общих чертах, не вдаваясь в сложные математические объяснения.
Как правило, чем сложнее модель нейронной сети, тем более сложные задачи она способна решать, но если мы решаем какую-то простую задачу, то нет смысла применять сложный инструмент. Понимание смысла текста отнюдь не является простой задачей. И в ее решении наилучшие метрики точности были достигнуты рекуррентными нейронными сетями, LSTM (сети с долгой краткосрочной памятью). Позже свое превосходство в этой нише обрели NLP-модели-трансформеры.
Описание упомянутых рекуррентных нейросетей (RNN), LSTM и GRU выходит за рамки темы статьи. Тем не менее для тех, кому интересно, расскажем в общих чертах об указанных моделях в спойлере.
Hidden text
Архитектура RNN позволяет модели поддерживать порядок слов в предложении и выявлять долгосрочные зависимости, что очень подходит для обработки последовательных входных данных. Однако RNN способны фиксировать зависимости только в одном направлении языка. То есть не учитывается влияние предшествующего слова на следующее за ним. Кроме этого, RNN не очень хороши в захвате долгосрочных зависимостей.

Рекуррентные нейронные сети добавляют память к искусственным нейронным сетям, но реализуемая память получается короткой — на каждом шаге обучения информация в памяти смешивается с новой и через несколько итераций полностью перезаписывается.
LSTM избегают проблемы долговременной зависимости, запоминая значения как на короткие, так и на длинные промежутки времени. Это объясняется тем, что LSTM не использует функцию активации внутри своих рекуррентных компонентов. Таким образом, хранимое значение не размывается во времени.

Разновидности LSTM часто используются в машинном переводе и в задачах генерирования текстов на естественном языке.
Перед нашей исследовательской группой стоял вопрос проработки возможности внедрения ИИ в сервис фильтрации веб-контента SWG-решения Solar webProxy. В результате перебора эмпирическим путем мы остановились на трансформере BERT, NLP-модели, которая, как мы потом убедились, оказалась очень удачной. По точности классификации текстового содержания веб-сайтов она превзошла все другие протестированные нами модели и алгоритмы Machine Learning.
Прежде чем использовать такой мощный и в то же время сложный инструмент, наша команда протестировала и более простые NLP-методы машинного обучения, в том числе «наивный байесовский классификатор», алгоритмы, использующие bag-of-words («мешок слов» — метод представления слов) и tf-idf (метрика определения частоты вхождения слов), а также простейшие модели нейронных сетей, состоящие из небольшого количества скрытых слоев. По объективным причинам, речь о которых пойдет дальше, данные методы и алгоритмы даже близко не приблизились к уровню точности BERT.
Знакомьтесь, BERT
— И за что тебя взяли?
— Я купил машину, а она оказалась роботом. Кто знал… (с) К/ф Трансформеры.
BERT, или Bidirectional Encoder Representations from Transformers, — нейросетевая модель-трансформер от Google, на которой сегодня строится большинство инструментов автоматической обработки языка.

Релиз BERT в 2018 году стал некоторой переломной точкой в развитии NLP-моделей. Его появлению предшествовал ряд недавних разработок в области обработки естественного языка (BERT, ELMO и Ко в картинках — как в NLP пришло трансферное обучение): Semi-supervised Sequence learning (Andrew Dai и Quoc Le), ELMo (Matthew Peters и исследователи из AI2 и UW CSE), ULMFiT (Jeremy Howard и Sebastian Ruder), OpenAI Transformer (исследователи OpenAI Radford, Narasimhan, Salimans, и Sutskever) и Трансформер (Vaswani et al).
Итак, далее речь пойдет о трансформерах, но не о тех, о которых вы подумали!
Трансформеры в машинном обучении — это семейство архитектур нейронных сетей, общая идея которых основана на так называемом «самовнимании» (self-attention). Этот алгоритм математически взвешивает отношения между каждым элементом или словом с другими словами во входной последовательности.
Разберем на примере: «Черепахе потребовалось очень много времени, чтобы перейти дорогу, потому что она очень медленная».
Здесь нам с первого взгляда видно, что последняя часть предложения «... она очень медленная» относится к черепахе, а не к дороге. Однако алгоритм Self-attention не сразу поймет смысл предложения. По мере того как алгоритм последовательно просматривает каждое слово в предложении, он ищет для себя «подсказки» (путем взвешивания слов), которые могут помочь в лучшем кодировании слова.

Более ранние архитектуры, чтобы обучиться предсказывали, какое слово, вероятнее всего, будет стоять следующим, учитывая все слова до него. На решение нейросети влияли только слова слева (так работает, например, трансформер от OpenAI). Такие нейросети называются однонаправленными.
Человек так не делает, обычно мы смотрим на все предложение разом. И чтобы сделать алгоритм более похожим на это, придумали двунаправленные нейронки. Здесь две сети работают параллельно, одна предсказывает слова слева направо, другая — справа налево. Потом результаты сетей объединяется.
По своей сути BERT — это обученный стек энкодеров Трансформера. Новшество заключается в предобучении модели на «маскированной языковой модели». Суть задачи —предсказать слово не в конце предложения, а в разных частях между словами. Маскированной модель называется потому, что искомый токен заменяется токеном "MASK".

Приведенная схема работы позволяет учитывать все части фразы, а не только слова слева или справа.
В открытом доступе имеются различные предобученные вариации BERT (на различных языках) и любой желающий может использовать их в своей разработке.
Категоризация сайтов с BERT'ом
Для работы мы взяли предобученную модель bert-base-multilingual-cased. Предобученность модели означает то, что она подготовлена ее авторами для работы "из-коробки" - модель заранее обучена для общей / универсальной задачи и у нее уже есть веса. Как правило, такое обучение требует больших вычислительных мощностей и может занимать продолжительное время (недели, месяцы, если конечно у Вас нет крутого железа). То есть, "нельзя просто так взять и" обучить с нуля сложную модель искусственной нейронной сети. Для этого мы должны обладать, например, видеокарточками Titan от Nvidia с немалым числом производительных ядер.
Разработкой и обучением модели BERT занималась целая группа исследователей Google AI Language на многомиллионном наборе слов на разных языках (более 100). Обучение модели заняло 4 дня на 64-х матричных процессорах (TPU's). И они обучили ее для 11 наиболее распространенных языковых задач, таких как анализ настроений и распознавание именованных объектов. Такую предобученную модель можно далее использовать в задачах, имеющих свою специфику, но при этом скорее всего потребуется дополнительное дообучение на конкретном наборе с данными. Уже для такого дообучения вовсе не требуются значительные вычислительные мощности и вполне хватит даже обычного домашнего ПК со средним GPU.
Таким образом, БЕРТ в стоке обучен предсказывать слова в предложениях, а значит, у него есть то, что нам нужно — способность работать с предложениями, словами и контекстом и это можно применить для категоризации текста веб-сайтов. И мы дообучили BERT распознавать текстовое содержимое сайтов по 63 категориям (медицина, здоровье, видео, интернет-магазины, юмористические сайты, эротика, оружие, секты, криминал и пр.).
Для дообучения был сформирован собственный набор данных с примерами веб-контента. Как известно, от качества обучающей выборки зависит чуть ли не половина успешности модели, поэтому этапу формирования датасета уделялось много внимания.
Поскольку наш ИИ должен понимать категорию сайта по его текстовому содержанию, каждый обучающий пример в датасете должен быть представлен как текст из HTML-страницы. Для сбора таких данных мы написали несколько программ на языке Python.
Для доступа к сайтам с запросами использовали библиотеку requests. С помощью метода get «стучимся» к сайту и если все «ok», то есть нам вернулся ответ со статусом «200», мы можем работать с полученными данными.
response = requests.get(url=current_url, timeout=10)
Полученные данные представляют собой текст, включенный между HTML-тегами, и наша следующая задача — получить текст из определенных тегов. Для этого используем всем известную библиотеку BeautifulSoup. С помощью функций find, find_all можем найти определенные теги и получить из них данные в виде текста. Сам этот процесс называется парсингом HTML-страниц.
Веб-страницы могут содержать рекламу, значки, спецсимволы и прочее, что мешает корректному анализу текста. Поэтому каждый полученный в результате парсинга текст дополнительно очищается с помощью регулярных выражений и методов "match", "search" и "sub" из python-библиотеки "re". Сам процесс очистки заключается в том, что мы сначала составляем регулярное выражение, например, исключающее из текста все числовые значения, оставляя только буквенные. Затем, применяя метод "sub", удаляем все числа из текста, подменяя их пробелом. Если вы не знаете, что такое регулярные выражения, рекомендую посмотреть эту статью.
Вуаля! Получаем очищенные данные, которые добавляем в датасет.
Как показали тесты, нам удалось добиться достаточно высоких результатов в категоризации. По 43 категориям из 63 точность распознавания варьируется в диапазоне 93-95%. И на этом мы не останавливаемся, а по мере накопления данных формируем дополнительные обучающие выборки, которые эпизодически используем для новых дообучений модели. Все это для повышения точности по тем категориям веб-сайтов, которые этого требуют. Кроме этого, с течением времени меняется и сам язык, в обороте речи появляются новые слова и выражения. Какие-то слова со временем понимаются по-разному. Все это требует нового дообучения НЛП-моделей, теперь уже в целях адаптации.
Знакомьтесь, категоризатор веб-сайтов Smart-Cat
Перед тем как брать контент с сайта, чтобы его категоризировать, неплохо было бы узнать, не является ли данный сайт вирусным, мошенническим или запрещенным Роскомнадзором. Поэтому я разработал программу — модуль для категоризатора, который проводит сверку с ежедневно обновляемой базой данных вирусных, запрещенных и мошеннических сайтов. Эту базу данных мы сформировали из открытых источников данных о вирусных сайтах (наподобие VirusTotal), мошеннических сайтов (в интернете имеются общедоступные ресурсы, предоставляющие такие списки), а также реестра Роскомнадзора. Если URL-адрес совпадет с записью в этой базе, категоризатор сделает отметку, что сайт является, к примеру, запрещенным на основании реестра РКН.
Кроме этого, непродолжительный срок существования сайта может вызывать определенные подозрения. Зачастую в таких случаях сайт оказывается вредоносным или мошенническим. Поэтому мы добавили еще один модуль проверки, который с помощью специальной Python-библиотеки «whois.api» проверяет время жизни сайта. В качестве контрольного порога мы выбрали шесть месяцев. Если сайт существует менее этого срока, программа поставит отметку о необходимости «обратить внимание» на этот факт.
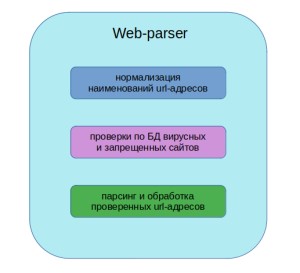
В промышленных масштабах объем URL-адресов для проверки и категоризации может достигать сотен тысяч или даже миллионов. При этом среди них могут быть повторяющиеся адреса, IP-адреса, непригодные для парсера. Для общего понимания того, в чем разница между IP-адресом и URL читайте данный материал. Для доступа к сайтам используются URL-адреса.
Кроме этого, URL может быть представлен тремя и более поддоменными уровнями. Как правило, такие URL недоступны, к ним практически невозможно подключиться (в основном такие адреса принадлежат сайтам, где требуется авторизация, либо это какие-либо специальные технические ресурсы). Для обработки таких моментов в категоризатор мы заложили функционал, который сокращает объем однотипных адресов (принадлежащих, к примеру, одному и тому же домену), удаляет IP-адреса, дубли и абракадабру, которая также встречается в больших списках URL-адресов. Здесь применяется та же схема, что и при обработке спарсенного веб-контента (см. выше).
Таким образом, пользователь передает в категоризатор список с URL-адресами. Smart-Cat на первом этапе проводит их предобработку. Затем выполняется сверка с базами данных. Если будет обнаружено совпадение, Smart-Cat сделает об этом отметку в результатах. И только после того, как прошли все проверки и чистки, оставшиеся URL переходят в модуль-парсер. Получившийся в результате контент передается BERT, который классифицирует его по категориям. На выходе мы имеем таблицу с детальной информацией по каждому URL-адресу.
Знакомьтесь, BERT-bot
Для удобства работы с категоризатором Smart-Cat мы создали специальный Telegram-бот. Он умеет проводить проверки по базам запрещенных, вирусных и мошеннических сайтов и затем категорировать сайты по 63 классам. Бота зовут BERT-bot.

Для запуска Берта отправляем ему в Telegram список с URL-адресами в виде обычного текстового файла (.txt) и ждем результат. После своей работы BERT-bot отправит CSV-таблицу. В ней будут указаны результаты проверок по базе данных, итоги категоризации, а также сведения по URL-адресам, по которым не получилось установить соединение либо возникли проблемы с получением от них данных. Доступ к боту есть только у сотрудников компании.
Заключение
Автоматизация процесса фильтрации сайтов по содержанию может быть реализована как с использованием методов машинного обучения, так и без них. Алгоритмы Machine Learning имеют свои нюансы и сложности в реализации. Поэтому там, где можно обойтись более легким решением, например простым сопоставлением данных между собой, лучше пойти в этом направлении.
Использование ИИ представляется более «дорогостоящим» решением, и к нему лучше прибегнуть при действительно сложных задачах. Так, мы, решая задачу фильтрации веб-сайтов по их текстовому содержанию, в первую очередь, проводим очистку данных и сверку с БД. И только потом, когда максимально проработан первоначальный массив с URL-адресами для проверки, наступает очередь работы искусственной нейронной сети. Она уже работает только с теми веб-сайтами, по которым на предыдущем этапе не были получены данные о категориях. В нашем случае мы реализовали комбинированное решение.
Предобученные языковые модели искусственных нейронных сетей, такие как BERT, демонстрируют наилучшую точность в классификации веб-сайтов по их текстовому содержанию. Но, как я уже сказал ранее, такие модели могут применяться не только в задачах классификации текста. При желании с помощью того же BERT'а можно реализовать «умного» переводчика, голосового ассистента (как Джарвиса у Тони Старка). При этом модель можно дообучить для работы в специфической сфере.
Системы с искусственным интеллектом в некоторых отраслях производства могут полностью заменить труд человека и стать, например, надежным инструментом в обеспечении информационной безопасности.
Если вы решаете задачи по автоматизации с помощью методов машинного обучения, расскажите о своем опыте в комментариях. Буду рад обменяться опытом :)
Автор: Анвар Баширов, аналитик данных RnD-лаборатории Центра продуктов Dozor
Источники литературы и ссылки
Васильев Ю. Обработка естественного языка. Python и Spacy на практике // Спб.: Питер, 2021. - 256 с.
Обработка естественного языка с TensorFlow / пер. с англ. В.С. Яценкова. - М.: ДМК Пресс, 2020. - 382 с.
Нейросетевые методы в обработке естественного языка / пер. с англ. А.А. Слинкина. - ДМК Пресс, 2019. - 282 с.