
Мне всегда было интересно (и не только мне) есть ли смысл запуска 1С в диске из оперативной памяти, потому что если посмотреть на графики скорости чтения различных типов накопителей, то преимущества очевидны:

Виртуальный диск из ОЗУ демонстрирует огромное преимущество над любым типом дисков, даже если бы мы использовали SSD с поддержкой NVMe PCI-express v4 (предлагаю дальше для упрощения просто указывать NVMe x3 для SSD на шине версии 3 и NVMe x4 с PCI-express версии 4) мы бы не смогли получить особого преимущества перед диском из оперативной памяти, так как это позволило бы только увеличить скорость записи больших файлов с 3521 Мб/сек до 5000, что все равно далеко от скоростей RAMDisk, но никак не повлияло бы на скорости мелких файлов и секторов, а в нашем случае это имеет важное значение. Кажется, что тестирование проводить смысла нет – исходя из графика сразу понятно кто аутсайдер, и кто победитель: заранее скажу что в целом – да, но не везде и не всегда, а жесткие диски списывать со счетов рано.
В связи с этим я решил сравнить скорость быстродействия 1C:Предприятие в различных способах управления информационной базой 1С: файловый вариант, MS SQL и POSTGRES. Тестирование проводилось поочередно на каждом из четырех накопителей. В качестве замера производительности применял два теста – перепроведение документов за одинаковый отрезок времени и формирование оборотной ведомости за 6 лет, различные синтетические тесты и «замеры производительности» не проводились ввиду того что они не всегда точно отображают реальную производительность.
В качестве тестового стенда применялся компьютер следующей конфигурации:
CPU |
AMD Ryzen R9 3900X (12 ядер, 24 потока, 3800МГц) |
RAM |
32 Гб DDR4 Kingston FURY 2666МГц (4*8ГБ) |
HDD |
1ТБ Seagate 1000DM003 |
SSD SATA |
500 Гб Samsung 870EVO |
SSD NVMe x3 |
500 Гб Samsung 970EVO |
OS |
MS Windows Server 2019 Standard |
1С:Предприятие |
Бухгалтерия для гос. Учреждений ПРОФ |
СУБД MS SQL |
2019 STANDARD |
СУБД POSTGRES SQL |
14.4-1.1C |
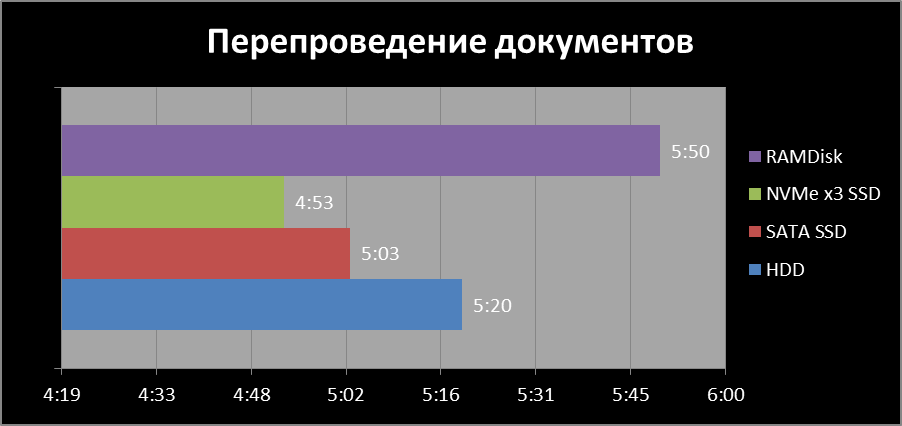
Тестирование начнём с самого простого способа управления информационной базой 1С:Предприятия – файловый (меньше – лучше, время в мин:сек):

То что жесткий диск оказался самым медленным способом обработки информации это ожидаемо, отставание SATA SSD от NVMe x3 составляет существенные 20%, а виртуальный диск из оперативной памяти хоть и самый быстрый, но разгромного преимущества перед NVMe x3 нет: выигрыш в скорости примерно 10%, несмотря на огромную разницу в скорости чтения и записи, что касается скорости в перепроведении документов ситуация уже не такая однозначная (меньше – лучше, время в мин:сек):

А вот и первый сюрприз: если с физическими накопителями всё закономерно, то в этот раз RAMDisk оказался самым медленным – я повторил тестирование три раза, но ничего не поменялось, возможно, проблема имеет общие корни с программными RAID массивами. Но при этом стоит обратить внимание, что здесь жесткий диск уже не кажется безнадежно устаревшим вариантом.
Теперь перейдём к тестированию варианта взаимодействия с информационной базой 1C:Предприятия через СУБД MS SQL 2019:

СУБД SQL от Microsoft показывает отличную оптимизацию обработки информации по сравнению с файловым вариантом, в целом можно сказать что все время формирования отчёта для SSD обоих типов и RAMDisk одинаково и лежит в пределах погрешности, но если жесткий диск справился почти в 5 раз быстрее (+500%), то для SSD прирост скорости составил 100% для NVMe x3 и 250% для SATA SSD. Прирост скорости для RAMDisk составил «скромные» 75%.

Здесь сохраняется логичное преимущество твердотельных накопителей над жестким диском, но диск из ОЗУ начинает демонстрировать недостатки программной эмуляции накопителя.
Чтобы получить результаты наиболее объективным, я решил проверить теорию влияния скорости на работу СУБД когда журналы пользователей и база данных хранятся на разных дисках, но это никак не повлияло на скорость формирования отчетов.
Теперь проверим быстродействие 1С:Предприятие с POSTGRES:

POSTGRES SQL показывает отличную масштабируемость в зависимости от типа диска и, что необычно, формирование отчёта с СУБД POSTGRES при разворачивании базы на жёстком диске оказывается быстрее в 1,5 раза по сравнению с СУБД от Microsoft. Но если смотреть на график относительно твердотельных накопителей (SSD), то, конечно, Microsoft SQL предпочтительнее. В случае с RAMDisk разницы нет.
Последний тест отлично показывает отсутствие целесообразности использования RAMDisk для размещения СУБД. Так как этот диск виртуальный и он создаётся посредством программного обеспечения, то наблюдается аналогия с программными и аппаратными RAID массивами: программные массивы обслуживаются вычислительными мощностями ЦП, стабильность и скорость работы целиком зависит от грамотности и правильности кода соответствующего программного обеспечения для создания диска из ОЗУ, аналогичная ситуация справедлива и для физических дисков: когда для создания RAID массивов применяется аппаратные средства, снимается с ЦП задачи по обслуживанию RAID, что положительно сказывается на общей производительности массива и отпадает зависимость от качества работы программного обеспечения сторонних разработчиков. В случае создания виртуального диска из оперативной памяти используется программное обеспечение, что накладывает определенные ограничения на работу данного диска, что и подтверждает тестирование – чёткой стабильности в производительности нет в отличие от физических накопителей. Но, как бы то ни было, последний тест в очередной раз подтверждает преимущество NVMe SSD накопителя перед другими типами дисков.
Проведенное тестирование показало преимущество СУБД MS SQL над POSTGRES и общее преимущество обоих типов СУБД над классическим способом работы 1С:Предприятие – файловым. Смысла использования RAMDisk нет от слова совсем – да, прирост в скорости в файловом варианте составляет примерно 12% от самого быстрого диска, но экономической целесообразности нет - в среднем 32 Гб ОЗУ DDR4 стоит 180$, а 500 Гб SSD NVMe x3 (в тестировании применялся SSD Samsung 500 Гб 970EVO) стоит 120$, разница в стоимости при пересчете Гб/$ составляет 5,6$ за гигабайт для ОЗУ и 0,24$ за гигабайт для SSD. Переплата в 23 раза (2300%) ради 12% производительности лишь в нескольких случаях смысла не имеет.
Отдельного внимания заслуживает СУБД POSTGRES SQL – в отличие от СУБД Microsoft она бесплатная, но в среднем увеличивает скорость работы с 1С в два раза, на мой взгляд неплохое предложение для недорогого (не забываем что необходимо для любого варианта использования SQL требуется приобретение лицензии на сервер 1С) но эффективного ускорения работы 1С:Предприятие. Что касается СУБД Microsoft SQL Server – это самый быстрый и эффективный способ обработки информации в 1С:Предприятие, да, он не бесплатный, но даёт прирост до 50% по сравнению с POSTGRES.
Что касается дисков, то, разумеется, SSD новейших форматов NVMe x3 (и x4) является наиболее предпочтительным вариантом - этот тип диска в связке с СУБД MS SQL даст наибольший прирост производительности, но если у вас стоит задача добиться значительного увеличения скорости работы 1С с минимальными затратами – можете смело использовать связку POSTGRES и старый добрый HDD.
В заключение, предлагаю ознакомиться с краткой таблицей сравнительного тестирования:
Тип работы |
Формирование оборотной ведомости |
Перепроведение документов |
Рейтинг производительности |
MS SQL + NVMe SSD |
0:18 |
2:40 |
1 |
MS SQL + SATA SSD |
0:19 |
3:02 |
2 |
MS SQL + RAMDisk |
0:20 |
3:29 |
3 |
POSTGRES + NVMe SSD |
0:27 |
4:53 |
4 |
POSTGRES + SATA SSD |
0:35 |
5:03 |
5 |
POSTGRES + RAMDisk |
0:19 |
5:50 |
6 |
MS SQL + HDD |
1:18 |
4:21 |
7 |
POSTGRES + HDD |
0:52 |
5:20 |
8 |
NVMe SSD |
0:39 |
10:52 |
9 |
RAMDisk |
0:35 |
12:55 |
10 |
SATA SSD |
0:48 |
11:50 |
11 |
HDD |
6:21 |
12:53 |
12 |
Комментарии (105)

sukharichev
20.10.2022 16:36Самого давно интересует этот вопрос, спасибо за статью. Но я не вижу очень существенного параметра (проглядел?) - размер базы и количество документов. Судя по скоростям, база какая-то микроскопическая. Вы уверены, что ваши данные не целиком влезали в кэш дисков и вы не измерили именно его?

schvii Автор
20.10.2022 17:25+1Размер базы - 6,5 Гб в файловом варианте, объем кэша LPDDR4 970EVO 512 мб, так что точно нет. Что касается по количеству документов, то 76440 за тестируемый интервал (6 лет)

edo1h
21.10.2022 01:07+1объем кэша LPDDR4 970EVO 512 мб
нет, память на ssd используется для хранения таблицы транслятора (ftl), а не для кэширования чтения.
зато операционная система использует всю свободную память для кэширования.BTW, кстати, не может оказаться, что снижение производительности в случае рамдиска было связано с уменьшением объёма доступной памяти?
76440 за тестируемый интервал (6 лет)
явно не хватает тестирования с серверным накопителем.
в синхронной записи (а СУБД на каждую транзакцию делает как минимум одну синхронную запись в wal) 970 evo показывает всего ≈500 iops
https://docs.google.com/spreadsheets/d/1E9-eXjzsKboiCCX-0u0r5fAjjufLKayaut_FOPxYZjc/edit?hl=en#gid=0не понимаю тяги к использованию десктопных накопителей под серверные задачи.
sukharichev
21.10.2022 10:26А я понимаю, потому что бюджет. Для подавляющего числа средних компаний с базами размером до 20 Гб никакого смысла в серверных накопителях нет. Да, у них выше надежность и скорость, но если у вас месяц закрывается за 20 минут и на обычных, то скорость серверных вам не нужна, а в смысле надежности проще за стоимость серверного докупить два таких же бытовых HDD на 8 или уже даже 16 Тб, и бэкапить туда базу и журнал почаще, да и все.
Мы себе такого позволить не можем у нас масштабы побольше, поэтому живем на серверных U.2 Oculink но в этом случае стоимость всей платформы (мат. плата, кабели, диски) возрастает настолько, что меньшему бизнесу такие затраты просто не потянуть, он может на десктопных ПК собрать на ту же цену кластер из 3 машин с SATA рейдами в каждой, и их скорости дадут возможность бэкапится каждые 5 минут.edo1h
21.10.2022 11:05смысле надежности проще за стоимость серверного докупить два таких же бытовых HDD на 8 или уже даже 16 Тб, и бэкапить туда базу и журнал почаще, да и все
вы как-то не так смотрите цены. открываю московский магазин, pm9a3 на 960 гигабайт стоит 17 тысяч рублей, это даже не в два раза дороже, чем обсуждаемый в этой статье 970 evo той же ёмкости.
U.2 Oculink но в этом случае стоимость всей платформы (мат. плата, кабели, диски) возрастает настолько
во-первых, серверные nvme бывают и в m.2 формате (именно о таком я и писал выше).
во-вторых, адаптер для подключения u.2 в обычный слот pcie стоит на али меньше тысячи рублей, в розничных магазинах подроже, но всё равно не такие большие деньги.он может на десктопных ПК собрать на ту же цену кластер из 3 машин с SATA рейдами в каждой
не смешно. я давно уже решил, что следующий домашний компьютер будет на eсс памяти, а вы предлагаете собирать «кластер» на десктопном железе и, очевидно, не-ecc памяти.
самое неприятное в не-ecc-памяти в том, что о проблемах с памятью вы не узнаете пока не запустите тест, то этого будет «ой, что-то программа вылетела», «ой, что-то база побилась»sukharichev
21.10.2022 15:37"вы как-то не так смотрите цены" - нет вы :)
970 Evo можно установить и в ПК и в любой сервер, u.2 только в сервер с соответствующей платформой. Да, в серверной платформе может быть разъем m.2 и у меня она такая и есть, но он там один, массив сделать нельзя, бэкапится надо очень часто, а бэкап даже журнала плохо влияет на повседневную работу , если сервер уже и так загружен. Мат. плата с двумя и более m.2 или более чем двумя oculink стоит существенно дороже. Кабель oculink у нормального продавца это +3-5 т. р на каждый диск, а SATA-кабель или m.2 разъем условно-бесплатные, они в комплекте с мат. платой.
2. "на али меньше тысячи " - в сервер? Адаптер с Али? Спасибо, но я так делать не буду. В моем представлении любой приличный бытовой сата-диск надежнее адаптера с Али.
3. Т. е. вот память обязательно с ЕЦЦ, а адаптеры для хранилища - с Али. Это точно разумный баланс по надежности? У нас есть несколько ПК для тестирования баз и быстрых перепроведений с 64 Гб памяти без ECC и за годы их жизни, прогнав через эту память сотни терабайт данных мы не столкнулись ни с какими "битыми базами".
Вы как-то неправильно представляете себе работу памяти с ECC, она защищает только от флип-бита в случае внешнего воздействия, а от повреждения микросхем - никак нет. Может быть, можно настроить получение данных об ошибках памяти и температурах с сенсора, снимать их с ipmi, отдавать в мониторинг и тогда, действительно, узнать, но я нигде такого не видел и не слышал. А в обычно, ECC при повреждении ведет себя так же, как и non-ECC - ошибки и вылеты программ, проблемы с компиляцией. Линус Торвальдс не даст соврать:https://www.zdnet.com/article/even-linus-torvalds-sometimes-has-pc-problems/
khajiit
21.10.2022 16:11Мат. плата с двумя и более m.2
… под Ryzen — явление давно уже рядовое
Линус Торвальдс не даст соврать
Это уже разбирали на хабре, и нет — память там была non-ECC

DaemonGloom
21.10.2022 20:23… под Ryzen — явление давно уже рядовое
Серверные материнки с парой М.2 или более — не особо рядовое. Хоть с Ryzen, хоть с Epic.
khajiit
22.10.2022 00:52+1К слову, а драйвера ставите на буковки или на железо? Вопрос риторический.
Скажем, в том же dns-shop материнок на AM4 всего 63, с двумя разъемами M.2 — 37, и еще с десяток на 3 или 4 M.2.
У AsrockRack или 2 M.2 или M.2 + Oculink (больше касается мелких типоразмеров).
Не говоря уже, что для серверных применений, если уж заострять на них внимание, более актуален U.2 или разные SFF, а PCI-E, как справедливо заметили, прекрасно в эти M.2/U.2 конвертится.
edo1h
21.10.2022 16:55+1970 Evo можно установить и в ПК и в любой сервер
честно говоря, не понял к чему вы это написали.
970 evo из статьи формата m.2, pm9a3, о котором я писал выше, тоже есть в том числе и в формате m.2Т. е. вот память обязательно с ЕЦЦ, а адаптеры для хранилища — с Али. Это точно разумный баланс по надежности?
да. потому что адаптер в части pcie — тупой механический переходник.
в серверах у меня таких нет, но дома используется.и если вам так претят китайские адаптеры, то есть вполне себе фирменные ретаймеры и свитчи, например в одном находящихся под моим присмотром серверов часть линий к бэкплейну подключена через свитч от intel. стоил не тысячу, но тоже каких-то не заоблачных денег.
(ретаймеры и свитчи нужны из-за того, что между разъёмом на материнской плате и накопителем/бэкплейном есть ещё полуметровый кабель, который вносит искажения в сигнал)Вы как-то неправильно представляете себе работу памяти с ECC, она защищает только от флип-бита в случае внешнего воздействия, а от повреждения микросхем — никак нет
это вы неправильно представляете, ecc помимо защиты от случайных ошибок (которые, говорят, таки есть, но я у себя их не наблюдаю) позволяет обнаруживать сбои памяти и оперативно менять неисправные модули.
если вы верите, что сбоев памяти не бывает, значит у вас пока просто мало опыта.
Может быть, можно настроить получение данных об ошибках памяти и температурах с сенсора, снимать их с ipmi, отдавать в мониторинг и тогда, действительно, узнать, но я нигде такого не видел и не слышал
очень грустно за вас, это совсем не rocket science.
кстати, снимать ошибки ecc можно не только из ipmi, в linux, например,edac-utilпокажет ошибки (да и в dmesg будет сообщение); в случае аренды сервера у хостера бывает полезно.
schvii Автор
21.10.2022 10:341) Ставил размер диска в интервале от 12 Гб до 21 Гб - разницы не было
2) Как только появится в наличии серверный ssd - разумеется добавлю в статью. Постараюсь заказать в течение месяца
edo1h
21.10.2022 11:101) Ставил размер диска в интервале от 12 Гб до 21 Гб — разницы не было
правильнее ИМХО повторить тест на базой на ssd с включенным (но не используемым) рамдиском.

nikweter
20.10.2022 16:36+1Так MS SQL всё равно сейчас не купить. Как можно сравнивать бесплатное с тем чего вовсе нет?
sukharichev
20.10.2022 16:52+1Есть доступный для бесплатной загрузки MS SQL Server 2019 for developers, ничем не отличается от полнофункциональной версии. И у многих уже купленные лицензии все еще есть, так что вопрос вполне актуальный. Тем более в свете необходимости планировать переход с MS SQL на Postgres - чтобы понимать, сколько именно производительности будет потеряно. Методика проверки в статье может быть неверной, но сама проблема актуальна. Тем более, что по моей практике, 1С сколько мощностей не дай, она все равно медленная. Если понимаешь, что станет еще медленнее, переход стоит отложить до выяснения подробностей.
schvii Автор
20.10.2022 17:27+1"Сейчас" означает что не навсегда, а во вторых этот форум же читают не только в РФ, но и в других странах. Ну и плюс, разве не интересно сравнить условно бесплатный продукт (не забываем что покупку лицензии на сервер 1С никто не отменял) с платным?
nikweter
20.10.2022 17:33+1Платный - значит можно купить за деньги. А MS SQL купить нельзя. Я только к этому придирался, не к самому сравнению.

sden77
20.10.2022 19:31+3Но ведь есть страны кроме РФ, где ms sql вполне актуален. Тем более сейчас это habr.com, что намекает на интернациональную аудиторию
nikweter
21.10.2022 03:30-1А 1с в этих странах актуален?
sden77
21.10.2022 07:101C актуален на бОльшей части бывшего СССР

Ivan22
21.10.2022 13:44при этом Украина его сейчас понятно массово заменяет
Беларусь под теми же санкциями (если еще нет - то будет)
Узбеки с Таджиками - ставлю свою тюбетейку, паленый mssql юзать не постесняются.
Остаются степи Казахстана
sden77
22.10.2022 11:45даже по вашим словам получается не так и мало, плюс еще есть Армения и Грузия. Насчет палёный/не палёный mssql в Узбекистане и Таджикистане - а какая разница, даже если так? Тут обсуждаются технические аспекты, а не юридические.

iliabvf
20.10.2022 20:28+2Как вообще можно рассматривать файловый режим как рабочий. Это же какой-то франкенштейн из 90х годов, готовый упасть в любой момент
ixsphin
20.10.2022 22:43Например из-за стоимости лицензии на сервер 1С, а x64 версия сервера ещё дороже. А при использовании в связке с веб-сервером становится возможно работать на HDD с файловой
Handogin
21.10.2022 01:41+2А что с файловым не так?
Вы предлагаете на компьютере каждого бухгалтера поднимать sql сервер?
Файловый это стабильный быстрый и удобный вариант.
А клиент-серверные решения применяют для большого количества пользователей.
Большая часть пользователей 1с работает как раз на файловом варианте.

mlnw
21.10.2022 01:41+1Он в 100500 раз быстрее и уместнее, когда ты, скажем, бух на фрилансе, ведущий кучу баз всяких ИП со своего ноута. Скули разворачивать для таких целей нет необходимости. Достаточно решить вопрос с бэкапами и в принципе можно работать.

jstbot
21.10.2022 09:36+1если база не большая у не большой конторы то смысл им покупать 1с сервер и городить это всё с БД на 1-2 пользователей? а таких случаев много

myhambr
20.10.2022 23:43Не указано потребление памяти в каждом случае, объём занимаемых данных на диске во всех 3х случаях хранения (файлы/MS/PG). Не приведён конфиг для Postgres. Может у Postgres по умолчанию выставлен маленький кэш, а у MSSQL большой.
По мотивам https://infostart.ru/1c/articles/962876/ - OnlineAnalyze.enable включен и Postgres поддерживает этот патч ?
schvii Автор
21.10.2022 01:03Спасибо за вопрос, я ждал его. В скором времени я хочу провести второй тест. Все настройки в данном тестировании у меня по дефолту. Мне нужны были "стандартные" результаты при установке по умолчанию. Теперь, когда у нас есть информация при дефолтных данных, я хочу сравнить какие можно получить результаты если постараться оптимизировать настройки MS SQL и POSTGRES SQL.

BigKote
21.10.2022 01:05+1Можете в статье указать какие параметры были у postgres? Интересно можно ли в вашем случае подтянуть pg по скорости. Есть ещё платный postgres pro, интересно его с версией от 1с посмотреть.
schvii Автор
21.10.2022 01:06Уже ответил выше:
Все настройки в данном тестировании у меня по дефолту. Мне нужны были "стандартные" результаты при установке по умолчанию. Теперь, когда у нас есть информация при дефолтных данных, я хочу сравнить какие можно получить результаты если постараться оптимизировать настройки MS SQL и POSTGRES SQL .
Что касается postgres pro - не обещаю но попробую добавить его если будет возможность

levkib
21.10.2022 08:49+1Установки по дефолту вещь своеобразная. Например сборка postgresql от 1с настроена на параметры по умолчанию которые тащатся в postgresql с незапамятных времен (а это примерно двух ядерный компьютер с 1ГБ ОЗУ и жестким диском, а например сборка от ПостгресПРО выполняет после установки скрипт который пытается хоть немного подстроить параметры СУБД под текущие параметры системы где устанавливается. MS SQL при работе часть параметров динамически подстраивает под оборудование. Так что сравнение производительности получается не очень корректное.

nbkgroup
21.10.2022 01:11Правильно настроеный Postgres на ZFS вообще не уступает MS SQL. Главное бутылочное горло 1C это скорость одного потока процессора.
schvii Автор
21.10.2022 01:30Возможно, я попробую поэкспериментировать с этой файловой системой после второго этапа тестирования. Но есть один нюанс - серверов под LINUX у меня нет в обеспечении. Как вариант можно заставить Windows понимать ZFS. Хотя это было бы интересное сравнение... В общем, пока могу сказать что подумаю на счет тестов на этой фс

badmilkman
21.10.2022 08:11Попробуй конечно, но у меня в 2016 году "правильно настроенный" закрывал месяц в течении недели. Стоковый MS SQL - 15 минут. (База около 80GB)
Возможно постгрес и вырос с тех пор, но насчет я не ZFS не уверен.levkib
21.10.2022 08:54В 16 году с оптимизацией связки 1С и postgresql было всё печально. На данный момент сменилось слишком много версий 1С и postgresql. Тот опыт уже не актуален.
nikweter
21.10.2022 10:09Ничего не изменилось, 100Гб база закрывает месяц 3 дня. На МС - 16 часов.

ptr128
21.10.2022 10:12Подозрительно большая разница. Складывается ощущение, что на MS SQL все запросы живут с MAXDOP 0, а на PostgreSQL параллелизация запросов сильно ограничена настройками.
nikweter
21.10.2022 10:25Да, МС тестировал в дефолте - себестоимость считается одним запросом на много часов, в МС распараллеливается на все ядра. В postgres запрос выполняется на одном ядре. Я пробовал распараллелить, но не смог. Там запрос вида INSERT INTO pg_temp.tt817 ...
Я на инфостате нашел статью про параллелизм и сравнение МС и посгрес. Там указано что в стандартной postgres работа с pg_temp не параллелится. PGpro вроде говорят, что внедрили у себя параллельную работу с временными таблицами, но я не проверял. У них вроде нет демо доступа, надо покупать.
myhambr
21.10.2022 12:25Читали https://infostart.ru/1c/articles/962876/ про OnlineAnalyze.enable для включения индексов во временных таблицах ? В 2016 его не было.
Ну и по выводом это статьи (2019 год), на Linux в 1.3-1.5 раза быстрее.nikweter
21.10.2022 12:33В последних версиях платформы analyze для временных таблиц выполняется и без этого плагина. Так что он не нужен больше. Это с 8.3.18 или 8.3.19, точно не помню.
Ну и написано много где много чего. По факту на Linux в 2-3 раза медленнее.
levkib
21.10.2022 15:10Видимо у вас сильно специфичные запросы. На не сильно модифицированных конфигурациях УПП и Торговли для свежих релизов Постгрес и 1С большой разницы с MS SQL не замченео. Базы гигов по 50-60. Постгрес используется от ПостгресПРО
ptr128
21.10.2022 21:31INSERT INTO в ванильном PostgreSQL не параллелится. Но есть обходные пути.
Во-первых, можно сделать CREATE TEMP TABLE ... AS ... , что замечательно параллелится в ванильном PostgreSQL. Ну а результат потом перелить куда надо, если надо. Все равно он будет, преимущественно в оперативке сервера.
Во-вторых, можно писать в одну UNLOGGED таблицу из нескольких соединений, породив их, например, через dblink(). Этакий ручной параллелизим.
В-третьих, есть PostgresPro с патчем, который это позволяет, что Вы уже сами упомянули.
Ну и в-четвертых, патч для ванильного PostgreSQL для параллельного INSERT INTO мурыжится уже два года. Применять его самому не советую, но может дождемся еще его стабилизации и включения в mainstreem.
nikweter
22.10.2022 08:06На самописе всегда можно сделать чтобы не тормозило. Но в 1С своя атмосфера. Никто не будет переписывать расчёт себестоимости из-за того что он медленно работает в постгре, проще взять мсскуль.

Bessome
23.10.2022 08:12Регистрируешься на сайте, выбираешь версию и кликнешь да на соглашении о некоммерческом использовании продукта и получаешь дистрибутив pgpro под различные системы с детальным описанием установки
Bessome
23.10.2022 08:10В 14 релизе postgres, по заявлениям производителя, добавлен алгоритм, аналогичный существующему в MySQL, который проталкивает наложение отборов ниже в структуре плана запроса .
В результате этого пресловутая проблема с производительностью по закрытию месяца должна уйти.
edo1h
23.10.2022 11:14который проталкивает наложение отборов ниже в структуре плана запроса
Хм, а что именно вы имеете в виду?
Сейчас перепроверилselect * from (select a.field1, b.field2 from a join b on …) с where field1=xxxусловие
field1=xxxбыло применено, как и ожидалось, до joinв MySQL
Это не опечатка?
Bessome
23.10.2022 12:09https://habr.com/ru/company/postgrespro/blog/682976/
Вот такие изменения. Есть ключевые именно для 1С
levkib
21.10.2022 08:56А можно хоть наметки как правильно приготовить postgres на ZFS? А то я при экспериментах не получил выигрыша ZFS от других ФС для postgres.
nbkgroup
21.10.2022 10:55+1Вкратце — нужно правильно распределить ОЗУ между ZFS ARC, postgres и остальной системой, включить в zfs как минимум для фс с postgres сжатие lz4 (zstd не дает выигрыша в производительности), а у postgres настроить effective_io_concurrency и отключить synchronous_commit и full_page_writes, так как целостностью данных управляет zfs. Ну и для полноты картины убедиться, что процессор работает в режиме максимальной производительности, а не энергосбережения.
Есть ещё ряд мелких настроек, дающих небольшой прирост производительности, но ни включение huge pages, ни отключение защиты от аппаратных уязвимостей процессоров mitigations = off не показали у меня увеличение производительности выше погрешности измерения.
Измерял тестом Гилёва, попугаи на не уступают конфигурациям с MS SQL.
Реальная производительность зависит от многих факторов, в т. ч. от версии платформы и конфигурации. С одной стороны, обновление платформы ухудшает показатели тестов на том же сервере. С другой — использование современных конфигураций может увеличить скорость работы в разы.
sden77
21.10.2022 07:29Как я понимаю, выбор сводится к двум вариантам ssd, причем, если уже есть sata диск, то менять его на nvme практически бессмысленно.
schvii Автор
21.10.2022 10:13Если речь идёт про уже имеющийся в наличии SATA SSD, то да, смысла особого нет при использовании СУБД MS SQL или POSTGRES, а если речь идёт про приобретение новых дисков, то разумеется, есть существенный смысл приобрести NVME
sukharichev
21.10.2022 10:17Нет, не так. Я не могу подготовить целую статью, времени нет и сил нет, но я проводил такие тесты:
База на MSSQL + Raid10 x4 SATA + журнал на другом Raid10 x4 SATA
и
База MSSQL + Raid1 x2 NVME U.2 Oculink + журнал на одиночном NVME 2 Tb PCI-e.
NVME в такой конфигурации существенно быстрее. База 70 Гб, Конфигурация Бухгалтерия вер. 3, платформа 1.8.3.18 Количество документов не помню, в самом ненагруженном месяце примерно 27000, в квартал около 160000Полное "Тестирование и исправление" базы со всеми галками на SATA - 22 часа, на NVME - 16. Закрытие месяца Sata 19 часов, NVME 9,9
По соотношению цена\скорость в тот момент выигрывал SATA потому что был гораздо дешевле, но для бизнеса была важнее скорость, потому что бухгалтерии работать надо, а не ждать, пока месяц закроется. Особенно когда база такая не одна.nikweter
21.10.2022 10:37Скажите, а при цене MSSQL вы все еще смотрите на цену дисков? Они же теряются где-то на фоне.
sukharichev
21.10.2022 11:18Мы смотрим
Нет, не теряются, посмотрите цены на 2 Tb U.2 - около 50.000 за штуку, а нужен Raid минимум из 2 шт, + кабели + мат. плата с разъемами oculink стоит на 40 Т. р. больше похожей без них
MSSQL мы купили давно и заплатили за него один раз, а диски желательно менять профилактически раз в три года, или уж если совсем затягивать, то раз в 5.
Множество других организаций не используют MSSQL или переходят с него на Postgres
UPD: А если вспомнить, сколько такие диски стоили в момент взлета криптовалюты "Чиа" и наводнений, разрушивших фабрики на Тайване и т. п., да еще умножить это не на 2 а на 4, потому что кластер...
edo1h
21.10.2022 11:18ИМХО сравнивать накопители по единственному параметру — интерфейс — это плохая идея.
sukharichev
21.10.2022 16:52Тут я полностью с вами согласен, но мы все дружно сидим и ждем, пока найдется добрый человек, или организация с бесконечным бюджетом денег и времени, которые кааак соберуться, каак выкатят нам массовый тест всех видов железа для 1С и best practice как это все готовить. Пока не дождались и читаем скупые рекомендации от 1С и инфостарт. Спасибо автору, потратил силы и время и сделал, что мог.
edo1h
21.10.2022 17:24речь была лишь про то, что делить накопители по признаку sata/nvme некорректно, конкретная модель накопителя важнее, чем интерфейс (особенно, если учесть, что в статье и комментариях мы не ограничиваемся dc-накопителями).

Fa11en_Angel
21.10.2022 08:51+2Что такое NVMe x3?
Если речь о PCI-E Gen 3, то надо так и писать. X используется для обозначения количества линий PCI-E, а никак не версии. А 3 линии у NVME в PCI - нонсенс
schvii Автор
21.10.2022 10:16Да, моё упущение. Добавил строчку: предлагаю дальше для упрощения просто указывать NVMe x3 для SSD на шине версии 3 и NVMe x4 с PCI-express версии 4. Но постараюсь в ближайшее время переделать всё на gen3 (или v3) чтобы не было больше вопросов
khajiit
21.10.2022 16:18Это все равно запутывает. Когда хочется сократить выражение вида "smth1 on smth2" — используют
@, он менее запутывающий и давно устоялся в качестве предлога "на" или "в".
NVMEx4@v3.

teplolub
21.10.2022 09:15Для корректного сравнения файловой и серверных версий на RAM диск нужно переносить и служебные файлы SQL серверов. Например, для MS SQL нужно перенести базу Tempdb. Эта база активно используется при перепроведении документов. Не увидел информации об этом в статье.
ptr128
21.10.2022 10:06+1Хотелось бы отметить, что Windows для PostgreSQL инородная среда, под которой оценивать его производительность уж точно не стоит. По двум причинам:
Во-первых, PostgreSQL каждый объект БД (раздел таблицы, индекс и т.п.) хранит в отдельном файле. А производительность даже древней ext3 при больших количествах файлов в одной директории, заметно выше, чем NTFS. Что уж говорить о современных файловых системах? В MS SQL эта проблема решается просто отказом от работы с файловой системой в процессе работы сервера и размещением всех объектов БД в одном или нескольких постоянно открытых файлах.
Во-вторых, PostgreSQL активно пользуется fork(), реализация которого под Windows далека от оптимальной. В первую очередь из-за отсутствия Copy-on-Write. Иными словами, если под Linux fork() выполняется почти мгновенно, откладывая копирование страниц памяти на потом, и только при их модификации, то под Windows такой возможности нет и при fork() выполняется принудительное копирование всей памяти процесса.
edo1h
21.10.2022 11:22А производительность даже древней ext3 при больших количествах файлов в одной директории, заметно выше, чем NTFS
слушайте, это тут вообще не к месту. ни по количеству файлов в каталоге (десятки-сотни-тысячи не являются проблемой ни для какой фс), ни по характеру использования (тормозит открытие файла; СУБД же, очевидно, держит файлы БД постоянно открытыми, а не открывает/закрывает их при каждом обращении)
sukharichev
21.10.2022 12:03+1У меня есть каталог на windows 2008r2 - сервере, лежащий на Raid1 из жестких дисков, в NTFS, где лежат несколько милионов документов в нескольких сотнях тысяч папок. Сколько именно я не могу сказать, потому что не могу ни зайти в него проводником, ни посчитать их скриптом powershell, сервер при этом зависает намертво. Диски в порядке и по смарту и по тестам поверхности и ФС chkdsk.
И есть копия этих же данных на Linux в Ext4, на одиночном диске. Там нет графического интерфейса, чтобы проверить, зайду ли я туда Наутилусом, но скрипты и du с ними работают вполне нормально. Считать их там я не пробовал, но разница даже по перемещению скрипта и подсчету занятого места явная
ptr128
21.10.2022 12:49+1Во-первых, раз речь об 1С, количество файлов может оказаться под миллион, так как каждый раздел и индекс - отдельный файл. По крайней мере на первой попавшейся мне сейчас под руку продуктивной БД PostgreSQL 500 таблиц хранятся в 7 тысячах файлах.
Во-вторых, это MS SQL держит все файлы открытыми, так как их у него на пальцах можно пересчитать. PostgreSQL так не делает и открывает/закрывает файлы по мере надобности в них. И в том то и проблема, что на современных FS в Linux операции открытия/закрытия файлов при работе PostgreSQL занимают меньше миллисекунды (не забываем об указании noatime,nodiratime при монтировании), тогда как на NTFS - несколько миллисекунд. Оба времени - с учетом кеширования.
edo1h
21.10.2022 16:46Во-первых, раз речь об 1С, количество файлов может оказаться под миллион,
не может
так как каждый раздел и индекс — отдельный файл. По крайней мере на первой попавшейся мне сейчас под руку продуктивной БД PostgreSQL 500 таблиц хранятся в 7 тысячах файлах.
чтобы число файлов выросло до миллиона, надо или создать миллион таблиц/индексов (чего в стандартных конфигурациях явно не бывает), или в существующие записать петабайт (ЕМНИП постгрес создаёт по файлу на гигабайт)
PostgreSQL так не делает и открывает/закрывает файлы по мере надобности в них
так увеличьте
max_files_per_process. 1с рекомендует 8к как начальное значение, и увеличивать с ростом базы.
https://its.1c.ru/db/metod8dev/content/5866/hdocptr128
21.10.2022 19:15Для того, чтобы число файлов PostgreSQL выросло до миллиона, достаточно несколько десятков тысяч таблиц, что я легко наблюдал на производственных предприятих. Любая таблица без индексов - уже минимум три файла (данные, карта свободного места и карта видимости). Каждый индекс - два файла (индекс и карта свободного места). То есть, одна таблица с восемью индексами - два десятка файлов. И это не считая вороха временных таблиц на каждого пользователя.
"Под миллион", как я писал выше - это фактическая картина для 1С на предприятии по производству ювелирных часов.
И при чем тут количество файлов для серверного субпроцесса? Эти субпроцессы форкаются в PostgreSQL по десятку-другому на один запрос.
edo1h
22.10.2022 01:51Для того, чтобы число файлов PostgreSQL выросло до миллиона, достаточно несколько десятков тысяч таблиц, что я легко наблюдал на производственных предприятих. Любая таблица без индексов — уже минимум три файла (данные, карта свободного места и карта видимости). Каждый индекс — два файла (индекс и карта свободного места). То есть, одна таблица с восемью индексами — два десятка файлов. И это не считая вороха временных таблиц на каждого пользователя.
"Под миллион", как я писал выше — это фактическая картина для 1С на предприятии по производству ювелирных часов.ваши оценки: под миллион файлов, по файлов на таблицу — итого выходит многие (не один-два) десятки тысяч таблиц.
я такого не видел. и не хотел бы увидеть.И при чем тут количество файлов для серверного субпроцесса? Эти субпроцессы форкаются в PostgreSQL по десятку-другому на один запрос
вы про распаралеливание запросов? нет, параметр был ещё до этого:
https://www.postgresql.org/docs/8.1/runtime-config-resource.html
если я правильно понимаю, он означает как много открытых файлов может быть в серверном процессе (читай клиентском подключении), при превышении этого числа процессу придётся закрывать какие-то из открытых прежде файлов (а при повторном обращении к ним открывать их снова)хотя я был неправ, похоже.
задирание этого параметра может кардинально снизить потребность в жонглировании закрытием/открытием файлов в уже существующем подключении, но никак не повлияет на открытие файлов в начале подключения.
впрочем, у меня есть сомнения, что задержки на это самое открытие файлов в начале подключения существенно влияют на производительность 1с.ptr128
22.10.2022 02:32Дело в том, что на больших БД, во-первых, активно используют частичные индексы. И таких индексов на таблице может быть несколько десятков. Во-вторых, для удобства архивирования старых лет и повышения производительности, все транзакционые таблицы (документы, регистры и т.п.) партиционируются по годам. А каждая партиция, с точки зрения PostgreSQL - отдельная таблица со своими индексами. Так что, если горизонт хранения лет 10 (что совершенно нормально, если убытки в первые годы работы покрываются потом прибылью последующих лет), такое количество файлов получить несложно.
edo1h
22.10.2022 07:38Используют и частичные индексы, и партицирование. И я использую (не с 1с, правда).
Но это всё осмыслено с большими таблицами, которых в базе разумного размера не может быть очень много.ptr128
22.10.2022 11:30Вам нравится партиционировать выборочно вручную и только большие таблицы. Но из этого не следует, что нельзя партиционировать автоматизировано все транзакционные таблицы. Я же не зря потребность в архивировании вынес раньше, чем производительность.

rezedent12
21.10.2022 10:09+1Что если это проблема windows, а точнее конкретной программы для создания виртуального накопителя? Для объективности надо сравнить с tmpfs в linux.

net_men
21.10.2022 10:17Долго боролись мы с 1С и её тормозами... в итоге пришли к следующему решению: сиквельную базу оставили на старом сервере с рейдами, а клиентскую часть я затолкал в новый сервак в виртуалку. Правда изначально этот сервер предназначался под файловое хранилище. Первое время было нормально, но после нескольких обновлений 1С стало ужасно тормозить. Самое интересное, что по производительности, не потребляется ничего, кроме оперативы, но чем больше пользователей входит, тем сильнее тормоза.
Оперативы было выделено 12ГБ, 2 проца Bronze 3106 (1,7ГГц)... работает обычно 12-15 клиентов. Как я говорил, занята была только оператива (до 97%) при полной загрузке... очередей по диску почти нет: изредка кратковременно очередь доходила до 5. По итогу, люди ждали загрузки 1С по несколько минут.
Чисто ради эксперимента перетащил виртуалку с клиентами на старый временный сервак (i5 10400, 16ГБ под виртуалку)... и скорость существенно выросла, но не идеально... и по прежнему загружена была только оператива.
На новом сервере рейд-массив 10 на хардах... на временном серваке обычный хард (по сути это обычный комп)... на обоих система работает на SSD.
Кто может объяснить что нужно этой 1С? Контора, которая обслуживает 1С, не может нам ничего сказать... регулярно что-то обновляют в ПО, но ничего не меняется в скорости в лучшую сторону. Как увидеть реальную потребность 1С в ресурсах? Я предложил проапгрейдить процы на сервере до 4115R + добавить 64ГБ оперативы... но будет ли от этого существенный прирост в скорости - не понятно. Самое обидное, что организация готова платить, но за что?

Elisy
21.10.2022 11:29+1Когда у нас встала задача оптимизации, мы начали с изменения конфигурации. Перевели все блокировки на управляемые, тем самым ускорив параллельную работу пользователей. Сейчас не знаю, но несколько лет назад перевод MSSQL в режим версионника тоже давал ускорение.
sukharichev
21.10.2022 11:30+1К сожалению, по нашему опыту улучшить производительность 1С "завалив" ее новеньким быстрым оборудованием получается, но совсем не так, как хотелось бы. Прирост мощностей в "попугаях" + 250% а быстродействия 1С - 25-30%.
Однако и это уже хорошо.
Обновления ПО на старом железе ухудшают ситуацию, потому что новое ПО приспосабливают делать работу быстрее, потребляя больше ресурсов и адаптируя под новые аппаратно реализованные алгоритмы.
1С очень любит частоту процессора а не количество ядер, потому что многие операции невозможно (или разработчики 1С не умеют) разделять в многопоток. 1.7 Ггц и 12 Гб это очень мало для нее. Рассчитывайте минимум 4 Гб на платформу, лучше 8, +2 Гб на каждого пользователя. А в моменты перепроведений месяцев\кварталов оно способно сожрать 256 Гб ОЗУ в зависимости от вашей базы и объема документов.
В нашем случае 4115R принес ускорение, но не сам по себе, а в сочетании с NVMe дисками и увеличением ОЗУ.UPD: Харды для 1С это смерть. Если хотите попробовать ускорится бюджетно, мы делали еще такой вариант: Мощный десктопный комп на Ryzen 7 3ХХХ (сейчас лучше 5ХХХ) с максимальной частотой и минимум 8 Ядрами, мат. плату с минимум 64Гб (желательно 128) ОЗУ и поддержкой 2 NVMe PCI-e 3.0 или 4.0. Систему на рейд из SATA SSD, Платформу и базы на NVMe, журналы и кэши на другой NVME. Все это уделает ваши чахлые "Bronze" в разы.
net_men
21.10.2022 12:16Всё понял, спасибо!
Оператива уже была закуплена некоторое время назад (64ГБ)... но "не взлетело": как оказалось, она совместима только со вторым поколением процов, а стоит первое (об этом нет нигде информации, выяснилось только по факту... и то, производитель ответил вот так: пробуйте обновить бивас... если не поможет - нужно 2е поколение процов).
Поэтому сейчас смотрю в сторону 4215R (не 4115 - опечатался) + NVMe на сервер с базой.
Сейчас база лежит на хардовом сервере с оперативой 64ГБ (через пару недель она сжирала 30 гигов и начинала ещё больше тормозить: помогала перезагрузка... недавно немного подрезали аппетит СУБД), но процы там тоже унылые. Соединены серваки по 1Гб.
ЗЫ: и всёравно я недоумеваю: почему не видно нагрузки на подсистемы... любой другой софт займёт все свободные ресурсы, пока ему не будет достаточно... а тут всё по минимуму и тормозит...
nikweter
21.10.2022 12:49+2Ну у нас 4215R - все не очень быстро. Там в разгоне все ядра 3.6Ггц, и в однопотоке 2300 попугаев. Я для тестов поставил на i5 10400 - там 4Ггц и 2600 попугаем - стало значительно лучше. Так что для 1с хорошо идут мощные десктопы типа i9 12900. Или Intel® Xeon® E-2388G - там колоссальные 3500 в однопотоке, это перебивает практически любые остальные опции в сервере.
sukharichev
21.10.2022 16:47+2"ЗЫ: и всёравно я недоумеваю: почему не видно нагрузки на подсистемы... " Сам испытываю те же чувства, но магией мониторить правильные показатели для работы 1С владеют не только лишь все. Я не владею. Я смотрел в sysmon\resmon и глубину очередей по дискам и ввод-вывод по процессам, пытался заглядывать в распределение памяти и в своп. В результате пришли к выводу, что повседневная производительность после апгрейда - хорошая, а по перепроведениям из абсолютно неприемлемой стала минимально достаточной, а для дальнейших улучшений нужен либо бюджет на еще больше быстрого железа, либо на найм аутсорса, который как раз все правильно помониторит, оптимизирует и почистит базу и т.д. Ни на то ни на другое денег пока нет.
edo1h
21.10.2022 11:44честно говоря, я из вашего описания вообще не понял кто на ком стоял.
sql-версия? где лежит база? где запущен сервер приложений? клиенты толстые/тонкие? где запущены?
Bessome
23.10.2022 08:23Раз с железом чехарда, надо смотреть настройки сервера 1с. Или у Вас файловая версия?
Для сервера 1С уменьшаем количество соединений на процесс до минимума от версии. Инструкцию под Стандартный сервер, корп сервер искать на инфостарте.
Для сервера 1С %Appdata% и %temp% на одно дисковое устройство, базу данных на другое. Тюнинг ос. Регулярная очистка кэша 1с.
При открытии тормозит из-за журнала 1с: читать как увеличить производительность и правильно работать с журналом 1С на инфостарте, хабр.
А еще долго может искать лицензии hasp в сети на клиентах. Как раз минуты две таймаут. Настроить поиск по ip адресам машин с хаспом или выдавать лицензии сервером 1С.
net_men
23.10.2022 13:09Спасибо, проверю...
Сервер лицензий 1С'ники вынесли на отдельный комп на *nix'е... Адрес в резерве. Кстати совсем недавно были проблемы с лицензиями: постоянно жаловался на нехватку, хотя сессий хватает. После долгих жалоб это поправили, но начались сильные тормоза.
Тормоза не только в долгом запуске, но и в элементарной работе: выпадающие менюшки падают через несколько секунд после клика и т.п.
Bessome
23.10.2022 14:01Выпадающие менюшки: клиент и журнал регистрации...
Опять же надо понимать, что за конфигурация, режим запуска толстый, тонкий клиент.
Можно организовать веб-доступ, если конфигурация позволяет и перевести клиентов на доступ через веб. Соединений к серверу за счет этого меньше будет, скорость повысится
nikweter
21.10.2022 10:35А клиенты где? На том же сервере? Или тонкие?
Если на том же - памяти очень мало. Да и в принципе мало, 16Гб - это только для 1с, для БД отдельно нужно.
1с очень любит частоту ядер. У Bronze 3106 (1,7ГГц) очень низкая, все будет мертвое. У i5 10400 в принципе норм, для 15 человек сойдет.
Ну и CCД под базы, никаких хардов.
DBA_KadushkinS
21.10.2022 13:50А настройки postgres менялись перед тестированием? Или использовались из коробки? Какая версия Postgres?
schvii Автор
21.10.2022 13:52Уже отвечал в комментариях, а версия postgres указана в самом начале статьи. Установки все по умолчанию - "из коробки", так как хочу в ближайшие дни провести тестирование после тюнинга настроек
Bessome
21.10.2022 14:40Заранее прошу прощения, если пропустил выше, но:
Не повлияло ли на тестирование размещение %temp% и прочих сервисных директорий на самом медленном диске в тестировании диска RAM? Мне кажется, по своему опыту, что ОЗУ должно выдать производительность на уровне SSD на PCI шине. Возможно, драйвер виртуального диска в ОЗУ требует настройки?
Naf2000
Лично по мне так огромнейшее время тратится на передачу контекстов форм с клиента на сервер и обратно