
Introduce
Привет, Хабр! Меня зовут Михаил. Я занимаюсь тестированием с июня 2018 года. Начинал, как и все, с низов, затем вырос, как в хард-, так и в софт-скиллах. На данный момент работаю в М.Тех (аккредитованная IT-дочка МВидео - Эльдорадо). Состою в команде, отвечающей за сервисы по обработке заказов. Занимаюсь тест-дизайном, участвую в оценке задач, тестированием ТЗ и прочими «тестировщическими вещами». Пишу тест-кейсы на Cucumber-JVM и занимаюсь поддержкой тестового фреймворка, а также с сентября 2021 провожу собеседования новых сотрудников и их первичный onboarding. Возможно, я даже Вас собеседовал =)
What do you use?
Кратко о нашей архитектуре проектов в целом
Все бизнес-приложения - это микросервисная архитектура Java 17 + Spring Boot. Взаимодействие между сервисами осуществляется через REST API, либо через Apache Kafka для процессов, которые позволяют асинхронную обработку. В качестве базы данных в основном используется PostgreSQL, но также есть ряд задач для которых применяем нереляционные базы данных (Couchbase, MongoDB и т.д.)
Фреймворк автотестов - Cucumber 6, Java 14, Apache Maven, Allure TestOps. Сам набор .features и тестовых данных хранится в директории приложения отдельным подпроектом со своим pom.xml
CI/CD - GitLab CI/CD pipelines
Немного о life-cycle приложений
Поступает ТЗ от аналитика в Confluence. Разработчик по нему пишет код. Код пушится в git-репозиторий. В gitlab, на моем проекте, в основном имеется pipeline из трёх job:
test-and-publish: собирается проект и прогоняются unit-tests,
build-docker: приложение собирается в docker-image и пушится в наш локальный репозиторий образов,
autotests: наши автотесты.
Подробнее про life-cycle автотестов (на примере нового проекта)
Представим, написали новое приложение и нам его надо покрыть тестами, настроив тест-инфраструктуру с нуля.
Для этого у нас уже есть репозиторий с шаблоном, представляющий собой набор файлов:
TestRunner.java: содержит различные общие утилитные методы и методы по подключению к сущностям, @after/@before и т.д.
Папка с features + testdata: просто пример по структуре хранения тест-данных
collect-logs.sh: собирает логи со всех контейнеров после прогона в CI в виде артефактов
docker-compose.yml: настройка инфраструктуры приложения (app, kafka, wiremock, etc)
healthcheck.sh: проверяет состояние самого приложения в CI перед прогоном тестов. Для этого в каждом нашем приложении подключается Spring Boot Actuator
test-env.yml: содержит url, ports, etc для инфраструктуры, используемая шагами тестов. Может содержать неограниченное кол-во профилей
-
pom.xml: наборы шагов хранятся в различных библиотеках, поэтому есть возможность подключать только необходимые зависимости

Модуль «intregartion-test», подключаемый в каждом проекте В итоге копируем это к себе как проект в директорию проекта, убираем лишнее, добавляем нужное, немного танцуем с бубном и…. это еще не все…
У нас же Spring Boot приложение? А, значит, есть возможность настраивать профили Spring Boot Profiles. Для настройки профиля под автотесты необходимо сделать отдельный application.yml. Для этого мы идем в корень проекта, делаем копию с припиской -autotest и также подстраиваем под себя: меняем все url’s на docker_container_name:port, ставим меньшее кол-во ретраев, таймауты и прочее. Данный профиль указываем как переменную в контейнере приложения в docker-compose.yml
С настройкой инфраструктуры, кажется, закончили. Могу лишь добавить свои ощущения, что читать - всегда легко, в любом приложении найдутся «свои приколы», и довольно часто надо будет посидеть, погуглить доп. переменные, подкрутить и т.д. и это реально интересно.Как я выше указал, мы используем docker-compose. Все наши приложения тестируются в gitlab, т.е. локально изолированно. Каждый pipeline прогоняется с image текущей ветки, поднимаем сущности, с которыми он работает (Kafka, Couchbase, WireMock, Postgre, Elastic, etc), а все сервисы, с которыми общается наше приложение, мы мокаем через WireMock. Но у нас есть и другие проекты, где QA-auto поднимают тестируемый сервис и связанные с ним реальные сервисы, с которыми он общается, и уже их наполняют тест-данными.
И, думаю, тут стоит оговориться: нет, это не всё тестирование наших приложений в широком смысле. У нас имеется отдельная специальная команда e2e-testing, которая уже мануально проводит тестирования от самой начальной точки «А» (первичный вход на сайт) до точки «Б» (полного получения заказа), а за этим кроется огромное множество внутренних систем, но каждая команда нашего проекта занимается в 90% изолированным тестированием, а 10% - это интеграционное.
Интеграционное тестирование на stage-стендах проводится редко, в основном, когда маленькая, но важная правка/фича, либо какой-то супер-пупер релиз, а также при переходе с одного эндпоинта на другой. Другими словами, не на «каждый чих» мы его проводим.
Кажется, немного отвлеклись от нашего life-cycle автотестов. Так вот, расскажу немного про нашу библиотеку, которую мы подключаем в pom.xml, где выбираем, какие зависимости подключать. Feature-steps хранятся в отдельном репозитории, являющиеся библиотекой АТ. Там же имеются различные классы по обработке окружения из test-env.yml и работа с ними.
В библиотеке также присутствуют кастомные классы, которые используются в 99% случаев:
по обработке дат - можно в тест-данные вставлять кастомные заглушки, типа
today#HOURS#0#yyyy-MM-dd'T'HH:00:00.s'Z', которые при сравнении, конвертируются в дату и обрезаются до часов, как в ОР так и в АР-
При создании переменных в шагах, которые пробрасываются в файлы, в шаги и т.д.
Например:
Используя шаг берем актуальное значение поля из JSON:И переменная "createdAt" принимает значение поля "$.dates[0].createdAt" из тела ответа JSON
а в самом JSON-файле ожидаемого результата в это поле пишем:{ “dates”: [ “updatedAt”: “2020-01-01”, “createdAt”: “{{createdAt}}” ] }
Это доступно для получаемых и отправляемых данных, а также можно не значение поля сохранить, а целый массив или даже часть JSON (да, при таком варианте идея будет ругаться на некорректный JSON)
При сверке такого ОР с АР шаг сначала преобразует данные, а затем сравнит Классы по работе с test-env.yml - собираются все тест-данные (url, ports, etc) и преобразуются в объекты, данные которых, используются при отправке данных в приложение и т.д.
Классы сравнения данных: при сравнении JSON можно выбрать тип сравнения (целые числа, порядок полей, их отсутствие и т.д.) Используется библиотека io.qameta.allure.jsonunit. Мы, как правило, проверяем, чтобы все данные были на месте, порядок не проверяем.
Прочие шаги по конвертации данных в base64 и обратно, просто создание переменных (не вытаскивая ни откуда) и т.д.
Подключены различные библиотеки-помогаторы по типу json-unit, pico-container и т.д.
По поводу pico-container: она позволяет наследовать имеющиеся шаги в нашей библиотеке автотестов и «накручивать свои шаги», как я это сделал в своем сервисе. Например, в библиотеке для конструкции запроса 6 раздельных шагов (планирует вызвать метод, и тело будет содержать, и код ответа будет.. и т.д.). Я же это совместил в один и назвал
Борис создает заказ с телом запроса "order-1.json". Значительно сокращает количество строк в .feature и избавляет от дублирования.Что очень радует, у нас демократичный подход к развитию фреймворка, который написал наш ведущий специалист Алексей, являющийся автором библиотеки, а также нашим «старшиной» в решении всех проблем в плане тестирования. Главное правило аппрува ваших «крутотеней» - докажите, что оно нужно, несет смысловую нагрузку и объясните, как оно работает.
Подводя итоги, да, вы верно поняли, наши QA-auto занимаются и тест-дизайном, и сами настраивают тестовую инфраструктуру, и отвечают за весь цикл тестирования (включая интеграционное тестирование и консультация тестировщиков при e2e) и занимаются, по возможности, развитием фреймворка. И отвечу, пожалуй, на еще один излюбленный всеми вопрос «а тестов-то много?». А «много» - это сколько? Лично я не люблю такой вопрос совершенно, поэтому отвечу просто как у нас есть - все зависит от сервиса. Может быть сервис, который просто складывает и достает профиль клиента, валидация на дубль по ID и больше ничего не делает, образно говоря. Там может быть штук 10 тестов, а есть сервисы по типу корзины, в котором на данный момент, 626 тестов, но он и содержит бешеное количество логики. Одним словом, зависит от сложности бизнес-процесса сервиса и, как говорится, «на всё воля
Божьяфантазии тестировщика».
What’s going on here?
Представились, кратко описал как у нас все устроено. Перейдём к сути статьи.
Недавно, мне поступила очень интересная задача. Я её успешно выполнил и появилось желание рассказать о моих болях, страданиях, удовольствии и тонкостях, которые я собрал по чатам в телеграммах, общении с тех. поддержкой TestOps и помощи моих коллег из команды.
Дано: имеется сервис по обработке заказов «order-service». Взаимодействует с ~10 другими сервисами, складывает заказы в Couchbase, отправляет сообщения в Kafka со статусами заказов и прочим. Еще у него есть подключенный postgres, но он используются Camund’ой внутри приложения. Он нам не интересен.
Чуть подробнее об «order-service»:
Сервис получает от сервисов-клиентов сформированный заказ с позициями товаров, акциями, подарков, способами получения заказа, инф-ей о клиенте и т.д. Собственно, что вы видите у себя, когда уже нажимаете «Оплатить»
Обрабатывает заказ и, в зависимости от кучи переменных в нем, выполняет запросы в другие сервисы для: резервирования товара на складах, ожидании факта оплаты, получения цифровых кодов и т.д.
Сохраняет заказ в Couchbase
Отправляет сообщения в Kafka о состоянии заказа, считыванием которых уже занимаются другие сервисы для своих нужд
Передает обогащенный заказ во внешние системы, кто будет его исполнять (доставка, оповещения и т.д.)
Что в нем меняется:
Сервис должен перестать сохранять заказ в Couchbase и перестать отправлять сообщения в некоторые топики Kafka
Вместо сохранения заказа в Couchbase, сервис должен обращаться в другой сервис - «oms-order-service» через REST API, который, в свою очередь, уже выполняет сохранение заказа в MongoDB
В чем задача:
Прогонять в CI тесты на старой и новой конфигурации с учетом всего вышеописанного
Поддержать старый алгоритм работы сервиса (то есть, чтобы была возможность сохранять заказы в Couchbase и Kafka, как раньше) при переключении определенного флага в конфигурации сервиса. Данная необходимость обусловлена требованием возможности плавного отката в случае нештатной ситуации в продакшене
Let’s the carnage begin
Вот мне это дали, я немного «похудел» от объема и того, что я знаю, как все работает, но не знаю, с чего начать и за что взяться…
Первым делом, я задумался, что с тестами делать? Варианты я видел следующие:
Имеющиеся шаги в моем сервисе завязать на флаг, который переключает его режимы работы, проверять его и, либо проверять заказ в Couchbase, либо запрашивать у «oms-order-service» путем вызова API:order/search
Продублировать все тесты, которые будут отличаться в паре шагов по проверке итогового результата и уберутся некоторые проверки топиков, но это куча дублей, и мне это не нравилось
Предлагал вариант снести старые тесты и протестировать новый функционал, но это сразу «нет», так как нам необходимо было сохранить возможность отката на старую, стабильную версию после выхода в продакшн и быть уверены, что оно работает
После коллективного общения на несколько часов, обсуждая каждый вариант, обсуждая и другие варианты, решили дублировать тест-кейсы. Таким образом, у нас две директории - со старыми тестами и «новыми» тестами, но измененным набором шагов, о которых дальше расскажу.
Теперь, перейдем к самому интересному - как это будет крутиться локально и в CI, о чем, собственно, статья.
У меня в голове было только понимание в тонкостях, как у нас все работает, как крутится, на чем и т.д., но как все это «впихнуть» я на первых порах не понимал. Начал добавлять в свою memory информацию по CI, Cucumber, Maven, гуглить, спрашивать в телеграмм каналах.
Накидал/набрал инфы и начал с простого - полез вспоминать, что у нас в pom. В pom у нас конкретно указывается раннер Java-класс
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>${maven-failsafe-plugin.version}</version>
<configuration>
<testFailureIgnore>false</testFailureIgnore>
<includes>
<include>**/IntegrationTestRunner.java</include>
</includes>
<argLine>-Xmx1024m -Dfile.encoding=UTF-8</argLine>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>Вариант 1 - создать второй раннер, настроить его, прописать другой тег внутри раннера, где будет набор тестов для сервиса с включенным флагом, но потом это надо дублировать Maven, дублировать job, и появятся еще дублированная информация, помимо тестов. Отказался от варианта.
Вариант 2 - добавить еще переменную, прописать её в раннер и, в зависимости от нее, запускать разный набор тестов
Потом я дополнительно пообщался с коллегами, и мы решили следующее:
Наследуемся в CI от имеющейся job автотестов, создаем вторую, и там, через параметры, запускаем второй набор тестов, т.к. CLI команда по -Dcucumber.filter.tags=@test2 имеет приоритет над раннером в Java-классе. Меня этот вариант более чем устроил
Дальше у меня возник вопрос - как я за установленный мне короткий срок сделаю достаточное количество mappings для 200 тестов? Ведь при обработке каждого заказа инициируется более 10 запросов. Снова созвон с разработчиками и консультация. Обсуждая, один коллега предложил добавить в docker-compose реальный сервис «oms-order-service» с мастер ветки на время переезда. Это очень ускорит процесс.
Остается не закрытый вопрос - сколько я времени потрачу на огромное количество mappings для WireMock уже после переезда, когда отключим реальный «oms-order-service»?
Тут я вспоминаю о спасительной манне небесной - WireMock > Proxying + Record and Playing. Суть функционала:
При получении запросов, подходящих под mapping для проксирования, перенаправлять запросы в указанный сервис
Ответы, полученные от другого сервиса, воспринимаются WireMock'ом как «успешный» ответ
Этот исходящий запрос и успешный ответ сохраняется в виде файлов
Т.е. WireMock - транслирует запросы в реальный сервис внутри моей инфраструктуры + еще и mappings все за меня сделает! Блестяще! tomakehurst - ты гений, спасибо тебе!
P.S.: кстати, есть WireMock для API с веб-версией, очень удобно, и не надо в логах фильтровать мусор

Пошли строить?
Что делаем с тестами?
Создаем новую папку в features, testdata, stub/mappings и stub/__files директориях
Копируем все старые тест-данные в новую папку по той же структуре
Для каждого .feature меняем тег в его шапке, по которому будет сбор тестов для прогона, на новый @test2
В поле «Функционал» добавляем ключевое слово(любое). Это крайне важно. @allure.id для каждого теста мы назначаем через plugin Allure TestOps в Intellij IDEA и он тригерится на название функционала и название теста в поле «Сценарий». Если название «Функционал» не изменить, то тому же тесту назначится старый ID существующего теста
Убираем шаги по проверке сообщений в топиках, с которыми приложение более не общается в рамках данной конфигурации
Заменяем шаги по проверке заказа в Couchbase на запрос по API:order/search
Перед проверкой заказа по API вставляем шаг
И в истории WireMock n-запросов, чтобы быть уверенными, что мы запросим заказ, после того как процесс успешно закончился
Остальное оставляем как есть. В итоге у нас 1 в 1 набор тестов, как и было. Наша задача убедиться - как работало, так и работает.
Начиняем инфраструктуру в docker-compose.yml
1. В параметры WireMock, ко всему прочему, проставляем «--record-mappings». Это позволит включить запись всех проксированных запросов в другой сервис без необходимости кодить

2. В контейнер «order-service» добавляем кастомную переменную USE_OMS_API_STORAGE: true/false, которая и будет флагом для переключения режимов работы. Дальше она будет нести еще одну функциональность

3. Добавляем образ «oms-order-service» и MongoDB, в которую он складывает заказы
4. В stubs/mappings кладем файлик, который будет проксировать все наши запросы к сервису-хранилке «oms-order-service» для дальнейшего сохранения mappings
{
"request": {
"urlPattern": "/order/.*"
},
"response": {
"status": 200,
"proxyBaseUrl": "http://oms-order-service:8181",
"transformers": [
"response-template"
]
},
"priority": 10
}5. Добавляем в collect-logs.sh, healthcheck.sh команды для «oms-order-service»
На этом всё. Наверное, уже подметили, что я не стал делать два docker-compose.yml Сделано это специально, потому что поддерживать их в разных местах не хочется, а если в обоих случаях поднимается что-то «лишнее», то на результат прогонов и сам сервис это никак не влияет.
Фреймворк АТ
При локальном многократном запуске я заметил, что записанные спроксированные mappings не удаляются методом WireMock.resetMappings(); Это создает проблему - при повторном прогоне, WireMock не старается спроксировать и перезаписать mapping, а просто берет ранее спроксированное, что мешает отладке тестов.
Нашел метод, который делает это - WireMock.removeMappings();, однако, у нас используются volumes для WireMock контейнера, и этот метод зачищает все mappings, которые были предварительно подготовлены для других эндпоинтов, к тому же, у нас иногда надо, чтобы mappings были еще до старта приложения, но это редко. Пока что, накрутил локально, чтобы у меня они очищались, но для CI этот метод по сути не нужен.
allurectl
Утилита для работы с launch’ами в Allure TestOps, отправке результатов прогона тестов из CI и т.д.
Раньше у нас работало через ‘allurectl upload’ - команда, которая берет уже готовый результат тестов в конце всего прогона, пакует, создает launch в TestOps и отправляет пачкой. Нашел, что появилась ‘allurectl watch’ - штука, которая принимает в параметрах Maven CLI-команду и вместе с началом прогона создает пустой launch, по мере прохождения каждого теста отправляет немедленно в launch, т.е. один тест прошел - отправил сразу в Allure TestOps. Дополнительно эта команда переезжает из этапа ‘after_script’ в ‘script’.
По информации с оф. сайта Allure, это значительно быстрее работает и красивее выглядит, что вы можете, не дожидаясь прохождения job, уже видеть упавшие тесты и начать править их.
При этом я сначала хотел сделать, чтобы каждый прогон был в разном launch. Успел уже так реализовать, но встретил ряд проблем - нужно много костылить. Пообщавшись с тех.поддержкой, пришли к выводу, что лучше все-таки сливать результаты в один launch. Так, действительно удобнее, но в целом, если кто-то захочет в будущем, то можно и делить на два разных в рамках одного pipeline. Проверено
По итогу, команда сменилась:
Было:
after_script:
- cd $CI_PROJECT_DIR/integration-test
- ./collect-logs.sh
- allurectl upload target/allure-results || trueСтало:
script:
- docker-compose up --detach
- ./healthcheck.sh
- allurectl watch -- mvn $MAVEN_AT_OPTS $MAVEN_TZ clean verifygitlab-ci.yml
В gitlab есть отдельный репозиторий с шаблонами CI, один из которых, для автотестов. В нем в целом стандартно: ставятся переменные, берется image с Java, поднимается окружение, прогоняются тесты через «clean verify» и отправляется отчет, плюс всякие rules и запуск скриптов на сбор артефактов прогона.
В нашем сервисе «order-service» делаем следующее:
я создал внутри проекта AT-with-feature-flag.gitlab-ci.yml, в нем отнаследовался от этого шаблона и прописал новые пункты:
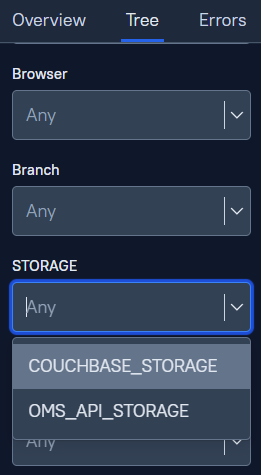
STORAGE: "COUCHBASE_STORAGE" - переменная, которая будет пробрасываться к каждому тесту и нам понадобится в Allure TestOps
Заполняем script из раздела allurectl
В after_script я захотел создать миниотчет в Mattermost. Для этого:
1. вытягиваем номер созданного launch'aexport ALLURE_LAUNCH_ID=$(allurectl launch list --project-id $ALLURE_PROJECT_ID | grep "$ALLURE_LAUNCH_NAME" | awk 'NR==1{print $1}')"
2. указываем шаблон для отправки данныхcurl -s -X POST -H "Content-Type:application/json" --data '{"field": “'"$ALLURE_REPORT_LINK"'”}' $REPORT_WEBHOOK
Информацию по форматированию можно найти на сайте Mattermost-
Далее, создаем вторую job, которая уже будет наследоваться от предыдущей, но с учетом перезаписанных данных, описанных выше добавив пару пунктов:
В переменную
MAVEN_AT_OPTSдобавляем CLI команду Maven-Dcucumber.filter.tags=@test2Переменная, переключающая режим конфигурации приложения на сохранение заказов в «oms-order-service» -
OMS_API_STORAGE: trueИ, естественно, переменную, которая понадобится для второго набора тестов:
STORAGE: "OMS_API_STORAGE"
В итоге получаем следующую картину:

Allure TestOps:
Через панель администратора «Administration - Environments» создаем переменную STORAGE, затем пушим наши тесты
После прогона видим следующую картину - отобразились наши переменные, тем самым мы видим, что оба прогона слились в один launch

И вот, для чего это переменная нужна - это фильтр, который позволяет фильтровать нам наш набор тестов внутри launch'a
Отчет в Mattermost выглядит следующим образом:

Послесловие:
Вот так, путем общения с коллегами, чатами, тех.поддержкой, гуглом мне удалось довольно аккуратно и красиво реализовать тестирование одного и того же приложения в двух конфигурациях в параллель, тем самым не увеличивая время прогонов, и не сильно изменив инфраструктуру, которую, к тому же легко откатить на старые «рельсы».
Однако, самый не приятный этап - это копирование тестов под новую конфигурацию. Объем большой, времени мало, да и в целом поддержка тестов на «два фронта» не радует, но радует, что это ненадолго, и после отказа от первой конфигурации с Couchbase, мы просто под 0 снесем старые тесты, и все вернется в прежнее русло.
К сожалению, есть «ложка дёгтя» - на каждый тест теперь большое количество исходящих запросов при обработке заказа и поэтапной отправке его в другой сервис. В будущем надо бы отказаться от поднятия «живого» сервиса и создать mappings. Правда, страшно представить, какое количество mappings у нас появится. Об этом надо будет думать позже…
А на этом всё. Большое спасибо всем моим коллегам, кто помогал, давал советы и был вовлечен в процесс вместе со мной.