
Если вам приходилось оптимизировать работу программ, то вы могли слышать о Профайлере Бедного Человека. Этой идее даже посвящён целый сайт. ПБЧ собирает статистику времени выполнения отдельных функций программы, «подглядывая» в процесс её исполнения с помощью дебаггера. Концепт ПБЧ хорошо прижился у нас в движке баннерной крутилки — не буду в 100 500-й раз напоминать, что у Яндекса всё высоконагруженное, ресурсоёмкое и нуждающееся в профилировании. Статья будет полезна тем, кто пилит инфраструктуру, адаптирует какой-нибудь общеизвестный профайлер под себя или просто хочет больше знать про свои программы. Как мы пришли к необходимости в ПБЧ и что именно сделали? Сейчас постараюсь рассказать, местами буду закапывать глубоко в технологии (если переусердствую, пишите в комментариях). А начну со стандартного инструмента статистического профилирования в Linux — perf.
Подходы к профилированию и perf
Есть два основных подхода к профилированию программ: инструментация и сэмплирование. В первом случае программа дополняется кодом для сбора различной статистики: количества вызовов функций, время их исполнения и так далее. Главный недостаток такого подхода — влияние самой инструментации на профилируемую программу, из-за чего результаты могут заметно искажаться. Кроме того, приходится иметь отдельную сборку и специальные выделенные серверы для профилирования.
Второй подход — сэмплирование (статистическое профилирование). В этом случае периодически собирается информация о текущем состоянии программы (например, стек вызовов функций), затем эти данные агрегируются. Такой подход не гарантирует идеальную точность и зависит от частоты и продолжительности сэмплирования. Зато он не требует никаких изменений в самой программе и минимально влияет на неё. Обычно систематическая погрешность от инструментирования оказывается более критичной для точности результатов, чем случайная погрешность сэмплирования, особенно при попытках оценить именно затрачиваемое различными частями программы процессорное время.
Оба подхода полезны и позволяют взглянуть на производительность программы с разных сторон, но сегодня мы поговорим именно о статистическом профилировании. Выбор более правильного подхода для вашего приложения остаётся в ваших руках.
В наборе утилит perf для Linux есть всё необходимое, в том числе и для визуализации результатов, но часто в дополнение к perf используют flamegraph.pl. Этот скрипт отображает статистику по стекам вызова в виде интерактивного svg-файла, в котором стеки сгруппированы в префиксное дерево и представлены в виде «пирамид», где ширина каждого блока пропорциональна количеству соответствующих стеков в выборке.
Инструмента perf уже достаточно, чтобы примерно представлять распределение времени выполнения программы по функциям, искать «горячие» места, которым необходима оптимизация и т. п. Однако у perf есть недостатки: он всё-таки влияет на исполняемую программу — тратит ресурсы CPU на сбор и обработку стеков. Минимизировать такое влияние можно уменьшением частоты сэмплирования, при этом увеличив время для получения стабильных результатов. Эта проблема не очень существенна для программ, запущенных на небольшом количестве серверов, но для крупного распределённого кластера она может стать препятствием.
Очевидное решение для большого кластера — запуск perf только на небольшом подмножестве серверов, выделяемых статически или динамически (ещё лучше), когда профайлер запускается на случайном наборе хостов. В таком случае гибко контролируется качество выборки сэмплов и ресурсы, затрачиваемые на профилирование.
Но недостатки инструмента perf особенно заметны в применении к программам, собранным оптимизирующим компилятором: без выключения некоторых оптимизаций разметка стека по вызываемым функциям оставляет желать лучшего, а многих заинлайненных функций может быть вообще не видно.

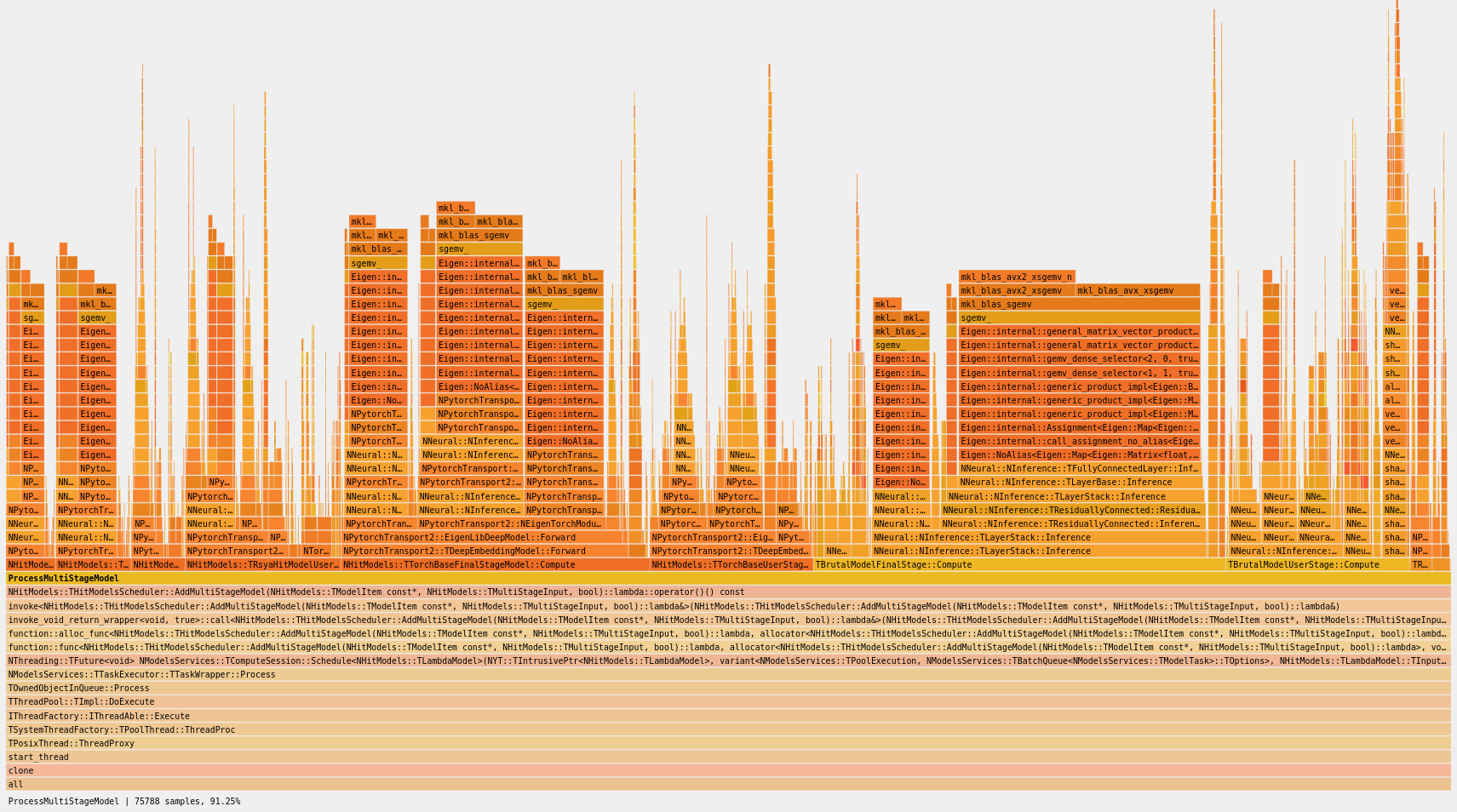
Слева — ПБЧ, справа — perf с флагом --call-graph dwarf
Концепт ПБЧ
Анализ стека гораздо точнее умеют делать отладчики, например GDB. Профайлер, основанный на сэмплировании стека с помощью отладчика, называют Профайлером Бедного Человека.
На сайте упоминается очень важное отличие такого профайлера от того же perf. ПБЧ — это wall-clock профайлер, который позволяет измерять настоящее (а не процессорное) время, проведённое в той или иной функции, включая блокировку на ввод-вывод. Полезность такого профайлера зависит от приложения.
Скомбинировав эти два подхода — «размазывание» сэмплирования по кластеру и сбор стеков с помощью GDB — можно получить весьма точный результат профилирования.
Устройство ПБЧ
В каждом контейнере нашего кластера запущен демон, который просыпается раз в несколько минут в случайные моменты времени и присоединяется к профилируемому процессу с помощью GDB. Затем, пробегаясь по всем тредам по очереди, он останавливает тред, записывает стек и отправляет тред работать обратно. Так минимизируется время остановки программы, а не находящиеся в данный момент под присмотром GDB треды могут продолжать свою работу.
У такой схемы есть приятный бонус — GDB умеет вызывать функции подключенной программы. Это позволяет достаточно просто извлекать произвольную информацию из профилируемого процесса. Такую функциональность мы используем для записи идентификатора обрабатываемого тредом запроса вместе со стеком, что даёт возможность в дальнейшем, поджойнив с другими нашими логами, строить флеймграфы в самых разных разрезах. Например, в разрезе экспериментов, запускаемых на долю трафика.
А теперь немного подробнее. На каждой итерации ПБЧ составляет скрипт для GDB по заданным параметрам, затем запускает и контролирует его безопасное выполнение. Скрипт состоит из двух частей: проставление нужных опций GDB (режим non-stop, опции unwind-on-signal и т. д.), и обход тредов процесса с извлечением требуемой информации. Скрипт запускается в режиме batch, выполнение останавливается при первой неуспешной операции или при превышении тайм-аута на итерацию, а в случае тайм-аута ПБЧ старается изящно завершить работу GDB. Если скрипт выполнен успешно, выход GDB парсится, и собранные данные пишутся в систему доставки логов, где они в итоге сохраняются в виде таблиц в YT.
Можно было бы написать ПБЧ поверх машинного интерфейса GDB или Python API, что ускорило бы его работу и позволило бы сделать его более интерактивным (допустим, тайм-аут на каждую отдельную операцию), но в нашем случае необходимости в этом не было, а текущая реализация получается очень простой — сам профайлер занимает меньше 600 строк кода на Python.
Для полноценной поддержки ПБЧ со стороны профилируемой программы нужно:
- Назвать треды: тредпулы, выполняющие разную работу, желательно должны иметь разные, уникальные имена.
- Проставить нужный стейт для извлечения из GDB.
Стейтом может быть ID запроса или вычисляемой ML-модели, или любая другая информация, в разрезе которой хочется строить флеймграфы.
У нас это выглядит примерно так: после генерации ID запроса, что происходит достаточно рано в его жизненном цикле, мы сохраняем ID в TLS (или coroutine-local storage) и генерируем специальную функцию для подгрузки данного значения — эту функцию как раз и вызываем из GDB на каждом воркер-треде.
Побочные эффекты и безопасность использования ПБЧ в проде
Очевидный минус — время простоя, пока программа находится под присмотром GDB. В нашем случае для сервера со ста тредами одна итерация занимает 10-15 секунд, но и это компенсируется тем, что все треды одновременно не останавливаются: большинство тредов могут продолжать обрабатывать запросы.
Вызов функций из GDB
Возможность вызова функций из GDB может сделать такой профайлер произвольно опасным. И даже если вызывать безобидные read-only функции, могут возникать спецэффекты, так как для совершения вызова GDB приходится менять состояние процесса — создавать dummy frame для исполнения функции и делать для неё адрес возврата, указывающий на инструкцию типа int 3 для передачи управления обратно GDB. Если, например, убить GDB во время такого вызова, процесс продолжит выполняться и в итоге упадёт на инструкции int 3. У нас встречались подобные проблемы. Они случались нечасто, и со временем мы смогли свести их количество к нулю.
Думая о корректности поведения программы под ПБЧ, нужно помнить, что любой вызов из GDB может произойти асинхронно с точки зрения программы. Man-страница про signal-safety содержит рекомендации, подходящие для написания безопасных для вызова из GDB функций.
Наш опыт
По нашим последним замерам, в текущей конфигурации запуска ПБЧ при пиковой нагрузке мы платим одним процентом ёмкости и небольшим ростом p999+ перцентилей времени ответа сервиса. Есть два простых способа минимизировать дополнительное потребление ресурсов:
- Ограничиться сэмплированием подмножества тредов, наложив фильтр на их имя. В нашем случае мы ограничиваемся воркер-тредами, непосредственно выполняющими запросы.
- Снизить частоту сэмплирования.
Эти результаты специфичны нашему приложению и могут сильно зависеть от профилируемого процесса. Это в том числе касается и объёма потребляемой памяти ПБЧ, где в первую очередь влияет размер дебажной информации, которую GDB нужно обработать для развёртывания стеков.
Скорость обхода стеков и потребление памяти можно дополнительно контролировать уровнем дебажной информации в бинарнике: первый уровень (-g1) содержит всю необходимую информацию и позволяет GDB сильно быстрее разворачивать стеки больших бинарников.
Наша текущая система
Как у нас используется ПБЧ
У нас есть два регулярных процесса, которые строят отчёты с флеймграфами. Первый процесс строит флеймграфы, сравнивающие новый релиз со старым. Такие отчёты помогают локализовать и выявлять проблемы в новом релизе, да и это просто полезный sanity-check перед подтверждением очередного релиза. Второй процесс строит флеймграфы со всего продакшена за последние несколько часов, день или неделю. Эти отчёты помогают понять, как меняется профиль нагрузки со временем.
Помимо регулярных отчетов, часто бывает полезным построить флеймграф на срезе трафика, например на конкретных экспериментах, страницах или для определённого типа объявлений. Для самых востребованных сценариев есть удобный способ построения флеймграфов по простому конфигу, в котором можно указать разные, но заранее заданные условия для сужения рассматриваемого трафика. Этот способ покрывает бо́льшую часть сценариев построения флеймграфов.
В случае более сложных срезов можно написать SQL-подобный запрос поверх таблиц с результатами профилирования и опционально поджойнить с другими таблицами по идентификатору запроса, оставляя только подходящие сэмплы. Так можно построить, например, флеймграф только по запросам, которые работали дольше 300 миллисекунд.
Где мы используем ПБЧ
Мы используем ПБЧ в нескольких сервисах, в основном в движке баннерной крутилки и смежных с ним ML-микросервисов — они как раз больше всех потребляют CPU. Суммарно это сотни тысяч ядер, поэтому даже один процент сэкономленного CPU в этих сервисах может освободить ресурсы под новые внедрения.
Все профилируемые программы написаны на C++ и собираются стандартной сборкой нашего монорепозитория с включением дебажной информации.
Флеймграфы и визуализация результатов
Для визуализации результатов работы профайлера обычно используются флеймграфы, в которых:
- Ось Y показывает глубину стека, фреймы идут снизу вверх в порядке возрастания вложенности.
- Порядок фреймов по оси X произвольный. Ширина фрейма пропорциональна доле попаданий сэмплов в него.
- Цвета выбираются случайно из определённой цветовой гаммы.
Эту картинку вы уже видели
Дифференциальные флеймграфы
Часто бывает полезным сравнить два профиля: старый/новый релиз и включенная/выключенная фича. В таких случаях оказываются полезными дифференциальные флеймграфы, в основном отличающиеся от обычных покраской. Форма флеймграфа строится по первому профилю так же, как для обычных флеймграфов. Дальше нормализуется количество сэмплов в обоих профилях, и производится покраска по следующему принципу: красный цвет соответствует приросту количества сэмплов во втором профиле относительно первого, синий — уменьшению. Чем больше разница, тем насыщеннее цвет.
Такая покраска имеет свойство распространяться вниз по дереву или вверх, как в нашем случае. Предположим, функция A каждый раз вызывает функцию B, и мы по какой-то причине начинаем реже вызывать функцию A. Тогда может получиться, что B будет покрашена в синий цвет, даже если она деградировала по производительности. Поэтому мы добавили другой способ покраски, в котором считается доля попаданий во фрейм относительно родительского. Оба способа доступны в флеймграфе и называются absolute и relative. Выбрать между ними можно с помощью переключателя в самом низу флеймграфа.
Пример флеймграфа, где можно посмотреть сравнение нового релиза со старым:
Кликабельно
Интерактивность
Флеймграфы интерактивны, они представляют собой SVG, встроенный в HTML. Если навести указателем мышки на фрейм, можно увидеть количество и долю попавших в него сэмплов. Нажав на фрейм, можно более детально изучить его поддерево. Также здесь реализован поиск по фреймам, он активируется с помощью Ctrl+F.
Кликабельно
В первой инкарнации для отрисовки флеймграфов мы использовали стандартный скрипт flamegraph.pl. Но получающиеся на выходе флеймграфы часто тормозили при большом количестве фреймов, и в итоге мы написали собственную отрисовку с более отзывчивыми флеймграфами.
Недостатки
У флеймграфов есть и минусы — очень просто не заметить деградацию в функции, разбросанной по разным веткам флеймграфа.

Кликабельно
Результаты могут зависеть от нагрузки и от других труднопредсказуемых факторов. Достаточно просто сделать неправильные выводы относительно производительности программы.
Часто возникает соблазн делать количественные выводы, например, что функция стала в n раз медленнее, исходя из дифференциальных флеймграфов. Но такие выводы, скорее всего, некорректны, и лично я воспринимаю дифференциальные флеймграфы как удобный инструмент, который в первую очередь помогает ответить на вопрос, где произошла деградация, а не насколько она сильная.
| Оказывает влияние по CPU на исполняемую программу | Не требует сборки с -fno-omit-frame-pointer | Интеграция с A/Б-экспериментами |
Отсутствуют побочные эффекты на исполнение программы | |
| perf на одном хосте с частым сэмплированием | + | – | – | + |
| perf на множестве хостов с редким сэмплированием | – | – | – | + |
| ПБЧ | – | + | + | – |
Заключение
Мы не думаем, что в задаче профилирования есть «серебряная пуля» — и потому считаем важным делиться своим опытом в эксплуатации таких систем.
В нашем случае Профайлер Бедного Человека незаменим. На этапе пул-реквеста разработчик может запустить нагрузочные тесты и увидеть отчёт в виде дифференциального флеймграфа. При релизе такие флеймграфы быстро помогут локализовать возможную проблему на престейбле. В A/Б-эксперименте, неожиданно повлиявшем на производительность, ПБЧ поможет ретроспективно найти узкое место. Наконец, флеймграфы — незаменимый инструмент разработчика, который оптимизирует большой сервис.
Мы планируем и дальше улучшать систему профилирования, повышая точность и упрощая эксплуатацию. Будем глубже интегрировать отчёты с флеймграфами в наши внутренние инструменты, например в анализы экспериментов и тестирования миграций — но не только. И спасибо моим соавторам Sarkin и ulyanin за то, что вложили в проект и в статью время и силы.
GloveRyba
perf в режиме сбора dwarf стеков (--call-graph dwarf) не требует пересборки кода. Дополнительно можно поэкспериментировать с размером собираемого стэка и включить компрессию (--compression-level).
poldnev Автор
Да, с
--call-graph dwarfтоже тестировали. На второй картинке правая часть (с неразмеченными функциями и отсутствующими фреймами) как раз собиралась в этом режиме.Подписали для ясности.