
Играли ли вы когда-нибудь в школьные годы в «испорченный телефон»? Первый человек шепотом произносил слово второму, тот тихо передавал его третьему, и так далее, и так далее. В конце очереди последний человек громко объявлял услышанное изречение, и, увы! Оно превращалось в какое-то новое выражение, совершенно непонятное по сравнению с первоначальным. Именно так можно представить себе жизнь без инженера-аналитика в вашей команде.
Итак, предположим, что у вас есть бизнес-вопрос, исходные данные в вашем хранилище, а dbt уже запущен и работает. Вы находитесь в идеальном положении, чтобы быстро завершить работу над этим подготовленным датасетом! Или нет?
Между вами и финальным набором данных стоят три шага. Если у вас нет инженера-аналитика, то работа может быть распределена следующим образом:

На первом этапе ваш специалист по анализу (аналитик) начнет изучение запроса стейкхолдера (заинтересованной стороны) и попытается свести его к наиболее резонансной задаче, которая будет способствовать развитию бизнеса. Например, вопрос может звучать следующим образом:
«Нам нужно иметь возможность отслеживать процесс потребления нашего продукта, и мы хотели бы получать некоторые данные об активных пользователях».
Аналитики являются экспертами в вопросах интерпретации общих утверждений в конкретные задачи.
«Некоторые данные» могут означать:
Один KPI (Key Performance Indicator. Ключевой показатель эффективности) с трендлайном в динамике.
Дашборд, разделенный на различные категории.
Таблица с фильтрацией и возможностью запроса для специального анализа.
«Активные пользователи» может означать:
Пользователи, которые авторизовались в течение определенного периода времени.
Пользователи с сессией дольше определенного времени.
Пользователи, которые пользовались конкретным функционалом.
После этого специалист по анализу составит исходную документацию и опишет, как должен выглядеть конечный набор данных. Если ваш специалист не обладает квалификацией инженера-аналитика, именно в этот момент ему необходимо передать проект инженеру по данным для построения модели.
В первый раз, когда команда специалистов по анализу и инженеров по обработке данных создает курированный датасет, они зачастую ожидают, что эта процедура будет идти по некоему прямому пути к завершению. Предполагается, что процесс будет выглядеть примерно так:
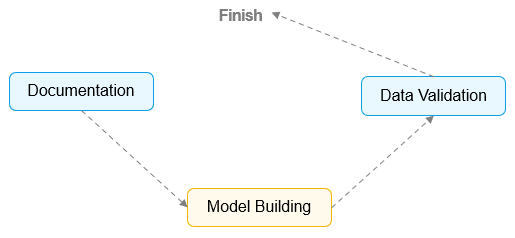
Вскоре становится очевидным, что такая убежденная нацеленность на линейность процесса часто приводит к образованию трех непредвиденных "петель/циклов":
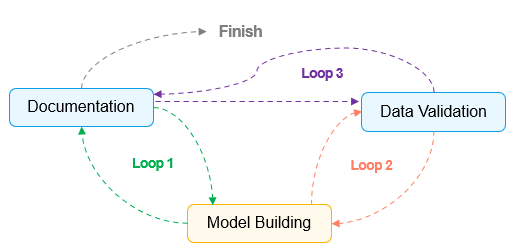
Цикл 1: Реагирование на выводы в необработанных данных
Допустим, ваш аналитик определил бизнес-потребность как датасет Active Users с "Уникальными пользователями, которые авторизовались в течение определенного дня". Он постарается предварительно проделать как можно больше исследовательской работы, поскольку трудно предсказать, что именно вы обнаружите в исходных данных. Когда инженер по данным испытывает затруднения при написании модели, он должен обратиться к аналитику для получения дополнительных сведений. Когда у специалиста по анализу (аналитика), который уже стал инженером-аналитиком, возникает вопрос в процессе написания модели, ему не нужно дожидаться обсуждения проблемы с кем-либо, и он может сразу же приступить к ее изучению. Это подводит нас к первому пункту:
Аналитики уже знают, какие данные им нужны.
Если исходный датасет Login, представленный ниже, содержит два разных поля даты (Login_Date и Session_Date), инженер по обработке данных окажется в затруднительном положении. Им нельзя просто так строить какие-то догадки, потому что использование неправильного поля даты приведет к созданию совершенно другой метрики! Поэтому они должны вернуться к аналитику и уточнить, какое поле следует использовать. Только что мы получили полный цикл с двумя вариантами передаваемых функциональных действий, а инженер по данным еще даже не приступил к построению модели.
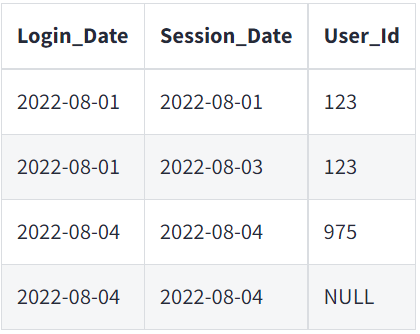
Для сравнения, ваши новоявленные инженеры-аналитики могут быстро перестроиться на основе выводов, сделанных в исходных данных. Они могут пропустить бесконечные циклы "открытия", потому что способны среагировать мгновенно. Увидев два поля даты для Login_Date и Session_Date, они могут моментально применить свои знания о продукте, сравнить с примерами или обратиться к своим бизнес-контактам, чтобы определить разницу и выбрать правильную дату для модели.
Если существует производственная необходимость в просмотре активных пользователей Active Users по группам Groups A, B, and C, то это добавляет дополнительный уровень сложности. Без инженера-аналитика у вас будут появляться дополнительные циклы и процессы передачи полномочий для доработки всей бизнес-логики, обработки NULL-значений и даже просто определения окончательного формата.
Формат модели, полученный с помощью инжиниринга данных
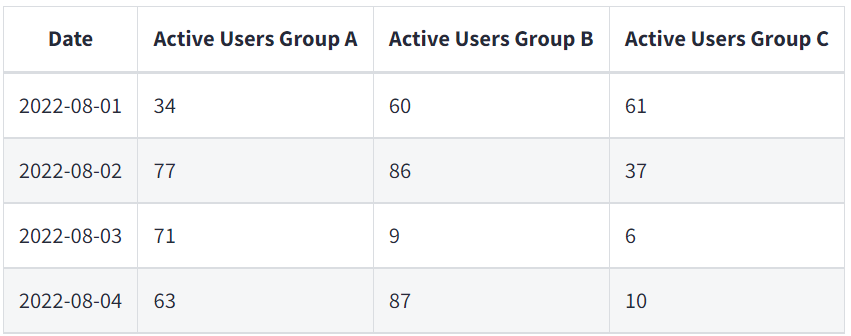
Формат модели, необходимый для работы инструмента BI (Business Intelligence)
Цикл 2: Реагирование на неожиданные результаты
Аналитики являются первой (а иногда и единственной) линией обороны для выявления проблем с качеством данных. Как только датасет сводится к одиночному значению для ответа на бизнес-вопрос, зачастую невозможно определить, не был ли использован неправильный фильтр или неверный набор логики.
Когда модель строится впервые, все стороны часто "не знают того, что им неизвестно". По мере того, как специалист по анализу будет копаться в курированном датасете, он обнаружит обновления, которые необходимо внести в модель. Отсюда вытекает наш второй пункт:
Аналитики ставят под сомнение все.
Group A для Active Users может быть сфокусирована на ролях участников Participant.
Стейкхолдер объяснил аналитику, что хочет исключить любых администраторов Admins, которые по-другому будут работать с продуктом.

Инженер по обработке данных, работающий на основе "списка сборки", добавит фильтр для WHERE Role = 'Participant'. На этапе проверки данных аналитик обнаружит, что на самом деле существует третья роль Role - редактора Editor, о которой никто не знал. Это создало бы цикл, в котором дата-инженеру пришлось бы редактировать модель, чтобы заменить в ней WHERE Role != 'Admin'.
Аналитик обнаружил проблему, потому что у него есть соответствующий контекст для валидации датасета. Они работают непосредственно со стейкхолдером, поэтому лучше знакомы с аббревиатурами, характерными для конкретной компании и отдела.
Как мы все знаем, валидация данных — это искусство, а не наука. Специалисты по анализу применяют всевозможные методы, начиная от "снифф-теста" (просмотр рандомной выборки строк) и заканчивая отдельными примерами (точное сопоставление один к одному с другой системой). Специалист должен использовать свой опыт, чтобы понять, когда датасет "достаточно хорош" для стейкхолдера и его запроса, поскольку точность на 100% может оказаться нецелесообразной. И, если быть честными, иногда для принятия бизнес-решения достаточно лишь выбрать правильное направление.
Аналитик способен определить, какие области не нуждаются в 100% точности, следовательно, он также может выявить, какие из них должны быть на 100% точными.
dbt позволяет очень быстро добавлять тесты для проверки качества данных. На самом деле, это происходит так быстро, что аналитику потребуется больше времени, для того, чтобы описать, какие тесты они хотят, чем просто по факту закончить написание кода.
Когда в бизнесе возникают проблемы с качеством данных, у аналитиков первым делом спрашивают:
Почему больше половины идентификаторов User_Ids теперь отображаются как NULL?
Почему эта диаграмма показывает местоположение Location пользователя не в США?
Почему фильтр дашборда говорит, что все зоны Zones пользователя — это зона 2?
Осознание того, какие типы проблем качества данных являются наиболее важными для бизнеса, означает, что аналитик зачастую способен заранее определить, какие из автоматизированных тестов следует добавить в дата-модель.
Цикл 3: Реагирование на несоответствующую документацию
Нет ничего хуже, чем вернуться к просмотру курированного датасета спустя несколько месяцев (или, возможно, после того, как кто-то из команды был уволен) и узнать, что в документации не содержится ничего, объясняющего, почему существует определенная логика. Или, что гораздо ужаснее, документация существует, но она больше не соответствует тому, что на самом деле делает модель. Это подводит нас к третьему и последнему пункту:
Аналитики понимают всю тяжесть ситуации, когда датасет не задокументирован должным образом.
Намного проще следовать руководству по именованию, когда автор глубоко разбирается в данных и в том, как на них ссылаются в бизнесе. Стейкхолдеры часто задают аналитикам схожие вопросы, что является дополнительным стимулом для создания с самого начала качественной документации.
Дата-инженер будет документировать датасет на основе того, что требовалось знать для его создания. Специалист с навыками аналитического инжиниринга будет документировать набор данных, исходя из того, как его использовать в дальнейшем.
Если необходимо узнать, как технически была построена определенная логика, мы можем ориентироваться на SQL-код в документации dbt docs. Если мы хотим знать, почему определенная логика была встроена в эту конкретную модель, то в этом случае следует обратиться к документации.
-
Пример не особенно полезной документации (dbt docs может создавать ее динамически):
Case when Zone = 1 and Level like 'A%' then 'True' else 'False' end as GroupB
-
Пример улучшенной, более описательной документации (добавьте в ваш dbt-файл markdown или описания столбцов):
Группа B определяется как пользователи в зоне 1 с уровнем, начинающимся с буквы 'A'. Эти пользователи получают доступ к нашему новому дополнительному продукту, бета-версия которого стартовала с августа 2022 года. Рекомендуется отфильтровать их из основной метрики активных пользователей Active Users.
Во втором примере документация написана с учетом интересов стейкхолдера и бизнеса, а аналитики выступают в роли экспертов по переводу технического языка в обычный.
Теперь вы убедились?
Научите своего специалиста по анализу быть инженером-аналитиком, чтобы он смог самостоятельно строить модели для курированных датасетов. Вы увидите, как этот процесс превращается в несколько небольших итераций, поскольку они добавляют поля и тестируют их по мере создания. Никаких циклов, никаких передач полномочий и никаких "испорченных телефонов". Ваш новый рабочий процесс будет выглядеть примерно так:

Вместо того чтобы пытаться определить все различные группы Active Users одновременно, инженер-аналитик может осуществлять валидацию строк Group A, одновременно добавляя Group B в свою локальную среду и продолжая работать со стейкхолдером над определением Group C.
Все это означает, что: ваш специалист по анализу, превратившийся в инженера-аналитика, — это ключ к быстрому созданию курированных датасетов с качеством данных и документацией нового уровня.
Как повысить квалификацию аналитиков?
Вот несколько шагов, которые помогут вам начать превращение ваших специалистов по анализу в инженеров-аналитиков:
Многие аналитики уже умеют составлять запросы к данным с помощью операторов SQL Select. Для тех, кому это не удается, необходимо попробовать начать получать данные для специальных запросов с помощью SQL. Попросите их сравнить некоторые распространенные преобразования в вашем BI-инструменте с функциями SQL или перестроить их с помощью CTE. Это подготовит их к изучению моделей dbt SQL.
Начните включать экспертную оценку как часть процесса публикации дашборда. Кроме того, подумайте о том, как вы настраиваете окружение дашборда (есть ли у вас локальная область разработки, область рецензирования и область публикации?). Это подготовит их к изучению Git, сред разработки и контроля версий.
Поговорите с аналитиком о том, как он принимает решение о создании предупреждений в BI-инструменте, или о регулярных проверках существующих дашбордов на предмет точности данных. А также о том, какой практике управления данными следует каждый дашборд (словарь данных? руководство по стилю?). Это подготовит их к изучению dbt-файла
.yml.
Приглашаем всех желающих на открытое занятие «Почему БД прилегла отдохнуть или вопросы оптимизации производительности». На занятии узнаете:
— О том, какие проблемы с производительностью будоражат хранителей DWH;
— Изучите существующие подходы, ключевые принципы и практики оптимизации;
— Поймете, как легко положить базу данных (конечно же для того, чтобы так не делать).