
Проблема выбора формата файла, с которым предстоит работать для чтения и записи pandas.DataFrame, заключается как раз в том, что есть из чего выбрать: даже сам pandas включает в себя функционал, позволяющий работать с большим перечнем типов файлов. Обилие доступных для данной задачи форматов обусловлено невозможностью решить проблему импорта/экспорта раз и навсегда: ничего идеального, как и формата для хранения данных, к сожалению, не существует, поскольку даже самый, на первый взгляд, оптимальный и минимально затратный по ресурсам pickle способен создать очень много проблем.
Чем плох pickle?
Данный формат самый быстрый, занимает меньше всего размера и требует меньше всего памяти. Также pickle не требует преобразование изменяемых типов данных, объектов классов при импорте и экспорте. Однако такие хорошие показатели по затратам ресурсов обусловлены особенностями, перекрывающих все достоинства этого формата:
не безопасен. Pickle осуществляет десериализацию объекта из потока байтов, не проверяя поток распакованных данных, есть риски считывания вредоносного кода из файла;
привязан к python и зависим от его версии;
объекты должны быть определены в среде (функции, классы).
Какая альтернатива?
Для того, чтобы понять, чем заменить pickle с наименьшими потерями по эффективности с точки зрения затраты ресурсов, было проведено исследование для нескольких кейсов:
числовые данные (int, float);
строки;
смешанные данные (int, float, bool, string, datetime, category);
изменяемые типы данных (list, set, tuple, dict, класс).
Для исследования были выбраны следующие форматы файлов, расскажем о них подробнее.
CSV
CSV – текстовый формат файла, не является стандартом. Csv файл легко сломать: достаточно записать неподдерживаемый символ или не заключить зарезервированные символы в кавычки. Проблемы с импортом возникнут, если в файл было записано пустое поле и если данные были заключены в кавычки. CSV-файл не имеет стандартных способов представления двоичных данных. Данный формат хорошо себя показывает при работе со строками, но не все типы данных десериализует корректно. Поддерживается pandas, отдельных библиотек не требует.
Feather
Бинарный формат. Зависит от Arrow, но независим от языка: экспортировать файл можно средствами Python, а импортировать с помощью R. поддерживает только неизменяемые типы данных и не нуждается в их дополнительной сериализации и десериализации, в связи с чем показывает неплохие результаты при работе с кейсом с разными форматами неизменяемых типов данных.
Pandas включает функционал работы с данным форматом, однако требуется подключение pyarrow.
Msgpack
Бинарный формат, похож на JSON, но занимает значительно меньше места на диске. Имеет ограничения по размеру записываемых данных – 64 бита. Требует преобразования датасета в словарь при записи и восстановлении из словаря при распаковке соответственно. Дополнительного преобразования типов не требует при записи, однако десериализацию необходимо прописать отдельно. Хорошо себя показывает при работе с изменяемыми типами данных.
Не поддерживается pandas напрямую, для работы с данным форматом необходимо подключение библиотеки msgpack.
JAY
Jay – бинарный формат. Для записи датасета необходимо преобразование в datatable.Frame и обратно для чтения соответственно. Демонстрирует хорошие результаты при работе с числовыми данными, а также с изменяемыми типами данных. Требует подключение пакета datatable, при импортировании на Window могут возникнуть проблемы.
Parquet
Parquet - бинарный, колоночно-ориентированный формат хранения данных, является независимым от языка. В каждой колонке данные должны быть строго одного типа. Parquet предоставляет возможность считывать не целиком весь файл, а только одну колонку, что может значительно минимизировать показатели ввода-вывода. Данный формат отлично справляется с сериализацией и десериализацией данных, если датасет содержит данные только неизменяемых форматов. Parquet показывает высокую производительность на датасетах со строковыми данными, а также неплохо справляется с точки зрения потребления ресурсов с изменяемыми типами данных. Функционал для работы с данным форматом поддерживается pandas.
HDF
HDF – формат, позволяющий хранить данные в иерархической структуре, сохранять метаданные для каждого объекта данных. Данный формат поддерживает организацию файла группами связанных данных и фрагментарное чтение и запись. В функционале HDF реализован автоматический подсчёт контрольных сумм для проверки целостности данных. Поддерживает несколько способов сжатия данных. В спецификации указано, что данный формат предназначен для хранения больших данных; на тестах данного исследования показал себя плохо практически во всех тестах, однако порой занимал лидирующие позиции по одному-двум критериям. Поддерживается pandas.
NPY
NPY – бинарный файл для хранения одного произвольного NumPy-массива на диске. Формат хранит всю необходимую информацию о форме и типе данных для правильного восстановления массива в т.ч. на другой машине с другой архитектурой. Возможно использование исключительно с массивами numpy, так что в тестах использовался только в кейсе с датасетом с числовыми данными. Не требует сохранения и восстановления типов данных при записи и чтении соответственно, однако необходимо преобразовать выходные данные для сохранения датасета, в том числе и имена колонок. Поскольку данный формат создавался специально для хранения числовых данных, в кейсе с датасетом, состоящем из данных типа int и float показал отличные результаты. Для использования необходим импорт библиотеки numpy.
В рамках данной задачи сравнивались показатели для каждого типа файла по следующим параметрам:
время чтения и время записи;
количество оперативной памяти, требующееся для чтения и для записи файлов соответственно;
размер файла на диске.
При оценке времени и памяти учитывалось время в том числе и на преобразование типов, сохранение названий колонок для тех файлов, для которых это необходимо, чтобы получить показатели времени и памяти, необходимых не только для непосредственно чтения или записи файла, но еще и для подготовки и восстановления датасета, так сказать, под ключ.
Как уже было отмечено выше, задача решалась на нескольких типах датасетов, содержащих
только числовые данные (int, float);
только строковые данные;
данные неизменяемых типов (int, float, string, bool, datetime, category);
данные изменяемых типов (list, set, tuple, dict, класс).
Для каждого типа датасетов было произведено 100 итераций, в каждой из которых типы данных столбцов генерировались случайным образом исходя из доступного множества, значения элементов также генерировались случайно. Размер датасета: 100 колонок, 10000 строк для всех неизменяемых типов данных и 50 колонок, 1000 строк для изменяемых, что обусловлено бОльшими временными затратами.
Числовые данные
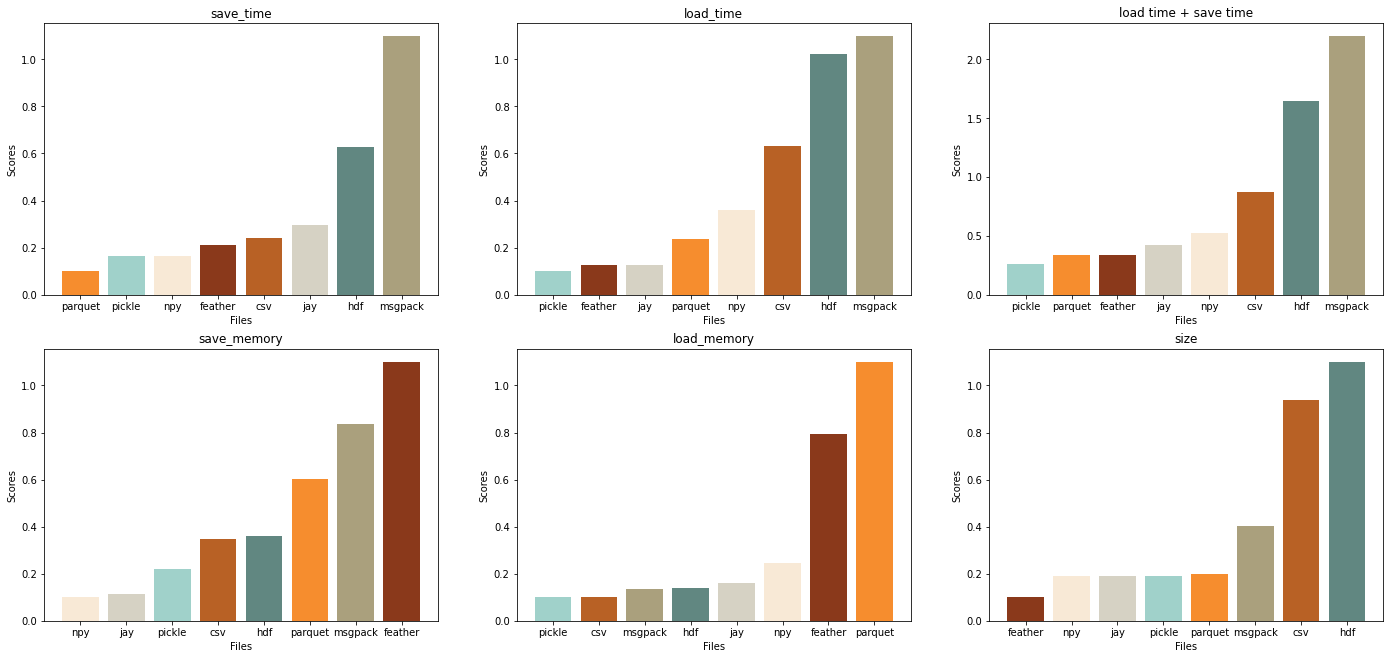
С числовыми данными лучше всех справились jay и npy.
Npy лучше, если необходимо многократно записывать, jay тратит меньше ресурсов на чтение. jay выигрывает npy, если хранить большие объемы данных, но незначительно.
Feather среди всех рассмотренных файлов занимает меньший объем места на диске и больше подойдет, если нужно хранить большие объемы данных, однако требует много памяти и при чтении, и при записи.
Feather, parquet стоит использовать в том случае, если важно время, но не важно потребление памяти, при этом
при многократной записи предпочтительнее parquet;
при многократном чтении предпочтительнее feather.
Притом, что csv не показывает сильно плохих результатов по времени и памяти, на диске он занимает значительно больше места, чем его конкуренты.
Суммарные результаты:
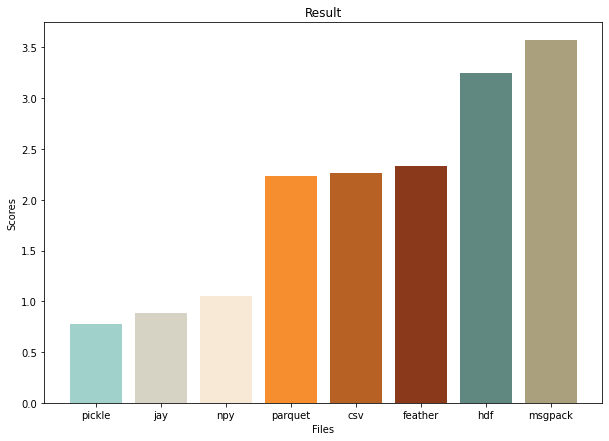
Вывод: для датасетов из чисел предпочтительнее использовать форматы jay и npy; hdf и msgpack использовать не стоит, остальные форматы имеют опциональные преимущества.
Строковые данные
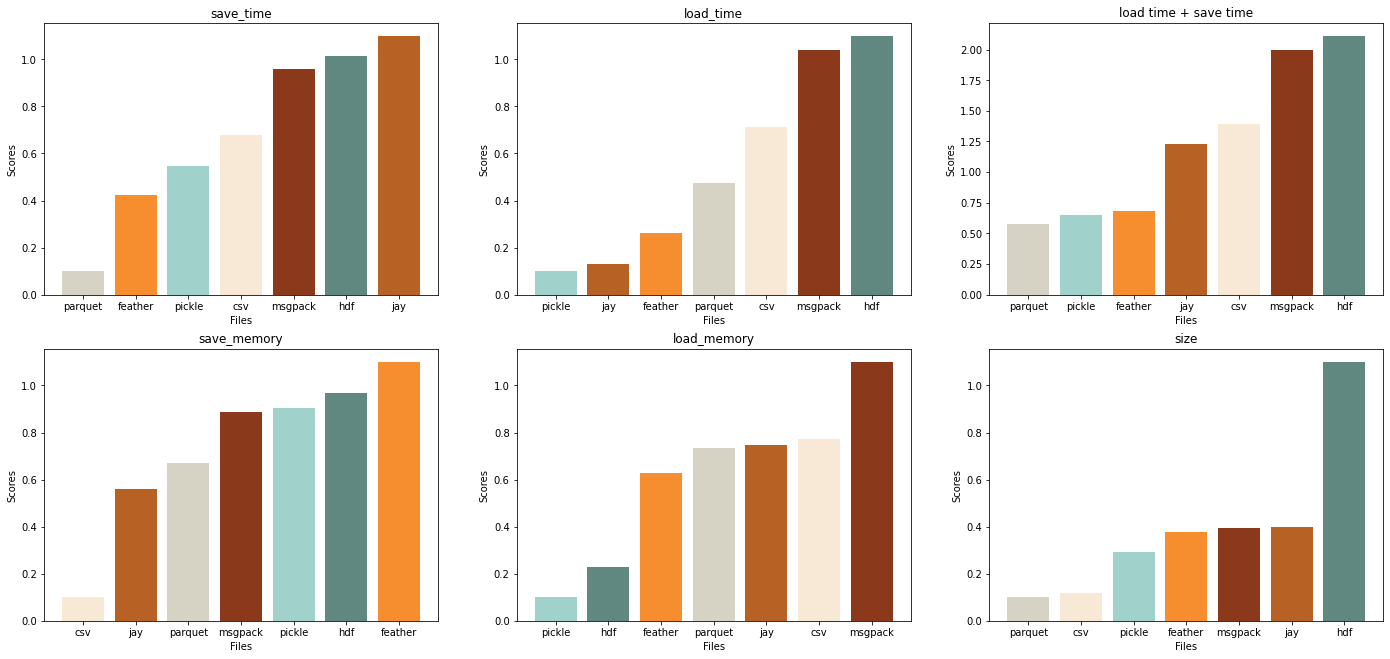
На строковых данных hdf и msgpack плохи, результаты сильно хуже, чем у всех остальных файлов, их точно не стоит использовать для датасета из строк.
Притом, что во всех остальных случаях pickle показывает преимущественно лучшие результаты по всем показателям, в работе со строковыми данными pickle чувствует себя значительно хуже.
Parquet и feather хороши по времени чтения и записи (результаты сравнимы с pickle), остальные форматы по сравнению с ними плохи.
Parquet и csv значительно лучше остальных рассматриваемых форматов по размеру файла, при этом csv лучше, чем parquet, по потреблению памяти, но хуже по времени.
Csv лучше использовать в случае, если надо часто сохранять при минимальных затратах памяти.
Hdf сильно лучше остальных форматов по потреблению памяти, если есть необходимость часто считывать файл и нет жестких ограничений по времени, в противном случае (нужно быстро и неограничена память) предпочтительнее jay.
Но оптимальнее при большом количестве считываний использовать feather, поскольку и по памяти, и по времени он неплохо выглядит по сравнению с другими форматами.
Также для частого чтения файла подойдет и parquet, поскольку его результаты хотя и немного хуже, но сравнимы с feather по памяти и времени, а также он занимает меньше места на диске.
Суммарные результаты:
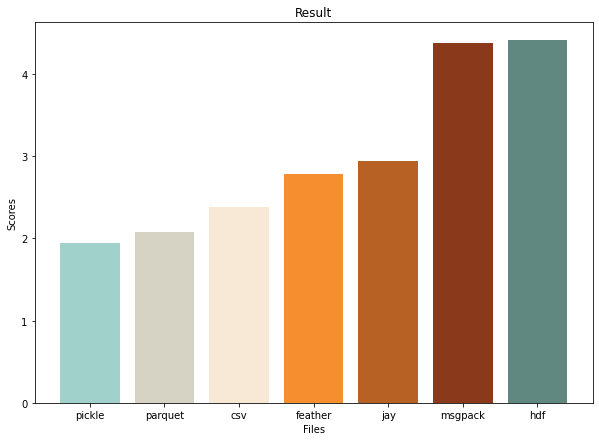
Вывод: лучше всех с работой со строковыми датасетами себя показывают parquet и csv; msgpack и hdf точно не стоит использовать; feather и jay выдающихся результатов не показали.
Данные неизменяемых типов
Типы: int, float, bool, string, datetime, category

В случае с данными разных неизменяемых типов выбора немного больше: в этом кейсе лидеры feather, jay и csv.
Среди лидеров feather лучше по размеру файла на диске, а также его стоит выбрать, если нужны минимальные затраты по времени чтения и записи и есть много памяти. Однако памяти feather требует больше почти всех своих конкурентов.
Csv лучше в противоположной ситуации: если мало памяти и временные затраты не сильно важны.
Для частой записи файла предпочтительнее jay и по времени, и по памяти, но по суммарному времени он хуже feather больше, чем в 3 раза.
Parquet лучше, если редко считывать и редко записывать, но хранить нужно много данных, при этом результаты по времени у этого формата лучше, чем у csv.
Видно, насколько сильно hdf отстает по размеру файла от своих конкурентов. Если важен именно этот критерий, hdf – худший вариант.
Суммарные результаты:
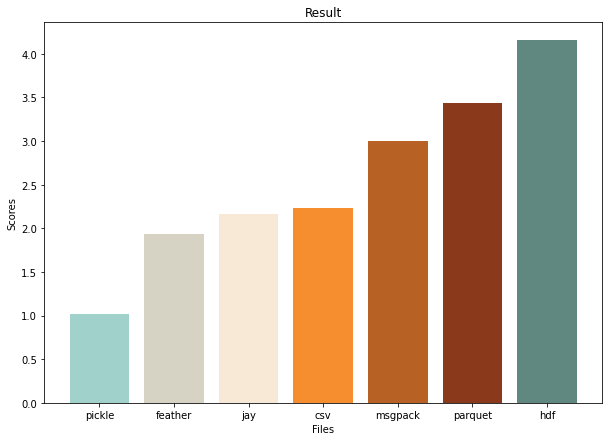
Вывод: если работать с датасетами разных неизменяемых типов данных, то лучше выбирать feather, jay и csv, опционально parquet.
Изменяемые типы данных
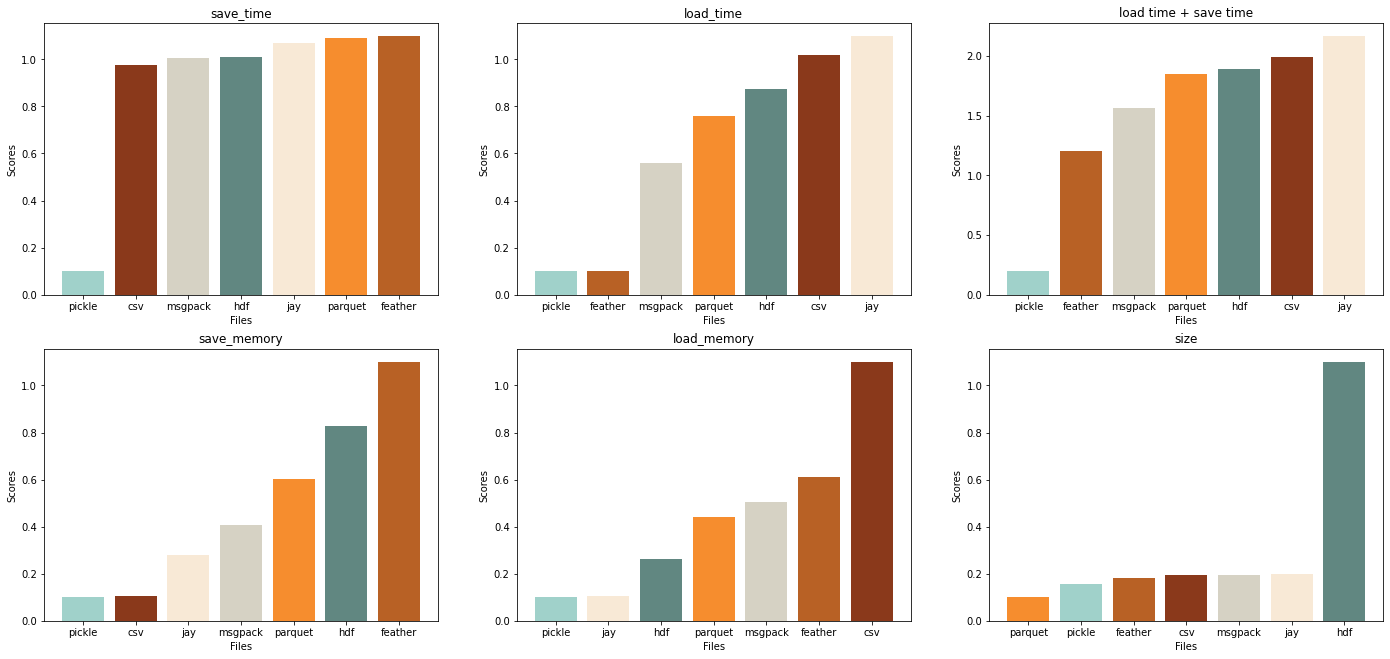
В случае изменяемых типов данных сериализация и десериализация требуется для всех форматов, (кроме pickle, который мы не рассматриваем).
Заметно, что показатели по времени записи у всех файлов примерно похожи, но feather вырывается вперед за счет маленьких временных затрат на чтение. Также feather лучше, если важно время чтения+записи и не важна память.
Формат jay – лучшее решение, когда мало памяти и когда не важны затраты по времени.
Сsv и msgpack лучше, когда надо часто записывать файл. При этом csv проигрывает всем форматам по ресурсам, требуемым для чтения, и выигрывает всех по ресурсам, требуемым для записи.
Msgpack оптимален по времени чтения и записи, а также по использованию памяти.
parquet лучше, если нужно хранить большие объемы данных и если есть необходимость часто читать файл.
Формат hdf вновь сильно плох по размеру файла, по остальным критериям - средние результаты.
Суммарные результаты:
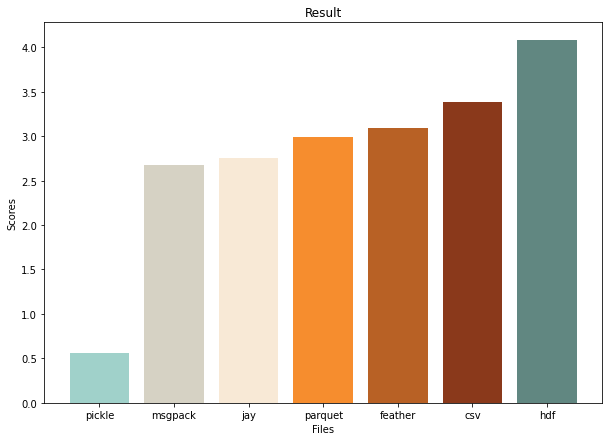
Вывод: для хранения изменяемых типов данных подойдут msgpack, parquet и jay. Csv и feather имеют некоторые преимущества, которые тоже могут быть полезны.
Заключение
Pickle за счет своих особенностей идеален почти по всем показателям для всех типов датасетов, рассмотренных в рамках этой задачи. Этот формат – лучший для использования, если безопасность не важна и исключена возможность влезть в код для злоумышленника.
Выбор формата сильно зависит от того, хранение данных какого формата планируется, а также от доступных ресурсов. Ниже приведена итоговая таблица с результатами для каждого критерия при условии, что остальные не важны.
Числа |
Строки |
Разные типы |
Изменяемые форматы |
|
Оптимальное решение |
jay |
parquet |
feather |
msgpack |
По времени |
parquet |
parquet |
feather |
feather |
По памяти |
csv |
jay |
csv |
jay |
По размеру на диске |
feather |
parquet |
parquet |
parquet |
При многократной записи |
parquet |
parquet |
jay |
parquet |
При многократном чтении |
feather |
feather |
feather |
csv |
Литература
https://docs.python.org/3/library/pickle.html
https://arrow.apache.org/docs/python/feather.html
https://thephp.website/en/issue/messagepack-vs-json-benchmark/
https://github.com/msgpack/msgpack/blob/master/spec.md
https://bawaji94.medium.com/feather-vs-parquet-vs-csv-vs-jay-55206a9a09b0
https://datatable.readthedocs.io/en/latest/api/frame/to_jay.html
https://softwaremill.com/big-data-and-parquet/
https://www.upsolver.com/blog/apache-parquet-why-use
https://www.neonscience.org/resources/learning-hub/tutorials/about-hdf5…
https://medium.com/nuances-of-programming…
https://medium.com/@black_swan/pandas-i-o-benchmarking-56cd688f832b
https://www.kaggle.com/code/pedrocouto39/fast-reading-w-pickle-feather-parquet-jay
https://towardsdatascience.com/the-best-format-to-save-pandas-data-414dca023e0d
Комментарии (2)

Ulrih
04.12.2022 13:10если нажать на диаграммы то видно только значения на белом фоне а оси както сильно прозрачные.
xamal
Размер датасета не имеет значения?