
Этот пост я решил написать, для тех, кто также искал понятный код и рабочий пример, который можно было взять, вставить в гугл колаб(google colab) и сразу начать "играться" с кодом. Но не нашел. Для вас, друзья!
P.S весь код будет в конце.
Импортируем бэкэнд кераса, по началу, мы его использовать не будем, но некоторые функции нам понадобятся
import tensorflow as tfИмпортируем сам пакет машинного обучения , его и будем использовать.
import kerasМатематические функции которые нам тоже понадобятся.
import numpy as npБиблиотека для вывода изображений.
import matplotlib.pyplot as pltДля чего эта строчка? - нагуглите сами.
%matplotlib inlineИмортируем слои, вернее классы слоёв для нашей нейронной сети.
from keras.layers import Dense, FlattenИмпорт нашей последовательной модели.
from keras.models import SequentialИмпортируем набор данных MNIST для нашего обучения.
from keras.datasets import mnistЗагружаем данные функцией load_data из названия нашего датасета mnist и разделяем наш датасет на тренировочную выборку и тестовую.
(X_train, y_train), (X_test, y_test) = mnist.load_data()Давайте посмотрим, что за изображения у нас и в какой они форме.
print(X_train.shape)
Вот, мы видим, что X_train представляет из себя массив данных с 60000 экземпляров картинок, которые имеют разрешение 28 на 28.
Теперь давайте посмотрим , что такое y_train.
print(y_train.shape)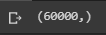
Мы видим , что это просто массив из 60000 значений не и более того.
А теперь давайте посмотрим, что же именно храниться в массивах, если X_train - массив изображений, давайте откроем одно!
Выводим 12 изображение из массива, и это цифра 3
plt.imshow(X_train[12], cmap='binary')
plt.axis('off')
print(y_train[12])
Вот мы и видим цифра 3 и картинку с цифрой 3!
Как вы все знаете, значение пикселя может быть от 0 до 255, и если мы будем подавать в нейронную сеть такие данные. Пиксель со значением 0 и пиксель со значением 255 имеют очень разные масштабы значений. Нам очень тяжело будет учить модель.
И чтобы их "нормировать", чтобы они были от 0 до 1 в идеале, мы разделим все наше "добро" на 255.
0 / 255 = 0 , 255 / 255 = 1, а любое число в диапазоне от 0 не до 255 будет просто дробью.
X_train = X_train/255
X_test = X_test/255Вот что мы получили:
print(y_train[0])
К сожалению, нельзя дать нейронке фото и сказать что это цифра 4, нужно это значение "векторизировать", это делается вот так:
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)Получилось:
print(y_train[0])
Теперь давайте напишем саму модель нейронной сети.
Инициализируем нашу модель.
model = Sequential()Дальше создаем наш первый слой, в нём будет 32 нейрона, также нужно указать форму входимых данных.
model.add(Dense(32, activation='relu', input_shape=(X_train[0].shape)))Ещё дальше создаем 4 нейрона с такой же функцией активации.
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(512, activation='relu'))Мы вытягиваем данные в вектор.
model.add(Flatten())И тут мы сравниваем вектор с вектором, по сути это так.
model.add(Dense(10, activation='sigmoid'))Тут компилируем нашу модель, оптимайзер - адам, потому-что он очень "классный", "categorical_crossentropy" - т.к мы определяем категории объектов.
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])Теперь тренируем модель:
model.fit(X_train, y_train, epochs=50 )Мы обучили нашу нейронную сеть и теперь, давайте посмотрим на результат.
Будем использовать команду "model.evaluate", если перевести дословно - модель.оценивать
Принимает проверочный датасет и смотрим какая потеря и какая точность:

Как мы видим, точность - 96%.
Создадим переменную k и запишем туда номер изображения в датасете и будем его вызывать.
Указали цифру 6, значит цифра 4 находится под индексом 6.
k = 6
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
Давайте укажем индекс 10, получили цифру 0.
k = 10
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
Теперь посмотрим, как именно работает наша нейронная сеть.
k = 6
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
print(
model.predict(np.array([X_test[k]]))
)
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] - единичка под индексом 4 , соответственно - цифра 4.
Визуально на картинке мы тоже видим цифру 4.
Теперь давайте рассмотрим ответ нейронной сети:
[[0.0000000e+00, 9.9408084e-18, 2.8947007e-22, 2.9116518e-10, 1.0000000e+00,
4.6417094e-17, 3.7773155e-38, 5.8520163e-07,, 3.7786970e-24, 4.3130936e-07]]
* - буква e это значение степени, рассмотрим число - 4.6417094e-17
число 4.6417094e-17 - это условно 4.6427 в минус 17 степени, это примерно 0.00000000000000004642 то есть очень маленькое число.
Посмотрим на весь массив и увидим, что есть число 0 в 0-ой степени , числа в отрицательной степени , и то, что нам нужно 1 в степени 0, любое число в нулевой степени равно единице.
Максимальный элемент массива под индексом 4, соответственно, цифра- 4.
Изменим индекс и посмотрим, что будет.
k = 10
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
print(
model.predict(np.array([X_test[k]]))
)
Тут видим, что исходя из степенней и чисел, мы видим, что большее число под индексом 0, соответственно и цифра 0.
Надеюсь, вам понравился мой пост и он будет вам полезен, вот весь код для вставки в гугл колаб:
import tensorflow as tf
import keras
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from keras.layers import Dense, Flatten
from keras.models import Sequential
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print(X_train.shape)
print(y_train.shape)
plt.imshow(X_train[12], cmap='binary')
plt.axis('off')
print(y_train[12])
X_train = X_train/255
X_test = X_test/255
print(y_train[0])
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
print(y_train[0])
model = Sequential()
model.add(Dense(32, activation='relu', input_shape=(X_train[0].shape)))
model.add(Dense(64, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Flatten())
model.add(Dense(10, activation='sigmoid'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50 )
k = 6
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
k = 10
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])2 блок кода:
k = 6
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
print(
model.predict(np.array([X_test[k]]))
)
k = 10
plt.imshow(X_test[k], cmap='binary')
plt.axis('off')
print(y_test[k])
print(
model.predict(np.array([X_test[k]]))
)
Комментарии (5)


Ascard
14.12.2022 09:50+6В названии поста есть "для максимально маленьких", чем он меня, как прошедшего в своё время мимо (увы) всей темы с нейросетями и заинтересовал. Ну надо же когда-то разобраться хоть на таком элементарном примере! Что в итоге я увидел в статье? Бессмысленный набор кода без каких-либо объяснений. Почему модель Sequential? Почему в нём будет 32 нейрона, а не 16, или 64, или 9000, или 100500 ? Какая ещё форма входных данных? Почему дальше создаём ещё 4 нейрона, а не 144 или миллион? Почему дальше "вытягиваем" данные в вектор и это вектор Flatten? И так далее. Ничего не понятно, ничего для себя не почерпнул, опять. Увы, очередной бесполезный пост в стиле "смотрите! я знаю питон!". Если уж копируешь код с оффсайта, так хоть добавь что-то от себя, смысловое и разъясняющее, "для максимально маленьких". Так сказать, держу в курсе.

paradiseMaestro Автор
14.12.2022 23:02Бессмысленный набор кода без каких-либо объяснений. - после каждой строчки мой комментарий.
Бессмысленный набор кода без каких-либо объяснений. Почему модель Sequential? Почему в нём будет 32 нейрона, а не 16, или 64, или 9000, или 100500 ? Какая ещё форма входных данных? Почему дальше создаём ещё 4 нейрона, а не 144 или миллион? Почему дальше "вытягиваем" данные в вектор и это вектор Flatten? И так далее. - хорошие вопросы, но только, не для этой статьи, люди которые зашли в программирование и хотят увидеть сразу реально рабочий пример с комментариями на русском будут рады.
Ничего не понятно, ничего для себя не почерпнул, опять. - с одной стороны мне дело до этого нет, с другой оно и понятно, если ты задаёшься вопросами выше, статья не для тебя.
Увы, очередной бесполезный пост в стиле "смотрите! я знаю питон!". - причем тут это, знать питон и просто на нем что-то писать - это разные вещи. Если ты пишешь такие комментарии, ты должен это знать.
Если уж копируешь код с оффсайта, так хоть добавь что-то от себя, смысловое и разъясняющее, "для максимально маленьких". - если ты действительно открывал код с офф сайта, то ты бы увидел, что там архитектура сети другая "гораздо правильнее", не просто Dense а макспулинги и т.д
Вообще не понятно , зачем ты потратил своё время, что бы написать не маленький коммент, при том, что пост тебя не понравился т.к он не для тебя. Наверное заряжаешь себя негативом...
Ascard
14.12.2022 23:51после каждой строчки мой комментарий.
Спасибо, я не слепой, я заметил. Но хоть код и откомментирован, это не значит что он объяснён и понятен. К примеру, строка про создание первого слоя. То что это добавление слоя в модель, я могу понять открыв документацию на Keras, где в разделе про класс Dense написано что это класс про слои, а "model.add" как бы намекает на добавление в модель, и ты мне для этого не нужен. А дальше, лично я, как не разбирающийся, вижу набор магических констант. Да взять бы то самое упомянутое мной число 32. Разъяснения почему 32, от тебя нет. Что это число значит? Как оно связано хоть с чем-то? Как мне использовать его дальше? От чего оно зависит и что зависит от него? Можно ли вообще менять это число? Как его менять? В каких пределах? Поэтому твой комментарий на половину самоочевиден, а на половину бесполезен.
люди которые зашли в программирование и хотят увидеть сразу реально рабочий пример с комментариями на русском будут рады.
Эти люди безусловно молодцы, но по факту они получили реально рабочий пример, который рабочий непонятно почему. То что он работает это хорошо, но твой пример сильно повторяет код примера с офф сайта по Keras-у, и ты этого не отрицаешь. Там он тоже реально рабочий. Ты мог вообще на заморачиваться придумыванием своего кода, а взять тот пример и разобрать его тут, с нормальными пояснениями. Да и комментарии "на русском" это хорошо, но мне кажется что если у человека хватает навыка взяться за изучение нейросетевой темы в прикладном разрезе, то уж навык английского у него на достаточном уровне. Может мне и зря это кажется, но если ты уж взялся комментировать код "для максимально маленьких", то пассажи вида "Для чего эта строчка? - нагуглите сами. " - это моветон.
с одной стороны мне дело до этого нет, с другой оно и понятно, если ты задаёшься вопросами выше, статья не для тебя
Я тогда не понимаю, а что ты хотел донести своей статьёй? Тебе нет дела дойдёт она до читателя или нет? Типа я написал, а дальше как хотите? Кто для тебя эти "максимально маленькие"? Если не планировал разбирать тут детали происходящего, то так и напиши вводную часть, мол "тут только код, в детали не вникаем, магические константы не раскрываем", и всё, и не было бы к тебе претензий. Тогда и заголовок попроще нужен, без громких заявлений про "для маленьких".
если ты действительно открывал код с офф сайта, то ты бы увидел, что там архитектура сети другая "гораздо правильнее", не просто Dense а макспулинги и т.д
Нет, я бы не увидел. Я как раз из тех, "максимально маленьких", в теме нейросетей. Я вообще не знаю ничего за архитектуры, их правильность, и что такое макспуллинги. Я рассчитывал это узнать тут, от тебя, я ошибался.
Вообще не понятно , зачем ты потратил своё время, что бы написать не маленький коммент, при том, что пост тебя не понравился т.к он не для тебя. Наверное заряжаешь себя негативом...
Я так понимаю, что тебя зацепило, то что ты "старался" и "писал статью", а по итогу не вышло ни обсуждений, ни спасибов, ни плюсов в рейтинг. Ещё и я пришёл, и попытался без оскорблений и ругани донести, что я ожидал увидеть под кричащим заголовком, и в чём ты не прав, с моей точки зрения конечно. Для тебя это почему-то "зарядка негативом" получается, а не фидбек, и мнение читателя потратившего на тебя своё время трижды (сама статья и два коммента). Штош. Удачи тебе, с просвещением масс. Надеюсь в следующий раз получится лучше.
Stefanio
На дворе был 2022 год...