
В силу тех или иных обстоятельств, развиваясь по карьерной лестнице мне все чаще стало необходимо соприкасаться с таким известным инструментом в IT мире, как ClickHouse. Хоть мои должности за последние N-лет и связаны уже больше с управлением коллективами - для меня очень важно понимать суть технологических решений и проблемы, с которыми мои команды сталкиваются. Не смотря на все свое дружелюбие и конструкторную гибкость — ClickHouse временами выглядит, как весьма капризная технология. Одной из таких особенностей, с которой мне довелось столкнуться — стала борьба с внезапным OOM. В данной статье мы вместе с вами попробуем рассмотреть причины, откуда этот внезапный OOM, собственно, может браться.
ClickHouse — одна из самых известных и эффективных колоночных аналитических баз данных, доступных для использования в self-hosted режиме. К тому же это opensource (в отличии от той же Vertica). Стандартная конфигурации ClickHouse вполне могут иметь от 128 до 256 GB RAM. Тем не менее, OOM, или Out of Memory exception — нехватка оперативной памяти для выполнения запроса, — довольно частая ошибка при работе с данной БД. Конечно, довольно часто причина кроется в неоптимальной схеме этой таблицы, неэффективном запросе или настройках самого ClickHouse. В этой статье мы шагнем чуть дальше и поговорим о бэкграундных процессах в ClickHouse, необходимых для его работы и при этом потребляющих драгоценную оперативную память.
Что за бэкграундные процессы?
Да, ClickHouse работает не только когда приходит запрос, а вообще когда ему вздумается! Мы привыкли к тому, что, скажем, у PostgreSQL рост потребления ресурсов следует за вызвавшим его запросом и, отправив ответ, заканчивается. Даже такие операции, как ANALYZE, VACUUM и REINDEX тоже выполняются по запросу, вручную. Репликация WAL, avtovacuum и прочее обычно не сказывается на перфомансе, или по крайней мере работа этих процессов не приводит к пикам в потреблении ресурсов диска, памяти или процессора.
В то же время, ClickHouse может в случайный момент времени запустить набор бэкграундных задач, задействовав ресурсы, сопоставимые со штатным аналитическим запросом. На моем опыте было два типа случаев, когда это приносит проблемы:
1) “мой аналитический запрос, который всегда отрабатывал вдруг упал по OOM, хотя в таблице особо ничего не менялось”;
и чуть более сложный:
2) “был выбран равномерный ключ шардирования, но какой-то из шардов постоянно недозагружен”. Чтобы ответить на этот запрос, давайте коротко обсудим как ClickHouse хранит данные.
Как ClickHouse хранит данные?
Во-первых, все же стоит упомянуть, что ClickHouse это колоночная база данных, а группировка записей по колонкам позволяет снизить количество чтений с произвольным доступом в агрегирующих запросах.
Во-вторых, эта база рассчитана на высокую пропускную способность для добавления новых записей. Остановимся на этом пункте поподробнее.
Если в реляционный базах данных во времяINSERT транзакции запись сразу же попадает на диск, то у ClickHouse в принципе нет транзакций, а запись вначале попадает в оперативную память. Таким образом, входящие записи какое-то время в живут mempool-е, прежде чем батчем отправиться на медленный диск. Такой подход лишает нас свойства D (Durability) из ACID принципов (Atomicy, Сonsistency, Isolation, Durability), которые есть в реляционных базах. (Стоит отметить, что ClickHouse в начале 2021-го начал поддерживать WAL+fsync, но крупным компаниям IT мира свойственен долгий переход на новые версии продукта.) Т.е. при нештатном завершении работы - данные из mempool могут быть потеряны, но зато это снижает количество записей с произвольным доступом на диск.

Батчи из mempool затем группируются по ключам (колонкам) с другими батчами в более крупные группы и так далее. Чтобы понять в какую группу отправится батч, в группе подсчитывается вероятностная структура данных — фильтр Блума с ключами, которые она содержит. Фильтры Блума могут иметь ложнопозитивные срабатывания, но не ложноотрицательные. Поэтому, например, сложно проверить, отсутствие ключа в группе, но ClickHouse это и не нужно.

Ну и наконец, сами группы батчей тоже соединяются в более крупные группы и сортируются по размеру в слои. Как раз этот процесс слияния — merge вероятно и дал название движку MergeTree в ClickHouse.
Основная идея, которая заложена в основу движков семейства MergeTree — следующая: если у вас есть огромное количество данных, которые должны быть вставлены в таблицу, мы должны уметь быстро записать их по частям, и после этого объединить части по некоторым правилам в фоновом режиме. Таким образом этот метод намного эффективнее, чем бесконечная перезапись данных в хранилище при вставке.
Слияние больших групп может задействовать ощутимое количество ресурсов, но чем больше группа, тем реже такие слияния происходят.
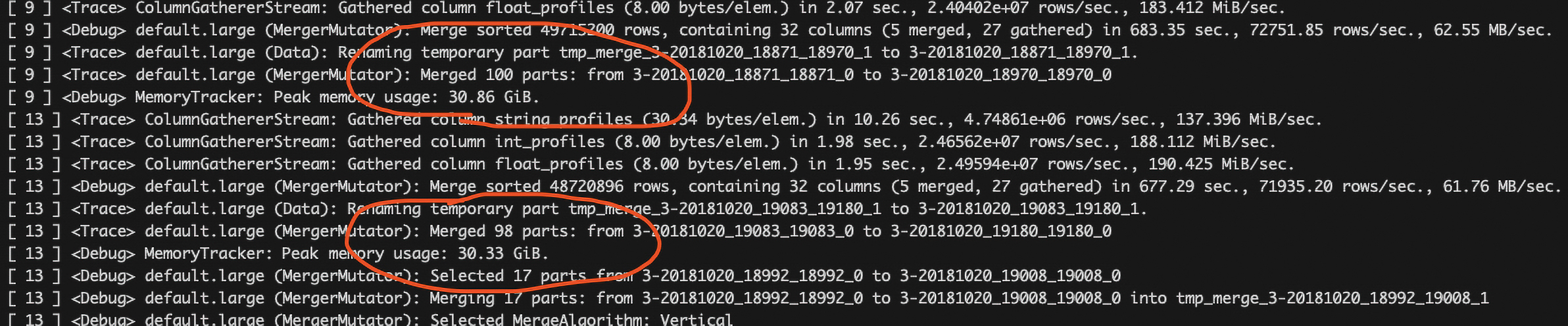
Эти слияния как раз и происходят в бэкграунде. В какой-то произвольный момент времени, когда ClickHouse решит, что уже пора записать на диск накопившийся mempool, а новый батч вызовет цепочку слияний больших групп — мы и можем получить неожиданный пик нагрузки.
При этом в распределенной таблицеENGINE=Distributed все еще интереснее. Слияния могут вызвать неравномерную загрузку шардов даже при хорошем ключе шардирования. Дело в том, что стандартный балансировщик из open-source версии ClickHouse не учитывает загрузку шардов и отправляет вставляемые записи в первый доступный. Но если в шарде происходит слияние, его пропускная способность падает и throughput деградирует. Но более подробнее про это мы поговорим в другой раз.
BugM
Если вы пишете на самом деле много данных, то не стоит писать в distributed таблицу. Пишите сразу в нужные локальные. Вроде это было где-то в документации даже.