
Пытаясь уследить за всем многообразием метрик и срезов на дашбордах, можно легко упустить из виду важное изменение метрик, сигнализирующее о проблеме. И если вовремя не отреагировать, то можно лишиться аудитории или выручки. Расскажем, как мы автоматизировали оповещения о падениях (или нездоровых взлётах) продуктовых метрик, чтобы сразу оценивать масштаб проблемы в деньгах, и что это дало продукту. Наш опыт будет полезен в первую очередь аналитикам и руководителям продуктов.

Содержание
Всем привет! Мы — Еремеев Иван, руководитель отдела аналитики, Нефёдов Сергей и Гайченкова Татьяна, продуктовые аналитики, — работаем в бизнес-юните по медиастратегии и развитию сервисов. Наша команда занимается аналитикой для трёх продуктов:
Relap.io — это одна из крупнейших сетей нативной рекламы в Рунете;
Пульс — сервис персональных рекомендаций контента;
Медиапроекты — новости, тематические проекты (Леди/Hitech/Авто/Кино и т.д.) на главной странице www.mail.ru и в мобильном приложении «Новости.Mail.ru».
Поиск наилучшего подхода
Однажды мы задумались над системным решением проблемы рассеивания внимания при контроле за показателями метрик.
Конечно, существует множество решений, связанных с оповещениями, и мы, безусловно, прежде чем изобретать велосипед, проанализировали готовые варианты. Так, например, различные популярные IT- и BI-системы (такие как Grafana, Redash, Power BI и др.) обладают встроенными возможностями, которые позволяют определённым образом сообщать о существовании проблем, но в них сложно гибко настроить все процессы и условия оповещений о метриках под наши потребности и обилие нюансов, а также заблаговременно оценивать потери в деньгах.
После попыток использовать готовые решения пришли к тому, что стоит настроить свою автоматизированную систему оповещений, которая поможет отслеживать эффекты от изменений в продукте и вовремя реагировать на проблемы. А ещё мы задумали прогнозировать изменения метрик, чтобы предупреждать возникновение проблем, а не ждать, когда они уже случатся.
Сначала мы задали себе вопросы:
Что считать аномалиями в наших метриках?
Когда присылать оповещения об их изменениях?
Как найти оптимальную периодичность, чтобы не слишком надоедать коллегам, но при этом не упустить критичные отклонения?
Сформулировав ответы, начали один за другим пробовать различные подходы к оповещениям:
Давайте теперь поговорим о достоинствах и недостатках этих подходов на примере работы с временными рядами.
Временной ряд
Временной ряд — это последовательность значений некоторой переменной (или переменных), регистрируемой через определённые промежутки времени (регулярные или нерегулярные). Любой временной ряд можно разложить на компоненты:
тренд — функция, описывающая рост или падение;
сезонность — отвечает за колебания в данных в течение года, недели, суток и т.д.;
праздники или другие события, которые могут существенно влиять на поведение временного ряда;
шум — случайные возмущения.
Сравнение текущего периода с предыдущим
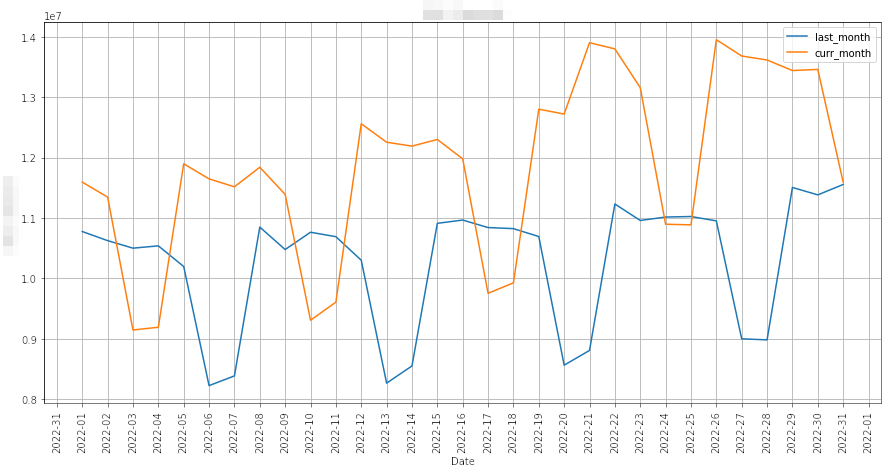
Мы начали с самого простого подхода — сравнения текущего периода времени с предыдущим (например, как на графике, месяц к месяцу): ноябрь сравнивали с октябрём, октябрь — с сентябрём и т.д. Простота — главное достоинство подхода, но у него оказался фатальный недостаток: он не учитывает нормально весь спектр сезонности метрик и тренды. Например, на графике выше в сравнение брался период, относящийся к low season, когда метрика DAU обычно ниже привычных для бизнеса значений, и этот промежуток времени сравнивался месяц к месяцу с периодом, когда начался уже high season. Понятно, что результаты не могли получиться удовлетворительными при таком подходе. Нам слишком часто присылались ложноположительные (false positive) оповещения, и мы решили пробовать дальше.
Скользящее среднее

Скользящее среднее представляет собой среднее значение метрики за выбранный период времени в прошлом. Например, мы пробовали сравнивать текущие показатели DAU с его усреднённым значением за 30, 60, 90 дней: если разница оказывалась велика, присылали оповещение. В целом нам удалось сгладить мелкие колебания метрики и определить сезонность и тренд. Но у этого метода большая чувствительность, из-за которой происходили ложноположительные оповещения об изменении метрик, поэтому пришлось от него отказаться.
Скользящие границы
Тогда мы решили модифицировать подход и рассчитывать для каждого показателя скользящие верхнюю и нижнюю границы (например, 90-й и 10-й перцентили распределения метрик), а также пробовали считать расхождения по стандартным отклонениям (например, брали ±2????, ±3????), чтобы при выходе метрики за эти пределы срабатывало оповещение.
Мы использовали этот подход как временное решение, пока искали более подходящий вариант. Иллюстрация подхода:
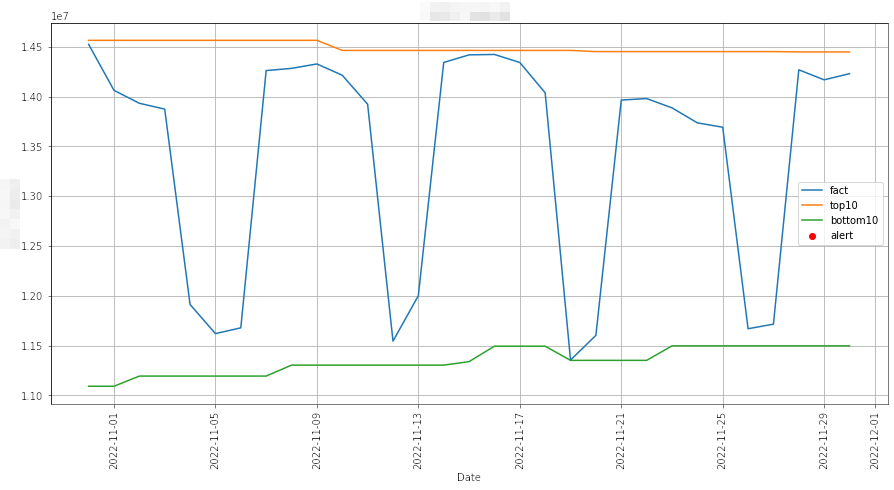
Основной недостаток здесь — низкая чувствительность, то есть можно не заметить малые колебания метрики. К примеру, проиллюстрированная на графике ситуация даёт нам понять, что как аномалии были определены довольно сильные отклонения от нормы, но при этом осталось без внимания падение 21 ноября 2022. Метрика просела внутри широких скользящих границ, поэтому и не была замечена моделью.
ML-методы
Решили протестировать варианты с машинным обучением. Рассматривали ML-инструменты, работающие на иных подходах — библиотеку XGBoost, регрессии, эконометрические модели, ARIMA. Пробовали и библиотеку Twitter Anomaly Detection, но нам не понравилось, что она работает по принципу «чёрного ящика» и часто выдаёт ложные оповещения. В итоге мы написали алгоритм прогнозирования временных рядов с помощью очень удобной и популярной библиотеки Prophet, потому что она показала на наших метриках наименьшую ошибку MAPE. Выбрали MAPE потому, что она одна из самых широко используемых и легко интерпретируемых оценок точности прогнозирования. MAPE — относительная величина, что позволяет сравнивать между собой ошибки прогнозирования различных метрик (например, DAU и клики на уникального пользователя).
Нам понравилась идея, схожая с концепцией синтетического контроля (SC): сначала обучают предиктивную модель на исторических данных с учётом тренда, сезонности и праздников, строят точечный прогноз, а также 95-процентный доверительный интервал для прогноза. Затем смотрят, выходят ли фактические показатели за границы этого интервала. Если да, то получаем оповещение.
Обучение модели на исторических данных:
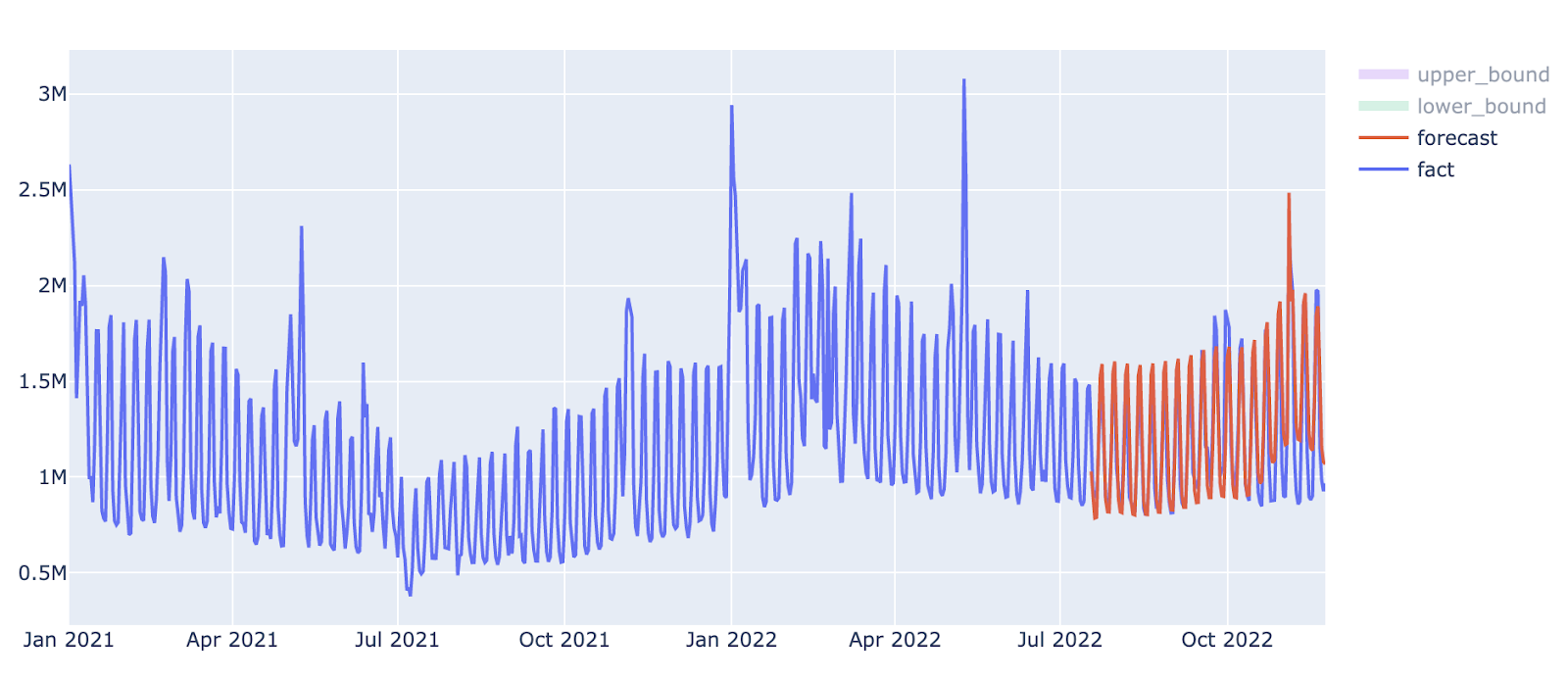
Прогнозирование метрики:

Наш алгоритм
Мы написали скрипт для сбора метрик через API Redash-а (Redash — это сервис, который позволяет работать с большими объёмами данных, создавать запросы к базам данных и строить визуализации). Далее перебрали разные комбинации гиперпараметров и выбрали те, при которых ошибка MAPE между фактом и прогнозом наименьшая. Применили метод преобразования Бокса-Кокса для повышения качества прогноза и затем обучили модель Prophet.

Полученные на выходе значения — наш контрольный уровень (baseline), с которым мы будем сравнивать фактические изменения метрики. У прогноза есть верхнее и нижнее значения — границы доверительного интервала (например, в Prophet стандартное значение этого параметра — 0,95, мы его и брали). Раз в сутки модель проверяет, выходят ли фактические значения метрики за эти границы, и если да, то срабатывает оповещение.
А так это выглядит на практике:

Мы научили модель хорошо прогнозировать, ошибка MAPE в основном стремится к минимальным значениям, не превышающим 10 % (а чаще гораздо ниже). Она может обнаруживать даже маленькие колебания метрик, но нас интересуют резкие скачки, вызванные каким-нибудь событием или чередой событий.
При этом мы не ограничивались использованием только библиотеки Prophet, ведь иногда не нужно усложнять, а стоит воспользоваться более простыми решениями. Таким образом, в качестве основного метода мы применяем прогнозирование Prophet-ом, но также в некоторых случаях, например, сравниваем план с фактом, и если метрика выбивается за рамки некоторого процента расхождений, то присылаем оповещение.
Также параллельно с поиском наилучшего подхода мы размышляли над удобством системы, ведь иначе ею никто не будет пользоваться. Поэтому особое внимание мы уделили и интерфейсу.
Интерфейс
В качестве внешнего отображения мы воспользовались сначала готовыми решениями, которые нам не очень подошли, затем уже решили создать самописное.
Redash
Мы обратились к Redash, в котором уже есть готовое решение для рассылки оповещений на почту. Сначала аналитик пишет SQL-запрос на наличие аномалий и указывает частоту проверки:
Здесь можно посмотреть список настроенных оповещений: название метрики и её статус на момент обновления данных запроса. Статус OK говорит о том, что всё в порядке, TRIGGERED — обнаружена аномалия.
Можно настроить отправку оповещения:
указав значение, за пределы которого метрика не должна выходить;
либо использовав дополнительное поле типа boolean в зависимости от заданного в SQL-запросе условия.
Можно добавить список почтовых адресов для рассылки оповещений:
Однако письма будут содержать лишь сам факт аномалии, а нам нужно было добавить подробное описание. К тому же оповещение можно привязать лишь к одному полю, поэтому мы не могли составлять более сложные условия проверки.
Почтовые оповещения
Тогда мы решили написать свой скрипт рассылки почтовых оповещений со всей необходимой нам информацией по метрикам и срезам. Здесь мы как раз внедрили модель на основе Prophet. Каждый день собранные метрики прогоняли через скрипт, и при срабатывании оповещения он рассылал письма.

В них была подробная информация: название метрики, её описание, ссылки на запросы и дашборды, и т.д.:
Но иногда возникала путаница из-за того, что на почту приходили письма с похожими темами — оповещения и рабочие обсуждения. Поэтому мы решили попробовать для рассылок Telegram-бота.
Telegram-бот
После того, как мы опросили коллег, кто был заинтересован в нашей системе оповещений, пришли к выводу, что мессенджер действительно гораздо удобнее подавляющему большинству, и многим пришёлся по душе вариант с получением сообщений от Telegram-бота, чем почтовая рассылка.
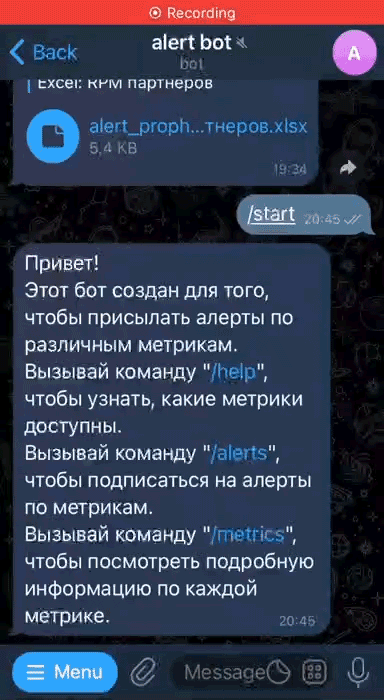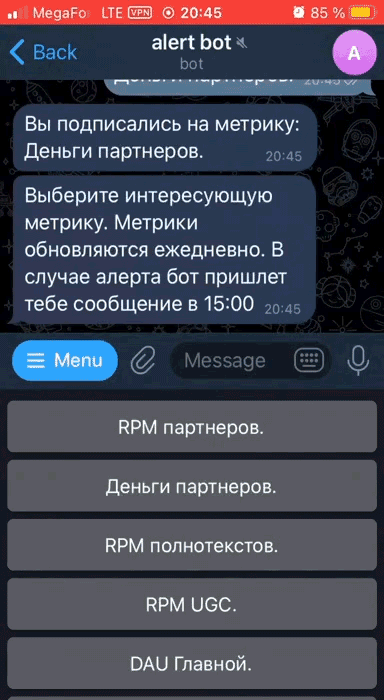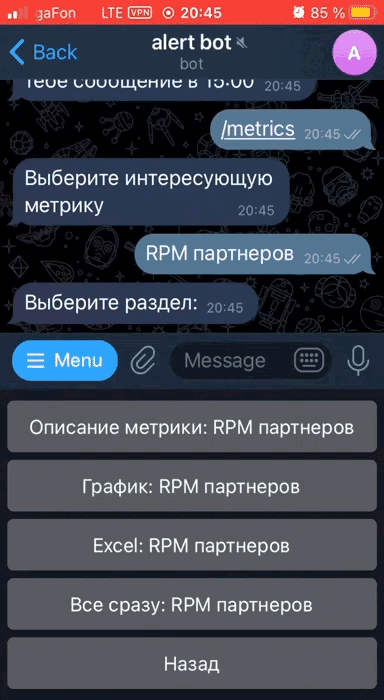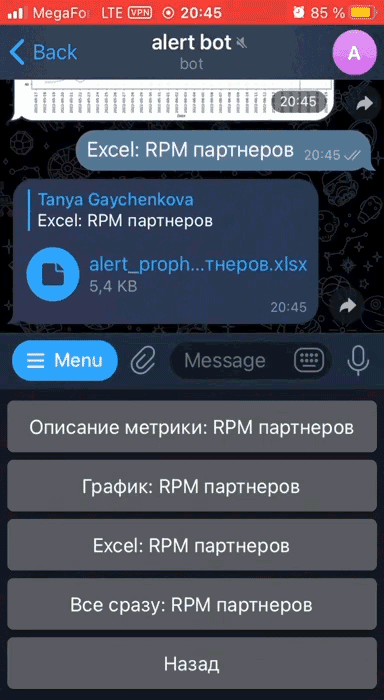
В боте можно выбрать интересующие метрики и подписаться на автоматические оповещения по ним, либо просмотреть весь список метрик и вручную выгрузить нужную информацию: график, описание, ссылку на дашборд и Excel-файл с подробными данными.

При запуске бота он присылает список главных команд:
/alerts— раздел автоматической подписки на периодические оповещения по конкретным метрикам;/metrics— ручной просмотр графиков, получения Excel-файлов и т.д. по любой метрике в любое время. Например, можно сначала ознакомиться с какой-то метрикой, а затем с помощью/alertsподписаться на рассылку оповещений по ней.

В разделе /alerts есть кнопки с метриками. Нажав на кнопку, пользователь подписывается на оповещения.

Все метрики автоматически пересчитываются раз в сутки. Бот сообщает в 15:00 обо всех случившихся выходах за пределы допустимых значений.

В разделе /metrics есть кнопки для скачивания подробных данных по конкретным метрикам:

Telegram-бот оказался удобнее почтовых рассылок. Он помог вовремя заметить падение денежных метрик, и, таким образом, нам удалось сэкономить несколько миллионов рублей. Благодаря оповещению мы увидели падение метрики RPM полнотекстов на мобильных устройствах.
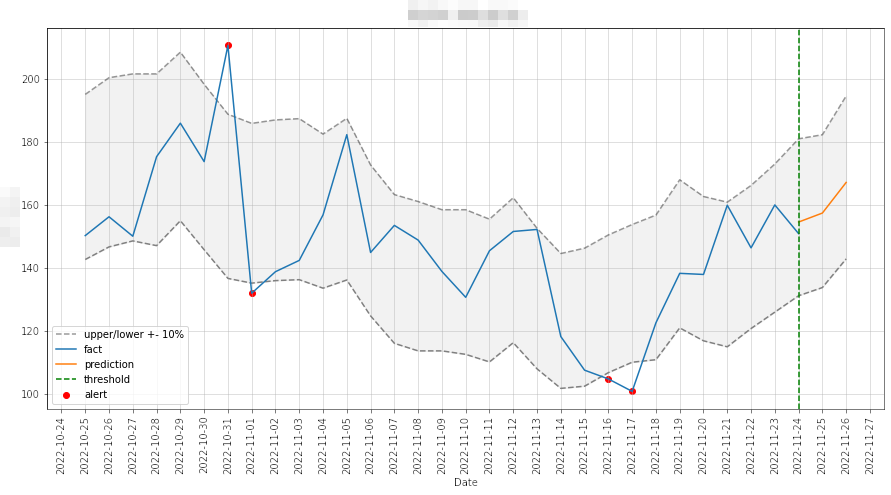
Успели отреагировать буквально на следующий день, что позволило уменьшить потенциальные потери на несколько сотен тысяч рублей в день. А если бы на проблему отреагировали спустя неделю, мы потеряли бы более миллиона рублей.
Другой пример — падение по метрике CPM dtd (target+direct). Потенциальные потери могли составить до нескольких сотен тысяч рублей в день.

Также у нас есть метрики, для которых хочется получать сообщения чаще, чем раз в сутки. Поэтому мы добавили ещё и почасовые оповещения. Они настроены на основе другой логики, без использования Prophet. Чтобы сильно не усложнять, расскажем на примере.
У нас есть рекламный формат с оплатой за переходы с прогнозируемой выручкой по каждому партнёру, который зарабатывает на кликах, и мы знаем по каждому партнёру дневные лимиты. Также есть план, согласно которому мы должны отдавать партнёру трафик на протяжении дня. Бот следит за откруткой каждый час и сравнивает план с фактом. Мы настроили уведомления так, что они приходят с интервалом в три часа, чтобы не сильно утомлять коллег. Если расхождение между фактом и планом больше 10 %, то приходит оповещение:

Если за предыдущие три часа ситуацию исправили и наверстали упущенное, то в следующий раз оповещение уже не отправляется. Например, в 12:00 не было откручено запланированное — бот оповещает об этом и коллеги берут задачу в работу. Если до 15:00 клики будут восполнены до планового значения, бот уже не будет оповещать.
Почасовые сообщения помогают нам следить за выполнением плана по открутке в течение дня и в прямом смысле сохранять деньги, вовремя реагируя на отклонения от плана и не откручивая лишний трафик.
Эффект в деньгах
Бот уже многое умеет, но здо̒рово, что можно развивать его дальше. Например, если подписаться на оповещения по всем метрикам, то в мессенджер приходит слишком много сообщений. Чтобы коллеги не утонули в них, мы сейчас работаем над приоритизацией метрик, благодаря которой можно будет оповещать в первую очередь о самых важных изменениях. Метрик огромное множество, но все они по-разному влияют на доход компании. Мы добавили преобразование из «родных» единиц измерения в деньги, и теперь все показатели можно напрямую сравнивать друг с другом. Например, возьмём метрики RPM и DAU. Логически преобразование можно описать так:
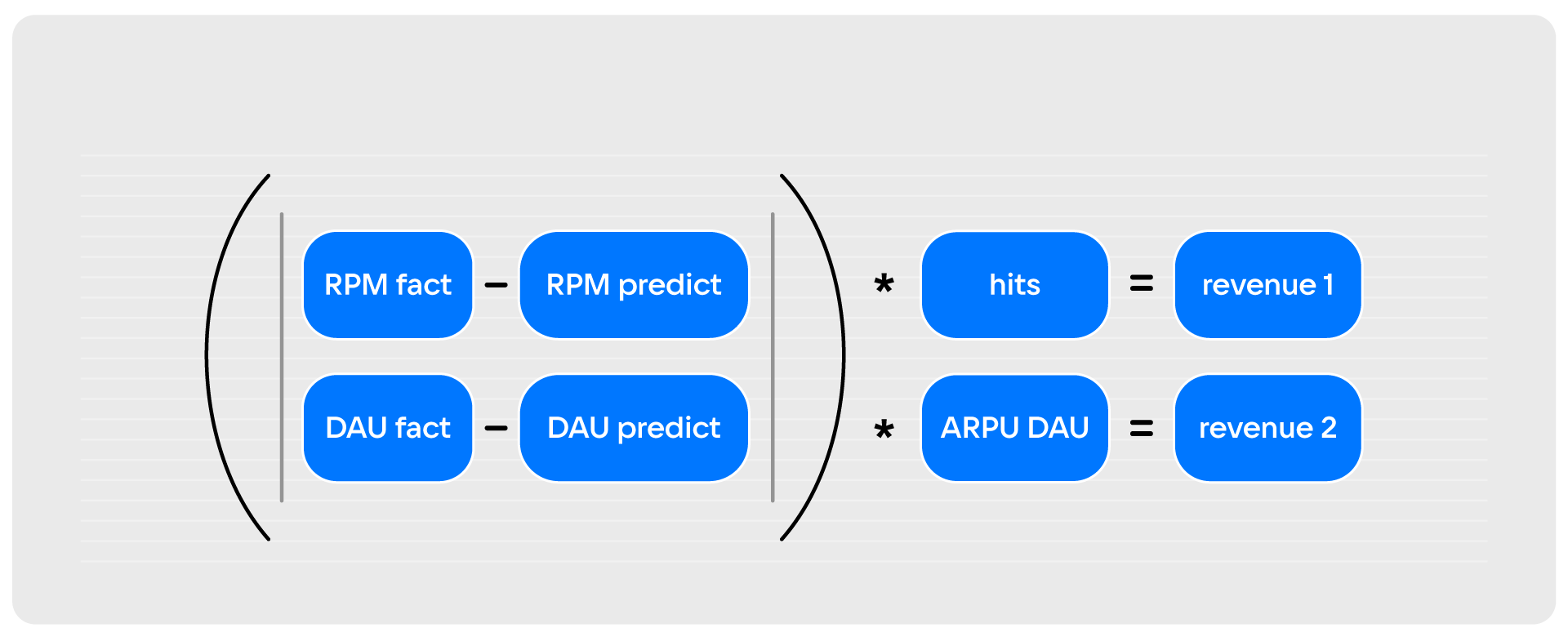
То есть мы рассчитываем влияние каждой из двух двух метрик как разность по модулю фактического показателя и прогнозируемого, затем умножаем полученные значения на единицы измерения (для RPM — хиты (загрузки страницы), а для DAU — ARPU DAU) и получаем результат в рублях.
Отсортировав преобразованные метрики, можно в первую очередь подписаться на оповещения по тем, которые могут принести самый большой убыток.
Итоги
Главным преимуществом нашего Telegram-бота является настроенная умная приоритизация, благодаря которой мы вовремя реагируем на особо критичные аномалии, когда потенциальная потеря в деньгах может оказаться существенной. Таким образом, мы можем экономить как время, затраченное на обнаружение проблем и оценку потерянного дохода, так и сами деньги.
Сегодня наша система оповещения прогнозирует изменения десятков продуктовых метрик и каждый день сообщает об аномалиях, позволяет отслеживать как подневные, так и почасовые отклонения. Из достоинств Telegram-бота можно отметить удобство самого мессенджера и настроек его API: сообщения по заданным условиям и в соответствии с расписанием приходят сотрудникам со всеми нужными описаниями, графиками и ссылками на подробную статистику в системе мониторинга. Не нужно следить самостоятельно: система сама предупредит о возможных проблемах.
Комментарии (2)

PavelOsipov
30.12.2022 18:52Видно, что сделано с душой)
Был бы очень рад узнать, учитываются ли прошлые и актуальные аномалии в процессе обучения модельки? Немного раскрою вопрос. Допустим, мы решили сделать baseline на очередной период, но у данной метрики наблюдались аномалии в прошлом, а то и вовсе она «болеет» прямо сейчас. Как решается вопрос исключения проблемных периодов из обучающей выборки? Помнит ли сама система о сбоях в прошлом или их выкусывание – это ручной процесс и таким образом построение прогноза всегда требует оператора?
Starnight1010
Спасибо большое автору! Очень интересная и полезная статья!