
Сегодняшняя задача вполне традиционна для любых учетных систем - поиск записей, содержащих максимальное значение по каждому из ключей. Что-то вроде "покажи мне последний заказ по каждому из клиентов", если переводить в прикладную область.
Кажется, что тут и споткнуться-то негде в реализации - но все оказывается совсем не тривиально.

КДПВ
Иллюстрации взяты отсюда.
Для определенности пробовать будем на PostgreSQL 13 и начнем с генерации тестовых данных о наших "заказах":
CREATE TABLE orders AS
SELECT
(random() * 1e3)::integer client_id -- один из 1K клиентов
, now()::date - (random() * 1e3)::integer dt -- дата заказа
, (random() * 1e3)::integer order_data -- извлекаемые данные по заказу
FROM
generate_series(1, 1e5); -- 100K произвольныхКак опытные разработчики мы уже понимаем, что "последний заказ по клиенту" подразумевает индекс по (client_id, dt):
CREATE INDEX ON orders(client_id, dt);
max + JOIN = 2 x Seq Scan
Сначала на ум приходит самый "тупой" вариант - найти эти самые "последние" значения по каждому из ключей, а потом извлечь соответствующую запись:
SELECT
*
FROM
(
SELECT
client_id
, max(dt) dt
FROM
orders
GROUP BY
client_id
) T
JOIN
orders
USING(client_id, dt);Это дает вот такой план на 47мс/1082 buffers, при котором таблица orders полностью перечитывается дважды:


DISTINCT ON
Но вроде достаточно очевидно, что читать всю таблицу дважды - не очень хорошо. Поскольку нам необходима всего лишь одна запись для каждого client_id, воспользуемся возможностями DISTINCT ON:
SELECT DISTINCT ON(client_id)
*
FROM
orders
ORDER BY
client_id, dt DESC;
Незадача... стало вдвое медленнее из-за попадания сортировки на диск.

Попробуем исправить, увеличив объем выделяемой для узла памяти work_mem, как советует нам подсказка на explain.tensor.ru:
SET work_mem = '8MB';

Помни о сортировке в индексе!
Но обратите внимание: Sort Key: client_id, dt DESC - сортировка-то не совпадает с созданным нами индексом. А что если...
CREATE INDEX ON orders(client_id, dt DESC);
По времени сравнялись с исходным, но вот buffers теперь в 100 раз больше!

Рекурсивный "DISTINCT"
Поскольку мы знаем, что клиентов существенно меньше, чем заказов, да и в общем количестве достаточно немного, мы можем использовать модель поиска "следующих" значений client_id прямо из индекса:
WITH RECURSIVE rec AS (
SELECT
-1 client_id -- инициализируем наименьший ключ индекса
, NULL::orders r
UNION ALL
SELECT
(X).client_id
, X
FROM
rec
, LATERAL (
SELECT
X -- возвращаем целую запись таблицы
FROM
orders X
WHERE
client_id > rec.client_id -- шагаем к "следующему" клиенту
ORDER BY
client_id, dt DESC -- помним о правильной сортировке
LIMIT 1 -- нам нужна всего одна запись
) T
)
SELECT
(r).* -- разворачиваем поля записи в столбцы
FROM
rec
OFFSET 1; -- пропускаем первую инициализационную запись
Запрос стал существенно сложнее, зато такой вариант уже выглядит гораздо интереснее в плане скорости: 9.5мс/3008 buffers - в 5 раз быстрее оригинального запроса!

Комментарии (36)

mishamota
14.01.2023 12:02+1Да, неплохо, и интересно, но всё равно, такой вариант - лучший из худших.
Если rps будет несколько сотен или даже тысяч - ничего хорошего уже не получится.
Гораздо проще обновлять у клиента ссылку на последний заказ при его создании (из примера в статье). Тогда вся эта задача сводится к простому чтению по ключу.

Ivan22
14.01.2023 12:22Это аналитическая задача, таких очень много и на каждую предрасчитанного заранее ответа не напасешся. То выбрать всех клиентов с оборотами больше N за последний месяц, то вывести не активных клиентов за последние полгода, то собрать топ 10 клиентов в разрезе каких-нить групп клиентов. И т.д. и т.п. Конечно по нормальному это все легко и быстро считается на OLAP базе внутри powerBi например юзая DAX, или вообще в отдельном аналитическом хранилище на новоможном Snowflake, но в жизни на безрыбье приходтся и постгрес мучать

Kilor Автор
14.01.2023 12:39Если кому-то хочется несколько сот раз в секунду искать последние заказы по всем-всем клиентам, то само это желание уже странное. И делается, конечно, иначе.
Но если, как было правильно отмечено в соседнем комментарии, захочется искать не самый последний, а последний в понедельник, эта схема сыплется.
Ivan22
14.01.2023 12:26+2Дефолтный запрос на такую аналитику всегда будет кстати не с group by, а с аналитической функцией, типа row_number (которая в плане будет юзать индекс также как и distinct on)
а-ля
Select client_id, dt
FROM
(
SELECT *, ROW_NUMBER() (Partition by client_id order by dt desc) RN
FROM orders
)
Where RN =1

al_kotler
15.01.2023 13:42Меня учили делать похоже, но разбивая на три запроса. Отобрать заказы, пронумеровать записи, отобрать первые. По принципу - чем проще запрос тем быстрее работает и труднее ошибиться (забыть про обязательное дополнительное условие).

Alpensin
15.01.2023 15:54Потерял создание индекса сначала. Теперь результаты с btree индексом как в примере.
demo=# explain analyze SELECT client_id, dt from (SELECT *, ROW_NUMBER() OVER (Partition by client_id order by dt desc) RN FROM orders) t where RN = 1 ; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------------------------------- Subquery Scan on t (cost=8.30..12407.85 rows=500 width=8) (actual time=0.089..41.055 rows=1001 loops=1) Filter: (t.rn = 1) -> WindowAgg (cost=8.30..11157.85 rows=100000 width=20) (actual time=0.088..40.955 rows=1001 loops=1) Run Condition: (row_number() OVER (?) <= 1) -> Incremental Sort (cost=8.30..9407.85 rows=100000 width=8) (actual time=0.082..34.998 rows=100000 loops=1) Sort Key: orders.client_id, orders.dt DESC Presorted Key: orders.client_id Full-sort Groups: 1001 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB Pre-sorted Groups: 1000 Sort Method: quicksort Average Memory: 29kB Peak Memory: 29kB -> Index Only Scan using orders_client_id_dt_idx on orders (cost=0.29..2592.29 rows=100000 width=8) (actual time=0.057..8.294 rows=100000 loops=1) Heap Fetches: 0 Planning Time: 0.074 ms Execution Time: 41.103 ms (13 rows) demo=# explain analyze SELECT * FROM ( SELECT client_id , max(dt) dt FROM orders GROUP BY client_id ) T JOIN orders USING(client_id, dt); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------- Hash Join (cost=2076.04..4142.03 rows=100 width=12) (actual time=21.726..34.166 rows=1042 loops=1) Hash Cond: ((orders.client_id = orders_1.client_id) AND (orders.dt = (max(orders_1.dt)))) -> Seq Scan on orders (cost=0.00..1541.00 rows=100000 width=12) (actual time=0.017..4.006 rows=100000 loops=1) -> Hash (cost=2061.02..2061.02 rows=1001 width=8) (actual time=21.683..21.684 rows=1001 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 48kB -> HashAggregate (cost=2041.00..2051.01 rows=1001 width=8) (actual time=21.485..21.588 rows=1001 loops=1) Group Key: orders_1.client_id Batches: 1 Memory Usage: 193kB -> Seq Scan on orders orders_1 (cost=0.00..1541.00 rows=100000 width=8) (actual time=0.005..4.907 rows=100000 loops=1) Planning Time: 0.364 ms Execution Time: 34.264 ms (11 rows)Kilor Автор
15.01.2023 15:56Я так понимаю по
WindowAgg / Run Condition, что план из PG15, а на более ранних версиях было бы еще дольше. Хотя сравнивать при дисковой сортировке, съевшей 37мс не особо корректно.Alpensin
15.01.2023 16:01Да, версия 15.1
Kilor Автор
15.01.2023 16:07Даже если предположить, что при увеличении work_mem время на сортировку обнулится, все равно останется еще 15мс.
Alpensin
15.01.2023 16:07Ага, запрос с созданием индекса как-то прошляпил. Отредактировал результаты уже с ним.
demo=# \d orders Table "bookings.orders" Column | Type | Collation | Nullable | Default ------------+---------+-----------+----------+--------- client_id | integer | | | dt | date | | | order_data | integer | | | Indexes: "orders_client_id_dt_idx" btree (client_id, dt)Kilor Автор
15.01.2023 16:15Ага, индекс и
Incremental Sortв памяти помогли, но все равно не лучшеJOIN.Alpensin
15.01.2023 16:22Можете посоветовать какой-то источник для изучения оптимизации запросов для Postgres? Я только начал погружаться в эту тему.
Kilor Автор
15.01.2023 16:30В моем профиле есть ссылки на статьи о многих способах оптимизаций для PG, и в рассылке Planet PostgreSQL интересное встречается.

Darigaaz
14.01.2023 15:34+1то что вы описали есть частное применение loose index scan, который, к сожалению, еще пока не реализован (не вмерджен) в main постгреса
общая методология описана на вики пг, оставлю ссылку
https://wiki.postgresql.org/wiki/Loose_indexscan
и я не понял как при seq scan всей таблицы буфера 502
а при скану по индексу 100000?
перед первым запросом сделали analyze, а перед вторым забыли?
о чём, кстати, было сообщено, но проигнорировано
Kilor Автор
14.01.2023 18:16Совершенно верно, это тот самый
Index Skip Scanс тяжелой судьбой. И именно из-за его отсутствияDISTINCTполучается с таким конским количеством buffers, причем стабильно каждый раз, независимо отANALYZE- "обычный"Index [Only] Scanне умеет искать уники эффективно.Darigaaz
15.01.2023 04:38вот я не могу понять почему для того что бы сделать seq scan надо 541 буфер (4.2 мб) и 6 мс
а для index scan - 100_000 буферов (782 мб) и 38 мсведь индекс заведомо меньше всей таблицы
а выглядит как будто таблица в 100+ раз меньше индексагде я не прав?
Kilor Автор
15.01.2023 08:28Поскольку мы получили не-
Only Index Scan, то после вычитки каждой следующей записи индекса (их как раз 100K) происходит чтение соответствующей записи таблицы на 1 buffer.Darigaaz
15.01.2023 15:11а при seq scan с диска читать все строки таблицы не надо что ли? =)
и прихранивать их в буфера - те постгрес такой - "я вот тут прочитал всю таблицу с диска, но кэшировать в буфера её я не буду", верно?тогда в первом примере где 2 x seq scan он 2 раза диск перечитывал?
мне всё еще не понятно как seq scan выполнился за 6 мс, а index scan за 38мс
типа seq scan читает с диска последовательно, а index scan последовательно читает индекс, а с диска - рандомно и в тесте не ssd диски у которых x6 оверхед на random access?
или при seq scan в дело вступает page cache ОС - поэтому так быстро
а при index scan - этого почему то не происходит?
но это всё тоже не объясняет почему на seq scan в примере нужно 4.2 мб, а на index scan - 782
вот мне кажется, в ваших примерах узлы с seq scan какие-то очень подозрительно быстрые в планах
пытаюсь понять, то ли вы где-то "обманулись", то ли я где-то ошибаюсь?Kilor Автор
15.01.2023 15:51+1Seq Scanнастолько быстр, поскольку читает всю относительно небольшую таблицу как раз последовательно, а вотIndex Scanпосле прочтения каждой записи индекса вынужден прочитать запись heap таблицы - ровно против этого придумалиIndex Only Scan.Причем чтение с диска и pagecache тут у нас не играли, поскольку везде только
shared hit- то есть было чтение страницы только из памяти (иначе было быshared read).Вот тут я рассказываю подробнее, как разные методы доступа работают.
Darigaaz
15.01.2023 18:11спасибо, что помогаете разобраться
получается мы получили замедление по времени в 6 раз между последовательным чтением таблицы

и непоследовательным через индекс
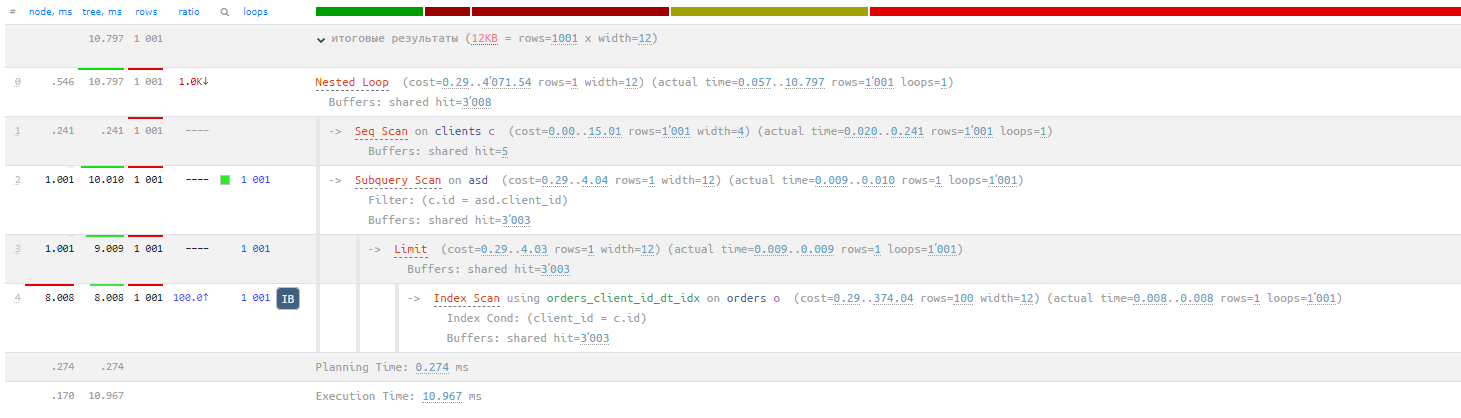
и вся таблица из 100к записей вмещается в 521 буфер и его то и прочитали в seq scan
а при использовании index scan нам пришлось прочитать 100_000 буферов?
ааа! не факт что это были разные буфера?
прочитали Х буферов для индекса (в плане 100_092 прочитано, поэтому предположу, для простоты, что 92 это буферы с индексом)
т.е. по факту 92 страницы буфера для индекса, 521 для таблицы, но крутились мы в цикле так, что суммарно эти 521 страницу перечитали 100_000 раз?
что то типа nested loop по буферам?алгоритм работы:
1) скопировали 92 страницы индексов в рабочую область процесса обрабатывающего запрос
2) идём в цикле по записям
2.1) для текущей записи в индексе находим страницу с данными таблицы
2.2) копируем себе в рабочую область эту страницу (8кб)
2.3) находим там единственную интересующую нас строку таблицы
2.4) ... работа ...
2.5) "забываем" про страницу с данными таблицы из пп2.2
2.6) берём след запись в индексе, возвращаемся к пп2.1и каждый раз в пп.2.2 страница буфера с данными таблицы копируется в область рабочего процесса обрабатывающего запрос, отсюда и 700+ мб начитанных данных?
верно понимаю?
кажется, что если бы алгоритм не "забывал" подгруженные страницы в пп2.5, то всё было бы сильно быстрее
(но понятно, что если сама таблица - гигабайты данных, то надо "забывать", а то workmem не хватит)
но я думал что в рабочем процессе что-то типа LRU кэша страниц буферов именно на такой случайKilor Автор
15.01.2023 18:27В целом - так. У нас 92 страницы индекса - их мы вычитаем каждую однократно. В таблице - 521, но каждую из них мы читаем многократно, но ровно одну для каждой записи из индекса.
Darigaaz
15.01.2023 18:38продублирую т.к. кажется обновил свой предыдущий пост уже после вашего ответа
я думал что в рабочем процессе что-то типа LRU кэша страниц буферов именно на такой случай
ясно. круто. еще раз спасибо что помогли разобраться
Darigaaz
15.01.2023 18:44это ж получается что и nested loop/merge join узел так же работает?
для каждой строки из левой таблицы он каждый раз вычитывает всю страницу правой таблицы ради одной записи? =(
Kilor Автор
15.01.2023 18:56Вот join-узлы обеспечивают только способ соединения самих записей, а чтение для них осуществляют нижележащие
Scan-узлы.Darigaaz
15.01.2023 19:21https://habr.com/ru/company/postgrespro/blog/578196/
нашел материал объясняющий как будет работать этот Index Scan
его эффективность связана с корреляцией
многое стало понятно =)




Arm79
15.01.2023 10:25Простите, а вам не кажется, что последний запрос по сравнению с первым стал нечитаемым?
Вы выиграли время за счёт увеличения цены поддержки кода.
Если я, глянув на первый запрос, сразу понимаю, что и зачем, то над оптимизированным - разбираться и разбираться. И я уверен, что люди с начальными и даже средними значениями sql не смогут дорабатывать такие запросы
К тому же запрос стал "вендор"-специфичен. Известные мне требования архитектуры многих компаний требуют избегания такого рода моментов
Kilor Автор
15.01.2023 10:32Если модель разработки предусматривает установку своего продукта на ресурсах клиента, то смысла их беречь примерно около нуля. Конечно, тогда стоит вкладывать в эффективность поддержки и кроссплатформность.
Если же это разного рода SaaS на собственных мощностях, где каждая миллисекунда в запросе может стоить в масштабе сотни тысяч разных денег на моноплатформе, то выбор очевиден.
Как раз недавно была статья в тему.
Alexidis
16.01.2023 10:24А почему просто не воспользоваться таблицей clients, с которой у нас связь по ключу? получится сделать все тоже самое, но без без усложнения в виде рекурсии. Результат выполнения у меня получился сопостовимый
Kilor Автор
16.01.2023 10:27Тут нас может поджидать проблема, если в
clientsлежат не только "активные" клиенты, уже делавшие заказы, но и все потенциальные, коих может быть и миллион - а такой запрос масштабируется линейно именно по ним.Alexidis
16.01.2023 10:32Но в таком случае вероятно будет признак архива и частичный индекс на не архивных клиентов. К тому же тогда у нас будут и заказы по архивным клиентам и тогда у вас не полное решение (если конечно orders это не таблица где хранятся только актуальные заказы)
Kilor Автор
16.01.2023 10:49Речь не об "архивных", а о тех, которые находятся "в проработке" - например, загрузили мы с разных "желтых страниц" кучу клиентов для прозвона...
Конечно, тут можно начать вводить флаги на записи клиента "были заказы", "взят в работу", "выставлено КП", ... - но это имеет косвенное отношение к задаче, потому что условия отбора заказов могут оказаться нефиксированными.

gleb_l
Прекрасно, но зачем все эти ковбои? Вы экономите буфера и чтения postgre, но заставляете крутиться диски CDN и щёлкать реле сетевого оборудования всего лишь для того, чтобы расцветить статью для профессионалов картинками для десятилетних мальчиков. Кому вы адресуете ваш материал?
Kilor Автор
gleb_l
Ответьте честно - вы искренне это поддерживаете, или потому, что сейчас так лучше продаётся?
Kilor Автор
Эмоциональная составляющая - важный аспект для запоминания темы. А тема эта достаточно распространенная в учетных системах.