

Node.js это кроссплатформенная среда выполнения JavaScript с открытым исходным кодом для выполнения JavaScript вне браузера. Он поддерживается движком Google V8, что делает его чрезвычайно производительным.
Асинхронная среда выполнения, управляемая событиями
Одно из наиболее распространенных утверждений, с которым мы сталкиваемся при знакомстве с Node, заключается в том, что он выполняется в одном потоке. Тем не менее каждый может задаться вопросом, как это возможно, что Node является одним из самых популярных инструментов для создания быстрых и масштабируемых API?
Технически, тот факт, что Node.js использует один поток не на 100% верно. Node.js на самом деле использует много потоков, но цикл событий (Event Loop - о котором мы упомянем позже), и пользовательский код выполняются в одном потоке. Если мы ознакомимся с документацией, то увидим, что Node.js использует управляемым событиями неблокирующую модель ввода-вывода (event-driven, non-blocking I/O model), которая делает его легким и эффективным.
Что такое управляемая событиями неблокирующая модель ввода-вывода?
Согласно руководству по Node.js, блокирующие методы выполняются синхронно, а неблокирующие методы выполняются асинхронно. Предположим, что нам нужно написать некоторый код, чтобы прочитать содержимое файла и распечатать его в консоли. Есть два способа сделать это в узле: синхронно и асинхронно.
Давайте сначала посмотрим синхронную версию:
В приведённом ниже коде происходит следующее: во-первых, нужно подключить модуль FS. Во второй строке вызывается метод readFileSync, и результат сохраняется в переменной data. Основной поток Node.js блокирует эту строку до тех пор, пока не будет прочитано все содержимое файла. Затем содержимое выводиться в консоль, и, в самом конце будет выведено в консоль “Done”.

Теперь давайте посмотрим, как тот же код выполняется асинхронно:

В этом примере используется метод ReadFile, который выполняется асинхронно. Как только встречается эта строка, управление передается в Libuv, где происходит чтение файла. Это не делается в основном потоке. Вместо этого используются рабочие потоки (worker threads) из пула потоков (Thread Pool) Libuv (по умолчанию 4 потока). Как только чтение завершено, соответствующий обратный вызов помещается в очередь (Event Queue), которая используется циклом событий (Event Loop). На следующей итерации цикла событий, во время фазы выполнения обратного вызова (callback), этот обратный вызов (callback) будет помещен в стек вызовов (Call Stack) V8 и в конечном итоге будет выполнен. Вся эта работа выполняется в фоновом режиме, и основной поток Node.js отвечает только за выполнение обратных вызовов. Итак, возвращаясь к приведенному выше примеру, сначала будет выведена строка “Done”, а результат чтения файла будет зарегистрирован после этого. Это то, что подразумевается под “неблокирующим вводом-выводом”, и именно поэтому в каждом руководстве по Node.js, которое вы могли встречать во время изучения, предлагают использовать асинхронные методы вместо синхронных.
Чем Node отличается от других веб-серверов?
По сравнению с многопоточными серверами среда выполнения Node, управляемая событиями, ведет себя совершенно по-другому. На многопоточном сервере каждое соединение порождает новый поток для обработки запроса, и вся работа, выполняемая в этом потоке, может быть заблокирована, не затрагивая другие соединения (т. е. вы можете запросить базу данных и дождаться результата, затем выполнить какую-то другую работу). Поскольку в настоящее время каждый процессор имеет много ядер, такой подход очень хорошо использует мощность процессора. Однако существует также много проблем. В многопоточной среде каждый поток добавляет некоторые накладные расходы, поскольку ему требуется память, а это означает, что количество потоков, которые можно использовать, ограничено. Что произойдет, если этот предел будет достигнут? Время ожидания нового соединения в конечном итоге истечет. В дополнение к этому, если приложение в основном связано с вводом-выводом, каждый поток будет тратить значительное количество времени на ожидание результатов из сети или с диска. Node.js, с другой стороны, обрабатывает все в одном потоке. Подобно тому, что мы объяснили выше с файловыми операциями, цикл событий действует как диспетчер, который непрерывно прослушивает новые события и делегирует работу ядру или другим рабочим потокам. Он никогда не блокируется (если только ему не приказано это сделать). Таким образом, сервер может принять новое клиентское соединение, затем выполнить какую-то другую работу, а затем продолжить принимать новые клиентские соединения снова и снова. Клиентскому соединению не нужен выделенный новый поток, ему просто нужен обработчик сокета, управляемый ядром. Этот подход быстрый, легкий и очень масштабируемый, и это главная причина, по которой Node.js может обрабатывать так много одновременных подключений.
Архитектура среды выполнения Node.js
Среда выполнения Node.js спроектирована как набор уровней, где пользовательский код находится сверху, и каждый уровень использует API, предоставляемый нижележащим уровнем.
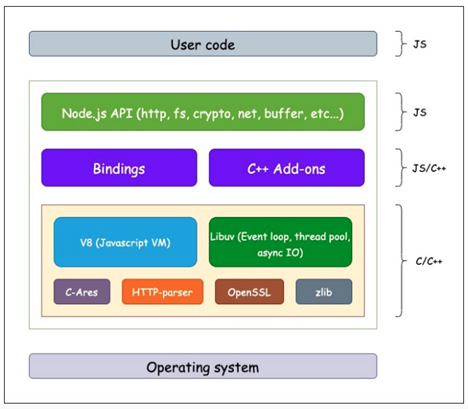
Пользовательский код: код приложения на JavaScript, написанный программистами.
Node.js API: список методов, предлагаемых Node, которые могут быть использованы в пользовательском коде (например, HTTP-модули для использования HTTP-методов, crypto module, fs для операций с файловой системой, net для сетевых запросов и т. д.). С полным списком методов, предлагаемых Node, вы можете ознакомиться в документации здесь. Кроме того, здесь вы можете найти реализацию исходного кода. API узла написан на JavaScript.
Привязки и дополнения C++: Читая о Node.js, вы видите, что V8 написан на C++, Libuv написан на C и так далее. В основном все модули написаны либо на C, либо на C++, поскольку эти языки настолько хороши и быстры в решении низкоуровневых задач и использовании OS API. Но как возможно, что код JavaScript на верхних слоях может использовать код, написанный на других языках? Это то, что делают привязки. Они действуют как связующее звено между двумя слоями, поэтому Node.js может беспрепятственно использовать низкоуровневый код, написанный на C или C++. Итак, что нам следует делать, если мы хотим добавить модуль C++ самостоятельно? Сначала мы реализуем модуль на C++, а затем пишем для него код привязки. Этот код, который мы пишем, называется дополнением. Более подробную информацию можно найти здесь.
Зависимости Node.js: Этот уровень представляет низкоуровневые библиотеки, которые использует узел. Самые большие зависимости — это движок Google V8 и Libuv. Другие библиотеки включают OpenSSL (для SSL, TLS и других базовых криптографических функций), HTTP-parser (для анализа HTTP-запросов и ответов), C-Ares (для асинхронных DNS-запросов) и Zlib (для быстрого сжатия и распаковки).
Операционная система: это самый низкий уровень, который представляет OS API (системные вызовы - syscalls), используемые упомянутыми выше библиотеками. Поскольку операционные системы разные, библиотеки включают реализации как для Windows, так и для Unix-версий, которые делают Node.js независимым от платформы.
Несколько слов о V8 и Libuv
Libuv - это библиотека, написанная на C, которая используется для абстрактных неблокирующих операций ввода-вывода. Он предлагает следующие функции:
Цикл событий (Event Loop)
Асинхронные сокеты TCP и UDP
Асинхронное разрешение DNS
Асинхронные операции с файлами и файловой системой
Пул потоков (Thread Pool)
Дочерние процессы (Child processes)
Часы с высоким разрешением
Примитивы потоковой передачи и синхронизации
Опрос (Polling)
Потоковая передача (Streaming)
Трубы (Pipes)
V8 - это библиотека, которая предоставляет Node.js свой движок JavaScript. А именно JIT (Just-in-time) компилятор. Он непрерывно переключается между компиляцией и выполнением блоков кода. Преимущество чередования компиляции и запуска заключается в том, что он может собирать информацию во время выполнения кода и на основе полученных данных строить предположения о том, что произойдет в будущем. Эти предположения полезны для оптимизации кода.
Если вы хотите узнать больше о Node.js, я рекомендую следующие ссылки:
postgree
Неужели опять зачёты за статьи?