

Все уже много раз слышали про конкурс по машинному обучению от Билайн и даже читали статьи (раз, два). Теперь конкурс закончился, и так вышло, что первое место досталось мне. И хотя от предыдущих участников меня и отделяли всего сотые доли процента, я все же хотел бы рассказать, что же такого особенного сделал. На самом деле — ничего невероятного.
Подготовка данных
Говорят, что 80% времени аналитики данных проводят за подготовкой данных и предварительными модификациями и только 20% за непосредственно анализом. И оно так не спроста, так как «garbage in — garbage out». Процесс подготовки исходных данных можно разбить на несколько этапов, по которым я предлагаю пройтись.
Исправление выбросов
После внимательного изучения гистограмм становится ясно, что в данные закралось довольно много выбросов (outliers). Например, если вы видите, что 99.9% наблюдений переменной Х сконцентрированы на отрезке [0;1], а 0.01% наблюдений выбрасывает за сотню, то довольно логично сделать две вещи: во-первых ввести новую колонку для индикации странных событий, а во-вторых заменить выбросы чем-то разумным.
data["x8_strange"] = (data["x8"] < -3.0)*1
data.loc[data["x8"] < -3.0 , "x8"] = -3.0
data["x31_strange"] = (data["x31"] < 0.0)*1.0
data.loc[data["x31"] < 0.0, "x31"] = 0.0
data["x40_zero"] = (data["x40"] == 0.0)*1.0
Нормализация распределений
Вообще, работать с нормальными распределениями крайне приятно, так как многие статистические тесты завязаны на гипотезу о нормальности. Современных методов машинного обучения это касается в меньшей степени, но все равно привести данные к разумному виду важно. Особенно важно для методов, которые работают с расстояниями между точками (почти все алгоритмы кластеризации, классификатор k-соседей). В этой части подготовки данных я обошелся стандартным подходом: логарифмирую все, что распределено плотнее около нуля. Таким образом для каждой переменной подобрал трансформацию, которая давала более приятный вид. Ну а после этого шкалировал все в отрезок [0;1]
Текстовые переменные
Вообще, текстовые переменные — кладезь для data mining’а, но в исходных данных были только хэши, да и названия переменных были анонимизированы. Поэтому только стандартная рутина: заменить все редкие хэши на слово Rare (редкие = встречаются реже 0.5%), заменить все пропущенные данные на слово Missing и развернуть как бинарную переменную (так как многие методы, в том числе xgboost, не умеют в категориальные переменные).
data = pd.get_dummies(data, columns=["x2", "x3", "x4", "x11", "x15"])
for col in data.columns[data.dtypes == "object"]:
data.loc[data[col].isnull(), col] = 'Missing'
thr = 0.005
for col in data.columns[data.dtypes == "object"]:
d = dict(data[col].value_counts(dropna=False)/len(data))
data[col] = data[col].apply(lambda x: 'Rare' if d[x] <= thr else x)
d = dict(data['x0'].value_counts(dropna=False)/len(data))
data = pd.get_dummies(data, columns=data.columns[data.dtypes == "object"])
Feature engineering
Это то, за что мы все любим data science. Но все зашифровано, поэтому этот пункт придется опустить. Почти. После пристального изучения графиков, я заметил, что x55+x56+x57+x58+x59+x60 = 1, а значит это какие-то доли. Скажем, какой процент денег абонент тратит на СМС, звонки, интернет, etc. А значит особый интерес представляют те товарищи, у которых какая-либо из долей более 90% или менее 5%. Таким образом получаем 12 новых переменных.
thr_top = 0.9
thr_bottom = 0.05
for col in ["x55", "x56", "x57", "x58", "x59", "x60"]:
data["mostly_"+col] = (data[col] >= thr_top)*1
data["no_"+col] = (data[col] <= thr_bottom)*1
Убираем NA
Тут все предельно просто: после того, как все распределения приведены к разумному виду, можно смело заменять NA-шки средним или медианой (теперь они почти совпадают). Я пробовал вообще выкинуть из обучающей выборки те строки, где более 60% переменных имеют значение NA, но добром это не кончилось.
Регрессия в качестве регрессора
Следующий шаг уже не такой банальный. Из распределения классов я предположил, что возрастные группы упорядочены, то есть 0<1…<6 или наоборот. А раз так, то можно не классифицировать, а строить регрессию. Она будет работать плохо, но зато её результат можно передать другим алгоритмам для обучения. Поэтому запускаем обычную линейную регрессию с функцией потерь huber и оптимизируем её через стохастический градиентный спуск.
from sklearn.linear_model import SGDRegressor
sgd = SGDRegressor(loss='huber', n_iter=100)
sgd.fit(train, target)
test = np.hstack((test, sgd.predict(test)[None].T))
train = np.hstack((train, sgd.predict(train)[None].T))
Кластеризация
Вторая интересная мысль, которую я пробовал: кластеризация данных методом k-средних. Если в данных есть реальная структура (а в данных по абонентам она должна быть), то k-средних её почувствует. Сначала я взял k=7, потом добавил 3 и 15 (в два раза больше и в два раза меньше). Предсказания каждого из этих алгоритмов — номера кластеров для каждого образца. Так как эти номера не упорядочены, то оставить их числами нельзя, надо обязательно бинаризовать. Итого + 25 новых переменных.
from sklearn.cluster import KMeans
k15 = KMeans(n_clusters=15, precompute_distances = True, n_jobs=-1)
k15.fit(train)
k7 = KMeans(n_clusters=7, precompute_distances = True, n_jobs=-1)
k7.fit(train)
k3 = KMeans(n_clusters=3, precompute_distances = True, n_jobs=-1)
k3.fit(train)
test = np.hstack((test, k15.predict(test)[None].T, k7.predict(test)[None].T, k3.predict(test)[None].T))
train = np.hstack((train, k15.predict(train)[None].T, k7.predict(train)[None].T, k3.predict(train)[None].T))
Обучение
Когда подготовка данных была завершена, встал вопрос, какой метод машинного обучения выбрать. В принципе, ответ на этот на этот вопрос давно известен.
На самом деле, помимо xgboost я пробовал метод k-соседей. Несмотря на то, что в пространствах высокой размерности он считается неэффективным, мне удалось добиться 75% (маленький шаг для человека и большой шаг для k-neighbors), считая расстояние не в обычном евклидовом пространстве (где переменные равноценны), а делая поправку на важность переменных, как показано в презентации.
Однако все это игрушки, и действительно хорошие результаты дала не нейросеть, не логистическая регрессия и не k-соседи, а то, что и ожидалось – xgboost. Позже, придя на защиту в Билайн, я узнал, что они также добились лучших результатов с помощью этой библиотеки. Для задач классификации она уже является чем-то типа «золотого стандарта».
«When in doubt – use xgboost»
Owen Zhang, top-2 on Kaggle.
Прежде чем начинать собственно бустить по-настоящему и получать отличные результаты, я решил посмотреть, насколько действительно важны все те колонки, которые были даны, и те, которые насоздавал я, развернув хэши и проведя кластеризацию методом К-средних. Для этого я провел легкий бустинг (не очень много деревьев), и построил столбцы, отсортированные по важности (по мнению xgboost).
gbm = xgb.XGBClassifier(silent=False, nthread=4, max_depth=10, n_estimators=800, subsample=0.5, learning_rate=0.03, seed=1337)
gbm.fit(train, target)
bst = gbm.booster()
imps = bst.get_fscore()
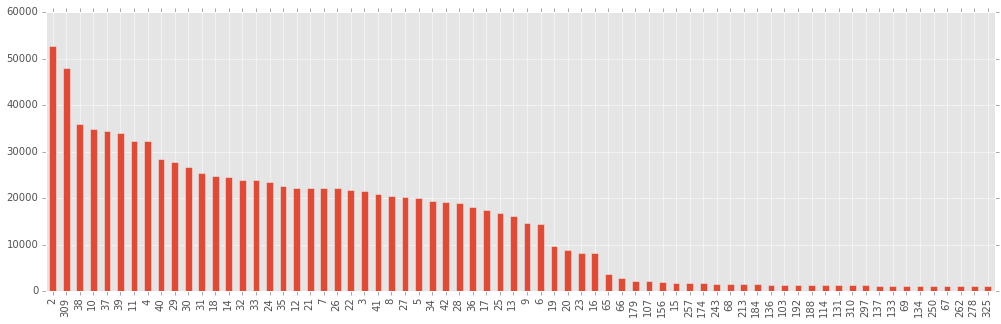
Мое мнение состоит в том, что те столбцы, важность которых оценена как “ничтожная” (а построена диаграмма только для самых важных 70 переменных из 335), содержат в себе больше шума, чем собственно полезных корреляций, и учиться по ним – себе вредить (i.e. переобучаться).
Интересно также заметить, что первая по важности переменная – x8, а вторая – результаты SGD-регрессии, добавленной мной. Те, кто пробовал участвовать в этом конкурсе, наверняка ломали голову, что за переменная x8, если она так хорошо разделяет классы. На защите в Билайне я не смог удержаться и не спросить, что же это было. Это был ВОЗРАСТ! Как мне объяснили, возраст, указанный в при покупке тарифа, и возраст, полученный в опросах, не всегда совпадают, так что да, участники действительно определяли возрастную группу в том числе и по возрасту.

Путем непродолжительных экспериментов я понял, что оставить 120 столбцов лучше, чем оставить 70 или оставить 170 (в первом случае, по всей видимости, все же выкидывается что-то полезное, во втором данные загрязнены чем-то бесполезным).
Теперь надо было бустить. Два параметра xgboost.XGBClassifier, заслуживающие наибольшего внимания – это eta (он же learning rate) и n_estimators (число деревьев). Остальные параметры не особо меняли результаты (поэтому я задал max_depth=8, subsample=0.5, а остальные параметры по умолчанию).
Между оптимальными значениями eta и n_estimators существует естественная зависимость – чем ниже eta (скорость обучения), тем больше деревьев необходимо, чтобы достичь максимальной точности. И мы действительно сталкиваемся здесь с оптимумом, после которого добавление дополнительных деревьев вызывает лишь переобучение, ухудшая точность на тестовой выборке. Например, для eta = 0.02 оптимальным будет примерно 800 деревьев:
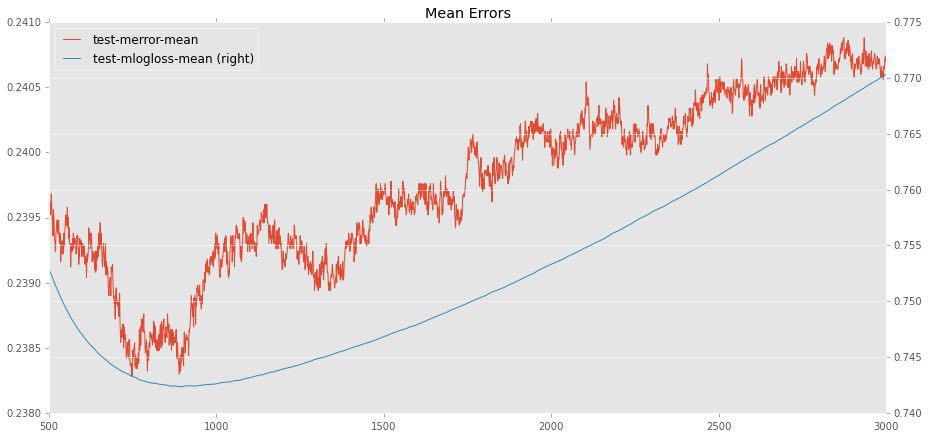
Сначала я попробовал работать с средними eta (0.01-0.03) и увидел, что в зависимости от случайного состояния (seed) есть заметный разброс (например для 0.02 счет варьируется от 76.7 до 77.1), а также заметил, что этот разброс становится меньше при уменьшении eta. Стало понятно, что большие eta не подходят в принципе (как может быть хорошей модель, настолько зависимая от seed?).
Тогда я выбрал то eta, которое могу позволить себе на моем компьютере (не хотелось бы считать сутками). Это eta=0.006. Дальше необходимо было найти оптимальное число деревьев. Тем же способом, что показан выше, я установил, что для eta=0.006 подойдет 3400 деревьев. На всякий случай я попробовал два разных seed (важно было понять, велики ли флуктуации).
for seed in [202, 203]:
gbm = xgb.XGBClassifier(silent=False, nthread=10, max_depth=8, n_estimators=3400, subsample=0.5, learning_rate=0.006, seed=seed)
gbm.fit(trainclean, target)
p = gbm.predict(testclean)
filename = ("subs/sol3400x{1}x0006.csv".format(seed))
pd.DataFrame({'ID' : test_id, 'y': p}).to_csv(filename, index=False)
Каждый ансамбль на обычном core i7 считался по полтора часа. Вполне приемлемое время, когда конкурс проходит полтора месяца. Флуктуации на public leaderboard были невелики (для seed=202 получил 77.23%, для seed=203 77.17%). Отправил лучший из них, хотя весьма вероятно, что на private leaderboard другой был бы не хуже. Впрочем, мы уже не узнаем.
Теперь немного о самом конкурсе. Первое, что бросается в глаза тому, кто знаком с Kaggle – немного необычные правила сабмита. На Kaggle число самбишнов ограничено (в зависимости от конкурса, но как правило, не более 5 в день), здесь же сабмишны безлимитные, что позволило некоторым участникам отправлять результаты аж 600 раз. Кроме того, финальный сабмишн надо было выбрать один, а на Kaggle обычно разрешается выбрать любые два, и счет на private leaderboard считается по лучшему из них.
Еще одна необычная вещь – анонимизированные столбцы. С одной стороны, это практически лишает какой-либо возможности для feature design. С другой стороны, отчасти это и понятно: столбцы с реальными названиями дали бы мощное преимущество людям, разбирающимся в мобильной связи, а цель конкурса была явно не в этом.
Комментарии (23)

Insty
07.11.2015 12:22Класс, спасибо, все понятно описано! Об XGB слышу впервые, довольно полезная штука оказывается. А численную регрессию она делать умеет? В моей практике размеры обучающей выборки бывают больше на порядки, еще ни одна библиотека не смогла такое прожевать — остается только кастомная нейросеть на плюсах и хардкорное обучение в 24 ядра на Xeon.

nurumaik
08.11.2015 03:54Численную регрессию умеет, нужно указать в конструкторе objective=«reg:linear»

Mnemonik
07.11.2015 12:39+7Вот это, я считаю, — настоящий победитель. Примерно до середины статьи читал с мыслью «о, я заморачивался точно так же!», после середины уже пошло то, до чего мне не хватило упорства, или знаний, не имеет значения. Но, очевидно, что такой подход — это подход специалиста, а не как в предыдущих статьях — «я засунул данные в веб сервис машинного обучения хх и он выдал мне 75%». От которых было немножко обидно (я выбил максимум 58 что-ли, где-то так).

AllexIn
07.11.2015 12:58+6Было круто читать! Хотя я почти ничего не понял. :( Но это проблема в моей низкой квалификации в данной области. Но все равно было очень интересно прочитать.
Спасибо!
rushter
07.11.2015 13:11+17Кратко, как я лоханулся и поверил публичному лидерборду :). В публичном я находился на отметке в 77.41, т.е. в топ 3 в таблице последнего дня, а в итоговом улетел далеко вниз.
Сделал 3 разных датасета:
1) В первом категориальные поля с большим кол-вом категорий были удалены, остальные были закодированы в бинарные фичи. У числовых переменных удалялись выбросы, а некоторые из них проходили через разнообразные преобразования.
2) Второй набор был оптимизирован для линейных моделей, от большинства которых, в итоге я отказался. На кроссвалидации в 5 проходов обычная логистическая регрессия показывала точность порядка 75.8.
3) В третем датасете все категориальные переменные были прогнаны через лассо регрессию, а их результаты использовались в качестве фичей. Это стандартная практика, т.к. модели на основе деревьев неспособны нормально воспринимать большие категориальные переменные.
На основе 2х xgboost моделей и одной randomforest с помощью первого датасета мне удалось получить 77.11.
Далее я решил попробовать stacking, эту технику давно хотелось изучить, а тут как раз повод появился.
После череды неудачных тестов я почти забросил эту идею, но в конце решил попробовать в качестве мета модели SVM и сразу же получил 77.21. Стандартным выбором для мета моделей обычно является логистическая регрессия, GBM, Knn или нейронная сеть. Все эти методы показывали достаточно неплохие результаты на моей кроссвалидации, но получали 76.7-76.9 в паблик таблице. Knn был очень нестабильный, но в самом конце он смог показать 77.27 на лидерборде. Логика говорила, что svm в качестве мета модели не может быть круче GBM, но я ей не поверил :)
C SVM все было наоборот, на кроссвалидации он показывал себя немного хуже. На этом моменте у меня закралась мысль, что тестовый датасет существенно отличается от того, на котором приходится тренировать модель или промежуточные 30% имеют перекос в сторону какого-то класса. Проверять это мне было лень, т.к. участие в конкурсе уже поднадоело, поэтому я взял запылившийся купон на 300$ для сервиса облачных вычислений и запустил сотни экспериментов на уже имеющемся у меня «фреймворке» :).
После 5 дней работы 16ти ядерного сервера я получи примерно такую модель, которая давала 77.41:

Как я уже писал выше, такой метод называется stacking, это очень популярный подход на kaggle, kddcup и т.д. Суть его достаточно проста, предсказания моделей на предыдущей уровне являются фичами для модели на следующем, в моём случае для SVM. Предсказания используются либо в обычном виде, либо в виде вероятности для каждого класса, я использовал второй подход. Чтобы не переобучить модели на первом уровне я делил обучающую выборку на две части и обучал попеременно (2-fold cv).
Плюс этого метода состоит в том, что те модели, которые слабые сами по себе и в одиночку дают точность ниже 60% могут сильно улучшить итоговые результат, если их использовать при стекинге.
После сотен автоматических экспериментов, о которых я писал выше, мне удалось найти достаточно простое решение, с использованием 4х моделей, которое давало 77.26 без стакинга.
В итоге у меня встала задача, какое решение выбрать, обычно на kaggle можно выбирать два, а тут надо было выбрать всего лишь одно.
Модель со стакингом получилась очень громоздкой и проверять её на локальной 5-fold кросс-валидации у меня не было никакого желания, поэтому решение я принимал, можно сказать, в слепую. В итоге я не устоял соблазну и сделал выбор в пользую сложной модели, хотя на практике сложные модели в итоге ведут себя хуже.
Главная ошибка — не поддаваться соблазну, делать меньше топорных экспериментов и не лениться больше изучать сами данные. Так же, в этом конкурсе, учитывая отсутствие лимитов, можно было эксплуатировать таблицу и понять примерный сплит тестовых данных, а это очень полезная информация.
Немного стыдно за результат, учитывая то, что у меня есть опыт участия 15+ конкурсах и я нахожусь в топ 100 общего рейтинга kaggle.
p.s. Жду от авторов тестовую выборку, чтобы самому покрутить результаты.
Isis
08.11.2015 07:14+1Если бы мы смотрели не последний результат, а вообще все, то твой был бы на первом месте :)
rushter
08.11.2015 08:15Я даже видел таблицу, с надписью финальный рейтинг, где я был первый, но верить ей не стал, учитывая предыдущие проблемы с организацией конкурса.
u1d
08.11.2015 19:55+3Таки 69.7% на зачетных 35000, которые Вам приписывают, тоже не похожи на правду, не верю, что та же модель, которая показывала 77%+ попаданий на пробных 15к (при том, что модель ранее эти 15к не видела) упала ниже 75% на оставшихся 35к. Скорее всего, тестовую выборку не покажут, чтоб не было бурлений по поводу некорректных итогов :)
gaploid
07.11.2015 15:44+1«этой части подготовки данных я обошелся стандартным подходом: логарифмирую все, что распределено плотнее около нуля». А не настоящий сварщик, а почему это улучшает результаты и насколько это эффективно? Я тоже логарифмами проходился, но это ничего не дало.
nurumaik
08.11.2015 04:23На деревья это не должно влиять, т.к. преобразование монотонное. Должно было быть влияние на k-means(результат используется, как дополнительные фичи) и k-neighbors, как и для любых методов, где есть понятие «расстояния». Насколько это эффективно я точно не знаю, т.к. преобразования были сделаны практически сразу. Ну и конечно на данные после таких преобразований смотреть намного приятнее :)
SantyagoSeaman
07.11.2015 16:09Тоже участвовал в этом конкурсе, но в привате оказался только на 80-м месте с результатом 75.67%.
Схема работы с данными приблизительно такая же. Отчистка данных, предварительные прогоны по xgb/glm/nn, анализ предикторов с высоким показателем важности. Была попытка генерации доп-фич в виде CTR для каждой пары класс-предиктор для ряда хорошо показавших себя предикторов. На тестовой выборке доп. фичи скорее мешали, чем помогали. Поэтому были исключены. Но благодаря им была найдена взаимосвязь между предикторами x55-60 и финальным классом. Так же обнаружилось, что каждый класс помимо самых жирных предикторов вроде x8 или x29/x30 наилучшим образом предсказывался своим набором предикторов и поэтому была сделана модель на основании xgboost, предсказывающая каждый класс в отдельности и потом делающая свёртку с коррекцией весов для каждого класса. В конечном итоге упёрся в те самые 25% выборки, которые по моим выводам предсказать было невозможно. Видимо, это те самые пенсионеры, покупающие молодёжные тарифы в подарок внучке :) И, судя по финальному месту, просто не хватило времени/терпения чтобы сделать тонкую настройку модели.

algorithmist
08.11.2015 11:01Сделайте одолжение, дайте какую-нибудь нормальную ссылку почитать про алгоритм XGboost. Именно top-level алгоритм. Реализация и детали не имеют значения.
А то я что-то никак не врублюсь, о чем идет речь.nurumaik
11.11.2015 19:18+1XGBoost — это на самом деле самая быстрая реализация алгоритма GBDT (gradient boosted decision trees). В документации есть его описание — xgboost.readthedocs.org/en/latest/model.html
YouraEnt
08.11.2015 21:47Где их можно почитать? u1d
u1d
08.11.2015 21:58+3hsto.org/storage/stuff/special/beeline/pravila_beeline_data_scientists_.pdf вот с этими правилами предлагалось согласиться при отправке решения.
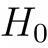
kxx
09.11.2015 00:48У меня такой вопрос: вы используете для обучения SGDRegressor и KMeans полный набор данных train, а потом же на этом же наборе с дополнительными переменными, полученными от SGDRegressor и KMeans обучаете XGBClassifier. Разве тут не должно быть переобучение XGBClassifier, который в качестве важных переменных воспримет только предсказания от SGDRegressor и KMeans?
Обычно для обучения вспомогательных моделей используют часть датасета, а основную модель обучают на второй части датасета + предсказания по этой второй части от вспомогательных моделей (как тут, например).nurumaik
11.11.2015 19:08Про SGDRegressor вы наверное правы, с таким подходом могло бы быть и лучше. Но с таким маленьким датасетом не хотелось разделять на части, т.к. маленький датасет сам по себе менее устойчив к переобучению. В KMeans все совсем немного по-другому. Он вообще запускается сразу на train+test, т.к. он unsupervised. Кластеры у него не очень соответствовали классам, и они были не самими важными(а некоторые вообще не вошли в топ100), то есть большого переобучения не могли дать.
nurumaik
12.11.2015 01:13На самом деле про train+test я обманул, KMeans у меня обучается на train :) Вспомнил про то, что лучше обучать на train+test слишком поздно и в финальную версию это не попало

sunnybear
Какую задачу решает xgboost?
voidnugget
Собственно на картинке в хабракате есть одна большая неточность: Naive Bayes, Logistic Regretion, SVM — это методы, а xgboost это библиотека для распределенного бустинга градиентов, что само по себе достаточно распространённая методика, которая используется для связки нескольких алгоритмов классификации для получения более точных результатов, её особенностью является генерализация и последующая возможность оптимизации простых дифференцируемых функций потерь.
Нужно понимать что тут нет методов которые чем-то лучше, или хуже — просто они по разному подходят для решения тех, или иных задач.
«Рейтинги» составлять — довольно нелепое занятие.