
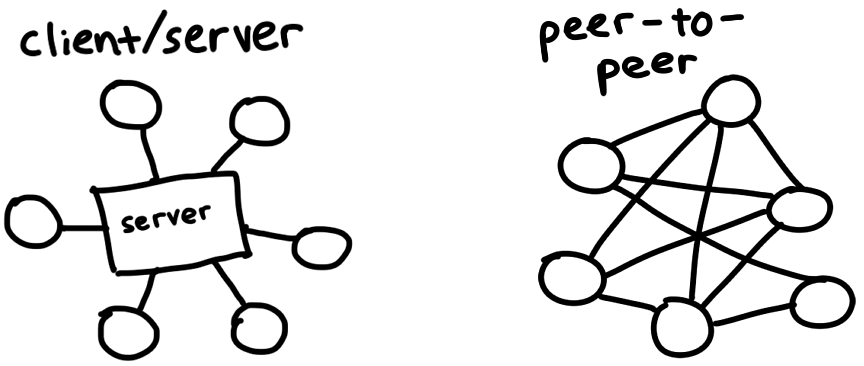
BitTorrent — протокол загрузки и распространения файлов через Интернет. В отличие от традиционных отношений клиент/сервер, когда загрузчики подключаются к центральному серверу (например, для просмотра фильма на Netflix или загрузки веб-страницы), участники сети BitTorrent, называемые одноранговыми узлами, загружают фрагменты файлов друг с друга. Это то, что делает BitTorrent одноранговым протоколом. Исследуем, как он работает, и создадим собственный клиент, который сможет находить одноранговые узлы и обмениваться с ними данными.
Протокол органично развивался в последние 20 лет, отдельные люди и организации добавили расширения для таких функций, как шифрование, приватные торренты и новые способы поиска одноранговых узлов. Чтобы управиться за выходные, реализуем оригинальную спецификацию 2001 года.
Я воспользуюсь Debian ISO, 350 МБ. Это популярный дистрибутив Linux, поэтому у нас будет множество быстрых и совместимых одноранговых узлов, к которым мы сможем подключиться. Получится также избежать юридических и этических проблем, связанных с загрузкой пиратского контента.
Поиск пиров
Вот проблема: мы хотим загрузить файл с помощью BitTorrent, но это одноранговый протокол, и мы понятия не имеем, где найти одноранговые узлы для его загрузки. Это очень похоже на переезд в новый город и попытку завести друзей — может быть, мы зайдём в местный паб или встретимся! Централизованные местоположения — главная идея трекеров, которые представляют собой центральные серверы, знакомящие одноранговые узлы друг с другом. Это просто веб-серверы, работающие по протоколу HTTP. Некоторые трекеры используют UDP — двоичный протокол для экономии полосы пропускания.

Конечно, эти центральные серверы могут подвергнуться рейду федералов, если они способствуют обмену незаконным контентом. Возможно, вы читали о том, что такие трекеры, как TorrentSpy, Popcorn Time и KickassTorrents, закрыты. Новые методы устраняют посредников, превращая в распределённый процесс даже обнаружение одноранговых узлов. Мы не будем их внедрять, но если вам интересно, некоторые термины, которые вы можете изучить, — DHT, PEX и магнитные ссылки.
Разбор файла .torrent
Файл .torrent описывает содержимое файла, доступного для торрента, и информацию для подключения к трекеру. Это всё необходимое, чтобы запустить загрузку торрента. Торрент-файл Debian выглядит так:
d8:announce41:http://bttracker.debian.org:6969/announce7:comment35:"Debian CD from cdimage.debian.org"13:creation datei1573903810e9:httpseedsl145:https://cdimage.debian.org/cdimage/release/10.2.0//srv/cdbuilder.debian.org/dst/deb-cd/weekly-builds/amd64/iso-cd/debian-10.2.0-amd64-netinst.iso145:https://cdimage.debian.org/cdimage/archive/10.2.0//srv/cdbuilder.debian.org/dst/deb-cd/weekly-builds/amd64/iso-cd/debian-10.2.0-amd64-netinst.isoe4:infod6:lengthi351272960e4:name31:debian-10.2.0-amd64-netinst.iso12:piece lengthi262144e6:pieces26800:PS^ (binary blob of the hashes of each piece)eeЭтот беспорядок закодирован в формате Bencode (произносится bee-encode), и нам нужно декодировать его.
Bencode может кодировать примерно те же типы структур, что и JSON — строки, целые числа, списки и словари. Закодированные bencode данные не так удобны для чтения / записи человеком, как JSON, но они могут эффективно обрабатывать двоичные данные, и их действительно просто анализировать из потока. Строки поставляются с префиксом длины и выглядят как 4:spam. Целые числа располагаются между маркерами start и end, поэтому 7 кодируется как i7e. Списки и словари работают аналогичным образом: l4:spami7ee представляет ['spam', 7], тогда как d4:spami7ee означает {spam: 7}.
В формате покрасивее .torrent выглядит так:
d
8:announce
41:http://bttracker.debian.org:6969/announce
7:comment
35:"Debian CD from cdimage.debian.org"
13:creation date
i1573903810e
4:info
d
6:length
i351272960e
4:name
31:debian-10.2.0-amd64-netinst.iso
12:piece length
i262144e
6:pieces
26800:PS^ (binary blob of the hashes of each piece)По этому файлу можно отследить URL трекера, дату создания (в виде временной метки Unix), имя и размер файла. Кроме этого, в файле есть большой бинарный блоб, в котором содержатся SHA-1 хэши каждой части файла. Эти части равны по размеру в пределах файла для скачивания. У разных торрентов размер части может быть разным, но обычно находится в пределах от 256 КБ до 1 МБ. Таким образом, крупный файл может состоять из тысяч частей. Эти части мы скачаем у пиров, проверим их по хэшам нашего торрент-файла и соберём их воедино. Всё. Файл готов!

Такой механизм позволяет проверить отдельно целостность каждой части файла в ходе процесса. При этом, BitTorrent устойчив к случайному и намеренному повреждению торрент-файла (torrent poisoning). Если хакеру не удалось взломать SHA-1 при помощи атаки праобраза (preimage attack), мы получим ровно тот контент, который запросили.
Здорово было бы написать свой bencode-парсер, но статья посвящена не парсерам. Парсер на 50 строк кода от Фредерика Лунда кажется мне наиболее интересным. Для этого проекта я пользовался github.com/jackpal/bencode-go:
import (
"github.com/jackpal/bencode-go"
)
type bencodeInfo struct {
Pieces string `bencode:"pieces"`
PieceLength int `bencode:"piece length"`
Length int `bencode:"length"`
Name string `bencode:"name"`
}
type bencodeTorrent struct {
Announce string `bencode:"announce"`
Info bencodeInfo `bencode:"info"`
}
// Open parses a torrent file
func Open(r io.Reader) (*bencodeTorrent, error) {
bto := bencodeTorrent{}
err := bencode.Unmarshal(r, &bto)
if err != nil {
return nil, err
}
return &bto, nil
}Мне нравится делать свои структуры относительно плоскими и отделять структуры приложения от структур сериализации (serialization structs). Поэтому я применил другую, более плоскую структуру TorrentFile и написал несколько вспомогательных функций для их взаимопреобразования.
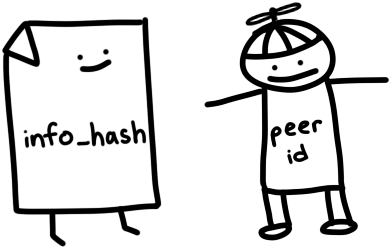
Обратите внимание, что pieces (изначально, это была строковая переменная) я разбил на хэш-слайсы (slice of hashes) по [20] байт на хэш. Это упросит доступ у отдельным хэшам. Кроме того, я рассчитал общий хэш SHA-1 всего кодированного в bencode словаря info (где содержатся имя, размер и хэш каждой части). Этот хэш известен нам как инфохэш (infohash), уникальный идентификатор файлов для передачи данных трекерам и пирам. Подробнее об этом поговорим позже.

type TorrentFile struct {
Announce string
InfoHash [20]byte
PieceHashes [][20]byte
PieceLength int
Length int
Name string
}Получение пиров через трекер
Теперь, имея информацию о файле и его трекере, давайте обратимся к трекеру для анонсирования нашего присутствия среди пиров и для получения списка других пиров. Для этого нужно составить запрос GET на URL announce в файле .torrent с несколькими параметрами запроса:
func (t *TorrentFile) buildTrackerURL(peerID [20]byte, port uint16) (string, error) {
base, err := url.Parse(t.Announce)
if err != nil {
return "", err
}
params := url.Values{
"info_hash": []string{string(t.InfoHash[:])},
"peer_id": []string{string(peerID[:])},
"port": []string{strconv.Itoa(int(Port))},
"uploaded": []string{"0"},
"downloaded": []string{"0"},
"compact": []string{"1"},
"left": []string{strconv.Itoa(t.Length)},
}
base.RawQuery = params.Encode()
return base.String(), nil
}Важные элементы кода:
-
info_hash: идентифицирует файл, который мы хотим скачать. Это инфохэш (infohash), который мы рассчитывали ранее по кодированному bencode словарю
info. Трекеру нужно знать этот хэш, чтобы показать нам именно тех пиров, которые нужны. -
peer_id: имя на 20 байт, которое идентифицирует нас на трекерах и для пиров. Для этого мы просто берём 20 случайных байтов. Реальные клиенты BitTorrent имеют ID вида
-TR2940-k8hj0wgej6ch, где закодированы программное обеспечение и его версия. В данном случае TR2940 означает Transmission client 2.94.
Парсинг ответа трекера
Мы получаем ответ, закодированный bencode:
d
8:interval
i900e
5:peers
252:(another long binary blob)
einterval указывает как часто мы можем делать запрос на сервер для обновления списка пиров. Значение 900 означает, что мы можем переподключаться раз в 15 минут (900 секунд).
peers — большой бинарный блоб, где содержатся IP-адреса каждого пира. Он образован группами по 6 байтов. Первые 4 байта — это IP адрес пира, а каждый байт показывает числовое значение в IP. Последние 2 байта — порт, в кодировке big-endian это uint16. Big-endian или сетевой порядок (network order) предполагает, что группу байтов можно представлять в виде целочисленного значения, двигаясь по порядку слева направо. Например, байты 0x1A, 0xE1 кодируются в 0x1AE1 или 6881 в десятичном формате.*Интерпретация тех же байтов в порядке little-endian дала бы 0xE11A = 57626

// Peer encodes connection information for a peer
type Peer struct {
IP net.IP
Port uint16
}
// Unmarshal parses peer IP addresses and ports from a buffer
func Unmarshal(peersBin []byte) ([]Peer, error) {
const peerSize = 6 // 4 for IP, 2 for port
numPeers := len(peersBin) / peerSize
if len(peersBin)%peerSize != 0 {
err := fmt.Errorf("Received malformed peers")
return nil, err
}
peers := make([]Peer, numPeers)
for i := 0; i < numPeers; i++ {
offset := i * peerSize
peers[i].IP = net.IP(peersBin[offset : offset+4])
peers[i].Port = binary.BigEndian.Uint16(peersBin[offset+4 : offset+6])
}
return peers, nil
}Скачивание у пиров
Теперь, имея список пиров, пора подключиться к ним и скачивать файл частями! Для каждого пира мы хотим сделать следующее:
- Начало подключения к пиру по TCP. Это всё равно, что снять трубку и набрать номер.
- Двустороннее BitTorrent-рукопожатие. Это всё равно, что сказать «Алло» и услышать «Алло» в ответ.
- Обмен сообщениями (messages) для скачивания частей файла. «Мне, пожалуйста, 231-ю часть».
Начало подключения по TCP
conn, err := net.DialTimeout("tcp", peer.String(), 3*time.Second)
if err != nil {
return nil, err
}Для соединения я воспользовался таймаутом, чтобы не терять слишком много времени на пирах, которые не дают подключиться. В основном же это довольно стандартное подключении по TCP.
Хэндшейк
Мы только что подключились к пиру. Теперь нужно рукопожатие, чтобы убедиться, что этот пир:
- может взаимодействовать по протоколу BitTorrent;
- может понимать наши сообщения и отвечать на них;
- имеет нужный нам файл, или хотя бы знает, о чём идёт речь.

Как некогда говорил мой отец, хорошее рукопожатие должно быть крепким и с контактом глазами, в этом и весь секрет. В BitTorrent же секрет хорошего «рукопожатия» — или хэндшейка — включает 5 аспектов:
- Длина идентификатора протокола всегда должна быть равна 19 (0x13 в hex)
- Идентификатор протокола, который называется pstr, — это всегда строка
BitTorrent protocol - 8 **зарезервированных байтов, выставленных в 0. Некоторые из них переводятся в состояние 1 для указания поддержки отдельных расширений (extensions). Так как этого не произошло, мы оставляем им значение 0.
- Инфохэш (infohash), который мы рассчитали ранее для желаемого файла
- ID пира (Peer ID), которым мы идентифицировали себя
Собираем это всё вместе и получаем хэндшейк:
\x13BitTorrent protocol\x00\x00\x00\x00\x00\x00\x00\x00\x86\xd4\xc8\x00\x24\xa4\x69\xbe\x4c\x50\xbc\x5a\x10\x2c\xf7\x17\x80\x31\x00\x74-TR2940-k8hj0wgej6chОтправив хэндшейк пиру, мы ожидаем аналогичный хэндшейк в том же формате. Инфохэш, который мы получим в ответе, должен совпасть с нашим. Тогда будет понятно, что говорим об одном и том же файле. Если всё идёт по плану, едем дальше. Если нет, мы можем разъединиться. «Алло». «Чже ши шей Нин сян яо шеньме» «Ой, извините, ошибся номером».
Реализуем в нашем коде структуру, представляющую хэндшейк, и записываем несколько методов для их сериализации и чтения:
// A Handshake is a special message that a peer uses to identify itself
type Handshake struct {
Pstr string
InfoHash [20]byte
PeerID [20]byte
}
// Serialize serializes the handshake to a buffer
func (h *Handshake) Serialize() []byte {
buf := make([]byte, len(h.Pstr)+49)
buf[0] = byte(len(h.Pstr))
curr := 1
curr += copy(buf[curr:], h.Pstr)
curr += copy(buf[curr:], make([]byte, 8)) // 8 reserved bytes
curr += copy(buf[curr:], h.InfoHash[:])
curr += copy(buf[curr:], h.PeerID[:])
return buf
}
// Read parses a handshake from a stream
func Read(r io.Reader) (*Handshake, error) {
// Do Serialize(), but backwards
// ...
}Отправка и получение сообщений
По завершении начального хэндшейка мы можем отправлять и принимать сообщения. Конечно, если другой пир не готов принимать сообщения, мы не сможем это делать, пока он не скажет, что готов. В этом состоянии мы, с точки зрения другого пира, «заглушены» (choked). Они должны отправить нам сообщение unchoke, сообщающее, что мы можем приступить к запросу данных. По умолчанию мы считаем, что всегда «заглушены», пока не убеждаемся в обратном.
Получив сообщение unchoked, мы можем приступать к отправке запросов (requests) на части файла, а они — присылать в ответ сообщения с такими частями.

Интерпретация сообщений
У сообщения есть длина, ID и полезная нагрузка (payload). Это выглядит так:
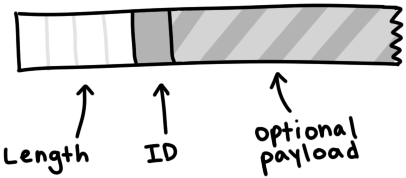
Сообщение начинается с указателя длины. Он показывает, сколько байт составит длина сообщения. Это целочисленная переменная в 32 бита, то есть 4 байта в кодировке big-endian. Следующий байт, ID, сообщает, какой тип сообщения мы получили — например, байт 2 означает «interested». Оставшуюся часть сообщения занимает полезная нагрузка.
type messageID uint8
const (
MsgChoke messageID = 0
MsgUnchoke messageID = 1
MsgInterested messageID = 2
MsgNotInterested messageID = 3
MsgHave messageID = 4
MsgBitfield messageID = 5
MsgRequest messageID = 6
MsgPiece messageID = 7
MsgCancel messageID = 8
)
// Message stores ID and payload of a message
type Message struct {
ID messageID
Payload []byte
}
// Serialize serializes a message into a buffer of the form
// <length prefix><message ID><payload>
// Interprets `nil` as a keep-alive message
func (m *Message) Serialize() []byte {
if m == nil {
return make([]byte, 4)
}
length := uint32(len(m.Payload) + 1) // +1 for id
buf := make([]byte, 4+length)
binary.BigEndian.PutUint32(buf[0:4], length)
buf[4] = byte(m.ID)
copy(buf[5:], m.Payload)
return buf
}Чтобы прочитать сообщение из потока (stream), мы просто следуем формату сообщения. Мы считываем 4 байта и интерпретируем их как uint32, чтобы узнать длину сообщения. Затем узнаём число байт, получаем ID (первый байт) и полезную нагрузку — оставшиеся байты.
// Read parses a message from a stream. Returns `nil` on keep-alive message
func Read(r io.Reader) (*Message, error) {
lengthBuf := make([]byte, 4)
_, err := io.ReadFull(r, lengthBuf)
if err != nil {
return nil, err
}
length := binary.BigEndian.Uint32(lengthBuf)
// keep-alive message
if length == 0 {
return nil, nil
}
messageBuf := make([]byte, length)
_, err = io.ReadFull(r, messageBuf)
if err != nil {
return nil, err
}
m := Message{
ID: messageID(messageBuf[0]),
Payload: messageBuf[1:],
}
return &m, nil
}Битовые поля
Один из интереснейших типов сообщений — битовое поле (bitfield). Это структура данных, с помощью которой пиры эффективно кодируют те фрагменты, которые могут отправить. Битовое поле похоже на байтовый массив (byte array). Чтобы проверить, какие части уже скачались, нужно только посмотреть на положения битов, значение которых равно 1. Можете считать это цифровым эквивалентом карты лояльности какой-нибудь кофейни. Вначале карта пуста, и все биты равны 0. Мы меняем значения на 1, чтобы «проштамповать» все позиции на карте.

Благодаря работе с битами вместо байтов, эта структура данных намного компактнее. Мы можем закодировать информацию о 8 частях в одном байте — это размер типа bool. Но цена такого подхода — большая сложность. Самый маленький размер для адресации — байт. Поэтому для работы с битами нужны некоторые манипуляции:
// A Bitfield represents the pieces that a peer has
type Bitfield []byte
// HasPiece tells if a bitfield has a particular index set
func (bf Bitfield) HasPiece(index int) bool {
byteIndex := index / 8
offset := index % 8
return bf[byteIndex]>>(7-offset)&1 != 0
}
// SetPiece sets a bit in the bitfield
func (bf Bitfield) SetPiece(index int) {
byteIndex := index / 8
offset := index % 8
bf[byteIndex] |= 1 << (7 - offset)
}Собираем всё вместе
Теперь у нас есть всё, чтобы начать скачивать файл: список пиров для трекера, связь с ними по TCP, рукопожатие, отправка и получение сообщений. Важнейшие из оставшихся задач — конкурентность при одновременной связи с несколькими пирами и управлении состоянием пиров, с которыми мы взаимодействуем. Обе задачи классические, но сложные.
Управление одновременной работой: каналы в качестве очередей
В Go память память распределяется через коммуникацию. При этом канал Go можно считать малозатратной потокобезопасной очередью.
Мы настроим два канала для синхронизации конкурентных воркеров: один для распределения задач (скачиваемых частей) между пирами, а другой — для сборки скачанных частей. Как только загруженные фрагменты попадают в канал с результатами, их можно копировать в буфер, чтобы можно было начать полную сборку файла.
// Init queues for workers to retrieve work and send results
workQueue := make(chan *pieceWork, len(t.PieceHashes))
results := make(chan *pieceResult)
for index, hash := range t.PieceHashes {
length := t.calculatePieceSize(index)
workQueue <- &pieceWork{index, hash, length}
}
// Start workers
for _, peer := range t.Peers {
go t.startDownloadWorker(peer, workQueue, results)
}
// Collect results into a buffer until full
buf := make([]byte, t.Length)
donePieces := 0
for donePieces < len(t.PieceHashes) {
res := <-results
begin, end := t.calculateBoundsForPiece(res.index)
copy(buf[begin:end], res.buf)
donePieces++
}
close(workQueue)Проводим по процессу в горутине каждого полученного на трекере пира. Каждый из них подключится к пиру, выполнит рукопожатие и будет получать задачи из workQueue, пытаясь выполнить скачивание, и отправлять скачанные части обратно по каналу results.

func (t *Torrent) startDownloadWorker(peer peers.Peer, workQueue chan *pieceWork, results chan *pieceResult) {
c, err := client.New(peer, t.PeerID, t.InfoHash)
if err != nil {
log.Printf("Could not handshake with %s. Disconnecting\n", peer.IP)
return
}
defer c.Conn.Close()
log.Printf("Completed handshake with %s\n", peer.IP)
c.SendUnchoke()
c.SendInterested()
for pw := range workQueue {
if !c.Bitfield.HasPiece(pw.index) {
workQueue <- pw // Put piece back on the queue
continue
}
// Download the piece
buf, err := attemptDownloadPiece(c, pw)
if err != nil {
log.Println("Exiting", err)
workQueue <- pw // Put piece back on the queue
return
}
err = checkIntegrity(pw, buf)
if err != nil {
log.Printf("Piece #%d failed integrity check\n", pw.index)
workQueue <- pw // Put piece back on the queue
continue
}
c.SendHave(pw.index)
results <- &pieceResult{pw.index, buf}
}
}Управление состоянием пиров
Мы будем следить за состоянием каждого пира в структуре (struct) и менять его по мере считывания полученных сообщений. В структуре будут храниться данные о том, сколько мы скачали у данного пира, сколько мы у него запросили и «заглушены» ли мы им. Всё это можно масштабировать до уровня конечного автомата, но пока нам достаточно структуры с обычным переключателем.
type pieceProgress struct {
index int
client *client.Client
buf []byte
downloaded int
requested int
backlog int
}
func (state *pieceProgress) readMessage() error {
msg, err := state.client.Read() // this call blocks
switch msg.ID {
case message.MsgUnchoke:
state.client.Choked = false
case message.MsgChoke:
state.client.Choked = true
case message.MsgHave:
index, err := message.ParseHave(msg)
state.client.Bitfield.SetPiece(index)
case message.MsgPiece:
n, err := message.ParsePiece(state.index, state.buf, msg)
state.downloaded += n
state.backlog--
}
return nil
}Пора делать запросы!
Файлами, частями и хэшами частей дело не кончится. Мы можем пойти дальше и разбить части на блоки. Блок — это фрагмент части. Его можно определить по индексу части, в которую он входит, байтовому смещению внутри части и длине. У пиров обычно запрашиваются блоки. Размер блока, как правило, 16 КБ, поэтому для получения части в 256 KB может понадобится 16 запросов.
Пир должен разрывать соединение при получении запроса на блок более 16 КБ. Но, как я знаю по своему опыту, большинство клиентов прекрасно обрабатывает запросы на блоки до 128 КБ. Но у меня прирост скорости при этом был довольно скромным, поэтому лучше, придерживаться требований спецификации.
Конвейерная обработка
Двусторонняя передача по сети (network round-trips) обходится дорого, а поблочные запросы зачастую просто убийственны для скорости скачивания. Поэтому важна конвейерная обработка запросов, при которой бремя незавершённых определённого числа процессов будет поддерживаться постоянным. Это может на порядок повысить пропускную способность нашего соединения.
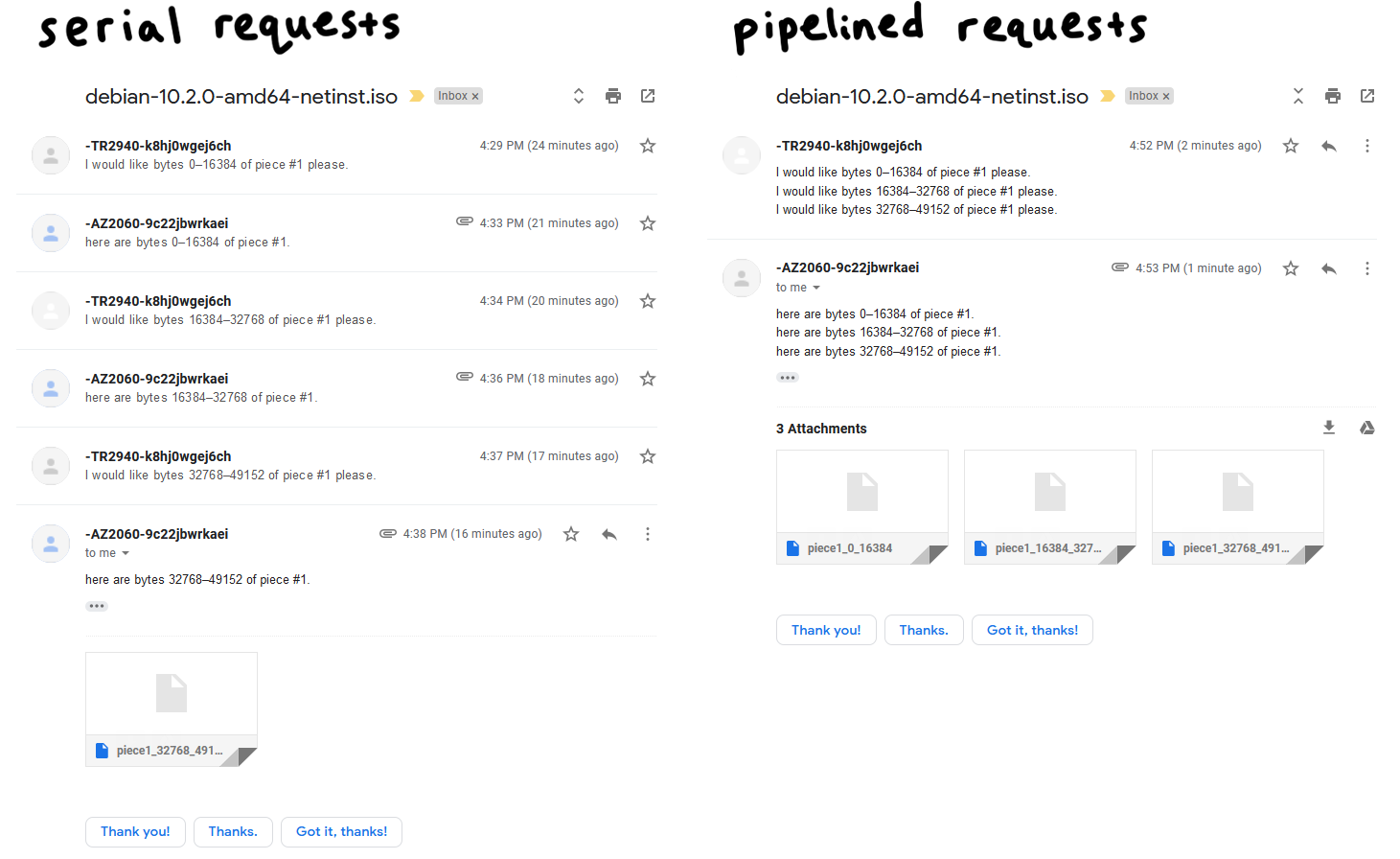
Клиенты BitTorrent традиционно поддерживают очередь из 5 конвейерных запросов (pipelined requests), и я возьму то же значение. Как я увидел, увеличение этого значения может удвоить скорость скачивания. Более современные клиенты используют адаптивный размер очереди (adaptive queue size), что лучше соответствует скоростям и условиям современных сетей. С этим параметром, определённо, стоит поиграть. Это простой и очевидный способ оптимизации производительности программы.
// MaxBlockSize is the largest number of bytes a request can ask for
const MaxBlockSize = 16384
// MaxBacklog is the number of unfulfilled requests a client can have in its pipeline
const MaxBacklog = 5
func attemptDownloadPiece(c *client.Client, pw *pieceWork) ([]byte, error) {
state := pieceProgress{
index: pw.index,
client: c,
buf: make([]byte, pw.length),
}
// Setting a deadline helps get unresponsive peers unstuck.
// 30 seconds is more than enough time to download a 262 KB piece
c.Conn.SetDeadline(time.Now().Add(30 * time.Second))
defer c.Conn.SetDeadline(time.Time{}) // Disable the deadline
for state.downloaded < pw.length {
// If unchoked, send requests until we have enough unfulfilled requests
if !state.client.Choked {
for state.backlog < MaxBacklog && state.requested < pw.length {
blockSize := MaxBlockSize
// Last block might be shorter than the typical block
if pw.length-state.requested < blockSize {
blockSize = pw.length - state.requested
}
err := c.SendRequest(pw.index, state.requested, blockSize)
if err != nil {
return nil, err
}
state.backlog++
state.requested += blockSize
}
}
err := state.readMessage()
if err != nil {
return nil, err
}
}
return state.buf, nil
}main.go
Это не займёт много времени. Мы почти закончили.
package main
import (
"log"
"os"
"github.com/veggiedefender/torrent-client/torrentfile"
)
func main() {
inPath := os.Args[1]
outPath := os.Args[2]
tf, err := torrentfile.Open(inPath)
if err != nil {
log.Fatal(err)
}
err = tf.DownloadToFile(outPath)
if err != nil {
log.Fatal(err)
}
}Это не всё
Для краткости я включил сюда лишь несколько основных фрагментов кода. Замечу, что весь связующий код (glue code), синтаксический анализ (parsing), юнит-тесты и другие скучные строительные элементы программы я опустил. Полную реализацию смотрите на Github.

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (8)

Demacr
01.02.2023 10:14Годная статья, наткнулся на оригинал полгода назад и по ней тоже посмотрел/изучил как работает торрент. Ну и плюс для размяться поверх этой репы реализовал мультифайловость и параллельную загрузку со случайной записью (не по порядку как в оригинале). Отличная учебная статья.

TheRaven
01.02.2023 13:13+1По поводу бенкод-парсера встретил интересную особенность — разные клиенты (основанные на разных либах) создавали .torrent-файл с разным SHA1 из одних и тех же данных, при чем это воспроизводилось только при создании .torrent-файла из нескольких файлов, при создании из одиночного sha1 совпадал. И это не из-за private-флага.
Многодневное рытьё исходников и тесты выявили причину — кто-то сортирует словари (dictionary, «d»), а кто-то нет.
По поводу аннонсов. С обращением по HTTP всё просто, но сейчас массово пришли UDP трекеры. Есть ли наработки на эту тему?
orenty7
01.02.2023 16:49Если кому интересно, словари по стандарту должны быть отсортированы, поэтому один из клиентов вообще не торрент-файл создаёт, а непонятно что. Интересно, как при этом считается info-hash, без которого не получится отправлять запросы

batyrmastyr
01.02.2023 20:40Так инфо хэш в самом торрент файле прописан, его проверяют в сыром виде, до перевода во внутренний формат.
В стандарте раньше не была указана кодировка названий файлов (Юникод vs все остальные) + макось и винда имеют своё одарённое мнение по «составным» символам (типа записи «ё» как код «е» + код точек, но вылезает на всяких иероглифах): одна их принудительно разделяет, другая соединяет.

nikhotmsk
Первый!
Скажу честно, автор оригинальной статьи читает мои мысли. Напоминает старые времена, когда чтобы поиграть в игру, ее нужно было сначала написать. Да, долго, но зато понимаешь, как оно устроено.
developer7
Во времена спектрумов у меня был аналог. При включении в ПЗУ находился интерпретатор бейсик. И всё.
И что бы поиграть, мне приходилось писать простенькие игры. Карточные, змейки, стрелялки и прочее… Запускать, играть. После выключения всё удалялось. В следующий раз всё по новой ))))