

В прошлой статье я затронул тему генерации звука с помощью диффузионной модели. Но какие методы существуют вообще и какой из них сейчас наиболее перспективен? Сегодня мы рассмотрим долгий путь этого направления в машинном обучении. Послушаем результаты, посмотрим метрики и просто взглянем на новые технологии, применяемые в совершенно разных нейросетях для аудиосинтеза.
▍ GAN: pjloop-gan
Генеративные состязательные сети (GAN) — это модели глубокого обучения, состоящие из двух частей: генератора и дискриминатора. Генератор отвечает за создание синтетических (поддельных) данных из случайного вектора входных данных. Дискриминатор — это классификатор, который пытается решить, являются ли предоставленные входные данные реальными или синтетическими. В процессе обучения как генератор, так и дискриминатор обновляются итеративным образом, чтобы в конечном итоге создать реалистичные синтетические данные, которые вводят дискриминатор в заблуждение. Затем это можно использовать для создания оригинальных образцов с результатом по последнему слову техники (SOTA) в области изображений и других областях. GAN также использовались для создания музыки как в символической, так и в звуковой области.
Нейросети на основе GAN используются в генерации звука ещё с момента появления архитектуры. Однако ганам, как известно, трудно тренироваться из-за противоположных целей их двух частей. Ключевая идея является ключевым недостатком архитектуры. Чтобы улучшить качество и скорость обучения GAN, в работе pjloop-gan используется Projected GAN, который добавляет в дискриминатор предварительно обученную сеть объектов со случайными компонентами, которые помогают предотвратить коллапс.
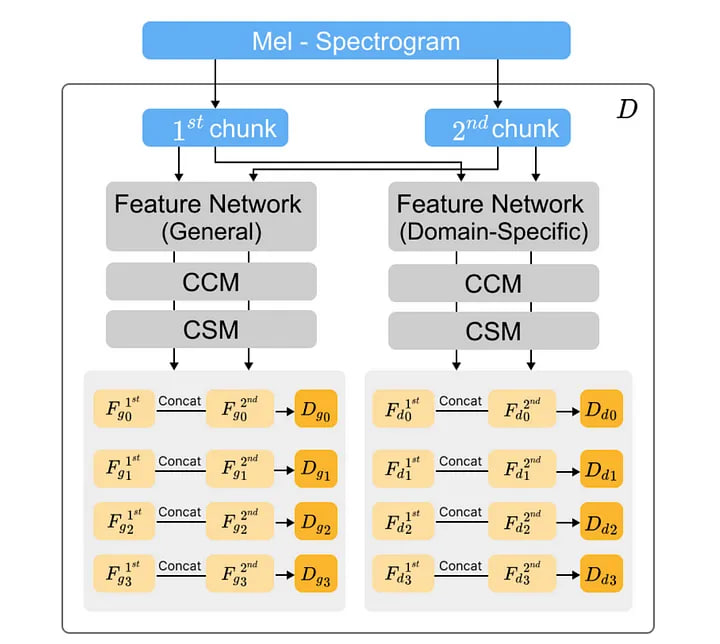
Pjloop-gan использует набор из четырёх «проекторов объектов» для сопоставления распределений данных в пространстве объектов вместо непосредственного распределения данных. Он состоит из предварительно обученной сети функций, модулей ковариационной модуляции по каналам (CCM) и модулей ковариационной модуляции по масштабу (CSM). CCM смешивает функции по каналам, в то время как CSM дополнительно смешивает их по масштабам. Случайные проекции, введённые обоими, повышают способность дискриминаторов учитывать всё пространство признаков. Прогнозируемый метод GAN обновляет свои потери путём суммирования выходных данных используемых дискриминаторов.
В качестве оценке модели авторы провели исследование, в котором участникам предлагалось оценить определённые аудиодорожки, генерируемые разными моделями, по пятибалльной шкале.
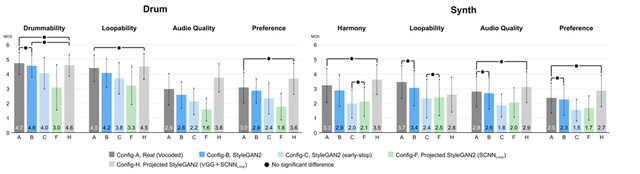
- Drummability or Harmony
Содержит ли сэмпл звуки перкуссии и гармонические звуки. - Loopability
Можно ли воспроизводить сэмпл многократно и при этом плавно. - Audio quality
Свободен ли сэмпл от неприятных шумов или артефактов.
Результаты показали, что модель, спроектированная StyleGAN2 (VGG + SCNNLoop), работала лучше всего и превзошла StyleGAN2 и реальный звук. Исследование также показало, что генеративная музыка сложнее.
Послушать
Несмотря на неплохие результаты, GAN всё ещё страдают в задаче генерации «правдоподобных» данных и слабо поддаются контролю. Всё же приятно, что практически забытыми подходами на фоне хайпа трансформеров и диффузионных моделей кто-то занимается по сей день.

▍ VAE: RAVE
Вариационные автокодеры (VAE) — это тип глубокой генеративной модели, используемой в основном для генерации синтетических данных. Они позволяют контролировать процесс генерации, раскрывая скрытую переменную, но обычно страдают от низкого качества синтеза.
VAE довольно часто и успешно используется в связи с GAN или Transformers.
Вариационный автоэнкодер звука в реальном времени (RAVE) — это улучшенная версия, которая позволяет быстро и качественно синтезировать звуковые сигналы. Он использует двухэтапную процедуру обучения, называемую обучением представлению и состязательной точной настройкой. Она применяет многополосную декомпозицию необработанной формы сигнала для генерации аудиосигналов частотой 48 кГц при работе в 20 раз быстрее, чем в реальном времени на стандартных процессорах ноутбуков. Чтобы определить наиболее информативные части скрытого пространства, RAVE использует разложение по сингулярным значениям (SVD), а также параметр точности, который определяет ранг этого пространства на основе его сингулярных значений.
Чтобы сделать модель эффективной, используется многополосная декомпозиция необработанной формы сигнала для уменьшения временной размерности данных. Это обеспечивает большее временное восприимчивое поле при той же вычислительной мощности. Кодер сочетает в себе многополосную декомпозицию и CNN для преобразования необработанной формы сигнала в 128-мерное скрытое представление. Декодер представляет собой модифицированную версию генератора, который преобразует последний скрытый слой в многополосный аудиосигнал, огибающую амплитуды и генератор шума. Дискриминатор используется для предотвращения артефактов и потери соответствия признаков для лучшего обучения. Наконец, для обучения модели на графическом процессоре TITAN требуется около 6 дней, и она сравнивается с двумя неконтролируемыми моделями для оценки.
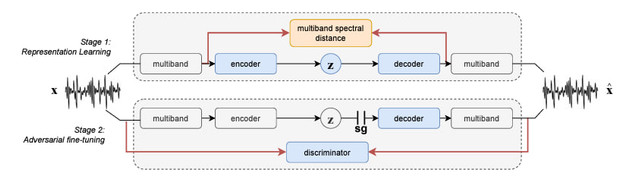
Двухэтапная процедура обучения — это процесс, используемый для обучения вариационного автоэнкодера, который является разновидностью алгоритма машинного обучения.
Этап № 1 двухэтапной процедуры обучения — обучение представлению, которое включает в себя использование многомасштабного спектрального расстояния для измерения расстояния между реальной и синтезированной формой сигнала. Это делается путём измерения сходства по амплитуде кратковременного преобразования Фурье.
Этап № 2 двухэтапной процедуры обучения — состязательная тонкая настройка. Включает в себя обучение декодера генерации реалистичных синтезированных сигналов, используя скрытое пространство со стадии 1 в качестве базового распределения и фокусируясь на версии цели GAN с потерями. Этот этап также включает в себя минимизацию спектрального расстояния и добавление потери соответствия характеристикам.

Результаты субъективных экспериментов (MOS) показывают, что RAVE превосходит существующие модели с точки зрения качества реконструкции, не полагаясь на генерацию авторегрессии или ограничение диапазона возможных генерируемых сигналов. Кроме того, он достигает этого с параметрами, по крайней мере, в 3 раза меньшими, чем у других протестированных моделей. Недавно был выпущен RAVE2 — это даёт надежду, что авторы готовы дорабатывать и улучшать свою нейросеть. Это уже больше похоже на перспективы.
Послушать результаты (к сожалению, есть результат только от первой версии — вторая вышла совсем недавно).
▍ Diffusion: audio-diffusion
Диффузионные модели стали очень популярны для создания изображений. Однако они мало применялись для создания звука. Генерация звука сложна, потому что она включает в себя множество деталей. Например, то, как звуки меняются с течением времени, и как разные звуки могут быть наложены друг на друга.
Наверное, самый выдающийся представитель диффузионных моделей в генерации звука из небольшого количества имеющихся это audio-diffusion-pytorch.
Генерация происходит очень схоже с диффузионными нейросетями для генерации изображений.
U-Net итеративно вызывается с различными уровнями шума, чтобы генерировать новые правдоподобные выборки из распределения данных. Чтобы ускорить генерацию и создать более реалистичные сэмплы, применяются различные методы, такие как сжатие с помощью автоэнкодера, который уменьшает временную размерность при увеличении дополнительных каналов, в то время как STFT увеличивает количество каналов, но уменьшает длину звука.

Для улучшения результатов автор предлагает использовать дополнительный диффузионный вокодер. Диффузионный вокодер — это модель, которая принимает звуковые сигналы и выдаёт их сглаженную версию с улучшенным качеством звука. Он делает это, сначала преобразуя волну сигнала в спектрограмму, графическое представление частот в звуке. Затем спектрограмма выравнивается с использованием типа свёртки, известного как транспонированная 1-мерная свёртка. Это выравнивание выполняется таким образом, чтобы учитывать размер окна, используемого для создания спектрограммы, и количество содержащихся в нём частотных каналов. Затем сглаженный выходной сигнал подвергается дискретизации с повышением, что означает, что он содержит дополнительные каналы, причём эти каналы вводятся в U-Net, чтобы придать звуку улучшенное качество звучания.
Такой подход даёт не только возможность восстанавливать высокие частоты и создавать недоступные для многих других моделей высококачественные формы сигналов, но и больший контроль над генерацией (посмотрите хотя бы на родственный ей Stable Diffusion).
Послушать (реально хорошая музыка).

▍ Заключение
Эффективное создание высококачественного звука — сложная задача, поскольку для точного воспроизведения звуковых волн требуется генерировать огромные массивы данных, особенно при стремлении к высококачественному стереозвуку с частотой дискретизации 48 кГц. Конечно, диффузионные нейросети показывают сейчас наибольшие успехи в этой и многих других непростых частях мира ИИ, но классические методы ещё остаются более быстрыми и простыми в использовании.
Что лучше — решать только вам.
Играй в наш скролл-шутер прямо в Telegram и получай призы! ????️????

VitalySh
Про "реально хорошую" музыку автор явно перегнул - пока это просто какофония звуков и инструментов.
Nikuson Автор
"реально хорошая" для нейросети, по сравнению с другими
Rio
Но тест Тьюринга это уже проходит (на мне, по крайней мере). Скорее всего, в слепом тесте уже не смогу отличить подобный сгенерированный сеткой кусок трека от созданного человеком (тем более в музыкальном стиле, с которым плохо знаком, в котором и человеком-то написанная музыка звучит для неподготовленного уха как "какофония звуков и инструментов").