
Готофобия – это боязнь использовать инструкции goto. Обычно возникает из-за непонимания и незнания контекста этой проблемы, а также из-за историй о незапамятных временах в истории программировании. Разработчики, страдающие готофобией, готовы жертвовать удобочитаемостью своего кода, только бы не прибегать к goto.
Каждая собака знает (уже мемородный) заголовок статьи Дейкстры Letters to the editor: go to statement considered harmful («О вреде оператора Go To») (изначально эта статья называлась A case against the goto statement). Но, как правило, забывают, в каком контексте была в 60-е написана эта статья. Ведь те вещи, которые сегодня воспринимаются как данность, тогда были в новинку.
Многие программисты учились своему ремеслу в мире, где оператор goto был основным инструментом, позволявшим контролировать поток управления. Даже в структурированных языках программист легко возвращался к выученным вредным привычкам и порочным методам. С другой стороны, сегодня складывается прямо противоположная ситуация: программисты не пользуются goto, когда он уместен, а вместо этого злоупотребляют другими конструкциями. По иронии судьбы, от этого читать код становится только неудобнее. Это зацикленность на ЧТО СДЕЛАТЬ ("избавиться от goto"), а не на ЗАЧЕМ ("поскольку так код становится удобнее читать и поддерживать").
В академических кругах продолжают талдычить, что "goto – это зло", даже не вполне понимая тот язык, который преподают. Из-за этого проблема только усугубляется (рассказываю на собственном опыте). Ведь кому интересно учиться хорошим практикам и дисциплине, верно? Очевидно, приятнее просто полностью игнорировать тему, оставляя студентам впоследствии лишь удивляться, отчего их атакуют велоцирапторы.
Сам по себе оператор "goto" не опасен — это языковая возможность, которая напрямую преобразуется в инструкции перехода, реализованные в машинном коде. «Goto» — точно как и указатели, перегрузка операторов и масса прочих «субъективных» зол — повсеместно ненавидят те, кто обжёгся на плохом программировании.
Если вы считаете, что спагетти-код нельзя написать «без goto», могу прислать вам несколько милейших примеров, способных развеять подобное заблуждение ;)
Если использовать goto на коротких дистанциях, снабжая хорошо документированными метками, то он позволяет писать более эффективный, быстрый и чистый код, чем пересыпанный сложными флагами или другими конструкциями. Также goto может быть безопаснее и логичнее, чем его альтернативы. Инструкция «break» - это goto; инструкция «continue» - это goto. Все эти инструкции явно переносят точку выполнения кода.
Конечно, ядро Linux стоит особняком, но даже если в таком строгом стандарте программирования как MISRA C (в редакции 2012 года) запрет на goto может быть смягчён с необходимого на рекомендуемый, то, думаю, в обычном коде вполне безопасно использовать goto так, как мы сочтём нужным.
Поэтому хочу представить некоторые ситуации и паттерны, где goto может быть приемлемым (или, возможно, наилучшим?) вариантом, либо можно хотя бы обдумать, стоит ли его использовать. Также я постараюсь упомянуть альтернативные решения без goto и рассмотреть их потенциальные недостатки (предположительно, вы уже знакомы как с их достоинствами, так и с возможными помехами, возникающими при вариантах с goto).
Источники
The C Programming Language, 2nd ed. by Kernighan & Ritchie
Modern C by Jens Gustedt
Structured Programming with go to Statements by Donald E. Knuth
Harmful GOTOs, Premature Optimizations, and Programming Myths are the Root of all Evil
Valid use of goto for error management in C? - Stack Overflow
Обработка ошибок/исключений и очистка
Образцовый пример работы с goto — в большинстве случаев приемлем, часто рекомендуется, а иногда без него даже решительно не обойтись. Применяя такой паттерн, получаем высококачественный код, так как работа алгоритма структурирована и чётко упорядочена, а ошибки и другие накладные расходы обрабатываются где-нибудь в сторонке, а не в основной линии развития программы. Альтернативы получаются не столь удобочитаемыми, а ещё в них сложно заметить, где именно основной код оказывается похоронен под ворохом проверки ошибок.
Из стандарта программирования SEI CERT языка C:
Для многих функций требуется выделять много ресурсов. Если выскальзывать и возвращаться где-нибудь в середине данной функции, не высвободив при этом всех ресурсов, то может возникнуть утечка в памяти. Распространённая ошибка — забыть высвободить один (или все) ресурс(ы) именно таким образом, поэтому цепочка goto – это простейший и самый аккуратный способ организовать выходы из функции, сохранив при этом правильный порядок высвобожденных ресурсов.
int* foo(int bar)
{
int* return_value = NULL;
if (!do_something(bar)) {
goto error_didnt_sth;
}
if (!init_stuff(bar)) {
goto error_bad_init;
}
if (!prepare_stuff(bar)) {
goto error_bad_prep;
}
return_value = do_the_thing(bar);
error_bad_prep:
clean_stuff();
error_bad_init:
destroy_stuff();
error_didnt_sth:
undo_something();
return return_value;
}Взятый наугад реальный пример из ядра Linux:
// SPDX-License-Identifier: GPL-2.0-or-later
/*
* MMP Audio Clock Controller driver
*
* Copyright (C) 2020 Lubomir Rintel <lkundrak@v3.sk>
*/
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
struct mmp2_audio_clk *priv;
int ret;
priv = devm_kzalloc(&pdev->dev,
struct_size(priv, clk_data.hws,
MMP2_CLK_AUDIO_NR_CLKS),
GFP_KERNEL);
if (!priv)
return -ENOMEM;
spin_lock_init(&priv->lock);
platform_set_drvdata(pdev, priv);
priv->mmio_base = devm_platform_ioremap_resource(pdev, 0);
if (IS_ERR(priv->mmio_base))
return PTR_ERR(priv->mmio_base);
pm_runtime_enable(&pdev->dev);
ret = pm_clk_create(&pdev->dev);
if (ret)
goto disable_pm_runtime;
ret = pm_clk_add(&pdev->dev, "audio");
if (ret)
goto destroy_pm_clk;
ret = register_clocks(priv, &pdev->dev);
if (ret)
goto destroy_pm_clk;
return 0;
destroy_pm_clk:
pm_clk_destroy(&pdev->dev);
disable_pm_runtime:
pm_runtime_disable(&pdev->dev);
return ret;
}Альтернатива без goto № 1: вложенные if
Недостатки:
вложение (антипаттерн "стрелка" )
потенциально возможно дублирование кода (см. приведённую в качестве примера функцию из Linux)
int* foo(int bar)
{
int* return_value = NULL;
if (do_something(bar)) {
if (init_stuff(bar)) {
if (prepare_stuff(bar)) {
return_value = do_the_thing(bar);
}
clean_stuff();
}
destroy_stuff();
}
undo_something();
return return_value;
}Переписанный пример из ядра Linux
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
ret = pm_clk_create(&pdev->dev);
if (!ret) {
ret = pm_clk_add(&pdev->dev, "audio");
if (!ret) {
ret = register_clocks(priv, &pdev->dev);
if (!ret) {
pm_clk_destroy(&pdev->dev);
pm_runtime_disable(&pdev->dev);
}
} else {
pm_clk_destroy(&pdev->dev);
pm_runtime_disable(&pdev->dev);
}
} else {
pm_runtime_disable(&pdev->dev);
}
return ret; // в оригинале явно возвращался 0
}А вот Microsoft дарит нам милый пример такого «красивого» вложения (версия в архиве).
Альтернатива без goto № 2: если нет – тогда очищаем
Недостатки:
код дублируется
множество точек выхода
int* foo(int bar)
{
int* return_value = NULL;
if (!do_something(bar)) {
undo_something();
return return_value;
}
if (!init_stuff(bar)) {
destroy_stuff();
undo_something();
return return_value;
}
if (!prepare_stuff(bar)) {
clean_stuff();
destroy_stuff();
undo_something();
return return_value;
}
clean_stuff();
destroy_stuff();
undo_something();
return do_the_thing(bar);
}Переписанный пример из ядра Linux
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
ret = pm_clk_create(&pdev->dev);
if (ret) {
pm_runtime_disable(&pdev->dev);
return ret;
}
ret = pm_clk_add(&pdev->dev, "audio");
if (ret) {
pm_clk_destroy(&pdev->dev);
pm_runtime_disable(&pdev->dev);
return ret;
}
ret = register_clocks(priv, &pdev->dev);
if (ret) {
pm_clk_destroy(&pdev->dev);
pm_runtime_disable(&pdev->dev);
return ret;
}
return 0;
}Альтернатива без goto № 3: флаги
Недостатки:
дополнительные переменные
«каскадирующие» булевы значения
потенциально возможны вложения
потенциально возможны сложные булевы выражения
int* foo(int bar)
{
int* return_value = NULL;
bool flag_1 = false;
bool flag_2 = false;
bool flag_3 = false;
flag_1 = do_something(bar);
if (flag_1) {
flag_2 = init_stuff(bar);
}
if (flag_2) {
flag_3 = prepare_stuff(bar);
}
if (flag_3) {
return_value = do_the_thing(bar);
}
if (flag_3) {
clean_stuff();
}
if (flag_2) {
destroy_stuff();
}
if (flag_1) {
undo_something();
}
return return_value;
}Переписанная функция mmp2_audio_clk_probe() не вполне чётко соответствует данному случаю, поэтому я решил, что лучше рассмотреть два варианта в альтернативе 3.5.
Альтернатива без goto № 3: флаг «пока и так сойдёт»
int foo(int bar)
{
int return_value = 0;
bool something_done = false;
bool stuff_inited = false;
bool stuff_prepared = false;
bool oksofar = true;
if (oksofar) { // этот IF опционален (всегда execs), но включён сюда для полноты картины
if (do_something(bar)) {
something_done = true;
} else {
oksofar = false;
}
}
if (oksofar) {
if (init_stuff(bar)) {
stuff_inited = true;
} else {
oksofar = false;
}
}
if (oksofar) {
if (prepare_stuff(bar)) {
stuff_prepared = true;
} else {
oksofar = false;
}
}
// Делаем что нужно
if (oksofar) {
return_value = do_the_thing(bar);
}
// Очистка
if (stuff_prepared) {
clean_stuff();
}
if (stuff_inited) {
destroy_stuff();
}
if (something_done) {
undo_something();
}
return return_value;Переписанный пример из ядра Linux
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
bool destroy_pm_clk = false;
ret = pm_clk_create(&pdev->dev);
if (!ret) {
ret = pm_clk_add(&pdev->dev, "audio");
if (ret) {
destroy_pm_clk = true;
}
}
if (!ret) {
ret = register_clocks(priv, &pdev->dev);
if (ret) {
destroy_pm_clk = true;
}
}
if (ret) {
if (destroy_pm_clk) {
pm_clk_destroy(&pdev->dev);
}
pm_runtime_disable(&pdev->dev);
return ret;
}
return 0;
}Переписанный пример из ядра Linux
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
bool destroy_pm_clk = false;
bool disable_pm_runtime = false;
ret = pm_clk_create(&pdev->dev);
if (ret) {
disable_pm_runtime = true;
}
if (!ret) {
ret = pm_clk_add(&pdev->dev, "audio");
if (ret) {
destroy_pm_clk = true;
}
}
if (!ret) {
ret = register_clocks(priv, &pdev->dev);
if (ret) {
destroy_pm_clk = true;
}
}
if (destroy_pm_clk) {
pm_clk_destroy(&pdev->dev);
}
if (disable_pm_runtime) {
pm_runtime_disable(&pdev->dev);
}
return ret;
}Альтернатива без goto № 4: функции
Недостатки:
-
Становится больше объектов (это не только новые функции, но зачастую и структуры) "Не умножай сущностей сверх необходимости"
Более глубокий стек вызовов
-
Часто требуется передача контекста
Увеличение числа указателей, направленных на указатели
Дополнительные структуры, о которых уже упоминалось выше
-
Фрагментированный код
Соблазн абстрагировать его без нужды
static inline int foo_2(int bar)
{
int return_value = 0;
if (prepare_stuff(bar)) {
return_value = do_the_thing(bar);
}
clean_stuff();
return return_value;
}
static inline int foo_1(int bar)
{
int return_value = 0;
if (init_stuff(bar)) {
return_value = foo_2(bar);
}
destroy_stuff();
return return_value;
}
int foo(int bar)
{
int return_value = 0;
if (do_something(bar)) {
return_value = foo_1(bar);
}
undo_something();
return return_value;
}Переписанный пример из ядра Linux
static inline int mmp2_audio_clk_probe_3(struct platform_device* pdev)
{
int ret = register_clocks(priv, &pdev->dev);
if (ret) {
pm_clk_destroy(&pdev->dev);
}
return ret;
}
static inline int mmp2_audio_clk_probe_2(struct platform_device* pdev)
{
int ret = pm_clk_add(&pdev->dev, "audio");
if (ret) {
pm_clk_destroy(&pdev->dev);
} else {
ret = mmp2_audio_clk_probe_3(pdev);
}
return ret;
}
static inline int mmp2_audio_clk_probe_1(struct platform_device* pdev)
{
int ret = pm_clk_create(&pdev->dev);
if (ret) {
pm_runtime_disable(&pdev->dev);
} else {
ret = mmp2_audio_clk_probe_2(pdev);
if (ret) {
pm_runtime_disable(&pdev->dev);
}
}
return ret;
}
static int mmp2_audio_clk_probe(struct platform_device* pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
ret = mmp2_audio_clk_probe_1(pdev);
return ret;
}Альтернатива без goto № 5: злоупотребление циклами
Недостатки:
Половина недостатков, характерных goto
Половина недостатков, характерных другим альтернативам
Никаких преимуществ от двух вышеупомянутых стратегий
Никакой структурности
Создаёт цикл, который не крутится
Злоупотребление одной из языковых конструкций, только бы не использовать инструмент, который как раз нужен для этой задачи
Портится читаемость кода
Контринтуитивно, путано
Добавляются ненужные вложения
Больше строк кода
И не думайте поставить полноценный цикл где-нибудь внутри этой мешанины, даже если он целесообразен
int* foo(int bar)
{
int* return_value = NULL;
do {
if (!do_something(bar)) break;
do {
if (!init_stuff(bar)) break;
do {
if (!prepare_stuff(bar)) break;
return_value = do_the_thing(bar);
} while (0);
clean_stuff();
} while (0);
destroy_stuff();
} while (0);
undo_something();
return return_value;
}Переписанный пример из ядра Linux
static int mmp2_audio_clk_probe(struct platform_device *pdev)
{
// ...
pm_runtime_enable(&pdev->dev);
do {
ret = pm_clk_create(&pdev->dev);
if (ret) break;
do {
ret = pm_clk_add(&pdev->dev, "audio");
if (ret) break;
ret = register_clocks(priv, &pdev->dev);
if (ret) break;
} while (0);
pm_clk_destroy(&pdev->dev);
} while (0);
pm_runtime_disable(&pdev->dev);
return ret;
}Перезапуск/повторная попытка
Такие случаи особенно обычны в *nix-системах, когда приходится иметь дело с системными вызовами, возвращающими ошибку при прерывании сигналом. Также системный вызов устанавливает errno в EINTR, чтобы указать, что работа идёт нормально, просто была прервана. Разумеется, такие примеры не ограничиваются системными вызовами.
#include <errno.h>
int main()
{
retry_syscall:
if (some_syscall() == -1) {
if (errno == EINTR) {
goto retry_syscall;
}
// обрабатываем настоящие ошибки
}
return 0;
}Думаю, что в данном конкретном случае один дополнительный уровень вложения не так плох. Но, буду честен: не переписав его, я не смог бы как следует представить альтернативу без goto.
Версия, в которой сокращены вложения:
#include <errno.h>
int main()
{
int res;
retry_syscall:
res = some_syscall();
if (res == -1 && errno == EINTR) {
goto retry_syscall;
}
"if (res == -1)"
// обрабатываем настоящие ошибки
}
return 0;
}Альтернатива без goto: цикл
Разумеется, можно воспользоваться циклом do {} while, указав условия в while:
#include <errno.h>
int main()
{
int res;
do {
res = some_system_call();
} while (res == -1 && errno == EINTR);
if (res == -1) {
// обрабатываем реальные ошибки
}
return 0;
}Думаю, обе альтернативы примерно одинаково удобно читать, но в версии с goto есть небольшое преимущество: здесь сразу видно, что лучше обойтись без цикла, тогда как while может быть неверно интерпретирован как цикл ожидания.
Менее тривиальный пример
Рассмотрим такой пример: я хочу разнообразить общую монохромную тему на сайте и определить цвета для подсветки синтаксиса. Даже при простом парсинге, который делается с помощью kramdown (в данном случае ваш редактор кода определённо справится с задачей лучше), уже заметно, как немного проступают на общем фоне кода метки и инструкции goto. С другой стороны, флаги почти теряются на фоне других переменных.
Версия с goto
#include <string.h>
enum {
PKT_THIS_OPERATION,
PKT_THAT_OPERATION,
PKT_PROCESS_CONDITIONALLY,
PKT_CONDITION_SKIPPED,
PKT_ERROR,
READY_TO_SEND,
NOT_READY_TO_SEND
};
int parse_packet()
{
static int packet_error_count = 0;
int packet[16] = { 0 };
int packet_length = 123;
_Bool packet_condition = 1;
int packet_status = 4;
// получить пакет и т.д.
REPARSE_PACKET:
switch (packet[0]) {
case PKT_THIS_OPERATION:
if (/* проблемная ситуация */) {
goto PACKET_ERROR;
}
// ... обработать THIS_OPERATION
break;
case PKT_THAT_OPERATION:
if (/* проблемная ситуация */) {
goto PACKET_ERROR;
}
// ... обработать THAT_OPERATION
break;
// ...
case PKT_PROCESS_CONDITIONALLY:
if (packet_length < 9) {
goto PACKET_ERROR;
}
if (packet_condition && packet[4]) {
packet_length -= 5;
memmove(packet, packet+5, packet_length);
goto REPARSE_PACKET;
} else {
packet[0] = PKT_CONDITION_SKIPPED;
packet[4] = packet_length;
packet_length = 5;
packet_status = READY_TO_SEND;
}
break;
// ...
default:
PACKET_ERROR:
packet_error_count++;
packet_length = 4;
packet[0] = PKT_ERROR;
packet_status = READY_TO_SEND;
break;
}
// ...
return 0;
}Версия без goto
#include <string.h>
enum {
PKT_THIS_OPERATION,
PKT_THAT_OPERATION,
PKT_PROCESS_CONDITIONALLY,
PKT_CONDITION_SKIPPED,
PKT_ERROR,
READY_TO_SEND,
NOT_READY_TO_SEND
};
int parse_packet()
{
static int packet_error_count = 0;
int packet[16] = { 0 };
int packet_length = 123;
_Bool packet_condition = 1;
int packet_status = 4;
// получить пакет и т.д.
_Bool REPARSE_PACKET = true;
_Bool PACKET_ERROR = false;
while (REPARSE_PACKET) {
REPARSE_PACKET = false;
PACKET_ERROR = false;
switch (packet[0]) {
case PKT_THIS_OPERATION:
if (/* проблемная ситуация */) {
PACKET_ERROR = true;
break;
}
// ... обработать THIS_OPERATION
break;
case PKT_THAT_OPERATION:
if (/* проблемная ситуация */) {
PACKET_ERROR = true;
break;
}
// ... обработать THAT_OPERATION
break;
// ...
case PKT_PROCESS_CONDITIONALLY:
if (packet_length < 9) {
PACKET_ERROR = true;
break;
}
if (packet_condition && packet[4]) {
packet_length -= 5;
memmove(packet, packet+5, packet_length);
REPARSE_PACKET = true;
break;
} else {
packet[0] = PKT_CONDITION_SKIPPED;
packet[4] = packet_length;
packet_length = 5;
packet_status = READY_TO_SEND;
}
break;
// ...
default:
PACKET_ERROR = true;
break;
}
if (PACKET_ERROR) {
packet_error_count++;
packet_length = 4;
packet[0] = PKT_ERROR;
packet_status = NOT_READY_TO_SEND;
break;
}
}
// ...
return 0;
}Общий код в инструкции switch
В такой ситуации бывает очень удобно проверить: а вдруг код вообще не нуждается в рефакторинге. Даже при этом иногда бывает желательно иметь оператор switch там, где условия вносят в код мелкие изменения, а затем этот код снова запускается.
Естественно, общий код хочется вынести в отдельную функцию, но затем этой функции требуется передавать весь контекст. Всё это может быть неудобно (например, потребуется передавать много параметров для создания выделенной структуры, в обоих случаях при этом, вероятно, будут задействованы указатели), и код ожидаемо усложнится. В некоторых случаях, возможно, вы захотите оставить всего один вызов функции, а не множество таких вызовов.
Так почему бы сразу не перейти к общему коду?
int foo(int v)
{
// ...
int something = 0;
switch (v) {
case FIRST_CASE:
something = 2;
goto common1;
case SECOND_CASE:
something = 7;
goto common1;
case THIRD_CASE:
something = 9;
goto common1;
common1:
/* код, общий для ПЕРВОГО, ВТОРОГО и ТРЕТЬЕГО случаев */
break;
case FOURTH_CASE:
something = 10;
goto common2;
case FIFTH_CASE:
something = 42;
goto common2;
common2:
/* код, общий для ЧЕТВЁРТОГО и ПЯТОГО случаев */
break;
}
// ...
}Альтернатива без goto № 1: функции
Недостатки:
«Не умножай сущности сверх необходимого»
Код приходится читать снизу вверх, а не сверху вниз
Может потребоваться передача контекста
struct foo_context {
int* something;
// ...
};
static void common1(struct foo_context ctx)
{
/* код, общий для ПЕРВОГО, ВТОРОГО и ТРЕТЬЕГО случаев */
}
static void common2(struct foo_context ctx)
{
/* код, общий для ЧЕТВЁРТОГО и ПЯТОГО случаев */
}
int foo(int v)
{
struct foo_context ctx = { NULL };
// ...
int something = 0;
ctx.something = &something;
switch (v) {
case FIRST_CASE:
something = 2;
common1(ctx);
break;
case SECOND_CASE:
something = 7;
common1(ctx);
break;
case THIRD_CASE:
something = 9;
common1(ctx);
break;
case FOURTH_CASE:
something = 10;
common2(ctx);
break;
case FIFTH_CASE:
something = 42;
common2(ctx);
break;
}
// ...
}Альтернатива без goto № 2: if-ы
Можно обойтись без красивостей и заменить оператор switch на if-ы
int foo(int v)
{
// ...
int something = 0;
if (v == FIRST_CASE || v == SECOND_CASE || v == THIRD_CASE) {
if (v == FIRST_CASE) {
something = 2;
} else if (v == SECOND_CASE) {
something = 7;
} else if (v == THIRD_CASE) { // здесь могло бы быть просто `else`
something = 9;
}
/* код, общий для ПЕРВОГО, ВТОРОГО и ТРЕТЬЕГО случаев */
} else if (v == FOURTH_CASE || v == FIFTH_CASE) {
if (v == FOURTH_CASE) {
something = 10;
} else {
something = 42;
}
/* код, общий для ЧЕТВЁРТОГО и ПЯТОГО случаев */
}
// ...
}Альтернатива без goto № 3: попеременное использование if и (0)
А… нужно ли здесь что-либо комментировать?
Нельзя одновременно утверждать, что «попеременное использование – это хорошо» и что "goto – это плохо"!
int foo(int v)
{
// ...
int something = 0;
switch (v) {
case FIRST_CASE:
something = 2;
if (0) {
case SECOND_CASE:
something = 7;
}
if (0) {
case THIRD_CASE:
something = 9;
}
/* код, общий для ПЕРВОГО, ВТОРОГО и ТРЕТЬЕГО случаев */
break;
case FOURTH_CASE:
something = 10;
if (0) {
case FIFTH_CASE:
something = 42;
}
/* код, общий для ЧЕТВЁРТОГО и ПЯТОГО случаев */
break;
}
// ...
}Вложенные break, помеченные continue
Думаю, этот пример тоже не требуется дополнительно объяснять:
#include <stdio.h>
int main()
{
for (int i = 1; i <= 5; ++i) {
printf("outer iteration (i): %d\n", i);
for (int j = 1; j <= 200; ++j) {
printf(" inner iteration (j): %d\n", j);
if (j >= 3) {
break; // выход из внутреннего цикла, внешний цикл продолжает работу
}
if (i >= 2) {
goto outer; // выход из внешнего цикла, переход непосредственно к "Done!"
}
}
}
outer:
puts("Done!");
return 0;
}Можно воспользоваться аналогичным механизмом при работе с continue.
В книге Beej's Guide to C Programming есть красивый пример, демонстрирующий,
как использовать эту технику наряду с очисткой:
for (...) {
for (...) {
while (...) {
do {
if (some_error_condition) {
goto bail;
}
// ...
} while(...);
}
}
}
bail:
// Здесь происходит очисткаБез goto пришлось бы проверять наличие флага ошибки во всех циклах, чтобы правильно пройти код.
Как покинуть цикл, выходя из инструкции switch
Аналогично, поскольку switch также использует ключевое слово break, именно из этой инструкции можно выйти, таким образом покинув цикл:
void func(int v)
{
// ...
while (1) {
switch (v) {
case SOME_V:
// ...
break; // не выходит из цикла
case STOP_LOOP:
goto break_while;
}
}
break_while:
// ...
}Простые машины состояния
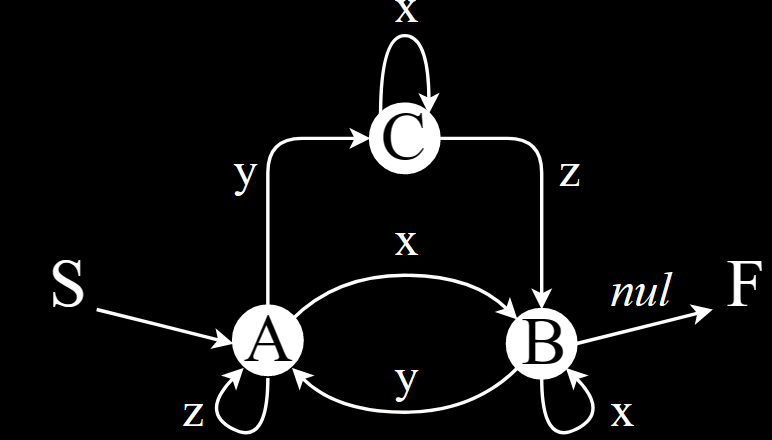
Далее приведён пример 1:1, недалеко ушедший от дословной математической нотации, позволяющей реализовать вышеприведённые автоматы:
_Bool machine(const char* c)
{
qA:
switch (*(c++)) {
case 'x': goto qB;
case 'y': goto qC;
case 'z': goto qA;
default: goto err;
}
qB:
switch (*(c++)) {
case 'x': goto qB;
case 'y': goto qA;
case '\0': goto F;
default: goto err;
}
qC:
switch (*(c++)) {
case 'x': goto qC;
case 'z': goto qB;
default: goto err;
}
F:
return true;
err:
return false;
}Переход в цикл событий
Да-да, я знаю, что предложение о переходе «в…» вас неприятно удивит. Тем не менее, в некоторых случаях вам может потребоваться сделать именно это.
Здесь на первой итерации программа не увеличивает переменную и переходит прямо к выделению. На каждой следующей итерации код выполняется именно так как записан, и при этом совершенно игнорируется метка, важная только при первом прогоне. Именно так вы поступили бы и при анализе.
#include <stdio.h>
#include <fancy_alloc.h>
int main()
{
int* buf = NULL;
size_t pos = 0;
size_t sz = 8;
int* temp;
goto ALLOC;
do {
if (pos > sz) { // изменить размер массива
sz *= 2;
ALLOC: temp = arrayAllocSmart(buf, sz, pos);
/* проверить наличие ошибок */
buf = temp;
}
/* проделать что-нибудь с буфером */
} while (checkQuit());
return 0;
/* обработка ошибок ... */
}Альтернатива без goto № 1: сторожевой флаг
Вероятно, этот пример донельзя красноречиво характеризует, насколько не выспался мой мозг, но я ухитрился допустить честную и очень тупую ошибку в этом простом фрагменте. Я её не замечал до тех пор, пока не проверил ассемблерный вывод и не увидел, что инструкций там гораздо меньше, чем ожидалось. Поскольку случай простой, но последствия весьма суровы, я решил оставить его читателям в качестве домашнего задания: найдите баг (должно быть не сложно, ведь вы уже знаете, что он здесь есть).
Недостатки — те же, что и обычно: вложения и необходимость отслеживать флаги.
#include <stdio.h>
#include <fancy_alloc.h>
int main()
{
int* buf = NULL;
size_t pos = 0;
size_t sz = 8;
int ret = 0
_Bool firstIter = true;
do {
if (pos > sz || firstIter) { // изменить размер массива
if (!firstIter) {
sz *= 2;
firstIter = false;
}
int* temp = arrayAllocSmart(buf, sz, pos);
/* обработать ошибки ... */
buf = temp;
}
/* проделать что-нибудь с буфером */
} while (checkQuit());
return 0;
}Альтернатива без goto № 2: дублирование кода
Этот недостаток очевиден, так что обойдёмся без дальнейших комментариев.
#include <stdio.h>
#include <fancy_alloc.h>
int main()
{
size_t pos = 0;
size_t sz = 8;
int* buf = arrayAllocSmart(NULL, sz, pos);
/* обработка ошибок ... */
do {
if (pos > sz) { // изменить размер массива
sz *= 2;
int* temp = arrayAllocSmart(buf, sz, pos);
/* обработать ошибки ... */
buf = temp;
}
/* проделать что-нибудь с буфером */
} while (checkQuit());
return 0;
}Оптимизация
Этот раздел даётся строго для информации, просто чтобы поставить галочку, что на практике такой вариант тоже встречается. Привести пример такого рода непросто, так как большинство таких примеров встречаются в очень ограниченных ситуациях, нередко граничащих с микрооптимизацией.
Зачастую используются такие расширения как вычисленные goto
В книге Биджа в качестве примера показана оптимизация хвостовых вызовов, к сожалению (о сожалении можно говорить только с педагогической точки зрения! Во всех остальных отношениях пример очень хорош) современные компиляторы легко оптимизируют такие простые вещи как факториал именно в такой ассемблерный код, который мы получили бы при оптимизации с использованием goto. С другой стороны, не каждому доступна такая роскошь, как современный оптимизирующий компилятор…
Структурированное программирование с использованием инструкций go to
Читайте тут: [ACM Digital Library] [PDF] [HTML]
Если я начал с Дейкстры, то естественно будет завершить Кнутом.
Почти каждый, кто положительно высказывается об инструкциях goto, ссылается на эту работу. И это справедливо! По сей день это один из самых полных источников на рассматриваемую тему (и настольная статья о goto). Пожалуй, некоторые из приведённых в ней примеров порядком устарели, некоторые проблемы не столь критичны, как на момент написания, но, тем не менее, это отличный материал.
Однако, есть вещь, которую мы здесь явно не артикулировали: из-за чего некоторые go to получаются плохими, а другие – приемлемыми. Дело в том, что внимание заостряется не на той проблеме: затрагивается объективный вопрос об устранении go to, а не важный субъективный вопрос о том, как структурировать программу. Выражаясь словами Джона Брауна, «Бросая наши мощнейшие интеллектуальные ресурсы на достижение призрачной цели писать программы без go to, мы сами себе помогли абстрагироваться от всех тех неподатливых и, возможно, нерешаемых проблем, с которыми в противном случае пришлось бы тягаться современному программисту». Написав эту длинную статью, я не хотел подлить масла в огонь споров об этих противоречиях, поскольку тема и так казалась слишком важной. Я ставил перед собой цель отложить эти противоречия в сторону и попытаться направить дискуссию в более плодотворное русло.
Комментарии (339)

NeoCode
00.00.0000 00:00+29goto - не зло, а просто весьма низкоуровеневый инструмент. Как ассемблерные вставки. Никто не применяет ассемблерные вставки где попало, просто потому что хочется, или потому что не дается структурное программирование? Вот и с goto также. Поэтому, конечно, в низкоуровневых языках, а также в универсальных, претендующих в том числе на системное программирование, оператор goto должен быть, причем у него могут быть и альтернативы, и расширения, что делает этот низкоуровневый инструмент более мощным и полноценным (хотя иногда и более опасным).
Первое - это использование именованных блоков кода и операторов break/continue с именами блоков кода. У каждого блока кода, начинающегося с ключевого слова (if, for, while, switch и т.д.) может быть имя, объявляемое после ключевого слова. Такое имя работает как метка, улучшает читаемость кода и может быть использовано для других целей - зависит от фантазии автора языка программирования. Не знаю в каких реальных языках это есть, но я подобное придумал уже давно:)
Второе - сам синтаксис объявления меток. В С/С++ он архаично-примитивен: имя и двоеточие. Это идеологически неверно, любое объявление должно начинаться с ключевого слова, например "label". Как минимум проще искать метки - и визуально, и с помощью инструментов поиска по тексту.
Третье - локальная видимость меток, т.е. метка, объявленная внутри блока кода, невидима вне этого блока кода (и в более широком смысле - явное управление видимостью меток, с локальной видимостью по умолчанию). Это дает некоторую "защиту от дурака": для выхода из вложенных циклов использовать такие метки просто, для входа куда-то вглубь - уже сложнее. В расширениях GCC это есть: https://gcc.gnu.org/onlinedocs/gcc/Local-Labels.html#Local-Labels
Четвертое - метки-переменные, массивы меток и т.д. Исключительно низкоуровневая возможность, сравнимая только с Ассемблером, в GCC опять же имеется: https://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html#Labels-as-Values

Prototik
00.00.0000 00:00+10По поводу первого - такое есть в Kotlin, очень полезная штука.
Примеры:outer@ while(/* condition */) { inner@ while(/* condition */) { if (error) { break@outer } if(eof) { break@inner // или просто break } } }Причём эти метки могут быть ещё и неявные, например, для разрешения неопределённости в каком контексте работает return в inline лямбдах:
fun compute(data: Data): Result { data.flatMap(/* process */).forEach { if (it.isSuccess) { return@compute it // это уже return из всей функции compute, а не из лямбды forEach } } }
IvanPetrof
00.00.0000 00:00+2Мне бы во многих случаях было достаточно параметра уровня для break и continue
К примеру
for ... for ... break 2; // выйти через 2 уровня циклов
dayllenger
00.00.0000 00:00-3Можно ещё так:
for ... for ... break break; for ... for ... break continue; ...Был такой proposal для C. Очень простая фича в реализации.

myxo
00.00.0000 00:00+10достаточно параметра уровня
А если при рефакторинге уберется / добавится цикл? С явными именами надежнееIvanPetrof
00.00.0000 00:00+2Справедливости ради, при рефакторинге может что угодно измениться. Так что, при должном умении, отстрелить ноги можно и с обычным break (и тем более goto).
NeoCode
00.00.0000 00:00// это уже return из всей функции compute, а не из лямбды forEach
А если мы эту лямбду вернем из функции в виде возвращаемого значения (она же first-class, значит имеем право?), и затем вызовем отдельно, то куда будет осуществлен return?

Cerberuser
00.00.0000 00:00+6А тогда мы не имеем права делать
return@compute- он работает только с лямбдой, которая в конечном счёте оказывается встроенной в вызывающую функцию (в данном случае за счёт того, чтоforEachпомечена какinline). Немного туповатый пример, но тем не менее, видно, что при попытке собрать этот код прямо говорится "return is not allowed".

Virviil
00.00.0000 00:00+2И конечно же в любом языке с hof (я уверен что и в котлине, честно не знаю синтакс) это решается гораздо читабельнее:
data.flatMap(...).first(it.isSuccess)И 99% примеров где нужен такой return или goto решаются каким-либо подобным очень простым и гораздо более читабельным способом.
И достаточно месяцок поупражняться с high order functions в хаскеле чтобы никогда в жизни в голове уже не возникала идея о необходимости раннего выхода, исключения, goto или чего-либо в таком роде.

0xd34df00d
00.00.0000 00:00У меня есть впечатление, что практически все подобные случаи являются либо абьюзом нотации (как в приведенном вами втором коде), либо существенно выиграют от разбиения на функции.

yatanai
00.00.0000 00:00+1Спорная штука, обычно это превращается в лапшу и работает только если компилятор может оптимизировать подобные выражения.
Консервативные деды недоверяют оптимизаторам. Ведь как можно гарантировать что код типа vec.iter().reverse().mutate(x=>if(x>0)--x) соберётся как "один итератор" к которому будет применяться все те модификаторы которые мы навешали.
0xd34df00d
00.00.0000 00:00Спорная штука, обычно это превращается в лапшу и работает только если компилятор может оптимизировать подобные выражения.
Ну тут от компилятора достаточно только уметь инлайнить, по большому счёту. Ничего сверхъестественного не требуется.
Консервативные деды недоверяют оптимизаторам. Ведь как можно гарантировать что код [...]
Гарантировать — никак. Но гарантировать нельзя даже отсутствие релоада чего-нибудь ненужного из памяти в регистры на каждую итерацию (если компилятору привидится алиасинг, например). Хочешь жёстких гарантий — пиши на ассемблере, обмазывайся тестами, етц.

aleksandy
00.00.0000 00:00Это вообще-то в jvm, а не в kotlin.
Prototik
00.00.0000 00:00+1Ну, да, в java такое тоже есть (а если говорить про jvm, именно про байткод - то там прямо таки есть goto в классическом его виде, не ограниченный только для break/continue).
Просто я сейчас в основном пишу на kotlin, а он компилируется не только для jvm, поэтому первый и пришёл на ум.

saboteur_kiev
00.00.0000 00:00+2В языках где есть и можно пользоваться goto, это инструмент такого же уровня как mallocate.
Можно сказать что низкоуровневый, можно сказать что обычный.

nuclight
00.00.0000 00:00-2использование именованных блоков кода и операторов break/continue с именами блоков кода. У каждого блока кода, начинающегося с ключевого слова (if, for, while, switch и т.д.) может быть имя, объявляемое после ключевого слова. Такое имя работает как метка, улучшает читаемость кода и может быть использовано для других целей - зависит от фантазии автора языка программирования. Не знаю в каких реальных языках это есть
Perl.
В С/С++ он архаично-примитивен: имя и двоеточие. Это идеологически неверно, любое объявление должно начинаться с ключевого слова, например "label". Как минимум проще искать метки - и визуально, и с помощью инструментов поиска по тексту.
Зачем? Достаточно конвенции "с начала строки", и прекрасно ищется регэкспом
^.*:
fk0
00.00.0000 00:00+4В C/C++ и многих языках пробелы не имеют значения и вся программа может содержаться в одной строке. Так что грамматику разбирать придётся. А в других языках есть многострочные строки-литералы. Там тоже grep не сработает.

DirectoriX
00.00.0000 00:00в других языках есть многострочные строки-литералы
В C++11 тоже появились сырые строки, так что даже в другие языки ходить необязательно.
А ещё встречал примеры, когда goto-метки отодвигают отступами, чтоб они визуально были в том же блоке, что и соседние строки; как по мне — красивее, чем когда метка «торчит» из блока 3-4 уровней вложенности (особенно если используются классические табы по 8 символов шириной). Впрочем, вкусовщина…
0xd34df00d
00.00.0000 00:00Если grep выдаст немного ложных срабатываний при отсутствии пропущенных случаев, то ничего страшного в этом нет, имхо.

playermet
00.00.0000 00:00+5Достаточно конвенции "с начала строки", и прекрасно ищется регэкспом
^.*:А еще этим регекспом найдутся строковые литералы с двоеточием, комментарии с двоеточием, несколько сотен/тысяч всяких "public:" и "private:", конструкторы со списками инициализации, объявления классов с наследованием, битовые поля, все case в свичах, тернарные операторы и примерно бесконечность обращений через неймспейс.

wadeg
00.00.0000 00:00+3Зачем? Достаточно конвенции «с начала строки», и прекрасно ищется регэкспом ^.*:
Этим регэкспом найдутся вообще абсолютно все двоеточия по всему тексту.

Vindex
00.00.0000 00:00По поводу первого: такое есть и в D (помимо Kotlin)
cycle1: foreach(option; [flag, altFlag]) { foreach(i, arg; args) { if (arg == option || arg.startsWith(option~"=")) { index1 = i; flag = option; break cycle1; } } }Редко приходится пользоваться, но когда приходится — довольно удобно (можно и
continueтак же использовать).
Плюс в switch-case-конструкциях можно использоватьgotoдля перехода именно
к нужному case, но это совсем не пригождалось.



DirectoriX
00.00.0000 00:00+6Сколько помню, «goto — зло, никогда не используйте его» встречал исключительно в обучающих пособиях для +- начинающих, и там это абсолютно уместно, примерно как «на 0 делить нельзя» в начальной и средней школе. Как ни крути, при использовании goto код превращается в королевские спагетти очень быстро, так что лучше использовать его там, где все другие способы хуже (а это бывает нечасто).
К счастью, если подняться чуть повыше C, то нужда вgotoотпадает (вот прям почти совсем), спасибо деструкторам.
Из «красивого», встреченного в живой природе:
В соседних похожих функциях междуvoid fn(args) { ... code ... if (!check1) goto done; ... code ... if (!check2) goto done; ... code ... if (!check3) goto done; ... code ... done: return; }done:иreturnесть некая очистка (в основном разлочить мьютексы), а в этой — простоgotoпотому что можем… ну, бывает
WinPooh73
00.00.0000 00:00+11Могу понять авторов - если в эту функцию кто-то придëт делать рефакторинг или доработку, при которой добавится содержательная обработка ошибок, ему сразу станет понятно, где еë разместить. Единообразие кода способствует его читаемости и поддерживаемости.

p07a1330
00.00.0000 00:00+3Скорее для консистнетности - если все соседние функции построены в таком духе, то и эту тоже стоит писать как остальные

Yura_PST
00.00.0000 00:00Ничего красивого, лучше заменить goto done на return.

DungeonLords
00.00.0000 00:00+1Ещё раз, между done: и return обычно есть некая очистка (например разлочить мьютексы).
0xd34df00d
00.00.0000 00:00примерно как «на 0 делить нельзя» в начальной и средней школе
Заинтриговали! А где на ноль делить можно?
DirectoriX
00.00.0000 00:00+5В рамках IEEE 754, например, получите бесконечность того же знака, что и делимое (или NaN если делимое равно 0).
А если вы готовы задействовать высшую математику, то во многих случаях предельные переходы позволяют находить точное значение a/b где b стремится к нулю. Да, это не «просто взял и разделил», но вся высшая математика такая: то пределы, то бесконечные ряды, то ещё чего похуже…0xd34df00d
00.00.0000 00:00+2В рамках IEEE 754, например, получите бесконечность того же знака, что и делимое (или NaN если делимое равно 0).
IEEE 754 так себе модель математики.
А если вы готовы задействовать высшую математику, то во многих случаях предельные переходы позволяют находить точное значение a/b где b стремится к нулю. Да, это не «просто взял и разделил», но вся высшая математика такая: то пределы, то бесконечные ряды, то ещё чего похуже…
Именно. Но и там нельзя делить на ноль: b действительно не число, а последовательность, и a/b означает тоже не деление чисел, а последовательность, i-ый элемент которой равен aᵢ/bᵢ.
Более того, если вы готовы задействовать совсем высшую математику, упороться матлогом и теорией моделей, и пойти в нестандартный анализ, где есть бесконечно большие и бесконечно малые числа, а не последовательности, то делить на ноль всё ещё нельзя даже там.
DirectoriX
00.00.0000 00:00+3IEEE 754 так себе модель математики
Как и любая другая модель, со своими достоинствами и недостатками. И всё же я настаиваю, что это корректный пример: деление на 0 определено, и в начальной-средней школе IEEE 754 (обычно) не изучают.делить на ноль всё ещё нельзя даже там
Википедия говорит, что бывают алгебры где на ноль таки можно делить: тыц. Понятия не имею, насколько это нишевые конструкции, но как второй пример сгодится.0xd34df00d
00.00.0000 00:00-1Как и любая другая модель, со своими достоинствами и недостатками.
Да, например, в ней не работают обычные свойства вроде ассоциативности и, как следствие, завязанные на ассоциативность операции (и поэтому
-ffast-mathи конкретно забыл какие флаги про ассоциативность, обратные и прочее, существенно помогают производительности). Спасибо, но я лучше буду не уметь делить на ноль, чем не уметь оптимизировать код благодаря алгебраическим преобразованиям.Ну и всё, что вы по факту делаете — это определяете
/как возвращающий не элемент вашей конечной структуры, аMaybeс этим элементом. Не думаю, что такое пополнение можно адекватно определить как «делить на ноль можно». С соответствующим пополнением вообще всё что угодно можно, и понятие «нельзя» теряет смысл.Википедия говорит, что бывают алгебры где на ноль таки можно делить: тыц.
Да, зачем нам быть группой что по сложению, что по умножению. Глупости какие, ненужное свойство.
Понятия не имею, насколько это нишевые конструкции, но как второй пример сгодится.
Можно проще: в алгебре из одного элемента (назовём его 0) можно делить на 0 без всяких извращений: 0/0 = 0, и все привычные алгебраические свойства выполняются (ну там, ∀x.∀y. (x / y) × y = x как пример).
Интересный пример, наверное.
DirectoriX
00.00.0000 00:00+1Ну и всё, что вы по факту делаете — это определяете / как возвращающий не элемент вашей конечной структуры, а Maybe с этим элементом.
Я правильно вас понимаю, что так делать нечестно, а вот обычная арифметика, возвращающаяResultпри делении (которыйErr(undefined)если делитель равен нулю) — это нормально?
Если да — не вижу смысла продолжать дальше ворочать софистику.0xd34df00d
00.00.0000 00:00Обычная арифметика не возвращает никаких Result, там
x / 0имеет примерно столько же смысла, какx / "мама мыла раму".DirectoriX
00.00.0000 00:00Какой же вы… интересный собеседник.
всё, что вы по факту делаете — это определяете / как возвращающий не элемент вашей конечной структуры, а Maybe с этим элементом.
Обычная арифметика не возвращает никаких Result
Зачем вы на ровном месте пытаетесь строить логические парадоксы?
IEEE 754 возвращает конкретное значение при делении на 0 — для вас это всего лишьMaybe.
Обычная арифметика говорит, что на 0 делить нельзя — для вас это неErr(undefined), этонельзя делить на 0.
То есть арифметикам разрешено возвращать потенциально пустое значение, но запрещено возвращать ошибку? А что тогда есть деление на 0 в обычной арифметике, если не ошибка?
Однако, вернёмся к началу треда:А где на ноль делить можно?
Я вам привёл 2 примера (IEEE 754 и алгебраические колёса) — они вас не устроили, потому что… не знаю почему, просто не устроили. Зато вы сами привели некий вырожденный пример, где на 0 делить можно:Можно проще: в алгебре из одного элемента (назовём его 0) можно делить на 0 без всяких извращений: 0/0 = 0, и все привычные алгебраические свойства выполняются (ну там, ∀x.∀y. (x / y) × y = x как пример).
Ваш собственный ответ вам же нравится? Или вы привели пример, который не пример по вашей оценке? В каком месте вы противоречите себе?0xd34df00d
00.00.0000 00:00+1IEEE 754 возвращает конкретное значение при делении на 0 — для вас это всего лишь Maybe.
У вас нет никакого адекватного сохраняющего структуру мономорфизма из [подмножества] IEEE 754-чисел в нормальные математические вещественные (или рациональные), который бы переводил результат деления n/0 в какое-то математически определённое вещественное.
То есть арифметикам разрешено возвращать потенциально пустое значение, но запрещено возвращать ошибку?
Что такое «потенциально пустое значение» в контексте арифметических операций, область значений которых, вообще говоря, те же числа?
А что тогда есть деление на 0 в обычной арифметике, если не ошибка?
Бессмысленное выражение, которое нормальные изложения оснований математики запрещают.
Деление на ноль ничем не отличается от деления на всё множество вещественных чисел или на множество всех программ, которые останавливаются за 10 шагов. Вы можете записать 10 / 0, 10 / ℕ и даже 10 / { то множество программ }, и эти выражения имеют примерно одинаковый смысл (никакой). Вы можете доопределить операцию деления, наделив смыслом каждое из них, но при этом у вас потеряются какие-то другие свойства структуры, которые, на мой взгляд, полезнее, чем умение делить на 0.
Ваш собственный ответ вам же нравится? Или вы привели пример, который не пример по вашей оценке?
Мой собственный пример мне настолько же не нравится: это не очень интересный объект.
IEEE 754 — тоже не очень интересный объект. Я бы даже сказал, что это вредный объект, потому что при прочих равных вы код на IEEE 754 даже оптимизировать толком не можете. Зато можете делить на ноль, большая удача!
DirectoriX
00.00.0000 00:00+3У вас нет никакого адекватного сохраняющего структуру мономорфизма из [подмножества] IEEE 754-чисел в нормальные математические вещественные (или рациональные)
А почему вы решили, что какие-либо преобразования между разными типами чисел вообще должны существовать? Если к 15 часам прибавить ещё 15 — это будет 30 == 6 часов, потому что модульная арифметика и всё такое. А вот 15+15 в не-модульной арифметике почему-то 30, но не 6. Как вы хотите30 == 6записать в терминах обычных вещественных (рациональных) чисел?Что такое «потенциально пустое значение» в контексте арифметических операций, область значений которых, вообще говоря, те же числа?
Откуда мне знать, это вы из кроличьей норы вытащилиMaybe. В рамках IEEE 754 любая математическая операция возвращает число, определённое тем же стандартом, ничто никуда не теряется и не становится внезапно IEEE 754-неопределённым.на мой взгляд
Во-от, с этого и надо было начинать. Зачем вообще приводить примеры, когда они субъективно плохи, и это единственное, что вам важно?Мой собственный пример мне настолько же не нравится: это не очень интересный объект
То есть вы отвергаете мои примеры, отвергаете свой собственный, потому что оказывается у примеров должны быть какие-то дополнительные, не оговорённые в явном виде свойства помимо "всего лишь соответствовать критериям запроса"? Да это же наглядный пример «без внятного ТЗ результат ХЗ».
Поскольку изначальный запрос был «А где на ноль делить можно?» — IEEE 754 является корректным ответом (как оказалось, даже не единственным). Все ваши дополнительные условия/требования — попытка не принять корректный пример как таковой.
Чтоб избегать подобных бессмысленных дискуссий в будущем, очень прошу вас впредь ко всем просьбам привести примеры добавлять что-то вроде «эти примеры должны также соответствовать любым моим хотелкам, которые могут прийти в голову во время дискуссии», либо сразу указывать полный список требований, и не ожидать от примеров чего-либо сверх указанного списка.
0xd34df00d
00.00.0000 00:00-1А почему вы решили, что какие-либо преобразования между разными типами чисел вообще должны существовать? Если к 15 часам прибавить ещё 15 — это будет 30 == 6 часов, потому что модульная арифметика и всё такое.
Модульная арифметика не претендует на то, чтобы быть моделью (в широком смысле) обычной арифметики. IEEE 754 вроде как косит под то, чтобы быть какой-то моделью вещественной арифметики.
Во-от, с этого и надо было начинать. Зачем вообще приводить примеры, когда они субъективно плохи, и это единственное, что вам важно?
Прикладная математика нужна затем, чтобы её куда-нибудь прикладывать. И вот то, насколько хорошо она к разным местам прикладывается, и показывает, насколько хороша или плоха математическая теория.
IEEE 754 хорошо прикладывается только к сопроцессору 8087 — собсна, на стандартизующих чуваков чуваки из интела в своё время и слегка нажимали тем, мол, что чё-т мы уже запилили в железе (год выхода 8087 — 1980-й), код под это дело разные люди написали, давайте стандартизуем теперь (год выхода первой версии 754 — ЕМНИП то ли 84-й, то ли 85-й).
Куда прикладываются эти ваши wheel'ы — понятия не имею, я вообще ни разу не встречался с ними вживую, а абстрактную алгебру я очень люблю. Даже эти мои одноэлементные структуры прикладываются куда чаще — это и начальный, и терминальный объект в категориях моноидов/групп/етц, оно хоть зачем-то полезно (правда, не потому, что там можно делить на ноль). Хотя, конечно, вы можете поспорить о том, насколько прикладным является аппарат теорката…
То есть вы отвергаете мои примеры, отвергаете свой собственный, потому что оказывается у примеров должны быть какие-то дополнительные, не оговорённые в явном виде свойства помимо "всего лишь соответствовать критериям запроса"? Да это же наглядный пример «без внятного ТЗ результат ХЗ».
указывать полный список требований,ИМХО лучшая статья на хабре ровно про это.

tyomitch
00.00.0000 00:00+1Модульная арифметика не претендует на то, чтобы быть моделью (в широком смысле) обычной арифметики.
Напротив: модульная арифметика в цифровых компьютерах стала наиболее широко (с огромным отрывом) применяемой моделью целочисленной арифметики. Может, вы знаете какую-нибудь более удобную модель, применимую в устройствах с конечной, дискретной, двоичной памятью? Я -- не знаю.
IEEE 754 вроде как косит под то, чтобы быть какой-то моделью вещественной арифметики.
Про неё можно сказать всё то же самое.
0xd34df00d
00.00.0000 00:00Напротив: модульная арифметика в цифровых компьютерах стала наиболее широко (с огромным отрывом) применяемой моделью целочисленной арифметики.
Нет. Начиная от того, что наиболее широко применяемые числа — всё же знаковые (а они не ведут себя как модульная арифметика, потому что
INT_MAX + 1не бывает), и заканчивая тем, что модульной (беззнаковой) арифметикой пользуются тогда, когда числа «не сильно большие», а про то, что произойдёт при переполнении, можно не думать.Когда нужна нормальная арифметика, берут длинные числа, gmp и всё такое.
Может, вы знаете какую-нибудь более удобную модель, применимую в устройствах с конечной, дискретной, двоичной памятью? Я — не знаю.
Смотря что считать «удобную». Если важно представлять произвольные числа — та же длинная арифметика. Если важно работать быстро — ну, обычная арифметика не про быстроту.

SpiderEkb
00.00.0000 00:00По моему, у вас спор слепого с глухим. Вы мешаете в кучу абстрактную математику и численные методы. Которые хоть и работают в целом по общим математическим законом, но все-таки имеют ряд допущений, связанных с реализацией всего это на уровне машинного представления чисел. Где нет понятия "бесконечность", где все, даже NaN есть некоторое представимое в виде набора бит число. И где два числа считаются равными (с точки зрения процессора) если они отличаются не более чем на некоторую предельно малую величину (для процессора опять же). Т.е.
#include <float.h> ... double a, b; ... if (a == b) { // Некорректно!!! } if (fabs(a - b) <= DBL_EPSILON) { // Корректно }
agf_ilya
00.00.0000 00:00+2Это распространённое заблуждение о том, как правильно сравнивать числа с плавающей точкой. Для критики такого сравнения - контрпример c малыми числами, между которыми помещается довольно много представимых значений double:
#include <float.h> #include <math.h> #include <stdio.h> int main() { double a = 1e-16; double b = 2e-16; if (a == b) printf("a == b"); // это условие не выполняется if (fabs(a - b) <= DBL_EPSILON) printf("fabs(a - b) <= DBL_EPSILON"); // это выполняется }Как корректно сравнивать, зависит от того, что значит "корректно". Некоторые варианты можно посмотреть, например, здесь.
Когда писал на Qt, использовал функцию qFuzzyCompare, которая определена вот так:
static inline bool qFuzzyCompare(double p1, double p2) { return (qAbs(p1 - p2) * 1000000000000. <= qMin(qAbs(p1), qAbs(p2))); } static inline bool qFuzzyCompare(float p1, float p2) { return (qAbs(p1 - p2) * 100000.f <= qMin(qAbs(p1), qAbs(p2))); }А с некоторых пор, если возможно, стараюсь избегать сравнения чисел с плавающей точкой на равенство.

Kelbon
00.00.0000 00:00-1это какая-то дичь извините написана. Нужно сравнивать умножая эпсилон на магнитуду чисел
playermet
00.00.0000 00:00А в чем принципиальная разница между умножением магнитуды на число на порядки меньше единицы с последующим сравнением с разницей, и умножение разницы на число на порядки больше единицы с последующим сравнением с магнитудой?

WASD1
00.00.0000 00:00Я думаю, что вы говорите о немного разных вещах.
Вы говорите о том, что IEEE 754 существует, а ваш собеседник, что его модель настолько плохая, что её и за модель-то считать не стоит.
Ну то есть IEEE 754 в случае переполнения портит вашу бизнес-логику (если нет прерываний, а их почти всегда нет) и вы можете вообще об этом не узнать и вместо ошибки получить какие-то неверные данные на выходе (а NAN вообще в промежуточной переменной с которой сравнились и забыли).

Hlad
00.00.0000 00:00+1Делить на ноль всё равно нельзя. Все эти пределы и правила Лопиталя сводятся к тому, чтобы путём хитрых преобразований выкинуть это самое деление из вычислений.
Проблема деления на ноль - фундаментальна: в момент деления на ноль разрывается связь в логической цепочке вычислений, и можно получить вообще любой результат. На эту тему полным полно простейших математических фокусов типа "докажем, что 2*2 = 5"

chicory-ru
00.00.0000 00:00+6Я для себя пришел к выводу, что goto очень полезен в программирование микроконтроллеров. Когда у тебя какой-нибудь микроконтроллер с флеш памятью под программу меньше 16 Кб, то при помощи goto можно написать более лаконичный и оптимизированный код. А в остальном, я тоже дискриминатор ни в чем неповинного goto. Мне, почему-то, не хочется его встречать в чужом коде, который я читаю.
fk0
00.00.0000 00:00+8Я работал в одной организации и был там один проект на микроконтроллере. Был поручен дяденьке который всю жизнь проработал в разных НИИ и не занимался коммерческим программированием. Вначале всё было хорошо. Через пару месяцев образовались огромные ватманы с чертежами блок-схем алгоритмов, начальство котороыми было восхищено и нарисованные алгоритмы начались воплощаться в программы.
В общем, в итоге, ещё через пару месяцев была написана какая-то программа, которую невозможно было отладить. Сказать, что программа была страшна -- ничего не сказать. Там алгоритмы изоморфно переносились в текст. Один лист с алгоритмом -- одна функция. И количество goto примерно соответствующее количество ромбиков со стрелочками в блок-схеме. В принципе можно было сличить блок-схему с кодом и найти сходство. Ещё, поскольку микроконтроллер "на котором нельзя динамически выделять память", эти алгоритмы изобиловали такими ужасами, что где-то в массиве A[12] в один момент времени хранится что-то одно, а в другой -- что-то другое. И главное не перепутать...
Судьба такой программы наверное понятна: была выкрашена и выброшена. После чего было начато программирование "в классическом стиле", когда без блок-схем просто пишется программа, обычным образом, с функциями, операторами и без массы goto, был принесён динамический аллокатор памяти, всё как обычно. Месяца через три была уже рабочая демка, которая скоро стала продуктом. А вот этот ужас с goto никогда продуктом не стал бы. Его постоянно приходилось бы "поддерживать" (чтоб не упал) и невозможно было бы продавать.

hhba
00.00.0000 00:00+2Какая-то немного котоламповая история, извините. Похоже, что в организации работали в основном круглые дураки (хотя скорее квадратные - отсыл к военным пенсионерам в менеджменте), либо это были первые 5 лет ее существования.
без блок-схем просто пишется программа
Которую потом никто не сможет поддерживать без блок-схем, UML-диаграмм и т.д. Но организации скорее всего уже наплевать)))
И, само собой, вся эта история не про вред goto, а про то, что программировать надо релевантно, а не как привык на прошлом месте работы. Ну или место работы выбирать релевантно.

mayorovp
00.00.0000 00:00+2Вы не путайте диаграммы с блок-схемами, первые дают взглянуть на систему под другом углом или менее детально, вторые — напротив, заставляют расписывать всё то, что обычно от программиста скрывают компилятор и стандартная библиотека. Да, наверное, если вторые готовить правильно, их тоже можно использовать для чего-нибудь полезного. К сожалению, те, кто считает что именно блок-схема является основным результатом работы программиста, "готовить" эти блок-схемы не умеют совершенно.
Не так давно пришлось мне читать дипломную работу, посвящённую созданию конвертора программ от одного станка с ЧПУ к другому. Сам "алгоритм" преобразования там заключался в 12 заменах подстрок. Угадайте, что было изображено на блок-схеме?
Там был изображён алгоритм поиска и замены подстроки. Очевидно, что именно поиск и замена подстроки — самое важное в конвертере программ для ЧПУ...
hhba
00.00.0000 00:00Это всего лишь вопрос к тому, что изображать на блок-схеме. Фраза "блок-схема алгоритма" дает автору достаточно свободы для определения того, что он считает алгоритмом, и на каком уровне разукрупнения хочет остановиться.
Мой коммент, как вы заметили, был не в ключе "блок-схемы vs диаграммы - кто победит?", а в ключе "да, конечно, сразу писать код без проектирования - это зе бест практисес". Я причем этот подход не критикую, сам так делаю порой, но тем не менее открыто заявляю всем (и себе), что непризнание программных макетов таковыми - одна из главнейших драм отрасли.
mayorovp
00.00.0000 00:00Но из "сразу писать код" далеко не всегда следует продолжение "без проектирования"...
WASD1
00.00.0000 00:00Пример очень слабый если честно и похож на "синдром утёнка". Если первый пример goto был от плохого программиста, значит.... если goto => неграмотные спецы, массивы вместо типизированных данные и т.д. и т.п.
А то, что первый же пример (с освобождением ресурсов) - типичный пример из Linux Kernel, где есть goto, а память шарится через union с флагом <=> тип-суммам как-то забывается.
ПС
Ну и да в описанном примере вопрос к менеджменту.
Если 3 месяца на разработку => 2 недели на тулчейн и стенд; 2 недели на дизайн; дальше прогать.
Ну и значит через месяц менеджмент должен был спросить:
- вы код писать уже начали?
- MVP когда
ПС2
Ну и да в похожем примере (если верить описанию) я бы сам начал с дизайна системы, т.к. в похожих случаях (общение драйвера с железкой) реализация API железки очень часто хорошо ложится на конечный автомат с неполной схемой переходов, которую проще сначала описать, потом прогать, чем хомяк-хомяк и в продакшн.

16tomatotonns
00.00.0000 00:00+1goto ещё крайне полезен в однопроходных компиляторах, где если ты его не используешь - получаешь неподдерживаемую лапшичку, или весьма прямой, конкретный, разбирабельный код если всё таки дёргаешь готушки.
fk0
00.00.0000 00:00+1Интересно. А можно пример? Именно компиляторах,не ассемблерах? У меня слово "однопроходный" ассоциируется только с ассемблером. Но в ассемблере же порядок инструкций непосредственно задан.
mayorovp
00.00.0000 00:00+1Однопроходные алгоритмы хорошо ложатся на генераторы и прочие сопрограммы. goto тут нужен только если их в языке нет.
WASD1
00.00.0000 00:00+1А зачем писать однопроходный компилятор (вы точно компилятор, например с парсером или ассемблером не спутали) в 2023 году?


smart_pic
00.00.0000 00:00+6В своих программах для МК на С использую goto когда это полезно для того что бы сделать более оптимальный по размеру и производительности код. Но я пришел к программированию на С из программирования МК на ASM, поэтому для меня не стояло этой дилеммы. И я не понимал тех кто категорично настаивал на запрете goto .
fk0
00.00.0000 00:00+4Это называется -- преждевременная оптимизация. Только проблема в том, что код для современного процессора компилятор оптимизирует, как правило, заметно лучше человека. Потому, что нужно учитывать что инструкции исполняются параллельно, что каждая инструкцию заканчивает исполнение и даёт результат за разное число тактов, и инструкции нужно разложить так, чтоб результат одной инструкции мог использоваться не раньше чем она закончит работу (иначе процессор будет бесполезно жрать), и поэтому можно спекулятивно что-то посчитать, что потребуется через несколько инструкций... Смысла в "микрооптимизациях" никакого, один вред.

BigBeaver
00.00.0000 00:00Все равно надо знать фишки архитектуры и принципы работы компилятора. Из простого — хвостовые вызовы. Если у вас килобайт флэш и сотка байт ram, то все равно придется самому думать, что дешевле — заинлайнить функцию или кидать состояние на стек.
fk0
00.00.0000 00:00Хвостовая рекурсия тривиально оптимизируется компилятором. Пример: https://godbolt.org/z/656Enfb99. Компилятор вообще умеет массу оптимизаций типично много большую, чем сходу придёт в голову программиста. Вот сходу оптимизировать рекурсию в цикл для чисел Фиббоначи -- не может, хотя есть известное решение заключающееся в добавлении дополнительного аргумента функции. Но здесь вся соль отнюдь не в goto, можно просто тело функции поместить в while(1) {} и всё.
BigBeaver
00.00.0000 00:00Хвостовые вызовы бывают не только рекурсивные. Но в целом, мой комментарий не к goto относился а к тому, что код, делающий в итоге одно и то же, но написанный по разному, компилятор может либо хорошо оптимизировать либо никак, и это надо учитывать.
0xd34df00d
00.00.0000 00:00Потому, что нужно учитывать что инструкции исполняются параллельно, что каждая инструкцию заканчивает исполнение и даёт результат за разное число тактов, и инструкции нужно разложить так, чтоб результат одной инструкции мог использоваться не раньше чем она закончит работу (иначе процессор будет бесполезно жрать), и поэтому можно спекулятивно что-то посчитать, что потребуется через несколько инструкций...
Разложить так, чтобы инструкции завершались до требования результата — это вопрос корректности, а не оптимизации. А с использованием суперскалярности в современных процессорах отлично справляется OoO и прочее подобное, как-то хитро в особом порядке шедулить инструкции статически не дает какого-либо значимого влияния на производительность.
Вот интринсики для simd использовать — другое дело, но компиляторы хорошо автовекторизуют только тривиальный код.
WASD1
00.00.0000 00:00Можно руками сделать happy path с минимумом branch (хотя во вложенном branch prediction - сужу по тестам год назад, в последние 6 лет большой прогресс, то что вызывало задержки на архитектурах 5-летней давности предсказывается на архитектурах годовой давности).
Но тут вопрос в том, что не зная прям досконально лучше не лезть.Улучшить можно, но если не разбираешься - ухудшить можно ещё сильнее, не говоря уже о поддерживаемости кода.
WASD1
00.00.0000 00:00Это ОЧЕНЬ сложный вопрос (если что peephole правила я руками для одного из компиляторов писал).
Если человек понимает что делает - может сделать немного или даже прилично лучше(*) если не понимет - то сильно хуже, как по уровню производительности так и по уровню поддерживаемости кода.
*) тут надо отметить, что по ощущениям вложенный branch prediction за последние лет 6, как я не в компиляторах в x86 хорошо улучшился.


lea
00.00.0000 00:00+14Ещё вариант - оформить код в виде автомата, чтобы избавиться от goto:
state = INIT_0; while (state != DONE) { switch (state) { case INIT_0: state = do_init_0() ? INIT_1 : CLEANUP_0; break; case INIT_1: state = do_init_1() ? DONE : CLEANUP_1; break; case CLEANUP_0: // blah-blah state = DONE; break; case CLEANUP_1: // blah-blah state = CLEANUP_0; break; } }WASD1
00.00.0000 00:00Как пример - хорошо.
Как реальный код - плохо.
Я как-то пытался лет 10 назад делать прям "автоматы-автоматы" (т.е. конечный автомат переносил в код примерно так) - через какое-то время вернулся и понял, что подход не очень.


Myclass
00.00.0000 00:00+1Если у человека "талант" в ковычках, то и без goto он может превратить код в нечитаемое что-то, например не использовать нигде name conventions для именнования переменных, обьектов, функций или классов. Если-же у человека настоящий талант, то и с goto он приготовит настоящий шедевр.
Просто надо осознать, по статистике кого больше. Это как с мусором в жизни - повсеместно запрещено кидать мусор где попал, но мусора валом везде. А если-бы не запрещали, а надеялись на личную совесть каждого? Было-бы мусора меньше? Мне кажется- нет.

mobi
00.00.0000 00:00Мне кажется, пример из ядра Linux логично смотрелся бы в таком виде:
static int mmp2_audio_clk_probe(struct platform_device *pdev) { // ... pm_runtime_enable(&pdev->dev); ret = pm_clk_create(&pdev->dev); if (!ret) { ret = pm_clk_add(&pdev->dev, "audio"); if (!ret) { ret = register_clocks(priv, &pdev->dev); if (!ret) { return 0; } } pm_clk_destroy(&pdev->dev); } pm_runtime_disable(&pdev->dev); return ret; // в оригинале явно возвращался 0 }И кода меньше, и дублирования нет, и меньше вероятность допустить ошибку. Или я где-то ошибся?

Hamletghost
00.00.0000 00:00+2В стате про это есть - это Arrow Anti Pattern. Не знаю как в ядре. Но у нас Нередко в ci используются статические анализаторы, которые будут ругаться на высокую вложенность блоков кода.
fk0
00.00.0000 00:00static int mmp2_audio_clk_probe(struct platform_device *pdev) { // ... pm_runtime_enable(&pdev->dev); ret = pm_clk_create(&pdev->dev); if (!ret) { do { ret = pm_clk_add(&pdev->dev, "audio"); if (ret) break; ret = register_clocks(priv, &pdev->dev); if (ret) break; ... return 0; } while(0); pm_clk_destroy(&pdev->dev); } pm_runtime_disable(&pdev->dev); return ret; }Можно использовать do { if (error) break... } while(0); для выхода в случае множественных проверок на ошибку.

eptr
00.00.0000 00:00+1Те, кто решили, что Arrow Anti Pattern — это антипаттерн, приводят такой пример кода (по той самой ссылке из статьи):
function isCorrect($param1, $param2, $param3) { if ($param1 !== $param2) { if ($param1 === ($param3 * 2)) { if ($param2 === ($param3 / 3)) { return true; } else { return false; } } else { return false; } } else { return false; } return false; }вместо очевидного такого:
function isCorrect($param1, $param2, $param3) { if ($param1 !== $param2) { if ($param1 === ($param3 * 2)) { if ($param2 === ($param3 / 3)) { return true; } } } return false; }И делают при этом невинный вид.
Они специально пишут не оптимальный код, выдавая свой вариант за лучший из возможных, чтобы попытаться на этом основании объявить Arrow Anti Pattern антипаттерном.
Нет, это — это именно паттерн, причём, зачастую, он лучше аналогичного с множеством
gotoи множеством меток, что mobi выше убедительно и продемонстрировал.Если статические анализаторы "заряжены" неверными посылками, логично неуместную ругань от них отключить или настроить порог их срабатывания на разумный уровень вложенности, если это возможно.
Hamletghost
00.00.0000 00:00+1А это да, я же просто отвечал на вопрос mobi, почему в статье отвергается вариант с вложенными условиями.
Статанализаторы обычно настраиваются на какую-то разумную вложенность (которая в примере mobi вполне допустима и даже наверно с запасом в 80 символов помещается). А так-то я как раз не согласен с тем как в статье это объявляется злом которое хуже goto. Также как не согласен, что разбиение на более мелкие функции тоже хуже goto (причем еще и дан специально кривой пример чтобы это продемонстрировать). Обычно это наоборот делает код более читаемым, а оверхеда не дает тк мелкие функции заинлайнятся
eptr
00.00.0000 00:00+1Поскольку тема уже была затронута, я не стал отдельный пост создавать.
В наше время 80 символов уже явно устаревшая ширина, 120 или 160 уместнее.

viordash
00.00.0000 00:00+1в guard стиле тоже симпатично:
function isCorrect($param1, $param2, $param3) { if ($param1 === $param2) { return false; } if ($param1 !== ($param3 * 2)) { return false; } if ($param2 !== ($param3 / 3)) { return false; } return true; }eptr
00.00.0000 00:00Симпатично, но copy-paste'а в виде повторяющегося
return false;мельтешит, дополнительные пустые строки междуif'ами раздувают код, и пропадает возможность структурировано освободить ресурсы в случае неудачи.В том примере по ссылке, мало того, что приведён неэффективный пример, так ещё и не показано преимущество структуры Arrow в смысле структурированного освобождения ресурсов в случае неудачи.

PeterAlmazov
00.00.0000 00:00А так?
return ($param1 !== $param2) && ($param1 === ($param3 * 2)) && ($param2 === ($param3 / 3)eptr
00.00.0000 00:00Да, конечно.
Но подразумевалось, что там должно быть ещё и структурированное освобождение ресурсов.Они там специально жульничают, сильно захламив конструкцию и не использовав её преимущество.
Фактически, они использовали её не по назначению, чтобы создать иллюзию, что паттерн — плохой.
А плохой, как раз, не паттерн.Я уже писал об этом:
В том примере по ссылке, мало того, что приведён неэффективный пример, так ещё и не показано преимущество структуры Arrow в смысле структурированного освобождения ресурсов в случае неудачи.
Без необходимости освобождения ресурсов, естественно, этот код вырождается в логическое выражение.

Mingun
00.00.0000 00:00Если уж брать читабельностью и краткостью, то оптимальный вариант:
return $param1 !== $param2 && $param1 === $param3 * 2 && $param2 === $param3 / 3Если не нужно никакого логгирования, то наиболее лаконично, иначе варианты с guard самый оптимальный, ИМХО.
saboteur_kiev
00.00.0000 00:00В детстве писал на бейсике, и какое-то время вообще не знал о наличии call, все делал через goto и не чувствовал никаких проблем.
Потом узнал про функции, понял их преимущество. Но при этом четко понимаю что goto - нормальный, полезный оператор в отдельных языках. Да, низкоуровневых, но там где именно ты контролируешь местоположение и кода и данных.
Опять таки, под капотом весь ваш код компилируется во множество goto.
aamonster
00.00.0000 00:00+2А в бейсике, когда узнали про gosub, сильно страдали от отсутствия локальных переменных? Или вы не узнали, просто язык сменили?
saboteur_kiev
00.00.0000 00:00+1вообще не страдал, и сейчас не страдаю =)
Я четко понимаю, где я бы мог использовать goto в современных языках программирования, но выгоду это принесет минимальную. Ибо удобный для чтения код - важнее в командной работе, чем мелкая оптимизация.
А высокая производительность обычно требуется в очень узком месте, которое можно написать не соблюдая human-friendly стиль, или вообще интегрировать низкоуровневую часть.В общем я не использую goto не потому, что это плохо, а потому что в подавляющем большинстве случаев, это не нужно. Но если это в конкретном случае нужно - я просто беру и юзаю, без всяких эстетических мучений
aamonster
00.00.0000 00:00Я именно про бейсик спрашивал – где был жесткач, вызвать подпрограмму можно, но переменные в ней те же, что в основной проге. Особенно доставляет при использовании рекурсии (но рекурсивная процедура заливки замкнутой области всё же получалась за счёт трюка "поменяем переменную перед вызовом, восстановим после")
Или вас зацепило ещё какими-то языками без локальных переменных?
saboteur_kiev
00.00.0000 00:00ассемблер и бейсик они оба без локальных переменных
в баше есть, но мало востребованы ибо нет смысла писать сложное на баш

CTheo
00.00.0000 00:00+2Опять таки, под капотом весь ваш код компилируется во множество goto.
Все-таки, компилятору, который делает это автоматически, по определенным шаблонам, исходники которого просматривают миллионы глаз, которым пользуются крупнейшие корпорации, как-то доверия больше, чем программисту, который в 2023 решил писать goto.
saboteur_kiev
00.00.0000 00:00а компиляторы пишут не программисты, что ли?
CTheo
00.00.0000 00:00Поэтому я и упомянул, что у разработчиков компиляторов, скорее всего, и код ревью более опытными программистами, и баги находят просто за счет большого количества заинтересованных в исправлении пользователей.

stt_s
00.00.0000 00:00-13Самое интересное, в школьном учебнике математики на полном серьёзе доказывается равенство 0.4(9) = 0.5, что для банковского округления совершенно неверно

acsent1
00.00.0000 00:00+4В компьютерах не может быть 0.4(9). Нет таких типов
stt_s
00.00.0000 00:00-5А было бы полезным, по крайней мере, в качестве теоретического построения, чтобы новоиспечённые айтишники не смотрели, как баран на новые ворота, столкнувшись с последствиями матокругления в сфере финансов

unC0Rr
00.00.0000 00:00+3При чём тут округление, если это банально одно и то же число?
stt_s
00.00.0000 00:00-30,5 округляется до единицы, 0,4(9) до нуля
Cerberuser
00.00.0000 00:00+40,499...9 с любым конечным количеством девяток округляется до нуля. 0,4(9) - до единицы, потому что его корректное представление при конечном числе значащих цифр - 0,5.
stt_s
00.00.0000 00:00+1тут некая натяжка, причём двойная, округление 0,5 в большую сторону само по себе - не очевидно
Cerberuser
00.00.0000 00:00+1Округление 0,5 в большую сторону - это то, что вы отстаиваете всю ветку, если я правильно вижу. Какая вторая натяжка?
stt_s
00.00.0000 00:00Про округление 0.5 к единице можно прочитать в том же учебнике математики, подается как некий консенсус-договорённость
SpiderEkb
00.00.0000 00:00И это действительно так. Просто договоренность о том, как уменьшить количество знаков после запятой.
В тех языках, где есть типы данных с фиксированной точкой (как правило, это языки для различного рода коммерческих расчетов - там объявление переменной содержит общее число знаков и число знаков после запятой), есть два типа присвоения для случаев когда значение переменной с большим количеством знаков после запятой присваивается переменной с меньшим количеством знаков - присвоение с отбрасыванием "лишних" знаков и присвоение с округлением. В первом случае результат для 0.49 будет 0.4, во втором - 0.5.
Какой тип присвоения когда использовать уже определяется бизнес-логикой.
Из того с чем сталкивался (или слышал) - SQL (типы NUMERIC(n, p) и DECIMAL(n, p)), COBOL, RPG (IBM'овский язык, замена коболу - типы zoned(n: p) и packed(n: p)). Также IBM в С и С++ для middlevare платформы IBM i добавила расширение в виде типов decimal(n, p) и _decimalT<n, p>
SpiderEkb
00.00.0000 00:00-1Не... Это совершенно другое.
Типы с фиксированной точкой хранятся в памяти совершенно иначе, чем типы с плавающей точкой.

Представление числа 21544 в разных форматах Т.е. тут все знаки числа хранятся в явном виде.
И арифметика с ними совершенно иная. И рекуррентное соотношение Мюллера для таких типов показывает существенно более высокую устойчивость, нежели для типов с плавающей точкой.
Присвоение:
dcl-s p1 packed(6: 3) inz(2.235); // переменная с фиксированной точкой // всего 6 знаков, 3 после запятой // проинициализирована значением 2.235 dcl-s p2 packed(5: 2); // переменная с фиксированной точкой // всего 5 знаков, 2 после запятой p2 = p1; // обычное присвоение // последний символ после запятой (5) откидывается // p2 = 2.23 eval(h) p2 = p1; // присвоение с округлением // последний символ откидывается // предпоследний округляется // p2 = 2.24 p2 = 2 / 3; // без округления // p2 = 0.66 eval(h) p2 = 2 / 3; // с округлением // p2 = 0.67такая вот арифметика.
eval в данном случае - модификатор обозначающий некое "особое" присвоение. Для чисел с фиксированной точкой eval(h) - присвоение с округлением. Для строк возможен evalr - "присвоение справа". Для структур - eval-corr - копирование полей, имеющих одинаковые имена (формат структур при этом может быть разным, переносятся только поля с совпадающими именами).
mayorovp
00.00.0000 00:00+1Что-то вы всё в кучу намешали: фиксированная точка, двоично-десятичный код и десятичное основание — это всё независимые вещи, которые могут использоваться как совместно, так и раздельно.
И рекуррентному соотношению Мюллера пофигу на формат хранения, оно одинаково неустойчиво на любых форматах. Имеет значение лишь логарифм единицы младшего разряда.
stt_s
00.00.0000 00:00ChatGPT мне отлично на эту тему высказался, я, говорит, для доказательства равнства 0,(9) = 1 буду использовать трюк) на предложение сделать это без трюка, перевернул с ног на голову, предположил, что 0,0(1) = 0 и тоже доказал)

vadimr
00.00.0000 00:00Ну вообще-то, если на то пошло, это равенство невозможно доказать, оно в стандартном анализе принимается как аксиома. А в нестандартном – не принимается, и это равенство считается неверным.
Это просто свойство, которым мы можем наделить множество R. Ни из чего не следующее.
tyomitch
00.00.0000 00:00+1Если это разные числа, то чему же равна их разница?
vadimr
00.00.0000 00:00-1Бесконечно малой. Которая в нестандартном анализе рассматривается как самостоятельное число.
tyomitch
00.00.0000 00:00Впервые про такое слышу :)
Это самостоятельное число записуемо в виде (конечной или бесконечной) десятичной дроби?
vadimr
00.00.0000 00:00Нет, конечно. Его вообще вычислить нельзя.
Там идея в том, что каждое вещественное число окружено облаком бесконечно мало от него отличающихся. Очень мутная тема.
tyomitch
00.00.0000 00:00+3Там каждое вещественное число окружено облаком невещественных?
И вдобавок вещественные числа там незамкнуты по сложению, что 1-0.(9) даёт невещественный результат??
vadimr
00.00.0000 00:00-1Нет, они все вещественные, только не все можно построить конструктивно.
tyomitch
00.00.0000 00:00+1В школе, и даже на матмехе, вещественное число - это, по определению, бесконечная дробь.
А там что такое вещественное число?
vadimr
00.00.0000 00:00-1Это конструктивное определение вещественного числа, оно в данном случае неприменимо.
Но можно же смотреть на вещи и аксиоматически, что вещественное число - это элемент множества R с заданными на нём определёнными операциями (т.е. поля определённого вида). И тогда оказывается, что никакие выводимые из аксиом свойства вещественных чисел не изменяются от того, примем мы существование актуальных бесконечно малых величин или нет.
0xd34df00d
00.00.0000 00:00Есть такая прикольная¹ ветвь матлога — теория моделей.
Для любой теории, не более чем счётно аксиоматизируемой в логике первого порядка (то есть, где достаточно счётного количества аксиом с кванторами, бегающими только по элементам, но не по множествам, множествам множеств и так далее), можно построить модель произвольно большой (Левенгейм-Сколем о повышении мощности) и, обратно,
произвольно малойсчётной (Левенгейм-Сколем о понижении) мощности.Дальше, у вас есть какой-то набор аксиом про вещественные числа. Почти все из них (кроме аксиомы о полноте) — высказывания первого порядка, и поэтому вы можете выкинуть аксиому о полноте, применить теорему о повышении и получить модель, в которой кроме непосредственно вещественных чисел будет произвольно много других объектов, которые вы можете назвать [на самом деле существующими, а не алиасами для последовательностей] бесконечно большими или бесконечно малыми, например.
С полнотой, кстати, тоже интересно: я когда-то давно встречал её формулировку как [счётной] схемы аксиом, что позволяет добавить её в нестандартную модель, но, если я тогда не напутал с интерпретацией этой схемы, она даёт полноту только для конструктивных чисел.
¹ Прикольная она потому, что, например, одно из следствий теоремы о понижении — существование счётной модели ZF (которая счётно аксиоматизируема логикой первого порядка), поэтому у вас в счётной модели оказывается множество, содержащее несчётное количество элементов (потому что существование несчётных множеств — теорема ZF). И если вы не привыкли разделять metalanguage и object language, то это вызывает некоторые вопросы.
0xd34df00d
00.00.0000 00:00+2У вас каша в голове, извините. Есть три с половиной вещи.
1. Конструктивные (или, вернее, вычислимые) вещественные числа — это вообще другое, это те числа, для которых есть алгоритм их вычисления. Тут не нужен никакой нестандартный анализ, обычных (не)конструктивных чисел бесконечно много, и неконструктивных — бесконечно больше, чем конструктивных (потому что конструктивных вещественных счётное число).
1а. Конструктивное построение вещественных чисел — это просто один из подходов к изложению классического анализа.
2. Конструктивный анализ — это математический анализ, построенный без аксиомы исключённого третьего, выводимый в рамках исключительно интуиционистской логики. Там дальше есть некоторые особенности, связанные с конкретной логикой — некоторые из них несовместимы с теми или иными формами аксиомой выбора, но вы люди молодые, шутливые, а я бы не стал вскрывать эту тему.
3. Нестандартный анализ — это когда мы фигачим теорему Левенгейма-Сколема для того, чтобы пополнить множество всех вещественных чисел ещё каким-то набором чисел, и в одной из метаинтерпретаций такого расширения эти дополнительные числа — как раз гипервещественные.
Естественно, всё это можно комбинировать в достаточно произвольных комбинациях.
vadimr
00.00.0000 00:00-1Как то, что вы написали, опровергает мои слова?
Разве что не надо путать конструктивные определения с вычислимыми числами. Любое вычислимое число может быть конструктивно определено (алгоритмом своего вычисления), но не наоборот.

DistortNeo
00.00.0000 00:00Бесконечно малой. Которая в нестандартном анализе рассматривается как самостоятельное число.
То есть существует такое число a, что 0,(9) + a = 1.
И особенность этого числа a такая, что оно больше нуля, но меньше любого другого числа (по определению бесконечно малой).
Ну тогда берём b = a / 2 и получаем число ещё меньше. Противоречие, да?DirectoriX
00.00.0000 00:00Отнюдь. Бесконечно малое чем-то похоже на «бесконечность наоборот», в частности при умножении/делении на конечное число вы получаете то же самое бесконечно малое (возможно, с другим знаком)
DistortNeo
00.00.0000 00:00То есть уравнение x * a = x имеет некоторое решение, и это решение не ноль?
DirectoriX
00.00.0000 00:00+1Даже в +- школьной математике у этого уравнения аж 3 решения: 0 и ещё 2 бесконечности с разными знаками.
О том, куда может завести дорога математических приключений, может поведать, например, это видео.
ksbes
00.00.0000 00:00+1Тогда уж и четыре — простая беззнаковая бесконечность под ваши рассуждения тоже подходит.
«Школьные» математические операции не определены для бесконечности. «Школьная» бесконечность — это просто обозначение расходимости и потому выражение a*∞ просто не имеет смысла.
А вот «арифметика бесконечно малых/больших» — она больше похожа на комплексные числа, где у вас вместо символа мнимой единицы символ бесконечности (или бесконечно малого). Но естественно, со своими правилами арифметики.
0xd34df00d
00.00.0000 00:00+1Нет, конечно.
В «стандартном» анализе не равная нулю тождественно последовательность x_i при умножении на любое число (кроме единицы) даст другую последовательность.
В нестанадртном анализе теорема ∀x.∀k. x ≠ 0 ⇒ k ≠ 1 ⇒ xk ≠ x выполняется так же, как и в стандартном.
vadimr
00.00.0000 00:00-1Трансфинитное число подставьте на место x.
Вам исчисление первого порядка, собственно, никто не обещал даже в стандартном анализе.
0xd34df00d
00.00.0000 00:00+2Трансфинитное число — это совсем из другой оперы. В очередной раз, замечу.
vadimr
00.00.0000 00:00-1Да какой же другой? Мы об актуальных бесконечностях говорим. Бесконечно больших или бесконечно малых. Которые в стандартном анализе заменяются потенциальными бесконечностями в предельном переходе.
Потом, какая вообще разница, из другой оперы или нет. Важно то, что можно так интерпретировать определение вещественного числа, чтобы ваша теорема не выполнялась.
0xd34df00d
00.00.0000 00:00+2Да какой же другой? Мы об актуальных бесконечностях говорим. Бесконечно больших или бесконечно малых.
Бесконечно большое из нестандартной модели R и бесконечно большое из арифметики ординалов — это вообще две принципиально разных сущности.
Которые в стандартном анализе заменяются потенциальными бесконечностями в предельном переходе.
Чего? У нас такого в стандартном анализе не было.
Важно то, что можно так интерпретировать определение вещественного числа, чтобы ваша теорема не выполнялась.
Нельзя по построению нестандартной модели.

alexeyrom
00.00.0000 00:00+1Неправда (если про нестандартный анализ). Вы получите другое число, но тоже бесконечно малое (их бесконечно много, как и бесконечно больших).
mayorovp
00.00.0000 00:00Отнюдь. Бесконечно малое чем-то похоже на «бесконечность наоборот», в частности при умножении/делении на конечное число вы получаете то же самое бесконечно малое (возможно, с другим знаком)
Э-э-э, ну уж нет. Если определять бесконечно малые так как сделали вы — вы не сможете найти производную функции как частное двух бесконечно малых, и зачем тогда это всё?
alexeyrom
00.00.0000 00:00+1И особенность этого числа a такая, что оно больше нуля, но меньше любого другого числа (по определению бесконечно малой).
Нет, бесконечно малые числа в нестандартном анализе меньше любого положительного стандартного числа. Их самих бесконечно много и b просто ещё одно из них.
(Вот только с a проблема; в знакомых мне системах нестандартного анализа 0,(9) = 1 никуда не девается и a=0. Но если возьмёте любое положительное бесконечно малое a то да, a/2 другое бесконечно малое меньше него).
DistortNeo
00.00.0000 00:00Окей, заходим с другой стороны.
Считаете ли вы записи 1/3 и 0,(3) эквивалентными?alexeyrom
00.00.0000 00:00+1В нестандартном анализе? Да. Там вообще все факты о пределах стандартных последовательностей сохраняются.
При этом в последовательностях 0,9, 0,99, ... и 0,3, 0,33, ... будут члены с бесконечно большими номерами, которые будут нестандартными числами, бесконечно близкими к 1 и к 1/3 соответственно. Но последнего среди них нет, за каждым следует ещё более близкое к пределу.

Ndochp
00.00.0000 00:00+2А причем тут последовательности?
1/3 * 3=1
0.(3)*3=0.(9)
Эквивалентность при умножении на одинаковое число сохраняется, значит запись 1 эквивалентна 0.(9) Никаких бесконечно малых между ними
alexeyrom
00.00.0000 00:00А причем тут последовательности?
При том, что по определению 0.(9) это предел последовательности 0,9, 0,99, ...? Или вы какое-то другое определение используете?
запись 1 эквивалентна 0.(9) Никаких бесконечно малых между ними
Я ровно это и написал выше:
в знакомых мне системах нестандартного анализа 0,(9) = 1 никуда не девается и a=0.
Эта ветка началась с комментария, в котором ошибочно утверждалось, что это не так https://habr.com/ru/post/720486/comments/#comment_25297768.
Ndochp
00.00.0000 00:00- бьем прямую на отрезки, ставим точку, записываем последовательность адресов отрезков. и по определению запись 0.(9) обозначает вот эту точку на числовой прямой.
- Извините, перепутал ники.
alexeyrom
00.00.0000 00:00Мне кажется такое определение куда менее удобным. Тем более:
Если прочитать буквально, 0.(9) у вас получается произвольная точка. Нужно расписать подробнее, как именно прямая разбивается (отрезки произвольные? Одинаковой длины? Уменьшающейся?), как точка на втором связана с отрезками, выбранными на первом шаге и т.д.
"записываем последовательность" странно смотрится рядом с "А причем тут последовательности?".
Поскольку наш контекст -- нестандартный анализ, придётся ещё объяснять, как его числовая прямая отличается от обычной.
stt_s
00.00.0000 00:00Самый 'затык' у него пошёл (>30 секунд раздумий в общей сложности), когда предложил округлить 0,4(9) до ближайшего целого. В первый раз округлил до единицы сославшись при этом на 0,4(9) >= 0,5. Во второй раз, после уточнения, извинился и снова округлил до единицы, сообщив при этом, что 0,4(9) > 0,5. В третий раз выдал результат:
"Извините за недопонимание в предыдущем ответе. 0,4(9) на самом деле меньше, чем 0,5.
Чтобы округлить 0,4(9) до ближайшего целого числа, нужно сначала определить, к какому числу оно ближе. Мы знаем, что 0,4(9) меньше чем 0,5, поэтому мы должны округлить до 0.
Таким образом, при округлении 0,4(9) до ближайшего целого мы получим 0."
stt_s
00.00.0000 00:00Полагаю, станданртным он стал во времена Эйлера, когда математика, как наука, оторвалась от чисто прикладных задач расчётов и банковского дела. Ну и безвестные арабы ещё постаралсь, свергнувшие с 'пьедестала' римскую систему счёта)
Ndochp
00.00.0000 00:00Оно следует из геометрической модели построения бесконечной десятичной записи.
Мы бьем всю числовую прямую на полуоткрытые иерархичные отрезки (по 10 штук) и на каждом шаге записываем номер отрезка. Для точки 1 будет запись (0)1.(0) для открытых с одной стороны или (0).(9) для открытых с другой стороны.
Так как разбиения с правым и левым открытым концом в целом равнозначны, то мы не можем сказать "всегда использовать вот такое разбиение". В итоге мы говорим "вот такие пары записей для чисел эквивалентны".
(если можно не буду в этом редакторе расписывать какие "такие")vadimr
00.00.0000 00:00Вы никогда не докажете, что ваши отрезки покрывают всю прямую (иными словами, что вообще можно выколоть одну точку), не используя то свойство, которое и собрались доказывать.
Почитайте про нестандартный анализ.
stt_s
00.00.0000 00:00-1Угу, из-за подобных утверждений горели костры инквизиции. Отдал я, значит, своего сына математике учиться, а он выучился и.. вогнал моё дело в убыток
0xd34df00d
00.00.0000 00:00Ну вообще-то, если на то пошло, это равенство невозможно доказать, оно в стандартном анализе принимается как аксиома.
Нет, оно спокойно доказывается. Пусть это разные числа, и пусть для определённости 1 > 0.(9), и пусть 1 — 0.(9) = ε (ε > 0), и далее по тексту.
А в нестандартном – не принимается, и это равенство считается неверным.
Любое высказывание про вещественные числа (или, более общо, элементы теории) верно и для нестандартных чисел (или, более общо, расширений модели). Оно там просто по построению модели более высокой мощности так получается.
vadimr
00.00.0000 00:00-1Нет, оно спокойно доказывается. Пусть это разные числа, и пусть для определённости 1 > 0.(9), и пусть 1 — 0.(9) = ε (ε > 0), и далее по тексту.
Что далее по тексту-то? Далее по тексту вы его пополам будете делить, рассчитывая получить другое число? А этого никто не обещал для нуля и бесконечно малых.
Любое высказывание про вещественные числа (или, более общо, элементы теории) верно и для нестандартных чисел (или, более общо, расширений модели). Оно там просто по построению модели более высокой мощности так получается.
"Любое вещественное число стандартно".
0xd34df00d
00.00.0000 00:00+1Что далее по тексту-то? Далее по тексту вы его пополам будете делить, рассчитывая получить другое число? А этого никто не обещал для нуля и бесконечно малых.
Для нуля — нет (но ε > 0). Для бесконечно малых — обещал.
"Любое вещественное число стандартно".
Запишите это языком теории вещественных чисел (вернее, real closed fields), тогда продолжим.
vadimr
00.00.0000 00:00-1Для нуля — нет (но ε > 0). Для бесконечно малых — обещал.
Из каких аксиом определения поля R это следует?
Запишите это языком теории вещественных чисел (вернее, real closed fields), тогда продолжим.
А вы запишите этим языком свой предельный переход.
0xd34df00d
00.00.0000 00:00+1Из каких аксиом определения поля R это следует?
Вы ожидаете, что я вам напишу полный формальный вывод?
А вы запишите этим языком свой предельный переход.
Во-первых, у меня нет никаких предельных переходов.
Во-вторых, это был такой лёгкий намёк, что записать это высказывание в теории RCF у вас не получится — можете даже не пытаться. Отсутствие неподвижных точек, кроме нуля, у операции
/ 2на вещественных числах, в свою очередь, выводится из аксиом.vadimr
00.00.0000 00:00-1Я прекрасно понимаю, что записать это в виде простого предиката невозможно. Но так же невозможно записать и тот предельный переход, о котором вы говорите (а именно, предел последовательности десятичных дробей, записываемый для краткости как 0.(9)).
Предельный переход вообще не является математической операцией в строгом, формально определённом смысле (каковой, например, является редукция в лямбда-исчислении). Это просто запись некоторого нашего интуитивного способа думать о предмете. Как только видим слово lim, то никакой синтаксически предопределённой интерпретации за ним не стоит.

zkutch
00.00.0000 00:00+1не является математической операцией
Что вы понимаете под операцией - это не функция? Возьмем множество действительных возрастающих последовательностей на расширенной прямой. Для каждой существует предел на расширенной прямой т.е. существует функция которая каждой последовательности сопоставляет ее предел. Все формально.
vadimr
00.00.0000 00:00-1Ну напишите тогда мне эту функцию. В том-то и дело, что функцию lim невозможно определить формально, аксиоматически. Это просто некоторые наши рассуждения.
ksbes
00.00.0000 00:00+1Функция — это не запись функции. Не надо путать понятия. Как говорится «sin(x)» — это не синус :)
zkutch
00.00.0000 00:00Функция уже написанна - функция это тройка: два множества и функциональный график на их произведении. Все элементы тройки уже приведены выше вполне формально. Что из трех непонятно? С помощью понятия предела я дал вам один пример корректного определения функции. Можно еще, но вы, верятно, говорите о чем-то другом, к тому-же довольно туманно
функцию lim невозможно определить формально
Что это такое "функцию lim"? Вы выдумали что-то свое или прочитали где-нибудь этот термин?
В приведенном мной примере для каждой возрастающей последовательности lim именно формально определенный и существующий, в названных условиях, элемент обобщенной прямой. В общем случае предел это элемент топологического пространства с определенным свойством. Иметь предел, свойство отображения. Все именно формально определено. Определяется существование объекта и не подразумевается алгоритма нахождения/вычисления.
p.s. я не могу отвечать раньше, чем через час.
vadimr
00.00.0000 00:00-1lim – это гипотетическая функция высшего порядка, которая имеет в качестве аргумента некоторую функцию и значение её аргумента, а на выходе выдаёт значение, к которому стремится функция в данной точке:
y ← lim (f(x), x₀)
Вы как непреложный факт постулируете, что такая функция существует, хотя на самом деле определены только отдельные тройки из двух аргументов и значения, и в каждом случае значение определяется разными рассуждениями. Знание о том, как вычислить предел, например, частного многочленов, ничем не поможет вам найти предел какой-нибудь другой функции.
Если бы предел был определён формально, мы бы могли просто синтаксическими преобразованиями определения функции получать её предел. А оно не так, тут ум нужен.
Возвращаясь к нашей теме, вы по сути говорите: "я утверждаю, что, записывая после "0," неограниченное число девяток, я бесконечно приближусь к значению 1 ..." (это верно и можно легко доказать), "... а такое бесконечное приближение как раз и означает значение предела, строго равное 1" (а вот это просто результат допущения, принятого в матанализе – о том, что бесконечно близкие точки совпадают). Так вы можете волюнтаристски назначить для функции предел, но не вывести его в строгом смысле, как результат формальных преобразований из аксиом алгебры.
Cerberuser
00.00.0000 00:00+1lim – это гипотетическая функция высшего порядка, которая имеет в качестве аргумента некоторую функцию и значение её аргумента
В данном случае не функцию и аргумент, а возрастающую последовательность (то бишь, возрастающую функцию из натуральных чисел в вещественные). Впрочем, остальных рассуждений это не отменяет.
zkutch
00.00.0000 00:00Так, стоп: получается, что для вас
функция высшего порядка
это понятие из программирования (https://ru.wikipedia.org/wiki/Функция_высшего_порядка)- правильно?
vadimr
00.00.0000 00:00-1Не обязательно из программирования. В математике это используется, например, в лямбда-исчислении.
zkutch
00.00.0000 00:00+2Ну, так, в лямбда-исчислении основным является то, что в отличии от обычного определения функции в математике там есть огромное добавочное требование "computability" - вычислимость (https://en.wikipedia.org/wiki/Computable_function).
Итак, если мы говорим об основном, общем, понятии функции в математике, то там с моим примером, получается, все в порядке. С помошью предела прекрасно определяется функция. Кстати, как раз, в мат. анализе.
Если же говорить именно о вычислимых функциях, то прежде чем продолжать обсуждение, надо разобраться с употребленным вами словом "гипотетическая". Что означает это слово? Вы можете привести источник где это вы видели так определенную функцию
"lim – это гипотетическая функция высшего порядка"
?
vadimr
00.00.0000 00:00Я говорю о значении самого символа lim, а не о пределах некоторых конкретных функций, которые, разумеется, существуют.
Это вы назвали предел функцией. Я написал, что, если бы такая функция, как lim, гипотетически существовала бы, она имела бы описанные проблемы. Но на самом деле предел - это не функция, ни вычислимая, ни невычислимая. Это просто мнемоническая запись формально не выводимого понятия, или скорее даже рассуждения.
Теперь о вычислимости. Если бы lim из матанализа была функцией, то она по определению была бы вычислима, так как на входе имеет конечную запись условия задачи. Можно было бы просто расписать таблицу, в левом столбце которой будут все возможные математические формулы ограниченной длины, а в правом - их пределы. А бесконечными рассуждениям матанализ не оперирует.
Но в действительности мы не знаем пределов некоторых формул, поэтому построить такую функцию не можем.
zkutch
00.00.0000 00:00Это вы назвали предел функцией
Вы все время не отвечаете на прямые вопросы, так, что постарайтесь ответить ГДЕ я назвал предел функцией?
Это просто мнемоническая запись формально не выводимого понятия
Опять-таки, постарайтесь точно ответить, где вы видели подобное заявление о пределе?
vadimr
00.00.0000 00:00Вы все время не отвечаете на прямые вопросы, так, что постарайтесь ответить ГДЕ я назвал предел функцией?
Вы не только не помните, с чем вы вступили в диалог, но и вам лень отмотать на 9 комментариев вверх?
Что вы понимаете под операцией - это не функция? Возьмем множество действительных возрастающих последовательностей на расширенной прямой. Для каждой существует предел на расширенной прямой т.е. существует функция которая каждой последовательности сопоставляет ее предел. Все формально.
Так вот, нет такой функции, которая сопоставляет каждой последовательности её предел. Точно в том же смысле и по тем же причинам, как нет функции, решающей проблему останова. Её невозможно построить, поскольку это изоморфные задачи (рассмотрим последовательность значений счётчика команд машины, выполняющей определённую программу, ну и т.д.)
...
Опять-таки, постарайтесь точно ответить, где вы видели подобное заявление о пределе?
Что значит – где видел? Я это заявление сделал.
zkutch
00.00.0000 00:00+1А вам хамство мешает видеть, что у меня приведено определение функции с помошью понятия предела а не определение предела как функции?
Вы спекулирете смешивая общее понятие функции с понятием вычислимой функцией и зачем-то приплетая сюда предел.
vadimr
00.00.0000 00:00А вам хамство мешает видеть, что у меня приведено определение функции с помошью понятия предела а не определение предела как функции?
Тогда зачем вы это пишете? Мы обсуждаем понятие предела само по себе.
zkutch
00.00.0000 00:00Отвечу:
Во-первых, не надо хамить. Во-вторых, нахамил, извиняйся. В третьих, последним вопросом вы признаете, что я не называл предел функцией, а вы прямо клевешете, будто-бы я это сделал. И после того, как вас ткнули носом в свою ложь, вы переводите разговор на то, что обсуждение идет фактически понятия предела.
И, наконец:
Я как раз вмешался потому, что вы делаете кошмарное заявление про предел, будто это
просто мнемоническая запись формально не выводимого понятия
Но, это лично ваше, ошибочное, восприятие. Вы основываете это на том, что "невозможно построить" функцию, прямо скажем функционал или оператор, который по данной функции и данной точке давал-бы значение предела. Тут, во-первых вы должны явно подчеркивать, что речь идет о вычислимой функции, а не функции вообще. Во-вторых, как обычно принято в математике, надо говорить не о решении вообще, а о решении в определенном классе. Довольно просто назвать такой класс функции в котором построить подобный функционал не проблема. Вероятно можно назвать такой класс, где функционал построить нельзя, но, это сперва нужно доказать. А потом это обычная ситуация в математике: где-то решение есть, где-то его нет. Манипулировать этим и обзывать одно из самых формально точно определенных понятий математики - понятие предела - какой-то "мнемонической записью", это я и называю спекуляцией ради красивого словца, хайпом.
vadimr
00.00.0000 00:00-1Мне кажется, хамить здесь пытаетесь только вы.
В третьих, последним вопросом вы признаете, что я не называл предел функцией, а вы прямо клевешете, будто-бы я это сделал
Вот это вот:
Возьмем множество действительных возрастающих последовательностей на расширенной прямой. Для каждой существует предел на расширенной прямой т.е. существует функция которая каждой последовательности сопоставляет ее предел.
кто написал?
Функция, сопоставляющая каждой последовательности её предел, не существует ни в вычислимом, ни в невычислимом классе. Точно так же как не существует множество всех множеств или функция-оракул, которая по тексту произвольного высказывания определяет его истинность. Это просто языковая игра, не имеющая формального содержания. А суть тут в том, что неверно допущение о возможности найти предел произвольной последовательности, или даже просто установить существование предела произвольной последовательности.
И я даже выше вам приводил пример последовательности, предположение о наличии либо отсутствии предела у которой приводит к противоречию.
одно из самых формально точно определенных понятий математики - понятие предела
Да ни фига оно точно не определено. Определены только различные необходимые условия по типу: если у нас есть функция f и значение y такое, что (blablabla), то y называется пределом f.
прямо скажем функционал или оператор
Если вам хочется называть это функционалом или оператором, я не возражаю. Мне такая терминология представляется менее конструктивной, поскольку порядок функции можно повышать неограниченно, и разных слов не хватит.
mayorovp
00.00.0000 00:00И я даже выше вам приводил пример последовательности, предположение о наличии либо отсутствии предела у которой приводит к противоречию.
Где? Что-то я не вижу...
vadimr
00.00.0000 00:00-2Пятый комментарий вверх от вашего.
На всякий случай, напишу ещё раз.
Пусть последовательность Θn(T) обозначает положение головки машины Тьюринга с лентой T на n-ном шаге. Если мы выведем предел этой последовательности по n, это будет означать, что мы решили проблему останова для T в положительном смысле. Если мы выведем, что предела нет, это будет означать, что мы решили проблему останова для T в отрицательном смысле. То и другое невозможно. Существуют такие значения T, для которых нельзя оценить Θ, не проделав все n шагов. А это и означает отсутствие формализма предела.
mayorovp
00.00.0000 00:00+1Это вы сейчас написали почему пределы некоторых функций невозможно вычислить. Но это не означает что самой функции предела не существует.
vadimr
00.00.0000 00:00-1Что вы вкладываете в понятие функции, для которой невозможно вычислить её область определения?
mayorovp
00.00.0000 00:00+1Именно это и вкладываю. В чём проблема функции, для которой невозможно вычислить область определения?
vadimr
00.00.0000 00:00Ну функция – это вроде бы как по определению морфизм из множества А в множество B. Нет множества – нет функции.
vadimr
00.00.0000 00:00В аксиоматической теории множеств не может быть невычислимых множеств. ZFC представима в лямбда-исчислении определённого вида.
mayorovp
00.00.0000 00:00Аксиоматическая теория множеств не знает что такое последовательность, функция, предел, машина Тьюринга и т.п., потому в ней всё и так просто.
Другие разделы математики не такие простые, в частности уже аксиомы вещественных чисел в логике первого порядка не выразимы.
zkutch
00.00.0000 00:00Назвать хама хамом это не хамство, а констатация хамства.
Далее:
Вот это вот:
Возьмем множество действительных возрастающих последовательностей на расширенной прямой. Для каждой существует предел на расширенной прямой т.е. существует функция которая каждой последовательности сопоставляет ее предел.
кто написал?
И где здесь написанно что предел это функция?
И разве непонятно, что в первом предложении специально подчеркнуто множество по отношению к которому и употреблен квантор всеобщности во втором?
Следующий момент:
вы нарочно передергиваете? Вы пишете
Функция, сопоставляющая каждой последовательности...
Разве у меня написанно "каждая"? Сами же приводите цитату в которой у меня написанно "множество действительных возрастающих последовательностей на расширенной прямой".
Сколько вам привести книг по мат. анализу и их известнейших авторов, где это элементарная теорема, что у возрастающих последовательностей на расширенной прямой существует предел? Опять же стараться это поставить на один уровень с множеством всех множеств, есть еще одна спекуляция. Разумеется, если у вас настолько распухло самомнение, что вы отметаете классический мат. анализ, то это прекрасная характеристика ценности всех ваших высказываний и хороший момент где продолжение разговора теряет смысл.
И наконец
определение есть не необходимое условие для самого себя, а эквивалентное.
0xd34df00d
00.00.0000 00:00Можно было бы просто расписать таблицу, в левом столбце которой будут все возможные математические формулы ограниченной длины, а в правом — их пределы. А бесконечными рассуждениям матанализ не оперирует.
А с машиной Тьюринга не получится так же решить проблему останова случайно?
vadimr
00.00.0000 00:00Я как раз и пишу об изоморфности этих задач. Если бы можно было так расписать пределы, то и проблему останова тоже.
0xd34df00d
00.00.0000 00:00+1И что это вообще доказывает в контексте исходной задачи? Вам это не мешает записывать утверждение lim x_n = y, и даже иногда его доказывать или опровергать.
vadimr
00.00.0000 00:00-2В контексте исходной задачи это говорит о том, что не всё так просто с lim, чтобы считать его каким-то однозначно заданным преобразованием. Собственно, это и так, вроде бы, должно быть понятно.
А то, что пределы некоторых функций существуют и однозначно определены, я не имею намерения опровергать.
tyomitch
00.00.0000 00:00Теперь о вычислимости. Если бы lim из матанализа была функцией, то она по определению была бы вычислима, так как на входе имеет конечную запись условия задачи. Можно было бы просто расписать таблицу, в левом столбце которой будут все возможные математические формулы ограниченной длины, а в правом - их пределы. А бесконечными рассуждениям матанализ не оперирует.
Предел может существовать и при этом быть недоказуем -- это следствие из https://ru.wikipedia.org/wiki/Теоремы_Гёделя_о_неполноте
lim из матанализа -- это отличный пример невычислимой функции. Результат прогона машины Тьюринга -- тоже функция и тоже невычислимая.
ksbes
00.00.0000 00:00Предел может существовать и при этом быть недоказуем — это следствие из теоремы Гёделя о неполноте
Довольно спорно.
Если у нас для пары число-последовательность может быть три варианта:
— эта пара удовлетворяет определению предела
— эта пара неудовлетворяет определенеию предела
— невозможно доказать удовлетворяет или нет
То только в первом случае мы можем говорить о том, что число является пределом последовательности.
Иногда мы можем доказать, что последовательность имеет предел, но не можем установить какой именно — но это другой вопрос.
ksbes
00.00.0000 00:00Неверно. Есть последовательности для которых нельзя определить наличие или отсутствие предела. Всё потому же Гёделю.
Cerberuser
00.00.0000 00:00Каким образом это следует из теоремы-то? Какая существует непротиворечивая формальная арифметика, в которой все формулы, кроме наличия или отсутствия предела у определённых последовательностей, являются либо выводимыми, либо опровержимыми?
vadimr
00.00.0000 00:00-1По вашей же ссылке написано:
Поскольку, вообще говоря, не существует общего метода, позволяющего для любого высказывания за конечное число шагов установить его истинность или истинность его отрицания, закон исключённого третьего не должен применяться в рамках интуиционистского и конструктивного направлений в математике как аксиома.
tyomitch
00.00.0000 00:00Ровно об этом я выше и пишу: что утверждение может быть истинным, и при этом недоказуемым.
mayorovp
00.00.0000 00:00В вашей же цитате написано:
Поскольку, вообще говоря, не существует общего метода, позволяющего для любого высказывания за конечное число шагов установить его истинность или истинность его отрицания, закон исключённого третьего не должен применяться в рамках интуиционистского и конструктивного направлений в математике как аксиома.
В рамках стандартной математики это всё ещё аксиома. Смиритесь уже с этим.
vadimr
00.00.0000 00:00-1Предел может существовать и при этом быть недоказуем
Может. Но это не тот случай.
Результат прогона машины Тьюринга – и вправду, (невычислимая) функция, так как он определён на известном множестве лент и шагов, а именно, на любой ленте и любом шаге. С lim такой номер не проходит.
0xd34df00d
00.00.0000 00:00Ну, так, в лямбда-исчислении основным является то, что в отличии от обычного определения функции в математике там есть огромное добавочное требование "computability" — вычислимость
Те или иные сорта лямбда-исчисления можно интерпретировать как логики соответствующих категорий, и никто не мешает объект и доказательство про него, записанные в λC, интерпретировать, например, в категории Set как выполняющиеся для любых функций.
Но там очень тонкий лёд, я бы не рекомендовал туда лезть.
0xd34df00d
00.00.0000 00:00+2Если бы предел был определён формально, мы бы могли просто синтаксическими преобразованиями определения функции получать её предел. А оно не так, тут ум нужен.
Нет, конечно — у вас даже равенство-то синтаксическими преобразованиями проверять невозможно, а тут пределы какие-то.
Так вы можете волюнтаристски назначить для функции предел, но не вывести его в строгом смысле, как результат формальных преобразований из аксиом алгебры.
Кто запретил?
Берёте утверждение, что ∀ε > 0. ∃n. ∀i > n. 1 — {0.(9)}_i < ε, из него делаете вывод, что они равны. Это утверждение вполне себе доказывается в теории RCF.
В теории RCF, правда, будут другие проблемы, которые я тут замёл под ковёр из «i > n», потому что в RCF не существует натуральных чисел, но это решаемая и достаточно техническая сложность.
vadimr
00.00.0000 00:00-1из него делаете вывод, что они равны
На основании чего такой вывод? Тут можно только сделать вывод, что ε можно бесконечно уменьшать.
Раз уж вы считаете только технической сложностью отображение из N в R, то возьмите трансфинитный ординал, который при сложении с самим собой даёт себя, примерно таким же образом отобразите его в расширенное R, посчитайте обратную величину, и вот вам актуальная бесконечно малая, которая при делении пополам не уменьшается.
mayorovp
00.00.0000 00:00Учитывая, что ε1 определяется через ε0+1, ε0 никак не может обладать тем свойством что вы ему приписали.
А вот вам более строгий вывод:
Для любого ординала α выполняется следующее:
α + α > α + 1 > α
Так что ординалов с желаемым вами свойством не существует.
ksbes
00.00.0000 00:00+1Имеется ввиду что само нахождение предела — это скорее доказательство теоремы, что некое число связанно с некоторой последовательностью так как это описывает определение предела.
Т.е. в общем случае нет однозначного алгоритма нахождения предела.
Но если так рассуждать — то и нахождение первообразной или любого другого интеграла — не операция.
vadimr
00.00.0000 00:00Имеется ввиду что само нахождение предела — это скорее доказательство теоремы, что некое число связянно с некоторой последовательностью так как это описывает определение предела.
Да. И это требует дополнительного допущения, что бесконечно близкие числа совпадают. Само это допущение ниоткуда не следует.
Нахождение первообразной – не формально определённая операция тоже.
alexeyrom
00.00.0000 00:00+2Ну вообще-то, если на то пошло, это равенство невозможно доказать, оно в стандартном анализе принимается как аксиома.
Возможно, конечно, и достаточно просто. Где вы видели изложение анализа, в котором оно было бы аксиомой?
А систем нестандартного анализа много, и по крайней мере в тех, которые мне лучше знакомы, 0,(9) (если его определять как lim_{n->бесконечность} (1-1/10^n)) по-прежнему равно 1 и существование бесконечно малых чисел этому никак не мешает.
fk0
00.00.0000 00:00+1В некоторых ЯВУ есть рациональные типы. Там что-то подобное можно получить (при переводе в десятичную систему).
0xd34df00d
00.00.0000 00:00+1Быть может. Проблема в том, что вы два произвольных построенных числа сравнить за любое конечное число шагов не можете.
Ndochp
00.00.0000 00:00Так верно же. В момент каста в тип с фиксировнным числом знаков после точки произойдет округление по математическим правилам и появится ожидаемое 0.5000
это вот 2.0f*2.0f <> 4.0f, но экспоненциальное представление в банковских приложениях использовать черевато.Mingun
00.00.0000 00:00+12.0f*2.0f <> 4.0f
Интересно, почему? И 2 и 4 представимы во float точно (как и все целые числа до 223, так как именно столько бит в мантиссе), почему результат этого вычисления должен оказаться неточным?
Ndochp
00.00.0000 00:00Склероз. Помнил, что вылетал в 3.9999999999999е0, но сейчас проверил на питоне, 4.0 получается.
vadimr
00.00.0000 00:00Например, потому, что про результат вещественных операций в реальных процессорах не гарантируется, что он совпадает с наиболее точным математическим представлением. И он запросто может различаться в младших битах на разных чипах.
Mingun
00.00.0000 00:00+2Это было бы понятно, если бы число не было бы точно представимо в двоичном представлении. Но и 2 и 4 — точные степени двойки, при перемножении так или иначе множатся мантиссы как обычные целые числа, перемножение целых всегда точно. Откуда конкретно в данном примере могут быть неточности?
vadimr
00.00.0000 00:00-1Никто не гарантирует, что мантиссы будут умножаться как целые числа. Скорее нет, чем да. Мало ли какие там техники приближённого умножения.
Помнится, на некоторых процессорах вещественное умножение быстрее целочисленного.
vadimr
00.00.0000 00:00Говоря предметно, когда вы будете 4 сдвигать влево, чтобы нормализовать к 2, то почему вы уверены, что в младший разряд запишется 0?
tyomitch
00.00.0000 00:00Потому что стандарт IEEE гарантирует получение ближайшей к точному результату двоичной дроби.
vadimr
00.00.0000 00:00А почему вдруг 0 ближе чем 1?
Это только ваши наивные интуитивные представления, что незаписанные разряды равны 0.
tyomitch
00.00.0000 00:00Отнюдь, это требование IEEE.
Весь смысл стандарта -- в том, что одинаковые действия над побитно одинаковыми числами приведут к одинаковым результатам на любой системе, соблюдающей этот стандарт.
vadimr
00.00.0000 00:00Вы совершенно неправильно понимаете стандарт IEEE, и на практике результаты вычислений на разных процессорах различаются.
Какое место в стандарте вы интерпретировали таким образом?
Стандарт гарантирует только отсутствие аномалий.
tyomitch
00.00.0000 00:00и на практике результаты вычислений на разных процессорах различаются
Пруф или не было
vadimr
00.00.0000 00:00Личный практический опыт, amd vs intel. У нас в фирме после этого покупку amd запретили, чтобы контрольные примеры побитово сходились.
Ну это давно было и редко, конечно, но тем не менее.
0xd34df00d
00.00.0000 00:00Достаточно собрать код на одной железке с FMA, а на другой — без, и не заметить этого, чтобы получить наблюдаемый эффект.
tyomitch
00.00.0000 00:00То, что разный код даёт разный результат - это понятно, и вопрос совсем не об этом.
tyomitch
00.00.0000 00:00+1Какое место в стандарте вы интерпретировали таким образом?
"Each of the computational operations that return a numeric result specified by this standard shall be performed as if it first produced an intermediate result correct to infinite precision and with unbounded range, and then rounded that intermediate result, if necessary, to fit in the destination’s format"
Ну это давно было и редко, конечно, но тем не менее.
Если у вас нет конкретных примеров, то и обсуждать нечего: доказывать отсутствие заварочного чайника в поясе астероидов я не собираюсь.
vadimr
00.00.0000 00:00-1Согласен, что в отношении умножения я погорячился, но, тем не менее, стандарт требует соответствия результатов только от:
add, subtract, multiply, divide, extract the square root, find the remainder, round to integer in floating-point format, convert between different floating- point formats, convert between floating-point and integer formats
К вычислению более сложных функций это требование не относится.
доказывать отсутствие заварочного чайника в поясе астероидов я не собираюсь
А вы не доказывайте, а слушайте людей, обогатившихся собственным опытом.

Format-X22
00.00.0000 00:00Может быть доля в чем-то равная одной трети, например. В юридических документах. И это надо хранить.
mayorovp
00.00.0000 00:00+3Самое интересное, в школьном учебнике математики на полном серьёзе доказывается равенство 0.4(9) = 0.5, что для банковского округления совершенно неверно
Оно, в таком виде, и для банковского округления верно. Хотя бы потому что операции округления в этой записи вообще нет.
stt_s
00.00.0000 00:00-5Речь, конечно, о 'теореме' 0,(9) = 1, весьма вредная штука, её бы вообще изъять из учебников, либо излагать вместе с понятием о банковском округлении. Просто взяли и 'скушали' ни в чём неповинное число. Используя 0,4(9) отличное от 0,5 возможно построить теоретическую модель без потерь, вызванных правилом округления 0.5 в большую сторону. Кроме того 'проистекающие' из подобного соотношения утверждения вида -0.0(1) = +0.0(1) аналогичны, в моём понимании, стягиванию земных полюсов в одну точку и полной отмене электричества.
mayorovp
00.00.0000 00:00+2Математика — это стройная система, а не набор хаков для финансовых расчётов. "Починить" финансы и уронить всё остальные расчёты — так себе затея.
Проблемы округления нормально описываются и исследуются классической математикой, только не в школе.
stt_s
00.00.0000 00:00В чём будет нарушена стройность и какие расчёты валятся-падают - совершенно непонятно. Казус этот всплывает, при попытке представить показательные дроби в виде десятичной записи с периодом, 1/3 = 0,(3), при этом нет дроби для записи 0,(9)
mayorovp
00.00.0000 00:00+1Правильно. А нет её потому что 0,(3)3 = 1/33 = 1. Вы предлагаете операцию деления сделать необратимой или как?
stt_s
00.00.0000 00:00-2Идеальная стройность и красота школьной математики рушится выражением 0,4(9) < 0,5, а 'теорема' о равенстве-эквиваленции 0,(9) и 1 является неким прикрытием и заметанием под ковёр данного факта, как собсенно и запрет на использование безусловного goto, уже в высшей школе, закрывает кучу пр'облемов и неоднозначностей на этапе компиляции, вызванных его применением
Cerberuser
00.00.0000 00:00Идеальная стройность и красота школьной математики рушится выражением 0,4(9) < 0,5
...для которого до сих пор не видно доказательства.
stt_s
00.00.0000 00:00-1О том и речь, невозможно заявить чтобы кто-нибудь не потребовал доказательства)
Cerberuser
00.00.0000 00:00Естественно. Либо доказательство, либо явное утверждение, что это неравенство принимается за аксиому (и дальше смотрим, что из этой аксиомы будет выводиться и насколько удобно с этим будет работать).
stt_s
00.00.0000 00:00Посмотреть можно, там некий аналог геометрии Лобачевского получается, выше парни писали, только про неевклидовы геометрии в школьном курсе даётся общее представление, а вот про неэйлерову алгебру ни слова
mayorovp
00.00.0000 00:00Только вот 0,4(9) = 0,5 и ничего не рушится.
а 'теорема' о равенстве-эквиваленции 0,(9) и 1 является неким прикрытием и заметанием под ковёр данного факта
какого факта?
eptr
00.00.0000 00:00Если применить альтернативное деление столбиком:
1|2 0|--- -|0.4999... 10 8 -- 20 18 -- 20 18 -- 20 18 -- 2то получатся удивительные результаты.
1 делится на 2 не нацело, запишем 0 в частное, и 1 будет в остатке.
Ставим десятичную точку в частное, дописываем справа 0 к остатку, получается 10.Далее, 10 делится на 2 нацело, и получается 5, но в данном случае деление — альтернативное, поэтому запишем в частное 4, а в остатке, соответственно, будет 2.
Дописываем к остатку 0, получается 20, которое тоже делится на 2 нацело, и получается 10, но такой цифры нет, поэтому запишем максимальную цифру, то есть, 9 в частное, и тогда 2 будет в остатке.
Дописываем 0, получается опять 20, поэтому опять записываем 9 в частное, и опять 2 будет в остатке.
Очевидно, что процесс замкнулся и стал бесконечным.
Итак, обычным делением столбиком получается 0.5.
Альтернативным делением столбиком получается 0.4(9).В школьной математике, скорее всего, такого нет, потому что я сам это придумал.
Теперь доказывать якобы неравенство
0.4(9) != 0.5стало труднее.stt_s
00.00.0000 00:00-1В старославянском языке было некотороеограничение против подобного, знак тилто над буквой, для обозначения числа, т.е. на результат деления 0,(Д) тилто можно было не ставить и дальнейшее действия не производить делимое/делитель = (стоп) без тилта
mayorovp
00.00.0000 00:00+1Причём тут вообще язык? Математика от языка не зависит.
stt_s
00.00.0000 00:00-1с,(топ), если точнее, ну цифрой 666 вряд ли кого напугать-предупредить можно, словами-цифрами эт сделать несколько 'проще' и диапазон - шире, а так - да
Cerberuser
00.00.0000 00:00+1Цифрой 666 лично меня напугать очень легко, т.к. страшно представить себе тех, кто использует систему счисления с настолько большим основанием (если, конечно, считать, что эта цифра соответствует десятичному числу с той же записью). Но все эти эмоциональные реакции в любом случае не имеют отношения к аксиоматике и выводимым из неё следствиям.
Cerberuser
00.00.0000 00:00+1А чем они-то тут помогут? Цифра 725, к примеру, меня напугала бы дословно так же. Да даже цифра 123. С цифрой 1000 чуть-чуть получше (римскую систему записи мы все помним, я надеюсь), другой вопрос - зачем это нужно, если позиционные системы в практических задачах почти всегда удобнее.
stt_s
00.00.0000 00:00-1китайские иероглифы - помогут, если не знать китайский, берём их, навешиваем тилты и вперёд, математика не для простых смертных
Cerberuser
00.00.0000 00:00Так тогда это не цифры. Символьные вычисления - это совсем другая задача, да.
stt_s
00.00.0000 00:00-1Вики в помощь: '
в некоторых языках, например, в церковнославянском, древнегреческом, иврите и др., существует система записи чисел буквами'
Cerberuser
00.00.0000 00:00+1В этом случае буквы являются цифрами, и знание/незнание языка на это не влияет. Максимум - может использоваться как мнемоника, если значения цифр согласованы с алфавитным порядком.
stt_s
00.00.0000 00:00-1'цифра 725, к примеру, меня напугала бы', а в чём особенность 725, если не привязываться к языку? В дореформенной орфографии были правила поминай/не поминай беса, проистекающие как раз из цифрабуквенной связки, ну и в китайском нет строго определённого алфавитного порядка, как в языках, на основное латыни, несколько мне известно
Cerberuser
00.00.0000 00:00а в чём особенность 725
Цитирую самого себя:
страшно представить себе тех, кто использует систему счисления с настолько большим основанием (если, конечно, считать, что эта цифра соответствует десятичному числу с той же записью).
Так что "особенность" здесь такая же, как и у 724, и у 726.
Cerberuser
00.00.0000 00:00+1Сочувствую, но при чём тут это? Числа там, конечно, большие, но цифры, насколько мне известно, вполне обычные.
stt_s
00.00.0000 00:00это ж какую голову иметь надо, чтобы представить себе систему счисления с основанием 32К.. таблицу умножения прикинь)
stt_s
00.00.0000 00:00-1твоя моя не понимай, речь вроде как о системе счисления с основанием 752 и выше..
Ndochp
00.00.0000 00:00Тут кажется идет активный троллинг между "позиционная система, сколько цифр, такое и основание" и "историческая система, если число записывается буквой, то эта буква — цифра, но к основанию системы счисления отношения не имеет".
Насколько я понимаю, на Руси была вполне себе десятичная система счисления, однако цифра 900 тоже была
"Значение 900 в древности выражалось «малым юсом» (ѧ), несколько похожим на соответствующую греческую букву «сампи» (Ϡ); позже в этом значении стала применяться буква «ц». " (С) вика
DistortNeo
00.00.0000 00:00+3Казус этот связан исключительно с тем, что вы пытаетесь вкладывать смысл в форму записи числа.

Deosis
00.00.0000 00:00+3Если вы утверждаете, что 0,(9) != 1, то которое равенство неверно?
1 = 9 * 1/9 = 9 * 0.(1) = 0.(9)
tyomitch
00.00.0000 00:00+2Используя 0,4(9) отличное от 0,5 возможно построить теоретическую модель без потерь, вызванных правилом округления 0.5 в большую сторону.
О каких таких "потерях" идёт речь вообще?
stt_s
00.00.0000 00:00-1Потерях в стиле иерихонских труб, когда 1000 лет так считали, а потом вдруг..

Hamletghost
00.00.0000 00:00+3А вот в golang, например, кейс с множественной инициализацией и очисткой нативно решается использование defer
Кейс с выходом из внешнего цикла решается break с меткой в том же golang
Кейс с ретраем нарочно не показывает более логичный вариант с циклом for(;;) + continue который вообще мало будет отличаться от исходного варианта но в качестве бонуса получим визуальные границы ретрая в виде {}
Вобщем написано много слов но по сути вывод то вот такой имхо: действительно нельзя обойтись без goto в C, но это диктуется низкой выразительностью языка и отсутствием его развития (кто мешает сделать те же break/continue с метками непонятно). И именно поэтому популярность C для написания несистемных программ такая низкая, особенно после появления golang.

ftc
00.00.0000 00:00+1Справедливости ради, не golang единым - примерно в любом языке, где есть деструкторы или обработка исключений (в лице блока finally),
gotoв кейсе "не забыть очистить ресурсы", особо-то и не нужен.
А вот break/continue с метками был бы полезен, много где.DistortNeo
00.00.0000 00:00Механизм деструкторов и finally довольно плохо ложится на сценарий, когда требуется условная очистка ресурсов (не отматывать операции при успешном выполнении цепочки операций).
ftc
00.00.0000 00:00Если не нужно очищать ресурсы, то по идее надо сохранять объект, который ими управляет, в области видимости (ну, вернуть его там или сохранить куда).
А про finally согласен.
В этом плане становится сложно, например, в C#, ибо даже вылетевший из области видимости объект, вообще говоря не удаляется. И что делать, кроме как явно очищать всякие файлы и сокеты (или возиться с IDisposable, но по сути, тоже, явно) - непонятно.DistortNeo
00.00.0000 00:00В С++ — да, следуя идеологии RAII, можно обернуть каждое владение ресурсом в объект, а потом, в случае успешности всей цепочки, используя move semantics, передавать эти объекты наружу в составе другого объекта. Единственный недостаток здесь — хранение контекста, который нужен для освобождения ресурса.
В C# — да, используйте IDisposable. Я нахожу это достаточно удобным.
nuclight
00.00.0000 00:00А где именно эта популярность низкая? По TIOBE вниз идёт как раз Go.
Hamletghost
00.00.0000 00:00Не хотел отвечать тк холиварно, но ваше утверждение про tiobe неверно: в марте 23 golang впервые вошел в 10-ку на tiobe. Ну и сам индекс tiobe такой себе показатель. Предлагаю в качестве альтернативы, например, посмотреть стату github там есть графики по годам и видно развитие популярности наглядно. Открытые вакансии это тоже подтверждают: если C (не c++), то либо что-то системное, либо embed разработка - полистайте hh
fk0
00.00.0000 00:00+20Автор забыл сказать, что goto привносит свой букет проблем: в первую очередь из-за возможности "перепрыгнуть" инициализацию переменных. О чём современные компиляторы могут предупредить, а могут и не предупредить. И почему в C++, в отличии от C, не всякие goto возможны. И это один из мотивов, почему в Linux боятся local scope переменных и по-старинке объявляют все переменные в начале функции (второй мотив, что это позволяет избегать висящих указателей на локальные переменные). Но это в свою очередь тоже ничего хорошего не приносит, т.к. теперь константную переменную присвоить невозможно и ключевое слово const избегается, что ведёт к другим ошибкам.
Приведённые автором примеры "как обойтись без goto" хоть и выглядят страшно, но легко читаемы сверху-вниз, обладают меньшей циклотомической сложностью. В отличии от спагетти-кода с goto;

Пример спагетти-кода. Вообще критика goto берёт свои корни из фортрана, пример приведён выше. Когда программа записывалась "в столбик" как в ассемблере:оператор-строка, что пошло от перфокарт (где было только 80 колонок и ни одной больше). Толковых операторов вертвления в языке не было, зато были развитые варианты goto (оператор IF). Такие программы было очень трудно воспринимать, очень легко наделать ошибок. Это было очевидной проблемой в ответ на которую возникло так называемое структурное программирование, основная идея которого в отказе от макаронных монстров из goto и в использовании специализированных управляющих конструкций или операторов (if, while, for, switch...) Такой код обладает меньшей сложностью и менее подвержен ошибкам. По ссылке приведён прекрасный обратный пример, как макаронный goto-монстр может быть превращён в читаемый код: https://craftofcoding.wordpress.com/2020/02/12/the-world-of-unstructured-programming-i-e-spaghetti-code/
И следует отметить в Linux не просто "широко используется goto", а реализован определённый паттерн программирования, фактически ручная реализация отсутствующего в языке C оператора defer, подробности по ссылке: https://gustedt.gitlabpages.inria.fr/defer/ В языке C++ для аналогичных целей Александреску предлагалась концепция "Declarative Flow Control", в частности шаблон/функция SCOPE_EXIT. Что в современных условиях может заменяться std::unique_ptr с определённым программистом deleter'ом и лямбда-функцией:
auto on_exit = [&](void *) { // Do deferred job. }; std::unique_ptr<void, decltype(on_exit)> catch_exit {this, on_exit};
Другим полезным использованием goto является выход из вложенных циклов. Его конечно можно реализовать в рамках структурного программирования с использованием дополнительной переменной, но часто объективно, код с goto в данном случае (а не вообще) -- лучше.Резюмируя: в целом -- goto опасный и плохой инструмент в очумелых ручках. Но иногда он нужен и полезен. Иногда. Точно так же, как и ассемблерные вставки. Иногда. В целом кода с goto следует избегать, особенно неопытным программистам, и стремиться использовать элементы структурного программирования: специализированные операторы и разбивку кода на отдельные функции если необходимо.
К несчастью в языке C отсутствует понятие лямбды, отсутствуют локальные для процедуры функции (как в Паскале), что затрудняет разбивку кода (т.к. функции часто нужен ещё и контекст, который трудно передать через переменные). Ввиду этого пишутся огромные по размеру функции и возникает goto (обработка ошибок, прерывание вложенных циклов). В Clang конечно есть code blocks, но их нет в GCC, а вложенные процедуры в GCC (которых нет в Clang) требуют трамплинов и в современных условиях мало применимы...
vadimr
00.00.0000 00:00+1Что характерно, арифметический IF выкинули из Фортрана 35 лет назад, а борьба с ним живёт до сих пор.
Первый Фортран 1954 года, на самом деле, не очень-то отличался от макроассемблера, там ещё и не такие прибабахи были. Была у машины IBM 704 инструкция арифметического ветвления, её и продублировали в языке. Там ещё какие-то операторы специально для управления магнитным барабаном были, что ли. Но всё это потом почистили потихоньку.
nuclight
00.00.0000 00:00Вот эти рассказы про Фортран - означают, что вопроса опять не поняли, и опять борются с ветряными мельницами образца 1960 года, которые давно как неактуальны. О чем, собственно, и рассказывает статья.

Neyury
00.00.0000 00:00+4множество точек выхода
А почему это вдруг минусом является? "Ранний возврат" вполне распространенный паттерн
fk0
00.00.0000 00:00+5В языках с явным потоком управления, куда относится C, становится важно иметь единственную точку выхода из функции. В C++ можно просто добавить к локальным переменным функции объект и деструктор всё сделает на выходе, в любом случае. В C нужно явно прописывать действия на выходе. Чему ранний выход может помешать, в том смысле, что провоцирует на ошибку (про него просто можно забыть).

PsyHaSTe
00.00.0000 00:00+1Собственно это и хотел написать. Статья про то как полезен GOTO в си, при том что в любом современном языке с деструкторами такой проблемы н стоит в принципе, а других преимуществ у него собственно и нет. Разводить софистику что свитч это гоуту, вызов функции это гоуту и вообще всё гоуту — считаю ересью.

FD4A
00.00.0000 00:00+3Тот 'goto', против которого возражал Дейкстра, это сегодня - 'nonlocal goto' (longjump, setjump и.т.п.). В современном виде эта штука вернулась к нам в виде короутин.

Arenoros
00.00.0000 00:00+1Я извиняюсь, а чем пример оптимизация хвостовых вызовов хорош?
в чём там приемущество в сравнение с обычным циклом?
годболт показывает абсолютно одинаковый выхлоп и читаемость кмк с цыклом лучше чем с goto


vadimr
00.00.0000 00:00Ничем не хорош, о чём и пишет автор статьи. Суеверие.
Точно такой же циклический код вы получите и при простом незамысловатом рекурсивном вызове с одним параметром, так как наивное вычисление факториала – это стилизованная рекурсивная функция, а компилятор умный.
Arenoros
00.00.0000 00:00ну он просто пишет что тут есть какая то оптимизация завязанная на goto для старых компиляторов, вот у меня и возник вопрос, а при чём тут goto когда это отлично решается и другими конструкциями и где goto как раз таки не стоит использовать.
vadimr
00.00.0000 00:00Ну он чисто формально поменял return recursive_f() на goto start, рассматривая это как самую примитивную, шаблонную технику TCO. Смысла в этом никакого нет, но мысль его, очевидно, следовала таким путём.
vadimr
00.00.0000 00:00+1Направление мыслей автора в целом верное, но на некоторых примерах его заносит. Например, переход между ветвями case я бы не назвал хорошей практикой.
CTheo
00.00.0000 00:00+7Задумка автора - убедить, что стоит пользоваться goto.
Реальный эффект - лишний раз уверил, что ни goto не надо использовать, ни duff devices, а раз в Си без них никак, то и его не стоит.
Лучше уж переходить на C++/Zig/Rust, где есть RAII/defer/scopeguard. И на микроконтроллеры можно использовать, там сейчас все хорошо с zero cost.
nuclight
00.00.0000 00:00+1Десятилетия идут, а религиозных фанатиков в отрасли меньше не становится - как им вдолбили "goto плохо", так они и продолжают игнорировать рациональные аргументы...
CTheo
00.00.0000 00:00Понимаете, рациональные аргументы в статье выглядят примерно так - почему вы говорите, что плохо ходить на ходулях? Вот на руках же ходить еще неудобнее! А я хочу, знаете, просто сесть хотя бы в телегу и ехать, после десятилетий то, а не разгадывать паззлы.
SpiderEkb
00.00.0000 00:00В настоящее время большую часть кода пишу на языке, где нет goto. Просто нет.
Зато есть сабрутины (subroutines) как в древнем бейсике - именованный блок кода внутри области видимости процедуры (т.е. использующий локальные переменные процедуры и не образующий уровень стека при вызове).
Поначалу казалось "фу, как бейсике...", потом проникся - во-первых, еще один инструмент для структурирования кода, во вторых, удобный инструмент когда один и тот же блок кода нужно или выполнить несколько раз, или обращаться к нему из разных точек процедуры.
Также на них легко реализуется "единая точка выхода":
... if <некоторое условие>; exsr srExit; endif; ... if <другое условие>; exsr srExit; endif; ... exsr srExit; return; // просто обозначате конец процедцры // объявление точки выхода begsr srExit; // делаем что нам надо на выходе return; // а это уже "настоящий" выход endsr;Хотя там есть и механизм on-exit:
dcl-proc myproc; dcl-s isAbnormalReturn ind; ... p = %alloc(100); price = total_cost / num_orders; filename = crtTempFile(); return; on-exit isAbnormalReturn; dealloc(n) p; if filename <> blanks; dltTempFile (filename); endif; if isAbnormalReturn; reportProblem (); endif; end-proc;В блок on-exit попадаем всегда или при выполнении оператора return (сколько бы их ни было) или при возникновении исключения (например, при делении на ноль).
При нормальном выходе индикатор isAbnormalReturn будет off, при вылете по ошибке (исключении) - on;
Также можно переопределять возвращаемое значение внутри on-exit
dcl-proc Division ; dcl-pi *n packed(7:3) ; Dividend packed(5) const ; Divisor packed(5) const ; end-pi ; dcl-s Result packed(7:3) ; dcl-s ErrorHappened ind ; Result = Dividend / Divisor ; return Result ; on-exit ErrorHappened ; if (ErrorHappened) ; return -1 ; endif ; end-proc ;В общем и целом, все эти механизмы вполне позволяют обходиться без goto и при этом писать читаемый и логически структурируемый код.
aamonster
00.00.0000 00:00Почему как в бейсике, а не как в паскале? В классическом бейсике никаких областей видимости и даже локальных переменных не было, а процедура внутри процедуры – это паскаль, довольно удобная штука, но за неё приходится платить: помимо указателя на стекфрейм текущей процедуры – нужен указатель на стекфрейм родительской, чтобы дотянуться до переменных (просто использовать фиксированное смещение от текущего стекфрейма нельзя, т.к. может быть несколько процедур, вызывающих друг друга, или вообще рекурсия).
SpiderEkb
00.00.0000 00:00Потому что речь идет о RPG (это такой специализированный язык для коммерческих расчетов от IBM - 80% кода на их middleware платформе IBM i пишется на нем). Ровесник кобола, но до сих пор развивается.
Так вот ранние версии там имели fixed нотацию

и там не было поддержки процедур, только сабрутины. В этом плане он был ближе всего именно к бейсику. И в той версии goto было
Потом от этого безобразия ушли, сейчас это нормальный процедурный язык.
goto из новой (т.н. "free") нотации убрали, добавили процедуры, но сабрутины остались просто перейдя внутрь процедур.
gem_ini
00.00.0000 00:00-2Слышал, что go to это не очень, старался не использовать. И когда у одного сокурсника увидел лабу, где почти все конструкции for были построены на go to - If - моя жизнь резко поделилась на до и после.. Сейчас, спустя 20 лет я использую все, что доступно: goto, continue, return, break. Так, как хочу. И счастлив. Если ты понимаешь, что и как работает, какая разница какими методами и инструментами достигается цель?

MiraclePtr
00.00.0000 00:00+5Если ты понимаешь, что и как работает, какая разница какими методами и инструментами достигается цель?
Современная разработка ПО обычно командная. Поэтому нужно писать так, чтобы код легко понимал и мог поддерживать не только его автор, но и любой другой разработчик.
nuclight
00.00.0000 00:00Всё хорошо, но пример со switch странный - там ведь на то и break, чтобы можно было писать один общий блок кода под несколько case сразу. И в этом случае ни goto, ни общая функция не нужны.
Mingun
00.00.0000 00:00Там не общий кусок кода под всеми вариантами. Там каждый вариант начинается со своего куска кода (инициализация некоей (одной и то же) переменной определённым значением), а потом идёт общий кусок для всех веток. Если вы там просто
breakпропустите, то во всех ветках переменная будет инициализирована одним и тем же значением — последним встретившимся.
Myclass
00.00.0000 00:00Всё хорошо, но пример со switch странный - там ведь на то и break, чтобы можно было писать один общий блок кода под несколько case сразу.
до сих пор не понимаю зачем вообще нужен синтаксически break в каждом case, ведь как только заканчивается блок и начинается cледующий case, то ведь и без break понятно, что выход из switch происходит...если он конечно внутри используется для преждевременного выхода, то тогда ок, согласен.
edo1h
00.00.0000 00:00+1switch (a) { case 1: do_something(); case 2: do_more(); }при
a==1будут вызыван обе функции.
иногда это действительно удобно, но в целом я понимаю создателей golang, которые посчитали это bad practice, сделав явныйfallthrough.Myclass
00.00.0000 00:00при
a==1будут вызыван обе функции.в том-то и дело, но свободно-стоящего case-оператора не может существовать в природе, т.е. не может после do_something(); компилятор если честно "не увидеть" case 2:. И то, что это в c-языках так и будет выполнено мне понятно, но считаю - ненужным.
edo1h
00.00.0000 00:00мне кажется, вы просто упускаете контекст появления языка.
во-первых, это было очень давно, когда разработка ПО только зарождалась; во-вторых изначально язык создавался максимально близким к ассемблеру, в том числе с точки зрения простоты компилятора.если смотреть с такой точки зрения, то многие решения, принятые при создании языка, становятся понятнее.
не его вина, что он стал использоваться буквально везде.
Myclass
00.00.0000 00:00Согласен с вами полностью и да, я понимаю и использую это уже лет 30, но просто говорю, что нелогично был сделать так. Хотя, если подумать, что оплата за код построчно была, то и дополнительные операторы в строчке - доп. прибавка к пенсии ???? гарантирована.
BigBeaver
00.00.0000 00:00При наличии общего кода это крайне удобно. Особенно, когда заглушки пишешь — кинул в default какой-то алерт вида «код в разработке» и всё.

akurilov
00.00.0000 00:00При быстрой отладке часто бесит, когда return происходит где-то в середине функции и начинаешь думать: "а что это сейчас было? ". Имхо, без return и goto посередине можно обойтись, делая функции покороче. Не более нескольких строк. Вынуждает более гранулярно именовать, поэтому многие и ленятся, лепят return посередине или даже goto
vadimr
00.00.0000 00:00Это зависит от того, что делает ваша программа. Если там какое-нибудь сложное преобразование данных вроде математического расчёта, то его разве что в функциональном стиле можно гранулировать, а это не относится к сильным сторонам языка Си.

jin_x
00.00.0000 00:00Мысли разумные. Нет плохих инструментов (языков, фреймворков), есть неуместные/неоптимальные в данной конкретной ситуации.
Что касается обработки ошибок с очисткой, с этим отлично справляется scope_exit (класс, которого несложно реализовать и самому). И читаемость прекрасная. Правда, для этого нужен C++.
С Си, конечно, сложнее. Вспомнилась функция pthread_cleanup_push, но тут появляются лишние сущности в виде функций.
DungeonLords
00.00.0000 00:00Равзе можно говорить о goto и не привести ссылку на труд Запретный плод GOTO сладок (версия для микроконтроллеров)!
@avn ещё в 2011 году всё предвидел!

nmrulin
00.00.0000 00:00Ну почти все привёденные альтернативы без goto лучше. "Антипаттерн" со вложенными if как раз можно оспорить, что во многих случаях вложенные if это самое то. Вот в приведённом примере вложенные if лучше. В goto переставил кусок кода и всё сломалось, а в if будет на уровне компилятора выдана ошибка. Флаги - ещё лучше - код предельно понятный. Вложенные функции тоже свой плюс имеют, тут трудно приляпнуть ошибку.
И так, где goto допустимо, его оставили в виде return/exit... и т.д. break и т.д. и других специфических операторов.
nmrulin
00.00.0000 00:00-1Тем более в Паскале и ему подобных например вместо громоздкого
if (flag_1) {flag_2 = init_stuff(bar);}было бы:
if flag_1 then flag_2 := init_stuff(bar);DistortNeo
00.00.0000 00:00+2Ну так и в C скобки не обязательны:
if (flag_1) flag_2 = init_stuff(bar);nmrulin
00.00.0000 00:00Видимо с каким-то C подобным языком перепутал , где нельзя без скобок.
DirectoriX
00.00.0000 00:00+2Из относительно популярных — например, в Rust скобки вокруг блоков обязательны (зато не обязательны для проверяемых условий):
if flag1 { flag_2 = init_stuff(bar); }
Сколько было совершено ошибок из-за подобного (см. ниже) сочетания необязательных фигурных скобок, невнимательности и кривого форматирования — отдельный вопрос…if (flag_1) flag_2 = init_stuff(bar); do_something(args);

StjarnornasFred
00.00.0000 00:00+1Если бы goto было абсолютным злом, его бы не было в синтаксисе языков программирования - это необязательный элемент. Соответственно, раз оно есть, значит, в ряде случаев его использование удобно и оправдано.

AnthonyMikh
00.00.0000 00:00-1Надеялся почитать аргументы за goto, а получил очередное перечисление недостатков C :/

perfect_genius
00.00.0000 00:00+1Почему в Си внутри switch нельзя прыгать на его произвольную метку? Типа goto case 2
Кто знает, или есть какие-то предположения?ksbes
00.00.0000 00:00Можно. Но не на case'ы, а на метки внутри блоков (если не боишься отдельного котла в аду для таких)
А так свитч-кейз это по сути и есть "множественный условный гоу-ту". Мы ж не на "пимп май райд" чтобы засовывать гоу-то внутрь гоу-то, чтобы ты мог делать безусловный преход, когда ты делаешь условный переход?perfect_genius
00.00.0000 00:00Т.е. можно, но нельзя, о чём я и написал.
Мне пришлось делать именно такую дикость:
case 2:
_case2:
_do_something;
_break;case 3:
_do_something;
_if(true) goto case2;
_do_something;ksbes
00.00.0000 00:00Э-э-э, зачем?
Это делается так:case 3: _do_something; _if(false) _do_something; _else brake; case 2: _do_something; _break;Т.е. просето break в конце case-выражения не пишете и "проваливаетесь" дальше
А если у вас более сложная логика, то за такую её реализацию — пять лет расcтрелов без права переписки :)
perfect_genius
00.00.0000 00:00Да, более сложная логика. Самым очевидным вариантом было выделение в функцию, но это функция нужна была бы только внутри этого switch.
DistortNeo
Я даже не догадывался, что язык вообще предоставляет возможность так писать.
me21
Ну switch - это фактически goto на один из case. Код примера, конечно, эзотерически выглядит.
А вот ещё классика: https://en.m.wikipedia.org/wiki/Duff's_device
fk0
В языке C, на самом деле, switch-case -- это тот же goto. Поэтому можно писать очень странные вещи, вроде такой:
Deosis
На ревью за такой код руки сломать могут.
Странно, что не рассмотрели вариант с 2 свичами: в первом выполняется уникальная работа, во втором - общие случаи.