

Всем привет! Сегодня рассмотрим задачу диагностирования респираторных заболеваний, то есть заболеваний дыхательной системы, но решать её будем не ушами, а алгоритмами. И решать её будем два раза, сначала методами классического машинного обучения, а затем методами глубокого обучения, то есть нейронной сетью.
Для медицинских опытов возьмем датасет “Respiratory Sound Database”, он доступен на Kaggle. В состав датасета входят 920 аудиофайлов с записями дыхания пациентов, как здоровых, так и страдающих различными респираторными заболеваниями. Ещё есть сводный файл с информацией о пациентах: рост, вес, возраст, пол и так далее, и отдельный файл с диагнозами. Авторы предлагают для него решать разные задачи. Помимо распознавания заболеваний по звуку, можно еще аннотировать записи дыхания, то есть детектировать момент времени когда происходит вдох, когда – выдох и есть ли в этом дыхательном цикле, например, хрипы. Но мы будем решать именно задачу распознавания заболевания.
Последнее что нужно учесть – соответствие записей пациентам. Аудиозаписей у нас 920, но пациентов только 126 – одному пациенту соответствует несколько записей, причём количество записей разное для разных пациентов.
Но мы, для упрощения задачи, будем считать записи самостоятельными и будем классифицировать каждую отдельно и независимо от остальных. Группировать записи по пациентам и оценивать их совместно, чтобы принять единое решение, мы не будем. Это увеличивает количество примеров в датасете, но, в теории, может ухудшить результат – возможно, какие-то заболевание по одной записи не диагностировать. Но сейчас, ради увеличения размера датасета, мы пренебрежём риском потерять в точности. Вообще, малое количество данных это известная проблема медицинских датасетов.
EDA
Начнём с общего анализа данных, это позволит лучше понять датасет. Но для начала их прочитаем. Тут есть одна хитрость – единого файла с данными о пациентах у нас нет, информация о диагнозах и о демографии пациентов разложены по разным файлам. Поэтому прочитаем их отдельно и объединим. Загрузив данные, посмотрим, что у нас за колонки.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 126 entries, 0 to 125
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PatientId 126 non-null int64
1 Diagnosis 126 non-null object
2 Age 24 non-null float64
3 Gender 24 non-null object
4 AdultBMI 12 non-null float64
5 ChildWeight 10 non-null float64
6 ChildHeight 10 non-null float64Как-то всё безрадостно. Во-первых, хотя мы старательно загрузили все данные, в полной мере у нас есть только информация о диагнозах. Возраст мы знаем меньше чем для четверти пациентов, равно как и пол. Индекс массы тела (колонка AdultBMI) встречается в два раза реже, чем возраст. Отбросить строки с пропусками мы не можем, их и так очень мало. Придётся принять волевое решение и отбросить столбцы с пустыми значениями. Ориентироваться придётся только по звуку.
Здесь нужно сделать небольшое отступление. Как гласит первое правило работы с медицинскими данными, “не гугли диагнозы и их симптомы!”. Иначе можно поймать себя на том, что мы занимаемся не решением самой задачи, а поиском этих симптомов у себя. Поэтому диагнозы будем называть так, как они названы в датасете, без перевода.
Раз кроме диагноза у нас и нет ничего, посмотрим, как распределяется для них количество пациентов.
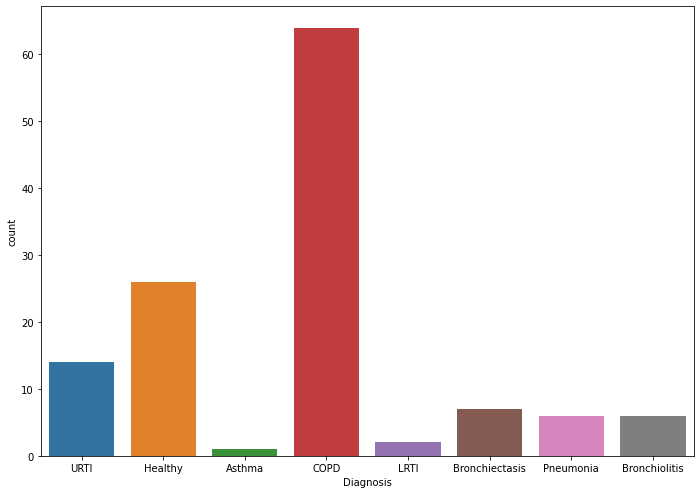
Из графика мы видим, что классы сильно несбалансированы, нужно будет это учесть при оценке точности модели. Два диагноза -- Asthma и LRTI встречаются крайне редко. Посмотрим, насколько они распространены.
Начнем с Asthma:
>> full_data[full_data['Diagnosis'] == 'Asthma'].count()
PatientId 1
Diagnosis 1
dtype: int64Мы видим, что этим заболеванием страдает только один человек в датасете. Теперь LRTI:
>> full_data[full_data['Diagnosis'] == 'LRTI'].count()
PatientId 2
Diagnosis 2
dtype: int64Здесь тоже не лучше, пациентов всего двое. То есть даже если мы научим нашу модель предсказывать эти заболевания, то не ясно, как её тестировать. Для Asthma вообще один пример, поэтому в тестовую выборку он в любом случае не попадет, а для LRTI примеров два, видимо, один для обучения, другой для теста, что тоже не очень поможет. Поэтому примем волевое решение — эти два заболевания наша модель прогнозировать не будет, а этих пациентов удалим из выборки.
Теперь у нас 6 классов, из них 5 соответствуют болезням, а один — здоровым пациентам.
Имена файлов с записями
Сами записи представлены обычными звуковыми файлами, но в их именах закодирована ещё информация. Помимо идентификатора пациента, в имени файла указано где именно был расположен микрофон на теле пациента при записи, и какое именно оборудование было использовано.
Здесь мы сталкиваемся с вопросом — какие из этих данных включать в датасет? С одной стороны мы можем включить все, позволив модели адаптироваться к разному расположению микрофона и особенностям оборудования. С другой, что если в тех случаях, когда у врача есть подозрение на некоторый диагноз, он будет в первую очередь располагать датчик так, чтобы подтвердить или опровергнуть своё предположение? Другими словами, может ли само расположение датчика быть подсказкой, какой диагноз мы ожидаем? Для используемого оборудования вопрос аналогичный. Предположим, у нас есть отделение, специализирующееся на астме, и у них стоит конкретный прибор. Тогда среди пациентов, обследованных этим прибором, количество пациентов с астмой будет больше, чем с любым другим заболеванием, и сам факт использования этого прибора может указывать на то, что мы ожидаем именно астму, а не что‑то другое. С другой стороны, если у одного и того же прибора (или одного и того же положения микрофона) могут быть разные диагнозы, то это знание не даст ничего. Поэтому не будем учитывать ни положение датчика, ни прибор при прогнозе.
Длительность записей
Записи у нас разной длины, но будет лучше, если все они будут одинаковые. Оценим, какой длины у нас записи и как эта длительность распределяется по количеству записей. Посмотрим на график.

Подавляющее большинство записей имеют длину 20 секунд. Хотя встречаются файлы другой длительности, по сравнению с двадцатисекундными их очень мало.
Итак, мы получили общее представление о нашем датасете, посмотрели на распределение числа пациентов по диагнозам, убрали очень редкие диагнозы, договорились, что из сведений о самих записях будем использовать, а что нет, и решили, до какой длины нормализовать все записи. Пора переходить к предобработке данных.
Подготовка данных
Сопроводительные файлы к записям
Вместе с каждой записью дыхания имеется файл с описанием. Для каждого цикла вдох-выдох в них указаны временные метки времени и признак наличия в этом цикле хрипов (crackles) и сипения (wheezes). Эти признаки могут оказаться полезными для постановки диагноза, поэтому их лучше включить в датасет. Посмотрим на один такой файл:
0.364 3.25 0 1
3.25 6.636 1 0
6.636 11.179 0 1
11.179 14.25 0 1
14.25 16.993 0 1
16.993 19.979 1 0Первые две колонки это момент вдоха и выдоха, а третья и четвертая – признаки наличия хрипов и сипения соответственно.
Здесь опять есть сложность: если модель научится учитывать эти звуки при предсказании, то это значит, что для оценки ранее неизвестной записи нужно чтобы для неё также было выявлено наличие этих звуков, другими словами – чтобы кто-то ее прослушал и разметил. Возможно, для этого можно привлечь специалиста (хотя непонятно, зачем тогда модель, ведь тогда специалист может и диагноз поставить) или использовать другую модель, которая их обнаружит. Но сейчас для простоты будем считать что эта разметка есть всегда.
Кроме того, нам не очень важно наличие этих звуков применительно к конкретным дыхательным циклам, мы будем анализировать аудиофайл целиком, так что в качестве признака будем использовать просто факт их наличие в любом месте записи.
Напишем простую функцию, которая читает файл и извлекает нужные нам признаки.
def parse_info_file(file_name: str):
frame = pd.read_csv(file_name, delim_whitespace=True, header=None, names=['begin', 'end', 'crackles', 'wheezes'])
has_sounds = frame[['crackles', 'wheezes']].max()
return {
'has_crackles': has_sounds['crackles'],
'has_wheezes': has_sounds['wheezes']
}Теперь мы можем для произвольного сопроводительного файла узнать, есть ли в дыхании хрипы и сипение.
Разделение на тестовую и учебную выборки
Как обычно, мы хотим, чтобы модель могла оценивать и те записи, которые она не видела в процессе обучения. Поэтому мы заранее отложим некоторое количество аудиозаписей, не будем использовать их для обучения и потом будем оценивать точность на них.
Для этого получим список всех файлов с записями и поставим каждому файлу в соответствие диагноз пациента согласно его номеру, который мы можем получить из имени аудиофайла. Сформируем из этих данных pandas.DataFrame и разделим его на выборки с помощью train_test_split из sklearn. Главное при разделении на выборки – не забыть выполнить стратификацию в соответствии с диагнозом.
В итоге, для обучающей выборки мы получим что-то вроде такого:
FileName |
PatientId |
Diagnosis |
164_1b1_Ll_sc_Meditron.wav |
164 |
URTI |
206_1b1_Pl_sc_Meditron.wav |
206 |
Bronchiolitis |
122_2b1_Ar_mc_LittC2SE.wav |
122 |
Pneumonia |
135_2b3_Al_mc_LittC2SE.wav |
135 |
Pneumonia |
149_1b1_Lr_sc_Meditron.wav |
149 |
Bronchiolitis |
179_1b1_Tc_sc_Meditron.wav |
179 |
Healthy |
208_1b1_Ll_sc_Meditron.wav |
208 |
Healthy |
Данные подготовили, пора переходить к обучению моделей.
Пара слов об оценке моделей
Прежде чем строить и обучать модели, нужно договориться о том, как их оценивать. Подходящих метрик много, но у нашего датасета есть одна особенность – он сильно несбалансирован. Это значит, что если модель будет ставить всем пациентам один и тот же диагноз, самый частый в датасете, то уже так она может достигнуть довольно высоких значений метрик, при этом вообще не решая задачу.
Чтобы бороться с этим эффектом, пакет sklearn предлагает метрику Balanced Accuracy. Она учитывает дисбаланс классов и сильнее “награждает” модель за правильное присвоение более редких классов, заставляя её не концентрироваться на распознавании наиболее распространённых.
Теперь договоримся о бейзлайне. Вспомним, что бейзлайн – это некоторое базовое значение точности, которое показывает (или показала бы) некоторая простая модель, с которой мы будем сравнивать нашу. Если наша модель оказалась лучше базовой, значит мы молодцы и решили задачу. Как мы помним, всего у нас 6 классов. Это означает, что если наша модель всегда будет назначать только один из них, она никогда не сможет показать сбалансированную точность больше 1/6 = 0.16. Это значение и будем использовать в качестве бейзлайна.
Решаем задачу методами классического машинного обучения
Для начала решим задачу классическим машинным обучением. Но для этого нужно завершить подготовку данных, чтобы привести их в вид, подходящий для машинного обучения. Звук можно представить как некоторый сигнал во времени. Это означает, что мы можем рассматривать задачу классификации звука как задачу классификации временных рядов. Используя python можно получить содержимое аудиофайла как звуковой сигнал разными способами, мы будем использовать librosa.
Построим график звукового сигнала для аудиофайла с записью дыхания здорового человека.

На графике мы можем увидеть чёткую периодичность сигнала. Даже воспользовавшись самым простым методом анализа – методом пристального взгляда – мы можем увидеть примерные моменты когда человек вдыхает, а когда – выдыхает. Для сравнения посмотрим на аналогичный график, но уже для человека с пневмонией.

Первое, что мы видим – никакой период не просматривается, сигнал выглядит почти произвольным. Моменты вдоха и выхода разглядеть невозможно. Кроме того, амплитуды сигнала заметно отличаются. В случае здорового человека, в пике сигнал достигает отметки 0.5, но у человека с пневмонией лишь в немногие моменты времени сигнал достигает 0.1.
Итак, мы сравнили графики изменения частот для здорового человека и для человека с пневмонией и смогли отличить их друг от друга. Если смогли мы, сможет и модель.
Но сначала нужно преобразовать аудиофайлы в вид, пригодный для обработки моделью. Можно просто извлечь частоты и представить их как массив чисел, но, во-первых, массивы получатся разного размера и объединить их в батчи для обучения будет сложно, а во-вторых, это будет ну очень много признаков, обучить модель на таком их количестве будет невозможно.
Для извлечения признаков из временных рядов воспользуемся пакетом tsfel. Этот пакет умеет извлекать множество разных признаков, но в этот раз ограничимся только статистическими. Процесс извлечения идёт быстрее, чем если бы мы использовали tsfresh, но всё равно заметное время. По его завершении мы получим 38 признаков.
Тридцать восемь признаков это гораздо меньше чем было, но всё равно, несколько больше чем нам хотелось бы. С помощью tsfel.correlated_features уберем признаки с сильной корреляцией (любопытно, что документация врёт – она утверждает, что этот метод возвращает pandas DataFrame, но на самом деле он возвращает список), а затем используем VarianceThreshold из sklearn, чтобы убрать те признаки, которые мало меняются. Также важно не забыть про признаки наличия хрипов и сипения на записи, которые мы обсудили чуть раньше. Теперь у нас 19 признаков, будем использовать их. Посмотрим, что получилось. Признаков много, поэтому все 19 смотреть не будем, хватит нескольких.
0_Histogram_0 |
0_Histogram_3 |
0_Kurtosis |
0_Mean |
0_Min |
0_Skewness |
has_crackles |
has_wheezes |
0 |
675 |
3,5832 |
-0,0002 |
-0,3012 |
1,0016 |
1 |
1 |
0 |
120 |
0,4107 |
-0,0001 |
-0,2207 |
0,0488 |
0 |
1 |
40 |
11753 |
2,9278 |
0,0000 |
-0,9186 |
-0,0220 |
0 |
1 |
0 |
5968 |
2,0586 |
0,0000 |
-0,5094 |
-0,1452 |
1 |
1 |
0 |
0 |
2,4692 |
0,0001 |
-0,1295 |
0,0442 |
1 |
0 |
215 |
9433 |
10,9515 |
-0,0002 |
-0,8624 |
0,6617 |
1 |
1 |
0 |
3712 |
1,2890 |
-0,0000 |
-0,4279 |
-0,1715 |
1 |
1 |
Итак, данные подготовили, на результат подготовки посмотрели. Самое время переходить к обучению моделей.
Модели
Из классического машинного обучения воспользуемся двумя моделями, стоящими, скажем так, на разных концах спектра всех моделей – KNN и градиентным бустингом над решающими деревьями. Трудно представить две более разные модели, поэтому и интересно их сравнить.
KNN
Начнём с KNN, метода K-ближайших соседей. Даже у такой простой модели есть несколько параметров, настройка которых может существенно повлиять на результат. Поэтому воспользуемся поиском по сетке. Перебрав все комбинации параметров, он выберет один, с лучшей оценкой.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
knn_grid_search = GridSearchCV(KNeighborsClassifier(), {
'n_neighbors': [3, 5, 7, 9],
'weights': ['uniform', 'distance'],
'algorithm': ['ball_tree', 'kd_tree', 'brute']
}, refit=True, scoring='balanced_accuracy')
knn_grid_search.fit(X_ml_train_data, Y_ml_train_data);
Теперь посмотрим на параметры лучшей модели:
{'algorithm': 'ball_tree', 'n_neighbors': 3, 'weights': 'distance'}Как видно, хватило трёх соседей, но при этом “вес” соседа определяется расстоянием от него до оцениваемого объекта. Посчитав точность получим 0.28. Это неплохое значение, бейзлайн у нас 0.16.
Теперь перейдём к более сложной модели, к градиентному бустингу.
Градиентный бустинг
Реализаций бустинга много, мы возьмем CatBoost – признаки наличия хрипов на записи можно рассматривать как категориальные, а CatBoost славится своей поддержкой таких признаков.
У бустинга параметров ещё больше, причём некоторые из них непрерывные. Здесь тоже будем подбирать параметры, но воспользуемся не поиском по сетке, а случайным поиском, задав для непрерывных признаков распределения, а не конечные списки вариантов.
import catboost as cb
from scipy.stats import randint, uniform
classifier = cb.CatBoostClassifier(loss_function='MultiClassOneVsAll',
class_weights=class_weights,
cat_features=ml_cat_features,
verbose=False,
task_type='GPU',
devices='0:1')
catboost_grid_search = RandomizedSearchCV(classifier, {
'iterations': [300, 500, 700, 1000],
'max_depth': randint(3, 10),
'learning_rate': uniform(loc=0.01, scale=0.04),
'l2_leaf_reg': randint(2, 30)
}, refit=True, scoring='balanced_accuracy', n_jobs=-1, verbose=3, n_iter=50)
catboost_grid_search.fit(X_ml_train_data, Y_ml_train_data);Мы ожидаем, что при таком наборе возможных параметров модели обучаться будут долго, поэтому задействуем GPU. Также указываем, какие признаки хотим считать категориальными. Важно указать веса классов, чтобы моделям было проще адаптировать к несбалансированному датасету. Рассчитать веса классов можно методом compute_class_weight из sklearn.
По окончании процесса смотрим, какие параметры по мнению случайного поиска были лучшими.
{'iterations': 300,
'l2_leaf_reg': 4,
'learning_rate': 0.031147424929735615,
'max_depth': 3}По умолчанию CatBoost выполняет 1000 итераций, но здесь хватило и 300. Рассчитав точность, получим 0.48. Это существенный прирост по сравнению c KNN, где было 0.28. Посмотрим на confusion matrix для этой модели чтобы понять, на каких классах она ошибается.
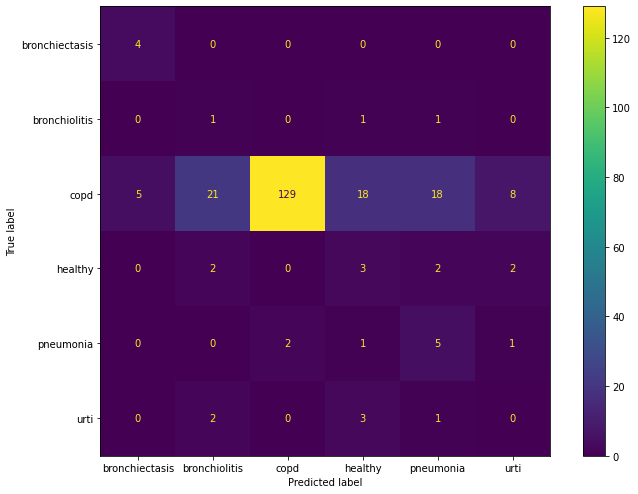
Из матрицы мы видим, что модель чаще путает болезни между собой, чем здоровых людей с больными.
Итак, использование градиентного бустинга позволило существенно улучшить результат по сравнению с KNN и получить точность втрое лучше, чем бейзлайн. Что же покажет глубокое обучение?
Решаем с помощью глубокого обучения
Есть разные подходы к решению связанных со звуком задач глубоким обучением. Мы можем использовать те же признаки, что сгенерировал tsfel для машинного обучения, мы можем построить эмбеддинги для звукового сигнала и использовать для классификации уже их, или мы можем сформировать для сигнала спектрограммы, тем самым преобразовав задачу классификации звука в задачу классификации изображений. Мы воспользуемся третьим способом.
Посмотрим на спектрограмму здорового человека.

Мы видим, что также, как и в случае с графиком изменения частоты, просматривается период сигнала. Теперь обратимся к спектрограмме сигнала для человека с пневмонией.

Здесь точно также изображение заметно отличается от случая здорового человека. Периодичность в некотором виде просматривается, но само изображение менее насыщенное.
Как и в случае с графиками сигналов, по спектрограммам мы смогли отличить здорового человека от нездорового, поэтому можем ожидать, что справится и глубокое обучение.
Простым скриптом сгенерируем для каждого аудиофайла его спектрограмму. Здесь нужно учесть, что нам нужно будет объединить несколько спектрограмм в батч, то есть изображения должны быть одного размера. При этом стоит использовать единый масштаб изображений, то есть чтобы одно и то же количество пикселей соответствовало одному и тому же “количеству сигнала”. Поэтому придется аудиозаписи усечь, чтобы все были одной длительности. Как мы помним, подавляющее большинство записей имеет длительность 20 секунд. Поэтому используем эту длительность, и все записи длиннее усечём, а все, что короче – дополним тишиной.
Модель
Теперь пора переходить к модели. Спектрограмма это картинка, поэтому логично использовать те же методы, что и при классификации изображений, ну и что, что наша картинка это на самом деле звук. За основу возьмем ResNet-18, предобученную на ImageNet. Да, для диагностики заболеваний по спектрограмме звука будем использовать сеть, которую обучали распознавать бытовые предметы.
Наша сеть выглядит так.
import torch.nn as nn
import torchvision.models as models
class CoughNet(nn.Module):
def __init__(self):
super().__init__()
self.parent = models.resnet18(weights='IMAGENET1K_V1')
self.parent.fc = nn.Linear(in_features=512, out_features=6, bias=True)
def forward(self, inputs):
return self.parent(inputs)Единственное изменение, которое нужно внести, это заменить голову сети. Изкоробочная голова предназначена для ImageNet и предполагает классификацию на 1000 классов, но нам столько не нужно, у нас классов всего 6, да и другие они. В такой конфигурации ResNet отвечает за извлечения признаков из изображения, а наша классифицирующая голова – за принятие решения о том болен ли пациент и если да, то чем.
В результате у нас получается следующая архитектура сети:

Теперь пора переходить к обучению модели. Обычно при работе с изображениями стараются увеличить размер датасета с помощью аугментации данных, то есть автоматического создания дополнительных примеров на основе существующих – можно случайным образом повернуть, обрезать, отразить или как-то еще поменять картинку. Но у нас не просто картинки, это спектрограммы, и если их, скажем отобразить по горизонтали, то получится уже другой сигнал. Нам такого не надо, так что придется обойтись без аугментаций.
Мы создадим обычный датасет типа ImageFolder из PyTorch, а из трансформаций используем только изменение размера и преобразование картинки в тензор. Обучать будем на батчах по 32 картинки.
Для оптимизации весов сети используем SGD с momentum равным 0.9, а в качестве функции потерь – CrossEntropyLoss, для которой также укажем веса классов. Обычно, когда некоторую модель адаптируют к решению другой задачи, не той для которой она была изначально обучена, запрещают обучение части или всех её слоёв, чтобы сохранить их веса. Но в нашем случае новая задача слишком отличается от исходной, поэтому дообучать будем всю сеть целиком. При обучении будем использовать GPU, иначе результата можно и не дождаться.
После того как обучение закончится, считаем сбалансированную точность на тестовых данных и получаем значение 0.59. Предыдущим рекордсменом был CatBoost, показавший 0.48, но глубокое обучение смогло превзойти его, улучшив результат на 0.11. Посмотрим на confusion matrix и для этой модели.

Из это матрицы мы видим, что глубокое обучение также, как и классические подходы, чаще путает болезни между собой, чем здоровых с больными.
Подводим итоги
Итак, мы решали задачу классификации звука, пытаясь диагностировать респираторные заболевания по записи дыхания пациента. Мы использовали разные модели и получили вот такой результат.
Модель |
Сбалансированная точность |
Бейзлайн |
0.16 |
KNN |
0.28 |
CatBoost |
0.48 |
ResNet |
0.59 |
Все рассмотренные модели превзошли бейзлайн. Мы видим, что с точки зрения сбалансированной точности победили методы, основанные на нейронных сетях. При этом машинное обучение использовало статистические признаки о звуке как временном ряде, признаки наличия на записи хрипов и сипения, что уже должно было частично подсказать диагноз. А глубокое обучение опиралось только на спектрограмму аудиофайла, и всё равно смогло превзойти классические подходы.
Можно ли улучшить результат моделей? Представляется, что да. Для глубокого обучения можно расширить набор признаков, и помимо спектрограммы использовать что-то еще, те же признаки наличия хрипов, а также использовать другой тип спектрограммы или даже несколько спектрограмм сразу, наконец, можно вообще поменять структуру сети, увеличив её размер или что-то подобное. Для классического машинного обучения можно использовать ансамбль, объединив несколько моделей, или объединить машинное обучение с глубоким, использовав нейронную сеть для генерации эмбеддингов и последующей классификации уже их. Можно и вовсе пойти третьим путём, используя два классификатора. Первый будет отличать здоровых пациентов от больных, а второй уже определять конкретную болезнь.
Данная статья была подготовлена выпускником курса "Machine Learning. Professional" на основе его выпускного проекта. Узнать подробнее о курсе и зарегистрироваться на бесплатный урок вы можете по ссылке ниже.

Akr0n
А человеческий врач способен по звуку определить заболевание или нет?
gsaw
Та же нейросеть, если дать послушать тысячу пациентов, то тоже наверное обучится различать.
А почему дополняли спекутограмы тишиной? Не правильнее было бы размножить значимый участок до нужной длинны? Не получится так, что спектограмы с тишиной будут признаком каких то определенных заболеваний?