
Исторически сложившиеся тест-сьюты тестируют слишком много и слишком мало одновременно
Поскольку программные системы обычно от релиза к релизу становятся все более функциональными, их тест-сьюты тоже растут. Это приводит к замедлению времени выполнения тестов. В этом случае ручным тестировщикам приходится прикладывать больше усилий, что напрямую ведет к увеличению затрат. А разработчикам тем временем приходится дольше ждать получения результатов автоматизированного тестирования. Для множества автоматизированных тест-сьютов время выполнения увеличивается с нескольких минут до нескольких дней или даже недель, особенно если речь идет об аппаратном обеспечении. Это мучительно медленно и косвенно приводит к увеличению затрат — ведь починить то, что сломалось две недели назад, гораздо сложнее, чем то, что сломалось всего час назад, ведь за это время много всего происходит.
Как ни странно, такие дорогие тест-сьюты зачастую даже не особенно хорошо помогают находить баги. С одной стороны, какие-то части ПО они вообще не тестируют. С другой стороны, они часто избыточны в том смысле, что другие части ПО тестируются слишком многими тестами. Баги в этих областях приводят к тому, что сотни или тысячи тестов оказываются неудачными. Таким образом, эти тест-сьюты не являются ни эффективными (потому что не проверяют некоторые области ПО), ни экономически целесообразными — потому что содержат избыточные тесты.
Конечно, это наблюдение не ново. Большинство команд, с которыми мы работаем, уже давно отказались от выполнения всего тест-сьюта при каждом изменении или даже при каждом новом релизе ПО. Вместо этого они либо выполняют весь тест-сьют только раз в пару недель — что приводит к позднему обнаружению ошибок и более дорогому их исправлению; либо выполняют только часть всех тестов — это приводит к пропуску многих багов, которые можно было найти с помощью других тестов.
В этой статье представлены лучшие решения, которые используют данные из тестируемой системы и сами тесты для оптимизации усилий по тестированию. Это позволяет командам находить больше багов, поскольку за меньшее время тестируются области с высокой плотностью ошибок, что достигается за счет сокращения количества тестов, которые обнаружат баги с низкой вероятностью.
Анализ данных о процессе разработки помогает оптимизировать тестирование
Если тест-сьют неэффективен и экономически нецелесообразен, очевидны негативные последствия для команд разработки и тестирования: несмотря на то, что на тестирование уходит много ресурсов, в продакшн просачивается слишком много багов.
Однако, поскольку в крупных компаниях полной информацией никто не обладает, обычно существуют различные — часто противоречивые — мнения о том, как решить эту проблему (или чья это вина). Мнения трудно подтвердить или опровергнуть на основе частичной информации. Если сосредотачиваться на том, что подкрепляет мнение, а не на общей картине, то можно увидеть команды, которые долгое время трудятся без существенного прогресса.
Например, мы иногда сталкивались с тем, что тестировщики возлагали вину на разработчиков за то, что внедрение новых фичей приводит к частым поломкам уже существующих. В этих случаях тестировщики направляли больше усилий на регрессионное тестирование. Одновременно разработчики обвиняли тестировщиков в том, что они слишком медленно находят баги в новых фичах. Однако, поскольку тестировщики уделяли больше внимания регрессионным тестам, ошибки в новых фичах стали обнаруживаться еще позже. К сожалению, поскольку разработчики поздно узнавали о багах в новых фичах, их запоздалые фиксы часто появлялись уже после завершения регрессионного тестирования. Если такой фикс вызывал ошибку в другом месте, у тестировщиков не было шансов обнаружить ее с помощью регрессионных тестов.
Как ни странно, такая динамика поддерживает точки зрения обеих команд, повышая их уверенность в правильности своей точки зрения, и в то же время усугубляет проблему.
Командам стоит перестать спорить об общих категориях — например, о том, сколько регрессионного тестирования необходимо в принципе — и обратиться к данным, чтобы понять, какие тесты необходимы для конкретного изменения прямо сейчас. Различные репозитории, такие как системы контроля версий, баг-трекеры и системы непрерывной интеграции, содержат массу данных о программном обеспечении, которые помогают оптимизировать деятельность по тестированию, основываясь именно на данных, а не на мнениях.
Чтобы ответить на конкретные вопросы о процессе тестирования, мы можем проанализировать все репозитории, которые собирают данные во время разработки программного обеспечения.
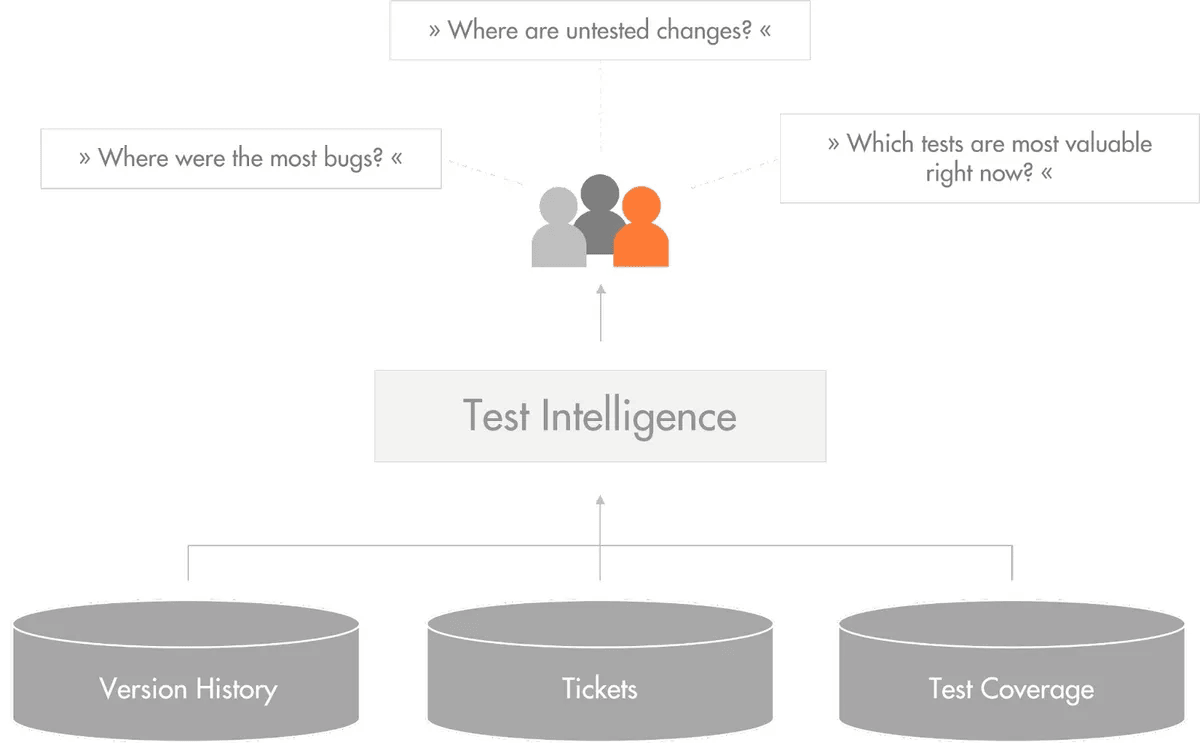
Где в прошлом было больше всего багов? Какие выводы из этого можно сделать?
История версий и баг-трекер содержат информацию о том, где в прошлом были исправлены баги. Эту информацию можно извлечь и использовать для расчета плотности дефектов в различных компонентах.

В одной системе это выявило компонент, плотность исправлений на строку кода которого была на порядок выше, чем средняя плотность исправлений в системе. Это показано на верхней синей карте трека. Каждый прямоугольник представляет файл, его площадь соответствует размеру файла в LoC. Чем глубже оттенок синего, тем чаще этот файл был частью коммита по исправлению ошибок.
В центре карты есть скопление файлов, большинство из которых гораздо более насыщенного синего цвета, чем остальные.
Нижняя карта отображает покрытие автоматизированных тестов. Белый цвет означает отсутствие покрытия, а оттенки зеленого показывают увеличение покрытия (чем более темный цвет, тем больше покрытие). Бросается в глаза то, что компонент в центре, который содержит большое количество исторических багов, почти не имеет покрытия автоматизированных тестов.
Обсуждение с командами выявило систематический недостаток в процессе тестирования этого компонента: в то время как разработчики написали юнит-тесты для всех остальных компонентов, для этого компонента не хватало тестового фреймворка, чтобы легко писать юнит-тесты. Разработчики написали тикет по улучшению тестового фреймворка. До его внедрения они систематически пропускали написание юнит-тестов для этого компонента. Поскольку команда не знала о влиянии ошибок, тикет так и оставался нетронутым в бэклоге.
Однако, как только вышеупомянутый анализ выявил, какое влияние оказывали баги, тикет был быстро реализован, а недостающие юнит-тесты написаны. После этого количество новых дефектов в этом компоненте не превышало количество дефектов в других компонентах.
Где находятся непроверенные изменения (пробелы в тестировании)?
Пробелы в тестировании — это участки нового или измененного кода, которые не были проверены. Команды обычно стараются тестировать новый и измененный код особенно тщательно, поскольку интуитивно и из эмпирических исследований мы знаем, что эти участки кода содержат больше багов по сравнению с участками кода, которые не менялись.
Анализ пробелов в тестировании объединяет два источника данных для выявления пробелов в тестировании: систему контроля версий и информацию о покрытии кода.
Во-первых, мы вычисляем все изменения между двумя версиями ПО (например, между последним релизом и следующим запланированным релизом) из системы контроля версий, поскольку интуитивно и из эмпирических исследований мы знаем, что эти области наиболее сильно подвержены ошибкам.

На этой карте изображена информационная бизнес-система объемом около 1,5 MLoC. Тридцать разработчиков работали в течение полугода над подготовкой следующего релиза. Каждый белый прямоугольник изображает компонент, а каждый прямоугольник с черной линией — функцию кода. Площадь компонентов и функций соответствует их размеру в LoC. Код в серых прямоугольниках не изменился с момента выхода последнего релиза. Красные прямоугольники — это новый код, а оранжевые — измененный код. Карта показывает, какие области изменились сравнительно мало (например, левая половина), а какие изменились сильно (например, компоненты в правой части).
Во-вторых, мы собираем все данные о тестовом покрытии. Это полностью автоматизируемый процесс сбора данных, как для автоматизированного, так и для ручного тестирования. Мы используем профилирование покрытия кода для сбора информации о тестовом покрытии для всех проводимых мероприятий по тестированию. Хотя для разных языков программирования, а иногда даже для разных компиляторов, могут потребоваться разные профилировщики, в целом они доступны для всех известных языков программирования.

Эта карта показывает тестовое покрытие одной и той же системы. Она объединяет покрытие автоматизированного тестирования (в данном случае юнит- и интеграционные тесты) и ручного тестирования (группа из пяти тестировщиков в течение месяца работала над выполнением ручных регрессионных тестов на уровне системы). Серые прямоугольники — это функции, которые не были выполнены во время тестирования, зеленые прямоугольники — выполненные функции.
Наконец, мы объединяем эту информацию, чтобы найти изменения, которые не были протестированы ни на одном этапе тестирования. Таким образом мы выявим пробелы в тестировании.

В этой карте мы не придаем большого значения коду, который не изменился. Поэтому он изображается серым цветом — независимо от того, был ли он выполнен во время тестирования. Новый и измененный код отображается цветом: если он был выполнен во время тестирования, то зеленым. Если нет, то для нового кода он изображается красным, а для модифицированного — оранжевым.
В данном примере — который был сделан за день до запланированной даты релиза, — мы видим, что несколько компонентов, состоящих из десятков тысяч строк кода, вообще не были выполнены во время тестирования.
Анализ пробелов в тестировании позволяет командам принимать взвешенные решения о том, хотят ли они отправить эти пробелы в тестировании (то есть новый или модифицированный непроверенный код) в производство. В каких-то ситуациях это может не быть проблемой — например, если нетестированная функция еще не используется, но часто лучше провести дополнительное тестирование критической функциональности.
В приведенном выше примере команда решила не делать релиз, поскольку непроверенная функциональность была критически важной. Релиз отложили на три недели, а большинство пробелов в тестировании закрыли тысячами запусков тестов по новым тест-кейсам, что позволило отловить и исправить критические баги.
Какие тесты наиболее важны в данный момент?
Если анализировать изменения кода и тестовое покрытие непрерывно, можно автоматически вычислить, какой код был изменен с момента последнего выполнения тест-сьюта. Это позволяет специально выбрать тесты, которые выполняют эти участки кода. Запуск подвергшихся воздействию тестов выявляет новые баги гораздо быстрее, чем повторный запуск всех тестов — поскольку тесты, не выполняющие никаких изменений, не могут найти новые ошибки, появившиеся в результате этих изменений.
Такой анализ влияния тестов уменьшает время обратной связи для разработчиков. В эмпирических исследованиях мы измерили, что он находит 80% ошибок (которые выявляет выполнение всего тест-сьюта) за 1% времени (которое требуется для выполнения всего тест-сьюта), или 90% ошибок за 2% времени. Подробнее читайте в этой статье о тестировании на основе изменений.

Этот сценарий применим, например, для выполнения тестов во время непрерывной интеграции.
Какие тесты являются наиболее ценными?
Некоторые тесты представляют собой дорогостоящий ресурс. Например, у некоторых наших клиентов есть тест-сьюты, которые они выполняют на дорогостоящей среде программно-аппаратного моделирования. Каждый тест включает десятки тысяч отдельных тестов, его выполнение занимает недели и объединяет программные компоненты из разных команд. Однако они критически важны, поскольку без проведения этих тестов ПО нельзя выпустить.
Настоящей проблемой для таких больших и дорогостоящих тестов становятся «массовые дефекты»: единичные дефекты, которые находятся в таком центральном месте, что приводят к отказу сотен или даже тысяч отдельных тест-кейсов. Если тестируемая версия системы содержит массовый дефект, то все тестирование будет испорчено, поскольку среди тысяч неудачных тестов трудно найти дальнейшие дефекты. Поэтому QA-команде лучше убедиться, что тестируемая система не содержит массовых дефектов, прежде чем начинать большой и дорогостоящий цикл тестирования.
Для предотвращения массовых дефектов команда использует приемочные тест-сьюты (иногда называемые smoke тестами), которые версия ПО должна пройти, прежде чем тестировщики смогут приступить к большому дорогостоящему тестированию. Хорошо собранный приемочный тест-сьют выполняет небольшое подмножество всех тестов, которые с высокой долей вероятности могут обнаружить дефект, приводящий к отказу многих тестов.
Мы можем выбрать оптимальный приемочный тест-сьют (оптимальным мы называем тот, который охватывает наибольшее количество кода за наименьшее время) из существующего набора всех тестов, основываясь на информации о покрытии кода в конкретных тест-кейсах. Для этого мы обнаружили, что хорошо работают так называемые «жадные» алгоритмы оптимизации: они начинают с пустого набора. Затем они добавляют тест, который покрывает наибольшее количество строк кода за секунду выполнения теста. Затем продолжают добавлять тест-кейсы, которые за каждую секунду выполнения теста охватывают наибольшее количество строк, которые еще не были охвачены ранее выбранными тестами. Этот процесс отбора повторяется до тех пор, пока не будет исчерпан бюджет времени на набор приемочных тестов. В ходе исследования мы обнаружили, что наборы приемочных тестов, которые мы составляем таким образом, находят 80% ошибок (которые может обнаружить весь тест-сьют) за 6% времени (которое требуется для выполнения всего тест-сьюта).

В одном из проектов мы сравнили этот подход к созданию набора приемочных тестов с набором, собранным вручную экспертами по тестированию. Для исторических данных выполнения тестов за предыдущие два года оптимизированный набор приемочных тестов обнаружил в два раза больше багов, чем набор, собранный экспертами вручную.
Это не так хорошо, как анализ влияния тестов (который требует только 1% времени для поиска 80% ошибок), но может быть применен, когда доступно меньше информации — в этом случае не нужно знать все изменения кода с момента последнего измеренного выполнения теста.
Как начать использовать анализ данных о тестировании в собственном проекте?
Анализ данных о тестировании может помочь получить ответы на всевозможные вопросы на основе данных. Поэтому может возникнуть соблазн поэкспериментировать с ними, чтобы посмотреть, что они могут рассказать о системе.
Однако эффективнее начать с конкретной проблемы в тестируемой системе. Это повышает вероятность успешного управления изменениями, поскольку убедить коллег и менеджеров решить конкретную проблему легче, чем играть с новыми инструментами.
Судя по нашему опыту, эти проблемы являются хорошей отправной точкой для размышлений о данных о тестировании:
Не слишком ли много дефектов просачивается в продакшн? Часто первопричиной являются пробелы в тестировании (новые или измененные непроверенные участки кода). Анализ пробелов в тестировании помогает найти и устранить их до релиза.
Не занимает ли выполнение всего тест-сьюта слишком много времени? Анализ влияния тестов может выявить 1% тест-кейсов, которые находят 80% новых багов, и это значительно укорачивает цикл обратной связи.
Результаты анализа данных о тестировании легко использовать для получения ответов и на другие вопросы. Поэтому команды редко используют только один анализ, а возможность решить существенную проблему оправдывает усилия по внедрению.
Приглашаем всех желающих на открытое занятие, на котором обсудим особенности организации процесса тестирования в различных командах. На встрече рассмотрим, как выстроен процесс тестирования в командах, работающих по скраму, канбану и масштабируемых фреймворках, таких как LESS или SAFe. Целью занятия будет разбор отличий и особенностей процесса тестирования в зависимости от применямой процессной методологии внутри команды. Записаться можно по ссылке.