

Будучи активным пользователем хранилища данных (DWH) на разных ролях, я всегда находил определенные ограничения (и разочарования!) в связи с задержкой данных между нашим DWH и данными, которые находятся в онлайновых транзакционных (OLTP) базах данных. В зависимости от того, где я работал, задержка составляла от нескольких часов до суток (дней), причем более крупные компании, как правило, работали медленнее.
В каких юзкейсах такая задержка репликации мешает работе?
Учитывая, что DWH - это платформа, существует множество юзкейсов, которые могут быть улучшены или усилены благодаря снижению задержки данных. Ниже я приведу несколько примеров:
Компании с высокой операционной нагрузкой
В компаниях с высокой операционной нагрузкой, как правило, требования и бизнес-процессы постоянно меняются. В результате инженерно-техническая команда обычно не успевает за ними - поэтому такие решения, как Zapier, Typeform, Retool, Tinybird и другие no-code средства стали частью стандартного набора инструментов для таких предприятий.
Такие инструменты могут накладываться одно поверх другого и ссылаться на данные в DWH, эффективность которых определяется задержкой репликации. При этом совсем не обязательно, чтобы все таблицы работали молниеносно. Это было бы неплохо... но все же в большинстве компаний обычно есть несколько критически важных таблиц, где подобная скорость действительно необходима.
Например, компания по доставке еды может настроить приложение Retool в качестве пользовательского приложения Zendesk, чтобы оно могло извлекать последние заказы покупателя и интеракции с ним.
В дополнение к предыдущим примерам, компаниям, работающим в этих отраслях, было бы полезно сократить задержку передачи данных в следующих таблицах (так называемых "критических таблицах"):
Отрасль |
Критическая таблица(ы) |
Доставка продуктов |
заказы |
Недвижимость |
имущество, документы |
Райдшеринг |
поездки |
Поддержка |
тикеты, электронные письма |
Примеры использования Lifecycle и платного маркетинга
В рамках Lifecycle маркетинга принято приобретать такие инструменты автоматизации маркетинга, как Iterable, Braze и Intercom. Каждый из этих инструментов имеет свою собственную версию того, как должны выглядеть модель пользователя и события, например, маркетологи могут создавать шаблоны электронных писем, такие как: Hi {{first_name}}!
Примеры дополнительных атрибутов пользователя для отправки:
Платный маркетинг: Если клиент запрашивает услугу поездки [райдшеринг], мы хотим отправить как можно больше его характеристик в такие сервисы, как Google и Facebook, чтобы они могли оптимизировать свой алгоритм и найти наибольшее количество совпадений.
Кампании по привлечению клиентов: Когда клиент регистрируется на нашем сайте, мы хотели бы использовать капельную кампанию, которая эффективно приветствует и привлекает пользователя. Хотелось бы при этом учитывать данные динамических полей, таких как взаимодействие с продуктом (сделали ли они что-то большее, чем просто зарегистрировались? Они уже просмотрели страницу? Запросили ли они поездку?) и другие атрибуты клиента.
Так каким же образом мы отправляем эти данные сегодня?
Как правило, команды используют различные пайплайны для создания пользовательских схем по отправке данных в различные пункты назначения. При подобной конфигурации существуют определенные недостатки:
Изменения блокируются инженерией.
Пользовательские поля почти никогда не находятся в одном сервисе. В результате нам придется вызывать другие службы (теперь нам понадобится обработка ошибок и ретраи [повторные попытки]). Бэкфилинг также может генерировать слишком большой трафик и DDOS внутренних сервисов, не приспособленных для обработки нагрузки.
Требуется обслуживание и постоянная поддержка. Если поле добавлено неправильно и не ссылается на индексированное, это может привести к замедлению работы всего пайплайна.
Данные обычно не находятся в DWH. В результате трудно проводить сегментацию и создавать отчеты.
Это можно было бы решить путем создания материализованных представлений, особенно если использовать для этого dbt (более выразительный фреймворк). Однако такие решения недостаточно зрелы, чтобы справиться с большинством маркетинговых юзкейсов.
Почему dbt или материализованных представлений недостаточно?
При создании материализованного представления нам необходимо указать, как часто они обновляются, задав расписание (пример: задачи Snowflake). Чтобы при этом визуализировать задержку, составим следующее уравнение:
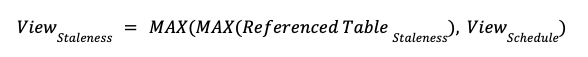
Например: мы можем заставить материализованное представление запускаться каждые 5 минут, но это не будет иметь значения, если соответствующая (ссылочная) таблица обновляется каждые 6 часов. Результирующее представление все равно отстает на 6 часов.
Именно поэтому мы создали Artie Transfer. Artie Transfer способен облегчить первую часть уравнения: MAX(Referenced Table Staleness) [Устаревание ссылочной таблицы] устраняя задержку необработанных OLTP-таблиц. Таким образом, для более быстрого просмотра мы можем просто увеличить частоту генерации представлений.
Как компании решают проблему задержки данных сегодня и почему это не лучшее решение?
Традиционный процесс обновления данных DWH выглядит примерно так:
Получение снапшота таблицы Postgres (в формате CSV) с помощью pg_dump
Парсинг вывода и форматирование данных для потребления DWH
Загрузка этих данных в DWH
И снова повторить... Как часто вы можете выполнять это ежедневно?
Сообразительные компании, страдающие от этого, обычно приобретают Fivetran for Databases или Fivetran Teleport. Однако такое решение не всегда является приемлемым для компаний по различным причинам, таким как стоимость, недостающие возможности/интеграции и другие.
Инженерные команды могут и пытались создать это самостоятельно, но решение является сложным и трудно масштабируемым. Почему?
Технология захвата измененных данных (CDC) не поддерживает языки описания данных (DDL), такие как добавление или удаление столбцов.
Компании обычно используют более одного типа баз данных, и для каждого из них требуется свой парсер и, возможно, новый пайплайн.
Надежность - это свойство равное 0. Быстрая репликация данных - это здорово, но только если результаты надежны. Если внутренний процесс пропускает событие CDC или обрабатывает строки не по порядку, итоговые данные перестают быть согласованными, и в конечном результате мы получаем неверное представление.
DWH предназначены для обработки высоких показателей QPS (запросов в секунду) для команд COPY, а для обработки мутаций данных (обновление и удаление) потребуется обходной путь.
Введение Artie Transfer
Artie Transfer непрерывно передает данные OLTP (через CDC) и реплицирует их на указанное DWH, сокращая задержку репликации с часов/дней до секунд. Мы считаем, что это позволит всей экосистеме генерировать более точные представления и раскрыть дополнительные юзкейсы, которые ранее были недостижимы из-за этого ограничения.
Для того чтобы реализовать данное обещание, ниже представлена конфигурация Artie Transfer под капотом.

Сквозной поток разбит на две части:
#1 - Захват событий CDC
Мы будем использовать коннектор для чтения логов базы данных и публикации их в Kafka. Обычно для этого применяется Debezium, когда он доступен.
На каждую таблицу будет приходиться один топик, поэтому можно независимо масштабировать последующие рабочие нагрузки в зависимости от пропускной способности таблицы.
Ключ партиции сообщения Kafka будет первичным ключом для таблицы и одного топика на таблицу.
#2 - Artie Transfer
Artie Transfer подписывается на топик Kafka и начинает создавать резидентную базу данных в оперативной памяти о том, как выглядят топики (один пользователь Artie Transfer может подписаться на один или несколько топиков Kafka). Затем, по истечении интервала очистки (по умолчанию 10 с) или при заполнении базы данных в оперативной памяти, в зависимости от того, что произойдет раньше, Artie Transfer выполнит очистку. После очистки Artie Transfer выполняет оптимизирующий запрос к целевому хранилищу данных и мерджит микропакеты измененных данных.
Чтобы поддерживать такой рабочий процесс, Artie Transfer обладает следующими возможностями:
Автоматические ретраи (повторные попытки) и идемпотентность. Мы серьезно относимся к надежности, и это свойство равно 0. Сокращение задержки - это хорошо, но не имеет значения, если данные неверны. Мы обеспечиваем ретраи в автоматическом режиме и идемпотентность, чтобы всегда достигать конечной согласованности.
Автоматическое создание таблицы. Transfer создаст таблицу в указанной базе данных, если она не существует.
Отчеты об ошибках. Предоставьте свой API-ключ Sentry, и ошибки, возникающие при обработке данных, будут появляться в вашем проекте Sentry.
Детекция схемы. Transfer автоматически обнаружит изменения столбцов и учтет их по месту назначения.
Масштабируемая архитектура. Архитектура Transfer остается неизменной независимо от того, имеем ли мы дело с 1 ГБ или 100+ ТБ данных.
Минимальная задержка. Transfer построен на основе потребительского фреймворка и постоянно передает сообщения в фоновом режиме. Попрощайтесь с диспетчерами!
В дополнение к этому предложению мы также предоставляем платную управляемую версию, которая включает в себя:
Настройка вашей базы данных по включению CDC и предоставление коннекторов для чтения и публикации сообщений на Kafka.
Предоставление управляемой версии Artie Transfer.
Наконец, мы считаем, что нулевая задержка репликации между OLTP и OLAP базами данных должна быть нормой, и стать широко доступной. В связи с этим мы предоставили открытый исходный код Artie Transfer!
В конце статьи хочу пригласить вас на бесплатный вебинар по теме: "Почему БД прилегла отдохнуть или вопросы оптимизации производительности".
Aldres
Пожалуй, корректнее было бы перевести, хотя бы как главное качество системы или вроде того. Иначе выходит надмозг