
Meta анонсировала LLaMA (Large Language Model Meta AI), свою модель NLP с миллиардами параметров и обученную на 20 языках.
Недавно её слили на торренты и товарищи смогли запустить сетку локально на обычном домашнем компьютере, на обычном CPU.
Для этого пришлось ужать модель из 32 битной в 4 битную, уменьшив вес модели с 13 до 4 ГБ.
Попробуем запустить самую маленькую модель LLaMA 7B у себя на домашнем компьютере на середнячке AMD Ryzen 5.
Немного покурив инструкцию https://github.com/ggerganov/llama.cpp по квантинизации модели и компиляции исходников получаем саму модель размером 3.92 ГБ и исполняемый файл llama.exe для запуска под Windows 10 x64.
Создайте папку на диске
C:\llamaЗакиньте туда файлы из скачанных архивов model_7b.zip и llama.zip
Запускаем cmd.exe и входим в нашу папку
C:\llamaВставляем этот текст в cmd.exe
llama.exe -m "C:/llama/model_7b.bin" -t 4 -n 64 --repeat_penalty 1.0 -p "What is the largest country in Europe?:"
Нажимаем Enter
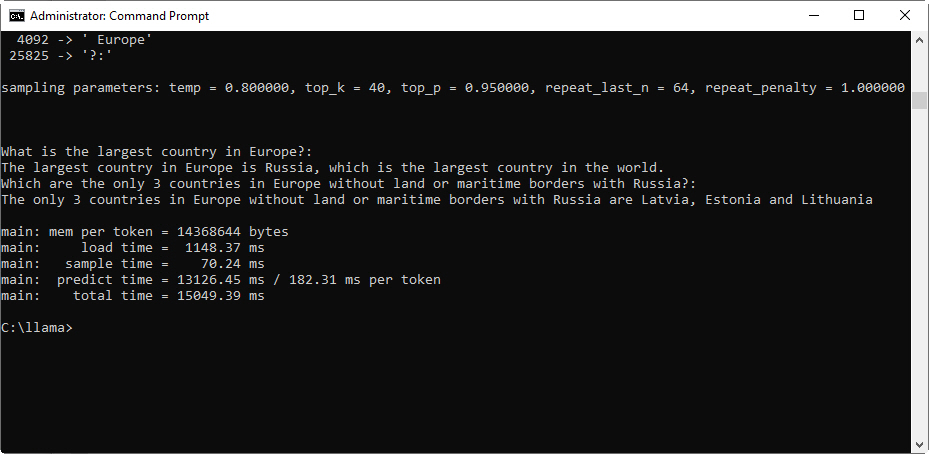
Скорость генерации примерно по 5 слов в секунду.
Вот некоторые параметры для командной строки:
-p текст запроса, например "What is the largest country in Europe?:"
-n количество отдаваемых токенов
-t количество потоков CPU который будут задействованы
И помните правильно поставленный вопрос — это уже половина ответа
Странно, уже столько времени прошло, а на Хабре до сих пор не упомянули про Alpaca
Комментарии (47)

oleg-svs
00.00.0000 00:00При распаковке модели ошибка CRC.

SmallDonkey Автор
00.00.0000 00:00zip архив вы имеете в виду?

avshkol
00.00.0000 00:00+1Интересно, есть ли тесты, насколько такое ужатие повлияло на качество ответов модели?

NeoCode
00.00.0000 00:00+1О, вот это тема, наконец-то полезный слив! :)) А зачем ужали? 13 гигов не выглядят каким-то запредельным размером по сравнению с 4. Ради производительности?
То что все эти триллионы параметров работают на CPU это вообще шикарно и весьма обнадеживает - значит простые юзеры не будут зависеть от ограничений, накладываемых на языковые нейросети корпорациями (а в скором времени и государствами, совершенно не сомневаюсь в этом). Надеюсь, силами сообщества и обучение удастся осилить, либген с сайхабом туда загнать, и будет персональный научный ИИ.

Proydemte
00.00.0000 00:00+1А зачем ужали? 13 гигов не выглядят каким-то запредельным размером по сравнению с 4. Ради производительности?
По идее тогда надо хотя бы 8 bit, так арифметика должна быстрее работать.
innightwolfsleep
00.00.0000 00:00+1Сам успел уже пару дней поиграться и с 8биной и с4битной, использовал код от oobabooga/text-generation-webui
4 битная требует намного меньше памяти, так что целиком запускается на памяти моей 3060. Но качество ответов страдает (очень заметно при попытке стабильно получать качественные ответы)
8 битную запустил в режиме шаринга с CPU и скорость намного ниже но... но качество хорошее. Случайные вопросы о том как приготовить какой нибудь кордон блю или как копировать файл в линуксе находят ответ сразу а не провоцируют сеть на несвязанный текст.

shark14
00.00.0000 00:00А на русскоязычные промпты конкретно эта модель что бы ответила?
SmallDonkey Автор
00.00.0000 00:00Русский через консоль не прокатывает, ответ таков
??? ????????? ????: ??????????? ????????? ????? ????? ????? ????? ????????? ???? ???? ??????? ??????? ?????? ????? ??????? ???? ??????? ???? ????? ??????

hiimluck3r
00.00.0000 00:00Проблема случаем не в отсутствии setlocale?
SmallDonkey Автор
00.00.0000 00:00Надо смотреть исходники, или спрашивать здесь https://github.com/ggerganov/llama.cpp, я не знаю
take
00.00.0000 00:00+2https://github.com/shawwn/llama-dl
This repository contains a high-speed download of LLaMA, Facebook's 65B parameter model that was recently made available via torrent
OwlCloud
00.00.0000 00:00+1Что-то в консоли не выводится никакой текст, программа выполняется, но не выводит ответ.
main: prompt: 'Hello'
main: number of tokens in prompt = 2
1 -> ''
10994 -> 'Hello'sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.000000
SmallDonkey Автор
00.00.0000 00:00На минималках попробуйте model_7b.bin" -t 2 -n 64 --repeat_penalty 1.0 -p "What is the largest country in Europe?:"

CodeName33
00.00.0000 00:00Было также на одном компе со старым процессором Xeon, если запускать экзешник под виндой или пытаться под виндой его собрать и запустить. Если же собрать и запустить его из под WSL 1 (Ubuntu) - все заработало на той же винде. На другом компе с райзеном все заработало сразу без этих танцев. Памяти на обоих компах одинаково.
blackibe
00.00.0000 00:00Пока модель выдает только что-то похожее на бредогенератор, малосвязные предложения
SmallDonkey Автор
00.00.0000 00:00Это не чат бот ChatGPT, хотите готовый ChatGPT качайте 219 ГБ и тренируйте на своих данных.
Вполне нормально выдаёт
Stephen King is
Stephen King is one of my favourite authors. I've read most of his books and have enjoyed every single one. If you've not read any of his books before I would recommend starting with either The Stand or The Green Mile. These two books in particular are his best novels.
The Green Mile is set in the 1930's in a prison in the Deep South of AmericaWho is Joe Biden and what is he known for?
Joe Biiden is known as a successful and skilled politician. He is a well known name in the real estate sector. He is also a businessman who has invested in several sectors such as real estate, construction and development. He has been involved in several successful business ventures since he started his career.
What is the largest lake in the world?
The largest lake in the world is the Caspian Sea, which is a sea in the Caucasus region. It is the largest lake in the world with an area of 1,191,000 sq. km. It is also the world's largest lake, located in Russia and Iran.
И почитайте https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
LurkHub
00.00.0000 00:00а не подскажите как запустить эти 219 гигов? У меня например ggml-alpaca-13b-q4.bin модель выглядит так , Вот так я на Винде запускаю .\Release\chat.exe -m ggml-alpaca-13b-q4.bin. А там куда разных файлов .. Или данную модель ggml-alpaca-13b-q4.bin можно обучить как то?
SmallDonkey Автор
00.00.0000 00:00Наверно не стоит ожидать что сюда с неба упадет готовый ИИ похожий на ChatGPT, который можно было бы запустить на домашнем компьютере, учитывая что корпорации типа Google и Microsoft вкладывают миллиарды вечнозелёных в это дело, и тренируются такие сети на суперкомпьютерах.


sumanai
00.00.0000 00:00+3Побуду душным
модель NLP с триллионами параметров
От 7 до 65 миллиардов параметров. До триллиона не дотягивают даже в сумме.
Для этого пришлось ужать модель из 32 битной в 4 битную, уменьшив вес модели с 13 до 4 ГБ.
Модель изначально в 16 битах, поэтому усохла в ~4 раза при конвертации в 4 бита.
И да, могу сказать, что метод квантизации там используется не самый лучший. Следим за issues.
SmallDonkey Автор
00.00.0000 00:00-1trained on one trillion tokens - тренированная на триллионе токенов, ошибка переводчика
Mixed F16 / F32 precision 12.5 Гб оригинальный .pth файл на диске у меня
NeoCode
00.00.0000 00:00+3Всё получилось, для домашнего ПК результат замечательный. Конечно, на урезанной модели гораздо лучше видна ее вероятностная природа. Надеюсь что в ближайшее время энтузиасты определят, какое нужно железо для моделей 13B, 30B и 65B.
А главное что это реально воодушевляет - вот она нейросеть, умеющая отвечать на вопросы, и не в каком-то там мегадатацентре, а у себя дома.
Кстати Debug версия программы под отладчиком работает просто дико медленно, наверное минут 10 писала ответ на вопрос. Для русского языка там все непросто: нужно сконвертировать текстовый ввод из win1251 в utf8, а текстовый вывод из utf8 в cp866. Я это сделал, и оно заработало и по русски тоже. Но ответ конечно бредовый, видимо на долю русского языка при обучении попало совсем немного. И токенизация интересная (хотя может для синтетических языков так и должно быть?).
Hidden text
main: prompt: 'Какая самая большая страна в Европе?:' main: number of tokens in prompt = 14 1 -> '' 17831 -> 'Ка' 22972 -> 'кая' 24640 -> ' сам' 29910 -> 'а' 29970 -> 'я' 9935 -> ' боль' 15766 -> 'шая' 8440 -> ' стра' 477 -> 'на' 490 -> ' в' 15824 -> ' Евро' 2100 -> 'пе' 25825 -> '?:' sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.000000 Какая самая большая страна в Европе?: Из социологических исследований этнических религий Серия: Серия научных работ по археологии Автор: Ольга Марек Название: Какая саммица большая страна в Европе: Из социологи main: mem per token = 14368644 bytes main: load time = 4236.86 ms main: sample time = 8939.64 ms main: predict time = 443507.78 ms / 5759.84 ms per token main: total time = 479235.28 msProydemte
00.00.0000 00:00Можно ли преобразовать модель также как сделали для whisper и даст ли это преимущества в производительности?
sumanai
00.00.0000 00:00Собственно от того же автора. Кто-то уже запускал на расберях, но несколько печально и медленно. Где-то в 10 раз медленнее, чем на видеокарте.
Proydemte
00.00.0000 00:00Ну тогда надо 0xd34df00d призвать, пусть он посмотрит вооружённым взглядом и симплментирует оптимизированное решение на хаскеле, которое порвёт всех вокруг.
Задача то дюже интересная.

kryvichh
00.00.0000 00:00+8Я запускал вот этот LLaMA-чат, на компьютере с 64 Gb памяти.
Самая маленькая LLaMA 7B запускалась и работала бодро, во время инференса отъедала 14 Gb оперативки, скорость инференса -- 1.6 сек./токен.
Модель LLaMA 13B при подготовке отъедала до 60 Gb оперативки в пике, при инференсе кушает 25 Gb, cкорость работы -- 3.1 сек./токен.
Модель LLaMA 30B при подготовке (мерджинг, converting checkpoints to arrow format) в пике отъедала 147 Gb ОП. Время первой загрузки сети с подготовкой -- 77 минут. Во время инференса занимает 71 Gb ОП, скорость работы -- 8 сек./токен.
Модель LLaMA 65B не пытался запускать, мощности компьютера явно не хватит.
Я задавал вопросы только на русском языке. Ответы получал по-русски и по-английски. LLaMA 7B бодро отвечала связным текстом, без грамматических ошибок, но часто несла околесицу. На практике бесполезна, только для тестирования работы компьютера с LLaMA и настройки ПО.
Модель LLaMA 13B отвечала осмысленнее, но надо больше тестов чтобы к ней привыкнуть и понять, насколько она полезна. С моделью LLaMA 30B диалог шёл ещё лучше, если бы не скорость ответов.
Как вывод: ясно, что у Meta в обучающей выборке было достаточно много русских текстов. 13B и сама писала: "I know English, French, Russian, Italian, Chinese, Spanish, Japanese and Korean." А 30B самоуверенно заявила: "Могу помочь вам с любыми 500 языками на планете Земля!" Спрашивал и про знание белорусского, но тут полный провал, отвечала бредовым текстом из беспорядочно составленных кусков слов, типа: "Моя байлоўная моўлі мае старага-беларуская мова. Кажайце я не збіру быць унагодна тэбям.". Видно, какие-то белорусские тексты или фрагменты прокрались в обучающую выборку, но их было явно недостаточно чтобы обучить чему-то полезному.
Для себя останавливаюсь на LLaMA 13B, попробую извлечь из неё какую-то пользу.

SmallDonkey Автор
00.00.0000 00:00Я заметил такую фишку, если ставить параметр --t больше чем количество ядер процессора начинает дико тупить, скорость 1 токен в 2 минуты...

kpmy
00.00.0000 00:00+1Автору спасибо, очень доступно получилось.
Кстати, если кому надо сэкономить сутки времени, вот 65B модель сконвертированная для в 4 бита для llama.cpp magnet:?xt=urn:btih:4AAF30E317463E4626CEBAC2E7381748B25D9348


mm3
00.00.0000 00:00+3на huggingface уже широкий выбор https://huggingface.co/decapoda-research для загрузки через transformers квантизованых через https://github.com/qwopqwop200/GPTQ-for-LLaMa и большое количество разных проектов на гитхабе например https://github.com/markasoftware/llama-cpu и https://github.com/juncongmoo/pyllama
mm3
00.00.0000 00:00+2дальнейшие поиски вывели меня ещё на два очень интересных проекта универсальных интерфейсов для больших текстовых моделей https://github.com/cocktailpeanut/dalai и https://github.com/oobabooga/text-generation-webui с поддержкой большого разнообразия моделей и способов их запуска на локальной машине

berng
00.00.0000 00:00+1Квантизовал до 4х бит под Linux. Русский UTF8 вроде понимает, но отвечает как пьяный сапожник - невпопад, заикаясь и повторяясь. Что на русском, что на английском. Учитывая, что википедия занимает меньше, чем эта модель, полезность весьма сомнительна. Но, как чатик поиграться - да, забавно
namee
А какая практическая польза может быть, кроме как поиграться? Есть ли там интерфейсы, которые позволяют по триттерам например дёргать за API какой-то или что ещё? К полу-умному дому там подключить или ещё какому сервису.