
Нативный кэш позволяет повысить производительность при чтении и записи, а также акцентировать достоинства Linux, при этом лучше понимая, что происходит.
Дисклеймер:
Некоторые приведённые здесь объяснения и описания значительно сокращены и упрощены по сравнению с реальными процессами, происходящими под капотом — это сделано для простоты и доходчивости, чтобы текст был интереснее для читателей, не слишком интересующихся темой и не столь вовлечённых в неё. Здесь я целенаправленно не вдаюсь в такие технические детали как работа со страницами, размеры блоков, более сложные термины и операции.
❯ Производительность Linux при чтении и записи
При управлении памятью ядро Linux использует нативный механизм кэширования, так называемый страничный кэш или дисковый кэш, чтобы повысить производительность операций чтения и записи.
Проще говоря: основное назначение этого механизма заключается в копировании данных и двоичных файлов из долговременной памяти в оперативную. Так сокращается количество дисковых операций ввода/вывода и в целом улучшается производительность. Это особенно заметно при работе с такими нагрузками, при которых часто приходится открывать одни и те же файлы или проводить другие ресурсозатратные операции, связанные с вводом/выводом.
Страничный кэш используется не только при чтении с диска, но и при записи на диск, но мы и до этого вскоре дойдём.
По умолчанию вся свободная физическая память используется операционной системой для нужд страничного кэша. В зависимости от рабочих нагрузок, операционная система управляет собственным состоянием и кэширует, переиспользует и вытесняет файлы по мере необходимости.
Даже притом, что современные твердотельные диски обеспечивают улучшенную пропускную способность, производительность системы можно тем более улучшить, если кэшировать файлы в памяти.
Кроме того, существует распространённое заблуждение, что операционная система (Linux, Unix или BSD-подобная) – в особенности при работе на мобильных устройствах – испытывает дефицит свободной памяти, поэтому с течением времени свободную память требуется тем или иным образом оптимизировать. Фактически, наличие свободной памяти – это уже хорошо; такая ситуация означает, что многие вещи уже кэшированы, многие наши приложения будут работать быстрее, а файлы – быстрее извлекаться из памяти.
Важно постоянно учитывать, что кэшированная память (всегда) — это свободная доступная память, которая будет возвращаться по мере необходимости без каких-либо штрафов для тех новых действующих процессов, которым она может потребоваться.
Оптимальной считается такая система, которая использует практически все доступные ресурсы (в основном это касается ОЗУ и ЦП) на те цели, для которых они предназначены, непосредственно перед тем, как начинает вырисовываться какой-либо конфликт за ресурсы или приходится расплачиваться за сниженную производительность.
❯ Простые операции чтения
Давайте рассмотрим простой пример с файлом на 2 ГБ. Ради простоты сейчас не будем ориентироваться на спецификацию VM – то есть, мы просто хотим убедиться, что у нас в распоряжении больше памяти, чем занимает тот файл, который мы читаем are.
Сначала проверим состояние памяти, чтобы посмотреть, сколько у нас её всего, каковы значения буферов и кэшей.
# free -wh
total used free shared buffers cache available
Mem: 5.8G 94M 5.7G 608K 2.1M 49M 5.6G
Swap: 0B 0B 0BПосле этого сгенерируем файл-заглушку размером 2 ГБ, а затем освободим и удалим все кэши, которые могли возникнуть при работе.
# head -c 2G </dev/urandom > dummy.file
# echo 3 > /proc/sys/vm/drop_cachesДалее подсчитаем количество строк в файле и замеряем, сколько времени он выполняется:
# time wc -l dummy.file
8387042 dummy.file
real 0m3.731s
user 0m0.278s
sys 0m1.223sВновь выполним ту же команду:
# time wc -l dummy.file
8387042 dummy.file
real 0m1.045s
user 0m0.575s
sys 0m0.471sТеперь чётко видно, что на последний прогон ушло гораздо меньше времени, чем раньше. Дело в том, что файл лежал в страничном кэше, и уже по этой причине операция чтения прошла лучше. Давайте ещё раз подтвердим значения состояния памяти.
# free -wh
total used free shared buffers cache available
Mem: 5.8G 94M 3.7G 608K 2.1M 2.1G 5.5G
Swap: 0B 0B 0BКак видим, теперь у нас на 2ГБ меньше свободной памяти, зато мы гораздо активнее используем буферы и кэш.
Кэш – это часть памяти, где хранятся файлы и бинарники, например, разделяемые библиотеки и данные. Благодаря кэшу, последующие обращения за этими данными удаётся обслуживать быстрее.
Буферы – это метаданные, касающиеся кэша.

Чтение без кэширования
Чтение с кэшированием
Теперь мы снова очистим кэши, чтобы вернуться к исходному состоянию, но воспользуемся иной командой, чтобы в дальнейшем полностью учитывать, что есть такая возможность.
# sysctl -w vm.drop_caches=3При подсчёте строк, опять же, берётся полное время, необходимое, чтобы заложить файл обратно в память. Но, прежде, чем к этому приступить, давайте при помощи команды проверим, кэширован ли файл.
Команду vmtouch нужно устанавливать отдельно. С её помощью можно проверить, кэширован ли файл (или его часть).
# vmtouch -v dummy.file
dummy.file
[ ] 0/524288
Files: 1
Directories: 0
Resident Pages: 0/524288 0/2G 0%
Elapsed: 0.013999 secondsПодсчитываем строки, убедившись, что файл не кэширован – и получаем 0%.
# time wc -l dummy.file
8387042 dummy.file
real 0m3.732s
user 0m0.284s
sys 0m1.539sЧто мы видим после первого считывания вывода vmtouch?
# vmtouch -v dummy.file
dummy.file
[OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO]524288/524288Files: 1
Directories: 0
Resident Pages: 524288/524288 2G/2G 100%
Elapsed: 0.024309 secondsФайл полностью кэширован, поэтому следующие операции чтения пойдут быстрее.
❯ Добавление информации в кэшированный файл
Если добавить информацию в кэшированный файл или изменить её, то конечный результат также будет кэшироваться, если доступная память этого не ограничивает. Далее показано, почему по той же причине был кэширован small.file – ведь он также был прочитан.
# cat small.file >> dummy.file
# vmtouch -v dummy.file
dummy.file
[OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO]786433/786433
Files: 1
Directories: 0
Resident Pages: 786433/786433 3G/3G 100%
Elapsed: 0.035199 secondsЕсли вы не заметили – это была операция записи. Далее давайте рассмотрим, как работает кэширование при записи.
❯ Запись файлов
Как уже упоминалось выше, страничный кэш используется и при записи на диск, и так улучшается общая производительность.
В Linux, когда мы создаём файл, этот файл первоначально записывается в страничный кэш, и только спустя некоторое время или по наступлении определённого условия этот файл сбрасывается на диск.
Стоит отметить, что такое поведение зависит от нескольких факторов – например, от типа той файловой системы, куда записывается файл, а также от системных вызовов, инициируемых приложениями. Обычно комбинации этих факторов дают в результате разные типы доступа при вводе/выводе.
❯ Прямой ввод/вывод
- Файлы сразу же сбрасываются на диск.
- Возможные проблемы с производительностью, если подсистема ввода/вывода или планировщик очень занят.
- Этот метод используется во многих хранилищах данных и базах данных, так, что они, а не операционная система контролируют операции записи.
- В некоторых файловых системах этот механизм поддерживается на уровне флагов монтирования.
❯ Буферизованный ввод/вывод
- Использует буферный кэш файловой системы.
- Операции записи происходят быстрее, так как информация первым делом заносится в память.
- Создаются временные грязные страницы.
- Возможны потери или повреждение данных при внезапном прекращении питания (очень редко).
Итак, мы используем страничный кэш при буферизованном вводе/выводе, давайте рассмотрим такую ситуацию на простом примере:
# free -wh
total used free shared buffers cache available
Mem: 5.8G 92M 5.7G 608K 1.9M. 50M 5.6G
Swap: 0B 0B 0B
# head -c 1G </dev/urandom > small.file
# free -wh
total used free shared buffers cache available
Mem: 5.8G 92M 4.7G 608K 1.9M 1.1G 5.5G
Swap: 0B 0B 0BЕсли ограничений памяти нет, то весь файл сначала (с сохранением грязных страниц) записывается в память, а затем целиком сбрасывается на диск.
Грязные страницы – это тот объем информации, который находится в страничном кэше, но ещё не синхронизирован с диском. Рано или поздно ядро всё равно синхронизирует всю находящуюся а памяти информацию и сбросит на диск.
Иногда одновременно поступает сразу много рабочей нагрузки, связанной с вводом/выводом, либо планировщик может быть занят выполнением задачи с более высоким приоритетом. Он будет импровизировать и найдёт оптимальный хронометраж для сброса данных на диск, так, чтобы «учитывать» производительность.
Можно проверить, сколько данных содержится на грязных страницах:
# cat /proc/meminfo | grep Dirty
Dirty: 369536 kBТакже можно выполнить принудительную синхронизацию.
# sync
# cat /proc/meminfo | grep Dirty
Dirty: 0 kB❯ Кэширование множественных файлов
Теперь давайте рассмотрим более сложный пример, где приходится работать сразу со множеством файлов. Причём, суммарный размер этих файлов больше, чем размер памяти, доступной для кэширования.
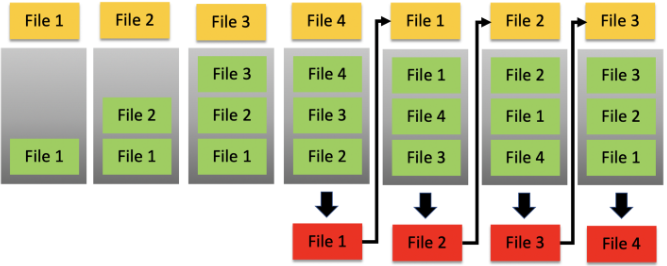
Давайте создадим 4 файла размером по 2 ГБ каждый, но имеющегося у нас кэша хватит всего на 3 таких файла:
# head -c 2G </dev/urandom > dummy.file1
# head -c 2G </dev/urandom > dummy.file2
# head -c 2G </dev/urandom > dummy.file3
# head -c 2G </dev/urandom > dummy.file4По мере чтения (жёлтый) каждого файла по порядку эти файлы будут укладываться в стек (зелёный) в страничном кэше.
Когда мы читаем следующий файл, а памяти на одновременное кэширование всех 4 файлов не хватает, один из этих файлов будет выталкиваться (красный) из стека. В этом случае будет выталкиваться файл 1 (самый старый).
Если мы снова прочитаем тот файл, который был вытолкнут, какой файл останется?
Проще говоря, тот файл, который сейчас был вытолкнут из кэша, становится LRU (тем, который «дольше всего не запрашивался») в соответствии с политикой замены страниц. В таком случае заменяется та запись кэша, которая ранее не использовалась дольше всего.
Важно отметить, что на самом деле действующий здесь алгоритм сложнее обычного LRU и сопряжён с использованием не одного списка, а нескольких. Подробнее эти вопросы описаны в документации по ядру.
Если мы повторно используем имеющийся файл кэша, он поднимется в стеке, как файл, используемый чаще всего.
В зависимости от количества файлов, их размера и доступной памяти, кэшироваться могут не файлы целиком, а лишь часть содержащейся в них информации.
Это видно на примере с командой vmtouch:
# vmtouch -v dummy.file1
dummy.file1
[ oOOOOO] 45414/524288
Files: 1
Directories: 0
Resident Pages: 45414/524288 177M/2G 8.66%
Elapsed: 0.035156 seconds❯ Кэширование огромного файла
Что произойдёт со страничным кэшем, если прочитать такой файл, размер которого значительно превышает объём доступной памяти в системе?
В таком случае должно быть понятно, что в страничном кэше будут сохранены только отдельные части файла. Но как повлияет на производительность вычисление данных из этого файла?
Давайте попробуем кэшировать большой файл:
# time wc -l big.file
33544011 big.file
real 0m14.426s
user 0m1.202s
sys 0m6.737s
# vmtouch -v big.file
big.file
[ oOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO] 1621005/2097152
Files: 1
Directories: 0
Resident Pages: 1621005/2097152 6G/8G 77.3%
Elapsed: 0.077948 secondsРазмер файла равен 8 ГБ, но, как видно из вывода vmtouch, в страничный кэш помещается только 6 ГБ. Что это означает с точки зрения производительности? Давайте повторно обработаем файл и посмотрим, получится ли выигрыш в производительности.
# time wc -l big.file
33544011 big.file
real 0m14.260s
user 0m1.959s
sys 0m4.741sПри повторном считывании целого файла производительность не улучшилась. Но почему?
Поскольку файл считывается, и в то же время результат чтения кэшируется, он не помещается в память полностью, что и показала нам vmtouch. Происходящее можно сравнить со скользящим окном, и в таком случае начало файла всегда остаётся вне кэша.
Голова файла вне кэша, но что, если мы попытаемся прочитать хвост файла?
# time tail -5000000 big.file >/dev/null
real 0m4.696s
user 0m2.687s
sys 0m2.001sКак это соотносится с некэшированным хвостом? Давайте очистим все кэши и обработаем только этот хвост.
# sysctl -w vm.drop_caches=3
# time tail -5000000 big.file >/dev/null
real 0m34.682s
user 0m2.987s
sys 0m4.379s
# time tail -5000000 big.file >/dev/null
real 0m4.524s
user 0m2.649s
sys 0m1.873s
# vmtouch -v big.file
big.file
[ oOOOOOOOO] 312460/2097152
Files: 1
Directories: 0
Resident Pages: 312460/2097152 1G/8G 14.9%
Elapsed: 0.080427 secondsЕстественно, мы сильно выиграли, начав с хвоста при считывании целого файла, так как, хотя весь файл и не поместился в страничном кэше, та часть, которой мы пользовались, в кэш попала.
Поскольку обработка конца файла сработала, то же самое подойдёт нам и при кэшировании головы файла, и при кэшировании любой другой его конкретной части.
Необходимо держать это в уме, работая с файлами больших данных, поскольку мы можем явно улучшить производительность, если будем кэшировать только те части файла, с которыми намереваемся работать.
Опережающая стратегия при кэшировании файлов позволяет повысить производительность как при чтении, так и при записи.
❯ Нативный страничный кэш vs Службы для выделенного кэширования
Как работает страничный кэш Linux в сравнении со службами для выделенного кэширования, действующими на основе свойств хранилища, либо на основе содержимого?
Первым делом уясним, что сервис для выделенного кэширования либо для обработки в оперативной памяти применяется в очень специфических целях и только с определёнными рабочими нагрузками. Поэтому любое непосредственное сравнение двух этих вариантов получится несбалансированным, а в некоторых случаях – и неприменимым.
Но определённо, любое кэширование на диске, выполняемое самим ядром, всегда пойдёт быстрее, чем при использовании локального выделенного сервиса поверх него, и гораздо быстрее, чем при использовании удалённого кэширующего сервера.
(Как правило) все эти сервисы конфигурируются поверх самого Linux. В особенности при работе с распределённым, а не единичным сервисом, приходится учитывать всю работу по координации и обнаружению, ведущуюся между узлами, а также возможные сетевые задержки и общее время передачи по сети.
Вот несколько разных типов кэширования:
Кэширование на стороне клиента
- Дисковый кэш
- DNS-кэш
- Браузерный кэш
Кэширование в сети
- Сети доставки содержимого
- Веб-прокси серверы
Кэширование на уровне сервера
- Кэширование на веб-сервере
- Кэширование в приложениях или обработка в оперативной памяти
- Кэширование в хранилищах данных и базах данных
❯ Заключение
Страничный кэш прост, он нативно расположен в операционной системе и даёт явное улучшение производительности при чтении и записи данных. Играет важную роль в работе нативных процессов операционной системы и при совместном использовании данных и библиотек между процессами, тем самым оптимизируя выполнение кода в пространстве ядра и пользовательском пространстве.
Понимая кэш, можно принимать более информированные решения о том, что следует кэшировать, когда, а также требуется ли в самом деле выделенный сервис для кэширования. При работе на локальной машине выделенный сервис обычно не требуется.
Во многих сервисах кэш используется нативно, а в некоторых реализуются разные уровни кэширования для тех или иных рабочих нагрузок – в особенности это касается баз данных.
К этой теме также относится обширная информация о подсистеме управления памятью, настройке кэша и производительности, управлении подкачкой, о различных файловых системой, параметрах ядра и конкретных устройствах для кэширования, но эти вопросы выходят за рамки данной статьи.
