
Рассказывает программист Александр Тулуп:

Время сборки проекта имеет немалое значение в процессе разработки. Начиная с "комфорта" разработчика при внесении изменений, заканчивая стоимостью оборудования, необходимого для организации CI.
Проблема
Проект активно разрабатывается, добавляется новый функционал, увеличивается объем кодовой базы и время сборки...
На момент начала исследования время сборки Debug перевалило за 20 минут и продолжало расти (а впереди ещё linux‑версия, что потребовало бы удвоения вычислительных мощностей), несмотря на использование средств ускорения компиляции, таких как Incredibuild. «Средний» компьютер разработчика в основном состоял из топового железа для своего времени, да и сеть уже была расширена до 1 Гбит.
А это значит, что «легких» способов ускорения практически не осталось.
C++ Build Insights
Придется подходить к делу с умом.
Как обычно ищут узкое место в производительности ? Правильно, используют профилировщик.
К этому моменту Microsoft выпустила дополнение к Windows Performance Analyzer (WPA), C++ Build Insights.
Суть ее в том, что в компилятор встраиваются метки, которые фиксируют время выполнения каждого этапа компиляции: препроцессор, генерация кода, оптимизация, линковка...
Для получения результатов используется системный профилировщик Windows Performance Analyzer (WPA).
Перед тем как начать замер, нужно подружить WPA с компилятором студии. Иначе результаты не будут видны.
Для этого нужно скопировать perf_msvcbuildinsights.dll из студии и прописать в настройки perfcore.ini, подробнее тут.
После чего сам процесс выглядит так:
Начало процесса замера: vcperf /start MySessionNameСборка проекта. События собираются глобально, со всей системы. Поэтому ничего лишнего не должно быть запущено.
Окончание замера: vcperf /stop MySessionName outputFile.etl
В результате мы получим .etl файл, в котором видны результаты профилирования
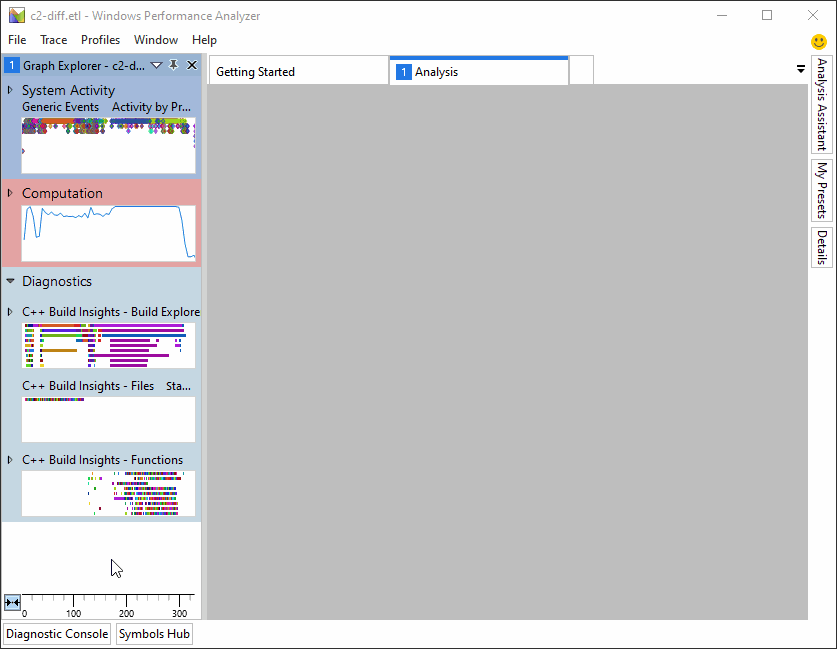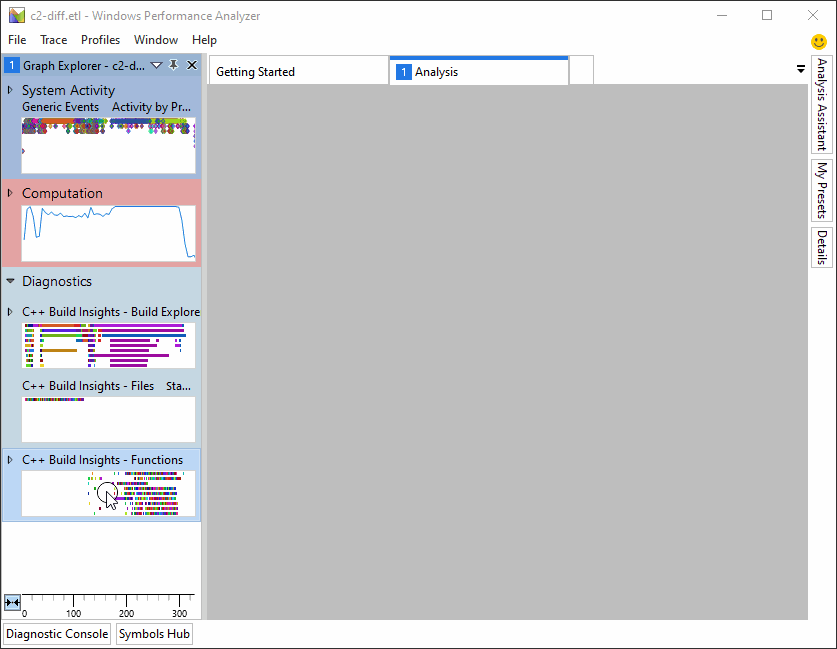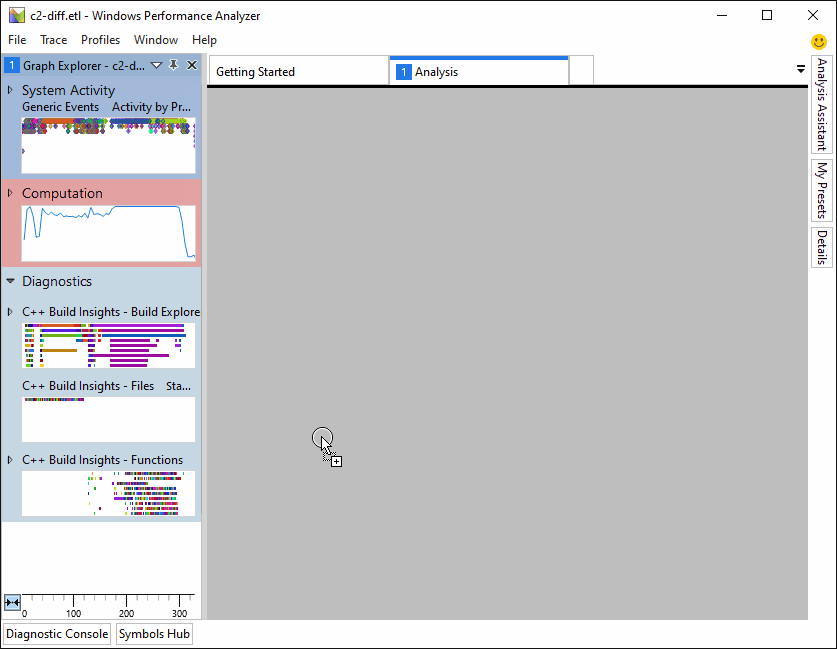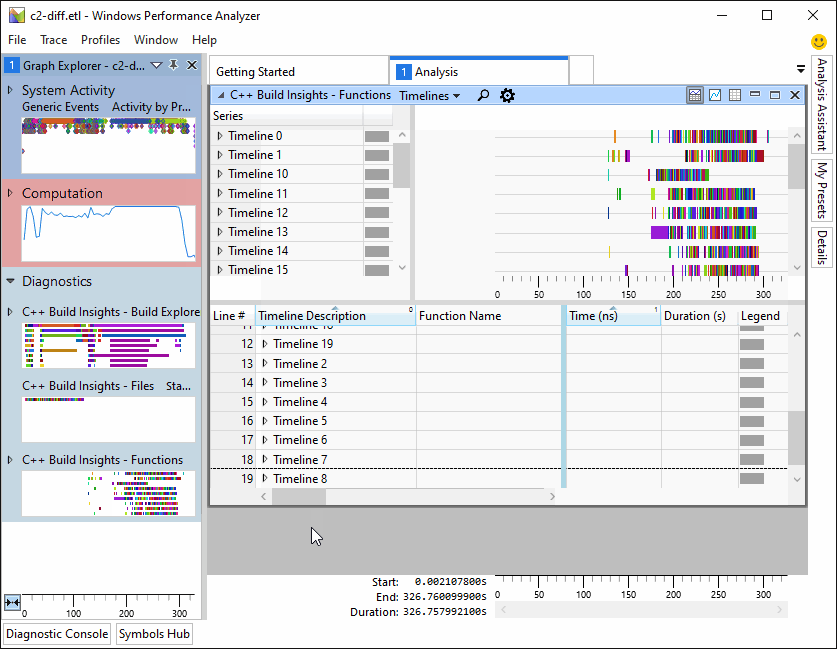
Просмотрев различные метрики, мы заметили, что узким местом оказался этап препроцессора. т. е. вместо того чтобы компилировать, препроцессор снова и снова перечитывал одни и те же файлы по много раз.
Напомню, вдруг кто забыл, как выглядит процесс компиляции (упрощенно):
Для каждой единицы трансляции (обычно *.cpp) выполняется ряд однотипных действий.
Сперва считывается все содержимое в виде текста, попутно раскрывая все инструкции препроцессора, к которым относится и #include.
Если #include содержит в себе вложенные инструкции, то аналогично и для них. И так рекурсивно до полного завершения. т. е. простая строчка в виде #include <boost/property_tree/ptree.hpp> может превратиться в сотни тысяч строк.
Полученный текст отдается генератору кода, который еще пытается что‑то оптимизировать.
На выходе получаем *.obj файл. После обработки всех *.cpp, их следует слинковать, чтобы получить исполняемый *.dll, *.exe, *.so...
Если в проекте используются одинаковые заголовочные файлы, особенно в случае когда что‑то тяжелое в виде boost вынесли в интерфейс, который повсеместно используется в проекте, то тут явно выполняется много избыточной работы.
И с этим нужно что‑то делать.
Варианты решения
Самый очевидный способ - писать код "правильно", используя по максимум forward declaration и идиому pimpl. Найти все "тяжелые" заголовки и переписать как надо. Но у нас проект с богатой историей, т.е. legacy. И просто так все переделать, ничего не поломав... Да к тому же нужно добавлять новый функционал и править баги. Поэтому отложим эту идею на светлое будущее или дождемся полной поддержки (С++20 modules).
А сейчас нужно работать с тем, что имеем.
К счастью, мы не первые, кто сталкивается с подобными проблемами, и уже есть решения. Рассмотрим некоторые из них.
Unity build - а что, если все *.cpp собрать в один и скомпилировать? Сразу отпадает тяжелая часть препроцессора. Были даже эксперименты, и результаты впечатляющие.
Но тогда возникает другая проблема. Такой код сложно поддерживать. Все "приватные" части сразу становятся видимыми. Изменения в одном тянут за собой пересборку большей части кода. Да и багов при переходе можно добавить немало, которые не сразу проявятся. Поэтому пока отложим эту идею в сторону.
Incredibuild, ccache, ... — а что если использовать «ускорители» сборки? Т.к. большинство программистов работают примерно с одним и тем же проектом, и часто на свежих ревизиях, то можно было бы закэшировать результат на сервере и вместо компиляции просто брать уже «готовый» *.obj. Идея выглядит интересно, но это сильно усложняет процесс, требует дополнительный настроек окружения и т. д. К тому же еще впереди портирование на linux, а значит требует дублирования инфраструктуры. Посмотрим, что еще есть?
Precompiled header (PCH) — а что, если взять часто используемые заголовочные файлы в проекте, предварительно их обработать в «оптимальный» для компилятора вид и в местах использования, вместо перечитывания #include, просто выдавать готовый результат? Это похоже на объединение двух предыдущих подходов, т. е. один раз обработать заголовочные файлы. При этом не требуется значительного изменения проекта. Осталось только понять, что туда нужно класть и как поддерживать в актуальном состоянии.
PCH
Для получения списка "горячих" мест используем уже знакомый C++ Build Insights. К счастью, у него уже есть интерфейс для программного доступа к результатам профилирования.
Даже есть репозиторий с готовыми примерами, нас интересует TopHeaders.
В нашем случае нужно просто достать топ N "тяжелых" заголовков и прописать их в PCH.
Достаточно собрать исполняемый файл и отдать ему полученный ранее .etl.
Тут есть одно "но". Для работы через SDK при завершении профилирования нужно выполнить команду с /stopnoanalyze, вместо /stop

TopHeaders уже умеет выдавать полезные метрики вроде частоты использования, времени обработки...
После многочисленных экспериментов с критериями добавления получилось что-то такое.
Оказалось, что чем больше добавляем в pch, тем лучше, но до определенного предела. Например, растет время генерации самого PCH и его объем.
На системах со слабым жестким диском можно даже замедлить.
В крупных проектах доходило до 200 заголовков.
Так же было замечено, что некоторые заголовки из списка уже включены в другие. В формируемом etl уже есть полное дерево include.
Строим граф и выбираем "верхушки". В итоге 200 превращаются в 10.
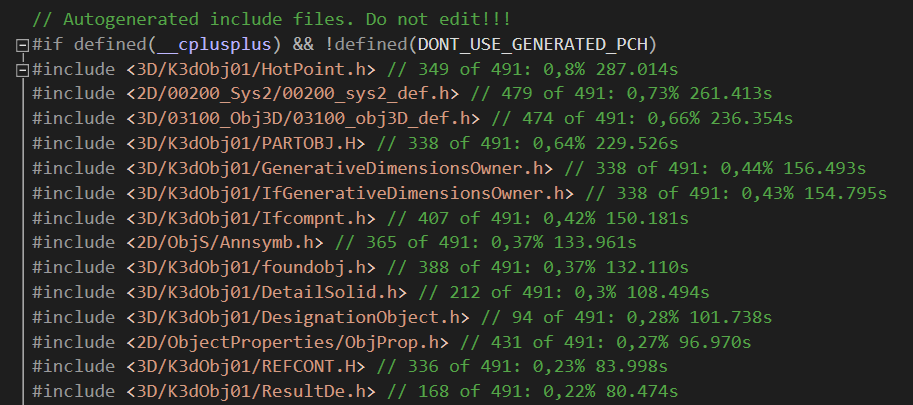
Самое интересное, на сколько удалось ускорить?
Каждый успешный этап заносился в табличку, далее пытались улучшить результат.
В некоторых случаях потребовалось "хирургическое" вмешательство. Т.е. вырезали особо "тяжелые" заголовки, перенося реализацию в pimpl.
На таблице результаты представлены следующим образом. Первый замер, добавили N заголовков, без дополнительной обработки.
Начальное время было около 45 минут. И далее пытаемся немного улучшить. В итоге ускорение получилось около 4 раз.
IWYU
Все это прекрасно, ускорили. А как жить дальше?
Проект постоянно меняется. Добавляется что-то новое, другие заголовки устаревают. Нужно думать, как поддерживать проект в актуальном состоянии.
Т.к. в PCH добавляются заголовки из самого проекта, то это начинает влиять на компиляцию.
Например, использовали std::vector, а заголовок не включили. И все компилируется, т.к. есть в PCH.
Теперь пытаемся перегенерировать, а для этого нужно удалить все из PCH, и получаем тысячи ошибок по всему проекту, что где-то чего то не хватает.
Можно конечно врукопашную "починить" сборку, ради такого раз в несколько месяцев можно и потерпеть. Но как показала практика, с каждым разом это становится все труднее. Проект не только активно развивается, но и переделывается для портирования на Linux.
А это несет за собой масштабные переносы файлов между проектами.
Вот бы этот процесс как-то автоматизировать. Т.е. для каждого *.cpp и *.h включить только те заголовки, что реально используются, и удалить все лишнее.
Оказывается, есть и такое.
Программа так и называется, include-what-you-use (IWYU). Работает это следующим образом. Используя фронтэнд от clang (llvm), строим AST файла.
Анализируем каждый символ, из какого заголовка он пришел. Сравниваем с тем, что включено, и добавляем недостающее, удаляем лишнее.
Но и тут не все так просто. Один и тот же символ может быть определён в разных *.h файлах. В некоторых проектах используется "проброс" деталей реализации в публичные заголовки.
Все это алгоритмически не может быть вычислено. Нужно явно настраивать. Для этого есть специальные *.imp файлы. По структуре, напоминающей json, в котором прописываем ,что откуда брать.
Подробнее тут.
Так же сам алгоритм поиска символов работает с небольшими огрехами. Например, путается в сложных шаблонах и удаляет то, что на самом деле нужно.
Для таких случаев нужно "настроить" проект на месте, прописав в необходимых местах специальные прагмы. В данном случае // IWYU pragma: keep
После длительного (1,5 года) процесса работы в таком режиме удалось достичь достаточно стабильного результата работы.
Иногда все же приходится подправлять руками, но значительно меньше чем до этого.
C++20 Modules
Что дальше ? На подходе с++20 modules. Точнее они уже есть, но поддержка со стороны cmake и основных компиляторов только на подходе.
В чем-то модули похожи с pch. Т.е. также формируют в оптимальном для компилятора формате файл, избавляя от избыточной работы препроцессора.
Но также добавляют еще множество плюшек. Подробнее можно почитать тут.
Вывод
И так, что можно сказать за 1,5 года применения данного подхода?
Позволил отказаться от стороннего ПО, сэкономленную сумму направили на закупку железа (один раз, вместо продления лицензии на крупную сумму каждый год).
Теперь можно собрать проект на месте, даже дома. Что было особенно актуально в эпоху "перехода на удаленку".
Значительно упрощена инфраструктура (не нужно ничего дополнительно устанавливать и настраивать: взял исходники, студию и можно собирать).
Позволил упростить разработку на Linux.
Относительно легко поддерживать в актуальном состоянии, после настройки iwyu.
Комментарии (14)


OMR_Kiruha
00.00.0000 00:00+2Шёл 23-й год... в Асконе узнали про PCH...
Интересно когда будет порт на линукс, надеюсь не в Wine.
Очень интересно когда исправят масштабы интерфейсов для 4к, например библиотеки стандартных. На 4к экранах масштаб элементов очень мелкий.

kompas_3d Автор
00.00.0000 00:00Wine уже есть - смотрите предыдущие статьи.
Очень интересно когда исправят масштабы интерфейсов для 4к, например библиотеки стандартных. На 4к экранах масштаб элементов очень мелкий.
Исправим заменой библиотеки.
kompas_3d Автор
00.00.0000 00:00Шёл 23-й год... в Асконе узнали про PCH...
Возможно это не самая новая технология, но у нас довольно загруженные программисты - добиться от них статьи не так просто. Конкретно эту статью мы ждали больше года, может быть за это время технология стала уже широко известна, но для нас это не повод отказываться от публикации столь долгожданной статьи.
OMR_Kiruha
00.00.0000 00:00Спасибо за статью и благодарность за работу вашим программистам.
Но дизайнеров интерфейса надо покарать. Это был тихий ужас, переход с 16 на последующие версии, до 19 версии работать хотябы так же эффективно как в 16 было практически не возможно. Тому кто придумал неизменяемые панели инструментов нужно в прокрустово ложе физически лечь.
BadHandycap
Я может быть чего-то не понимаю, но при чём тут КОМПАС-3D?
kompas_3d Автор
Автор статьи разработчик КОМПАС-3D, в тексте про работу с исходниками КОМПАС-3D, этого разве не достаточно?)
BadHandycap
Спасибо, кэп. Я не настолько туп чтобы понять о чём речь в статье.
kompas_3d Автор
А чего же вам тогда не хватает?)
BadHandycap
Разве я сказал что мне чего-то не хватает?
kompas_3d Автор
Тогда я не понимаю для чего вы написали этот вопрос. Пытался вам на него ответить как мог.
BadHandycap
В статье описан процесс использования precompiled headers. При чём тут КОМПАС-3D мне совершенно непонятно. Данный подход не работает на любых других проектах? Только на КОМПАС-3D?
kompas_3d Автор
Если бы он не работал в других проектах, то для кого бы мы писали статью для хабра?) Очевидно, что он работает в любых больших проектах.