

Построить свою конвейерную ленту по разработке нейронок не так сложно. Нужен «всего лишь» сервер с GPU и настроенное окружение с библиотекой Diffusers. Если вам интересно, что это такое, как создать свою «Midjourney на коленке» и генерировать вайф в режиме 24/7, добро пожаловать под кат!
Знакомство с Diffusers
Diffusers — это библиотека от Hugging Face, которая позволяет работать с сотнями обученных Stable Diffusion-моделей для генерации изображений, аудио и даже объемных молекулярных структур. Ее можно использовать как для экспериментов с существующими моделями, так и для обучения своих.
Разработчики из Hugging Face утверждают, что их детище — простой модульный проект. И профессиональные знания об устройстве нейронных сетей и работе с тензорами не нужны. Это действительно так: для работы с Diffusers достаточно импортировать несколько пакетов и запустить пайплайн на полюбившейся модели. Последнее можно найти на Civitai

Галерея моделей на Civitai.
Раз все так просто, давайте поэкспериментируем c Diffusers.

Подготовка облачного окружения
Для нашего проекта локальная машина не подойдет: генерация одной картинки потребляет много виртуальных ресурсов и времени. Особенно в случае сервиса, с которым могут работать сразу несколько пользователей. Поэтому для работы нашего проекта понадобится виртуальный сервер с GPU и настроенным окружением.

Чтобы избежать ситуации как на картинке, развернем проект на Data Analytics Virtual Machine — виртуальном сервере с предустановленным набором инструментов для анализа данных и машинного обучения. А за основу возьмем конфигурацию с видеокартой Tesla T4.
- Переходим в раздел Облачная платформа внутри панели управления.
- Выбираем пул ru-7a и создаем облачный сервер с дистрибутивом Ubuntu LTS Data Analytics 64-bit и нужной конфигурацией.
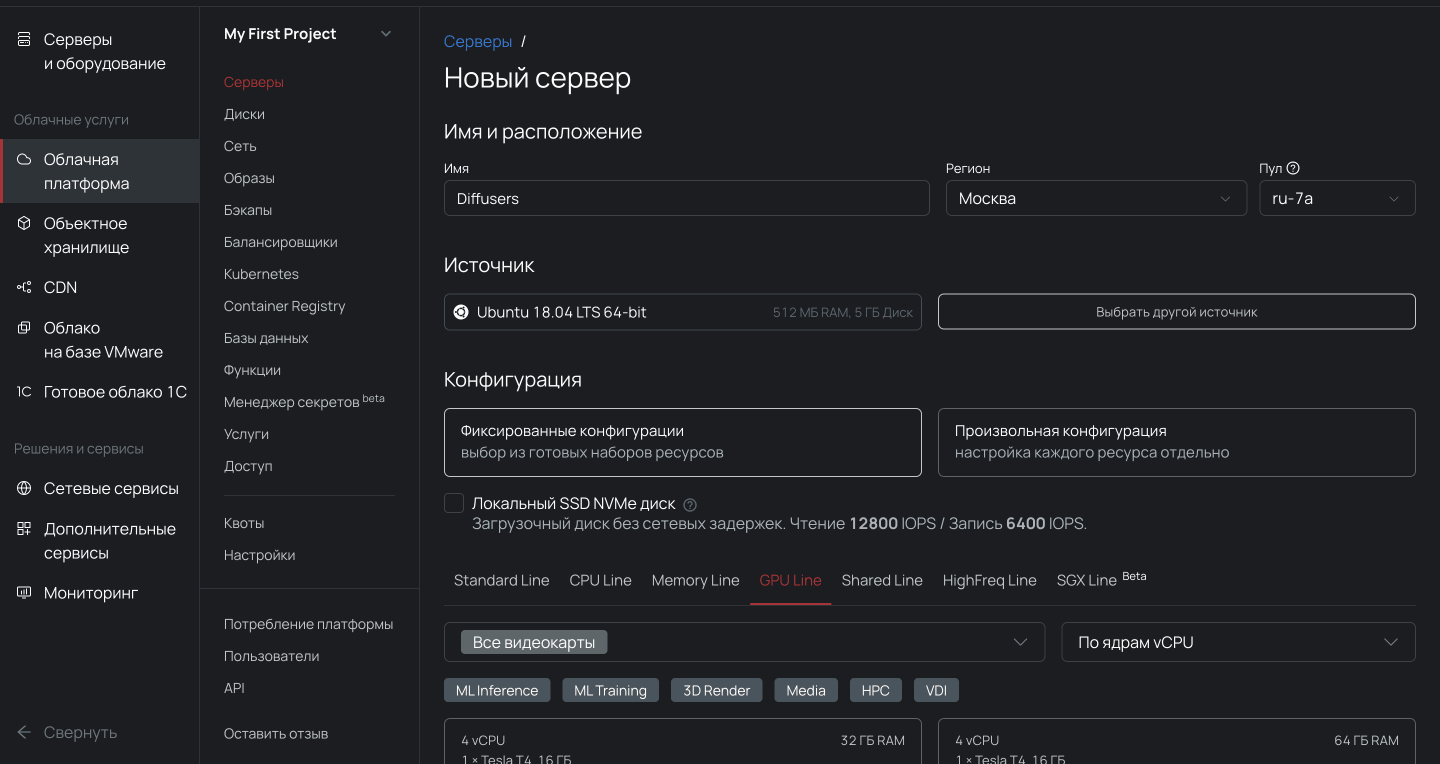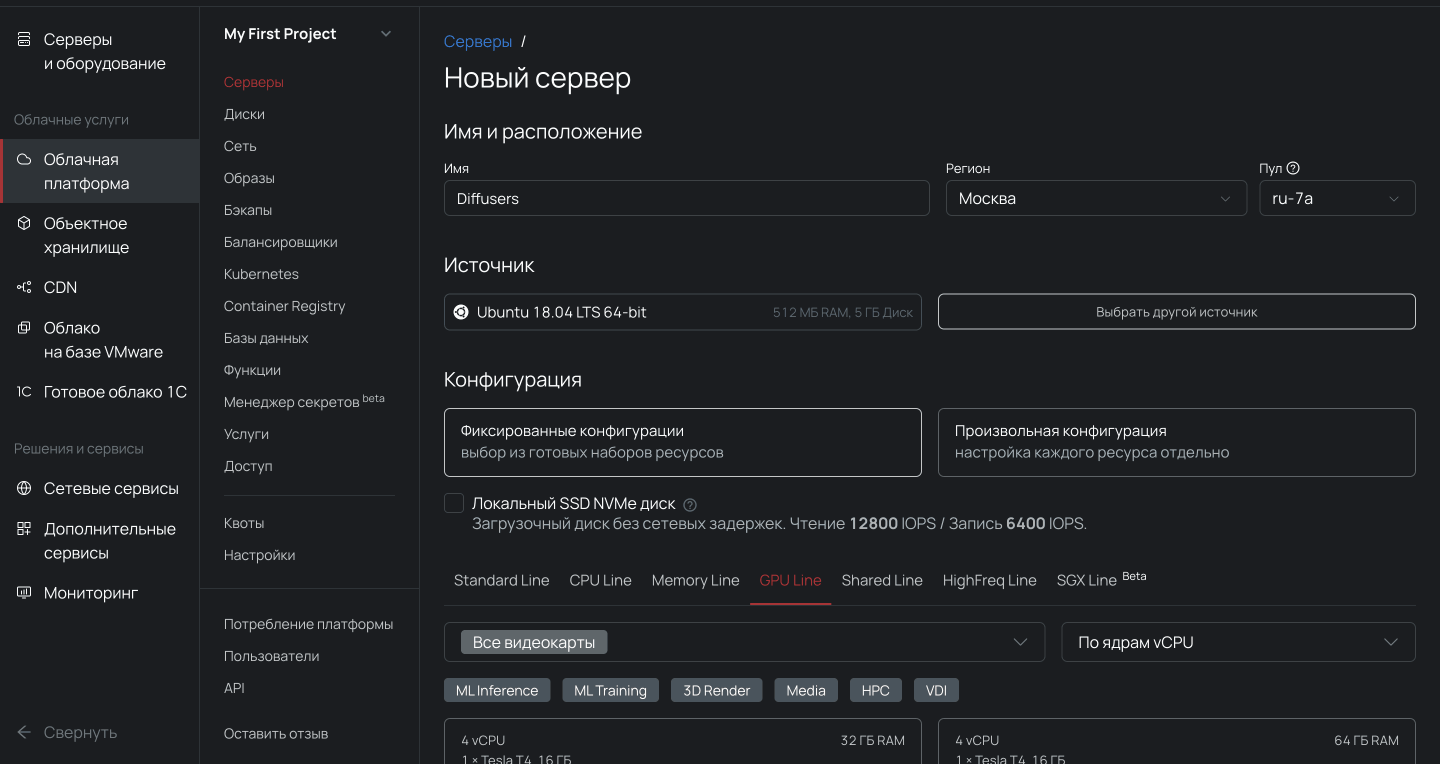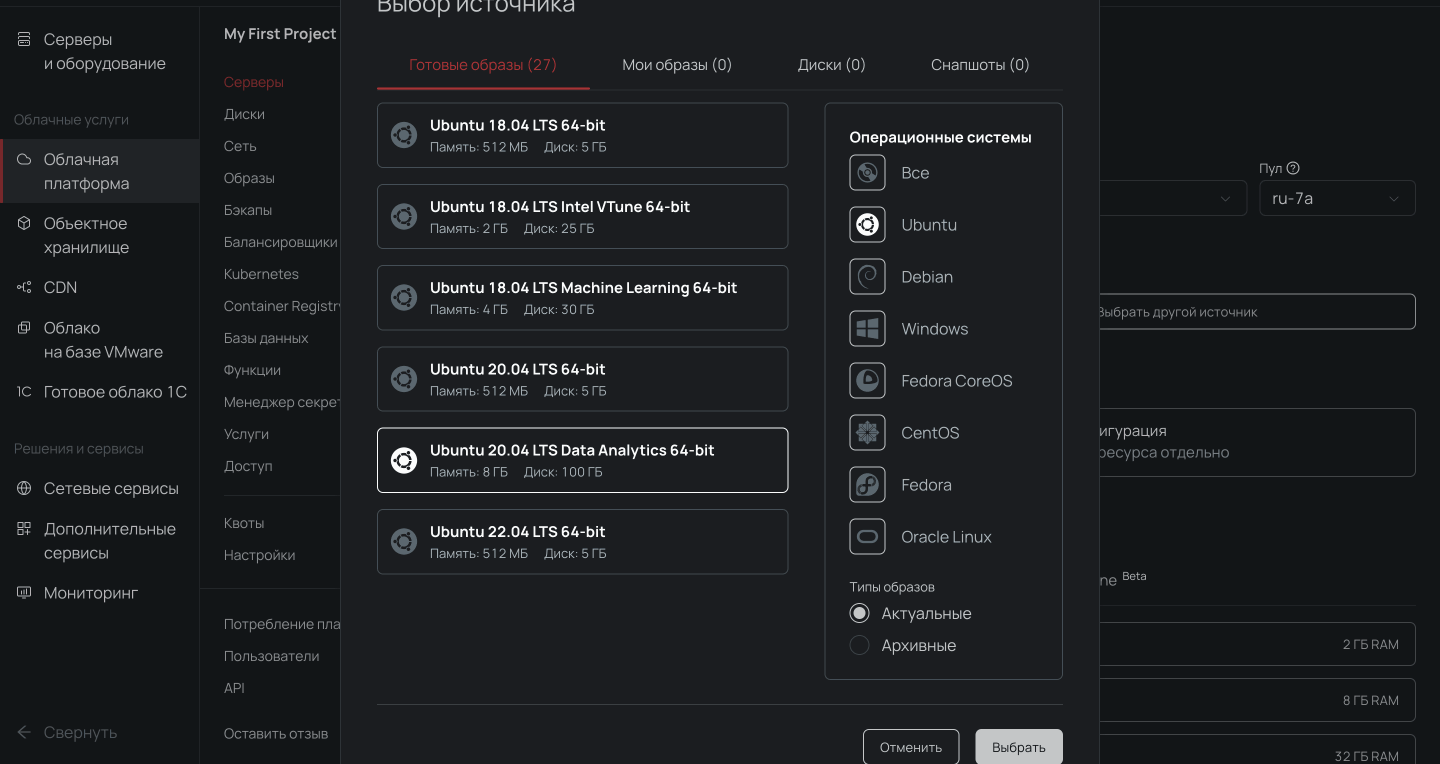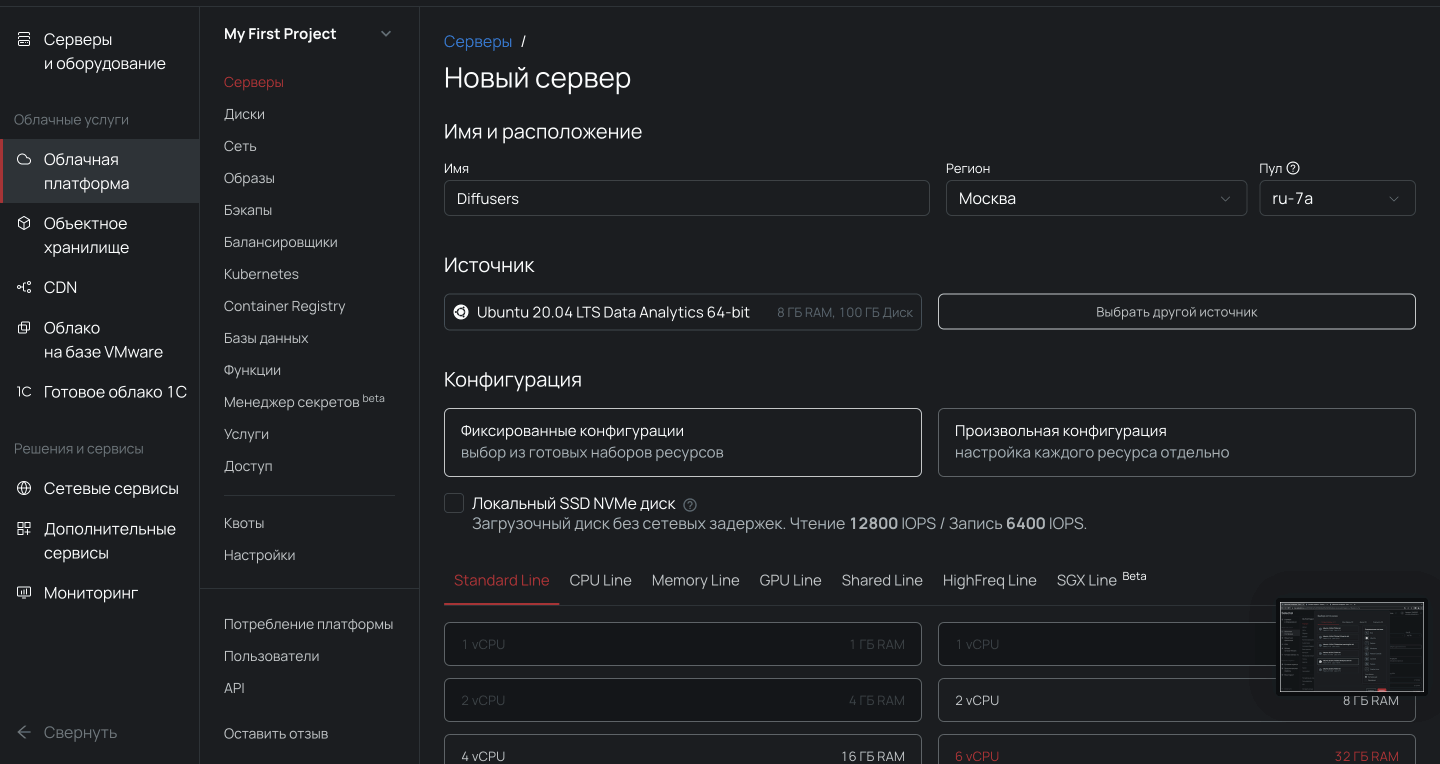
Выбор дистрибутива для Data Analytics Virtual Machine.
Важно, чтобы сервер был доступен «из интернета», иначе с компьютера не подключиться. Для этого во время настройки конфигураций выберите новый публичный IP-адрес.
Далее — запускаем сервер и настраиваем окружение.
Подключаемся к DAVM и разворачиваем Diffusers
Нужно дать системе пару минут на подгрузку всех Docker-образов. Потом, чтобы настроить окружение, нужно просто подключиться к серверу по SSH — тогда он покажет данные для авторизации в окружении DAVM.
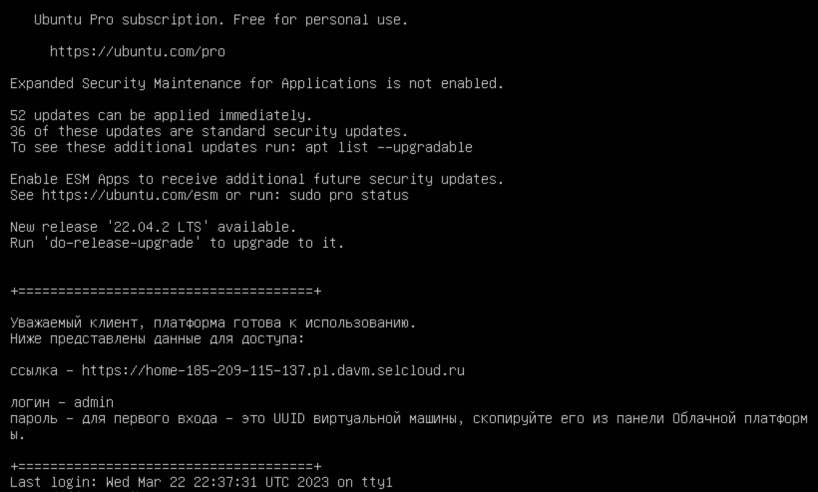
Данные для подключения к DAVM.
Теперь, если перейти по ссылке из сообщения и авторизоваться в DAVM, можно запустить Jupyter Lab, Keycloak, Prefect или Superset. Для нашего «Midjourney на коленке», понадобится только первое.

Список инструментов DAVM.
После перехода в Jupyter Lab нужно загрузить готовый notebook-шаблон для работы с Diffusers. Его можно взять в нашем GitHub-репозитории. Рассмотрим самые основные блоки.
Краткий обзор шаблона
Внутри шаблона есть несколько основных блоков — импорт нужных библиотек, загрузка модели для генерации изображений, настройка пайплайна и вывод «детища искусства».
На что стоит обратить внимание:
- model_id — переменная-ссылка на модель в Hugging Face, которую хотите использовать. Галерею каждой модели можно посмотреть на Civitai и в официальной библиотеке. Так, если хотите получить изображения в стиле Midjourney, — используйте prompthero/openjourney. Если нужна модель, заточенная под портреты, — darkstorm2150/Protogen_v2.2_Official_Release, а если под вайфы — hakurei/waifu-diffusion.
- pipe.to() — метод, с помощью которого можно выбрать, на каких ядрах запустить инференс модели. Если вы используете сервер с GPU, должно быть pipe.to(«cuda»), если только процессорные мощности — pipe.to(«cpu»).
pipe = pipe.to("cuda")
Мы проверили скорость генерации изображений через модель darkstorm2150/Protogen_v2.2_Official_Release — на CPU и CUDA-ядрах. На процессоре инференс занимает примерно в 20 раз больше времени.
Если вы не хотите использовать серверы с видеокартами, попробуйте оптимизировать инференс на CPU. О том, какие инструменты можно использовать, рассказали по ссылке.
- pipe() — это функция, которая отвечает за генерацию изображений. С помощью специальных аргументов ее можно конфигурировать — например, настраивать количество размеры изображений, число итераций в инференсе, сам prompt и другое. Не забывайте, что работаете со Stable Diffusion-моделями — желательно разбираться в основных параметрах.
images = pipe(
prompt = "A ultra detailed portrait of a sailor moon girl smiling, color digital painting, highly detailed, digital painting, artstation, intricate, sharp focus, warm lighting, attractive, high quality, masterpiece, award-winning art, art by Yoshitaka Amano, and Brian Froud, trending on artstation, trending on deviantart, Anime Key Visual, anime coloring, (anime screencap:1.2),(Graphic Novel),(style of anime:1.3), trending on CGSociety",
negative_prompt = "cut off, bad, boring background, simple background, More_than_two_legs, more_than_two_arms, (3d render), (blender model), (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), ((extra arms)), ((extra legs)), mutated hands, (fused fingers), (too many fingers), ((long neck)), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist's name",
height = 1024,
width = 512,
num_inference_steps = 100,
guidance_scale = 8.5, # попробуйте поменять этот параметр самостоятельно
num_images_per_prompt = 1
).images
Обратите внимание на negative prompt — для некоторых моделей это важный параметр, который позволяет исключить большую долю странных генераций. А иногда эта разница не так заметна.
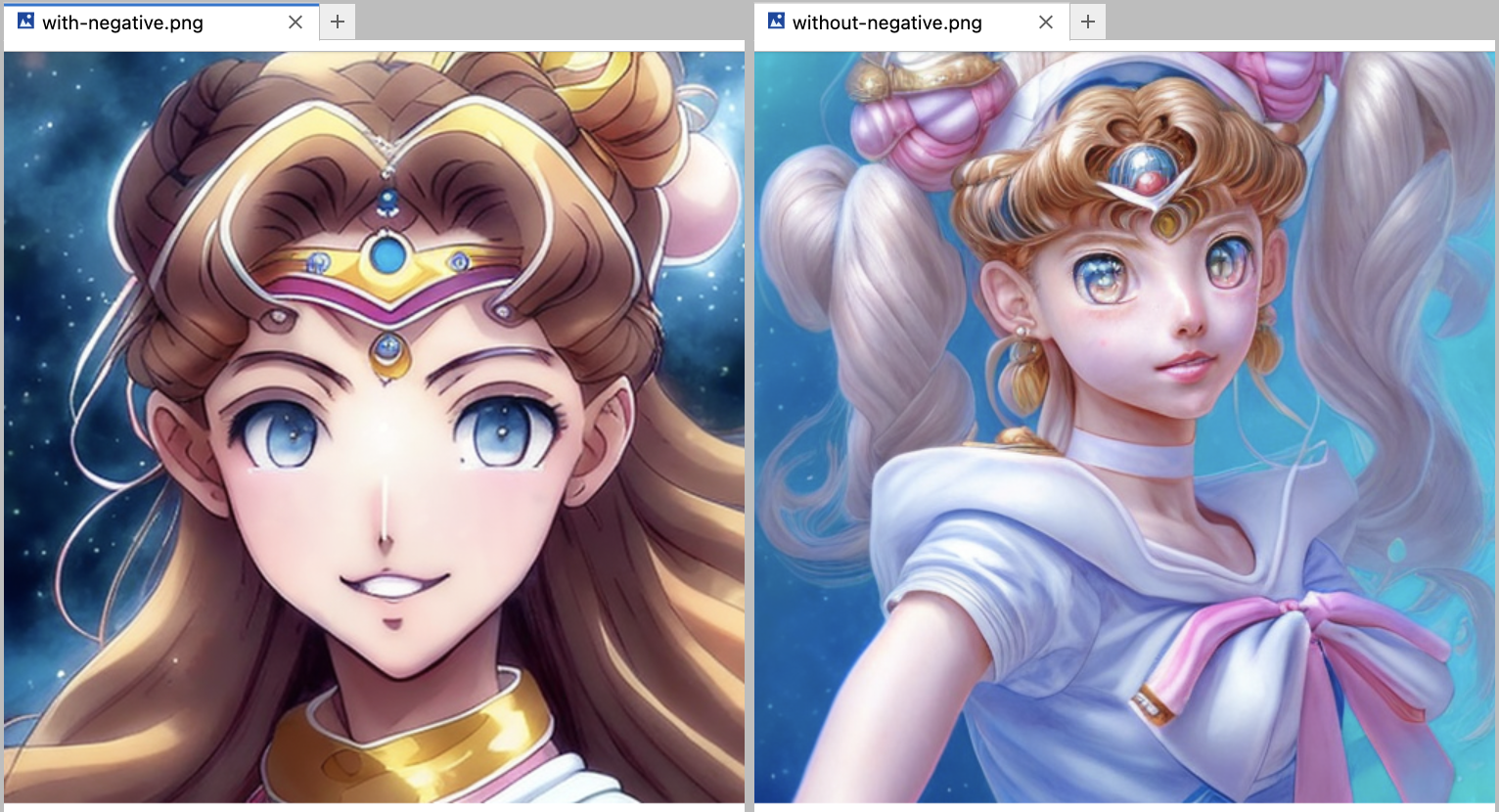
prompthero/openjourney, reference — шаблон в GitHub.
Что получилось
Отлично — теперь мы умеем подгружать модели Diffusers и генерировать собственные изображения.
Что крутого:
- Весь процесс от запуска сервера до генерации картинки занимает около 5 минут.
- Лимитов на количество генераций нет. Фактически, у нас готово окружение для тестирования моделей в режиме 24/7.


prompthero/openjourney
Используя дистрибутив DAVM, не нужно тратить время на поиск, установку и настройку необходимых драйверов, разрешение конфликтов. Сборка готова к работе прямо «из коробки».
Теперь можно поделиться доступом к проекту с друзьями и коллегами. Это бывает полезно, если нужно протестировать, например, собственную модель
Возможно, эти тексты тоже вас заинтересуют:
→ Решаем задачу по взаимодействию микросервисов на Python тремя способами
→ Альфа-тестирование MidJourney V5: научилась ли нейросеть рисовать руки и неоновых котиков
→ 5 полезных и просто занимательных проектов на Raspberry Pi начала весны 2023 года
Создание Telegram-бота

Попробуем набросать «базовый» Telegram-интерфейс для работы с нашей нейросетью. Здесь можно позаимствовать best practices и реализовать ту самую команду — /imagine. Большего на первых порах и не нужно.
Единственное, что можно добавить кроме /imagine — кнопки (или команды) для конфигурирования pipe(), чтобы настраивать геометрию изображений, guidance scale и другие параметры. Но имеет ли это смысл, если можно удобно настраивать модель в предустановленном Jupiter Lab? Нет — поэтому остановимся на простом варианте.
Обработчик команды /imagine
После того, как вы зарегистрировали Telegram-бота в @BotFather и импортировали telebot, можно написать простой обработчик команды /imagine на стандартном message_handler.
bot = telebot.TeleBot(key.secret)
# отслеживаем сообщения пользователя
@bot.message_handler(content_types=["text"])
def main(message):
user_id = message.chat.id
# смотрим, есть ли в сообщении prompt
user_prompt = re.findall('/imagine (.*?)', message.text)
if len(user_prompt) > 0: # если prompt есть, генерируем изображение
bot.send_message(user_id, "Подождите несколько секунд.", parse_mode='html')
# получаем путь до сгенерированного изображения
path = generate(user_id, user_prompt[0])
# отправляем картинку
with open(path, 'rb') as photo:
bot.send_photo(user_id, photo)
else:
# если prompt отсутствует, просим ввести его через команду /imagine
bot.send_message(user_id, "Введите запрос через команду <i>/imagine</i>", parse_mode='html')</i>
Функция для генерации изображений
Обработчик message_handler проверяет, есть ли в сообщении пользователя prompt. Если находит — отправляет его генератору изображений, который не только отрисовывает, но и сохраняет результат в директиве images.
def generate(user_id, user_prompt):
# генерируем изображение, отсекаем лишнее (negative_prompt)
images = pipe(
prompt = user_prompt,
negative_prompt = "cut off, bad, boring background, simple background, More_than_two_legs, more_than_two_arms, (3d render), (blender model), (fat), ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), ((extra arms)), ((extra legs)), mutated hands, (fused fingers), (too many fingers), ((long neck)), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist's name",
height = 512,
width = 512,
num_inference_steps = 100,
guidance_scale = 8.5,
num_images_per_prompt = 1
).images
# прописываем директиву для сохранения, изображение обзываем пользовательским идентификатором
user_image_path = f"./images/{user_id}.png"
# удаляем прошлые изображения того же пользователя
if os.path.exists(user_image_path):
os.remove(user_image_path)
# сохраняем изображение и возвращаем до него путь в функцию main
try:
images[0].save(user_image_path)
display(images[0])
return user_image_path
# если сохранить изображение не удалось, показываем грустный смайлик (error.png)
except:
bot.send_message(user_id, "Произошла ошибка, попробуйте позже.", parse_mode='html')
return "./images/error.png"
Готово — Telegram-бот работает, через него можно тестировать модели из библиотеки Diffusers. Даже с учетом того, что сейчас генерация не асинхронна и есть «строгая очередь» из пользовательских запросов, несколько человек могут работать с ботом спокойно.

Даже с учетом дополнительного функционала в виде Telegram-бота, процесс развертывания «Midjourney на коленке» занял около часа. Основные сложности возникают только с подбором моделей, их параметризацией и составлением prompt-запросов. Но разве не это делает процесс интересным?
Подключайтесь к нашему репозиторию на GitHub, делайте «форк» и используйте его в качестве референса, если хотите поднять собственный проект. А также делитесь мнением и предлагайте свои улучшения в комментариях.
Комментарии (9)

JPEGEC
00.00.0000 00:00Неинтересно.
Понятно что вся суть поста "покупайте наших слонов", но откровенно говоря под словами "как развернуть нейросеть" ожидались действия по разворачиванию оной а не по запуску готового дистрибутива.

Doctor_IT Автор
00.00.0000 00:00Так, чтобы развернуть нейросеть, нужна библиотека Diffusers — о ней и говорится в тексте)
Вы можете обойтись и без дистрибутива DAVM, без Jupyter Lab или Notebook. Дистрибутив лишь упрощает установку необходимых инструментов в облаке, а Jupyter — прототипирование и тестирование моделей.

7313
00.00.0000 00:00+2Минутточку.. А при чем тут вообще Midjourney-то? Только схожестью названия довольно "так себе" модели openjourney, которая все равно Stable Diffusion и к Midjourney не относится вообще никаким боком? И вообще чем это в принципе отличается от установки в облако какого-нибудь стандартного AUTOMATIC1111, у которого меньше системные требования и заведомо больше возможностей, хотя бы в сторону поддержки нативными плагинами ControlNet с разнообразными Posex?

NeoCode
00.00.0000 00:00Когда речь идет о чем-бы то ни было облачном, нужно сразу писать платно это или бесплатно. Если платно - то сколько стоит, если бесплатно - то как зарегистрироваться, нужны ли иностранные номера и VPN и т.п.
Doctor_IT Автор
00.00.0000 00:00Добрый день. Все зависит от задачи и потребностей)
Например, если вы работаете над каким-то научным проектом, или просто нужно генерировать много изображений, предпочтительней будут конфигурации с видеокартами. Если время генерации неважно и вы готовы тратить, в среднем, полчаса на одну картинку, будет достаточно конфигурации без GPU. В остальном выбор конкретной конфиги можно сделать по такой мапе:

Подробнее рассказали в отдельной статье Также стоимость конкретной конфигурации зависит от типа виртуальной машины. Например, прерываемые серверы дешевле непрерываемых. Здесь уже стоит вопрос, важна ли вам, чтобы сервер работал в режиме 24/7.


firnind
00.00.0000 00:00+2Ну и самый главный вопрос, ответ на который все хотят знать, но стесняются спросить: можно ли таким образом генерировать «пикантные» изображения?
Doctor_IT Автор
00.00.0000 00:00+1Да, главное отключить классификатор NSFW.
Вот, как это сделать: https://www.reddit.com/r/StableDiffusion/comments/wv28i1/how_do_we_disable_the_nsfw_classifier/
MountainGoat
Я всё хочу попробовать, но всё некогда: существует модификация xformers, использующая OpenVINO. Что по смыслу означает, что её можно запускать на разных нейронных сопроцессорах от Intel, которые дешевле видеокарт.
Doctor_IT Автор
Интересная тема! В статье уже про это говорил, но мы пробовали запускать модельки на torch с помощью transformers в режиме cpu-only, и получили замедление примерно в 20 раз. Осмелюсь предположить, что на xformers промедления будут примерно в 13 раз, попробуйте)