
Во время работы с различными проектами, будь то небольшой блог или огромная web-платформа, неизбежно возникает необходимость хранить и организовывать большие объемы данных. Базы данных являются ключевым элементом в этом процессе, и позволяют легко хранить и быстро получать доступ к необходимой информации. Однако, для начинающих свой путь в айти тема база данных может оказаться сложным и даже запутанным заданием.
В первый раз столкнувшись с термином "база данных", многим это может показаться непонятным и сложным. Я тоже помню свой первый опыт работы с базами данных, но с опытом понял, что их использование не только несложно, но и облегчает многие задачи в работе с информацией. Давайте вместе разберемся, что такое базы данных и зачем они нужны.
Начнем с нулевого уровня: что такое база данных?
Google определяет базу данных как “структурированный набор данных, хранящийся в компьютере, доступный разными способами”. В своей основе база данных - это всего лишь способ хранения и организации информации. Желательно, чтобы она была организована таким образом, чтобы ее можно было легко получать, управлять и обновлять.
Мне нравятся метафоры, и простой пример базы данных для меня похож на книжный магазин. Допустим, вы владелец книжного магазина. Вам нужна система управления инвентаризацией, чтобы вы знали, какие книги точно есть на складе, сколько их стоит и где они находятся. Вы можете организовать свой магазин, как ящик для инструментов - все книги на своих полках и будут отсортированы по жанрам и авторам. Однако, это не идеальная система. Если вы продаете большой объем книг и имеете несколько магазинов, может быть сложно отслеживать, какую книгу и где продали. Вместо этого вы можете использовать базу данных, в которой каждая книга хранится как запись. Каждая запись может содержать информацию о названии книги, авторе, жанре, доступности, цене и других характеристиках. Это дает вам возможность искать книги по разным параметрам, просматривать свою инвентаризацию в режиме реального времени и узнавать, какие книги на данный момент проданы и где они находятся. Вы можете также использовать эту информацию для управления своими продажами, определения, какие книги труднее всего продавать, оценки популярных жанров и авторов и т. д.

Этот пример надуманный, но раскрывает некоторые проблемы, которые вы должны учитывать при выборе базы данных или способах хранения ваших данных в ней.
Терминология
Если вы начнете направленно гуглить “базы данных” (как я сделал), вы скоро поймете, что существует несколько различных типов баз данных и множество терминологии, связанной с ними. Давайте попробуем разобраться с возможными языковыми барьерами:
Запрос - это единственное действие, выполняемое с базой данных, запрос, представленный в предопределенном формате. Наиболее часто используются команды SELECT, INSERT, UPDATE или DELETE.
Мы также используем "запрос" для описания запроса от пользователя на получение информации из базы данных. «Книжный магазин, мне нужны от тебя книги в жанре фантастики!", может выглядеть что-то вроде:
SELECT genre FROM bookshop
where genre = 'fantastic'Транзакция - это последовательность операций (запросов), составляющих единицу работы, выполненную в отношении базы данных. Например, когда Андрей платит Алисе 300 рублей, это транзакция, состоящая из двух операций UPDATE: уменьшение баланса Андрея на 300 рублей и увеличение баланса Алисы.
-
ACID: Атомарность, Согласованность, Изоляция, Устойчивость. В большинстве популярных баз данных транзакция считается транзакцией только в том случае, если она обладает четырьмя "ACID" свойствами:
Атомарность: Каждая транзакция - это уникальная единица работы. Если одна операция не выполнена, данные остаются неизменными. Это "все или ничего". Андрей никогда не потеряет 300 рублей если, Алиса не получит оплату.
Согласованность: Все данные, записанные в базу данных, подвергаются созданным правилам. После завершения транзакции все данные должны находиться в согласованном состоянии.
Изоляция: Изменения, внесенные в рамках транзакции, не видны другим транзакциям до их завершения.
Устойчивость: Изменения, завершенные в рамках транзакции, хранятся и доступны в базе данных, даже в случае сбоя системы.
Схема базы данных - это "скелет" или структура базы данных, логический чертеж ее построения и того, как связаны между собой элементы (с таблицами / отношениями, индексами и т.д.).

-
Некоторые схемы статичны (определены до написания программы), а некоторые динамичны (определены программой или самими данными).
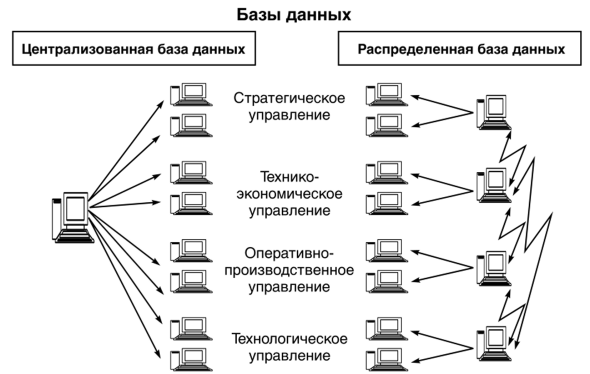
Распределенные БД и Централизованные БД
Как следует из их названий, централизованная база данных имеет только один файл базы данных, который хранится в одном месте на данной сети, а распределенная база данных состоит из множества файлов базы данных, хранящихся в нескольких физических местах, все они контролируются центральной системой управления базами данных.
Распределенные базы данных более сложны и требуют дополнительной работы для поддержания актуальности хранящихся данных и предотвращения дублирования. Однако они обеспечивают параллелизм (что балансирует нагрузку между несколькими серверами), предотвращая узкие места при большом количестве запросов.
Централизованные базы данных обеспечивают более простое поддержание целостности данных; после хранения данных более не доступны устаревшие или неточные данные (устаревшие данные) в других местах. Однако в централизованной базе данных может быть сложнее получить потерянные или перезаписанные данные, поскольку доступные копии отсутствуют по своей природе.
-
Масштабируемость - это способность базы данных обрабатывать все большее количество данных. Существуют два типа масштабирования:
Вертикальное масштабирование Практически каждая база данных вертикально масштабируема.
Вертикальная масштабируемость в базах данных (БД) означает увеличение ресурсов (например, добавление процессоров, оперативной памяти) на одном сервере для улучшения его производительности и обработки большего объема данных. Это означает, что более мощный и производительный сервер заменяет предыдущий сервер.
Однако у вертикальной масштабируемости есть свои ограничения, поскольку ее производительность ограничена только мощностью одного физического сервера. Если мощности сервера оказывается недостаточно, то необходимо увеличивать вертикальную масштабируемость, то есть расширять ресурсы на более мощный сервер, что может быть достаточно дорогостоящей опцией.
Горизонтальное масштабирование означает добавление емкости путем добавления еще нескольких машин. Система управления базами данных должна быть способной разделить, управлять и поддерживать данные на всех машинах.

Реляционные (SQL) базы данных
В реляционной базе данных каждое отношение представляет собой набор кортежей. Каждый кортеж является списком атрибутов, представляющих отдельный элемент в базе данных. Каждый кортеж («строка») в отношении («таблице») имеет общие атрибуты («столбцы»). Каждый атрибут имеет определенный заранее тип данных (int, string и т.д.). Схема в реляционной базе данных является статической.
Примеры включают Oracle, MySQL, SQLite, PostgreSQL
SQL: Структурированный язык запросов
SQL - язык программирования, основанный на реляционной алгебре, используемый для манипулирования и извлечения данных в реляционной базе данных. Примечание: в предыдущем пункте я намеренно разделил терминологию реляционных баз данных (отношение, кортеж, атрибут) от терминологии SQL (таблица, строка, столбец), чтобы обеспечить ясность и точность.
Мы можем хранить все данные блога в реляционной базе данных. Одно отношение представляет наши сообщения в блоге, каждое из которых будет иметь атрибуты «заголовок» и «содержание сообщения», а также уникальный «ID сообщения» (первичный ключ). Другое отношение может хранить все комментарии на блоге. Каждый элемент здесь также имеет атрибуты, такие как «имя автора комментария», «содержание комментария» и «ID комментария» (опять же, первичный ключ), а также собственный «ID сообщения». Этот атрибут представляет собой внешний ключ и говорит нам, к какому блогу относится каждый комментарий. Когда мы хотим открыть веб-страницу для сообщения #2, например, мы можем сказать базе данных: «выбрать все из таблицы« сообщения », где ID сообщения равен 2», а затем «выбрать все из таблицы комментариев, где 'post_id' равно 2.»
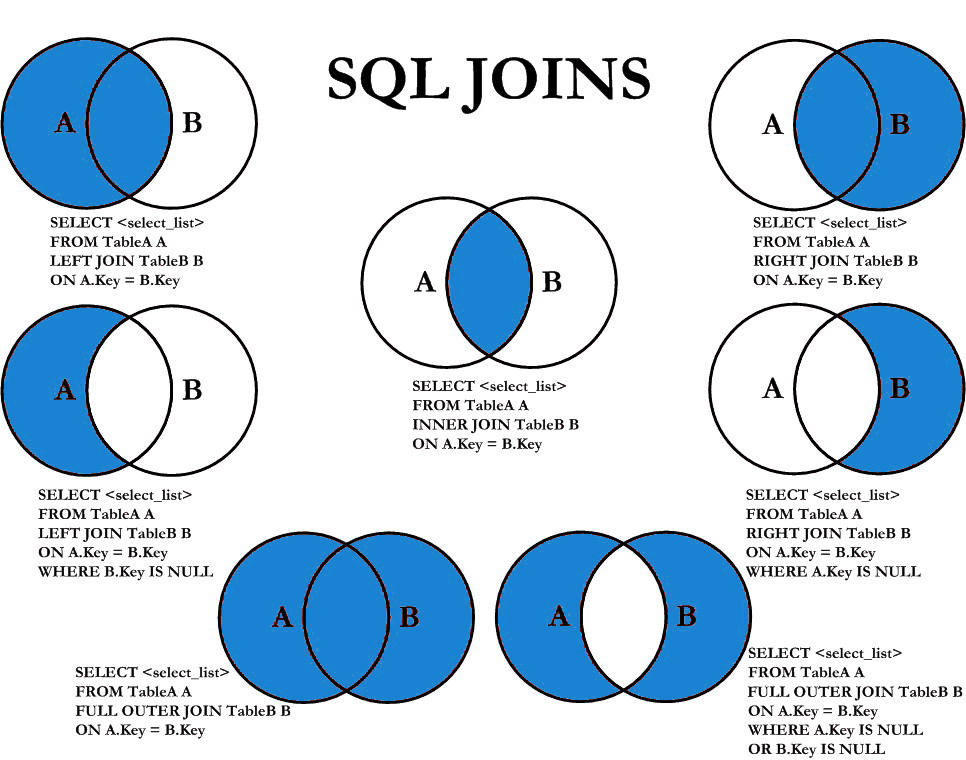
Операции JOIN
Операция JOIN объединяет строки из нескольких таблиц в одном запросе. Существуют несколько типов соединений и причин их использования.
Эти операции обычно используются только с реляционными базами данных, поэтому они часто упоминаются при описании функциональности "реляционных" баз данных.
Нормализация и денормализация
Нормализация - это процесс организации соотношений и атрибутов реляционной базы данных таким образом, чтобы уменьшить избыточность и улучшить целостность данных (то есть точность, последовательность и актуальность данных). Данные могут быть организованы на основе зависимостей между атрибутами, например - мы можем предотвратить повторение информации, используя операции JOIN.
Денормализация, в свою очередь, представляет собой процесс добавления избыточных данных для ускорения сложных запросов. Мы можем включить данные из одной таблицы в другую, чтобы убрать вторую таблицу и уменьшить количество операций JOIN. ORM: Сопоставление объектов-отношений ORM - это техника перевода логического представления объектов (как в объектно-ориентированном программировании) в более атомизированную форму, которая может храниться в реляционной базе данных (и обратно, когда они извлекаются). Здесь я не буду давать более подробных объяснений, но хорошо знать, что это существует.
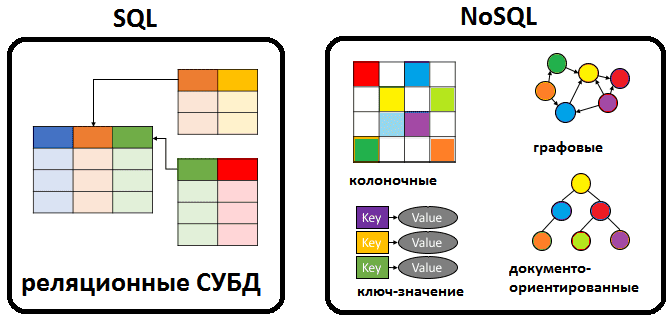
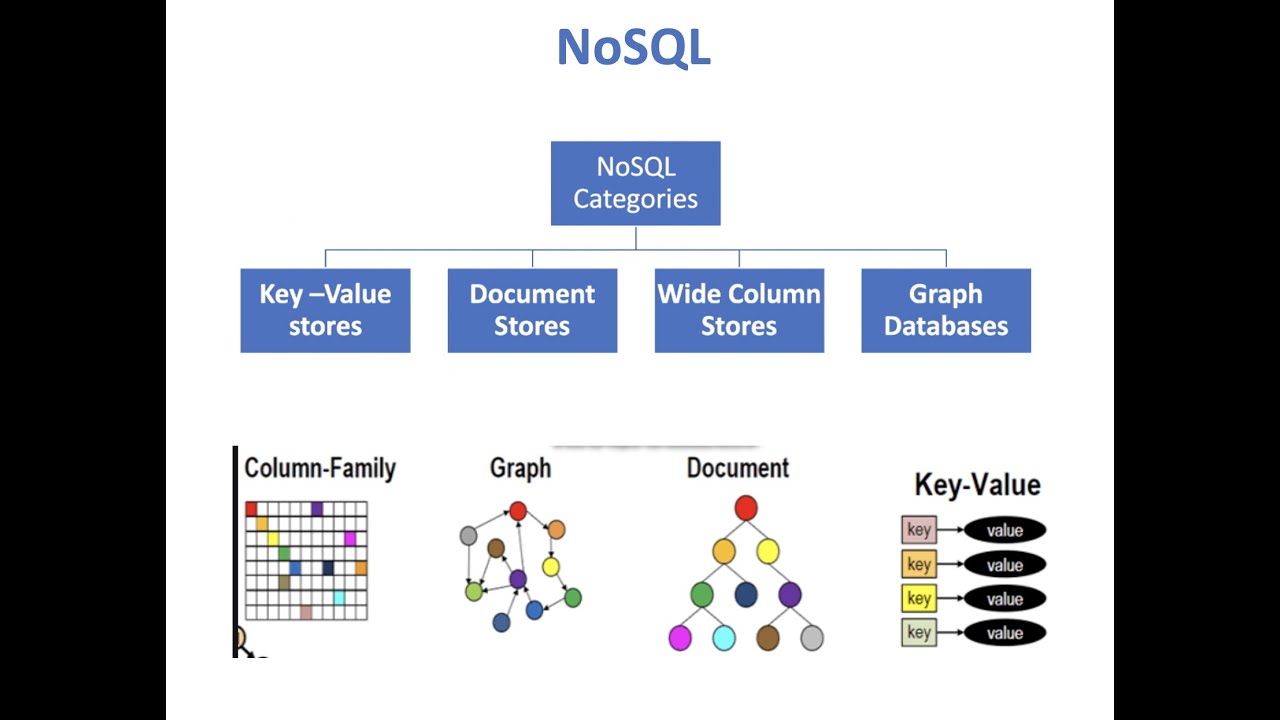
Нереляционные базы данных
Проще всего сказать, что нереляционная база данных - это база данных, которая не использует реляционную модель; нет отношений (таблиц) с кортежами (строками) и атрибутами (столбцами). Это понятие охватывает довольно широкий спектр моделей, обычно объединяемых в четыре категории: хранилища ключ-значение, графовые хранилища, столбцовые хранилища и хранилища документов.
Пример:
Мы можем сравнить это с организацией нашего гардероба. Вместо того, чтобы размещать одежду по категориям в одном ящике или шкафу, мы можем использовать нереляционную модель и разместить элементы в разных местах, связывая их между собой по необходимости. Например, если мы хотим выбрать майку и шорты для нашего нового тренировочного костюма, мы можем просто запросить все элементы, связанные с тегом "тренировка", вне зависимости от того, где они хранятся.
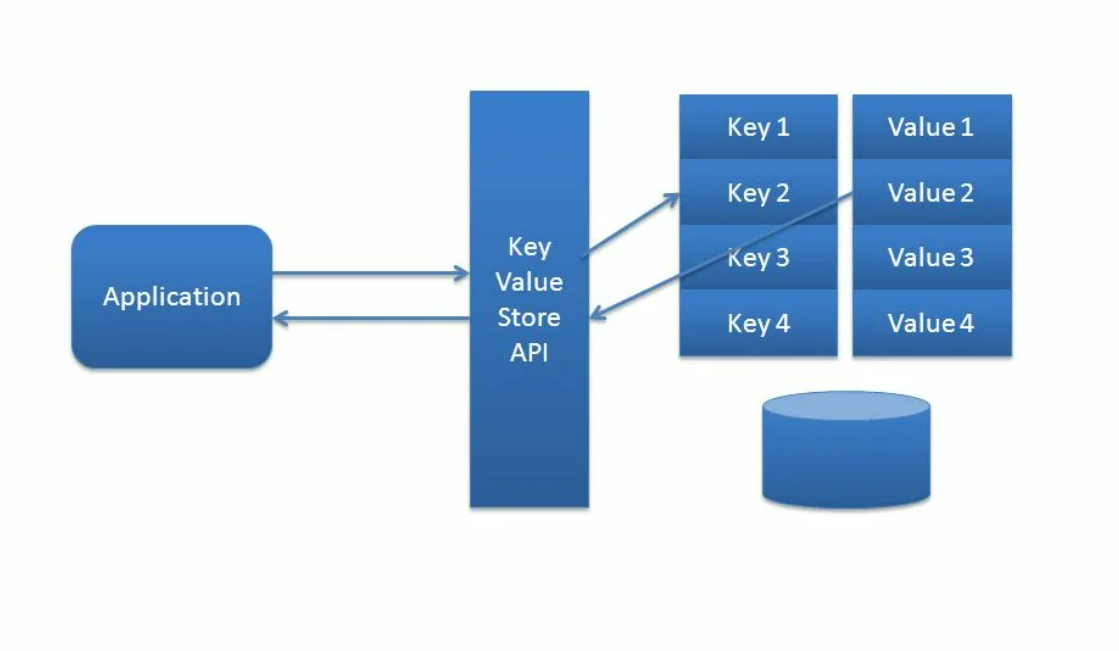
Key-Value Store
Хранилища ключей-значений не используют заранее определенную структуру реляционных баз данных, а вместо этого рассматривают все свои данные как единый набор элементов.
-
Основной принцип этой модели заключается в ее простоте. Как карта или словарь, каждая пара ключ-значение определяет связь между некоторым уникальным «ключом» (например, именем, идентификатором или URL) и его «значением» (изображение, файл, строка, int, список и т.д.). Здесь нет полей, поэтому вся информация должна быть обновлена, если вносятся изменения. Хранилища ключей-значений, как правило, быстрые, масштабируемые и гибкие.
Примеры включают: Dynamo, MemcacheDB, Redis
Graph Store
Хранилища графов немного более сложные. Используя структуры графов, этот тип базы данных предназначен для работы с взаимосвязанными данными - подумайте о социальных медиа-связях, семейном древе или пищевой цепочке. Элементы в базе данных представлены «узлами», а «ребра» напрямую представляют отношения между ними. Каждый узел и ребро могут хранить дополнительные «свойства»: идентификатор, имя, тип и т. д.

Column Store
Реляционные базы данных, ориентированные на строки, описывают отдельные элементы в виде строк и хранят все данные строки конкретной таблицы вместе: "пельмень_01", "средний", "синий"; "пельмень_02", "большой", "вкусный". Сохранение столбцов, в свою очередь, обычно хранит все значения конкретного столбца вместе: "пельмень_01", "пельмень_02"; "средний", "большой"; "синий", "вкусный".
Это может стать достаточно запутанным, но два подхода очень различаются. В системе, ориентированной на строки, основным ключом является идентификатор строки, отображенный на ее данные. В системе, ориентированной на столбцы, основным ключом является данные, отображающие обратно на идентификаторы строк. Это позволяет выполнять очень быстрые агрегации, такие как итоги и средние значения.
Примеры включают: Accumulo, Cassandra, HBase.
Хранилище документов
Хранилища документов рассматривают всю информацию для конкретного элемента в базе данных, как единую запись в базе данных (каждая из которых может иметь собственную структуру и атрибуты, подобно другим нереляционным базам данных). Эти "документы" обычно могут быть представлены в виде наборов пар ключ-значение: {Наименование инструмента: «молоток_01», Размер: «средний», Цвет: «синий»}
Документы могут быть независимыми единицами, что улучшает производительность и горизонтальную масштабируемость, а неструктурированные данные могут быть легко сохранены.
Примеры включают: Apache CouchDB, MongoDB, Azure DocumentDB.
Объектные или объектно-ориентированные базы данных
Не так распространены, как другие нереляционные базы данных, объектная или объектно-ориентированная база данных представляет данные в форме "объектов" (с атрибутами и методами), используемых в объектно-ориентированном программировании. Этот тип может использоваться вместо реляционной базы данных и ORM и может быть целесообразен, когда данные сложны или имеются сложные соотношения многие-ко-многим. Однако они зависят от языка и могут вызывать трудности при запросах.
Разработка баз данных может быть сложной и трудоемкой задачей даже для профессионалов.
Хочу еще раз подчеркнуть, что для успешной разработки любого проекта или приложения, в котором используются данные, необходимо обладать знаниями и опытом работы с базами данных. Безудержный рост объемов данных в наше время делает их хранение, организацию и анализ намного сложнее, и базы данных становятся все важнее и необходимее. Поэтому настоятельно рекомендую всем разработчикам уделить особое внимание освоению баз данных, что позволит им создавать более сложные, но и более функциональные проекты в будущем.
Спасибо за внимание и удачи в разработке!
Комментарии (3)

PuerteMuerte
04.04.2023 21:36+1Сначала так по-доброму начал тему раскручивать, с книжного магазина, а потом бац! И сразу с козырей зашёл:
В реляционной базе данных каждое отношение представляет собой набор кортежей.

ZoomLS
04.04.2023 21:36Начало же было хорошее, даже простой пример SELECT запроса есть, дальше я ожидал его разбора, ещё кода. Туториал это или нет? Но, нет. Дальше пошла теория про базы данных, какие они бывают и т.д. Это новички всё могут сами легко найти, та же википедия. Если это первая часть, тогда ок.

kurozetsu
04.04.2023 21:36Очень полезная и информативная статья, все никак не мог начать копаться в этой теме, спасибо)
Myclass
Так как вам нравятся метафоры, то одной строчкой из Бородино хочеться дать свою оценку этой статье - "Смешались в кучу кони, люди, …"
Для новичков - не понятно ничего, просто набор несвязных между собой тем. Про знающих - я вообще промолчу.