
В докладе я препарирую Istio, дабы понять, как он работает, какие у него подводные камни и как им правильно пользоваться.
Это мой второй доклад про Istio и Service Mesh. Первый я сделал на конференции Kuber Conf 2021: «Что ждать от внедрения Istio?». Рекомендую ознакомиться сначала с ним, будет несколько проще.

Видеоверсию доклада можно посмотреть на YouTube (~50 минут). Ниже — основная выжимка из него в текстовом виде.
Что такое Service Mesh
С помощью Service Mesh можно реализовать разные паттерны по управлению TCP-трафиком в проекте. Настраиваются они через декларативный язык с помощью API Kubernetes. Бонусом мы получаем расширенные возможности по наблюдаемости за проектом. Более ёмко определение термина я раскрыл в предыдущем докладе.

Какие вызовы стоят перед вами, если вы решили внедрять Istio? Главных — два:
Надежность приложения. Как Istio повлияет на latency и надежность компонентов ПО? Что будет, когда проект вырастет? И прочее.
Сложность Istio. Всякий, кто сталкивался с Istio, знает, что это сложная штука. Одних только интерфейсов, которые предоставляет Istio, наберется с десяток. А к документации есть много вопросов.
Мой доклад даёт необходимые знания о том, что ждать от Istio, к чему готовиться и как действовать в тех или иных ситуациях. Ну и самое главное: как им правильно пользоваться.
Базовые принципы работы Istio
Рассмотрим типовой веб-проект, который работает в Kubernetes. Каждый компонент — фронтенд, бэкенд и база данных — живут каждый в своём Поде:

Мы решили внедрить Istio. Что произойдет с нашим кластером:
там появится контроллер istiod, который в мире Istio называется Control Plane;
каждому Поду в нагрузку выдадут сайдкар (sidecar), который обрабатывает пользовательские запросы, — весь массив сайдкаров называется Data Plane.
Нам же остается настраивать сетевые паттерны через API Kubernetes. Control Plane эти паттерны переваривает и рассылает по сайдкарам инструкции.

Примерно так выглядит типичный Service Mesh, в частности Istio. И с этой схемой мы будем разбираться в подробностях.
Как работает Istio на уровне Pod
Заглянем внутрь сайдкара и обнаружим там Envoy:
Без понимания его философии и базовых принципов изучение Istio невозможно.
Envoy — типичный универсальный прокси-сервер. Он принимает на вход TCP- и HTTP-запросы, переваривает их и отправляет наружу. Смысл в том, что Envoy даёт нам интерфейс для управления процессом обработки этого запроса. Этот интерфейс называется envoy API:
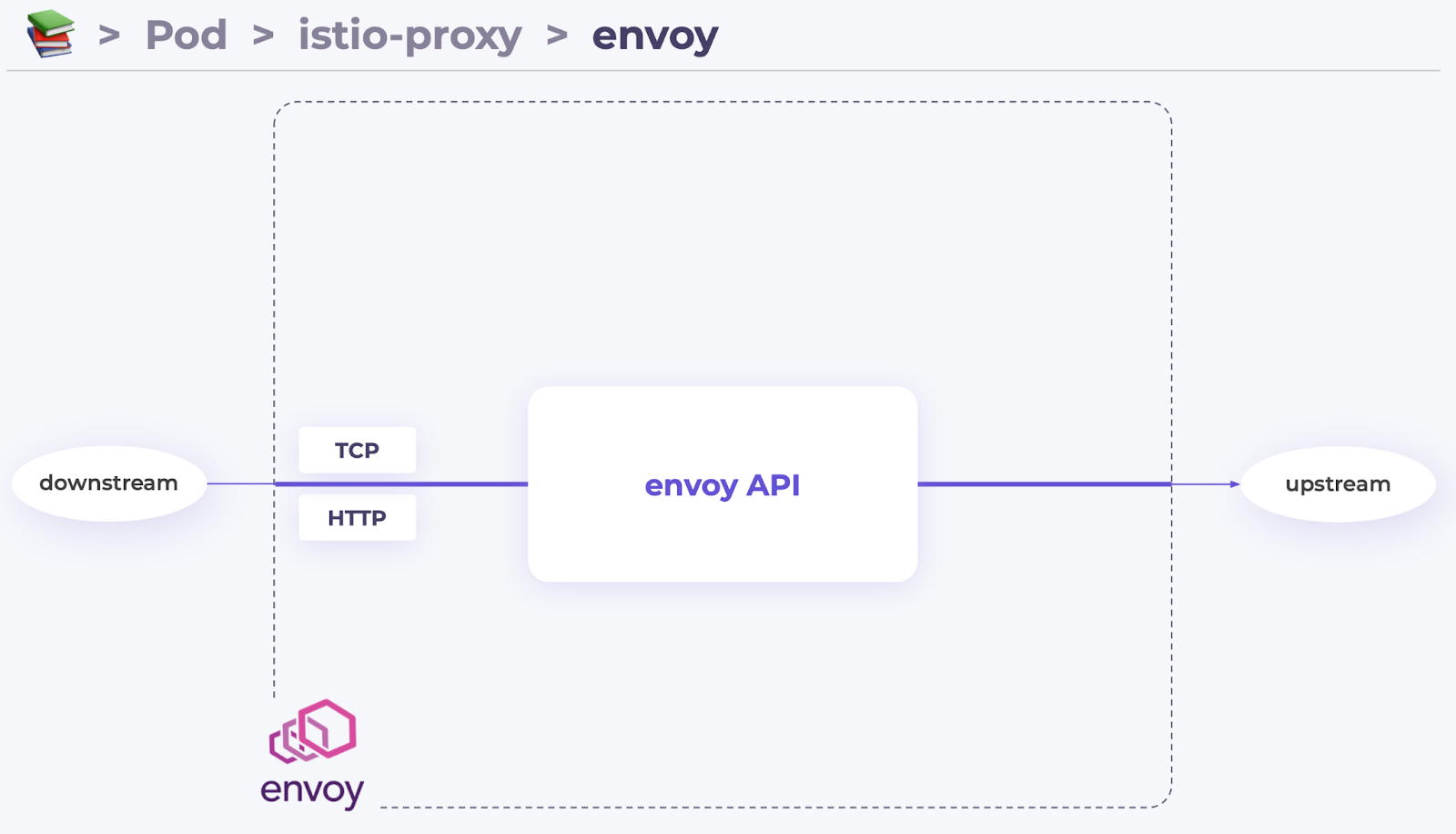
Envoy API — очень гибкая структура, которая хорошо задокументирована. Мы не полезем в дебри, а лишь познакомимся с базовыми понятиями и примитивами.
Всё начинается с примитива listener. Сначала кажется, что это некая инструкция, которая заставляет Envoy слушать портик. Но на самом деле всё гораздо сложнее: listener — это целый конвейер по обработке входящего запроса. Он содержит цепочку фильтров, которые
валидируют TLS;
калькулируют метрики для экспорта в Prometheus;
обеспечивают авторизацию запросов;
и так далее.

Этот конвейер может состоять из сколь угодно большого количества фильтров, которые могут идти в любом порядке. Но как правило вся цепочка listener'а заканчивается фильтром route.
А само решение, куда именно полетит запрос, основывается на другом фундаментальном понятии Envoy — cluster. (Я терпеть не могу этот термин: с ним связано очень много коллизий. Но имеем, что имеем.)

Cluster содержит исчерпывающую информацию о сервисе, к которому полетит запрос:
список эндпоинтов с IP-адресами и портами;
правила балансировки между IP-адресами;
сертификаты для установки TLS-соединения;
правила для калькуляции метрик.
И вот примерно по такому пути проходит запрос в Envoy:

Вернемся к нашему сайдкару. Что мы еще о нем знаем? Знаем, что сайдкар перехватывает прикладные запросы и отправляет их дальше. Возникают вопросы:
Каким образом он перехватывает запрос?
В чьих интересах он обрабатывает эти запросы? Где берёт инструкции?
Давайте разбираться.
В случае с перехватом трафика всё просто: в каждом Поде, который работает под управлением Istio, настроен обычный DNAT. Весь DNAT исходящего трафика направляется на порт 15001 listener'а:

Таким образом, Envoy получает трафик, чтобы потом с ним что-то сделать.
С входящими запросами происходит примерно то же самое, поэтому мы его рассматривать не будем.
В чьих интересах Envoy обслуживает запросы, откуда он берет информацию?
На самом деле Envoy в sidecar'е не один: вместе с ним работает istio-agent. Именно он держит связь с Control Plane, получает от него всю информацию о состоянии кластера и переводит ее на понятный для Envoy язык:

Так Envoy получает информацию о состоянии кластера.
Далее разберемся с цепочкой istiod — Envoy.
Конвертация объектов Kubernetes в Envoy API
У каждого компонента нашего приложения есть Service. Компоненты могут жить в нескольких Подах, и у каждого — свой IP:

Всю эту информацию Control Plane (istiod) получает от API Kubernetes, переваривает и рассылает по Envoy в сайдкарах:

Чтобы разобраться, как устроен этот процесс, предлагаю представить себя на месте Istio и понять, какие объекты из мира K8s нам нужно преобразовать в объекты из мира Envoy:

Мы можем создать для Сервисов соответствующие кластеры, используя IP эндпоинтов и порт Сервисов:

Теперь мы можем настроить маршрутизацию между этими объектами. Что такое маршрутизация: мы берём запрос, берём какие-то параметры этого запроса и на их основе решаем, куда далее лететь запросу.
Что мы видим в перехваченном запросе:
TCP IP/port, куда летел запрос;
заголовок Host, если это HTTP-запрос;
TLS SNI, если трафик зашифрован на стороне приложения (в нашем кластере таких приложений нет, поэтому этот вариант не рассматриваем).
У нас в кластере есть два HTTP-сервиса (front и back), для идентификации которых можно использовать заголовок Host. Также есть обычный TCP-сервис (mysql).
Что получается: мы должны создать таблицу маршрутизации, в которой будут в кучу сложены и HTTP-, и TCP-сервисы? Но это как-то странно. Неужели мы будем залезать в каждый MySQL-запрос в поисках HTTP-заголовка?
В Istio согласились, что это неразумно и решили не объединять все сервисы в одну таблицу маршрутизации. Вместо этого для обычных TCP-сервисов, которые не поддерживают «умную» маршрутизацию, создаются отдельные listener'ы с отдельной таблицей маршрутизации:

В новом listener'е для MySQL (10.222.0.42:3306) таблица маршрутизации содержит единственную запись и по факту это не таблица, а обычный tcp proxy.
HTTP-сервисы мы можем смело объединить в другом listener'е, а различать их — по заголовку Host.
Итоговая схема:

Здесь внимательные люди вспомнят, как я говорил, что у Envoy есть только один listener:

Я почти не обманул. Да, этот listener в Envoy есть, и он действительно слушает порт 15001. Разница в том, что остальные listener'ы — «воображаемые». Их не видно в netstat, если вы посмотрите в сетевое пространство имен Пода. Эти listeners существуют только в воображении Envoy и называются «виртуальными».
Благодаря тому, что порт 15001 Envoy слушает с флагом use_original_dst, он может узнать оригинальный destination у ядра перед процедурой DNAT. На основе этих данных Envoy передает запрос на обработку соответствующему listener'у:

Примерно по такой схеме работает Envoy. Сейчас мы закрепим эту информацию, изучив жизненный цикл одного запроса.
Жизненный цикл запроса под управлением Istio
Возвращаемся к нашему Поду с приложением и Envoy. Допустим, нашему приложению потребовалось отправить GET-запрос. Оно делает resolve IP-адреса, получает его и отправляет запрос куда-то наружу. Envoy этот запрос перехватывает:

… и видит: запрос летел на порт 8080. Envoy понимает, что для этого запроса есть подходящий listener, и отправляет запрос ему на обработку.
Далее:
запрос обрабатывается фильтрами listener'а и маршрутизируется в кластер;
подходящий кластер выбирается на основе заголовка Host: в запросе (
back).

Далее в cluster:
настраиваем балансировку между существующими эндпоинтами;
устанавливаем TCP-соединение;
пополняем статистику для пассивного health check;
загружаем необходимые сертификаты для установки зашифрованного соединения;
калькулируем метрики;
отправляем запрос в соседний Под.
В итоге получается, что когда мы включаем Istio, наш запрос летает вот по такой загогулине:

С одной стороны, это пугает. С другой, у нас появился контроль через призму этих самых фильтров Envoy. И Istio на самом деле придуман для того, чтобы дать нам интерфейс управления этими фильтрами.
Особенности Istio API
Istio даёт нам набор интерфейсов:
PeerAuthentication — для управления аутентификацией входящих запросов.
DestinationRule — для управления аутентификацией при исходящих запросах; он же отвечает вообще за всё, что связано с исходящими запросами.
AuthorizationPolicy — для авторизации.
VirtualService — для маршрутизации.

Разберёмся с каждым из этих них.
PeerAuthentication
Спецификация интерфейса очень простая. Единственный флажок, который мы можем крутить, — «режим» (mode):
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: mtls-on
namespace: myns
spec:
mtls:
mode: XXX # <---Мы можем:
выключить входящую аутентификацию, то есть не валидировать запрос (
DISABLE);строго валидировать каждый входящий запрос (
STRICT);включить режим «ни нашим, ни вашим»: зашифрованные запросы валидируем, незашифрованные пропускаем как есть (
PERMISSIVE).
☝️ С последним режимом, PERMISSIVE, есть нюанс. Если у вас используется FTP, SMTP, MYSQL или другой протокол, который подразумевает, что первое слово за сервером — например, сервер должен сделать приветствие, — у Envoy «сорвет башню». Он будет ждать от клиента извне хотя бы один пакетик, чтобы понять, зашифрован он или нет. А клиент будет ждать приветствия от нашего подконтрольного приложения. Получается, проблема курицы и яйца. Это очень популярная ошибка, которую тяжело выявить. Имейте в виду.
DestinationRule
Хотя это сам по себе очень сложный объект, для настройки аутентификации нам тоже доступен только флаг mode:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: mtls-on
namespace: myns
spec:
host: *.myns.svc
trafficPolicy:
tls:
mode: XXX # <---Мы можем:
не шифровать исходящий запрос (
DISABLE);использовать для соединения клиентские сертификаты, которые сгенерировал Istio (
ISTIO_MUTUAL);использовать пользовательские клиентские сертификаты (
MUTUAL);просто валидировать сертификат сервера и не представляться клиентским сертификатом (
SIMPLE).
Если мы объединим два этих ресурса — PeerAuthentication и DestinationRule, — получим тот самый Mutual TLS.
☝️ Пугаться сложности не стоит: если вы твердо не знаете, зачем вам это надо, скорее всего, настраивать ничего не придётся. Istio делает это автоматически. Если он видит, что общение между двумя Подами идет под его управлением, — настраивает между ними Mutual TLS. Если хотя бы один из Подов не под управлением Istio, он работает в режиме PERMISSIVE, со всеми вытекающими.
DestinationRule также отвечает за все нюансы установки исходящих соединений:
балансировка между эндпоинтами;
настройка TCP-параметров;
пассивный health check (Circuit Breaking).
Для примера я подготовил такую хитрую спецификацию:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: mypolicy
spec:
host: back
trafficPolicy:
loadBalancer:
consistentHash:
httpCookie:
name: user
ttl: 0s
connectionPool:
tcp:
maxConnections: 1
http:
maxRequestsPerConnection: 10
outlierDetection:
consecutive5xxErrors: 7
interval: 5m
baseEjectionTime: 15mЧто тут написано:
Istio, если запрос полетит в сервис
back, используй не стандартный алгоритм балансировки, а алгоритмconsistentHashна основе httpCookie, которая называетсяuser;не устанавливай более одного TCP-соединения в сторону сервиса, обновляй это соединение каждые 10 запросов;
если какой-то из эндпоинтов сервиса будет «моросить» — то есть в течение 5 минут вернет хотя бы 7 ошибок, — дай ему отдохнуть на 15 минут.
Это всё, на что способен DestinationRule.
☝️ Здесь имеет место очень распространенная ошибка. В примере мы указали Istio, чтобы на сервис не летело больше одного соединения (maxConnections: 1). И мы надеемся, что Istio так и будет работать. Действительно: если у нас один клиентский сервис, и мы настроили один DestinationRule, у нас будет одно соединение. Но стоит нам масштабировать клиента, окажется, что каждый сайдкар будет поддерживать по соединению в сторону сервиса. И этим сайдкарам до лампочки, есть у них соседи или нет. Наше приложение может быть к этому не готово. Эту особенность Istio просто нужно иметь в виду.
☝️ И еще один нюанс. Меня несколько раз просили настроить активные health checks в Istio. Я не знаю, откуда люди берут эту информацию. Поэтому я решил вынести это в доклад: активных health checks в Istio нет. Есть только пассивные. И есть настоявшийся issue, на который я не оставляю надежды.
AuthorizationPolicy
Для авторизации запроса мы можем использовать разные параметры:
диапазоны IP;
-
параметры Kubernetes (если клиентский Под работает под управлением Istio):
из какого пространства имён прилетел запрос;
из-под какого ServiceAccount работает Под, сделавший этот запрос.
HTTP-параметры;
пользовательские заголовки.
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
selector:
matchLabels:
app: httpbin
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/sleep"]
- source:
namespaces: ["test"]
to:
- operation:
methods: ["GET"]
paths: ["/info*"]
when:
- key: request.auth.claims[iss]
values: ["https://accounts.google.com"]
- key: request.headers[X-Secret]
values: ["la-resistance"]
Самое интересное — то, что мы можем взять публичный ключ нашего провайдера аутентификации и передать его Istio. А тот сможет валидировать наши прикладные JWT-токены, которые находятся в HTTP-заголовке Authorization:. Из этих токенов можно достать лэйблы и на их основе производить авторизацию (см. поле when). Это очень удобно с точки зрения безопасности.
☝️ Выше я говорил, что к документации Istio есть определенные вопросы, в том числе в случае AuthorizationPolicy. Там как-то не по-людски описан процесс принятия решения. Я постарался это уладить в документации модуля istio для Deckhouse — перевел описание процесса на более понятный, на мой взгляд, язык. Надеюсь, кому-нибудь поможет.
Еще один важный нюанс с точки зрения безопасности — то, что авторизация работает на каждом сайдкаре, который встретится на пути запроса. Если запросу нельзя наружу, ближайший сайдкар его не выпустит. Но если запрос каким-то образом вылетел вовне и долетел до сервиса, то там его ждет еще одна проверка. Безопасность должна быть безопасной.
VirtualService
Разберем маршрутизацию на примере пары задач.
Допустим, у нас есть клиентский Под, который общается с бэкенд-сервисом. Мы решили отрефакторить бэкенд и вытащили из него админку. И теперь мы хотим, чтобы все запросы, у которых location начинается с /admin, отправлялись в новый сервис — admin:

Классическая задача, с которой Istio прекрасно справится. Для этого берем VirtualService с нехитрой спецификацией:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: back
spec:
hosts:
- back
http:
- match:
- uri:
prefix: "/admin"
route:
- destination:
host: admin
- route:
- destination:
host: back☝️ При этом для match нам необязательно использовать какие-то locations, HTTP-методы. Можно использовать всякие регулярные выражения, хуки, пользовательские заголовки, параметры Kubernetes и пр.
☝️ Стоит добавить, что VirtualService, как и DestinationRule, работает только на стороне клиента. Если запрос прилетел на какой-то сервис, второй раз маршрутизация производиться не будет.
Возьмем задачу посложнее: мы написали новую версию сервиса back и хотим, чтобы она поработала на реальной нагрузке, прежде чем выкатывать ее в production. То есть хотим реализовать пресловутый канареечный деплой. Как поступим?
Можно в лоб: выкатываем сервис в кластер в виде Deployment и добавляем его к существующему сервису. Тем самым мы расширяем список существующих endpoints еще одним:

И балансировка теперь происходит по одноранговым эндпоинтам. В принципе, это более-менее рабочий вариант. Для сельской местности сойдет.
Но есть вопросы:
Как нам выделить особые условия для нашего канареечного деплоя?
Как выделить фокус-группу?
Как повлиять на процент трафика, который прилетит на этот деплой?
Сделать всё это можно, но сложно. Поэтому этот вариант мы считаем скучным и не рассматриваем. Единственный плюс — для этого варианта можно даже Istio не включать.

Давайте к нашему Deployment добавим K8s-сервис:

Таким образом, в нашей системе появляется соответствующий кластер (в мире Istio), и мы можем маршрутизировать трафик в кластер back-canary.
Берем VirtualService и с его помощью настраиваем, например, Weighted Load Balancer. То есть направляем 90% трафика на оригинальный сервис, а 10% — на канареечный деплой:

К этому способу у меня лично нет вопросов. И я могу рекомендовать его каждому.
Но у Istio свой взгляд на ситуацию. Они, видимо, решили, что создавать новый сервис для канареечного деплоя — это как-то накладно, неудобно или неправильно. Поэтому они дали пользователям возможность виртуально клонировать существующий кластер. То есть взять всю информацию из кластера и скопировать в его клон. А еще дали возможность корректировать те или иные настройки этого кластера-клона:

Такой клон в мире Istio называется сабсет (subset). И они активно используют эту штуковину в своей документации. Поэтому я обязан был о ней рассказать.
Воспользуемся этими сабсетами. Создадим сабсет для бэкенда, поправим список эндпоинтов и настроим маршрутизацию.
Чтобы создать сабсет, нам нужно снова вернуться к DestinationRule — именно он отвечает за управление сабсетами. Вот его спецификация:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: back-canary
spec:
host: back
subsets:
- name: canary
labels:
version: newТут сказано: «возьми кластер back, создай для него сабсет с именем "canary” и скорректируй список энжпоинтов, используя другой label selector».
Теперь можно маршрутизировать запрос в сторону сабсета с помощью VirtualService:

Спецификация этого VirtualService похожа на предыдущий, кроме одного нюанса: 90% трафика у нас так же направляется на оригинальный кластер back, и оставшиеся 10% — тоже на кластер back, но точнее — на его сабсет.
В Istio считают, что это самый правильный способ делать канареечный деплой, поэтому активно форсят его в своей документации. Но лично я ни разу не встречал кейсов, когда использование сабсета было оправдано. Почти всегда можно создать еще один Сервис, и это будет гораздо прозрачнее и понятнее для пользователя.
Еще есть легенда, что Istio — это некое коробочное решение для «канарейки». Это не так. Istio умеет делать хитрую маршрутизацию и ничего более. То есть не более того, что умеет делать Envoy.
То же самое касается всех остальных интерфейсов. Istio — всего лишь интерфейс для настройки Envoy в ваших сайдкарах.

Но зато в этом ограничении есть преимущество: если вам что-то не понятно в документации интерфейсов Istio, вы можете найти что-то похожее в документации Envoy, и там, скорее всего, гораздо лучше всё написано.
Как Istio влияет на надежность
Какие вопросы обычно возникают к Istio в контексте надежности:
Что с latency?
Что с безопасностью?
Что, если что-то сломается?
Что с масштабированием?
Latency
Для предыдущего доклада я сделал пару сотен синтетических замеров. Главный вывод: нужно закладывать ~2,5 мс на запрос — и с этим придется жить.
Безопасность
В том же докладе я в деталях раскрыл, как работает Mutual TLS, как ротируются сертификаты, на основе каких данных и насколько это безопасно. Вывод: беспокоиться не о чем, если:
не пускать кого попало в API K8s;
не раздавать кому попало корневой сертификат Istio (не путать с корневым сертификатом Kubernetes);
бережно относиться к ServiceAccount-токенам, который Kubernetes генерирует для каждого Пода.
Ломаем компоненты
Вернемся к нашему привычному сетапу: фронтенд, бэкенд, база. Что с ним может пойти не так? Самое простое — может отвалиться какой-нибудь сайдкар внутри Data Plane. Трагедии здесь нет, просто этот Под будет висеть в crash.
Самое интересное — это когда отваливается Control Plane:

Тут начинаются спецэффекты. Control Plane перманентно рассылает информацию по сайдкарам. Если у нас в кластере что-то изменится — появится или сломается Под, появится Сервис и т. д. — Control Plane не узнает об этом от API K8s. Соответственно, не сможет разослать новую сводку по сайдкарам. Те будут жить по старым инструкциям, что, в принципе, иногда допустимо и катастрофы не произойдёт:

Но если в этой же ситуации у нас вдобавок падает существующий Под, нам останется только надеяться на outlier detection, то есть на пассивные health checks. Control Plane этот эндпоинт автоматически из списка не выпилит, чтобы не дёргать его.
Другая возможная неприятность: если у нас в кластере появится ещё один Под, которому нужно управление Istio, он зависнет в состоянии pending:

Control Plane также отвечает за инъекцию Подов, и в нашем случае он не сможет это сделать. Поэтому Под не появится в кластере. Грустно, но надо быть к этому готовым.
Масштабирование
Наше приложение-пример работает в пространстве имён. Допустим, оказалось, что кластер у нас коммунальный: мы выкатили туда ещё одно приложение либо компонент, с которым существующее приложение знаться не хочет. Для Control Plane дизайн нашего кластера не важен, все сайдкары он любит одинаково. Поэтому он честно рассылает полную сводку о состоянии кластера по каждому сайдкару:

То есть каждый сайдкар знает о существовании сервисов в соседнем пространстве имён: у них есть столько-то Подов, такие-то пользовательские настройки и пр. Это приводит к тому, что сайдкар начинает съедать больше ресурсов CPU и RAM. Но и это не катастрофа.
Настоящие проблемы начинаются, когда дело касается Control Plane. Ведь теперь на каждый чих в кластере Control Plane обязан рассылать сводку о состоянии кластера по каждому сайдкару. Причем делает он это асинхронно. И это очень дорогая операция. Рассылается не изменение (diff), которое произошло в кластере, не какое-то сообщение о том, что что-то поменялось, — Control Plane рассылает полный пакет с данными о состоянии кластера. Получается, что Control Plane как минимум вынужден «шевелить транзисторами» и косвенно съедать ресурсы сети:

Я видел сетап, где такой трафик перманентно съедал 500 Мбит.
Однако есть решение и этой проблемы. Самое правильное, что мы можем сделать, — воспользоваться ресурсом Sidecar. Он позволяет изолировать друг от друга группы Подов:

В спецификации Sidecar мы пишем (см. параметр hosts): «Не хочу знать никого, кроме ребят из пространства имён myns. Еще иногда хочу общаться с Control Plane».
Если мы распределим эти Sidecars по пространствам имён, область видимости сайдкаров снизится:

Тем самым снизится нагрузка на Control Plane и на сеть.
Это, кстати, хорошо и для безопасности: если компоненты не будут друг о друге знать, то не смогут друг друга сломать.
Другой способ решения проблемы — масштабировать Control Plane. Нагрузка между сайдкарами размажется. Но гарантий здесь нет, поэтому такой способ я не рекомендую.
Есть еще один способ — «секретный»: можно использовать протокол Delta xDS. Суть в том, что Istio на самом деле умеет рассылать не полную сводку, а только diff-ку. Это значительно сокращает нагрузку на Control Plane и сеть. Но это экспериментальная фича. Поэтому рекомендовать ее я тоже не буду. Я вам о ней не говорил.
Самые большие надежды у меня на другой подход к организации Service Mesh, который вскоре предоставит Istio: Ambient Mesh. В Istio решили отказаться от индивидуальных сайдкаров в пользу коммунальных. Теперь сайдкары будут размазаны по узлам с помощью DaemonSet. Это снизит нагрузку на Control Plane, упростит обновления и добавит много других плюшек (и, естестенно, анти-плюшек). Сейчас — в Istio 1.16 — Ambient Mesh еще нет. Ждём с нетерпением.
На этом всё. Надеюсь, информация из доклада поможет вам беспроблемно использовать Istio в ваших проектах.
Видео и слайды
Видеозапись выступления (~50 минут):
Презентация:
P.S.
Читайте также в нашем блоге:
alecx
Спасибо за отличный доклад.
В Istio DeltaXD еще не реализован полностью, но двигаются в этом направлении
This feature uses the delta xds api, but does not currently send the actual deltashttps://github.com/istio/istio/blob/29aa4bcc537997ed98b84c87edd0f5c73061d532/pilot/pkg/features/pilot.go#L637-L639В 1.17 выкатили Ambient в раннем альфа режиме. Так что ждем.