
На связи команда по разработке риск-моделей для крупного корпоративного, а также малого и среднего бизнеса банка «Открытие» — Андрей Бояренков, Владимир Иванов и Иван Луговский. В этой статье мы расскажем про наш опыт улучшения показателей ранжирования моделей оценки вероятности дефолта заемщика/скоринговых моделей за счет использования различных источников данных и объединения их в отдельные модули.
Стоит начать с ответа на вопрос, для чего вообще нужны скоринговые модели в банке? Скоринговые модели и модели оценки вероятности дефолта заемщика (PD модели) оказывают существенное влияние на все процессы банка и его доход. Такие модели используются как при принятии решений по заемщикам в качестве Cut-off при одобрении сделки, так и в подходах Risk Based Limit (RBL), Risk Based Pricing (RBP). То есть в подходах, когда лимит и процентная ставка зависят от вероятности дефолта отдельно взятого заемщика.
Помимо указанных выше областей применения скоринговые и PD модели также используются:
При расчете резервов банка и требуемого капитала;
Для риск-отчетности по качеству кредитного портфеля;
Для установления внутренних лимитов по рискам;
Для мониторинга изменения качества конкретных заемщиков и кредитного портфеля в целом.
Учитывая такое влияние, к моделям оценки вероятности дефолта предъявляются очень высокие требования в части ранжирующей способности и точности.

Теперь, когда функции скоринговых моделей определены, стоит разобраться с общей структурой модели. Нередко модели для клиентов корпоративного сегмента состоят из нескольких отдельных модулей, которые отличаются источниками данных для моделирования и, соответственно, объединяют факторы в одну смысловую группу. При грамотном подходе чем больше источников используется в модели, тем выше ее ранжирующая способность. Исторически в корпоративных моделях стандартно использовались следующие модули:
Модуль с финансовыми показателями, характеризующими деятельность компании. Данный модуль включает в себя факторы, связанные с ликвидностью, оборачиваемостью, финансовой независимостью, рентабельностью и динамикой бизнеса;
Модуль качественных факторов. К этому модулю относятся такие факторы, как прозрачность бизнеса, наличие конфликтов у акционеров, прогнозы рынка и т.п. Как правило, для формирования факторов используется историческая статистика из внутренних данных банка, то есть данные, которые оценивались банком при принятии решений по заемщикам.
Поскольку банки ограничены собственной статистикой, а также из-за того, что на рынке периодически происходят объединения банков, возникают сложности в сборе качественных факторов в исторических периодах для разработки моделей. Сами факторы могут не совпадать, методология сбора может отличаться, а информация может быть в наличии только за разрозненные периоды.
Поэтому сейчас уже фактически стало стандартом использование ряда дополнительных источников, которые помогают в решении данной проблемы. Самыми распространенными источниками на данный момент являются:
Транзакционные данные;
Данные кредитной истории;
Данные источников-агрегаторов;
Арбитражи.

Далее последовательно приведем описание всех перечисленных источников, каждый из которых формирует отдельный модуль модели.
Транзакционные данные
В каждом банке есть очень важный, доступный и бесплатный источник информации по клиентам — обороты по счетам и данные по депозитам. Эти данные могут оказывать разное влияние на вероятность дефолта. Например, вероятность дефолта клиента, как правило, тем ниже:
Чем ниже доля штрафов и судебных платежей в его расходах;
Чем выше доля уплаченных налогов;
Чем более стабильны поступления и расходы (самую низкую вероятность дефолта показывают клиенты, у которых идет умеренный рост поступлений и расходов, и, наоборот, резкий рост или падение расходов/поступлений могут увеличивать вероятность дефолта).
В целом из опыта можно сказать, что для малого и среднего бизнеса, который чаще, чем крупный держит средства в одном банке, это один из самых предсказательных модулей (коэффициент Джини более 50%), к тому же этот модуль показывает очень стабильные результаты при мониторинге модели.
Стоит отметить, что для работы с данным источником требуется формирование отдельных правил раскраски транзакций заемщика по категориям с использованием парсинга текста проводок. Например, возможно выделение таких категорий, как погашение кредитов, оплата налогов, выдача из кассы, аренда, инкассация, платежи от покупателей и т.д. Возможно выделение большого количества таких категорий, в том числе с использованием подходов ML.
Данные кредитной истории
При количественной оценке кредитного риска очень важна информация о том, как заемщик ранее обслуживал свой долг. Необходимо формирование в банке витрин, которые содержат информацию и по внутренней кредитной истории, и по внешней — из запросов в БКИ, которые делались по клиенту. Можно привести следующие примеры факторов:
Максимальный бакет просрочки по заемщику за последний год (1-30, 31-60, 60+);
Количество договоров, по которым допущена просрочка определенного типа за последний год;
Количество погашенных/закрытых договоров, количество действующих договоров;
Срок кредитной истории.
Возможен также учет типа продуктов: например, потребительских кредитов по индивидуальным предпринимателям.
Данные источников-агрегаторов
В качестве отдельных модулей могут использоваться данные источников-агрегаторов — таких, как: СПАРК, Селдон, Контур-фокус, БИР-Аналитик, Интегрум. Из данных источников можно взять информацию по отрасли, региону работы, сроку работы компании, количеству смен руководителей/собственников и т.д.
Арбитражи
Данные по арбитражам также могут оказывать сильное влияние на ранжирующую способность модели. В качестве примера можно привести следующие факторы:
Суммы исков в качестве ответчика по отношению к выручке/активам/прибыли;
Динамика зарегистрированных исков/проигранных дел (суммы, количество) за текущий год к предыдущему году;
Доля проигранных дел от всех поданных исков;
Возможно использование исков определенного типа (хозяйственные, налоговые, корпоративные, имущественные, административные, финансовые, др.)
Этот источник также важен для среднего и крупного бизнеса, поскольку, как правило, у таких компаний арбитражных споров больше.
Помимо перечисленных выше источников также возможно использование в моделях скорингов, основанных на данных телекоммуникационных компаний, по интернет-активности, платежных и фискальных данных.
Теперь, когда мы разобрались с возможной структурой модели, состоящей из разных модулей, возникает вопрос, как эти модули связать между собой, чтобы это стало полноценной моделью? Сейчас постепенно придем к ответу на этот вопрос.
При наличии большого количества источников наиболее оптимально формирование модульной структуры модели, когда каждый модуль отвечает за один или несколько схожих источников информации, а потом они взвешиваются с определяемыми на статистике весами в единый стекинг.

Разберемся, кто такой, а, точнее, что такое стекинг и как он применяется.
Стекинг
Стекинг в данном случае — это алгоритм объединения результатов работы различных модулей с целью получения итогового прогноза модели. Задача на этапе стекинга — получить финальный скоринговый балл (далее — скор) на основании скоров по всем модулям модели. Однако по определенной части наблюдений может не быть информации, необходимой для расчета скора по тому или иному модулю (например, если у компании нет отчетности или нет кредитной истории для применения соответствующих модулей). Чтобы решить эту проблему для каждого наблюдения, по которому нет необходимой информации, рассчитываются прокси-скоры.
Перед расчетом прокси-скоров по каждому из модулей модели необходимо рассчитать уровни дефолтности (Default Rate, DR):
по наблюдениям, где есть скоры (DR);
по наблюдениям, где нет скоров (DRns).
Для справки: Default Rate (DR), или уровень дефолтности — это отношение фактически вышедших в дефолт заемщиков ко всем недефолтным заемщикам на начало рассматриваемого периода, обычно выражается в процентах.
Для построения регрессии и расчета прокси-скоров рассчитывается калибровочный вес по формуле:
где dr — фактическая вероятность дефолта по выборке, tr — целевая вероятность дефолта.
Затем на данных выборки строится логистическая регрессия с присвоением классам весов W_calib для недефолтных и 1 для дефолтных наблюдений. Из результатов регрессии сохраняются коэффициенты a и b.
def calibration(scores, target, tr):
”””
Функция калибровки.
- scores – значения скоров
- target – массив меток о дефолте в выборке для разработки
- tr – целевой Default Rate
”””
model = LogisticRegression(penalty=’none’, class_weight={0:w_calib, 1:1})
model.fit(scores, target)
# параметры
a = model.intercept_[0]
b = model.coef_[0][0]
return a, bЗдесь и для дальнейшего понимания нужно учесть, что вероятность дефолта связана со скором следующей формулой:
где S — скор, PD — вероятность дефолта (probability of default)
На основании полученных коэффициентов a и b значение вероятности дефолта может быть переведено в скор по формуле, приведенной выше.
Вероятность дефолта наблюдений без реальных скоров по модулю считается равной DRns, таким образом, прокси-значение скора по данным наблюдениям получается путем преобразования DRns в скор. После этого в выборке с наблюдениями без скора проставляется полученный единый для таких наблюдений прокси-скор.
Для получения итогового скора применяется логистическая регрессия, имеющая вид:
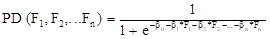
где:
PD (F1, F2,…,Fn) — моделируемая вероятность дефолта;
Fn — трансформированное и нормализованное значение скора модуля n;
βn — коэффициенты регрессии.
Значения коэффициентов регрессии получаем посредством максимизации функции правдоподобия:

где:
L (Y1, Y2,..., Yn; ϴ) — функция максимального правдоподобия;
Y1...n — реализованное событие;
Pϴ (Yn) — логистическая регрессия, моделирующая вероятность дефолта;
ϴ — вектор коэффициентов βn логистической регрессии.
Веса факторов определялись на основе коэффициентов логистической регрессии в соответствии с формулой:

где:
Wi – вес i-го фактора;
βi – коэффициент регрессии i-го фактора;
βj– коэффициенты логистической регрессии.
Подводя итог: данная структура модели — модули, взвешенные в единый стекинг — позволяет существенно улучшить ранжирование по модели, в отличие от «плоской» структуры, когда вся модель — это один модуль с набором факторов из разных источников. Можно привести пример, подтверждающий преимущества модульной структуры модели. Так, при тестировании одной из последних разработанных моделей были получены следующие показатели: +8% показателя Джини модели в абсолютном значении, +15% — в относительном при модульной структуре модели по сравнению с «плоской».
К этому моменту мы разобрались с различными источниками данных, из которых формируются модули модели и выяснили, что такое стекинг и для чего он нужен. Казалось бы, все шаги пройдены, итоговый скор по модели получен, все готово. Но нет. Остался последний, немаловажный этап — калибровка.
Калибровка
После стекинга средняя предсказанная вероятность дефолта может не совпадать с целевой вероятностью для всего портфеля. Поэтому полученные результаты нужно откалибровать на целевой прогнозируемый по кредитному портфелю показатель Default Rate (DR).
Калибровка выполняется в два этапа.
На первом этапе необходимо получить коэффициенты a и b калибровочной кривой. Они подбираются таким образом, чтобы средняя рассчитанная вероятность дефолта PD стремилась к заданному уровню. Важно отметить, что все действия выполняются на выборке для разработки.
Для выборки рассчитывается фактическая вероятность дефолта по формуле:
где N_def — количество дефолтов, N_obs — количество наблюдений.
Аналогично стекингу, здесь рассчитывается калибровочный вес и строится логистическая регрессия, из которой сохраняются коэффициенты a и b.
Первый этап калибровки (на выборке для разработки) может не позволить корректно учесть ряд существенных аспектов, влияющих на итоговую вероятность дефолта, т.к. в исторической статистике не было данной информации (например, влияние данных по поддержке группы, в которую входит заемщик, наличие предупреждающих сигналов и т.п.). Поэтому необходим второй этап калибровки, который проводится на выборке клиентов текущего портфеля, так как эта выборка более приближена к ситуации применения в силу наличия в ней большего количества информации по клиентам.
Целью второго этапа является изменение смещения калибровочной кривой при ее неизменной форме таким образом, чтобы средняя вероятность дефолта PD текущего портфеля с учетом дополнительных модулей соответствовала целевому прогнозируемому по кредитному портфелю показателю Default Rate (DR).
print(‘Подбор параметра минимизации’)
methods = [‘BFGS’,
‘L-BFGS-B’,
‘SLSQP’,
‘Nelder-Mead’,
‘Powell’,
‘CG’,
‘Newton-CG’,
‘TNC’,
‘COBYLA’,
‘trust-constr’,
‘dogleg’,
‘trust-ncg’,
‘trust-exact’,
‘trust-krylov’]
for method in methods:
print(method)
minimizer = minimize(
calc_min_score,
a,
method = method
)
if minimizer.success:
break
if not minimizer.success:
raise ValueError(‘Подбор не удался!’)
res = minimizer.x.tolist()[0]И вот теперь точно все! В этой статье мы рассказали вам о сущности и областях применения скоринговых моделей и моделей PD; осветили возможные дополнительные источники данных для моделирования, а также их связь с модулями модели; объяснили, как связать все модули для получения итогового скора (стекинг) и коротко описали процесс калибровки полученной модели.
Для решения задач, описанных в статье, применяются стандартные функции sklearn и scipy в Python.